Generate diagnostic reports to monitor the internal stages of the export process. This tool aids in unblocking model exports and debugging the exporter.
#### Settings
~~1. Choose if you want to produce a .sarif file and specify its location.~~
1. Updated: saving .sarif file should be done by `export_output.save_sarif_log(dst)`, similar to saving exported onnx model `export_output.save(model_dst)`.
2. Customize diagnostic options:
- Set the desired verbosity for diagnostics.
- Treat warnings as errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106741
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby, https://github.com/malfet
RFC: https://github.com/pytorch/rfcs/pull/54
First commit is the contents of https://github.com/Quansight-Labs/numpy_pytorch_interop/
We have already been using this in core for the last few months as a external dependency. This PR pulls all these into core.
In the next commits, I do a number of things in this order
- Fix a few small issues
- Make the tests that this PR adds pass
- Bend backwards until lintrunner passes
- Remove the optional dependency on `torch_np` and simply rely on the upstreamed code
- Fix a number dynamo tests that were passing before (they were not tasting anything I think) and are not passing now.
Missing from this PR (but not blocking):
- Have a flag that deactivates tracing NumPy functions and simply breaks. There used to be one but after the merge stopped working and I removed it. @lezcano to investigate.
- https://github.com/pytorch/pytorch/pull/106431#issuecomment-1667079543. @voznesenskym to submit a fix after we merge.
All the tests in `tests/torch_np` take about 75s to run.
This was a work by @ev-br, @rgommers @honno and I. I did not create this PR via ghstack (which would have been convenient) as this is a collaboration, and ghstack doesn't allow for shared contributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106211
Approved by: https://github.com/ezyang
https://github.com/pytorch/pytorch/issues/105555
Existing flow first exports and then calls torch._inductor.aot_compile. However, export calls aot_autograd with the core aten decomposition table, and then torch._inductor.aot_compile calls aot_autograd again with the inductor decomposition table. The 2nd calling of aot_autograd is supposedly causing some problems, and seems excessive, so instead we will create a new function, torch._export.aot_compiler which will export using the inductor decomposition table, pass it to inductor's compile_fx_aot, and because it has already been exported, avoid recalling aot_autograd.
```
def aot_compile(
f: Callable,
args: Tuple[Any],
kwargs: Optional[Dict[str, Any]] = None,
constraints: Optional[List[Constraint]] = None,
) -> Tuple[str, ExportedProgram]:
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105977
Approved by: https://github.com/desertfire, https://github.com/zhxchen17, https://github.com/eellison
Includes stable diffusion, whisper, llama7b and clip
To get this to work I had to Pass in hf auth token to all ci jobs, github does not pass in secrets from parent to child automatically. There's a likelihood HF will rate limit us in case please revert this PR and I'll work on adding a cache next - cc @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @ipiszy @chenyang78 @aakhundov @malfet
Something upstream changed in torchbench too where now `hf_Bert` and `hf_Bert_large` are both failing on some dynamic shape looking error which I'm not sure how to debug yet so for now felt a bit gross but added a skip since others are building on top this work @ezyang
`llamav2_7b_16h` cannot pass through accuracy checks cause it OOMs on deepcloning extra inputs this seems to make it not need to show up in expected numbers csv, will figure this when we update the pin with https://github.com/pytorch/benchmark/pull/1803 cc @H-Huang @xuzhao9 @cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106009
Approved by: https://github.com/malfet
### Description
As an alternative to PR #105774, which provides a standalone, end-to-end minification script that covers all types of failures and has more functionality, this PR adds the ability to minify models when they fail the eval loop (accuracy checks). Both this PR and the other one can be merged without issue.
### Purpose
The goal is to leverage the minifier to minify models that fail accuracy checks, allowing failed models to be debugged more easily. The ideal use-case is trying to run a model suite on a backend where operator coverage is not known or is limited. If models can compile but fails the eval loop, having the repro script for each model is valuable for any developer that's trying to fix the issue.
### Functionality
- Create minify flag that minifies models when they fail accuracy check
- Produce minified graph for each model, and save it into repro script
- Move repro script to output directory/base Dynamo directory
- Enable functionality for running an entire model suite (Hugging Face, timm, and TorchBench) by prepending model name to repro script
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106201
Approved by: https://github.com/ezyang
Summary:
Original PR at https://github.com/pytorch/pytorch/pull/104977. Landing from fbcode instead.
Add an aot_inductor backend (Export+AOTInductor) in the benchmarking harness. Note it is not a dynamo backend.
Moved files from torch/_inductor/aot_inductor_include to torch/csrc/inductor as a more standard way for exposing headers
Created a caching function in benchmarks/dynamo/common.py for compiling, loading and caching the .so file, as a proxy for a pure C++ deployment, but easier for benchmarking.
Differential Revision: D47452591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105221
Approved by: https://github.com/jansel
The general idea is to do a separate CUDA graph for each size. Because of cuda graph trees, these graphs will all share the same memory pool, so your memory usage will only be the worst case memory usage of the biggest dynamic size you want. This requires an extra dispatch in the cudagraphified callable. You must pay for a CUDA graph recording for every dynamic size you encounter, but this is MUCH cheaper than running the entire PT2 compile stack, so I expect you to still see benefits.
This was surprisingly easy to do.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105064
Approved by: https://github.com/voznesenskym
This PR disables translation validation (TV) when running the benchmark suits on
performance workflows: inductor with A100s.
In summary, the changes are:
- Add flag for turning TV on and off on _benchmarks/dynamo/common.py_
- Turn TV on only on CI accuracy builds
- Add `--no-translation-validation` target flag to _.ci/pytorch/test.sh_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104887
Approved by: https://github.com/ezyang
As of now, translation validation runs to its completion. However, Z3 is time
consuming. PR #104464, for example, disables translation validation for a few benchmarks.
Instead, this PR introduces a timeout for translation validation. In that case, Z3 will
return `unknown`, since it wasn't able to prove or disprove the assertions. Then, we log
it as a warning, but don't stop execution.
Here's a summary of the changes:
- Added an environment variable for turning translation validation on and off
- Added an environment variable for setting the translation validation timeout
- Possibly reverts the changes in #104464
- ~~Move from "QF_NRA" to "QF_NIRA" logic~~
- ~~It makes more sense, given the nature of the problems~~
- "QF_NRA" seems to solve more instances of _dynamo/test_dynamic_shapes.py_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104654
Approved by: https://github.com/ezyang
issues resolved: https://github.com/pytorch/pytorch/issues/104294
local test on TB and TIMM
* python benchmarks/dynamo/torchbench.py -d cuda --inference --accuracy --progress --export --print-dataframe-summary
* python benchmarks/dynamo/timm_models.py -d cuda --inference --accuracy --progress --export --print-dataframe-summary
why not HF
* huggingface use kwargs (dict) to torch.nn.module
* we will need to support kwargs in torch._export.export, which is in progress
local test result
timm 95% pass rate (58 ouf of 61 passed) P781702926
* 1 x [export specific]1 x ERROR:common:Mutating module attribute rel_indices during export
* 1 x[not relevant to export] Unknown model (SelecSls42b)
* 1 x [not relevant to export] Failed to load model: HTTP Error 409: Public access is not permitted on this storage account
torchbench 54% pass rate (41 out of 75 passed) P781690552
* 7 x ERROR:common:Dynamo input and output is a strict subset of traced input/output
* 3 x ERROR:common:call_method NNModuleVariable() / UserDefinedObjectVariable
* 3 x ERROR:common:Mutating module attribute {xx} during export.
* 2 x ERROR:common:inline in skipfiles
* 2 x ERROR:common:Consider annotating your code using constrain_as_*(). It appears that you're trying
* 1 x ERROR:common:guard on data-dependent symbolic int/float
* 1 x ERROR:common:Tensor.tolist
* 1 x ERROR:common:Tensor.numpy. Turn on config.numpy_ndarray_as_tensor and install torch_np to support tensor.numpy(). [may be dev * env?]
* 1 x ERROR:common:missing: BUILD_SET
* 1 x ERROR:common:whole graph export entails exactly one guard export
* 1 x ERROR:common:call_function BuiltinVariable(str) [GetAttrVariable(UserMethodVariable(<function
* 1 x ERROR:common:Dynamic slicing on data-dependent value is not supported
* 1 x ERROR:common:Failed running call_function <function interpolate at 0x7f60a8361ea0>(*(FakeTensor(..., device='cuda:0', size=(1, 3, * 427,
* 1 x ERROR:common:Dynamo attempts to add additional input during export: value=0.6177528500556946, source=RandomValueSource(random_call_index=0)
* 1 x Found following user inputs located at [16, 17, 18, 19, 20, 21, 22] are mutated. This is currently banned in the aot_export workflow.
* 1 x RuntimeError: cumsum_cuda_kernel does not have a deterministic implementation
* 4 x pass_due_to_skip
* 1 x eager_2nd_run_OOM
* 1 x fail_accuracy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104382
Approved by: https://github.com/zhxchen17
Some notes:
* I now manually turn off `_generate` jobs from running with cudagraphs, as it is unrealistic to expect to cudagraph autoregressive generation up to max sequence length, this would imply compiling the entire unrolled sequence generation. Concretely, cm3leon_generate was timing out post this change, likely due to the compile time slowdown of dynamic shapes ON TOP OF accidentally unrolling all the loops
* A few torch._dynamo.reset tactically inserted to force recompiles on tests that expected it
* expectedFailureAutomaticDynamic flip into patching automatic_dynamic_shapes=False
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103623
Approved by: https://github.com/voznesenskym
This PR turns translation validation on by default for tests and accuracy benchmark
runs. It also installs Z3 on CI.
The main changes are:
- Add `--no-translation-validation` as an option in _test/run_tests.py_
- Set `PYTORCH_TEST_WITH_TV` environment variable
- Add `TEST_WITH_TV` variable in _torch/testing/_internal/common_utils.py_
- Turn translation validation on for accuracy benchmarks in _benchmarks/dynamo/common.py_
- Add Z3 installation on CI scripts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103611
Approved by: https://github.com/ezyang
- Extend dynamo bench interface with '--compilers onnx' and '--compilers dynamo-onnx'
- ONNX bench exports model to onnx and runs in ONNX Runtime.
- Introduce error aggregation and report.
- Scripts to build ONNX deps and running ONNX bench.
- Huggingface accuracy check workaround for ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103135
Approved by: https://github.com/thiagocrepaldi, https://github.com/jansel
Previously, cudagraphs and dynamic_shapes were incompatible and enabling
dynamic shapes would forcibly disable cudagraphs. This new strategy
I think is better. The idea is essentially that cudagraphs is an
"optimization" that happens to guard on every input. When cudagraphs
is on, we force everything static, and this automatically does the right
thing because we will force a recompile if sizes change.
This obsoletes https://github.com/pytorch/pytorch/pull/101813
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103290
Approved by: https://github.com/voznesenskym, https://github.com/eellison
Originally, my goal for this PR was to remove the `dynamic_shapes` tests in torch/_dynamo/variables/builder.py. However, one thing lead to another, and it turns out that it was easiest to do all of the following in one go:
* Unconditionally allocate a ShapeEnv, no matter if dynamic_shapes is enabled or not (torch/_dynamo/output_graph.py). There is a small adjustment to export torch/_dynamo/eval_frame.py to account for the fact that a ShapeEnv always exists, even if you're not doing symbolic export.
* Remove dynamic_shapes test from unspec logic (torch/_dynamo/variables/builder.py), the original goal
* Specialize strides and storage offset if all sizes are dynamic (torch/fx/experimental/symbolic_shapes.py). This is required to deal with unconditional ShapeEnv: if a ShapeEnv exist, fake tensor-ification may choose to allocate symbols. The idea is that with `automatic_dynamic_shapes == False`, Dynamo should never request dynamic sizes, but this invariant was not upheld for nontrivial strides/offset.
The rest are just auxiliary fixups from the above:
* Workaround bug in FakeTensorProp where sometimes it doesn't return a FakeTensor (torch/fx/passes/fake_tensor_prop.py), see https://github.com/pytorch/pytorch/pull/103395 for follow up
* Make ShapeProp correctly handle int inputs (torch/fx/passes/shape_prop.py)
* Disable indexing strength reduction if `assume_static_by_default` is False (torch/_inductor/codegen/triton.py)
* Fix hf_T5_generate to NOT toggle `assume_static_by_default` if dynamic shapes is not enabled (benchmarks/dynamo/common.py); technically this is not necessary anymore but it's in for safety.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103302
Approved by: https://github.com/voznesenskym
Previously, cudagraphs and dynamic_shapes were incompatible and enabling
dynamic shapes would forcibly disable cudagraphs. This new strategy
I think is better. The idea is essentially that cudagraphs is an
"optimization" that happens to guard on every input. When cudagraphs
is on, we force everything static, and this automatically does the right
thing because we will force a recompile if sizes change.
This obsoletes https://github.com/pytorch/pytorch/pull/101813
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103290
Approved by: https://github.com/voznesenskym
Even if you passed in --amp we would run inference in float32.
`AlbertForMaskedLM` goes from 1.305 float32 to 1.724x amp, and then again to 1.910x with freezing. Benchmark numbers for amp are about to go way up lol.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103220
Approved by: https://github.com/desertfire
The "tolerance" option evaluates the model on the baseline device in eager mode (default: CPU) compared to the test device (e.g., CUDA, XLA, etc.) and compares the output tensors to determine the absolute tolerance value based on the [formula](https://pytorch.org/docs/stable/generated/torch.allclose.html). It then saves the results in a CSV file. This comparison highlights the tolerance/accuracy difference between XLA and GPU/CPU devices and can also be used to evaluate newer accelerators. This feature aims to identify accuracy failures on the test device (e.g., XLA) and facilitate quick bug triaging.
This feature enables the following capabilities:
1. Ability to monitor accuracy issues of backends
2. Provide more informative picture on accuracy beyond pass/ fail status
3. Having a dump of accuracy information will help triage models accordingly
The data generated using this feature is in the [spreadsheet](https://docs.google.com/spreadsheets/d/1A8BAzSqfAw0Q5rgzK5Gk__Uy7qhuynh8tedxKnH-t94/edit#gid=0).
The spreadsheet data can be used to compile the below summary table:
| Suite | Max Tolerance | | No. of models with high inaccuracy(>=0.005) | | Mean Tolerance | |
|------------------ |:-------------:|:--------:|:-------------------------------------------:|:--------:|:--------------:|:--------:|
| | xla | inductor | xla | inductor | xla | inductor |
| huggingface | 0.1169 | 0.0032 | 1 | 0 | 0.0022 | 0.0005 |
| timm_models | 0.0373 | 2.8892 | 10 | 8 | 0.0028 | 0.7044 |
| torchbench | 3.013 | 3.0381 | 6 | 2 | 0.0016 | 0.0016 |
| All models | 3.013 | 3.0381 | 17 | 10 | 0.0028 | 0.7044 |
I used PyTorch release/2.0 branch and corresponding [commit_pin](https://github.com/pytorch/pytorch/blob/release/2.0/.github/ci_commit_pins/xla.txt) for XLA to generate the above data.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102218
Approved by: https://github.com/jansel
With the TQDM changes in #100969 -- the models names ended up getting hidden from the benchmark printouts. We would print the model name with no newline, then tqdm would print a `\r` and overwrite the name of the running model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101627
Approved by: https://github.com/ezyang
This pr accomplishes
1) Enables retries for downloading torchbenchmark and huggingface models in a similar method to how we do it for timm models right now.
2) creates a `_download_model` function for the hugging face and TIMM runners whose output I plan to use to preload the models somewhere if possible (please double check I'll be saving the right thing). Instead of retries, we plan to just add torchbench to a docker image as it is relatively small.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 3361a4c</samp>
> _We're the brave and bold coders of the `common.py` module_
> _We've made a handy function for downloading models_
> _We've shared it with our mates in the other runners_
> _So pull and push and try again, we'll get them all in time_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101019
Approved by: https://github.com/huydhn, https://github.com/desertfire
Previously, we had a problem when partitioning forward-backward dynamic graphs, which is that we could end up with a backward graph that mentions a symbol in an input tensor (e.g., `f32[s0 + s1]`), but without this symbol being otherwise bound elsewhere. When this happens, we have no way of actually deriving the values of `s0` and `s1`. Our fix for this in https://github.com/pytorch/pytorch/pull/93059 was to just retrace the graph, so that s0 + s1 got allocated a new symbol s2 and everything was happy. However, this strategy had other problems, namely (1) we lost all information from the previous ShapeEnv, including guards and (2) we end up allocating a LOT of fresh new symbols in backwards.
With this change, we preserve the same ShapeEnv between forward and backwards. How do we do this? We simply require that every symbol which may be present inside tensors, ALSO be a plain SymInt input to the graph. This invariant is enforced by Dynamo. Once we have done this, we can straightforwardly modify the partitioner to preserve these SymInt as saved for backwards, if they are needed in the backwards graph to preserve the invariant as well.
This apparently breaks yolov3, but since everything else is OK I'm merging this as obviously good and investigating later.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99089
Approved by: https://github.com/voznesenskym
Dynamo benchmark --verbose is broken:
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 400, in <module>
torchbench_main()
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 396, in torchbench_main
main(TorchBenchmarkRunner(), original_dir)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 1967, in main
return maybe_fresh_cache(
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 993, in inner
return fn(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 2135, in run
torch._dynamo.config.log_level = logging.DEBUG
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/config_utils.py", line 67, in __setattr__
raise AttributeError(f"{self.__name__}.{name} does not exist")
AttributeError: torch._dynamo.config.log_level does not exist
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99224
Approved by: https://github.com/voznesenskym
Symbolic shapes compile time on full CI with inductor is horribly long (even though our aot_eager local runs seemed to suggest that the added latency was only 10s per model.) To patch over the problem for now, run the benchmark suite with dynamic batch only. This should absolve a lot of sins.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97912
Approved by: https://github.com/janeyx99, https://github.com/desertfire
Follow-up to #96245. alexnet, Background_Matting, vision_maskrcnn, and vgg16 all have the same problem; but on float32 they were also failing on the previous day so I missed this. Once the amp jobs became available I could see that these have the same issue (on both float32 and amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96324
Approved by: https://github.com/desertfire
Summary: ciflow/inductor-perf-test-nightly now contains full dashboard
run which takes a very long time. Ed proposed a simplification of the
perf run there, but it is still worth to have a set of fast perf test
which only includes one configuration (--training --amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96166
Approved by: https://github.com/huydhn, https://github.com/weiwangmeta
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
Summary: When running the benchmark test with --accuracy, two eager runs
should return the same result. If not, we want to detect it early, but
comparing against fp64_output may hide the non-deterministism in eager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95616
Approved by: https://github.com/ZainRizvi
I believe this fixes the AllenaiLongformerBase problem in periodic.
The longer version of the problem is here is we are currently optimistically converting all item() calls into unbacked SymInt/SymFloat, but sometimes this results in a downstream error due to a data-dependent guard. Fallbacks for this case are non-existent; this will just crash the model. This is bad. So we flag guard until we get working fallbacks.
What could these fallbacks look like? One idea I have is to optimistically make data-dependent calls unbacked, but then if it results in a crash, restart Dynamo analysis with the plan of graph breaking when the item() call immediately happened.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94987
Approved by: https://github.com/Skylion007, https://github.com/malfet
```
GuardOnDataDependentSymNode: It appears that you're trying to get a value out of symbolic int/float whose value is data-dependent (and thus we do not know the true value.) The expression we were trying to evaluate is Eq(i3, -1). Scroll up to see where each of these data-dependent accesses originally occurred.
While executing %as_strided : [#users=1] = call_method[target=as_strided](args = (%pad,), kwargs = {size: (12, %add, 768, 64), stride: (%getitem, %mul, %getitem_1, %getitem_2)})
Original traceback:
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/models/longformer/modeling_longformer.py", line 928, in <graph break in _sliding_chunks_matmul_attn_probs_value>
chunked_value = padded_value.as_strided(size=chunked_value_size, stride=chunked_value_stride)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94986
Approved by: https://github.com/albanD
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
The functorch setting still exists, but now it is no longer necessary:
we infer use of Python dispatcher by checking if the ambient
FakeTensorMode has a ShapeEnv or not. The setting still exists,
but it is for controlling direct AOTAutograd use now; for PT2,
it's sufficient to use torch._dynamo.config.dynamic_shapes.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94469
Approved by: https://github.com/Chillee, https://github.com/voznesenskym, https://github.com/jansel
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Change the dynamo benchmark timeout from hard code to a parameter with default value 1200ms, cause the hard code 1200ms timeout led some single thread mode model crashed on CPU platform. With the parameter, users can specify the timeout freely.
Fixes#94281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94284
Approved by: https://github.com/malfet
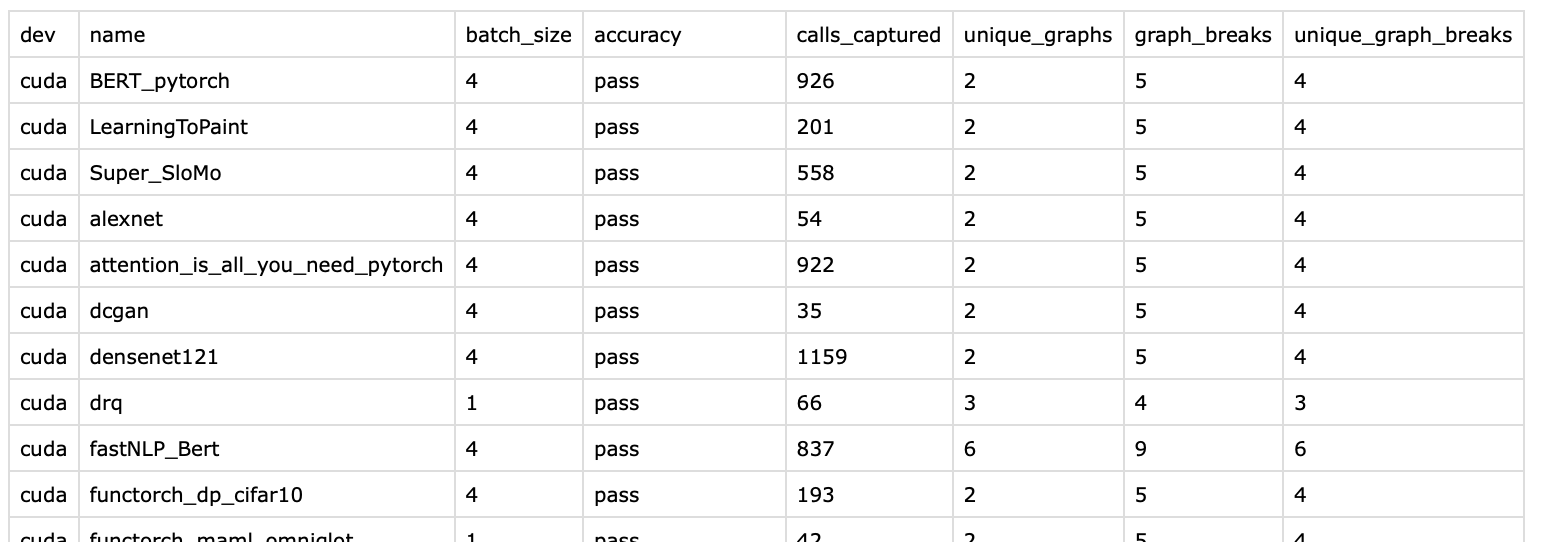
graph break != graph count - 1. Suppose you have a nested
inline function call f1 to f2 to f3. A graph break in f3
results in six graphs: f1 before, f2 before, f3 before, f3 after,
f2 after, f1 after.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94143
Approved by: https://github.com/voznesenskym
These backends have been broken for some time. I tried to get them
running again, but as far as I can tell they are not maintained.
Installing torch_tensorrt downgrades PyTorch to 1.12. If I manually
bypass that downgrade, I get import errors from inside fx2trt. Fixes that
re-add these are welcome, but it might make sense to move these wrappers
to the torch_tensorrt repo once PyTorch 2.0 support is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93822
Approved by: https://github.com/frank-wei
As @peterbell10 pointed out, it was giving incorrect results for `compression_ratio`
and `compression_latency` when you used `--diff-branch`.
This fixes this by running a separate subprocess for each branch to make sure you are not being affected by run for other branch.
Also added a couple of more significant figures
to numbers in summary table.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93989
Approved by: https://github.com/jansel
--diff_main renamed to --diff-branch BRANCH and now works again
Summary table splits results per branch.
csv output now has column with branch name when run in this mode
Added --progress flag so you can track how many models are going to be
run.
Example output:
```
$ python benchmarks/dynamo/torchbench.py --quiet --performance --backend inductor --float16 --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt) --filter 'alexnet|vgg16' --progress --diff viable/strict
Running model 1/2
batch size: 1024
cuda eval alexnet dynamo_bench_diff_branch 1.251x p=0.00
cuda eval alexnet viable/strict 1.251x p=0.00
Running model 2/2
batch size: 128
cuda eval vgg16 dynamo_bench_diff_branch 1.344x p=0.00
cuda eval vgg16 viable/strict 1.342x p=0.00
Summary for tag=dynamo_bench_diff_branch:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.09x mean=25.26x
compilation_latency mean=2.0 seconds
compression_ratio mean=0.9x
Summary for tag=viable/strict:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.11x mean=25.29x
compilation_latency mean=0.5 seconds
compression_ratio mean=1.0x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92713
Approved by: https://github.com/jansel
Since the CI exclusions are hard-coded in our script, we might as well require them to match exactly. This solved some head scratching where I was like, "this model is not obviously excluded, why is it not showing up in CI."
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92761
Approved by: https://github.com/jansel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}