Summary:
Add base support for torch.logspace. See #19220 for details.
SsnL can you feedback? Thanks a lot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19542
Differential Revision: D15028484
Pulled By: soumith
fbshipit-source-id: fe5a58a203b279103abbc192c754c25d5031498e
Summary:
Changelog:
- Rename `potri` to `cholesky_inverse` to remain consistent with names of `cholesky` methods (`cholesky`, `cholesky_solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `cholesky_inverse` under the name `potri` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19498
Differential Revision: D15029901
Pulled By: ezyang
fbshipit-source-id: 2074286dc93d8744cdc9a45d54644fe57df3a57a
Summary:
Attempt fix for #14057 . This PR fixes the example script in the issue.
The old behavior is a bit confusing here. What happened to pickling is python2 failed to recognize `torch.float32` is in module `torch`, thus it's looking for `torch.float32` in module `__main__`. Python3 is smart enough to handle it.
According to the doc [here](https://docs.python.org/2/library/pickle.html#object.__reduce__), it seems `__reduce__` should return `float32` instead of the old name `torch.float32`. In this way python2 is able to find `float32` in `torch` module.
> If a string is returned, it names a global variable whose contents are pickled as normal. The string returned by __reduce__() should be the object’s local name relative to its module
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18045
Differential Revision: D14990638
Pulled By: ailzhang
fbshipit-source-id: 816b97d63a934a5dda1a910312ad69f120b0b4de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18960
empty_affine_quantized creates an empty affine quantized Tensor from scratch.
We might need this when we implement quantized operators.
Differential Revision: D14810261
fbshipit-source-id: f07d8bf89822d02a202ee81c78a17aa4b3e571cc
Summary:
This adds checks for `mul_`, `add_`, `sub_`, `div_`, the most common
binops. See #17935 for more details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19317
Differential Revision: D14972399
Pulled By: zou3519
fbshipit-source-id: b9de331dbdb2544ee859ded725a5b5659bfd11d2
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Now compatible with both torch scripts:
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"), pin_memory=False)`
and
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"))`
Same checked for all similar functions `rand_like`, `empty_like` and others
It is fixed version of #18455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18952
Differential Revision: D14801792
Pulled By: VitalyFedyunin
fbshipit-source-id: 8dbc61078ff7a637d0ecdb95d4e98f704d5450ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18546
We'll expose all combinations of various ways of quantization in the top level dispatch key, that is we have AffineCPUTensor, PerChannelAffineCUDATensor, etc.
QTensor method added:
- is_quantized()
- item()
Differential Revision: D14637671
fbshipit-source-id: 346bc6ef404a570f0efd34e8793056ad3c7855f5
Summary:
I've been messing around with vectorizing the fusion compiler in JIT, and noticed that these ops were pathologically slow. I moved them to use TensorIterator + Vec256<> and got some speed wins.
Benchmark script:
```
import torch, time
ops = ['abs', 'neg', 'reciprocal', 'frac']
x = torch.rand(1024, 1024)
NITER = 10000
print('op', 'time per iter (ms)', 'gops/s', 'GB/s', sep='\t')
for op in ops:
s = time.time()
for i in range(NITER):
getattr(x, op)()
elapsed_sec = ((time.time() - s) / NITER)
print(op, elapsed_sec * 1000, (1024*1024/elapsed_sec)/1e9, (1024*1024*4*2) / elapsed_sec / 1e9, sep='\t')
```
Before this change (on my mac with a skylake):
```
op time per iter (ms) gops/s GB/s
abs 0.9730974197387695 1.0775652866097343 8.620522292877874
neg 1.0723679780960083 0.9778136063534356 7.822508850827485
reciprocal 1.2610594034194946 0.8315040490215421 6.6520323921723366
frac 1.1681334018707275 0.8976509004200546 7.181207203360437
```
After this change:
```
op time per iter (ms) gops/s GB/s
abs 0.5031076192855835 2.084198210889721 16.673585687117768
neg 0.4433974027633667 2.3648672578256087 18.91893806260487
reciprocal 0.47145988941192624 2.2241043693195985 17.79283495455679
frac 0.5036592721939087 2.0819154096627024 16.65532327730162
```
So, after this change it looks like we are hitting machine peak for bandwidth and are bandwidth bound.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19041
Differential Revision: D14862037
Pulled By: jamesr66a
fbshipit-source-id: e2032ac0ca962dbf4120bb36812277c260e22912
Summary:
Changelog:
- Rename `btrisolve` to `lu_solve` to remain consistent with names of solve methods (`cholesky_solve`, `triangular_solve`, `solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `lu_solve` under the name `btrisolve` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18726
Differential Revision: D14726237
Pulled By: zou3519
fbshipit-source-id: bf25f6c79062183a4153015e0ec7ebab2c8b986b
Summary:
Partial fix of: https://github.com/pytorch/pytorch/issues/394
- `gels` and `triangular_solve` now returns namedtuple
- refactor test for namedtuple API for better coverage and maintainability
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17195
Differential Revision: D14851875
Pulled By: ezyang
fbshipit-source-id: 9b2cba95564269d2c3a15324ba48751d68ed623c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18832
ghimport-source-id: fde4ad90541ba52dfa02bdd83466f17e6541e535
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18833 [STACK] Cache device on TensorImpl; clean up TensorImpl constructors.
* **#18832 [STACK] Disallow changing the device of a tensor via set_.**
* #18831 [STACK] Stop swapping in Storages of the wrong device for Tensors.
This is necessary to cache the device on a TensorImpl.
Differential Revision: D14766231
fbshipit-source-id: bba61634b2d6252ac0697b96033c9eea680956e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18831
ghimport-source-id: 2741e0d70ebe2c2217572c3af54ddd9d2047e342
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18833 [STACK] Cache device on TensorImpl; clean up TensorImpl constructors.
* #18832 [STACK] Disallow changing the device of a tensor via set_.
* **#18831 [STACK] Stop swapping in Storages of the wrong device for Tensors.**
This is necessary to support device caching, see https://github.com/pytorch/pytorch/pull/18751 and https://github.com/pytorch/pytorch/pull/18578.
In library code, we potentially swap in Storages with the wrong device when device_guard is False. This happens as follows with "view-like" operations.
1) We allocate a tensor on the 'wrong' device (because device_guard is false).
2) We swap out the 'wrong' storage with the 'right' storage using e.g. THCTensor_setStorage.
Instead, we can just construct the Tensor with the correct Storage from the beginning. This is what we do with 'view'.
Note there are two other "view-like" cases where this happens:
1) unfold
2) set_()
Because these aren't performance critical, I just added the device_guard instead of applying the above correction.
For completeness, this also includes a test that all `device_guard: false` functions behave properly under these conditions.
Reviewed By: dzhulgakov
Differential Revision: D14766232
fbshipit-source-id: 0865c3ddae3f415df5da7a9869b1ea9f210e81bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18648
ghimport-source-id: 1cf4a8fe91492621e02217f38cae5d7e0699fb05
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18661 Step 7: remove _unique
* #18655 Step 6: Rename _unique2 to unique and add int? dim
* #18654 Step 5: remove _unque_dim in favor of unique_dim
* #18651 Step 4: add support for unique with dim=None
* #18650 Step 3: Add support for return_counts to torch.unique for dim not None
* #18649 Step 2: Rename _unique_dim2_temporary_will_remove_soon to unique_dim
* **#18648 Step 1: Secretly add return_counts to unique, and refactor unique_dim for performance**
`unique` is fragile, previously I tried to change it in #18391 and #17097, they all pass OSS tests but finally get reverted due to internal failure. My previous work of refactoring unique #18459 is based on #18391, and after #18391 get reverted, I could not work on #18459. To continue working on #18459, #18391, and #17097 without worrying about internal failures, I am suggesting the following steps for the improvements of `unique` and `unique_dim`. soumith Please take this and there is no need to put #18391 back.
The motivation is basically to move forward as much as possible without causing any internal failures. So I will try to divide it into steps and sort from low probability of internal failure to high probability. (I don't know what the internal failure is, so I have to guess). Let's merge these PR stack one by one until we enounter internal failure.
Step 1: Create two new ATen operators, `_unique2_temporary_will_remove_soon` and `_unique_dim2_temporary_will_remove_soon` and keep `_unique` and `_unique_dim` unchanged. The backend of these two functions and `_unique` and `_unique_dim` are all the same, the only difference is the temporary ones support `return_counts` but not the `_unique` and `_unique_dim`. Step one is mostly #18391 + #18459. The cuda8 errors has been fixed. At this point, there is no user visible API change, so no docs are updated. `torch.unique` does not support `return_counts` yet, and `return_counts` is tested through the newly added temporary operators. This step just added two new ATen operators, so there shouldn't be any internal failure.
Step 2: Rename `_unique_dim2_temporary_will_remove_soon` to `unique_dim`. This should cause no internal failure either, because no change to existing operators. The only thing to worry about is to delete `unique_dim` from python side because we don't want users to use it. At this point, C++ users now have `return_counts` support for `unique_dim`.
Step 3: Update the docs of `torch.unique` and use `unique_dim` inside `torch.unique` to support `return_counts` In the docs, we should say `torch.unique` with None dim support does not support `return_counts` yet. This might cause internal failure.
Step 4: Rename `_unique2_temporary_will_remove_soon` to `_unique2` and use `_unique2` inside `torch.unique` to support `return_counts`. Update the docs saying that `torch.unique` with None dim now support `return_counts`. This might cause internal failure.
Step 5: Remove `_unique_dim`. This might cause internal failure.
Step 6: Rename `_unique2` to `unique`, add optional `dim` argument to make it looks like the signature of Python's `torch.unique`. Inside `torch.unique`, use `unique` and get rid of `unique_dim`. Unbind `unique_dim` totally from Python at codegen. This is likely to cause internal fail.
Step 7: Remove `_unique`. This is very likely to cause internal failure.
This PR
======
This PR is for step 1. This create two new ATen operators, `_unique2_temporary_will_remove_soon` and `_unique_dim2_temporary_will_remove_soon` and implement `return_counts` inside them and do refactor for performance improvements.
Please review ngimel VitalyFedyunin. They are mostly copied from #18391 and #18459, so the review should be easy.
Below is a benchmark on a tensor of shape `torch.Size([15320, 2])`:
Before
---------
```python
print(torch.__version__)
%timeit a.unique(dim=0, sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(dim=0, sorted=True, return_inverse=True); torch.cuda.synchronize()
```
```
1.0.1
192 µs ± 1.61 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
548 ms ± 3.39 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
```python
print(torch.__version__)
%timeit a.unique(sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(sorted=True, return_inverse=True); torch.cuda.synchronize()
```
```
1.0.1
226 µs ± 929 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
302 µs ± 7.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After
-------
```python
print(torch.__version__)
%timeit a.unique(dim=0, sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(dim=0, sorted=True, return_inverse=True); torch.cuda.synchronize()
%timeit torch._unique_dim2_temporary_will_remove_soon(a, dim=0, sorted=True, return_inverse=False, return_counts=True); torch.cuda.synchronize()
%timeit torch._unique_dim2_temporary_will_remove_soon(a, dim=0, sorted=True, return_inverse=True, return_counts=True); torch.cuda.synchronize()
```
```
1.1.0a0+83ab8ac
190 µs ± 2.14 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
237 µs ± 1.23 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
219 µs ± 2.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
263 µs ± 1.15 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
```python
print(torch.__version__)
%timeit a.unique(sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(sorted=True, return_inverse=True); torch.cuda.synchronize()
%timeit torch._unique2_temporary_will_remove_soon(a, sorted=True, return_inverse=False, return_counts=True); torch.cuda.synchronize()
%timeit torch._unique2_temporary_will_remove_soon(a, sorted=True, return_inverse=True, return_counts=True); torch.cuda.synchronize()
```
```
1.1.0a0+83ab8ac
232 µs ± 2.21 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
301 µs ± 1.65 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
264 µs ± 7.67 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
339 µs ± 9.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Differential Revision: D14730905
fbshipit-source-id: 10026b4b98628a8565cc28a13317d29adf1225cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18230
Implementing minimum qtensor API to unblock other workstreams in quantization
Changes:
- Added Quantizer which represents different quantization schemes
- Added qint8 as a data type for QTensor
- Added a new ScalarType QInt8
- Added QTensorImpl for QTensor
- Added following user facing APIs
- quantize_linear(scale, zero_point)
- dequantize()
- q_scale()
- q_zero_point()
Reviewed By: dzhulgakov
Differential Revision: D14524641
fbshipit-source-id: c1c0ae0978fb500d47cdb23fb15b747773429e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18749
ghimport-source-id: 9026a037f5e11cdb9ccd386f4b6b5768b9c3259b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18751 Disallow changing the device of a tensor via set_.
* #18750 Use non-legacy constructors for tensor deserialization.
* **#18749 Add device and dtype to storage.**
The goal here is to fix our serialization, which currently depends on the legacy constructors. Having dtype and device on Storage allows us to use the non-legacy constructors.
This fits somewhat along our goal of removing Storage, my having Storage act like a Tensor.
Differential Revision: D14729516
fbshipit-source-id: bf4a3e8669ad4859931f4a3fa56df605cbc08dcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18166
ghimport-source-id: a8e2ba2d966e49747a55701c4f6863c5e24d6f14
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18166 Bool Tensor for CUDA**
* #18165 Resolved comments from Bool Tensor for CPU PR
------
This PR enables bool tensor creation and some basic operations for the CPU backend. This is a part of Bool Tensor feature implementation work. The whole plan looks like this:
1. Storage Implementation [Done]
2. Tensor Creation.
a) CPU [Done]
b) CUDA [This PR]
3. Tensor Conversions.
4. Tensor Indexing.
5. Tensor Operations.
6. Back compatibility related changes.
Change:
Enable bool tensor in CUDA with the following operations:
torch.zeros
torch.tensor
torch.ones
torch.rand/rand_like/randint/randint_like
torch.full
torch.full_like
torch.empty
torch.empty_like
Tested via unit tests and local scripts.
Differential Revision: D14605104
fbshipit-source-id: b7d7340a7d70edd03a109222d271e68becba762c
Summary:
Argument dim=-1 doesn't work for torch.cross. The signature of the torch.cross has been changed to c10::optional<int64_t> dim instead of int64_t. So based on document "If dim is not given, it defaults to the first dimension found with the size 3." and if dim is specified (even negative) it will use the correspondent dim.
Fixes#17229
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17582
Differential Revision: D14483063
Pulled By: ifedan
fbshipit-source-id: f9699093ec401cb185fd33ca4563c8a46cdcd746
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18455
Reviewed By: ezyang
Differential Revision: D14672084
Pulled By: VitalyFedyunin
fbshipit-source-id: 9d0997ec00f59500ee018f8b851934d334012124
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Changelog:
- Renames `btriunpack` to `lu_unpack` to remain consistent with the `lu` function interface.
- Rename all relevant tests, fix callsites
- Create a tentative alias for `lu_unpack` under the name `btriunpack` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18529
Differential Revision: D14683161
Pulled By: soumith
fbshipit-source-id: 994287eaa15c50fd74c2f1c7646edfc61e8099b1
Summary:
Changelog:
- Renames `btrifact` and `btrifact_with_info` to `lu`to remain consistent with other factorization methods (`qr` and `svd`).
- Now, we will only have one function and methods named `lu`, which performs `lu` decomposition. This function takes a get_infos kwarg, which when set to True includes a infos tensor in the tuple.
- Rename all tests, fix callsites
- Create a tentative alias for `lu` under the name `btrifact` and `btrifact_with_info`, and add a deprecation warning to not promote usage.
- Add the single batch version for `lu` so that users don't have to unsqueeze and squeeze for a single square matrix (see changes in determinant computation in `LinearAlgebra.cpp`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18435
Differential Revision: D14680352
Pulled By: soumith
fbshipit-source-id: af58dfc11fa53d9e8e0318c720beaf5502978cd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18507
ghimport-source-id: 1c3642befad2da78a7e5f39d6d58732b85c76267
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18507 Upgrade flake8-bugbear to master, fix the new lints.**
It turns out Facebobok is internally using the unreleased master
flake8-bugbear, so upgrading it grabs a few more lints that Phabricator
was complaining about but we didn't get in open source.
A few of the getattr sites that I fixed look very suspicious (they're
written as if Python were a lazy language), but I didn't look more
closely into the matter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14633682
fbshipit-source-id: fc3f97c87dca40bbda943a1d1061953490dbacf8
Summary:
This depend on https://github.com/pytorch/pytorch/pull/16039
This prevent people (reviewer, PR author) from forgetting adding things to `tensors.rst`.
When something new is added to `_tensor_doc.py` or `tensor.py` but intentionally not in `tensors.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16057
Differential Revision: D14619550
Pulled By: ezyang
fbshipit-source-id: e1c6dd6761142e2e48ec499e118df399e3949fcc
Summary:
More ops for https://github.com/pytorch/pytorch/issues/394. ~~Also need to rebase after landing #16186, because we need to update the whitelist of the new unit test added in #16186.~~
cc: ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17093
Differential Revision: D14620068
Pulled By: ezyang
fbshipit-source-id: deec5ffc9bf7624e0350c85392ee59789bad4237
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18165
ghimport-source-id: 55cb3fb63a25c2faab1725b4ec14c688bf45bd38
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18166 Bool Tensor for CUDA
* **#18165 Resolved comments from Bool Tensor for CPU PR**
-------
------------
This is a follow up PR that resolves some additional feedback on one the of previous Bool Tensor PRs.
gchanan, here is a list of almost all the comments from the original PR with respective fixes and replies:
**[utils/python_scalars.h]** why is this converting from uint8_t and not bool? (comment?)
When i was adding this, i was testing by creating a tensor and then calling its .tolist(). it worked for bool and uint8_t equally good so i left uint8_t as thought it makes more sense as we are calling PyBool_FromLong. �Changing it to bool.
**[ATen/Dispatch.h]**better name?.
fixed.
**[test/test_torch.py]** what about other factories, such as full? (and more).
There is a test that goes through the factory methods - test_tensor_factories_empty. i added some bool cases above it and added a comment that once CUDA will be done, i will unite them and it will iterate not just between CUDA and CPU but also all types. ��Adding all bool cases now. Will unite in CUDA PR.
**[generic/THTensorMath.h]** any changes in this file actually needed?
Bad merge. Fixed.
**[TH/THTensor.h]** this generates code for random, clampedRandom, and cappedRandom -- do we have tests for all of these with bool?
Added
**[c10/core/ScalarType.h]** I'm not very confident about the lack of Bool here -- can you look at the call sites and see what makes sense to do here?
Added bool to the macro and created a similar one without for a single case which fails the build with errors:
_./torch/csrc/jit/symbolic_variable.h:79:20: error: ambiguous overload for ‘operator*’ (operand types are ‘const torch::jit::SymbolicVariable’ and ‘torch::jit::Value*’)
return (*this) * insertConstant(rhs);_
Differential Revision: D14605105
fbshipit-source-id: abf82d50e8f8c50b386545ac068268651b28496d
Summary:
`SobolEngine` is a quasi-random sampler used to sample points evenly between [0,1]. Here we use direction numbers to generate these samples. The maximum supported dimension for the sampler is 1111.
Documentation has been added, tests have been added based on Balandat 's references. The implementation is an optimized / tensor-ized implementation of Balandat 's implementation in Cython as provided in #9332.
This closes#9332 .
cc: soumith Balandat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10505
Reviewed By: zou3519
Differential Revision: D9330179
Pulled By: ezyang
fbshipit-source-id: 01d5588e765b33b06febe99348f14d1e7fe8e55d
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/12598
This PR was originally authorized by ptrblck at https://github.com/pytorch/pytorch/pull/15495, but since there was no update for months after the request change, I clone that branch and resolve the code reviews here. Hope everything is good now. Especially, the implementation of count is changed from ptrblck's original algorithm to the one ngimel suggest, i.e. using `unique_by_key` and `adjacent_difference`.
The currently implementation of `_unique_dim` is VERY slow for computing inverse index and counts, see https://github.com/pytorch/pytorch/issues/18405. I will refactor `_unique_dim` in a later PR. For this PR, please allow me to keep the implementation as is.
cc: ptrblck ezyang ngimel colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18391
Reviewed By: soumith
Differential Revision: D14605905
Pulled By: VitalyFedyunin
fbshipit-source-id: 555f5a12a8e28c38b10dfccf1b6bb16c030bfdce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18362
ghimport-source-id: 374b7ab97e2d6a894368007133201f510539296f
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18242 Test running a CUDA build on CPU machine.
* **#18362 Add ability to query if built with CUDA and MKL-DNN.**
Fixes#18108.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14584430
fbshipit-source-id: 7605a1ac4e8f2a7c70d52e5a43ad7f03f0457473
Summary:
Changelog:
- Renames `trtrs` to `triangular_solve` to remain consistent with `cholesky_solve` and `solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `triangular_solve` under the name `trtrs`, and add a deprecation warning to not promote usage.
- Move `isnan` to _torch_docs.py
- Remove unnecessary imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18213
Differential Revision: D14566902
Pulled By: ezyang
fbshipit-source-id: 544f57c29477df391bacd5de700bed1add456d3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18231
ghimport-source-id: 78c230f60c41877fe91b89c8c979b160f36f856b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18231 Add a decorator for marking slow tests.**
The general strategy:
- It's a normal skip decorator, which triggers a skip if
PYTORCH_TEST_WITH_SLOW is not set.
- It also annotates the method in question that says it's
slow. We use this to implement a catch-all skipper in
setUp that skips all non-slow tests when
PYTORCH_TEST_SKIP_FAST is set.
I added a little smoketest to test_torch and showed that I get:
```
Ran 432 tests in 0.017s
OK (skipped=431)
```
when running with PYTORCH_TEST_WITH_SLOW=1 and PYTORCH_TEST_SKIP_FAST=1
CI integration coming in later patch, as well as nontrivial uses of
this decorator.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14544441
fbshipit-source-id: 54435ce4ec827193e019887178c09ebeae3ae2c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18181
ghimport-source-id: 9c23551584a1a1b0b7ac246367f3a7ae1c50b315
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18184 Fix B903 lint: save memory for data classes with slots/namedtuple
* **#18181 Fix B902 lint error: invalid first argument.**
* #18178 Fix B006 lint errors: using mutable structure in default argument.
* #18177 Fix lstrip bug revealed by B005 lint
A variety of sins were committed:
- Some code was dead
- Some code was actually a staticmethod
- Some code just named it the wrong way
- Some code was purposely testing the omitted case
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14530876
fbshipit-source-id: 292a371d9a76ddc7bfcfd38b6f0da9165290a58e
Summary:
Why do we need this workaround? `PythonArgParser` handles these two cases well.
The discussion started at https://github.com/pytorch/pytorch/pull/6201#issuecomment-378724406. The conclusion at that time by goldsborough was:
> Because we wanted to allow `dim=None` in Python and route to a different function. Essentially the problem was wanting to wrap the C++ function in Python. AFAIK there is no way of translating `dim=None` behavior into C++? So Richard and I came up with this strategy
Maybe at that time `PythonArgParser` was not powerful enough to handle the routing of two function with same name but different C++ signature.
Will keep an eye on the CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17103
Differential Revision: D14523503
Pulled By: VitalyFedyunin
fbshipit-source-id: cae3e2678062da2eccd93b51d4050578c7a9ab80
Summary:
- Remove single batch TH/THC implementations
- Remove `_batch_trtrs_lower` from `multivariate_normal`
- Add tests for batched behavior
- Modify trtrs_backward to accommodate for batched case
- Modify docs
In a future PR, this will be renamed to `triangular_solve`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18025
Differential Revision: D14523004
Pulled By: ifedan
fbshipit-source-id: 11c6a967d107f969b60e5a5c73ce6bb8099ebbe1
Summary:
Changelog:
- Renames `gesv` to `solve` to remain consistent with `cholesky_solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `solve` under the name `gesv`, and add a deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18060
Differential Revision: D14503117
Pulled By: zou3519
fbshipit-source-id: 99c16d94e5970a19d7584b5915f051c030d49ff5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17927
ghimport-source-id: 626d321e430b6b5c0ea3aa1eb9df8c1e2d058bf8
Stack:
* #17926 Implement at::has_internal_overlap helper function
* **#17927 Error out on in-place (unary) ops on tensors that have internal overlap**
On the way to #17935.
Works for CPU and CUDA on the following ops:
- abs_, acos_, asin_, atan_, ceil_, cos_, erf_, erfc_, exp_, expm1_
- floor_, log_, log10_, log1p_, log2_, round_, rsqrt_,
- sin_, sqrt_, tan_, tanh_, trunc_
This PR adds a check to see if the out/result tensor has internal
overlap. If it does, then we error out because the result **may** be
incorrect.
This is overly conservative; there are some cases where if the result is
the same as the input, the inplace operation is OK (such as floor_,
round_, and trunc_). However, the current code isn't organized in such a
way that this is easy to check, so enabling those will come in the future.
Reviewed By: ezyang
Differential Revision: D14438871
fbshipit-source-id: 15e12bf1fdb2ab7f74bb806e22bc74840bd6abd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17926
ghimport-source-id: 9f7572b5d43e474492363fa17dcb86a6c27ca13c
Stack:
* **#17926 Implement at::has_internal_overlap helper function**
* #17927 Error out on in-place (unary) ops on tensors that have internal overlap
On the way to #17935.
Checks if a tensor's sizes/strides indicate that multiple elements share
the same memory location. This problem in general is hard so
at::has_internal_overlap implements two heuristics and avoids solving
the general problem:
if a tensor is contiguous, it cannot have internal overlap
if a tensor has any zero strides, it does have internal overlap
otherwise, return MemOverlap::kTooHard to indicate that there might be
overlap, but we don't know.
Reviewed By: ezyang
Differential Revision: D14438858
fbshipit-source-id: 607ab31771315921ab6165b2a1f072ac3e75925a
Summary:
ROCm 2.2 was released today, if we respin the CI docker images with the attached, PyTorch/Caffe2 will support ROCm 2.2
Changes necessary:
* for the Ubuntu target, HIP PR 934 needs to be applied to fix the forceinline definition. ROCm 2.3 will contain this.
* two unit tests proof flaky on different platforms, disable them defensively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18007
Differential Revision: D14473903
Pulled By: bddppq
fbshipit-source-id: b1939f11d1c765a3bf71bb244b15f6ceb0e816d3
Summary: https://github.com/pytorch/pytorch/pull/17995 's CI has verified it should fix the CI.
Reviewed By: bddppq
Differential Revision: D14447674
fbshipit-source-id: 50085db9ae7421b5be216ed0a2216234babfdf6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17807
Lint also detected a bug in test_linspace where we weren't
actually testing the CUDA case.
Differential Revision: D14388241
fbshipit-source-id: e219e46400f4952c6b384bca3baa0724ef94acde
Summary:
This PR causes kthvalue to be consistent with sort
(i.e. treat NaN as larger than any number), so that
`a.kthvalue(n) == a.sort()[n - 1]`.
One drawback is that median with a NaN argument does not return NaN,
which is a deviation from NumPy.
Thank you, ngimel, for raising this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17824
Differential Revision: D14410092
Pulled By: ezyang
fbshipit-source-id: bdec2d8272dc4c65bcf2f9b8995e237774c44c02
Summary:
Motivation:
- Earlier, `torch.btrifact` could not handle tensors with greater than 3 dimensions. This is because of the check:
> AT_CHECK(THTensor_(nDimension)(a) == 3, "expected 3D tensor, got size: ", a->sizes());
What is in this PR?:
- Move `btrifact` to ATen
- Remove relation to TH/THC.
- Handle tensors with more than three dimensions
- Tests
- Docs modifications: added a note about the non-pivoting variant.
[blocked due to old magma-cuda binaries]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14964
Differential Revision: D14405106
Pulled By: soumith
fbshipit-source-id: f051f5d6aaa45f85836a2867176c065733563184
Summary:
Currently the following code gives an error on python 2 because `ret` is a structseq which is not a tuple
```python
ret = a.max(dim=0)
ret1 = torch.max(a, dim=0, out=ret)
```
This PR modify tuple check in python arg parser to allow structseq to be input of operators where tuple is expected, which would make the above code work.
Depend on: https://github.com/pytorch/pytorch/pull/17136
Partially fixes: https://github.com/pytorch/pytorch/issues/16813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17208
Differential Revision: D14280198
Pulled By: VitalyFedyunin
fbshipit-source-id: beffebfd3951c4f5c7c8fe99a5847616a89491f3
Summary:
- Test updates
1. test_torch: added 0-d test case and t_() test cases
2. test_jit : updated error message for TestAsync.test_async_script_error
- Updating documentation for torch.t()
Adding information regarding new support of 0-D and 1-D tenso
Fixes#17520
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17535
Differential Revision: D14269984
Pulled By: gchanan
fbshipit-source-id: 38b723f31484be939261c88edb33575d242eca65
Summary:
Pytorch's tensor.t() is now equivalent with Numpy's ndarray.T for 1D tensor
i.e. tensor.t() == tensor
Test case added:
- test_t
fixes#9687
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17462
Differential Revision: D14214838
Pulled By: soumith
fbshipit-source-id: c5df1ecc8837be22478e3a82ce4854ccabb35765
Summary:
I originally set out to fix to_sparse for scalars, which had some overly restrictive checking (sparse_dim > 0, which is impossible for a scalar).
This fix uncovered an issue with nonzero: it didn't properly return a size (z, 0) tensor for an input scalar, where z is the number of nonzero elements (i.e. 0 or 1).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17406
Differential Revision: D14185393
Pulled By: gchanan
fbshipit-source-id: f37a6e1e3773fd9cbf69eeca7fdebb3caa192a19
Summary:
Currently, when the input tensor `self` is not contiguous, `tril_` and `triu_` calls `self = self.contiguous()`, which allocates a new contiguous tensor and assign it to `self`. This effectively changes the input tensor `self`'s pointer and will break downstream code after Variable/Tensor merge.
This PR fixes it so that `tril_` and `triu_` always update the input tensor in-place and preserve the input tensor's TensorImpl.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17031
Differential Revision: D14069592
Pulled By: yf225
fbshipit-source-id: d188218f426446a44ccc1d33fc28ac3f828c6a05
Summary:
This is the first commit from a series of planned changes in order to add boolean tensors to PyTorch. The whole plan looks like this:
0. Storage Implementation (this change)
1. Tensor Creation.
2. Tensor Conversions.
3. Tensor Indexing.
4. Tensor Operations.
5. Back compatibility related changes.
This feature was requested by the community:
https://github.com/pytorch/pytorch/issues/4764https://github.com/pytorch/pytorch/issues/4219https://github.com/pytorch/pytorch/issues/4288
**Change**:
Added boolean type to the Storage class for CPU and CUDA backends.
**Tested via**:
1. unit tests
2. running this:
-> import torch
-> torch.BoolStorage
<class 'torch.BoolStorage'>
-> torch.cuda.BoolStorage
<class 'torch.cuda.BoolStorage'>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16810
Reviewed By: gchanan
Differential Revision: D14087246
Pulled By: izdeby
fbshipit-source-id: 042642ced1cb0fd1bb6bff05f9ca871a5c54ee5e
Summary:
Based on https://github.com/pytorch/pytorch/pull/12413, with the following additional changes:
- Inside `native_functions.yml` move those outplace operators right next to everyone's corresponding inplace operators for convenience of checking if they match when reviewing
- `matches_jit_signature: True` for them
- Add missing `scatter` with Scalar source
- Add missing `masked_fill` and `index_fill` with Tensor source.
- Add missing test for `scatter` with Scalar source
- Add missing test for `masked_fill` and `index_fill` with Tensor source by checking the gradient w.r.t source
- Add missing docs to `tensor.rst`
Differential Revision: D14069925
Pulled By: ezyang
fbshipit-source-id: bb3f0cb51cf6b756788dc4955667fead6e8796e5
Summary:
This fixes the segfault.
Changelog:
- Modify the function calls in LegacyDefinitions for `geqrf_out` and `ormqr_out`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16964
Differential Revision: D14025985
Pulled By: gchanan
fbshipit-source-id: aa50e2c1694cbf3642273ee14b09ba12625c7d33
Summary:
This is the first round of enabling unit tests that work on ROCm 2.1 in my tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16871
Differential Revision: D13997662
Pulled By: bddppq
fbshipit-source-id: d909a3f7dd5fc8f85f126bf0613751c8e4ef949f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16548
With this macro, a caffe2 operator can now directly be registered with c10.
No need to write custom wrapper kernels anymore.
Differential Revision: D13877076
fbshipit-source-id: e56846238c5bb4b1989b79855fd44d5ecf089c9c
Summary:
Move `logsumexp` and `max_values` to `TensorIterator` and use it to make `logsumexp` work for multiple dimensions.
Timings on a tensor of shape `(10,1000000,10)`, for each combination of (cpu, single-threaded cpu, gpu) and dimension:
**before**
208 ms ± 2.72 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
279 ms ± 5.07 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
199 ms ± 2.64 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.11 s ± 33.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.25 s ± 25.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.11 s ± 6.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
15.4 ms ± 1.02 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
132 ms ± 30.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
39.6 ms ± 19.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
**after**
199 ms ± 8.23 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
307 ms ± 8.73 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
207 ms ± 7.62 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
1.16 s ± 8.92 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.26 s ± 47.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.13 s ± 13.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
15.4 ms ± 868 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
132 ms ± 27.6 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
39.6 ms ± 21.8 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16475
Differential Revision: D13855746
Pulled By: umanwizard
fbshipit-source-id: aaacc0b967c3f89073487e1952ae6f76b7bd7ad3
Summary:
So that things like below can be JITable, and available in C++ API:
```python
import torch
torch.jit.script
def f(x, y, z):
x.index_add(0, y, z)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12413
Differential Revision: D13899948
Pulled By: suo
fbshipit-source-id: b0006b4bee2d1085c813733e1037e2dcde4ce626
Summary:
cdist is used for calculating distances between collections of observations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16168
Differential Revision: D13739147
Pulled By: ifedan
fbshipit-source-id: 9419c2c166891ac7db40672c72f17848f0b446f9
Summary:
Partially fixes: https://github.com/pytorch/pytorch/issues/394
Implementation detail:
Codegen is modified to generate codes that looks like below:
```C++
static PyObject * THPVariable_svd(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"svd(Tensor input, bool some=True, bool compute_uv=True, *, TensorList[3] out=None)",
}, /*traceable=*/true);
ParsedArgs<6> parsed_args;
auto r = parser.parse(args, kwargs, parsed_args);
static PyStructSequence_Field fields0[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc0 = {
"torch.return_types.svd_out", nullptr,
fields0, 3
};
static PyTypeObject type0;
static bool namedtuple_type_initialized0 = false;
if (!namedtuple_type_initialized0) {
PyStructSequence_InitType(&type0, &desc0);
namedtuple_type_initialized0 = true;
}
static PyStructSequence_Field fields1[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc1 = {
"torch.return_types.svd", nullptr,
fields1, 3
};
static PyTypeObject type1;
static bool namedtuple_type_initialized1 = false;
if (!namedtuple_type_initialized1) {
PyStructSequence_InitType(&type1, &desc1);
namedtuple_type_initialized1 = true;
}
if (r.idx == 0) {
if (r.isNone(3)) {
return wrap(&type1, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2)));
} else {
auto results = r.tensorlist_n<3>(3);
return wrap(&type0, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2), results[0], results[1], results[2]));
}
}
Py_RETURN_NONE;
END_HANDLE_TH_ERRORS
}
```
Types are defined as static member of `THPVariable_${op_name}` functions, and initialized at the first time the function is called.
When parsing function prototypes in `native_functions.yaml`, the parser will set the specified name as `field_name` when see things like `-> (Tensor t1, ...)`. These field names will be the field names of namedtuple. The class of namedtuples will be named `torch.return_types.${op_name}`.
In some python 2, `PyStructSequence` is not a subtype of tuple, so we have to create some functions to check if an object is a tuple or namedtuple for compatibility issue.
Operators in `native_functions.yaml` are changed such that only `max` and `svd` are generated as namedtuple. Tests are added for these two operators to see if the return value works as expected. Docs for these two ops are also updated to explicitly mention the return value is a namedtuple. More ops will be added in later PRs.
There is some issue with Windows build of linker unable to resolve `PyStructSequence_UnnamedField`, and some workaround is added to deal with this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15429
Differential Revision: D13709678
Pulled By: ezyang
fbshipit-source-id: 23a511c9436977098afc49374e9a748b6e30bccf
Summary:
1) Reverts https://github.com/pytorch/pytorch/pull/12302 which added support for batched pdist. Except I kept the (non-batched) test improvements that came with that PR, because they are nice to have. Motivation: https://github.com/pytorch/pytorch/issues/15511
2) For the non-batched pdist, improved the existing kernel by forcing fp64 math and properly checking cuda launch errors
3) Added a 'large tensor' test that at least on my machine, fails on the batch pdist implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15901
Reviewed By: ezyang
Differential Revision: D13616730
Pulled By: gchanan
fbshipit-source-id: 620d3f9b9acd492dc131bad9d2ff618d69fc2954
Summary:
Timings are the same as for `std` .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15892
Differential Revision: D13651173
Pulled By: umanwizard
fbshipit-source-id: a26bf1021dd972aa9e3e60fb901cd4983bfa190f
Summary:
Turns out this has basically been implemented already in Resize.h / Resize.cuh.
Also added some testing, basically just to check that empty_strided behaves equivalently to as_strided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15948
Differential Revision: D13631098
Pulled By: gchanan
fbshipit-source-id: eb0e04eead45e4cff393ebde340f9d265779e185
Summary:
This was causing a problem in #15735 but appears to have been fixed.
Adding this test to prevent regressions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15835
Differential Revision: D13600282
Pulled By: zou3519
fbshipit-source-id: d9939e74d372be71c50122a5f6a615fbd7fa4df6
Summary:
soumith zou3519
I was browsing the code, and think `vec256_int.h` might need a minor revision, but not 100% sure.
1. It currently invert the result by `XOR` with 0. Should it `XOR` with 1 instead?
~2. AVX2 logical operations would set all bits in a byte/word/... to `1` if the condition holds. So functions, such as `_mm256_cmpeq_epi64 ` would return `0/-1` instead of `0/1`. Should it be masked with `1` to make sure it returns 0/1?~
~Would I be correct if I assume that the code revised below is not yet activated, but will be after we port legacy code to ATen?~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15659
Differential Revision: D13565929
Pulled By: mrshenli
fbshipit-source-id: 8ae3daf256c3d915dd855a2215c95275e899ea8c
Summary:
Changelog:
- Optimize btriunpack by using `torch.where` instead of indexing, inplace operations instead of out place operations and avoiding costly permutations by computing the final permutation over a list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15286
Differential Revision: D13562038
Pulled By: soumith
fbshipit-source-id: e2c94cfab5322bf1d24bf56d7b056619f553acc6
Summary:
This PR removes the TH/THC binding for gesv.
Changelog:
- Remove TH/THC binding
- Port single matrix case to ATen
- Enable test_gesv for CUDA as well
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15510
Differential Revision: D13559990
Pulled By: soumith
fbshipit-source-id: 9da2825e94d3103627e719709e6b1f8b521a07fb
Summary:
Changes originally in this PR:
1. Move Variable::Impl data members into TensorImpl as `AutogradMeta` struct
2. Change Variable::Impl functions to use data members in `AutogradMeta` struct
3. Add `shallow_copy_and_detach()` function to each subclass of TensorImpl
4. Do shallow copy when the user calls `make_variable(tensor)` / `make_variable_view(tensor)` / `variable.set_data(tensor)` / `variable.detach()`
Changes moved from https://github.com/pytorch/pytorch/pull/13645:
1. Add a flag to Variable to disallow size/stride/storage_ptr changes from in-place operations such as `resize_` / `resize_as_` / `set_` / `transpose_`, and set this flag to true when people call `tensor.data` in Python.
2. Write text in the docs to actively discourage changing the shape or storage of `tensor_detached` and expecting `tensor` to also be updated.
This is the 1st+2nd PR mentioned in https://github.com/pytorch/pytorch/issues/13638.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13827
Differential Revision: D13507173
Pulled By: yf225
fbshipit-source-id: b177b08438d534a8197e34e1ad4a837e2db0ed6a
Summary:
Currently torch.isinf on integral tensor will raise RuntimeError: value cannot be converted to type int16_t without overflow: inf.
This pr will suppress the error and return false(0) for all integral tensors. The behavior will also be consistent with np.isinf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15489
Reviewed By: zou3519
Differential Revision: D13540786
Pulled By: flashhack
fbshipit-source-id: e730dea849da6a59f3752d347bcfbadfd12c6483
Summary:
Followup PR of #14904, and the stretch goal of #12653.
Directly calculate coordinates in the original tensor using column index in the result tensor. Every GPU thread takes care of a column (two numbers) in the output tensor.
The implementation detects and handles precision loss during calculating the square root of a `int64_t` variable, and supports tensors with up to `row * column = 2 ^ 59` numbers.
Algorithm details are describe in [comments of TensorFactories.cu](23ddb6f58a/aten/src/ATen/native/cuda/TensorFactories.cu (L109-L255)).
zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15203
Reviewed By: zou3519
Differential Revision: D13517695
Pulled By: mrshenli
fbshipit-source-id: 86b305d22cac08c8962a3b0cf8e9e620b7ec33ea
Summary:
This updates pdist to work for batched inputs, and updates the
documentation to reflect issues raised.
closes#9406
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12302
Reviewed By: ezyang
Differential Revision: D13528485
Pulled By: erikbrinkman
fbshipit-source-id: 63d93a6e1cc95b483fb58e9ff021758b341cd4de
Summary:
This is the CUDA version of #14535 .
It refactors Reduce.cuh to allow more general classes of reductions to be performed -- we no longer assume that the temporary data returned during reduction is just one scalar, and instead allow an arbitrary accumulate type.
We also allow 64-bit indexing when necessary, since in general we will no longer be able to accumulate directly in the output. (In the cases when we can, we continue to split the tensors until they can be addressed with 32-bits, as before).
As an initial use-case, we implement `std` in multiple dimensions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14990
Differential Revision: D13405097
Pulled By: umanwizard
fbshipit-source-id: a56c24dc2fd5326d417632089bd3f5c4f9f0d2cb
Summary:
Changelog:
- Renames `potrs` to `cholesky_solve` to remain consistent with Tensorflow and Scipy (not really, they call their function chol_solve)
- Default argument for upper in cholesky_solve is False. This will allow a seamless interface between `cholesky` and `cholesky_solve`, since the `upper` argument in both function are the same.
- Rename all tests
- Create a tentative alias for `cholesky_solve` under the name `potrs`, and add deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15334
Differential Revision: D13507724
Pulled By: soumith
fbshipit-source-id: b826996541e49d2e2bcd061b72a38c39450c76d0
Summary:
Certain tensor shapes failed when being resized. This pull request addresses the bug found in #13404.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14874
Differential Revision: D13429788
Pulled By: soumith
fbshipit-source-id: 8aa6451dbadce46d6d1c47a01cb26e6559bcfc8c
Summary:
This is an optimized implementation that does the following:
1. created an empty Tensor of correct size.
2. fill the Tensor with correct values.
The following three designs to fill in the Tensor result in roughly the same performance. Hence, the 2nd option is taken for simpler code, and to return contiguous tensors.
1. Sequential: fill row coordinates first, then columns. This results in two for-loop and more arithmetic operations.
2. Interleaved: fill in index coordinates one by one, which jumps between the two output Tensor rows in every iteration.
3. Transpose: create a n X 2 Tensor, fill the Tensor sequentially, and then transpose it.
<img width="352" alt="screen shot 2018-12-10 at 3 54 39 pm" src="https://user-images.githubusercontent.com/16999635/49769172-07bd3580-fc94-11e8-8164-41839185e9f9.png">
NOTE:
This implementation returns a 2D tensor, instead of a tuple of two tensors. It means that users will not be able to do the following:
```python
x = torch.ones(3, 3)
i = torch.tril_indices(3, 3)
x[i] # need to first convert the 2D tensor into a tuple of two 1D tensors.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14904
Reviewed By: zou3519
Differential Revision: D13433027
Pulled By: mrshenli
fbshipit-source-id: 41c876aafcf584832d7069f7c5929ffb59e0ae6a
Summary:
While moving these scenarios into `_test_dim_ops` I accidentally left an empty loop in the actual tests, causing them to do nothing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15077
Differential Revision: D13428759
Pulled By: umanwizard
fbshipit-source-id: 08f53068981d9192c1408878b168e9053f4dc92e
Summary:
When rewriting `default_collate`, I noticed that `from_numpy` and `as_tensor` and `tensor` all do not work on `np.int8` arrays.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14700
Reviewed By: weiyangfb
Differential Revision: D13305297
Pulled By: soumith
fbshipit-source-id: 2937110f65ed714ee830d50098db292238e9b2a9
Summary:
The other direction of #14700
cc soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14710
Reviewed By: weiyangfb
Differential Revision: D13306052
Pulled By: soumith
fbshipit-source-id: 202d038f139cf05e01069ff8d05268c66354c983
Summary:
Tested on a tensor with 1 billion elements and 3 dimensions on a powerful, highly
multi-core Linux machine.
parallelized: All operations (e.g., `t.std(1)`) that could be done in the old code are now several times faster. All
new operations (e.g., `t.std((0,2))` are significantly faster than the NumPy equivalents.
`t.std((0, 1, 2))`, a new operation, is logically equivalent to the
old `t.std()`, but faster.
serial: The above comment about old operationos now being faster still
holds, but `t.std((t1, ..., tn))` is now a few
times slower than `t.std()`. If this turns out to be important, we can
special-case that to use the old algorithm.
The approach is to create a new method, `TensorIterator::foreach_reduced_elt`,
valid for `TensorIterator`s that represent a dimension reduction. This
method calls a supplied function for each element in the output,
supplying it with the input elements that correspond to that output.
Given that primitive, we can implement reductions like the following pseudocode:
If there is more than one output element:
```
PARALLEL FOR EACH element IN output:
accumulator = identity
SERIAL FOR EACH data_point IN element.corresponding_input:
accumulator.update(data_point)
element = accumulator.to_output()
```
If there is only one output element, we still want to parallelize, so we
do so along the *input* instead:
```
accumulators[n_threads]
PARALLEL FOR EACH input_chunk IN input.chunks():
accumulators[thread_num()] = identity
SERIAL FOR EACH data_point IN input_chunk:
accumulators[thread_num()].update_with_data(data_point)
accumulator = identity
SERIAL FOR EACH acc in accumulators:
accumulator.update_with_other_accumulator(acc)
output_element = accumulator.to_output()
```
Note that accumulators and data points do not have to be the same type
in general, since it might be necessary to track arbitrary amounts of
data at intermediate stages.
For example, for `std`, we use a parallel version of Welford's
algorithm, which requies us to track the mean, second moment, and number
of elements, so the accumulator type for `std` contains three pieces of
data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14535
Differential Revision: D13283887
Pulled By: umanwizard
fbshipit-source-id: 8586b7bf00bf9f663c55d6f8323301e257f5ec3f
Summary:
* Enable unit tests known to work on ROCm.
* Disable a few that are known to be flaky for the time being.
* Use std::abs for Half
* No more special casing for ROCm in TensorMathReduce
* Document an important detail for a hardcoded block size w.r.t. ROCm in TensorMathReduce
ezyang bddppq for awareness
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14011
Differential Revision: D13387679
Pulled By: bddppq
fbshipit-source-id: 4177f2a57b09d866ccbb82a24318f273e3292f71
Summary:
`torch.linspace(0, 1, 1)` fails with `RuntimeError: invalid argument 3: invalid number of points at ../aten/src/TH/generic/THTensorMoreMath.cpp:2119`, while `np.linspace(0, 1, 1)` works fine.
Looking at the code, there is even a comment by gchanan asking: "NumPy allows you to pass different points even if n <= 1 -- should we?"
I would say "yes". Currently, I would need to handle the case of `steps == 1` or `steps == 0` separately, making sure to change the `end` when calling `torch.linspace`. This is impractical. If we support `start != end`, there are two possibilities for the result: Either we ensure the first value in the resulting sequence always equals `start`, or we ensure the last value in the resulting sequence always equals `end`. Numpy chose the former, which also allows it to support a boolean `endpoint` flag. I'd say we should follow numpy.
This PR adapts `linspace` and `logspace` to mimic the behavior of numpy, adapts the tests accordingly, and extends the docstrings to make clear what happens when passing `steps=1`.
If you decide against this PR, the error message should become explicit about what I did wrong, and the documentation should be extended to mention this restriction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14748
Differential Revision: D13356136
Pulled By: ezyang
fbshipit-source-id: db85b8f0a98a5e24b3acd766132ab71c91794a82
Summary:
Before this PR, tensor.clamp() would return an empty tensor if min and
max were not specified. This is a regression from 0.4.1, which would
throw an error. This PR restores that error message.
Fixes#14470
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14716
Differential Revision: D13311031
Pulled By: zou3519
fbshipit-source-id: 87894db582d5749eaccfc22ba06aac4e10983880
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13603
P
Moved vectorized CPU copy to aten. Notable changes mainly in _copy_same_type_.
Reviewed By: ezyang
Differential Revision: D12936031
fbshipit-source-id: 00d28813e3160595e73d104f76685e13154971c1
Summary:
Multi-dimensional `sum` is already implemented, and it's trivial to implement `mean` in terms of `sum`, so just do it.
Bonus: Fix incomplete language in the `torch.sum` documentation which doesn't take into account multiple dimensions when describing `unsqueeze` (at the same time as introducing similar language in `torch.mean`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14252
Differential Revision: D13161157
Pulled By: umanwizard
fbshipit-source-id: c45da692ba83c0ec80815200c5543302128da75c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/14344 and https://github.com/pytorch/pytorch/issues/6863
The slowdown was due to the fact that we were only summarizing the tensor (for computing the number of digits to print) if its first dimension was larger than the threshold. It now goes over all the dimensions.
Some quick runtime analysis:
Before this PR:
```python
In [1]: import torch; a = torch.rand(1, 1700, 34, 50)
In [2]: %timeit str(a)
13.6 s ± 84.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
After this PR
```python
In [1]: import torch; a = torch.rand(1, 1700, 34, 50)
In [2]: %timeit str(a)
2.08 ms ± 395 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [3]: b = a.cuda()
In [4]: %timeit str(b)
8.39 ms ± 45.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14418
Reviewed By: weiyangfb
Differential Revision: D13226950
Pulled By: soumith
fbshipit-source-id: 19eb4b855db4c8f891d0925a9c56ae8a2824bb23
Summary:
They didn't turn up in my tests because I use pytest which doesn't
print debug statements if the tests pass
Differential Revision: D13115227
Pulled By: soumith
fbshipit-source-id: 46a7d47da7412d6b071158a23ab21e7fb0c6e11b
Summary:
Implements batching for the Cholesky decomposition.
Performance could be improved with a dedicated batched `tril` and `triu` op, which is also impeding autograd operations.
Changes made:
- batching code
- tests in `test_torch.py`, `test_cuda.py` and `test_autograd.py`.
- doc string modification
- autograd modification
- removal of `_batch_potrf` in `MultivariateNormal`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14017
Differential Revision: D13087945
Pulled By: ezyang
fbshipit-source-id: 2386db887140295475ffc247742d5e9562a42f6e
Summary:
This enables the distributions and utils test sets for ROCm.
Individual tests are enabled that now pass due to fixes in HIP/HCC/libraries versions in white rabbit.
For attention: bddppq ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13166
Differential Revision: D12814759
Pulled By: bddppq
fbshipit-source-id: ea70e775c707d7a8d2776fede6154a755adef43e
Summary:
- This is a straightforward PR, building up on the batch inverse PR, except for one change:
- The GENERATE_LINALG_HELPER_n_ARGS macro has been removed, since it is not very general and the resulting code is actually not very copy-pasty.
Billing of changes:
- Add batching for `potrs`
- Add relevant tests
- Modify doc string
Minor changes:
- Remove `_gesv_single`, `_getri_single` from `aten_interned_strings.h`.
- Add test for CUDA `potrs` (2D Tensor op)
- Move the batched shape checking to `LinearAlgebraUtils.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13453
Reviewed By: soumith
Differential Revision: D12942039
Pulled By: zou3519
fbshipit-source-id: 1b8007f00218e61593fc415865b51c1dac0b6a35
Summary:
update roll to behave as in numpy.roll when dimension to roll not specified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13588
Differential Revision: D12964295
Pulled By: nairbv
fbshipit-source-id: de9cdea1a937773033f081f8c1505a40e4e08bc1
Summary:
- a walk around for #13292, a complete fix requires investigation on the root cause when using advanced indexing
- this PR brings in `filp()` CUDA implementation for CPU kernel
- with this change:
```
>>> t = torch.randn(1, 3, 4, 5)
>> t.flip(1, 3).shape
torch.Size([1, 3, 4, 5])
```
- performance:
```
====== with this PR ======
>>> a = torch.randn(1000, 1000)
>>> %timeit -r 100 a.flip(0, 1)
1.98 ms ± 579 µs per loop (mean ± std. dev. of 100 runs, 1000 loops each)
====== Perf at previous PR #7873 ======
100 loops, best of 3: 11 ms per loop
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13344
Differential Revision: D12968003
Pulled By: weiyangfb
fbshipit-source-id: 66f434049d143a0575a35b5c983b3e0577a1a28d
Summary:
- fixes weights-contiguous requirement for THCUNN Convolutions
- Add tests that conv backward pass works for non-contiguous weights
- fix RNN tests / error messages to be consistent and pass
- relax weight grad precision for fp16 for a particular test
- fix regression of CMAKE_PREFIX_PATH not passing through
- add missing skipIfNoLapack annotations where needed
Differential Revision: D12918456
Pulled By: soumith
fbshipit-source-id: 8642d36bffcc6f2957800d6afa1e10bef2a91d05
Summary:
Fixes#13326
Also now you can use `run_test.py` with `pytest`. E.g.,
```
python run_test.py -vci distributed -pt
```
Yes it works with `distributed` and `cpp_extension`.
cc zou3519 vishwakftw
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13416
Differential Revision: D12895622
Pulled By: SsnL
fbshipit-source-id: 2d18106f3a118d642a666bfb1318f41c859c3df7
Summary:
This PR performs a renaming of the function `potrf` responsible for the Cholesky
decomposition on positive definite matrices to `cholesky` as NumPy and TF do.
Billing of changes
- make potrf cname for cholesky in Declarations.cwrap
- modify the function names in ATen/core
- modify the function names in Python frontend
- issue warnings when potrf is called to notify users of the change
Reviewed By: soumith
Differential Revision: D10528361
Pulled By: zou3519
fbshipit-source-id: 19d9bcf8ffb38def698ae5acf30743884dda0d88
Summary:
Currently, `a = 1 - torch.tensor([1]).to('cuda:1')` puts `a` in `cuda:1` but reports `a.device` as `cuda:0` which is incorrect, and it causes illegal memory access error when trying to access `a`'s memory (e.g. when printing). This PR fixes the error.
Fixes https://github.com/pytorch/pytorch/issues/10850.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12956
Differential Revision: D12835992
Pulled By: yf225
fbshipit-source-id: 5737703d2012b14fd00a71dafeedebd8230a0b04
Summary:
ezyang on the template hack
smessmer on SFINAE of the `TensorOptions(Device)`
goldsborough on the C++ API test changes
zdevito on the `jit` codegen changes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13146
Reviewed By: ezyang
Differential Revision: D12823809
Pulled By: SsnL
fbshipit-source-id: 98d65c401c98fda1c6fa358e4538f86c6495abdc
Summary:
1. Refactors `TestTorch` into `TestTorchMixin` (subclass of `object`) and `TestTorch` (subclass of `TestCase`, MRO `(TestCase, TestTorchMixin)`, only defined if `__name__ == '__main__'`). So other scripts won't accidentally run it.
2. Adds an assertion in `load_tests` that each script only runs cases defined in itself.
cc yf225 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13250
Differential Revision: D12823734
Pulled By: SsnL
fbshipit-source-id: 7a169f35fe0794ce76e310d8a137d9a3265c012b
Summary:
Fixes#12578#9395.
* Fix and simplify print logic
* Follow numpy print rule eb2bd11870/numpy/core/arrayprint.py (L859)
> scientific notation is used when absolute value of the smallest number is < 1e-4 or maximum > 1e8 or the ratio of the maximum absolute value to the minimum is > 1e3
I hope I didn't break anything since there seems to be a lot of edge cases here... Here are some easy sanity checks.
```
In [5]: torch.tensor(1)
Out[5]: tensor(1)
Out[2]: array(1) # numpy
In [6]: torch.tensor(10)
Out[6]: tensor(10)
Out[3]: array(10) # numpy
In [8]: torch.tensor(99000000)
Out[8]: tensor(99000000)
Out[5]: array(99000000) # numpy
In [9]: torch.tensor(100000000)
Out[9]: tensor(100000000)
Out[6]: array(100000000) # numpy
In [10]: torch.tensor(100000001)
Out[10]: tensor(100000001)
Out[7]: array(100000001) # numpy
In [11]: torch.tensor(1000000000)
Out[11]: tensor(1000000000)
Out[8]: array(1000000000) # numpy
In [12]: torch.tensor([1, 1000])
Out[12]: tensor([ 1, 1000])
Out[9]: array([ 1, 1000]) # numpy
In [13]: torch.tensor([1, 1010])
Out[13]: tensor([ 1, 1010])
Out[10]: array([ 1, 1010]) # numpy
```
For floating points, we use scientific when `max/min > 1000 || max > 1e8 || min < 1e-4`
Lines with "old" are old behaviors that either has precision issue, or not aligned with numpy
```
In [14]: torch.tensor(0.01)
Out[14]: tensor(0.0100)
Out[11]: array(0.01) # numpy
In [15]: torch.tensor(0.1)
Out[15]: tensor(0.1000)
Out[12]: array(0.1) # numpy
In [16]: torch.tensor(0.0001)
Out[16]: tensor(0.0001)
Out[14]: array(0.0001) # numpy
In [17]: torch.tensor(0.00002)
Out[17]: tensor(2.0000e-05)
Out[15]: array(2e-05) # numpy
Out[5]: tensor(0.0000) # old
In [18]: torch.tensor(1e8)
Out[18]: tensor(100000000.)
Out[16]: array(100000000.0) # numpy
In [19]: torch.tensor(1.1e8)
Out[19]: tensor(1.1000e+08)
Out[17]: array(1.1e8) # numpy 1.14.5, In <= 1.13 this was not using scientific print
Out[10]: tensor(110000000.) # old
In [20]: torch.tensor([0.01, 10.])
Out[20]: tensor([ 0.0100, 10.0000])
Out[18]: array([ 0.01, 10. ]) # numpy
In [21]: torch.tensor([0.01, 11.])
Out[21]: tensor([1.0000e-02, 1.1000e+01])
Out[19]: array([ 1.00000000e-02, 1.10000000e+01]) # numpy
Out[7]: tensor([ 0.0100, 11.0000]) # old
```
When print floating number in int mode, we still need to respect rules to use scientific mode first
```
In [22]: torch.tensor([1., 1000.])
Out[22]: tensor([ 1., 1000.])
Out[20]: array([ 1., 1000.]) # numpy
In [23]: torch.tensor([1., 1010.])
Out[23]: tensor([1.0000e+00, 1.0100e+03])
Out[21]: array([ 1.00000000e+00, 1.01000000e+03]) # numpy
Out[9]: tensor([ 1., 1010.]) # old
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12746
Differential Revision: D10443800
Pulled By: ailzhang
fbshipit-source-id: f5e4e3fe9bf0b44af2c64c93a9ed42b73fa613f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12794
common.py is used in base_module for almost all tests in test/. The
name of this file is so common that can easily conflict with other dependencies
if they happen to have another common.py in the base module. Rename the file to
avoid conflict.
Reviewed By: orionr
Differential Revision: D10438204
fbshipit-source-id: 6a996c14980722330be0a9fd3a54c20af4b3d380
Summary:
I found a bug in norm() and fixed it (and added tests to make sure it's fixed)
here is how to reproduce it:
```python
import torch
x = torch.FloatTensor([[10, 12, 13], [4, 0, 12]])
print(torch.norm(x, -40, dim=0, keepdim=True)) #output is tensor([[ 4.0000, 0.0000, 11.9853]])
print(torch.norm(x, float('-inf'), dim=0, keepdim=True)) #output is tensor([[1., 1., 1.]]) which is wrong!
from numpy.linalg import norm as np_norm
x = x.numpy()
print(np_norm(x, ord=-40, axis=0)) #output is array([[4., 0., 11.985261]])
print(np_norm(x, ord=float('-inf'), axis=0)) #output is array([[4., 0., 12.0]])
```
it's related to [#6817](https://github.com/pytorch/pytorch/issues/6817) and [#6969](https://github.com/pytorch/pytorch/pull/6969)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12722
Differential Revision: D10427687
Pulled By: soumith
fbshipit-source-id: 936a7491d1e2625410513ee9c39f8c910e8e6803
Summary:
`torch.isfinite()` used to crash on int inputs.
```
>>> import torch
>>> a = torch.tensor([1, 2])
>>> torch.isfinite(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/scratch/pytorch/torch/functional.py", line 262, in isfinite
return (tensor == tensor) & (tensor.abs() != inf)
RuntimeError: value cannot be converted to type int64_t without overflow: inf
```
But this is a easy special case and numpy also supports it.
```
>>> import numpy as np
>>> a = np.array([1, 2])
>>> a.dtype
dtype('int64')
>>> np.isfinite(a)
array([ True, True], dtype=bool)
```
So added a hacky line to handle non-floating-point input. Since pytorch raises exception when overflow, we can safely assume all valid int tensors are infinite numbers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12750
Differential Revision: D10428204
Pulled By: ailzhang
fbshipit-source-id: f39b2d0975762c91cdea23c766ff1e21d85d57a5
Summary:
The mapping protocol stipulates that when `__delitem__` is called, this is passed to `__setitem__` [(well, the same function in the C extension interface)](https://docs.python.org/3/c-api/typeobj.html#c.PyMappingMethods.mp_ass_subscript) with NULL data.
PyTorch master crashes in this situation, with this patch, it does not anymore.
Test code (careful, sefaults your interpreter):
```python
import torch
a = torch.randn(5)
del a[2]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12726
Differential Revision: D10414244
Pulled By: colesbury
fbshipit-source-id: c49716e1a0a3d9a117ce88fc394858f1df36ed79
Summary:
- This was one of the few functions left out from the list of functions in
NumPy's `linalg` module
- `multi_mm` is particularly useful for DL research, for quick analysis of
deep linear networks
- Added tests and doc string
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12380
Differential Revision: D10357136
Pulled By: SsnL
fbshipit-source-id: 52b44fa18d6409bdeb76cbbb164fe4e88224458e
Summary:
* switches docker files over to white rabbit release - removed custom package installs
* skips five tests that regressed in that release
* fixes some case-sensitivity issues in ROCm supplied cmake files by sed'ing them in the docker
* includes first changes to the infrastructure to support upcoming hip-clang compiler
* prints ROCm library versions as part of the build (as discussed w/ ezyang )
* explicitly searches for miopengemm
* installs the new hip-thrust package to be able to remove the explicit Thrust checkout in a future revision
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12577
Differential Revision: D10350165
Pulled By: bddppq
fbshipit-source-id: 60f9c9caf04a48cfa90f4c37e242d944a175ab31
Summary:
Fixes#12260#2896
```
torch.multinomial(torch.FloatTensor([0, 1, 0, 0]), 3, replacement=False)
```
The old behavior is that we return `0` after we run out of postive categories. Now we raise an error based on discussion in the issue thread.
- Add testcase for cpu & cuda case, in cuda case `n_samples=1` is a simple special case, so we test against `n_sample=2` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12490
Differential Revision: D10278794
Pulled By: ailzhang
fbshipit-source-id: d04de7a60f60d0c0d648b975db3f3961fcf42db1
Summary:
* Topk part 1: fix intrinsincs for 64 wave front (#224)
64 in a wave front - intrinsics change.
* Disable in-place sorting on ROCm. (#237)
It is known to hang - use the Thrust fallback
Skip one test - fails with the fallback.
* Topk fixes (#239)
* Spec (https://docs.nvidia.com/cuda/pdf/ptx_isa_6.3.pdf) Sec 9.7.1.19 (bfe) and 9.7.1.20 (bfi) requires pos and len to be limited to 0...255
* Spec (https://docs.nvidia.com/cuda/pdf/ptx_isa_6.3.pdf) Sec 9.7.1.19 requires extracted bits to be in LSBs
* Correct logic for getLaneMaskLe. Previous logic would return 0x0 instead of 0xffffffffffffffff for lane 63
* Round up blockDim.x to prevent negative index for smem
bddppq ezyang
Note the one additional skipped test resulting from using the thrust sort fallback for all sizes. We are working on getting bitonic to work properly (and always). Until then, this needs to be skipped on ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12337
Differential Revision: D10259481
Pulled By: ezyang
fbshipit-source-id: 5c8dc6596d7a3103ba7b4b550cba895f38c8148e
Summary:
- fixes https://github.com/pytorch/pytorch/issues/10723
- migrate PReLU to ATen and deprecate legacy PReLU
- performance:
CPU with weight.numel() = 1
```
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
100 loops, best of 100: 9.43 ms per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
10 loops, best of 100: 24.4 ms per loop
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 695 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.47 ms per loop
```
CPU with weight.numel() = channels
```
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 603 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 13.3 ms per loop
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 655 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.45 ms per loop
```
CUDA with weight.numel() = 1
```
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 187 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.01 ms per loop
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 195 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.28 ms per loop
```
CUDA with weight.numel() = channel
```
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 174 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.27 ms per loop
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 181 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.26 ms per loop
```
The huge performance regression in CPU when weight.numel() = 1 is addressed by replacing at::CPU_tensor_apply* with parallelized kernels.
ezyang SsnL zou3519 soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11758
Differential Revision: D9995799
Pulled By: weiyangfb
fbshipit-source-id: d289937c78075f46a54dafbde92fab0cc4b5b86e
Summary:
- fix PR https://github.com/pytorch/pytorch/pull/11061 by moving `detach_()` and `set_requires_grad()` to `torch.tensor_ctor()` and `tensor.new_tensor`, and also removed warnings and `args_requires_grad` from `internal_new_from_data `
- with this patch, the returned tensor from `tensor_ctor()` and `new_tensor` will be detached from source tensor, and set requires_grad based on the input args
- `torch.as_tensor` retains its behavior as documented
gchanan apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11815
Differential Revision: D9932713
Pulled By: weiyangfb
fbshipit-source-id: 4290cbc57bd449954faadc597c24169a7b2d8259
Summary:
+ https://github.com/pytorch/pytorch/issues/10236 : torch.bernoulli's out kwarg is broken
fixed in moving `bernoulli_out` to ATen
+ https://github.com/pytorch/pytorch/issues/9917 : BUG torch.bernoulli(p.expand(shape)) is broken
fixed in moving all `bernoulli` ops in ATen to use the modern apply utils methods
+ https://github.com/pytorch/pytorch/issues/10357 : torch.bernoulli inconsistent gpu/cpu results
fixed by adding CUDA asserts
In order to use `curand_uniform4`, I made some changes to `CUDAApplyUtils.cuh`. Specifically, I introduced an optional template parameter `int step` to the `CUDA_tensor_applyN` methods, representing that we want to process `step` values at each time for each of the `N` tensors.
The calling convention for `step = 1` (default) isn't changed. But if `step > 1`, the given lambda `op` must take in `int n` as its first argument, representing the number of valid values, because there may not be full `step` values at the boundary. E.g., here is what the `bernoulli(self, p_tensor)` call look like:
```cpp
// The template argument `4` below indicates that we want to operate on four
// element at each time. See NOTE [ CUDA_tensor_applyN helpers ] for details.
at::cuda::CUDA_tensor_apply2<scalar_t, prob_t, 4>(
ret, p,
[seeds] __device__(
int n, scalar_t& v1, scalar_t& v2, scalar_t& v3, scalar_t& v4,
const prob_t& p1, const prob_t& p2, const prob_t& p3, const prob_t& p4) {
curandStatePhilox4_32_10_t state;
curand_init(
seeds.first,
blockIdx.x * blockDim.x + threadIdx.x,
seeds.second,
&state);
float4 rand = curand_uniform4(&state);
switch (n) {
case 4: {
assert(0 <= p4 && p4 <= 1);
v4 = static_cast<scalar_t>(rand.w <= p4);
}
case 3: {
assert(0 <= p3 && p3 <= 1);
v3 = static_cast<scalar_t>(rand.z <= p3);
}
case 2: {
assert(0 <= p2 && p2 <= 1);
v2 = static_cast<scalar_t>(rand.y <= p2);
}
case 1: {
assert(0 <= p1 && p1 <= 1);
v1 = static_cast<scalar_t>(rand.x <= p1);
}
}
}
);
```
Benchmarking on `torch.rand(200, 300, 400)` 20 times, each time with 20 loops:
post patch
```
➜ ~ numactl --cpunodebind 1 --membind 1 -- taskset -c 12,13,14,15,16,17,18,19,20,21,22,23 env CUDA_LAUNCH_BLOCKING=1 python bern.py
torch.bernoulli(x)
6.841588497161865 +- 0.05413117632269859
torch.bernoulli(xc)
0.05963418632745743 +- 0.0008014909108169377
x.bernoulli_()
0.4024486541748047 +- 0.0021550932433456182
xc.bernoulli_()
0.02167394384741783 +- 2.3818030967959203e-05
```
pre-patch
```
➜ ~ numactl --cpunodebind 1 --membind 1 -- taskset -c 12,13,14,15,16,17,18,19,20,21,22,23 env CUDA_LAUNCH_BLOCKING=1 python bern.py
torch.bernoulli(x)
12.394511222839355 +- 0.0966421514749527
torch.bernoulli(xc)
0.08970972150564194 +- 0.0038722590543329716
x.bernoulli_()
1.654480218887329 +- 0.02364428900182247
xc.bernoulli_()
0.058352887630462646 +- 0.003094920190051198
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10273
Differential Revision: D9831294
Pulled By: SsnL
fbshipit-source-id: 65e0655a36b90d5278b675d35cb5327751604088
Summary:
Adds vararg support for meshgrid and adds checks for all the tensor arguments to have the same dtype and device.
Fixes: [#10823](https://github.com/pytorch/pytorch/issues/10823), #11446
The earlier pull request closed without any changes because I had some rebasing issues, so I made another pull request to close out #10823. Sorry for the inconvenience.
Differential Revision: D9892876
Pulled By: ezyang
fbshipit-source-id: 93d96cafc876102ccbad3ca2cc3d81cb4c9bf556
Summary:
tset_potri -> test_potri, even though it has been like this for a long time
More a curiosity than grave functionality...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11770
Reviewed By: ezyang
Differential Revision: D9884767
Pulled By: soumith
fbshipit-source-id: 9bedde2e94ade281ab1ecc2293ca3cb1a0107387
Summary:
Fixes#11663
`TensorIterator` was replacing the op tensors with type casted tensors
which ended up producing side effects in binary ops like `a.float() * b`
where `a` and `b` are `LongTensor`s.
colesbury ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11708
Differential Revision: D9834016
Pulled By: driazati
fbshipit-source-id: 4082eb9710b31dfc741161a0fbdb9a8eba8fe39d
Summary:
…cuda())
While I was at it, I audited all other ways I know how we might get a CUDA
type from PyTorch and fixed more constructors which don't work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11533
Differential Revision: D9775786
Pulled By: ezyang
fbshipit-source-id: cd07cdd375fdf74945539ec475a48bf08cbc0c17
Summary:
Arg parser allowed additional positional args to be parsed into keyword-only params.
Fixes a couple cases:
- The positional argument happens to be of the right type, and it just works silently. Now, we fail as expected.
- The positional argument fails later down the line. Now, we fail at the appropriate time and get a better error message.
Pre-fix:
```
>>> torch.cuda.LongTensor((6, 0), 1, 1, 0)
tensor([6, 0], device='cuda:1')
```
Post-fix:
```
>>> torch.cuda.LongTensor((6, 0), 1, 1, 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new() received an invalid combination of arguments - got (tuple, int, int, int), but expected one of:
* (torch.device device)
* (torch.Storage storage)
* (Tensor other)
* (tuple of ints size, torch.device device)
* (object data, torch.device device)
```
Pre-fix:
```
>>> a = torch.tensor(5)
>>> a.new_zeros((5,5), 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new_zeros(): argument 'dtype' (position 2) must be torch.dtype, not int
```
Post-fix:
```
>>> a = torch.tensor(5)
>>> a.new_zeros((5,5), 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new_zeros() takes 1 positional argument but 2 were given
```
fixes#8351
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10499
Differential Revision: D9811093
Pulled By: li-roy
fbshipit-source-id: ce946270fd11b264ff1b09765db3300879491f76
Summary:
After discussions in #11584 , new PR for just the test skip and hgemm integration.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11593
Differential Revision: D9798527
Pulled By: ezyang
fbshipit-source-id: e2ef5609676571caef2f8e6844909fe3a11d8b3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11420
Surprisingly tricky! Here are the major pieces:
- We grow a even yet more ludicrous macro
AT_FORALL_SCALAR_TYPES_WITH_COMPLEX_EXCEPT_COMPLEX_HALF
which does what it says on the tin. This is because I was
too lazy to figure out how to define the necessary conversions
in and out of ComplexHalf without triggering ambiguity problems.
It doesn't seem to be as simple as just Half. Leave it for
when someone actually wants this.
- Scalar now can hold std::complex<double>. Internally, it is
stored as double[2] because nvcc chokes on a non-POD type
inside a union.
- overflow() checking is generalized to work with complex.
When converting *to* std::complex<T>, all we need to do is check
for overflow against T. When converting *from* complex, we
must check (1) if To is not complex, that imag() == 0
and (2) for overflow componentwise.
- convert() is generalized to work with complex<->real conversions.
Complex to real drops the imaginary component; we rely on
overflow checking to tell if this actually loses fidelity. To get
the specializations and overloads to work out, we introduce
a new Converter class that actually is specializable.
- Complex scalars convert into Python complex numbers
- This probably fixes complex tensor printing, but there is no way
to test this right now.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Reviewed By: cpuhrsch
Differential Revision: D9697878
Pulled By: ezyang
fbshipit-source-id: 181519e56bbab67ed1e5b49c691b873e124d7946
Summary:
vishwakftw Your patch needed some updates because the default native function dispatches changed from `[function, method]` to `[function]`. The CI was run before that change happened so it still shows green, but the internal test caught it.
I did some changes when rebasing and updating so I didn't just force push to your branch. Let's see if this passes CI and internal test. If it does, let me know if you want me to force push to your branch or use this PR instead.
Note to reviewers: patch was already approved at #10068 .
cc yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11421
Differential Revision: D9733407
Pulled By: SsnL
fbshipit-source-id: cf2ed293bb9942dcc5158934ff4def2f63252599
Summary:
This PR cleans up the `at::Tensor` class by removing all methods that start with an underscore in favor of functions in the `at::` namespace. This greatly cleans up the `Tensor` class and makes it clearer what is the public and non-public API.
For this I changed `native_functions.yaml` and `Declarations.cwrap` to make all underscore methods `variant: function` (or add such a statement to begin with), and then fixed all code locations using the underscore methods.
ezyang colesbury gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11152
Differential Revision: D9683607
Pulled By: goldsborough
fbshipit-source-id: 97f869f788fa56639c05a439e2a33be49f10f543
Summary:
Add the gpu kernel version.
The parallelism I went with performs poorly when there are a large number of vectors, but they're all short, as I don't allocate the thread pool to wrap in that case.
Test Plan
---------
```
python -m unittest test_torch.TestTorch.test_pdist_{empty,scipy} test_nn.TestNN.test_pdist{,_zeros,_empty_row,_empty_col,_cpu_gradgrad_unimplemented,_cuda_gradgrad_unimplemented} test_jit.TestJitGenerated.test_nn_pdist
```
Current performance specs are a little underwhelming, I'm in the process of debugging.
size | torch | torch cuda | scipy
-----|-------|------------|------
16 x 16 | 9.13 µs ± 3.55 µs | 9.86 µs ± 81.5 ns | 15.8 µs ± 1.2 µs
16 x 1024 | 15 µs ± 224 ns | 9.48 µs ± 88.7 ns | 88.7 µs ± 8.83 µs
1024 x 16 | 852 µs ± 6.03 µs | 7.84 ms ± 6.22 µs | 4.7 ms ± 166 µs
1024 x 1024 | 34.1 ms ± 803 µs | 11.5 ms ± 6.24 µs | 273 ms ± 6.7 ms
2048 x 2048 | 261 ms ± 3.5 ms | 77.5 ms ± 41.5 µs | 2.5 s ± 97.6 ms
4096 x 4096 | 2.37 s ± 154 ms | 636 ms ± 2.97 µs | 25.9 s ± 394 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11102
Differential Revision: D9697305
Pulled By: erikbrinkman
fbshipit-source-id: 2b4f4b816c02b3715a85d8db3f4e77479d19bb99
Summary:
In #9466 I got rid of storage views and eliminated all places where
they were used... OR SO I THOUGHT. In actuality, under certain
conditions (specifically, if you trained a CUDA multiprocessing model
shared over CUDA IPC and then serialized your parameters), you could
also serialize storage slices to the saved model format. In #9466,
I "fixed" the case when you loaded the legacy model format (really,
just unshared the storages--not strictly kosher but if you aren't
updating the parameters, shouldn't matter), but NOT the modern model format, so
such models would fail.
So, I could have applied the legacy model format fix too, but
hyperfraise remarked that he had applied a fix that was effectively
the same as unsharing the storages, but it had caused his model to
behave differently. So I looked into it again, and realized that
using a custom deleter, I could simulate the same behavior as old
storage slices. So back they come.
In principle, I could also reimplement storage views entirely using
our allocators, but I'm not going to do that unless someone really
really wants it.
Fixes#10120.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11314
Reviewed By: ailzhang
Differential Revision: D9671966
Pulled By: ezyang
fbshipit-source-id: fd863783d03b6a6421d6b9ae21ce2f0e44a0dcce
Summary:
Allows mulitplication of e.g. numpy.float32 with tensors.
This came up with #9468
If you want this and after the other patch is done, I'll add tests (but that would be conflicting, so I prefer to wait).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9659
Differential Revision: D8948078
Pulled By: weiyangfb
fbshipit-source-id: c7dcc57b63e2f100df837f70e1299395692f1a1b
Summary:
* improve docker packages (install OpenBLAS to have at-compile-time LAPACK functionality w/ optimizations for both Intel and AMD CPUs)
* integrate rocFFT (i.e., enable Fourier functionality)
* fix bugs in ROCm caused by wrong warp size
* enable more test sets, skip the tests that don't work on ROCm yet
* don't disable asserts any longer in hipification
* small improvements
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10893
Differential Revision: D9615053
Pulled By: ezyang
fbshipit-source-id: 864b4d27bf089421f7dfd8065e5017f9ea2f7b3b
Summary:
Also add single grad whitelist to the jit test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10782
Reviewed By: ezyang
Differential Revision: D9583378
Pulled By: erikbrinkman
fbshipit-source-id: 069e5ae68ea7f3524dec39cf1d5fe9cd53941944
Summary:
Initial version of `unique` supporting a `dim` argument.
As discussed in [this issue](https://github.com/pytorch/pytorch/issues/9997) I added the `dim` argument to `torch.unique` with the same behavior like [numpy](https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.unique.html).
Since the implementation is based on `std/thrust::unique`, the `tensor` always needs to be sorted. The `sorted` argument in `torch.unique` does not have any function, as in the CUDA version of the plain `torch.unique`.
To check the performance and equal behavior between `torch.unique` and `np.unique`, I've used [this gist](https://gist.github.com/ptrblck/ac0dc862f4e1766f0e1036c252cdb105).
Currently we achieve the following timings for an input of `x = torch.randint(2, (1000, 1000))`:
(The values are calculated by taking the average of the times for both dimension)
| Device | PyTorch (return_inverse=False) | Numpy (return_inverse=False) | PyTorch (return_inverse=True) | Numpy (return_inverse=True) |
| --- | --- | --- | --- | --- |
| CPU | ~0.007331s | ~0.022452s | ~0.011139s | ~0.044800s |
| GPU | ~0.006154s | - | ~0.105373s | - |
Many thanks to colesbury for the awesome mentoring and the valuable advices on the general implementation and performance issues!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10423
Differential Revision: D9517289
Pulled By: soumith
fbshipit-source-id: a4754f805223589c2847c98b8e4e39d8c3ddb7b5
Summary:
Fix#10345, which only happens in CUDA case.
* Instead of returning some random buffer, we fill it with zeros.
* update torch.symeig doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10645
Reviewed By: soumith
Differential Revision: D9395762
Pulled By: ailzhang
fbshipit-source-id: 0f3ed9bb6a919a9c1a4b8eb45188f65a68bfa9ba
Summary:
When 0-sized dimension support is added, we expect an empty sparse tensor to be a 1-dimensional tensor of size `[0]`, with `sparseDims == 1` and `denseDims == 0`. Also, we expect the following invariants to be preserved at all times:
```
_sparseDims + _denseDims = len(shape)
_indices.shape: dimensionality: 2, shape: (_sparseDims, nnz)
_values.shape: dimensionality: 1 + _denseDims. shape: (nnz, shape[_sparseDims:])
```
This PR fixes various places where the invariants are not strictly enforced when 0-sized dimension support is enabled.
Tested and `test_sparse.py` passes locally on both CPU and CUDA with the `USE_TH_SIZE_ZERO_DIM` flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9279
Differential Revision: D8936683
Pulled By: yf225
fbshipit-source-id: 12f5cd7f52233d3b26af6edc20b4cdee045bcb5e
Summary:
Implemented via a wrapper, thank you Richard for the suggestion!
Fixes: #9929
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10067
Differential Revision: D9083388
Pulled By: soumith
fbshipit-source-id: 9ab21cd35278b01962e11d3e70781829bf4a36da
Summary:
Test only for existence for now. I had to skip a lot of them so there a FIXME in the test.
Also I'm not testing torch.* because of namespace issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10311
Differential Revision: D9196341
Pulled By: SsnL
fbshipit-source-id: 9c2ca1ffe660bc1cc664474993f8a21198525ccc
Summary:
* some small leftovers from the last PR review
* enable more unit test sets for CI
* replace use of hcRNG w/ rocRAND (docker image was already updated w/ newer rocRAND)
* use rocBLAS instead of hipBLAS to allow convergence w/ Caffe2
* use strided_batched gemm interface also from the batched internal interface
* re-enable Dropout.cu as we now have philox w/ rocRAND
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10406
Reviewed By: Jorghi12
Differential Revision: D9277093
Pulled By: ezyang
fbshipit-source-id: 7ef2f6fe4ead77e501ed7aea5c3743afe2466ca2
Summary:
This PR for the ROCm target does the following:
* enable some unit tests on ROCm
* fix a missing static_cast that breaks BatchNorm call on ROCm
* fix BatchNorm to work on ROCm w/ ROCm warp sizes etc
* improve the pyhipify script by introducing kernel scope to some transpilations and other improvements
* fix a linking issue on ROCm
* for more unit test sets: mark currently broken tests broken (to be fixed)
* enable THINLTO (phase one) to parallelize linking
* address the first failing of the elementwise kernel by removing non-working ROCm specialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10266
Differential Revision: D9184178
Pulled By: ezyang
fbshipit-source-id: 03bcd1fe4ca4dd3241f09634dbd42b6a4c350297
Summary:
This exposes expand_outplace to python. Fixes#8076. Fixes#10041.
I didn't name it torch.broadcast because numpy.broadcast does something
slightly different (it returns an object with the correct shape
information).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10075
Differential Revision: D9125816
Pulled By: zou3519
fbshipit-source-id: ebe17c8bb54a73ec84b8f76ce14aff3e9c56f4d1
Summary:
This causes numpy to yield to the torch functions,
e.g. instead of numpy array/scalar __mul__ converting the tensor to
an array, it will now arrange for the Tensor __rmul__ to be called.
Fixes case 2 of #9468
I also makes case 3 and 4 equivalent but does not fix them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9651
Differential Revision: D8948079
Pulled By: ezyang
fbshipit-source-id: bd42c04e96783da0bd340f37f4ac3559e9bbf8db
Summary:
These could use some autograd tests, which are coming in a later PR, but using them in autograd is probably pretty rare.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9947
Reviewed By: ezyang
Differential Revision: D9032778
Pulled By: gchanan
fbshipit-source-id: fa5a6509d3bac31ea4fae25143e82de62daabfbd
Summary:
```
This adds TensorIterator, a helper class for computing element-wise
operations that's intended to replace the CPU and CUDA apply utils
functions.
CPU kernels are implemented as functions that operate on strided 1-d
tensors compared to CPUApplyUtils which operated individual elements. This
allows the kernels to handle vectorization, while TensorIterator handles
parallelization and non-coalesced dimensions.
GPU kernels continue to operate on elements, but the number of
specializations is reduced. The contiguous case remains the same. The
non-contiguous case uses a single (reduced) shape for all operands and
the fast integer division from THCIntegerDivider. To avoid extra
specializations for indexing with 64-bits, large operations are split
into smaller operations that can be indexed with 32-bits.
Major semantic changes:
- No more s_add, s_mul, s_div, or s_sub. Broadcasting is handled by
TensorIterator. The autograd engine performs the reduction assuming
standard broadcasting if the gradient shape does not match the
expected shape. Functions that do not use standard broadcasting rules
should either continue to trace the expand calls or handle the
reduction in their derivative formula.
- Use ONNX v7, which supports broadcasting ops.
Performance impact:
- Small increased fixed overhead (~0.5 us)
- Larger overhead for wrapped numbers (~2.5 us)
- No significant change for ops on contiguous tensors
- Much faster worst-case performance for non-contiguous GPU tensors
- Faster CPU bias addition (~2x)
- Faster GPU bias addition (~30% faster)
Future work:
- Decrease overhead, especially for wrapping numbers in Tensors
- Handle general inter-type operations
- Extend to unary ops and reductions
- Use buffering for compute-bound operations on non-contiguous tensors
(pull in from CPUApplyUtils)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8919
Differential Revision: D8677600
Pulled By: colesbury
fbshipit-source-id: 61bc9cc2a36931dfd00eb7153501003fe0584afd
Summary:
The primary use-site of typeString was checked_cast_tensor.
I did a little more than I needed in this patch, to set
the stage for actually deleting the tensor type.
Specifically, I modified checked_cast_tensor to explicitly
take Backend and ScalarType, the idea being that once we
remove the tensor subclasses, we will delete the T template
parameter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9764
Differential Revision: D8969196
Pulled By: ezyang
fbshipit-source-id: 9de92b974b2c28f12ddad13429917515810f24c6
Summary:
Fixes: #9754
Maybe this could also make its way into 0.4.1, it is a severe debugging headache if you hit this...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9755
Reviewed By: ezyang
Differential Revision: D8967178
Pulled By: zou3519
fbshipit-source-id: 151ed24e3a15a0c67014e411ac808fb893929a42
Summary:
…unctions.
This also unifies the error checkign between scatter/scatterAdd on CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9658
Differential Revision: D8941527
Pulled By: gchanan
fbshipit-source-id: 750bbac568f607985088211887c4167b67be11ea
Summary:
This is mainly straightforward, with two exceptions:
1) cublasSgemv, cublasDgemv appear to have a bug where (x,0).mv(0) does not handle beta, whereas cublasSgemm, cublasDgemm do for case where (x,0).mm(0,y). This is handled by manually calling zero / mul.
2) I fixed a bug in btrifact that was broken even when dealing with non-empty tensors. Basically, if out.stride(0) was 1, because the underlying BLAS call expects column-major matrices, to get a column-major tensor, out.transpose_(0, 1) would be called. But this is just wrong, as if the batch dimension (0) doesn't match the size of the columns (1), you don't even have a tensor of the correct shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9573
Reviewed By: ezyang
Differential Revision: D8906144
Pulled By: gchanan
fbshipit-source-id: de44d239a58afdd74d874db02f2022850dea9a56
Summary:
…CPU LAPACK routines.
Note that the LAPACK functions in general require a different approach, because direct calls with size zero dims do not work.
Here I just selected a reasonable subset of LAPACK routines to support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9522
Reviewed By: ezyang
Differential Revision: D8888180
Pulled By: gchanan
fbshipit-source-id: 16b9013937806d375d83d1c406815765fda00602
Summary:
If this is good, I could write some tests to ensure collision doesn't occur within a given range.
Closes#7228
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9246
Differential Revision: D8872608
Pulled By: ezyang
fbshipit-source-id: 0ed29a73188f4167b42756f59a5c9a3d5cb37326
Summary:
…ors (CPU).
This includes (mainly) CPU fixes; CUDA fixes are a little more involved because you can't use an empty grid.
This also includes a fix for index_copy, which checked that self.size(dim) == src.size(0), which isn't correct (the same dimension should be compared).
Finally, also includes a fix for CUDA flip (although it's not tested yet), to get the stride using multiplication rather than division to avoid divide-by-0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9482
Reviewed By: ezyang
Differential Revision: D8873047
Pulled By: gchanan
fbshipit-source-id: 86523afd3d50277834f654cd559dfbc7875cdffe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9497Fixes#7883 by using `rfft`.
It's worth noting that this is BC breaking. And it's impossible to detect the change because the two signatures before and after this change supports a common subset of calling patterns, e.g., `stft(Tensor, int, int)`. (some other calling patterns will raise error).
soumith and I plan to change the current `stft` interface because it is a bit messy and non-standard. rafaelvalle suggested us that `librosa` is a good reference API to align with. After discussing with soumith and ezyang , and given that `stft` is only out for 1 release, I decide to go with directly changing the signature. Also, my understanding is that most researchers in this field will welcome this change as `librosa` seems to be the golden-standard here. (it doesn't yet support all `pad_mode` but those will become available if added to `F.pad`.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9308
Reviewed By: ezyang
Differential Revision: D8806148
Pulled By: SsnL
fbshipit-source-id: f6e8777d0c34d4a4d7024e638dc9c63242e8bb58
Summary:
Storage views were previously used to implement CUDA IPC sharing,
but they weren't necessary. The new strategy is described in
Note [CUDA IPC and the caching allocator].
This also fixes an unrelated bug, where we weren't actually using
the Tensor forking pickler, because we didn't register a pickler
for torch.Tensor.
Fixes#9447. Fixes#46.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
CC apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9466
Reviewed By: apaszke
Differential Revision: D8859698
Pulled By: ezyang
fbshipit-source-id: 3362cb92f6ae4aa37084c57d79b31004bd0b4a97
Summary:
`test_neg` sometimes fails internally because `random_()` can generate an out-of-range value for CharTensor. This PR fixes it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9431
Reviewed By: SsnL
Differential Revision: D8843284
Pulled By: yf225
fbshipit-source-id: bf516cceb8f780e133fa54f7364c77821eb7c013
Summary:
Fixes: #9421
I don't think it is easy to deal with non-contiguous array in cuda topk, so I'm adding a check.
The argument number is a bit confusing when it shows in PyTorch but it is consistent with the other checks. (Not sure whether it would make sense to eliminate argument numbers from the error TH/THC error messages given that they're probably off more than once...)
Do we need a test that it indeed refuses non-contiguous?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9441
Reviewed By: soumith
Differential Revision: D8850719
Pulled By: ezyang
fbshipit-source-id: d50561bb37ed50ab97aeaf54d8e3fc6c765bdc7c
Summary:
This includes either bug fixes or NumPy semantics changes for the following methods:
chunk, diagonal, unfold, repeat, flatten, reshape, split, unsqueeze.
The n-dimensional empty tensor feature is still hidden behind a feature flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9362
Reviewed By: ezyang
Differential Revision: D8817002
Pulled By: gchanan
fbshipit-source-id: 6ff704ec96375f00b4dd39ebcd976efac0607fb4
Summary:
This PR implements and tests N-dimensional empty tensors for indexing, factories, and reductions if compiled with -DUSE_TH_SIZE_ZERO_DIM.
Still remaining to add:
1) TensorShape functions
2) Simple linear algebra functions (matrix multiply variants)
3) Other functions that operate over a dimension (but don't reduce).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9209
Reviewed By: ezyang
Differential Revision: D8751257
Pulled By: gchanan
fbshipit-source-id: 2113374dc7af6caf31a99bf67b3893f130a29e23
Summary:
cc vishwakftw
Also added a check if none of the input tensors in `gradcheck` have `requires_grad=True`.
Closes https://github.com/pytorch/pytorch/pull/9192
Differential Revision: D8739401
Pulled By: SsnL
fbshipit-source-id: 81bb3aa0b5c04eb209b137a4bd978e040e76cbcd
Summary:
Closes#9147
Added a test to prevent regression in test_torch
Added entries in docs
cc ezyang weiyangfb
Closes https://github.com/pytorch/pytorch/pull/9156
Differential Revision: D8732095
Pulled By: soumith
fbshipit-source-id: 7a6892853cfc0ccb0142b4fd25015818849adf61
Summary:
This will resolve some of the timeout issues in CPU and GPU tests internally.
Closes https://github.com/pytorch/pytorch/pull/9061
Reviewed By: ezyang
Differential Revision: D8707471
Pulled By: yf225
fbshipit-source-id: 9dc82a2c9da0c540ae015442f74b9b2b1a67a246
Summary:
Currently the `test_RNG_after_pickle` in the PR would fail because pickling a tensor changes the RNG state. This PR aims to fix it.
Closes https://github.com/pytorch/pytorch/pull/8971
Reviewed By: ezyang
Differential Revision: D8677474
Pulled By: yf225
fbshipit-source-id: 1713d9611699ad288b66d92dbb29ce9feb34b8cf
* add opencl + fpga context
adds an opencl context inside caffe2/fb which can be used for fpga access
* [Caffe2] Force tensor inference checks to be triggered during testing
We've started to rely on TensorInference functions more for different analysis. This diff ensures that the TensorInference function's result matches what is expected from the definition of the operator.
* Enable building //caffe2:torch with @mode/opt
In @mode/opt, python runs out of a PAR, which breaks a lot of
assumptions in the code about where templates/ folders live relative
to __file__. Rather than introduce hacks with parutil, I simply turn
template_path into a parameter for all the relevant functions and
thread it through from the top level.
* [Caffe2] Fix cost models for DotProduct and Div. Update Tensor Inference for dot product
As title. DotProduct states that output is a 1-D tensor (https://caffe2.ai/docs/operators-catalogue.html#dotproduct) though code suggests it is either 0- or 1-D depending on inputs. TensorInference defined to support implementation.
* [SG-MoE] Add an option to make the experts NOT as components
* [nomnigraph] Rename and fixup convertToNeuralNetOperator API
This will make things a bit cleaner
* no longer symlink THNN.h and THCUNN.h
* forced decoder network (onnx export)
Closes https://github.com/pytorch/translate/pull/95
Add networks in ensemble_export.py to create a forced decoding network from PyTorch NMT checkpoints. This network takes an arbitrary numberized (source, target) pair and returns the model score for the translation, including penalties.
Vocabulary reduction networks are also supported, but note that target indices which are not in the possible_translation_tokens generated for the source input will be trea
* Revert schema change to fix production models
Revert schema change to fix production models
* MockLogDeviceReader - rebase on FIX
# Goal
1), Build a make_mock_log_device_reader using make_mock_reader
2), Replace the real log_device_reader here: https://fburl.com/raihwf1p
# Log by D8151734
Real log_device_reader:
```
I0529 20:29:05.373108 954994 tensor.h:839] Tensor print_net/log of type std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >. Dims: (): read_net/ParseOpenTrainingRow:0
I0529 20:29:05.373244 954994 tensor.h:839] Tensor read_net/ParseOpenTrainin
* [C2/D2][1/n]: Nonnegative-Constrained Optimization -- log barrier
implement log barrier as a regularization method
* Add teacher weight screening.
Add teacher weight sceening according to teacher labels. If teacher label is zero, we do not use the distill loss in the objective function.
* Add NormalizerContext
See task for more detail. This implementation is a copy of what exists for RegularizerContext except for how the parameters are defined in the model_definition thrift file.
I'll try an alternative implementation which overrides the default arguments of functions instead like for argscopes in tensorflow.
https://github.com/pytorch/pytorch/compare/master...MaximeBoucher:update-from-facebook-0939578c068c?expand=1
* Adding cosine similarity option in dot processor
Add pairwise cosine similarity option in dot product.
Add an option to concate dot product and cosine similarity.
Add test cases.
* [nomnigraph][redo] Concat elim for sparseNN
Same as D7962948, which was reverted because Operator Schema was not
defined
* [pytorch] Revert pytorch/pytorch#7918 'Release GIL when copying to shared memory', breaks ASAN
Revert this pytorch diff that breaks ASAN when running Filament in dev mode; in opt mode it gives "bad file descriptor" errors. Looks like a race when copying tensors to shared memory in multiple mp.Queue's (which spawn separate threads).
https://github.com/pytorch/pytorch/pull/7918/files
* [nomnigraph][mobile] Enable nomnigraph by default, use -Oz on nomnigraph related code to reduce code size
enables nomnigraph and reduces codesize
* [Warmup] Allow both offline incremental training and online training
Change plan name on saving side and reading side to support both training type
This diff depends on D8128530 and D8168651.
* Revert D7802642: [Warmup] Allow both offline incremental training and online training
This reverts commit afc213cf9b36cecf75333a788391c4d09f4afccc
@bypass-lint
An infra SEV is better than not reverting this diff.
If you copy this password, see you in SEV Review!
@cause_a_sev_many_files
* Add legacy grad logic to fix div op on old graphs.
Add legacy grad logic to fix div op on old graphs.
* Correctly propagate operator failures
Propagate errors from operators that throw exceptions and return false
* Revert D8374829: [caffe2][nomnigraph][redo] Concat elim for sparseNN
This reverts commit 6dda028c463e54bb5c32188bbbe9202107e188a5
@bypass-lint
An infra SEV is better than not reverting this diff.
If you copy this password, see you in SEV Review!
@cause_a_sev_many_files
* [Caffe2] Added extra_info to core.DeviceOption(), enforced extra_info to be inherited in scope.DeviceScope
extra_info is a newly defined field in DeviceOption proto. This diff added extra_info to the core.DeviceOption(). And, In scope.DeviceScope(), this diff enforce the new scope to inherit the extra_info from old scope.
* [opt] hgdirsync wasn't enabled, merge diverged code
Here's the damage, P59732616 basically xplat was left behind but had
the change from assert to CAFFE_ENFORCE
* OMP parallelism over RoIs for RoIAlign op
Simpler to parallelize over RoIs. Shouldn't affect other uses as it relies on
the number of OMP threads set during startup.
PR: https://github.com/pytorch/pytorch/pull/8562
* Use int64_t for shape in FillOps
to avoid overflow of int32
* Implement Rotated RoIAlign op
Based on Rotated RPNs as explained in https://arxiv.org/abs/1703.01086.
The idea is simple - orientation/angle is added as an RPN
anchor parameter and then the angle is further regressed similar to bbox
coords. There are some additional changes related to NMS and IoU, but besides
that it's a direct extension to Faster-RCNN. Further details in https://fb.quip.com/sZHlA1iMfWPZ.
RoIs are represented in [center_x, center_y, width, height, angle] format.
`angle` repre
* Rotated RoIAlign op CUDA forward implementation
CUDA forward impl for D8415490
* RoIAlignRotated op CUDA backward pass implementation
TSIA
* All remaining fixes to eliminate process_github.sh
Most of this diff has already been reviewed separately, except for the parts relating to _thnn/utils.py and _utils._internal.py
remove skipIf(True, 'Fbcode') line from process_github.sh
replace sed of cpp file with #ifdef to control cudnnDestroy use
undo sync-time deletion of .gitattributes, remove process_github.sh
switch to using _utils._internal rather than try-import-except
This diff also fixes the open-source bug where rebuilds have
* Back out "Revert D7802642: [Warmup] Allow both offline incremental training and online training"
Original commit changeset: 7707d2efe60e The original diff is backout becuase the online trainer package is backed out. This code would only work with new online trainer package
* [easy] improve error log in adagrad op
as title
* re-allow use of thnn_h_path
This fixes cffi usage in OSS
* [4/4] [tum] paralyzing layerNorm for GPU full sync
as title
* add compile=False to pytorch tests, remove hack with pyc
* Add shape and type inference for RowWiseArgMax operator
See title
* Revert D8515341: Back out "Revert D7802642: [Warmup] Allow both offline incremental training and online training"
This reverts commit 78167eeef0af16b60f72c82f9dcdda9b41b4dcbd
@bypass-lint
An infra SEV is better than not reverting this diff.
If you copy this password, see you in SEV Review!
@cause_a_sev_many_files
* [fix-flaky-test] mock_hive_reader_test flaky, because GlobalCounter collects local counts intervally
# Problem
`MockHiveReader` uses `GlobalCounter` to limit `max_examples`.
GlobalCounter on server node collect local counts from worker nodes every 1 sec.
This 1 sec delay makes it impossible to limit exactly to the `max_examples`, it will definitely exceed `max_examples`.
# Plan
Given,
```
Expected num_examples = max_examples + num_examples/sec (Read Speed) x 1 sec (GlobalCounter Sync Int
* [Caffe2] Fix FCGradient cost inference. Prevent overflow in cost inference
FCGradient missed a factor 2 in the `num_outputs == 3` case. Overflow was occurring with flop calculation for FC. Changed types to `uint64_t` to prevent future problems.
* Fix binary ops with empty inputs
Fix binary ops with empty inputs
* Support the filling of input blob with provided data
as title for Biz Integrity case
* Back out "Revert D8515341: Back out "Revert D7802642: [Warmup] Allow both offline incremental training and online training""
Original commit changeset: 30c55dd38816 Original diff is reverted due to introducing bad integration test. Fixed the integration test.
* [c2][easy] improve pack ops error loggings
as desc.
* Add ShapeTypeInference for LpNorm operator
As desc
* Shard test_nn to reduce runtime for each test target
Closes https://github.com/pytorch/pytorch/pull/8793
The current test_nn would time out and be disabled in GreenWarden, and we need to have an option to split it up in order to pass the stress test. Right now GreenWarden roughly allows running 100 test cases in test_nn before timing out, and here we have an option to divide test_nn into 30 shards (with ~40 tests in each shard) to allow for some test suite growth in the future.
* Change default caffe2_streams_per_gpu to 1
* Remove IN_SANDCASTLE from common.py and test_nn.py
We prefer to disable the failing tests through Sandcastle UI instead.
* Add a new class for an updated prof_dag.proto
This diff contains:
- An updated prof_dag.proto that contains blob profiles.
- A class to deserialize this information (serialization is in a follow up diff)
- Update to separate profiling information from NeuralNet (and use it as part of the class above).
- Unit tests
* Lambdarank for SparseNN
This diff adds a lambda_rank_layer for SparseNN.
changes include
1) Adds support for multi sessions in c2 op
2) Adds support for two different loss functions in c2 op
3) Unit tests for op
* Revert D8586950: Back out "Revert D8515341: Back out "Revert D7802642: [Warmup] Allow both offline incremental training and online training""
This reverts commit 012220ed63eccc35659a57b31d16a3625da6317b
@bypass-lint
An infra SEV is better than not reverting this diff.
If you copy this password, see you in SEV Review!
@cause_a_sev_many_files
* [easy] A few fixups to multithread predictor benchmark
(1) support perf on T6 server
(2) remove dead code
* fix a bug about the map size
as title
* Fix reduce sum on in-place case.
Fix reduce sum on in-place case.
* [Warmup] Reland reverted diff Allow both offline incremental training and online training
Closes https://github.com/pytorch/pytorch/pull/8827
fix net transform integration test. Allow offline and online trainer to coexist D7802642.
* Add StoreHandlerNotAvailableException
Add an exception for a store that is not available or has been
deleted.
* Use exception handling for fault tolerance, missing KV store
Remove status blobs to communication ops so that exceptions propagate on
failure.
* [C2/D2][2/n]: Nonnegative-Constrained Optimization -- bounded grad proj
for simple bounded constrained optimization, incl non-negative box constraints.
* [GanH]: Adaptive Weighting with More Estimations
With implemented postivity optimization, we now learn adaptive weights with different
parameterizations.
This improves parameter estimation and training stability.
* Revert some changes for landing
* Remove AutoNoGIL in StorageSharing
* Temporarily disable net_tests
* Revert "[Caffe2] Force tensor inference checks to be triggered during testing"
This reverts commit 67ef05c22b2f71b4a489695384932f968384a2a4.
* Revert "Fix reduce sum on in-place case."
This reverts commit 6cb8a8e1b3db7b6d20941b0053e3f3836068eb64.
* Revert "Revert "Fix reduce sum on in-place case.""
This reverts commit 130a257c0893dc09f4bd6e6a45d112261807fd2c.
* Better forward methods in C++ API
capitalize error message in test_torch.test_flatten
Support for operator()
* Add operator() to Functional
* Get rid of SigmoidLinear
* Add BoundFunction to FunctionalImpl
* Remove macro from conv because it makes errors more nasty
* Some 0-sized dimension support, port catArray away from resizeLegacy.
The goal of this PR is to port catArray away from resizeLegacy (so we can delete the legacy resize calls), but since catArray has some weird behavior because
we don't have arbitrary 0-sized dimension support, I made some effort to fix these both in one pass.
The major changes here are:
1) catArray uses the new resize API, no longer the old resizeLegacy API.
2) As 1) is the last usage of resizeLegacy, it is deleted.
3) If compiled with USE_TH_SIZE_ZERO_DIM, catArray will work and properly check shapes for n-dimensional empty tensors.
4) However, we retain the old behavior of "ignoring" size [0] tensors in catArray. We previously allowed this because we didn't have n-dimensional empty tensors.
5) To get the above to work, we also add support for n-dimensional empty tensors for narrow and slice (ifdef USE_TH_SIZE_ZERO_DIM).
6) We change the stride formula for empty tensors to match NumPy; basically, we never multiply by 0 as the size, always at least 1, so the
strides are monotonically increasing in the empty tensor case.
7) We print the size of empty tensors if size != [0]; this matches NumPy behavior (even in cases where the size could be inferred from the brackets.
8) For test purposes, we add torch._C._use_zero_size_dim() to add tests for the above.
* Fix flake8.
* Address review comments.
* Created TensorOptions
Storing the type in TensorOptions to solve the Variable problem
Created convenience creation functions for TensorOptions and added tests
Converted zeros to TensorOptions
Converted rand to TensorOptions
Fix codegen for TensorOptions and multiple arguments
Put TensorOptions convenience functions into torch namespace too
All factory functions except *_like support TensorOptions
Integrated with recent JIT changes
Support *_like functions
Fix in place modification
Some cleanups and fixes
Support sparse_coo_tensor
Fix bug in Type.cpp
Fix .empty calls in C++ API
Fix bug in Type.cpp
Trying to fix device placement
Make AutoGPU CPU compatible
Remove some auto_gpu.h uses
Fixing some headers
Fix some remaining CUDA/AutoGPU issues
Fix some AutoGPU uses
Fixes to dispatch_tensor_conversion
Reset version of new variables to zero
Implemented parsing device strings
Random fixes to tests
Self review cleanups
flake8
Undo changes to variable.{h,cpp} because they fail on gcc7.2
Add [cuda] tag to tensor_options_cuda.cpp
Move AutoGPU::set_index_from into .cpp file because Windows is stupid and sucks
Fix linker error in AutoGPU.cpp
Fix bad merge conflict in native_functions.yaml
Fixed caffe2/contrib/aten
Fix new window functions added to TensorFactories.cpp
* Removed torch::TensorOptions
Added code to generate wrapper functions for factory methods
Add implicit constructor from Backend to TensorOptions
Remove Var() from C++ API and use torch:: functions
Use torch:: functions more subtly in C++ API
Make AutoGPU::set_device more exception safe
Check status directly in DynamicCUDAHooksInterface
Rename AutoGPU to DeviceGuard
Removed set_requires_grad from python_variables.h and warn appropriately in Variable::set_requires_grad
remove python_default_init: self.type()
Add back original factory functions, but with deprecation warnings
Disable DeviceGuard for a couple functions in ATen
Remove print statement
Fix DeviceGuard construction from undefined tensor
Fixing CUDA device compiler issues
Moved as many methods as possible into header files
Dont generate python functions for deprecated factories
Remove merge conflict artefact
Fix tensor_options_cuda.cpp
Fix set_requires_grad not being checked
Fix tensor_new.h
TEMPORARILY put some methods in .cpp files to see if it solves issues on windows and mac
Fix bug in DeviceGuard.h
Missing includes
TEMPORARILY moving a few more methods into .cpp to see if it fixes windows
Fixing linker errors
* Fix up SummaryOps to use new factories
Undo device agnostic behavior of DeviceGuard
Use -1 instead of optional for default device index
Also move DeviceGuard methods into header
Fixes around device index after optional -> int32_t switch
Fix use of DeviceGuard in new_with_tensor_copy
Fix tensor_options.cpp
* Fix Type::copy(
* Remove test_non_float_params from ONNX tests
* Set requires_grad=False in ONNX tests that use ints
* Put layout/dtype/device on Tensor
* Post merge fixes
* Change behavior of DeviceGuard to match AutoGPU
* Fix C++ API integration tests
* Fix flip functions
* Spelling fix in MultivariateNormal docstring (#7915)
* [c10d] MPI Process Group Implementation (#7783)
This provides a bare-minimum MPI Process Group implementation, the commit is on top of @pietern's Gloo Process Group PR.
* [c10d] MPI Process Group Implementation
ref: https://github.com/pytorch/pytorch/issues/7434
* Better exception, atexit func, and addressed comments
* Clang formatting changes
* Static initialization and addressed comments
* Added constness back
* Test will now launch mpi processes if found
* CMakeList Changed
* Fix Windows doc for import error (#7704)
* Fix Windows doc for import error
* Fix doc again
* Fix wrong format
* Moved condition for dilated grouped convolutions to CUDNN convolution implementation (#7465)
* Updates to caffe2 operator documentation (#7917)
* Significant updates to the operator docs in prep for merge
* [auto] Update onnx to 307995b - Update from upstream (onnx/onnx#1038)
307995b143
* Test if ASAN is actually working as part of ASAN tests. (#6050)
* Test if ASAN is actually working as part of ASAN tests.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Drop explicit use of libstdc++, we should not care.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Build with DEBUG=1
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Increase main thread stack size when using ASAN.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Split up detail.h (#7836)
* Fix THCUNN SpatialDepthwiseConvolution assuming contiguity (#7952)
* Fix fbcode compatibility (#7939)
* add test for correctness of transpose fusion (#7950)
* [JIT][script] Fix emitted gather and slice for dynamic indices (#7861)
* [JIT][script] Fix emitted gather for dynamic indices
* Also fix slice
* Address comments
* cache and use BLAS_SET_BY_USER so that it doesn't set itself to TRUE when run second time (#7942)
* Add unsafe flag to skip checking in prepare (#7832)
* Add unsafe flag to skip checking in prepare
* pop
* Rename cuda::type to cuda::into_type and provide cuda::from_type. (#7937)
These are used to convert Half -> half and half -> Half respectively.
from_type will be used for runtime type checking in THC.
* Try to fix TORCH_CUDA_ARCH_LIST for PyTorch again (#7936)
* try again
* use DEFINED
* use a loop
* Minor fixes
* remove sort requirement from pad-sequence (#7928)
* pad-sequence no longer requires sorting entries
pad-sequence can get the max_len from the list of sequences. entries only need to be sorted if output will be used for pack_padded_sequence, which can throw the error itself.
* remove sort requirement from pad-sequence
Picks up from #5974.
Removes the requirement that input sequences to pad_sequence have to be
sorted. Addressed the comments in the PR:
- Updated docstring for pad_sequence
- Remove sort requirement in pad_sequence test
- Test unsorted and sorted sequences in pad_sequence test
* Fix checkBackend error message (#7926)
* Fix checkBackend error message
Fixes#7849
* Switch order of printing args
* Split CI tests in half and run them in parallel (#7867)
* Split and run tests in parallel
* Refactor tests
* Handling of scalars in torch.Size (#5676)
* Handling of scalars in torch.Size
torch.Size() constructor uses python_arg_parser
IntList in python_arg_parser can take iter/range
Have IntList take python iterables and ranges.
Address comments: don't use python_arg_parser and instead call __index__ in THPSize_pynew
Address comments
Address comments
* Rebased
* Address nit
* [JIT] Fission and fusion passes for addmm (#7938)
* Addmm decomposition pass
* Addmm peephole pass
* Fix handling of output shape in fusion pass
* Add DCE to the peephole passes
* add comments
* maybe bugfix?
* Fix GPU tests
* fix py2/3 test issue
* Set smaller grain size for some cases (#7941)
* Fix returning scalar input in Python autograd function (#7934)
* fix _wrap_outputs not working with scalar inputs
* add a test
* Prevent git autocrlf for bash scripts (#7949)
* Delete unused file (#7919)
* Fix typo in autodiff formula for addmm (#7932)
* 1) use meshgrid for flip() CPU implementation, only need one copy of input tensor; 2) changed kernel of CUDA implementation, no need materialized indices tensor; 3) reusing error checking code
* [caffe2] YellowFin parameter update GPU code fix. (#6993)
* [Caffe2] Keep name of caffe2_pybind11_state and caffe2_pybind11_state_gpu in debug build (#7155)
* Allowing MatMul to create a gradient even with 3 inputs. useful if you are differentiating a graph twice (#6536)
* added const for local variables
* Fix the cpp libtorch CUDA build (#7975)
* Use mingfeima's mkldnn (#7977)
* Fix the import part of the windows doc (#7979)
* Change perf test folder after git checkout (#7980)
* Move the broadcast check in MKL Add/Sum to runtime (#7978)
* Use Glog's implementation of STL logging when possible. (#7206)
Inject custom workaround into namespace std so that it can be found by ADL.
* [Hotfix] Bring back warnings and -Werror to ATen (#7866)
* Bring back warnings and -Werror to ATen
* Unbreak...
* Fix tbb errors
* Enable ONNX backend Mean tests (#7985)
* Add third wayt to determine IS_CONDA (#7971)
* Fix EmbeddingBag max_norm option (#7959)
* fix EmbeddingBag max_norm option
* flake8
* add warning to the embedding bag arg change
* Raise error when torch.load a storage on a non-existing device (#7921)
* Raise error when torch.load a storage on a non-existing device
Before, doing torch.load(...) on a CUDA tensor on a CPU-only machine
would raise an unreadable error:
```
~/pytorch/pytorch/torch/cuda/__init__.py in __enter__(self)
223 if self.idx is -1:
224 return
--> 225 self.prev_idx = torch._C._cuda_getDevice()
226 if self.prev_idx != self.idx:
227 torch._C._cuda_setDevice(self.idx)
AttributeError: module 'torch._C' has no attribute '_cuda_getDevice'
```
This PR makes it so that torch.load raises a hard error if one tries to
load a storage onto a non-existing device and suggests the user to use
torch.load's map_location feature.
* Address comments
* missing dep
* Make THStorage / THCStorage have void* data ptr. (#7964)
* Make THStorage / THCStorage have void* data ptr.
This is the initial step in unifying the ATen and TH tensor representations, next is to only generate a single THStorage / THCStorage type.
The major changes here are:
1) data has been renamed to data_ptr and made void* in THStorage/THCStorage.
2) THStorage / THCStorage stores a at::ScalarType representing its data type (This will be useful when we generate a single THStorage/THCStorage).
3) APIs for Accessing the data as a real*:
a) storage->data<real>() -- this does runtime-type checking (checks that the at::ScalarType is correct).
b) storage->unsafeData<real>() -- as above, but no runtime-type checking (used in inner loops / fast code paths).
c) THStorage_(data)(storage) -- this already existed, just calls storage->data<real>().
* Add include.
* Attempt to fix clang build issues.
* Clarify comment and remove extra character.
* Rename unsafeData -> unsafe_data.
* Remove unnecessary 'to' function to get compile time rather than link time errors.
* Import/export observer symbols for DLL, which fixes the linking error in Visual Studio. (#6834)
* Import/export observer symbols for DLL, which fixes the linking error in Visual Studio.
* Add support of all default cmake build types for release to cuda.
* Remove python bindings for `torch.slice` (#7924)
* skip python bindings for slice
* remove tests
* convert slice test to indexing
* Build ONNX for PyTorch version of libcaffe2 (#7967)
* support loading gzip (#6490)
* support loading gzip
* address comments
* address comments
* fix lint
* fix test for python2
* Add memory leak check in CUDA tests (#7270)
* Add memory leak check in CUDA tests
* Tracking multi-GPU too
* fix run_test.py not running __name__ == '__main__' content; add test for make_cuda_memory_checked_test
* add a comment
* skip if cuda
* 1. Change the wrapper to a method in common.py:TestCase
2. Refactor common constants/method that initialize CUDA context into common_cuda.py
3. Update some test files to use TEST_CUDA and TEST_MULTIGPU
* Fix MaxUnpool3d forward memory leak
* Fix MultiLabelMarginCriterion forward memory leak
* Fix MultiMarginLoss backward memory leak
* default doCUDAMemoryCheck to False
* make the wrapper skip-able
* use TEST_MULTIGPU
* add align_corners=True/False tests for Upsample; fix TEST_CUDNN
* finalize interface
* VolumetricMaxUnpooling_updateOutput
* fix test_nccl
* rename THC caching allocator methods to be clearer
* make the wrapped function a method
* address comments; revert changes to aten/src/THC/THCCachingAllocator.cpp
* fix renamed var
* Revert "Set smaller grain size for some cases" (#7988)
* Entry for c10d in CODEOWNERS (#8001)
* Fix a couple of typos (#7998)
* Fix typo
* Fix typo
* Fix typo
* Fix typo
* Add on-stack observer cache for Observable (#7931)
observers_list_ stores all the observers for an observable. The list is allocated on heap, which
can cause LLC miss. Add an on-stack observer cache for fast access. In production, we have seen 20%
speed up for start and stop observer calls.
* Reduce grain size for Unary operations (#8003)
* [auto] Update onnx to 8ec0e5f - Add index check for Transpose's type inference function (onnx/onnx#1053)
8ec0e5fe9b
* Make AT_FORALL_SCALAR_TYPES usable outside of at::namespace. (#7935)
* Make AT_FORALL_SCALAR_TYPES usable outside of at::namespace.
This requires renaming the _cast functions which used the unqualified names.
* Separate onnx mapping of scalar type from cast name.
* Fix flake8.
* Properly cast onnx.
* Remove WITH_ROCM cmake flag/variable (use USE_ROCM solely) (#8013)
* Mention the pytorch-ci-hud on the README. (#8004)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Re-enable build env check (#7969)
* Re-enable build env check
* Fix linux test error
* Try to fix macOS test error
* Update nn.rst (#8029)
* Example for Transformed Distribution (#8011)
* [auto] Update onnx to 33e9cd4 - Remove the usage of default value to fix invalid proto3 files. (onnx/onnx#1052)
33e9cd4182
* [auto] Update onnx to 1504a33 - Convert schema assert for duplicate type names to exception (onnx/onnx#1057)
1504a33abb
* Support CUDA tensors in ProcessGroupGloo (#7694)
This adds an unconditional dependency on CUDA, which is not desirable
for the long term. Ideally we have split like ATen where we have
different artifacts for different backends so you can decide at runtime
what to use.
* [auto] Update onnx to 3fb9656 - Fix for fbcode CI (onnx/onnx#1062)
3fb965666e
* propagate nan in some activations (#8033)
* propagate nan in some activations
* fix py2 not having math.nan
* flake8
* Fix profiler crash when no events register (#8034)
* Fix profiler crash when no events register
When trying to profile, attempting to print the event table throws a vague error because the event list is empty:
....
max_name_length = max(len(evt.key) for evt in events)
ValueError: max() arg is an empty sequence
This change fixes the error by returning an empty string.
* Update profiler.py
* Allow CI testing with different AVX configs (#8020)
* Allow CI testing with different AVX configs
* Unset ATEN_DISABLE_AVX and ATEN_DISABLE_AVX2 in default config
* Support for generating ATen during the fbcode build, rather than committing the generated files (#8002)
Paint the internal bikeshed a slightly different color to appease Buck tooling.
* Factor python dependency out of interpreter (#7970)
* Factor python dependency out of interpreter
* Remove NO_PYTHON for the autograd engine
If there is no python bindings, then a default Engine is constructed
the first time it is requested.
If the python libraries are loaded, then they override the default
accessor and the default engine becomes a python Engine.
Note: it is possible for two engines to be generated if a non-python
one gets created before the python bindings are loaded. This case
is rare, and just results in additional threads being spawned.
* Fixing AlexNet test which is skipped in CI
* [auto] Update onnx to 760c928 - add missing hasNInputShapes check for bidirectionalBroadcastShapeInference (onnx/onnx#1060)
760c9283d0
* Support modules that output scalar in Gather (and data parallel) (#7973)
* Support modules that output scalar in Gather (and data parallel)
* Improve warning msg
* [auto] Update onnx to 9e7855d - Remove PyTorch generated Upsample tests cases (onnx/onnx#1064)
9e7855dcd4
* [script] Add support for torch.zeros, torch.ones, etc. (#7799)
* [script] Add support for torch.zeros, torch.ones, etc.
* modifies gen_jit_dispatch to creating bindings for functions that do
not take tensor arguments, but do have an initial type argument
* adds tensor attributes to these functions for device, layout, and
dtype specification
* extends the list of valid compiler constants to include device, layout,
and dtype.
* allows functions with Generators, but only using the default generator
Known limitations:
* when using `torch.float`, we convert it to a scalar tensor and make
no checks that it is actually used only in a dtype specification.
This is similar to how we handle Python numbers, creating some situations
where the script is more permissive. Fixing this requires much more
significant changes to the IR, so is lower priority for now.
* devices specified using string literals e.g. 'cuda:1' do not work,
since we do not support string literals in general.
* Add profiling annotations to NeuralNet[Operator|Data] (#8005)
* Update from facebook 1ee4edd286a3 (#8040)
* Adding instance weight to batch distill loss
as title
* add bfloat 16-31
added bfloat 16-31 and their respective unit tests
* [CUDA9] Upgrade - fbcode
CUDA9 upgrade diff D5654023 has been out for a while thanks to Pieter. But with time growing it's becoming quite hard to rebase, because of the symlinks and auto-generated build/config files in tp2. Break D5654023 into two diffs, one touching tp2 config files, and another one touching fbcode TARGETS file (adding nvcc flag). These two should be a bit easier to rebase (for detailed procedure see "Test Plan").
This diff can only be committed if:
1. CUDA 9 rpm is rolled out fleet-wide (TBD)
2. NVidia driver 390.40 is rolled out fleet-wide (done)
3. Upgrade CUDA 9.1, cudnn 7.1, nccl 2.1 (done)
4. Make sure all dependents are built (done)
5. Test all C2 operators, PyTorch (see test plan)
* Share intermediate int32 buffer across Conv ops
Adding a known type
* [C2 fix] infer function for ensure_cpu_output_op
this is adding the missing device funtion for ensure_cpu_output_op
* [int8] Add blob serializer/deserializer for Int8TensorCPU
To export to logfiledb
* [nomnigraph] Add try catch block to optimization passes in predictor
This will catch failures that happen in the optimization pass.
* Caffe2: avoid static initialization order fiasco for CAFFE_ENFORCE
CAFFE_ENFORCE uses strack trace fetcher. Which is currently a
global static variable. If at static initialization time CAFFE_ENFORCE
is used, this is a SIOF. Recently CAFFE_ENFORCE was added into init
functions registration, so we started to see this.
Meyers singleton is going to provide safety here. If stacktrace
fetcher was not registered yet, it will just use a dummy one.
* NUMA support in SparseNN CPU benchmark
Adding support for NUMA in SparseNN CPU benchmark
* [mobile-roofline] Add logging needed for roofline model
This should be all that's needed
* Let the operators using the same input if the operators are not chained
or else, we have to change the input data dims
* fix null-pointer-use UBSAN errors in in reshape_op.h
* revert previous fix on input blob name
as title
* Adding flag to let MineHardNegative automatically extract single value from dict
Model exporter requires the output of the model to be a struct. This makes it convenient to use those models directly in MineHardNegative by allow automatic extraction of the single element of dict, which is a common use case.
* Reverting change that broke internal tests back to OSS compatible state
* Skip CUDA memory leak test on BN tests on windows (#8043)
* workaround for Sequential when one cannot retrieve python source (#8048)
* [auto] Update onnx to 0dbec2a - - Generate protoc type hints on Windows (onnx/onnx#1047)
0dbec2a047
* [auto] Update onnx to 4f8ef17 - Remove erroneous documentation around maps and sequences. (onnx/onnx#1069)
4f8ef17ad3
* [auto] Update onnx to e6a500e - Extract constant to initializer (onnx/onnx#1050)
e6a500e54c
* [auto] Update onnx to 033f956 - make gcc happy (onnx/onnx#1061)
033f956f41
* Remove NO_PYTHON macros from Exceptions.h/cpp (#8007)
Removes cases where NO_PYTHON was unnecessary in Exception.h/cpp
* [ready] Clean up torch.distributions (#8046)
* Have a single THStorage and THCStorage type. (#8030)
No longer generate data-type specific Storage types, since all Storage types are now identical anyway.
For (some) backwards compatibility and documentation purposes, the Real names, e.g. THLongStorage are now #defined as aliases to the single THStorage type
* Reduce usages of TensorUtils<T>::DataType in THC. (#8056)
TensorUtils<T> is basically ATen-dispatch-lite in that it allows one to do multi-type THC function dispatch with a single call.
However, it is templatized on the Tensor type, and since we are moving to a single Tensor type, this doesn't work.
Most of the functions in TensorUtils (e.g. getDims) can be pulled up a level, to just call THCTensor_nDimension (or directly accessing the member),
but the DataType specific functions are more problematic.
So, this PR does two things:
1) Replaces calls of 'TensorUtils<THCTensor>::DataType' with 'real' since these are identical
2) Templatizes the THC_pointwiseApplyX functions to take scalar types. To ensure this is done correctly, we static_assert that the scalar type template parameter matches the scalar type of
the corresponding template parameter. We will need to get rid of these static_asserts in the future, but this is useful for now.
* Support to run ONNX Upsample operator (mode=nearest) in Caffe2 (#8037)
* Added support to run ONNX Upsample operator (mode=nearest) in Caffe2
* adding error checks to upsample
* adding error checks to upsample
* adding error checks to upsample
* changing to np.isclose
* Revert onnx submodule update
* still fixing
* [auto] Update onnx to eb12f72 - Add conv transpose test cases (onnx/onnx#886)
eb12f72a86
* [auto] Update onnx to bd98abb - Add a hook for doing post-processing on protobuf generated header files (onnx/onnx#1068)
bd98abbba0
* Skip ConvTraspose ONNX backend tests (#8074)
* Post process onnx proto (#8064)
* Post processing onnx generated protobuf files to hide global symbols
* .
* .
* Add code for TensorBoard visualization of JIT GraphExecutors (#8050)
* [auto] Update onnx to cc26486 - bump version to 7 for prelu. (onnx/onnx#1063)
cc26486541
* [auto] Update onnx to 356208d - add input tensor dimension checks to shape inference (onnx/onnx#1070)
356208d756
* Move backtrace to its own header (#8096)
* Move backtrace to its own header
* Move cxxabi.h into Backtrace.cpp
* Fix and ignore some warnings (#8081)
* Do an additional sanity check that nvcc and CUDA include dir agree. (#8094)
If you set CUDA_HOME and CUDA_NVCC_EXECUTABLE together, you may
end up in a situation where the CUDA_VERSION of your includes
mismatches the CUDA version of your nvcc. See #8092 for a concrete
case where this can occur. Explicitly detect this situation and
give a good error message in this case!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* use regex in kwarg parser (#8061)
* Removing remaining NO_PYTHON ifdefs (#8067)
* Remove NO_PYTHON in tracing
* Remove NO_PYTHON in ir.h
* Remove NO_PYTHON in test_jit.cpp
* Replace std::size_t with size_t (#8093)
* Remove out-of-date comment (#8114)
* [Caffe2] Enabling AMD GPU Backend for Caffe2 (#7955)
* Add hip support for caffe2 core
* Add MIOPEN header/wrapper to caffe2 core
* Add HIP device into caffe2 PB
* top level makefile change for rocm/hip
* makefile scaffolding for AMD/RocM/HIP
* Makefile scafodding for AMD/RocM/HIP; add makefile/utility for HIP files
* caffe2 PB update for AMD/ROCM HIP device
* Add AMD/RocM/Thrust dependency
* HIP threadpool update
* Fix makefile macro
* makefile fix: duplicate test/binary name
* makefile clean-up
* makefile clean-up
* add HIP operator registry
* add utilities for hip device
* Add USE_HIP to config summary
* makefile fix for BUILD_TEST
* merge latest
* Fix indentation
* code clean-up
* Guard builds without HIP and use the same cmake script as PyTorch to find HIP
* Setup rocm environment variables in build.sh (ideally should be done in the docker images)
* setup locale
* set HIP_PLATFORM
* Revert "set HIP_PLATFORM"
This reverts commit 8ec58db2b390c9259220c49fa34cd403568300ad.
* continue the build script environment variables mess
* HCC_AMDGPU_TARGET
* Cleanup the mess, has been fixed in the lastest docker images
* Assign protobuf field hip_gpu_id a new field number for backward compatibility
* change name to avoid conflict
* Fix duplicated thread pool flag
* Refactor cmake files to not add hip includes and libs globally
* Fix the wrong usage of environment variables detection in cmake
* Add MIOPEN CNN operators
* Revert "Add MIOPEN CNN operators"
This reverts commit 6e89ad4385b5b8967a7854c4adda52c012cee42a.
* Resolve merge conflicts
* .
* Update GetAsyncNetHIPThreadPool
* Enable BUILD_CAFFE2 in pytorch build
* Unifiy USE_HIP and USE_ROCM
* always check USE_ROCM
* .
* remove unrelated change
* move all core hip files to separate subdirectory
* .
* .
* recurse glob core directory
* .
* correct include
* .
* Detect CUDNN related environment variables in cmake (#8082)
* Implement adaptive softmax (#5287)
* Implement adaptive softmax
* fix test for python 2
* add return_logprob flag
* add a test for cross-entropy path
* address review comments
* Fix docs
* pytorch 0.4 fixes
* address review comments
* don't use no_grad when computing log-probs
* add predict method
* add test for predict
* change methods order
* get rid of hardcoded int values
* Add an optional bias term to the head of AdaptiveSoftmax
* Make libshm also test if rt requires pthread. (#8112)
In some configurations (e.g., our internal build of GCC 5 + GLIBC 2.23),
-lrt is not sufficient to use shm_open; you also need to declare
a dependency on pthread. This patch adds a surgical extra fix to
detect this situation, in the case that I noticed it failing in the
wild.
Fixes#8110
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* [auto] Update onnx to 2d5ce4a - Remove empty model (onnx/onnx#1058)
2d5ce4aeb6
* Add missing pragma once. (#8118)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* [auto] Update onnx to 2a87616 - Tests for LRN operator (onnx/onnx#903)
2a876162ac
* Split SparseTensorImpl off from TensorImpl. (#7990)
* Split SparseTensorImpl off from TensorImpl.
At the moment they have the same data layout, but with the upcoming refactor
they will not, and we need a place to put all of the sparse tensor specific
fields.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Update SparseTensorImpl.h
* [Caffe2] Support non peer access in muji and fix bug when reduced_affix is empty (#6896)
* [Caffe2] Support non peer access in muji
* [Caffe2] Add test for 4 gpus and 2 groups
* [Caffe2] Add comments
* Fix bug when reduced_affix is empty
* Fix typo and add comments about cpu and amd gpu
* Skip OnnxBackendNodeModelTest::test_lrn_default_cuda that causes segfault (#8127)
* Replace most remaining usages of TensorUtils<T>::DataType. (#8124)
As in https://github.com/pytorch/pytorch/pull/8056, this doesn't work with a single TensorImpl type.
This replaces the usages of with a templatized parameter and static_asserts that the new and old are equal.
After this we can get rid of the old template parameter, but I want to ensure they are equivalent across all builds first.
* Add utf-8 header to Python file with Unicode. (#8131)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Add back lrn test (#8134)
* Revert "Skip OnnxBackendNodeModelTest::test_lrn_default_cuda that causes segfault (#8127)"
This reverts commit 410191c417.
* Fix mismatched default values
* Add non_blocking to Tensor/Module.to (#7312)
* Add non_blocking to Tensor/Module.to
* flake8
* Add argparse tests
* cpp parse
* Use C++ parser
* use a commong parse function with Tensor.to
* fix test_jit
* use THPObjectPtr
* increase refcount for None, True, and False
* address comments
* address comments
* Fix job name checking for AVX tests (#8135)
* Fix a corner case for ReShapeOp (#8142)
In my use case, in the backward propogate pass, the reshape need to
change a [0] tensor into [0,0] shaped tensor. The original implementation would
cause out of index issue. This diff fix this problem.
* cpu/ideep context converter (#8139)
* fix type mismatch while call torch._C._cuda_setDevice (#8065)
* fix type mismatch while call torch._C._cuda_setDevice
* fix type mismatch in scatter
* fix type mismatch in scatter
* fix type mismatch while call torch._C._cuda_setDevice
* fix type mismatch while call torch._C._cuda_setDevice
* fix type mismatch while call torch._C._cuda_setDevice
* docs: Add warning to torch.repeat() (#8116)
* docs: Add warning to torch.repeat()
closes#7993
* docs: Add links for numpy functions
* docs: Break the too long line
* Accelerate bernoulli number generation on CPU (#7171)
* opt bernoulli rng with vsl and openmp
* detect cpu vendor for bernnoulli
* retrigger test platform
* check the vendor more severely
* use cpuinfo to check vendor
* docs: add canonical_url and fix redirect link (#8155)
* docs: enable redirect link to work for each specific page
* docs: add canonical_url for search engines
closes#7222
* docs: update redirect link to canonical_url
* docstring support for @script and @script_method (#7898)
* docstring support for @script and @script_method
* make it python2 compatible
* improve according to review
* improve build_stmts
* use filter instead of list comprehension
* improve the way wrap is handled for script_method
* stash the original method instead
* allow dynamic attr for ScriptMethod and GraphExecutor
* a bit comment on build_Expr
* remove _build_wrap
* a bit improve on comments
* rename to __original_methods
* should be _original_methods
* [auto] Update onnx to 968d28d - fix Node::isBefore (onnx/onnx#1075)
968d28d901
* remove some unnecessary cudaGetDevices (#8089)
* remove unnecessary cudaGetDevices
* make curDevice argument non-optional, add explicit checks to current_device
* Fix cuda.framework error on OSX. (#8136)
When compiling OSX with CUDA, Caffe2's build system uses
find_package(cuda) to get its grubby hands on the CUDA driver
library (for some strange reason, FindCUDA doesn't save this
information as a variable). Unfortunately, on OSX, sometimes
this picks up the cuda.framework folder, and then our build
system chokes to death because it doesn't try to link against
this as a framework. (Is the folder even a framework? I have
no idea).
This commit attempts to fix this in a two pronged fashion:
1. For some users, reducing the precedence of frameworks
using CMAKE_FIND_FRAMEWORK seems to help. So we set these
variables. However, this fix is not perfect; on my laptop
it doesn't actually solve the problem.
2. PyTorch doesn't actually need the CUDA driver API. So we
only add the dep when building Caffe2.
Fixes#8022
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* [C++ API] Improve and use OrderedDict for parameters / modules (#7823)
* Improve OrderedDict for C++ API
* Give OrderedDict a subject and fix review comments
* Fix OrderedDict use in torch/csrc/jit/script/init.cpp
* Fix __rshift__ bug (#8161)
* Fix __rshift__ bug
* Add small tests for __lshift__ and __rshift__ in test_cuda
* Add a more elaborate check for __lshift__ and __rshift__
* refactor the test to address @zou3519 's comments
* Move non-generic Storage code needed by TensorUtils to non-generic C++. (#8164)
For non-generic function call implementations in Storage used by TensorUtils, we do the following:
1) Move the declaration from generic/C to non-generic/C++; we don't need backwards compatibility on these functions and want to use e.g. at::ScalarType.
2) Move the implementation from generic/C++ to non-generic/C++.
3) Change the generic implementation to call the non-generic implementation.
This will allow us to get rid of the corresponding TensorUtils calls (once we move over the Tensor functions in the same manner).
* Pinning opencv to < 3.4 in conda builds (#7923)
* Pinning opencv to 3.1.0 in conda builds
* Also pinning numpy to 1.11
* Trying only specifying <3.4
* Adding -setup- path, and better code structure (#8122)
* Abstract parallelization to faciliate using threadpools (#8163)
* [Caffe2] Update elementwise ops to support numpy style boradcast (#8070)
* Update elementwise ops to support numpy style boradcast
Update elementwise ops to support numpy style boradcast
* Fix sqrt_op
* Fix compare ops
* Fix gradient test
* Fix optimizer legacy broadcast
* Fix legacy broadcast for elementwise ops
* Skip flaky test
* Fix eigen simple binary op
* Fix attention test
* Fix rnn test
* Fix LSTM test
* Fix tan grad
* Fix schema check
* Export getCudnnHandle (#7726)
* [JIT] Support a single TensorList argument anywhere in the argument list + index_put (#8173)
* [JIT] Support a single TensorList argument anywhere in the argument list
* [JIT] index_put
* use the correct datatype format (#8144)
* Add back onnx console scripts dropped during migration from onnx-caffe2 (#8143)
* Get rid of SOVERSION (again). (#8132)
We don't want SOVERSION because pip will lose the symlink and
double your distribution size, and also because our setup.py
accidentally links against both libcaffe2.dylib and libcaffe2.1.dylib
on OS X. This leads to a very puzzling error where you get
the error "cannot initialize CUDA without ATen_cuda", because
there are actually two copies of your registry in memory (because
there are two copies of the dynamic library). Dropping SOVERSION
makes it impossible to make this mistake.
In principle, if the shared library load is done with DYLD_GLOBAL,
that should also prevent two copies of the registry from popping up.
Worth checking at some later point, if you need to bring back
SOVERSION (because, e.g., pip finally fixed their software.)
Partially fixes#8022.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* Fix a corner case for ReShapeOp (#8178)
In my use case, in the backward propogate pass, the reshape need to
change a [0] tensor into [0,0] shaped tensor. The original implementation would
cause out of index issue. This diff fix this problem.
* Better conv error message basing on weight shape (#8051)
* Add retry logic to sccache download for Windows build (#7697)
* Add retry logic to sccache download for Windows build
* fix script bug
* clean up
* fix caffe2 docker build (#7411)
* [ONNX] Fix type_as symbolic (#8183)
* [ONNX] Nuke type_as symbolic
* make it better
* Fix lookup + test
* Yangqing as an ONNX codeowner (#8185)
* Fix protobuf options (#8184)
* protobuf
* fix protobuf_MSVC_STATIC_RUNTIME
* Add a loop unrolling pass to PyTorch JIT (#7672)
* [auto] Update onnx to 4e65fd8 - fuse consecutive squeezes (onnx/onnx#1078)
4e65fd83ba
* [Caffe2] Merging setup.py with setup_caffe2.py (#8129)
* Mergine setup.pys, torch works, caffe2 works up to other KP
* Fix to super call for python 2
* Works on python2 on mac
* Consolidating Caffe2 flags
* Fix scalar check for sparse tensors. (#8197)
* Fix scalar check for sparse tensors.
As discovered in #8152
If `t` is a scalar sparse tensor, `t._indices` used to return a sparse
empty tensor because the scalar check was incorrect. This PR modifies
the scalar check to return a dense tensor instead of a sparse tensor.
i.e.
```
tensor = torch.sparse_coo_tensor([], [], torch.Size([]), device=device)
out = tensor._indices() # was a sparse tensor, now is dense.
```
* Fix typos
* fix lint
* Add more annotations for arguments in ATen schema (#8192)
* use THCThrustAllocator in BCECriterion (#8188)
* Allow parallel_apply to take in list[Tensor] (#8047)
* Docs for gradcheck and gradgradcheck; expose gradgradcheck (#8166)
* Docs for gradcheck and gradgradcheck; expose gradgradcheck
* address comments
* Implement randperm for CUDA (#7606)
* Implement randperm for CUDA
* Use Thrust to implement randperm
* clean up
* Fix test
* Offload small input scenario to CPU
* Fixed test
* Try to fix Windows error
* Fix Windows error and clean up
* Use fork_rng context manager
* Move test_randperm_cuda to test_cuda
* Add half tensor support
* Fix cuda::type error
* Fix CPU offloading
* Fix issues
* No need to check range for n == 0 case
* Update c10d build to link against Caffe2 (#8201)
This follows #7399.
* add wipe_cache option (#8204)
as title
* Replace (non-data) TensorUtils calls with non-generic THCTensor calls. (#8176)
* Replace (non-data) TensorUtils calls with non-generic THCTensor calls.
TensorUtils is templatized on the THTensor type, so to support a single tensor type (like ATen), we need to remove these.
This PR does the following:
1) Allows THCTensorTypeUtils.cuh to include THCTensor.hpp.
This involves moving includes of it outside of generic/, so we can use the new implementations.
2) Defines a single _THTensor struct and changes THCRealTensor to be a derived type of _THCTensor.
This allows us to implement a single non-generic function and avoid static_cast or void * tricks to call it from the generic functions.
3) For functions inside of TensorUtils that don't use data pointers:
a) Implement the functions in (non-generic) THTensor.cpp and declare them in (non-generic) THTensor.hpp.
b) Have the generic versions call the non-generic versions.
c) Replace the corresponding TensorUtils<THCTensor>::fn call with (non-generic) THTensor_fn.
* Add comment about THCTensor struct.
* Error if storage is null in setStorageNd or resizeNd.
* Fix c10d compiler warnings (#8206)
Copy compiler flags from the ones used in setup.py and fix warnings.
This makes the root build that includes c10d headers warning free.
* Bump gloo submodule (#8202)
This includes facebookincubator/gloo#125.
* rm -rf aten/contrib (#8165)
* Remove aten/contrib
* Remove from CMake
* Fix tanh_op on ios build (#8207)
* Fix tanh_op on ios build
* Fix tanh
* [auto] Update onnx to f28e2f1 - fix lrn spec (onnx/onnx#1090)
f28e2f1a60
* [cmake] deprecate caffe2_* specific cuda function in cmake. (#8200)
* deprecate caffe2_* specific cuda function in cmake.
* ENV{} -> $ENV{}
* CUDA_ARCH_NAME -> TORCH_CUDA_ARCH_LIST
* .
* .
* .
* skip CUDA memory leak check on Windows altogether (#8213)
* Record shape and type in autograd to validate gradients (#8168)
The check that the gradient is defined is currently disabled because
TestJit.test_ge_optimized will trigger the error.
* [auto] Update onnx to 18d70ff - Graph should only have one (input) kParam node (onnx/onnx#1088)
18d70ff529
* Set up a c10 source folder (#7822)
* Set up a c10 source folder
* Change the benchmark log format and also log flops (#8215)
as title
* Move helper functions to unnamed namespace. (#8224)
Currently, the helper functions in this file are in global
namespace. I am guessing the purpose of excluding them from was to
keep them local.
* [auto] Update onnx to e96d823 - Update Google benchmark to 1.4.1 (onnx/onnx#1083)
e96d823e5c
* Change new bernoulli implementation to be fully generic. (#8218)
The current implementation depends on THTensor types being unique, which is not guaranteed going forward.
* Structure THTensor like THCTensor is structured. (#8217)
In particular, define a base type, _THTensor, that can be used for all THRealTensor structs.
This is just to have less cognitive load when dealing with generic THTensor/THCTensor types (as in templates).
* move THCP-related utils to cuda/utils.cpp. (#8221)
These files don't follow the usual pattern: In general the files torch/csrc/X torch/csrc/cuda/X
both include the generic file torch/csrc/generic/X, where torch/csrc/X includes the cpu implementations and torch/csrc/cuda/X includes the cuda implementations.
(Aside: this is probably not the best structure, the torch/csrc/X fiels should probably be moved to torch/csrc/cpu/X).
utils.cpp combines these so that torch/csrc/utils.cpp has cuda specific code. This makes it impossible to declare a single THTensor and THCTensor template type (i.e. THPPointer<_THTensor>, THPointer<_THCTensor>).
* [READY TO MERGE] Use ccache in macOS build (#8009)
* Use ccache in macOS build
* Moving to sccache
* Don't use sccache in test job
* [NEEDS REVIEW] Add nan and inf probability check to multinomial (#7647)
* Add nan and inf probs check to multinomial
* fix bug
* Spawn CUDA test in subprocess
* Make sure invalid input won't pass the test case
* Try to fix error
* Test failure cases in Python 3 only
* Try to fix Windows error
* Move CUDA test to test_cuda.py
* fix issues
* fix module name error
* no need to check for CUDA existence in test_cuda
* Use PY3
* [READY TO MERGE] Enable tests that use DataLoader with multiple workers on Windows (#6745)
* Don't import TEST_CUDA for test_dataloader on Windows
* test_partial_workers is stuck on Windows
* Don't copy unneeded grads when using a function for several derivatives (Fixes#7722) (#7759)
Trying to copy all results fails when one of them is a tensor list which
has not been populated. This blew up for CuDNN RNNs when the weights
did not require grad.
Thanks to Sylvain Gugger for reporting!
* Fix win mkldnn (#7718)
* Sync build_pytorch_libs.bat with build_pytorch_libs.sh
* fix quoting
* add warnings
* fix warnings
* Add /EHa
* [Caffe2] Add ADD operator for IDEEP (#8220)
* Add ADD operator for IDEEP
* Add boradcast check
* Comments
* Allow optional build and installation of native test binaries (#8225)
* test finetuning
* install off by default
* Turn BUILD_TEST=ON for jenkins.
* Turn on install_test in jenkins as well
* Update MKL exporter to IDEEP ops (#8228)
IDEEP exporter support
* [ideep] Add IDEEP Squeeze op (#8227)
Similar to MKLSqueezeOp at caffe2/mkl/operators/squeeze_op.cc
* [auto] Update onnx to 62e63e9 - Fix build errors inside protobuf-bench (onnx/onnx#1084)
62e63e9de8
* Use .cc since some downstream libraries are configured for C++ only. (#8234)
* Rename SparseTensor to SparseTensorRef. (#8237)
I want to introduce using SparseTensor = Tensor (as a documentary
type alias for Tensor), but the name is already taken.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* [caffe2] Build Android tests and binaries in CI (#7593)
Update benchmark submodule to version with fixed Android/GNUSTL build
* Remove core and util warnings (#8239)
* Fix some signed/unsigned mismatches
* Skip unused result warning
* Explict fallthrough for murmur hash
* Enable aligned new support to eliminate warning
* Switch to int instead of unsigned in some cases
* Remove .gitmodules.aten since it is in .gitmodules now (#8232)
* Fix: gradcheck forced float32 (#8230)
* Print requires_grad and grad_fn in string repr of tensor (#8211)
For example:
>>> torch.ones(3).requires_grad_()
tensor([ 1., 1., 1.], requires_grad=True)
>>> torch.ones(3).requires_grad_() * 5
tensor([ 5., 5., 5.], grad_fn=<MulBackward0>)
The suffix (dtype, requires_grad, grad_fn) wraps to a new line if
it would cause the the line to exceed the linewidth.
>>> torch.ones(10).double().requires_grad_()
tensor([ 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
dtype=torch.float64, requires_grad=True)
* Fix TEST_CUDA import in test_cuda (#8246)
* Fix lifting cat into its constant version (#8174)
This fixes a bug where schema including varargs lists did not lift
properly blocking correct ONNX export.
* Don't override Tensor, Storage macros defined outside torch/csrc in t… (#8243)
* Don't override Tensor, Storage macros defined outside torch/csrc in torch/csrc.
This PR does the following:
1) Removes THSTensor macros in torch/csrc, which aren't used.
2) For macros defined outside of torch/csrc (THTensor, THTensor_, THStorage, THStorage_):
a) No longer override them, i.e. previously THTensor could actually be THCTensor if a generic file was included from a file including THCP.h.
b) Instead, introduce new macros THW* (e.g. THWTensor) to represent a (potentially empty) wildcard character.
In addition to making this code easier to read and codemod, this allows us to more freely change TH/THC; for example:
currently in the THC random code, the state is casted to THByteTensor*; this happens to work because the macros don't happen to override THByteTensor.
But if THByteTensor just becomes an alias of THTensor (which is the plan for a single tensor type), then this no longer works.
The whole thing is a bit of a mess previously because you really have to understand which macros and redefined and which aren't.
We could also rename the macros that live in torch/csrc (e.g. the THPTensor macros), but since that is more self contained, I punted for now.
* Don't change the plugin.
* [auto] Update onnx to 3a035f4 - Add retry logic to model downloading (onnx/onnx#1077)
3a035f4397
* Fully genericize THC/THCUNN (except for TensorUtils and DeviceTensorUtils). (#8251)
* [cmake] Use CAFFE2_USE_* for public/cuda.cmake (#8248)
* Fix app size check (#8256)
Fix app size check
* wip on CPU impl
* Stop BCELoss from returning negative results (#8147)
* Stop BCELoss from returning negative results
* check explicitly for 0 before taking log
* add tests
* fix lint
* address comments
* Relax CUDA_HOME detection logic, to build when libraries are found. (#8244)
Log when no cuda runtime is found, but CUDA is found
* Added backward function for kl_div target (#7839)
* added backward fn for target
* added module test for kl_div target, and assuming targets are probabilities
* Change the output format of caffe2 observers (#8261)
as title
* Remove TensorUtils<T>::getData, provide data<T>() in TH(C)Tensor. (#8247)
* Remove TensorUtils<T>::getData, provide data<T>() in TH(C)Tensor.
* Fix template parameter.
* [caffe2] Move submodule onnx-tensorrt forward (#7659)
Commit 82106f833dcb0070446a150e658e60ca9428f89b is essential.
* [ideep] Add IDEEP fallbacks for Faster-RCNN ops (#8260)
TSIA
* un-genericize THCDeviceTensorUtils. (#8258)
* provide data<T>() in TH(C)Tensor.
* un-genericize THCDeviceTensorUtils.
This is used outside of generic context, so we need to un-genericize it to have a single THCTensor type.
* [caffe2] Fix ATen dispatch for ops with TensorList arg (#8226)
* [cmake] Add and export Modules_CUDA_fix (#8271)
* Add and export Modules_CUDA_fix
* actually, need to include before finding cuda
* [auto] Update onnx to 2508156 - Make error message more verbose (onnx/onnx#1097)
2508156135
* [auto] Update onnx to 39e4668 - fix optimizer does not set ir_version bug (onnx/onnx#1098)
39e46687ea
* [cmake] Make cudnn optional (#8265)
* Make cudnn optional
* Remove cudnn file from cpu file
* Move signal window functions to ATen; add Blackman window (#8130)
* Move signal window functions to ATen; add Blackman window
* fix cuda test not checking scipy
* [ideep] Fuse Conv-Relu after IDEEP graph rewrite, skip group conv (#8233)
IDEEP supports fusion for non-group conv
* [c10d] NCCL Process Group implementation (#8182)
* [c10d] Process Group NCCL implementation
* Addressed comments
* Added one missing return and clang format again
* Use cmake/Modules for everything and fix gloo build
* Fixed compiler warnings
* Deleted duplicated FindNCCL
* Set up CI build for CUDA 9.2 + macOS (#8274)
* Add macOS CUDA build to CI
* Fix undefined symbols issue
* Use sccache for CUDA build
* Fix sccache issues
* clean up
* c10 build setup (#8264)
* Move c10/ to caffe2/dispatch/
* Set up caffe2/utils directory
* Remove remaining TensorTypeUtils functions. (#8286)
Mostly what's remaining is copy utilities -- these are now provided in THCTensorCopy.hpp and templatized on the ScalarType rather than the TensorType.
* Create initial Python bindings for c10d (#8119)
* Build and install c10d from tools/build_pytorch_libs.sh
* Create initial Python bindings for c10d
* clang-format
* Switch link order to include more symbols
* Add bindings and tests for ProcessGroupGloo
* Add broadcast test
* Separate build flag for c10d
* Explicit PIC property
* Skip c10d tests if not available
* Remove c10d from Windows blacklist
Let it skip by itself because it won't be available anyway.
* Make lint happy
* Comments
* Move c10d module into torch.distributed
* Close tempfile such that it is deleted
* Add option USE_NVRTC which defaults to off (#8289)
* [build] Remove /torch/lib/THD/cmake in favor of /cmake (#7159)
* Remove /torch/lib/THD/cmake in favor of /cmake
* path fix
* Explicitly marking gloo to use cuda
* Fix gloo path in THD
* Have a single THTensor / THCTensor type. (#8288)
* Remove remaining TensorTypeUtils functions.
Mostly what's remaining is copy utilities -- these are now provided in THCTensorCopy.hpp and templatized on the ScalarType rather than the TensorType.
* Have a single THTensor / THCTensor type.
As was previously done with Storages, have only a single (dtype-independent) THTensor / THCTensor.
For documentation and backwards compatibility purposes, the old names, e.g. TH(Cuda)LongTensor alias the new TH(C)Tensor type.
* undef GENERATE_SPARSE.
* [auto] Update onnx to 58efe0a - add float16 support back for math and reduction ops (onnx/onnx#1102)
58efe0a9ca
* Some utils for compile-time programming (#7778)
* Add some C++17 features, implemented with C++14
* Add some type traits
* Compile-time type list abstraction
* Some utils for compile-time programming
* Fix compatibility with a larger range of compilers
* Use guts::array instead of std::array because of std::array shortcomings
* code review comments
* Use quotes for includes
* Remove THC's FindMAGMA (#8299)
* Entries for torch.distributed in CODEOWNERS (#8293)
* Add depthwise convolution test for IDEEP (#8301)
* Fix dividing by zero segfault in Reshape (#8302)
when infer a dimension of zero size new shape
* Removes unused THCTensorConv (#8229)
* Replace Variables to Tensors (#8309)
* Clean up old sccache log before build (#8305)
* Remove unused grad ops on mobile to reduce app size (#8297)
Remove unused grad ops on mobile to reduce app size
* Small fixes (#8296)
* [auto] Update onnx to 5ed684e - Remove/replace /MX with /WX for MSVC build. Was typo in a previous ch… (onnx/onnx#1104)
5ed684ebe5
* Fix sample code for cuda stream (#8319)
* [auto] Update onnx to 4b4085c - Add missing warning ignoring flags to onnx_proto CMake target (onnx/onnx#1105)
4b4085c2e9
* [THD] fix broken THD build with NCCL (#8323)
* Add docstring for `torch.sparse_coo_tensor` (#8152)
* add sparse_coo_tensor docstring
* update empty tensor example
* whitespace
* whitespace again
* add error when backend is not supported by DDP (#8325)
* Fix collect_env.py for Windows (#8326)
* Fix collect_env.py for Windows
* Fix expect file for Win machine
* Fix the script doesn't stop eariler on error for MSVC and Ninja (#8277)
* Simplify the solution
* Remove the usage of set errorlevel
* Skip test_multinomial_invalid_probs_cuda on Windows (#8324)
* Support printing sparse tensors in ATen, fixes#8333. (#8334)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* [C++ API] Cursors (#8190)
* Add cursors to C++ API
* Small self nits
* s/struct/class
* Use more STL like names for cursors
* Implement dim_arange operator (#8266)
* Implement arange_like operator
* add ONNX symbolic
* lint
* change name
* Comment the hack
* 1. fixed flip CPU impl for non-continuous flip dims; 2. added more tests; 3. using TensorInfo and collapseDims to speed up CUDA impl for cases where flip dim is the 1st or last dim
* nits
* 1. removed for loop in pointwise CUDA kernel; 2. using templated (int64_t) IndexType for indices in pointwise CUDA kernel
* added torch.flip.__doc__
* nits
* Port THS to ATen.
The basic structure of the patch:
- All kernels in aten/src/THS got rewritten as native
functions in aten/src/ATen/native/sparse
I took the liberty to rename some of the kernels,
opting for a longer, more transparent names than
things like 'spaddcmul'.
- Instead of holding fields for sparse tensor in the TH
C struct THSTensor, they are now held in a C++ class
SparseTensorImpl (this explains why I had to do this
all in one go; I can't have *two* reps for sparse
tensors!)
Along the way, we change a key internal representation
invariant: an "empty" sparse tensor has dimI == 1 and
dimV == 0 (this is different from dimI == 0 and dimV == 0
we had before); this ensures that we maintain the invariant
that dim == dimI + dimV. "Scalar" sparse tensors are
made illegal, because there really is no way to properly
express them in COO format.
- Because we haven't ported THCS or any of the traditional
dense TH implementations, there is a new set of adapter
functions in native/LegacyBridge.cpp exclusively devoted
to deciding whether or not to go to the new native implementation
or back to the legacy TH binding (prefixed with th_).
The intent is that when everything gets ported, we can
delete this file.
- I've kept the stubs for all the THS functions, but they now all
error if you try to actually call them. Eventually, we should
replace these with calls to ATen so that everything keeps
working.
- I gobbled up SparseMM (SparseMM.cpp is no more). It was tasty.
There are some miscellaneous improvements which were needed for other
changes in this patch:
- There is now AT_FORALL_SCALAR_TYPES_EXCEPT_HALF, which does what
it says on the tin.
- axpy templated function moved to TH/BlasUtils.h, there's a new macro
which lets you easily forward to all of the TH functions. We also expose
THBlas_copy. I'm not terribly pleased with these functions but
they seem to serve a purpose they need.
- New method on Tensor to get TensorImpl*, unsafeGetTensorImpl
- accessor() is now this-const, since const-correctness on Tensor is a lie
- New toSparse()/toDense() methods on Type; now you can call these
directly without having to manually apply at::toSparse/toDense
on the Backend and then running toBackend yourself.
Changes to the kernels:
- Previously, the whole body of all kernels was compiled for
every supported scalar type. In our new implementation,
the scalar dispatch has been pushed into the smallest extent
which (1) is not in a type loop and (2) requires statically
knowing the scalar type. These sites all use
AT_DISPATCH_ALL_TYPES. I tried to use lambdas as much as
possible, but sometimes it was not possible when a OpenMP
pragma was used.
- Anywhere we tested if the nDimension of a tensor was zero,
we replaced with a test that numel is zero. Because, as we
known, nDimension of zero-size tensors in TH is zero, and
that's wrong wrong wrong (and not done this way in ATen).
Some subtleties:
- Places where previously fastget1d was used, I now use a
TensorAccessor. However, you have to be careful about grabbing
the accessor, because sometimes you will be accessor'ing
indices/values and they are empty, which means they will
be *1D* ("oh, aren't indices always 2D?" Nope. Nyet.)
So, essentially, it is only safe to grab an accessor *after*
you have checked that nnz != 0. All of these shenanigans
will go away when we properly support zero-size dimensions.
A few places, we test for this case just by wrapping the loop
in a conditional on nnz. Some other places this is not so easy,
so we instead short-circuit the function with a special case for
when nnz == 0 (usually, these implementations are degenerate).
- There is a very subtle but important difference between
_sparse_get_impl(self)->indices() and self._indices();
the latter may return a view! This is because nnz is
not guaranteed to match the dimensions of indices/values;
you can "truncate" a sparse tensor by setting the nnz.
Actually, I think this is not a good idea and we should
enforce a stronger invariant, but for this patch I slavishly
adhere to the old ways, and as such I have to be very
careful if I want to resize something, I had better use
the former and not the latter.
- I had to reimplement broadcasting by hand (thus the s_
and non-s_ functions in the sparse native files). There
is a very important distinction between foo_out and foo_,
so it is important that the LegacyBridge function always
call to the lower layer, and not try to avoid boilerplate
by calling to another LegacyBridge function first.
I did NOT put broadcasting in LegacyBridge (even though,
ultimately, that's where it must live), because the th_
functions which are invoked from LegacyBridge handle
broadcasting themselves, and I don't want to broadcast
twice.
- Sparse function MUST explicitly specify the Type they
dispatch from, otherwise Variable wrapping/unwrapping will
not work correctly. If you use _get_sparse_impl, that is
sufficient to levy this requirement.
- The "has native" tests in LegacyBridge.cpp are not 100%,
because some of the functions are mixed dense-sparse functions,
and so you can't just say, "Oh, if it's sparse and CPU, call
the native sparse implementation." This is handled on a
case by case basis. There is some especially complex
logic for add(), which has dense-dense, sparse-sparse
and dense-sparse implementations.
- I added some uses of SparseTensorRef in native_functions.yaml,
but you will notice that these are all on native_* functions,
and not the actual, top-level functions. So the SparseTensorRef
is purely documentary (helping you not call the wrong overload)
but there is no magic; we do the wrapping ourselves the hard
way. (This is in constrast to the TH binding code which is magical.)
Except for _sparse_mask; _sparse_mask is magical.
- There is a raw_copy_sparse_ method, which is really my way of
getting around the fact that copy_ has never been implemented
for sparse tensors (even before this patch), but there IS a
super secret, internal way of doing these copies that the THS
code used, and which I needed to get my hands on when I did this
port. We should refactor so that either (a) copy_ does support
sparse-sparse copy natively, or (b) we do this other ways.
- Irritatingly, I must explicitly resize_as_ before copy_ into
a tensor. This was not the case with THTensor_(copy) but I don't
have any direct binding that doesn't have this requirement.
- For some reason, the sparse tensor constructor accepts a scalar
tensor for the values tensor. This is kind of weird because
you always need an nnz-dimension. However, the old code supported
this and just expanded it into a 1D size 0 tensor; so we need some
explicit code to do this.
There are maybe a bit more AT_ASSERTs in some of the kernels
than is wise. I added them all when I was debugging and was
loathe to remove them.
Some last mile fixes after this commit went into PR
- Move expand outside of dispatch so autograd works (it used to be inside and then we lost all of the recorded broadcasts).
- Hack to duplicate the derivatives for our now two definitions TH and native. Mercifully the derivatives are short.
- Apparently, TH has a special case to make foo_ functions method only, and if you don't do this the Python arg parsing is wrong. We carefully work around this in the native bindings
- Apply DCE to a test_jit case, fixes wobbling due to DCE trick in tracing
- Update test_function's output
- Some last mile fixes for dispatch confusion in sparse_coo_tensor functions.
- New simplified regression test based on failures I saw in ONNX
- Increase tolerance on super resolution test
- More robust dynamic_type normalization, fixes ONNX bug.
The dynamic_type situation is very delicate; probably need
to stop having both Scalar and real.
- Make new_with_tensor_sparse more CUDA safe
- Note about CUDA-safety in SparseTensorImpl
- Rename dimI/dimV to sparseDims/denseDims.
- Make localScalar on SparseTensorImpl work.
- Make numel uniformly supported on all types, not just dense
types
- Add tests for is_nonzero() method (which exercises localScalar)
- Disable constant JIT autogenerated tests, which are fragile and broken
by this change, but being fixed in a parallel track.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* throw error on 0-length tensor slicing
* return empty tensor instead of throwing error
* make 0 slice work for tuples also
* add tests
* move check to aten
* Address comments
* 1. added hardshrink() to ATen (CPU + GPU); 2. removed nn.Hardshrink(); 3. reusing previous tests for nn.Hardshrink() and included CUDA tests at test_nn; 4. default parameter lambda=0.5 is not working yet
* optimized memory read/write
* 1. pass in lambd as scalar for CPU/CUDA_apply*; 2. removed tests for hardshrink at test_legacy_nn
* fixes test_utils
* 1. replace zeros_like with empty_like; 2. use scalar_cast in cuda
* 1. printing lambd value; 2. default lambd=0.5 is still failing
* getting around Scalar bug buy removing default value of lambd from native_functions.yaml, and declare it at nn/functional.py
* cleaned up debug printf
* Implement CPU bincount feature support
* Incorporate feedback on renaming to SummaryOps file and other nits
* bincount gpu implementation
* refactor cuda code and incorporate nits
* doc fix
* cuda bincount - cast weights to double if integral type
* fix: signed unsigned comparison error
* fix: ssize_t error
* refactor
* make template typenames readable and other nist
* make compatible with v0.5
* incorporate comments
* update test cases to ensure CUDA code coverage
* Improve number formatting in tensor print
* fix bad rebase
* address comments
* fix test
* fix test
* use assertExpected for tests
* address comments
* address comments
* Add nan and inf probs check to multinomial
* fix bug
* Spawn CUDA test in subprocess
* Make sure invalid input won't pass the test case
* Try to fix error
* Test failure cases in Python 3 only
* Try to fix Windows error
* Move CUDA test to test_cuda.py
* fix issues
* fix module name error
* no need to check for CUDA existence in test_cuda
* Use PY3
* Add non_blocking to Tensor/Module.to
* flake8
* Add argparse tests
* cpp parse
* Use C++ parser
* use a commong parse function with Tensor.to
* fix test_jit
* use THPObjectPtr
* increase refcount for None, True, and False
* address comments
* address comments
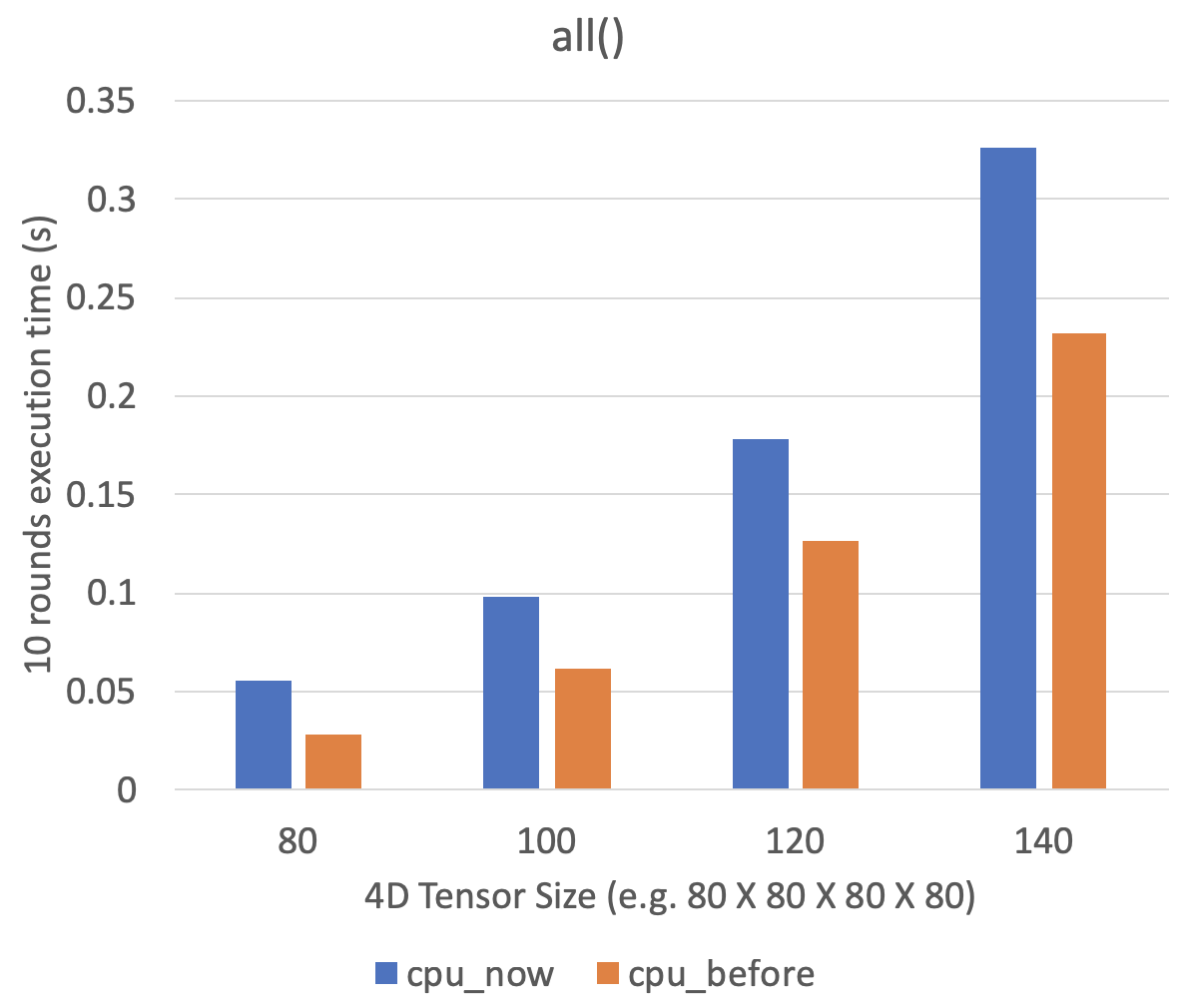{kind=link}
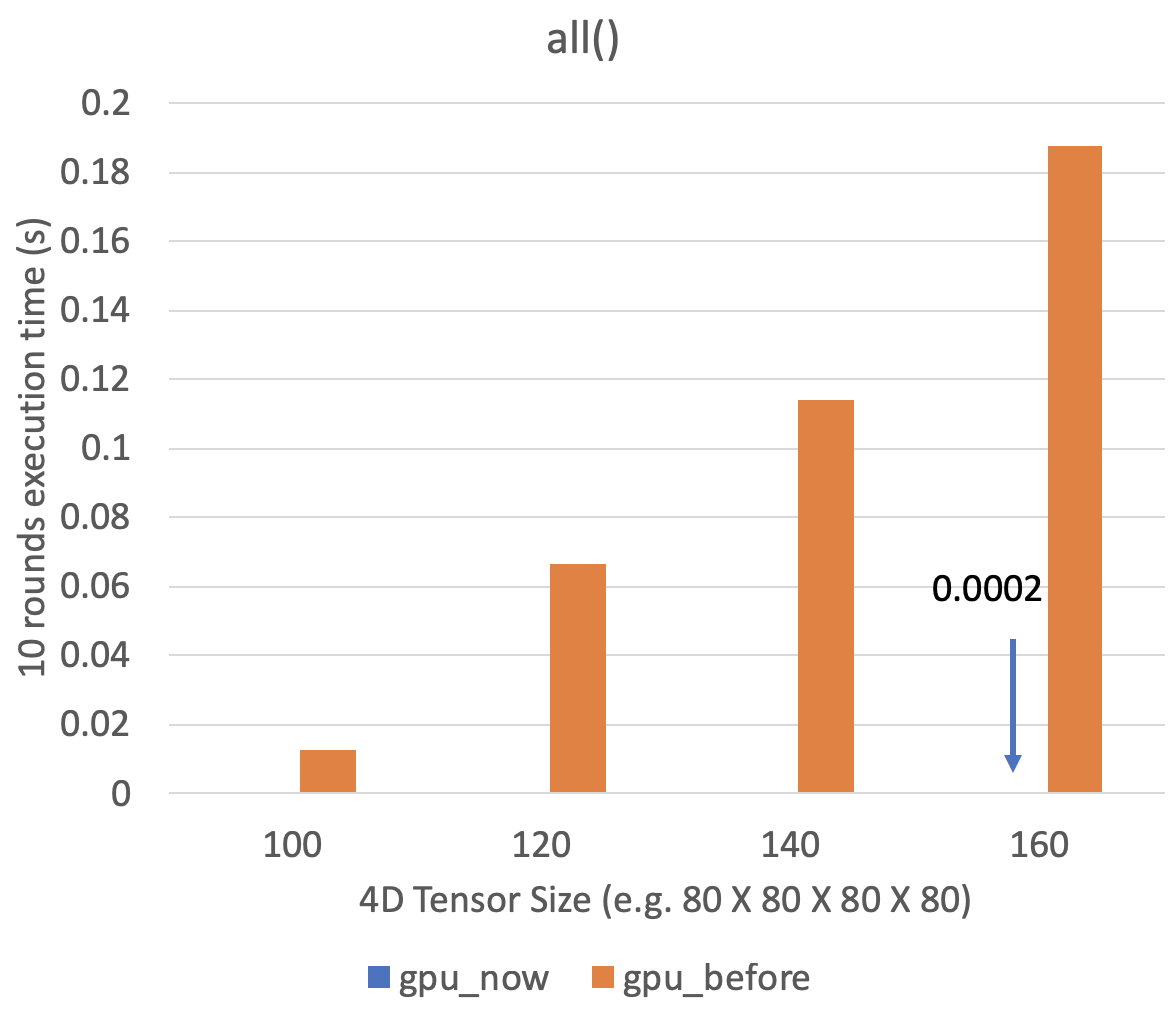{kind=link}
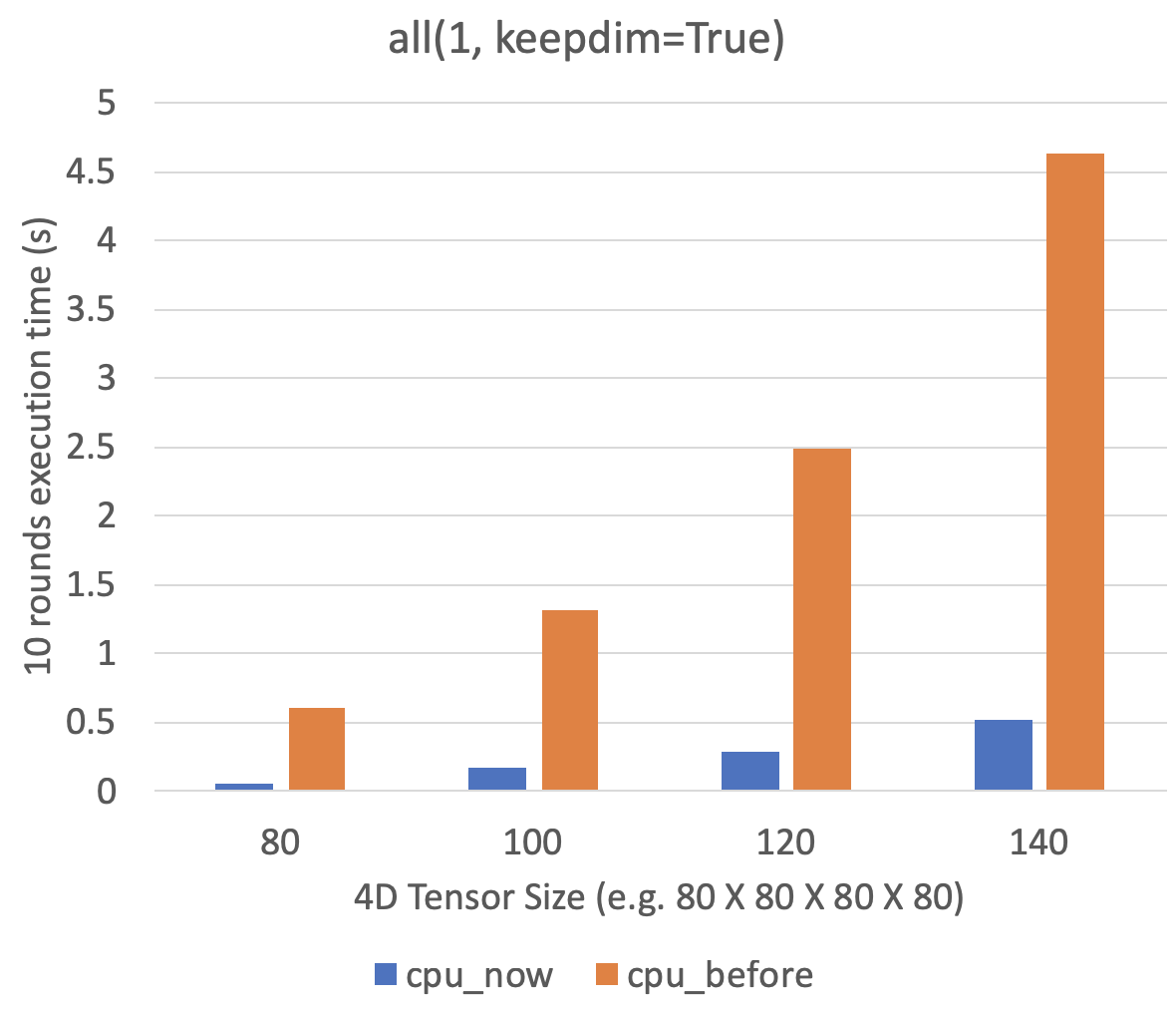{kind=link}
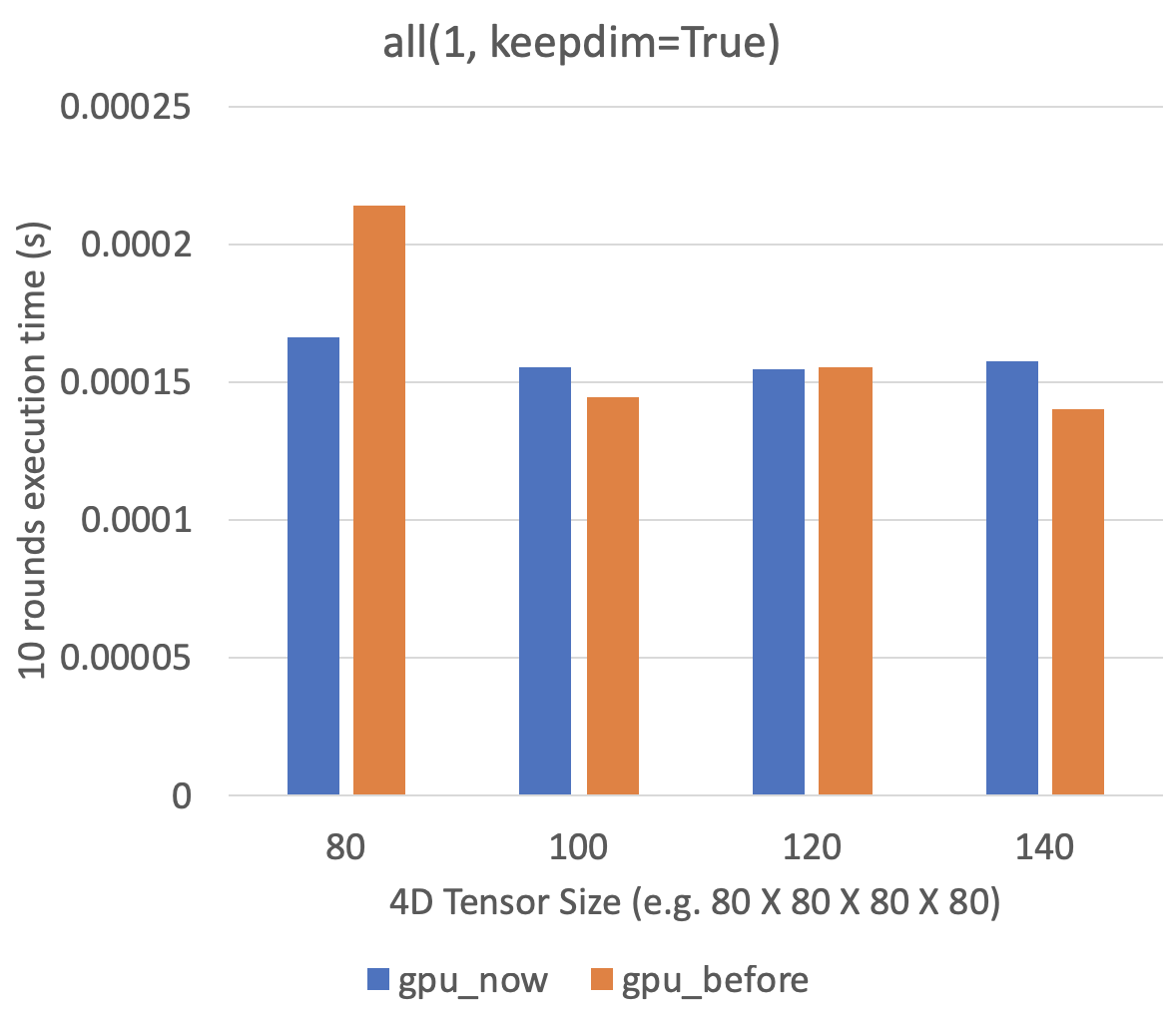{kind=link}
{kind=link}