Previously the change to aten/src/ATen/native/LossNLL.cpp eventually resulted in a double / SymInt division, which ended up calling the int64_t / SymInt overload, truncating the double (bad!) By adding overloads for all the int/float types, we avoid this situation from happening in the future.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100008
Approved by: https://github.com/albanD
This is a mirror PR of D45339293
Summary:
These tests cause the following errors internally with unknown reason:
```
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adam'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adamw'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_sgd'
```
Commenting these tests out to unblock other PRs.
Test Plan: Sandcastle
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100215
Approved by: https://github.com/wz337, https://github.com/fduwjj
There's a longstanding, well known mutability bug in dynamo, https://github.com/pytorch/pytorch/issues/93610 (and more issues, but this is the one I had at hand).
Ops that do in place mutation of tensors will mutate their corresponding FakeTensors.
So, for example, if you do `t_` on a tensor, you will reverse its strides. This, in turn, means that the FakeTensors strides are now also reversed, say, if you are trying to torch.compile:
```
class F(torch.nn.Module):
def forward(self, x, y):
x = x.t_()
y = y.t_()
return (x + y,)
```
However, we recently introduced accessing the fake_tensor memo/cache to get the symbolic shape values for sizes and strides during guard installation time.
This means that tensors captured with a given size and stride, say, for x above, size:(3,3) stride:(3, 1), will get their memo updates to size(3, 3), stride(1, 3). Now, whenever you access this value for anything, it reflects it's current state in the tracing, as opposed to the state at which we initially started tracing on.
This causes us to produce guards that are never valid, for the example above, that `x.stride()[0] == 3`.
The solution is to not allow mutation to affect the fake tensors we use as source of truth here. We can do this by forcing a clone of the fake tensor at builder time, and storing that as the source of truth for our dynamic sizes and strides during guard installation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100128
Approved by: https://github.com/ezyang
When use_orig_param is True and sharding is NO_SHARD, parameters and states are not flattened, so optimizer states should not be flattened as well. The unit test will fail without the fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100189
Approved by: https://github.com/awgu
The input tensor of the RNN forward must be the same type as the weights.
While passing tensor of type long the error is:
`RuntimeError: expected scalar type Long but found Float`
Which is misleading because it said to convert Something to Long, but the correct solution is to convert the input to Float (Which is the type of the weights).
The new error:
`RuntimeError: input must have the type torch.float32, got type torch.int64`
Is correct and more verbose
Fixes#99998
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100100
Approved by: https://github.com/drisspg
Fixes [#82206](https://github.com/pytorch/pytorch/issues/82206)
When executing a `ShardedGradScaler` step in the context of `cpu_offload`, [the function](ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L151-L152)) `_foreach_non_finite_check_and_unscale_cpu_` is grindingly slow. This issue is due to the elementwise op dispatching/redispatching/execution that is engendered by the current approach to gradient tensor validation:
ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L159-L163)
The subsequent `isinf` and `isnan` checks with associated `any` checks result in unscalable elementwise op dispatches:
ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L173-L181)
This inefficency is of course hidden in the current FSDP tests given their (appropriately) trivial parameter dimensionality. In the perf analysis below, the example test configures only the final `Linear(4, 8)` module parameters to require grad, so there are 40 elements to iterate through. However, if one increases the dimensionality to a still-modest 320008 elements (changing the final module to `Linear(40000,8)`), the execution time/cpu cost of the test is dominated by the elementwise op dispatching/redispatching/execution of the `any` validation ops in this function.
To characterize the current behavior, I use a slightly modified version of an existing `ShardedGradScaler` test [^1]. The following modifications to the test are made to allow the analysis:
1. Run just `CUDAInitMode.CUDA_BEFORE` for clarity instead of additional scenarios
2. Increase the final module to `Linear(40000, 8)` (along with modifying the preceding module to make the dimensions work) ,
3. For the cProfile run (but not valgrind or perf) the test runs just a single [`_train_for_several_steps`](ecd2c71871/torch/testing/_internal/common_fsdp.py (L926-L934)) step per rank (instead of 2 steps)
4. I temporarily reduce `init_scale` further to ensure we don't hit any `infs`, short-circuiting our analysis
### Current behavior
The most relevant call subgraph:
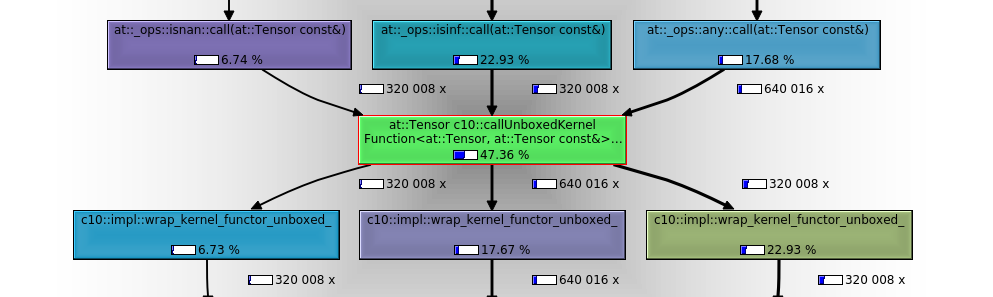
Note that:
1. Instead of dispatching to the relevant autograd op and then redispatching to the relevant CPU op implementation 8 times per test, (2 train steps x 2 any calls per parameter per step x 2 orig parameters) we (I believe unnecessarily) call the relevant dispatch flow elementwise, so 640016 times! (only 1 node in this trace so 320008 elements/2 X 2 train steps x 2 calls per element per step).
2. Nearly 50% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (320008 execs), `isinf` (320008 execs) and `any` (640016 execs) calls.
3. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) are below to give one a sense of the relative dispatch and op execution cost in an elementwise context[^3].


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_8wa9uw39.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 20.159 20.159 66.805 66.805 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
160004 18.427 0.000 18.427 0.000 {built-in method torch.isinf}
160004 6.026 0.000 6.026 0.000 {built-in method torch.isnan}
```
We see that a single step of the scaler runs for more than a minute. Though there is non-trivial cprofile overhead, we can infer from this that per-element op dispatches/executions are on the order of a 100ns.
On the order of 100 nanoseconds per dispatch is acceptable if we're using typical tensor access patterns, but if we're dispatching each element for each op, obviously everything is going to come to a grinding halt for many practical use cases.
(Given the cost of this function is currently O(n) in the number of gradient elements, feel free to set `TORCH_SHOW_DISPATCH_TRACE=1` if you want to make this function cry 🤣)
I've attached a flamegraph at the bottom of the PR[^2] that more intuitively demonstrates the manner and extent of resource consumption attributable to this function with just a modest number of gradient elements.
### After the loop refactor in this PR:
The most relevant call subgraph:

Note that:
1. Less than 0.4% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (4 execs), `isinf` (4 execs) and `any` (8 execs) calls (versus ~50% and 320008, 320008, 640016 respectively above)
2. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) reflect far less overhead (of secondary importance to item number 1)


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_pfap7nwk.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.013 0.013 0.109 0.109 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
2 0.022 0.011 0.022 0.011 {built-in method torch.isinf}
2 0.018 0.009 0.018 0.009 {built-in method torch.isnan}
```
We can see our function runtime has dropped from more than a minute to ~100ms.
### Assumptions associated with this loop refactor:
The key assumptions here are:
1. The grads are always on CPU in this function so any MTA-safe constraints ([`can_use_fast_route`](efc3887ea5/aten/src/ATen/native/cuda/AmpKernels.cu (L110-L111)) relating to the relevant CUDA kernel path selection, i.e. slower `TensorIterator` gpu kernel vs `multi_tensor_apply_kernel`) do not apply in this context
2. We've already filtered by dtype and device and can assume the presence of a single CPU device. Unless manually creating separate CPU devices with manually set non-default indexes (which I don't think FSDP supports and should be validated prior to this function), device equality should always be `True` for `cpu` type devices so we should just need to check that the current device is of `cpu` type. [^4].

[^1]: `TestShardedGradScalerParityWithDDP.test_fsdp_ddp_parity_with_grad_scaler_offload_true_none_mixed_precision_use_orig_params` test in `test/distributed/fsdp/test_fsdp_sharded_grad_scaler.py`
[^2]: Note the native frame stacks for `torch::autograd::THPVariable_isinf`, `torch::autograd::THPVariable_isnan`, `torch::autograd::THPVariable_any` in particular.
[^3]: There's more `TensorIterator` etc. setup overhead further up the stack beyond `structured_any_all_out`, but roughly speaking
[^4]: Device equality is based on [type and index combination](efc3887ea5/c10/core/Device.h (L47-L51)), CPU device type is -1 by default (`None` on the python side) and is intended to [always be 0](cf21240f67/c10/core/Device.h (L29)) if set explicitly. Though technically, unless in debug mode, this constraint isn't [actually validated](bb4e9e9124/c10/core/Device.h (L171-L184)), so one can actually manually create separate `cpu` devices with invalid indices. I suspect it's safe to ignore that potential incorrect/unusual configuration in this context but let me know if you'd like to add another `cpu` device equality check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100108
Approved by: https://github.com/awgu
This pr makes summary of dimension constraints actionable. Before the pr, it will print:
```
torch.fx.experimental.symbolic_shapes: [WARNING] Summary of dimension constraints:
The following dimensions have been specialized and CANNOT be dynamic.
NOTE: Specializations will happen by default with `assume_static_by_default=True`.
L['c'].size()[1] == 3
L['a'].size()[2] == 3
L['a'].size()[1] == 3
L['b'].size()[2] == 2
L['b'].size()[1] == 2
L['c'].size()[2] == 3
The following dimensions CAN be dynamic.
You can use the following code to specify the constraints they must satisfy:
'''
constraints=[
dynamic_dim(L['c'], 0) == dynamic_dim(L['a'], 0),
2 <= dynamic_dim(L['b'], 0),
2 <= dynamic_dim(L['a'], 0),
]
'''
```
Users need to initialize the L environment manually and copy the constraints over. After the pr, we have:
```
[2023-04-26 05:43:12,849] torch._dynamo.eval_frame: [WARNING] Summary of dimension constraints:
The following dimensions have been specialized and CANNOT be dynamic.
NOTE: Specializations will happen by default with `assume_static_by_default=True`.
'''
def specializations(a, b, c):
return (a.size()[2] == 3 and
c.size()[1] == 3 and
a.size()[1] == 3 and
c.size()[2] == 3 and
b.size()[2] == 2 and
b.size()[1] == 2)
'''
The following dimensions CAN be dynamic.
You can use the following code to specify the constraints they must satisfy:
'''
def specify_constraints(a, b, c):
return [
2 <= dynamic_dim(b, 0),
dynamic_dim(c, 0) == dynamic_dim(a, 0),
2 <= dynamic_dim(a, 0),
]
'''
```
, where dynamic_constraints has the same input signature as users code. This allow users to copy-paste and run the code to generate the constraints before exporting as shown below:
```
def specify_constraints(a, b, c):
return [
2 <= dynamic_dim(b, 0),
dynamic_dim(c, 0) == dynamic_dim(a, 0),
2 <= dynamic_dim(a, 0),
]
torch._dynamo.export(my_dyn_fn, x, y, z, constraints=specify_constriants(x, y, z))
```
Implementation-wise, this pr also
1. changes shape_env.produce_guards to produce_guards_and_constraints,
2. adds contraints_export_fn hooks,
The purpose is to surface the DimConstraints to dynamo.export, where we could reliably get the original function's signature.
The alternative to the above is to get the function signature before creating SHAPE_ENV guard (https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/output_graph.py#L227) and pass it to DimConstraints, but I couldn't recover the signature before creating SHAPE_ENV because the frame's f_globals/locals don't contain the original function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100103
Approved by: https://github.com/guangy10, https://github.com/tugsbayasgalan
Talked to @zou3519 and @ezyang on what the right UX is: tentatively, adding a new dynamo backend is cheap and simple, so it seems worth doing. And longer term, we agreed (?) that it's worth seeing if we can get custom ops sanity asserts to run more automatically, instead of needing a separate backend.
Side comment: that actually seems tough: the mode detects secret mutations by cloning every input to every op, running the op, and checking that the data matches between the real input and the cloned input. So I doubt we'll be able to make that behavior always-on? It would need some config at least.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99744
Approved by: https://github.com/albanD, https://github.com/ezyang, https://github.com/zou3519
Split existing 4 hour scheduled into two 8 hour ones
And schedule x86 MacOS test every 8 hours and exclude them from leak
checks
Schedule iOS tests every 8 hours and exclude them from leak-checks as
well
Remove IOS metal job, as it is already tested by ARM64 MPS job as well
as x86 and arm64 vanilla jobs, as they never caught any regressions in
last 60 days, based on data from running the following query on RockSet:
```sql
SELECT started_at,
DATE_DIFF(
'MINUTE',
PARSE_TIMESTAMP_ISO8601(started_at),
PARSE_TIMESTAMP_ISO8601(completed_at)
) as duration,
conclusion, name, html_url, torchci_classification
FROM commons.workflow_job
WHERE
workflow_name = 'periodic' and
name like 'ios-12% % build (default, 1, 1, macos-12)' and
url like 'https://api.github.com/repos/pytorch/pytorch/%'
and conclusion = 'failure'
order by started_at desc, run_id;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100182
Approved by: https://github.com/PaliC, https://github.com/huydhn
On top of #95849 this PR is trying to handle the special case when dealing with numpy.
Consider the following example:
```
def f(x: torch.Tensor) -> np.ndarray:
a = x.numpy()
return a.T
```
In previous PR this will error out because we translate `a.T` to be a method call on `torch_np.ndarray.T` which is also a `torch_np.ndarray`.
This PR handles this case, by conditionally converting a `torch_np.ndarray` to `np.ndarray` before returning, to match the original behavior.
The compiled version will be:
```
def f(x):
___tmp_0 = __compiled_fn_0(x)
if isinstance(___tmp_0, torch_np.ndarray):
return ___tmp_0.tensor.numpy()
else:
return ___tmp_0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99560
Approved by: https://github.com/jansel, https://github.com/yanboliang
Issue: #93684
# Problem
Reduce graph breaks when dynamo compiles python functions containing numpy functions and ndarray operations.
# Design (as I know it)
* Use torch_np.ndarray(a wrapper of tensor) to back a `VariableTracker`: `NumpyTensorVariable`.
* Translate all attributes and methods calls, on ndarray, to torch_np.ndarray equivalent.
This PR adds `NumpyTensorVariable` and supports:
1. tensor to ndarray, ndarray to tensor
2. numpy functions such as numpy.meshgrid()
3. ndarray attributes such as `itemsize`, `stride`
Next PR will handle returning `np.ndarray` and add support for ndarray methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95849
Approved by: https://github.com/ezyang
@wconstab As we discussed last Friday, I added the unit test for explicitly calling __call__ and added comment to explain why we redirecting ```UserMethodVariable.call_function``` to ```NNModuleVariable.call_method``` for a certain case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100146
Approved by: https://github.com/wconstab
This adds helpers that replace tritons `minimum`, `maximum`, `min` and
`max` with the correct NaN prrpagation. I also removed
`ops.int_minimum` in favor of `ops.minimum` because we can just omit
the nan-checks by checking the dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99881
Approved by: https://github.com/ngimel
This changes codegen of `torch.prod` from:
```python
tl.reduce(tmp2, 1, _prod_accumulate)[:, None]
```
where `_prod_accumulate` is defined elsewhere, to
```python
triton_helpers.prod(tmp2, 1)[:, None]
```
A quirk I uncovered though is that `TritonCodeCache` breaks if you
define any new symbol beginning with `triton_`, since it assumes that
must be the kernel name. Instead, I've made the kernel name an
explicit argument to `async_compile.triton` so it doesn't have to guess.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99880
Approved by: https://github.com/ngimel
Add use_local_synchronization argument to new_group.
When this argument is True, is change new_group to do a store_barrier only on the ranks that are park of the group and not the whole cluster.
This addressess both scalability and composability problems associated with new_group.
Fixes#81291.
This is relanding #84224
As part of the original PR I did a quick benchmark of creating 3 PGs per rank using both functions and perf is the following:
new_group use_local_synchronization=False:
| World Size | Time (in secs) |
| --- | ----------- |
| 4 | 0.12 |
| 8 | 0.25 |
| 16 | 0.51 |
| 32 | 0.87 |
| 64 | 1.50 |
| 128 | 2.87 |
new_group use_local_synchronization=True:
| World Size | Time (in secs) |
| --- | ----------- |
| 4 | 0.05 |
| 8 | 0.04 |
| 16 | 0.03 |
| 32 | 0.03 |
| 64 | 0.04 |
| 128 | 0.04 |
Scaling for `use_local_synchronization=False` is sub linear because the number of process groups created as a multiple of world_size decreases as we go up. It's 6 with world_size 4 and 192 with world_size 128.
Scaling for `use_local_synchronization=True` is constant as the number of store barriers executed per rank remains constant at 3.
Setup:
1 AWS host, backend gloo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99931
Approved by: https://github.com/xw285cornell
The new minifier script looks like this:
```
import torch._dynamo.repro.after_aot
reader = torch._dynamo.repro.after_aot.InputReader(save_dir='/tmp/tmpcsngx39e')
buf0 = reader.storage('e2b39c716c0d4efb9fa57375a3902b9dab666893', 16)
t0 = reader.tensor(buf0, (4,))
args = [t0]
mod = make_fx(Repro(), tracing_mode='real')(*args)
```
The real tensor data is stored in the storages folder of the checkpoint dump directory. If you delete this folder / it is otherwise missing, we will transparently fall back to generating random data like before. The tensors are serialized using content store from #99809, which means each storage is content-addressed and we will automatically deduplicate equivalent data (which is useful if you keep dumping out, e.g., your parameters.) We don't use the tensor serialization capability from content store, instead all of the tensor metadata is stored inline inside the repro script (so that everything is in one file if you lose the checkpointed tensors).
We also add a stable_hash option to content store, where we use a slow SHA-1 sum on the data in CPU side to compute a hash that is stable across systems with the same endianness.
Out of rage, I also added support for Dtype.itemsize property access.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99834
Approved by: https://github.com/voznesenskym
Make traceable collectives work with torchdynamo,
bypassing problems with tracing the AsyncTensor subclass.
Accept a suboptimal solution for now, and optimize it later.
For now, wait happens immediately, which generally forces an early sync.
Later, find a way either in dynamo or AOT stack to handle
AsyncCollectiveTensor to get the wait in the optimal place.
Note on implementation:
- Dynamo traces 'user-level' fc apis that are designed to behave differently
in eager vs compiled. In eager, there will be work-obj registration and
a wrapper subclass will insert a 'wait' call at the appropriate time.
In compile/trace mode, wait will be immetiately called, and work obj
registration is required to be handled by the compile backend at runtime.
- Dynamo needs to trace into some of the helper functions in the 'user-level'
api, such as '_expand_group' which is essentially a constant transformation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94440
Approved by: https://github.com/kumpera
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}