This PR is a copy of https://github.com/pytorch/pytorch/pull/90849 that merge was reverted.
The PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
`torch.sparse.check_sparse_tensor_invariants` class provides different ways to enable/disable the invariant checking.
`torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR fixes https://github.com/pytorch/pytorch/issues/90833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92094
Approved by: https://github.com/cpuhrsch
#75854
A naive attempt at working around the limitations of using a single 64-bit integer to pack `stream_id`, `device_index`, and `device_type`.
Stills needs sanity checks, testing, and minimization of BC-breaking changes.
Currently a Holder for the `StreamData3` struct is used for `IValue` compatibility. While doing this seems to work for `ivalue.h` and `ivalue_inl.h`, this doesn't seem to be naively working for the JIT CUDA stream wrapper? (Something about ambiguous calls if an `intrusive_ptr` to `c10::ivalue::StreamData3Holder` is used as the return type for `pack()`. It turns out that the methods required to access the fields for rematerializing a CUDA Stream are basically already present anyway, so `pack` is simply removed in the wrapper for now and the methods to access the required fields are called directly.
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81596
Approved by: https://github.com/ezyang
This PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
- `torch.enable_check_sparse_tensor_invariants` and `torch.is_check_sparse_tensor_invariants_enabled` functions to globally enable/disable the invariant checks and to retrieve the state of the feature, respectively
- `torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR also fixes https://github.com/pytorch/pytorch/issues/90833
# Main issue
*The following content is outdated after merging the PRs in this ghstack but kept for the record.*
The importance of this feature is that when enabling the invariants checks by default, say, via
<details>
```
$ git diff
diff --git a/torch/__init__.py b/torch/__init__.py
index c8543057c7..19a91d0482 100644
--- a/torch/__init__.py
+++ b/torch/__init__.py
@@ -1239,3 +1239,8 @@ if 'TORCH_CUDA_SANITIZER' in os.environ:
# Populate magic methods on SymInt and SymFloat
import torch.fx.experimental.symbolic_shapes
+
+# temporarily enable sparse tensor arguments validation in unsafe
+# constructors:
+
+torch._C._set_check_sparse_tensor_invariants(True)
```
</details>
a massive number of test failures/errors occur in test_sparse_csr.py tests:
```
$ pytest -sv test/test_sparse_csr.py
<snip>
==== 4293 failed, 1557 passed, 237 skipped, 2744 errors in 69.71s (0:01:09) ====
```
that means that we are silently constructing sparse compressed tensors that do not satisfy the sparse tensor invariants. In particular, the following errors are raised:
```
AssertionError: "resize_as_sparse_compressed_tensor_: self and src must have the same layout" does not match "expected values to be a strided and contiguous tensor"
RuntimeError: CUDA error: device-side assert triggered
RuntimeError: `col_indices[..., crow_indices[..., i - 1]:crow_indices[..., i]] for all i = 1, ..., nrows are sorted and distinct along the last dimension values` is not satisfied.
RuntimeError: expected col_indices to be a strided and contiguous tensor
RuntimeError: expected row_indices to be a strided and contiguous tensor
RuntimeError: expected values to be a strided and contiguous tensor
RuntimeError: for_each: failed to synchronize: cudaErrorAssert: device-side assert triggered
RuntimeError: tensor dimensionality must be sum of batch, base, and dense dimensionalities (=0 + 2 + 0) but got 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90849
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
Continuation of #79979.
Fixes#79161
This PR does the following:
* Expands the `parametrize_fn()` signature from returning a 3-tuple of `(test, test_name, param_kwargs)` to returning a 4-tuple of `(test, test_name, param_kwargs, decorator_fn)`. Expected signature for the addition is `decorator_fn(param_kwargs) -> List[decorator]` i.e. given the full set of test params, return a list of decorators to apply.
* `modules`, `ops`, and `parametrize` now fit the new signature, returning `decorator_fn`s instead of applying decorators themselves.
* `instantiate_parametrized_tests()` and `instantiate_device_type_tests()` now call the returned `decorator_fn`, passing in the full set of `param_kwargs` (after composition + `device` / `dtype` additions) and applying the returned decorators.
* Composing multiple `parametrize_fn`s also composes the corresponding `decorator_fn`s; the composed `decorator_fn` simply concatenates the decorator lists returned by the constituents.
* Expands `DecorateInfo.is_active` to support callables:
```python
DecorateInfo(
unittest.expectedFailure, "TestOps", "test_python_ref_executor",
device_type='cuda', active_if=lambda params: params['executor'] == 'nvfuser'
),
```
* Adds several tests to `test/test_testing.py` ensuring proper decoration using `@parametrize`, `@modules`, and `@ops`.
* (minor) Fixes a couple `ModuleInfo` naming oddities uncovered during testing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91658
Approved by: https://github.com/malfet
I made an important mistake here when thinking `not result.skipped` mean that the current test wasn't skipped.
Similar to `result.failures` or `result.errors`, `result.skipped` is that it's a list including all the skipped messages so far in the test suite (https://docs.python.org/3/library/unittest.html#unittest.TestResult). As such, the correct way to check if the current test was skipped is to compare `skipped_before` and `len(result.skipped)` after running the test in the same way as failures and errors are handled. If they are the same, the test isn't skipped.
### Testing
`python test/run_test.py -i test_autograd --verbose` to confirm that the disabled test `test_profiler_seq_nr` is run 50 times always in rerun mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90888
Approved by: https://github.com/clee2000
#85303 added a patch to `torch.testing.assert_close` to handle `torch.storage.TypedStorage`'s. This change is not reflected in the docs and is not intended for the public API. This PR removes the patch ones again and moves the behavior to `TestCase.assertEqual` instead. Meaning, `TypedStorage`'s are again not supported by the public API, but the behavior is the same for all internal use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89557
Approved by: https://github.com/kurtamohler, https://github.com/mruberry
This PR extends the `Tensor.to_sparse()` method to `Tensor.to_sparse(layout=None, blocksize=None)` in a BC manner (`layout=None` means `layout=torch.sparse_coo`).
In addition, the PR adds support for the following conversions:
- non-hybrid/hybrid COO tensor to CSR or CSC or a COO tensor
- short, bool, byte, char, bfloat16, int, long, half CSR tensor to a BSR tensor
and fixes the following conversions:
- hybrid COO to COO tensor
- non-batch/batch hybrid BSR to BSR or BSC tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89502
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
The idea is to add a custom handler to Functionalize key in Python
dispatcher that runs the functionalized version along side a non
functionalized version, and checks that their outputs agree in the
end. (Technically, for metadata mutation we should also check the
inputs, but for now we're relying on those functions returning self.)
I turned this on for test_functionalize.py (new TestCrossRefFunctionalize)
and found a bunch of failures that look legit.
This probably doesn't interact that nicely if you're also tracing at
the same time, probably need more special logic for that (directly,
just disabling tracing for when we create the nested fake tensor mode,
but IDK if there's a more principled way to organize this.)
There are some misc fixups which I can split if people really want.
- xfail_inherited_tests moved to test common_utils
- Bindings for _dispatch_tls_set_dispatch_key_included,
_dispatch_tls_is_dispatch_key_included and _functionalization_reapply_views_tls
- Type stubs for _enable_functionalization, _disable_functionalization
- all_known_overloads utility to let you iterate over all OpOverloads
in all namespaces. Iterator support on all torch._ops objects to let
you iterate over their members.
- suspend_functionalization lets you temporarily disable functionalization mode
in a context
- check_metadata_matches for easily comparing outputs of functions and see
if they match (TODO: there are a few copies of this logic, consolidate!)
- _fmt for easily printing the metadata of a tensor without its data
- _uncache_dispatch for removing a particular dispatch key from the cache,
so that we force it to regenerate
- check_significant_strides new kwarg only_cuda to let you also do stride
test even when inputs are not CUDA
- Functionalize in torch._C.DispatchKey
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89498
Approved by: https://github.com/malfet
When looking into Rockset data for disabled test unittest, for example `testAdd`, I see that it's re-run only 3 times instead of 50+ times as expected under rerun-disabled -test mode
```
[
{
"name": "testAdd",
"classname": "TestLazyReuseIr",
"filename": "lazy/test_reuse_ir.py",
"flaky": false,
"num_green": 3,
"num_red": 0
}
]
```
It turns out that I made a mistake mixing `RERUN_DISABLED_TESTS` and `report_only` into `(RERUN_DISABLED_TESTS or report_only) and num_retries_left < MAX_NUM_RETRIES` in https://github.com/pytorch/pytorch/pull/88646. The retrying logic for successful tests under rerun-disabled-tests mode is never executed because num_retries_left would be equal to MAX_NUM_RETRIES (not smaller) if the very first run successes. Thus, the sample test `testAdd` finishes right away (1 success count)
* `report_only` and `RERUN_DISABLED_TESTS` are 2 different things and shouldn't be mixed together. RERUN_DISABLED_TESTS has the higher priority.
* We also don't want to retry skipped tests under rerun-disabled-tests mode because they are only skipped due to `check_if_enable` check `Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run`
### Testing
* CI https://github.com/pytorch/pytorch/actions/runs/3518228784 generates https://gha-artifacts.s3.amazonaws.com/pytorch/pytorch/3518228784/1/artifact/test-reports-test-default-4-4-linux.4xlarge.nvidia.gpu_9627285587.zip in which `testAdd` is correctly called multiple times and `TestLazyReuseIr` is skipped correctly
* Locally
```
# export CI=1
# export PYTORCH_RETRY_TEST_CASES=1
# export PYTORCH_OVERRIDE_FLAKY_SIGNAL=1
# export PYTORCH_TEST_RERUN_DISABLED_TESTS=1
$ python test/run_test.py --verbose -i lazy/test_reuse_ir
Ignoring disabled issues: []
Selected tests:
lazy/test_reuse_ir
Prioritized test from test file changes.
reordering tests for PR:
prioritized: []
the rest: ['lazy/test_reuse_ir']
Downloading https://raw.githubusercontent.com/pytorch/test-infra/generated-stats/stats/slow-tests.json to /Users/huydo/Storage/mine/pytorch/test/.pytorch-slow-tests.json
Downloading https://raw.githubusercontent.com/pytorch/test-infra/generated-stats/stats/disabled-tests-condensed.json to /Users/huydo/Storage/mine/pytorch/test/.pytorch-disabled-tests.json
parallel (file granularity) tests:
lazy/test_reuse_ir
serial (file granularity) tests:
Ignoring disabled issues: []
Ignoring disabled issues: []
Running lazy/test_reuse_ir ... [2022-11-21 13:21:07.165877]
Executing ['/Users/huydo/miniconda3/envs/py3.9/bin/python', '-bb', 'lazy/test_reuse_ir.py', '-v', '--import-slow-tests', '--import-disabled-tests', '--rerun-disabled-tests'] ... [2022-11-21 13:21:07.166279]
Expand the folded group to see the log file of lazy/test_reuse_ir
##[group]PRINTING LOG FILE of lazy/test_reuse_ir (/Users/huydo/Storage/mine/pytorch/test/test-reports/lazy-test_reuse_ir_6cf_dxa1)
Running tests...
----------------------------------------------------------------------
Test results will be stored in test-reports/python-unittest/lazy.test_reuse_ir
testAdd (__main__.TestLazyReuseIr) ... ok (1.215s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 50
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 49
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 48
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 47
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 46
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 45
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 44
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 43
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 42
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 41
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 40
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 39
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 38
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 37
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 36
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 35
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 34
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 33
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 32
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 31
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 30
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 29
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 28
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 27
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 26
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 25
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 24
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 23
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 22
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 21
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 20
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 19
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 18
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 17
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 16
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 15
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 14
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 13
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 12
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 11
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 10
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 9
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 8
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 7
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 6
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 5
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 4
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 3
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 2
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 1
ok (0.001s)
testAddSub (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 0
skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
testAddSubFallback (__main__.TestLazyReuseIr) ... skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
testBatchNorm (__main__.TestLazyReuseIr) ... skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
----------------------------------------------------------------------
Ran 54 tests in 1.264s
OK (skipped=3)
```
Here is the sample rockset query
```
WITH added_row_number AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY name, classname, filename ORDER BY _event_time DESC) AS row_number
FROM
commons.rerun_disabled_tests
)
SELECT
name,
classname,
filename,
flaky,
num_green,
num_red
FROM
added_row_number
WHERE
row_number = 1
AND name = 'testAdd'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89454
Approved by: https://github.com/clee2000
Print unexpected success as XPASS. I will submit a PR to test-infra so that the log classifier can find these
Ex: https://github.com/pytorch/pytorch/actions/runs/3466368885/jobs/5790424173
```
test_import_hipify (__main__.TestHipify) ... ok (0.000s)
test_check_onnx_broadcast (__main__.TestONNXUtils) ... ok (0.000s)
test_prepare_onnx_paddings (__main__.TestONNXUtils) ... ok (0.000s)
test_load_standalone (__main__.TestStandaloneCPPJIT) ... ok (16.512s)
======================================================================
XPASS [4.072s]: test_smoke (__main__.TestCollectEnv)
----------------------------------------------------------------------
----------------------------------------------------------------------
Ran 31 tests in 24.594s
FAILED (skipped=7, unexpected successes=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89020
Approved by: https://github.com/huydhn, https://github.com/seemethere
Rerun all disabled test to gather their latest result so that we can close disabled tickets automatically. When running under this mode (RERUN_DISABLED_TESTS=true), only disabled tests are run while the rest are skipped `<skipped message="Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run" type="skip"/>`
The logic is roughly as follows, the test runs multiple times (n=50)
* If the disabled test passes, and it's flaky, do nothing because it's still flaky. In the test report, we'll see the test passes with the following skipped message:
```
<testcase classname="TestMultiprocessing" file="test_multiprocessing.py" line="357" name="test_fs" time="0.000" timestamp="0001-01-01T00:00:00">
<skipped message="{"flaky": True, "num_red": 4, "num_green": 0, "max_num_retries": 3, "rerun_disabled_test": true}" type="skip"/>
</testcase>
```
* If the disabled test passes every single time, and it is not flaky anymore, mark it so that it can be closed later. We will see the test runs and passes, i.e.
```
<testcase classname="TestCommonCUDA" name="test_out_warning_linalg_lu_factor_cuda" time="0.170" file="test_ops.py" />
```
* If the disabled test fails after all retries, this is also expected. So only report this but don't fail the job (because we don't care about red signals here), we'll see the test is skipped (without the `flaky` field), i.e.
```
<testcase classname="TestMultiprocessing" file="test_multiprocessing.py" line="357" name="test_fs" time="0.000" timestamp="0001-01-01T00:00:00">
<skipped message="{"num_red": 4, "num_green": 0, "max_num_retries": 3, "rerun_disabled_test": true}" type="skip"/>
</testcase>
```
This runs at the same schedule as `mem_leak_check` (daily). The change to update test stats, and (potentially) grouping on HUD will come in separated PRs.
### Testing
* pull https://github.com/pytorch/pytorch/actions/runs/3447434434
* trunk https://github.com/pytorch/pytorch/actions/runs/3447434928
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88646
Approved by: https://github.com/clee2000
Hybrid sparse CSR tensors can currently not be compared to strided ones since `.to_dense` does not work:
```py
import torch
from torch.testing._internal.common_utils import TestCase
assertEqual = TestCase().assertEqual
actual = torch.sparse_csr_tensor([0, 2, 4], [0, 1, 0, 1], [[1, 11], [2, 12] ,[3, 13] ,[4, 14]])
expected = torch.stack([actual[0].to_dense(), actual[1].to_dense()])
assertEqual(actual, expected)
```
```
main.py:4: UserWarning: Sparse CSR tensor support is in beta state. If you miss a functionality in the sparse tensor support, please submit a feature request to https://github.com/pytorch/pytorch/issues. (Triggered internally at ../aten/src/ATen/SparseCsrTensorImpl.cpp:54.)
actual = torch.sparse_csr_tensor([0, 2, 4], [0, 1, 0, 1], [[1, 11], [2, 12] ,[3, 13] ,[4, 14]])
Traceback (most recent call last):
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 1098, in assert_equal
pair.compare()
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 619, in compare
actual, expected = self._equalize_attributes(actual, expected)
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 706, in _equalize_attributes
actual = actual.to_dense() if actual.layout != torch.strided else actual
RuntimeError: sparse_compressed_to_dense: Hybrid tensors are not supported
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "main.py", line 10, in <module>
assertEqual(actual, expected)
File "/home/philip/git/pytorch/torch/torch/testing/_internal/common_utils.py", line 2503, in assertEqual
msg=(lambda generated_msg: f"{generated_msg}\n{msg}") if isinstance(msg, str) and self.longMessage else msg,
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 1112, in assert_equal
) from error
RuntimeError: Comparing
TensorOrArrayPair(
id=(),
actual=tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([[ 1, 11],
[ 2, 12],
[ 3, 13],
[ 4, 14]]), size=(2, 2, 2), nnz=4,
layout=torch.sparse_csr),
expected=tensor([[[ 1, 11],
[ 2, 12]],
[[ 3, 13],
[ 4, 14]]]),
rtol=0.0,
atol=0.0,
equal_nan=True,
check_device=False,
check_dtype=True,
check_layout=False,
check_stride=False,
check_is_coalesced=False,
)
resulted in the unexpected exception above. If you are a user and see this message during normal operation please file an issue at https://github.com/pytorch/pytorch/issues. If you are a developer and working on the comparison functions, please except the previous error and raise an expressive `ErrorMeta` instead.
```
This adds a temporary hack to `TestCase.assertEqual` to enable this. Basically, we are going through the individual CSR subtensors, call `.to_dense()` on them, and stack everything back together. I opted to not do this in the common machinery, since that way users are not affected by this (undocumented) hack.
I also added an xfailed test that will trigger as soon as the behavior is supported natively so we don't forget to remove the hack when it is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88749
Approved by: https://github.com/mruberry, https://github.com/pearu
tbh at this point it might be easier to make a new workflow and copy the relevant jobs...
Changes:
* Disable cuda mem leak check except for on scheduled workflows
* Make pull and trunk run on a schedule which will run the memory leak check
* Periodic will always run the memory leak check -> periodic does not have parallelization anymore
* Concurrency check changed to be slightly more generous
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88373
Approved by: https://github.com/ZainRizvi, https://github.com/huydhn
Fixes: https://github.com/pytorch/pytorch/issues/88010
This PR does a couple things to stop slow gradcheck from timing out:
- Splits out test_ops_fwd_gradients from test_ops_gradients, and factors out TestFwdGradients and TestBwdGradients which both inherit from TestGradients, now situated in common_utils (maybe there is a better place?)
- Skips CompositeCompliance (and several other test files) for slow gradcheck CI since they do not use gradcheck
- because test times for test_ops_fwd_gradients and test_ops_gradients are either unknown or wrong, we hardcode them for now to prevent them from being put together. We can undo the hack after we see actual test times are updated. ("def calculate_shards" randomly divides tests with unknown test times in a round-robin fashion.)
- Updates references to test_ops_gradients and TestGradients
- Test files that are skipped for slow gradcheck CI are now centrally located in in run_tests.py, this reduces how fine-grained we can be with the skips, so for some skips (one so far) we still use the old skipping mechanism, e.g. for test_mps
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88216
Approved by: https://github.com/albanD
Meta tensor does a lot of work to make sure tensors "look" similar
to the original parts; e.g., if the original was a non-leaf, meta
converter ensures the meta tensor is a non-leaf too. Fake tensor
destroyed some of these properties when it wraps it in a FakeTensor.
This patch pushes the FakeTensor constructor into the meta converter
itself, so that we first create a fake tensor, and then we do various
convertibility bits to it to make it look right.
The two tricky bits:
- We need to have no_dispatch enabled when we allocate the initial meta
tensor, or fake tensor gets mad at us for making a meta fake tensor.
This necessitates the double-callback structure of the callback
arguments: the meta construction happens *inside* the function so
it is covered by no_dispatch
- I can't store tensors for the storages anymore, as that will result
in a leak. But we have untyped storage now, so I just store untyped
storages instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87943
Approved by: https://github.com/eellison, https://github.com/albanD
dynamo tests call a helper function in torch/_dynamo/test_case.py which then calls run_tests in common_utils.py so the test report path looked something like /opt/conda/lib/python3/10/site-packages/torch/_dynamo/test_case
* instead of using frame, use argv[0] which should be the invoking file
* got rid of sanitize functorch test name because theyve been moved into the test folder
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87378
Approved by: https://github.com/huydhn
I noticed that a lot of bugs are being suppressed by torchdynamo's default
error suppression, and worse yet, there's no way to unsuppress them. After
discussion with voz and soumith, we decided that we will unify error suppression
into a single option (suppress_errors) and default suppression to False.
If your model used to work and no longer works, try TORCHDYNAMO_SUPPRESS_ERRORS=1
to bring back the old suppression behavior.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87440
Approved by: https://github.com/voznesenskym, https://github.com/albanD
If an invalid platform is specified when disabling a test with flaky test bot, the CI crashes, skipping all tests that come after it.
This turns it into a console message instead. Not erroring out here since it'll affect random PRs. Actual error message should go into the bot that parses the original issue so that it can respond on that issue directly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86632
Approved by: https://github.com/huydhn
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
Fixes#85615
Currently, internal test discovery instantiates an `ArgumentParser` and adds numerous arguments to the internal parser:
f0570354dd/torch/testing/_internal/common_utils.py (L491-L500)
...
In this context, `argparse` will load [system args](b494f5935c/Lib/argparse.py (L1826-L1829)) from any external scripts invoking PyTorch testing (e.g. `vscode`).
The default behavior of `argparse` is to [allow abbreviations](b494f5935c/Lib/argparse.py (L2243-L2251)) of arguments, but when an `ArgumentParser` instance has many arguments and may be invoked in the context of potentially conflicting system args, the `ArgumentParser` should reduce the potential for conflicts by being instantiated with `allow_abbrev` set to `False`.
With the current default configuration, some abbreviations of the `ArgumentParser` long options conflict with system args used by `vscode` to invoke PyTorch test execution:
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/visualstudio_py_testlauncher.py \
--us=./test --up=test_cuda.py --uvInt=2 -ttest_cuda.TestCuda.test_memory_allocation \
--testFile=./test/test_cuda.py
>>>PYTHON-EXEC-OUTPUT
...
visualstudio_py_testlauncher.py: error: argument --use-pytest: ignored explicit argument './test'
```
The full relevant stack:
```
pytorch/test/jit/test_cuda.py, line 11, in <module>\n from torch.testing._internal.jit_utils import JitTestCase\n'\
pytorch/torch/testing/_internal/jit_utils.py, line 18, in <module>\n from torch.testing._internal.common_utils import IS_WINDOWS, \\\n'
pytorch/torch/testing/_internal/common_utils.py, line 518, in <module>\n args, remaining = parser.parse_known_args()\n'
argparse.py, line 1853, in parse_known_args\n namespace, args = self._parse_known_args(args, namespace)\n'
argparse.py, line 2062, in _parse_known_args\n start_index = consume_optional(start_index)\n'
argparse.py, line 1983, in consume_optional\n msg = _(\'ignored explicit argument %r\')\n'
```
The `argparse` [condition](b494f5935c/Lib/argparse.py (L2250)) that generates the error in this case:
```python
print(option_string)
--use-pytest
print(option_prefix)
--us
option_string.startswith(option_prefix)
True
```
It'd be nice if `vscode` didn't use two-letter options 🤦 but PyTorch testing shouldn't depend on such good behavior by invoking wrappers IMHO.
I haven't seen any current dependency on the abbreviated internal PyTorch `ArgumentParser` options so this change should only extend the usability of the (always improving!) PyTorch testing modules.
This simple PR avoids these conflicting options by instantiating the `ArgumentParser` with `allow_abbrev=False`
Thanks to everyone in the community for their continued contributions to this incredibly valuable framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85616
Approved by: https://github.com/clee2000
Fixes#85578
Currently, many test modules customize test loading and discovery via the [load_tests protocol](https://docs.python.org/3/library/unittest.html#load-tests-protocol). The salient custom behavior included (introduced with https://github.com/pytorch/pytorch/pull/13250) is to verify that the script discovering or executing the test is the same script in which the test is defined.
I believe this unnecessarily precludes the use of external tools to discover and execute tests (e.g. the vscode testing extension is widely used and IMHO quite convenient).
This simple PR retains the current restriction by default while offering users the option to disable the aforementioned check if desired by setting an environmental variable.
For example:
1. Setup a test env:
```bash
./tools/nightly.py checkout -b some_test_branch
conda activate pytorch-deps
conda install -c pytorch-nightly numpy expecttest mypy pytest hypothesis astunparse ninja pyyaml cmake cffi typing_extensions future six requests dataclasses -y
```
2. The default test collection behavior discovers 5 matching tests (only tests within `test/jit/test_cuda.py` because it doesn't alter the default `load_test` behavior:
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/testing_tools/unittest_discovery.py \
./test test_cuda.py | grep test_cuda | wc -l
5
```
3. Set the new env variable (in vscode, you would put it in the .env file)
```bash
export PYTORCH_DISABLE_RUNNING_SCRIPT_CHK=1
```
4. All of the desired tests are now discovered and can be executed successfully!
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/testing_tools/unittest_discovery.py \
./test test_cuda.py | grep test_cuda | wc -l
175
```
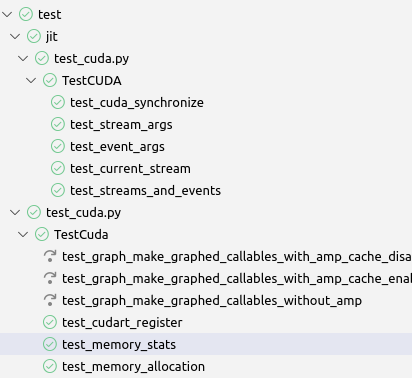
A potentially relevant note, the previous behavior of the custom `load_tests` flattened all the `TestSuite`s in each test module:
4c01c51266/torch/testing/_internal/common_utils.py (L3260-L3262)
I haven't been able to find any code that depends upon this behavior but I think retaining the `TestSuite` structure is preferable from a user perspective and likely safe (`TestSuite`s [can be executed](https://docs.python.org/3/library/unittest.html#load-tests-protocol:~:text=test%20runner%20to-,allow%20it%20to%20be%20run,-as%20any%20other) just like `TestCase`s and this is the structure [recommended](https://docs.python.org/3/library/unittest.html#load-tests-protocol:~:text=provides%20a%20mechanism%20for%20this%3A%20the%20test%20suite) by the standard python documentation).
If necessary, I can change this PR to continue flattening each test module's `TestSuite`s. Since I expect external tools using the `unittest` `discover` API will usually assume discovered `TestSuite`s to retain their structure (e.g. like [vscode](192c3eabd8/pythonFiles/visualstudio_py_testlauncher.py (L336-L349))) retaining the `testsuite` flattening behavior would likely require customization of those external tools for PyTorch though.
Thanks to everyone in the community for the continued contributions to this incredibly valuable framework!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85584
Approved by: https://github.com/huydhn
{kind=link}