This PR is part of a series of PRs to significantly speed up torch.onnx.export for models with many nodes (e.g. LLM). See #121422 for more analysis.
- As part of torch.onnx.export, a reverse look-up is made in env. This is done for each node, and this look-up costs in proportional to the graph size, which incurs and overall O(N^2) time complexity.
- A pragmatic solution is simply to keep a separate data structure to make this de facto constant time. So, this introduces a set containing all the values of env. Open to other ideas. Ideally `exist_in_env` wouldn't be needed at all, but to preserve current behavior exactly I'm not sure how that can be done.
- Resolves (4) in #121422.
- This code change and the choice of py::set looks a bit more natural on top of #123063, where the env is changed from a std::unordered_map to a py::dict.
Partially fixes#121422
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124909
Approved by: https://github.com/srikris-sridhar, https://github.com/justinchuby
This PR is part of an effort to speed up torch.onnx.export (#121422).
- This copies the shape and type from the node to the nodes that are produced by the export. However, for 1-to-N exports, which are very common, this doesn't make much sense and can give the graph in broken shape or type information. As far as I can tell, a shape inference pass is used to propagate the correct shape and type for all interemediate (and final) nodes.
- If there is a situation where this is necessary (shape inference turned off and only 1-to-1 ops are exported ??), perhaps this can be conditionally skipped. It does incur a quadratic cost. Another option is to set a global default for the metadata and
use that for all nodes that get created. Again, this meta data may not make sense for all ops and seems dangerous to do.
- Resolves (8) in #121422.
(partial fix of #121422)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123027
Approved by: https://github.com/BowenBao
### Description
This PR fixes a bug with getting module attributes during `torch.onnx.export` when `export_modules_as_functions` is used. With this fix, we can compare the LLaMA-2 models produced by the TorchScript exporter and the [Dynamo exporter](https://github.com/pytorch/pytorch/issues/104903).
### Context
When exporting LLaMA-2 from Hugging Face with `export_modules_as_functions`, the `Embedding` object does not have the `freeze` attribute.
```
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py", line 662, in forward
inputs_embeds = self.embed_tokens(input_ids)
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1519, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1558, in _call_impl
args_result = hook(self, args)
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/onnx/utils.py", line 1394, in _track_module_attributes_forward_pre_hook
setattr(module, attr_name, _get_module_attributes(module))
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/onnx/utils.py", line 1474, in _get_module_attributes
return {k: getattr(module, k) for k in annotations}
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/onnx/utils.py", line 1474, in <dictcomp>
return {k: getattr(module, k) for k in annotations}
File "/home/kvaishnavi/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1696, in __getattr__
raise AttributeError(f"'{type(self).__name__}' object has no attribute '{name}'")
AttributeError: 'Embedding' object has no attribute 'freeze'
```
To get around this issue, we can skip adding the keys in the dictionary when the object does not have the attribute.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109759
Approved by: https://github.com/BowenBao
Cap opset version at 17 for torch.onnx.export and suggest users to use the dynamo exporter. Warn users instead of failing hard because we should still allow users to create custom symbolic functions for opset>17.
Also updates the default opset version by running `tools/onnx/update_default_opset_version.py`.
Fixes#107801Fixes#107446
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107829
Approved by: https://github.com/BowenBao
### Proposal
When arg of 'keep_initializers_as_inputs' is True, it's quite possible that parameters are set by initializer of input.
Hence we should disable de-duplicate initializer optimization when 'keep_initializers_as_inputs==True'.
- [x] Update doc related to `keep_initializers_as_inputs`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96320
Approved by: https://github.com/abock, https://github.com/thiagocrepaldi
Fixes#88286, Fixes#97160
Repro:
```python
import torch
import io
from torch.utils.checkpoint import checkpoint
class A(torch.nn.Module):
# A supported module.
def __init__(self):
super(A, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
def forward(self, x):
return self.l1(x)
class B(torch.nn.Module):
# This module is not exportable to ONNX because it
# uses gradient-checkpointing. However, its two sub-module's
# are exportable, so ORTModule should be used to compute them.
def __init__(self):
super(B, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
self.a = A()
def forward(self, x):
def custom():
def custom_forward(x_):
return self.a(x_)
return custom_forward
z = self.l1(checkpoint(custom(), x))
return z
torch.onnx.export(
B(),
(torch.randn(2, 2),),
io.BytesIO(),
autograd_inlining=True
)
```
`torch.onnx.export(autograd_inlining=True)` should repro the user error as this is the original execution path.
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f0f011faee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1576, in _export
graph, params_dict, torch_out = _model_to_graph(
File "<@beartype(torch.onnx.utils._model_to_graph) at 0x7f0f01187dc0>", line 11, in _model_to_graph
File "/opt/pytorch/torch/onnx/utils.py", line 1130, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 1006, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 910, in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File "/opt/pytorch/torch/jit/_trace.py", line 1269, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/jit/_trace.py", line 128, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/opt/pytorch/torch/jit/_trace.py", line 119, in wrapper
outs.append(self.inner(*trace_inputs))
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1492, in _slow_forward
result = self.forward(*input, **kwargs)
File "repro88286.py", line 32, in forward
z = self.l1(checkpoint(custom(), x))
File "/opt/pytorch/torch/utils/checkpoint.py", line 412, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/opt/pytorch/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
RuntimeError: _Map_base::at
```
By using `autograd_inlining=False`, the export still fail with a different error because autograd inlining is not enabled:
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f6088b32ee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1615, in _export
) = graph._export_onnx( # type: ignore[attr-defined]
RuntimeError: ONNX export failed: Couldn't export Python operator CheckpointFunction
```
To allow `CheckpointFunction` into the onnx graph, `operator_export_type=torch.onnx.OperatorExportTypes.ONNX_FALLTHROUGH` flag can be added to `torch.onnx.export`, which would lead to the following ONNX graph:
```bash
Exported graph: graph(%prim::PythonOp_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu),
%l1.weight : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu),
%l1.bias : Float(2, strides=[1], requires_grad=1, device=cpu)):
%/PythonOp_output_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu) = ^CheckpointFunction[inplace=0, module="torch.utils.checkpoint", onnx_name="/PythonOp"](<function B.forward.<locals>.custom.<locals>.custom_forward at 0x7fdf9182f670>, True)(%prim::PythonOp_0), scope: __main__.B:: # /opt/pytorch/torch/autograd/function.py:506:0
%6 : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1, onnx_name="/l1/Gemm"](%/PythonOp_output_0, %l1.weight, %l1.bias), scope: __main__.B::/torch.nn.modules.linear.Linear::l1 # /opt/pytorch/torch/nn/modules/linear.py:114:0
return (%6)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104067
Approved by: https://github.com/BowenBao, https://github.com/kit1980
Merges startswith, endswith calls to into a single call that feeds in a tuple. Not only are these calls more readable, but it will be more efficient as it iterates through each string only once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96754
Approved by: https://github.com/ezyang
All this time, PyTorch and ONNX has different strategy for None in output. And in internal test, we flatten the torch outputs to see if the rest of them matched. However, this doesn't work anymore in scripting after Optional node is introduced, since some of None would be kept.
#83184 forces script module to keep all Nones from Pytorch, but in ONNX, the model only keeps the ones generated with Optional node, and deletes those meaningless None.
This PR uses Optional node to keep those meaningless None in output as well, so when it comes to script module result comparison, Pytorch and ONNX should have the same amount of Nones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84789
Approved by: https://github.com/BowenBao
Fix#82589
Why:
1. **full_check** works in `onnx::checker::check_model` function as it turns on **strict_mode** in `onnx::shape_inference::InferShapes()` which I think that was the intention of this part of code.
2. **strict_mode** catches failed shape type inference (invalid ONNX model from onnx perspective) and ONNXRUNTIME can't run these invalid models, as ONNXRUNTIME actually rely on ONNX shape type inference to optimize ONNX graph. Why we don't set it True for default? >>> some of existing users use other platform, such as caffe2 to run ONNX model which doesn't need valid ONNX model to run.
3. This PR doesn't change the original behavior of `check_onnx_proto`, but add a warning message for those models which can't pass strict shape type inference, saying the models would fail on onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83186
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi, https://github.com/jcwchen, https://github.com/BowenBao
Extend `register_custom_op` to support onnx-script local function. The FunctionProto from onnx-script is represented by custom op and inserted into ModelProto for op execution.
NOTE: I did experiments on >2GB case of a simple model with large initializers:
```python
import torch
class Net(torch.nn.Module):
def __init__(self, B, C):
super().__init__()
self.layer_norm = torch.nn.LayerNorm((B, C), eps=1e-3)
def forward(self, x):
return self.layer_norm(x)
N, B, C = 3, 25000, 25000
model = Net(B, C)
x = torch.randn(N, B, C)
torch.onnx.export(model, x, "large_model.onnx", opset_version=12)
```
And it turns out we won't get model_bytes > 2GB after `_export_onnx` pybind cpp function, as we split initializer in external files in that function, and have serialization before return the model bytes, which protobuf is not allowed to be larger than 2GB at any circumstances.
The test cases can be found in the next PR #86907 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86906
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Follow-up for #87735
Once again, because BUILD_CAFFE2=0 is not tested for ONNX exporter, one scenario slipped through. A use case where the model can be exported without aten fallback when operator_export_type=ONNX_ATEN_FALLBACK and BUILD_CAFFE2=0
A new unit test has been added, but it won't prevent regressions if BUILD_CAFFE2=0 is not executed on CI again
Fixes#87313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88504
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Update `register_custom_op_symbolic`'s behavior to _only register the symbolic function at a single version_. This is more aligned with the semantics of the API signature.
As a result of this change, opset 7 and opset 8 implementations are now seen as fallback when the opset_version >= 9. Previously any ops internally registered to opset < 9 are not discoverable by an export version target >= 9. Updated the test to reflect this change.
The implication of this change is that users will need to register a symbolic function to the exact version when they want to override an existing symbolic. They are not impacted if (1) an implementation does not existing for the op, or (2) they are already registering to the exact version for export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85636
Approved by: https://github.com/BowenBao
Update `unconvertible_ops` to create a list of unconvertible ops using the updated registry.
- Use fewer passes in the jit process instead to avoid errors during conversion in the ONNX fallback mode
- Actually check the registry to find implemented ops
- Fix type hints for `_create_jit_graph` and `_jit_pass_onnx_remove_inplace_ops_for_onnx`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85595
Approved by: https://github.com/BowenBao
`_set_opset_version` and `_set_operator_export_type` are previously deprecated. This PR decorates them with the deprecation decorator, so warnings are emitted.
- Remove usage of `_set_opset_version` and `_set_operator_export_type` in favor of setting the globals vars directly in torch.onnx internal
- Update `GLOBALS.operator_export_type`'s default to not be None to tighten types
- Remove usage of `_set_onnx_shape_inference`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85165
Approved by: https://github.com/BowenBao, https://github.com/AllenTiTaiWang
This PR create the `GraphContext` class and relays all graph methods to _C.Graph as well as implements the `g.op` method. The GraphContext object is passed into the symbolic functions in place of _C.Graph for compatibility with existing symbolic functions.
This way (1) we can type annotate all `g` args because the method is defined and (2) we can use additional context information in symbolic functions. (3) no more monkey patching on `_C.Graph`
Also
- Fix return type of `_jit_pass_fixup_onnx_controlflow_node`
- Create `torchscript.py` to house torch.Graph related functions
- Change `GraphContext.op` to create nodes in the Block instead of the Graph
- Create `add_op_with_blocks` to handle scenarios where we need to directly manipulate sub-blocks. Update loop and if symbolic functions to use this function.
## Discussion
Should we put all the context inside `SymbolicContext` and make it an attribute in the `GraphContext` class? This way we only define two attributes `GraphContext.graph` and `GraphContext.context`. Currently all context attributes are directly defined in the class.
### Decision
Keep GraphContext flatand note that it will change in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84728
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
## Summary
The change brings the new registry for symbolic functions in ONNX. The `SymbolicRegistry` class in `torch.onnx._internal.registration` replaces the dictionary and various functions defined in `torch.onnx.symbolic_registry`.
The new registry
- Has faster lookup by storing only functions in the opset version they are defined in
- Is easier to manage and interact with due to its class design
- Builds the foundation for the more flexible registration process detailed in #83787
Implementation changes
- **Breaking**: Remove `torch.onnx.symbolic_registry`
- `register_custom_op_symbolic` and `unregister_custom_op_symbolic` in utils maintain their api for compatibility
- Update _onnx_supported_ops.py for doc generation to include quantized ops.
- Update code to register python ops in `torch/csrc/jit/passes/onnx.cpp`
## Profiling results
-0.1 seconds in execution time. -34% time spent in `_run_symbolic_function`. Tested on the alexnet example in public doc.
### After
```
└─ 1.641 export <@beartype(torch.onnx.utils.export) at 0x7f19be17f790>:1
└─ 1.641 export torch/onnx/utils.py:185
└─ 1.640 _export torch/onnx/utils.py:1331
├─ 0.889 _model_to_graph torch/onnx/utils.py:1005
│ ├─ 0.478 _optimize_graph torch/onnx/utils.py:535
│ │ ├─ 0.214 PyCapsule._jit_pass_onnx_graph_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ ├─ 0.190 _run_symbolic_function torch/onnx/utils.py:1670
│ │ │ └─ 0.145 Constant torch/onnx/symbolic_opset9.py:5782
│ │ │ └─ 0.139 _graph_op torch/onnx/_patch_torch.py:18
│ │ │ └─ 0.134 PyCapsule._jit_pass_onnx_node_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ └─ 0.033 [self]
```
### Before
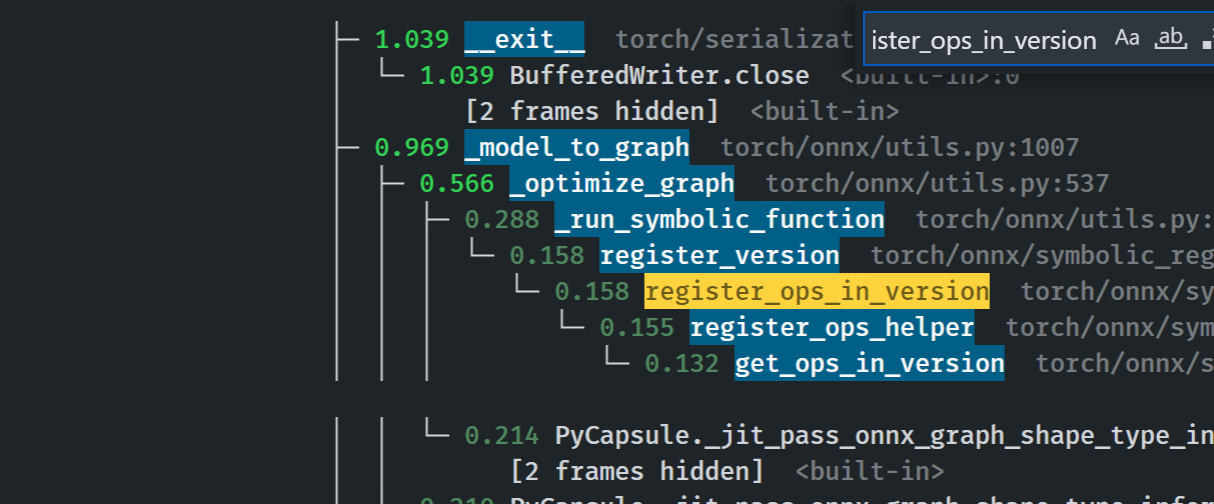
### Start up time
The startup process takes 0.03 seconds. Calls to `inspect` will be eliminated when we switch to using decorators for registration in #84448

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84382
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
The default value for params_dict in _optimize_graph, which is None, throw the following error:
> _C._jit_pass_onnx_unpack_quantized_weights(
> TypeError: _jit_pass_onnx_unpack_quantized_weights(): incompatible function arguments. The following argument types are supported:
> 1. (arg0: torch::jit::Graph, arg1: Dict[str, IValue], arg2: bool) -> Dict[str, IValue]
Replacing it by an empty dict fixes the issue (and makes more sense).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83996
Approved by: https://github.com/BowenBao
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
This PR provides a temporary fix on #84092 in exporter to avoid more cases falling into this bug.
A long-term fix will be provided later.
A simple repro with torch.onnx.export is still under investigation, as torch.jit.trace() is not the API we call inside torch.onnx.export, and it may introduce the difference. Therefore, a test case is provided here only.
A specific test one can use,
```python
import torch
import onnxruntime
from onnxruntime.training.ortmodule import DebugOptions, LogLevel
from onnxruntime.training.ortmodule import ORTModule
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.cv1 = torch.nn.Conv2d(3, 3, 5, 2, 1)
def forward(self, x):
x = self.cv1(x)
return x
x = torch.randn(10, 3, 20, 20) * 2
m = MyModule().eval()
x = x.cuda()
m = m.cuda()
debug_options = DebugOptions(log_level=LogLevel.VERBOSE, save_onnx=True, onnx_prefix="ViT-B")
m = ORTModule(m, debug_options=debug_options)
with torch.cuda.amp.autocast(dtype=torch.float16, cache_enabled=True):
loss = m(x)
```
AND make assertion fail in ORTModule
17ccd6fa02/orttraining/orttraining/python/training/ortmodule/_io.py (L578-L581)
Without the fix, the user will see the weight/bias of Conv node becomes constant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84219
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
Introduce `_jit_pass_onnx_assign_node_and_value_names` to parse and assign
scoped name for nodes and values in exported onnx graph.
Module layer information is obtained from `ONNXScopeName` captured in `scope`
attribute in nodes. For nodes, the processed onnx node name are stored in
attribute `onnx_name`. For values, the processed onnx output name are stored
as `debugName`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82040
Approved by: https://github.com/AllenTiTaiWang, https://github.com/justinchuby, https://github.com/abock
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao
Introduce `_jit_pass_onnx_assign_node_and_value_names` to parse and assign
scoped name for nodes and values in exported onnx graph.
Module layer information is obtained from `ONNXScopeName` captured in `scope`
attribute in nodes. For nodes, the processed onnx node name are stored in
attribute `onnx_name`. For values, the processed onnx output name are stored
as `debugName`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82040
Approved by: https://github.com/AllenTiTaiWang, https://github.com/justinchuby, https://github.com/abock
This PR adds an internal wrapper on the [beartype](https://github.com/beartype/beartype) library to perform runtime type checking in `torch.onnx`. It uses beartype when it is found in the environment and is reduced to a no-op when beartype is not found.
Setting the env var `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK=ERRORS` will turn on the feature. setting `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK=DISABLED` will disable all checks. When not set and `beartype` is installed, a warning message is emitted.
Now when users call an api with invalid arguments e.g.
```python
torch.onnx.export(conv, y, path, export_params=True, training=False)
# traning should take TrainingModel, not bool
```
they get
```
Traceback (most recent call last):
File "bisect_m1_error.py", line 63, in <module>
main()
File "bisect_m1_error.py", line 59, in main
reveal_error()
File "bisect_m1_error.py", line 32, in reveal_error
torch.onnx.export(conv, y, cpu_model_path, export_params=True, training=False)
File "<@beartype(torch.onnx.utils.export) at 0x1281f5a60>", line 136, in export
File "pytorch/venv/lib/python3.9/site-packages/beartype/_decor/_error/errormain.py", line 301, in raise_pep_call_exception
raise exception_cls( # type: ignore[misc]
beartype.roar.BeartypeCallHintParamViolation: @beartyped export() parameter training=False violates type hint <class 'torch._C._onnx.TrainingMode'>, as False not instance of <protocol "torch._C._onnx.TrainingMode">.
```
when `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK` is not set and `beartype` is installed, a warning message is emitted.
```
>>> torch.onnx.export("foo", "bar", "f")
<stdin>:1: CallHintViolationWarning: Traceback (most recent call last):
File "/home/justinchu/dev/pytorch/torch/onnx/_internal/_beartype.py", line 54, in _coerce_beartype_exceptions_to_warnings
return beartyped(*args, **kwargs)
File "<@beartype(torch.onnx.utils.export) at 0x7f1d4ab35280>", line 39, in export
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/site-packages/beartype/_decor/_error/errormain.py", line 301, in raise_pep_call_exception
raise exception_cls( # type: ignore[misc]
beartype.roar.BeartypeCallHintParamViolation: @beartyped export() parameter model='foo' violates type hint typing.Union[torch.nn.modules.module.Module, torch.jit._script.ScriptModule, torch.jit.ScriptFunction], as 'foo' not <protocol "torch.jit.ScriptFunction">, <protocol "torch.nn.modules.module.Module">, or <protocol "torch.jit._script.ScriptModule">.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/justinchu/dev/pytorch/torch/onnx/_internal/_beartype.py", line 63, in _coerce_beartype_exceptions_to_warnings
return func(*args, **kwargs)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 482, in export
_export(
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 1422, in _export
with exporter_context(model, training, verbose):
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/contextlib.py", line 119, in __enter__
return next(self.gen)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 177, in exporter_context
with select_model_mode_for_export(
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/contextlib.py", line 119, in __enter__
return next(self.gen)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 95, in select_model_mode_for_export
originally_training = model.training
AttributeError: 'str' object has no attribute 'training'
```
We see the error is caught right when the type mismatch happens, improving from what otherwise would become `AttributeError: 'str' object has no attribute 'training'`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83673
Approved by: https://github.com/BowenBao
Legacy code has onnx_shape_inference=False by default, which is misleading
as every other export api sets it to True unless otherwise overriden by caller.
There is only two tests that need updating according to this change.
* test_utility_funs.py::test_constant_fold_shape. The resulting number of nodes
in graph is increased by 1, due to that previously the extra constant node was
added as initializer.
* test_utility_funs.py::test_onnx_function_substitution_pass. Enabling onnx
shape inference discovered discrepancy in test input shape and supplied dynamic
axes arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82767
Approved by: https://github.com/justinchuby, https://github.com/abock
### Description
<!-- What did you change and why was it needed? -->
Remove unused patching methods:
- `torch._C.Graph.constant`
- unpatch `torch._C.Node.__getitem__` and move the helper function to `symbolic_helper`
Add typing annotations
### Issue
<!-- Link to Issue ticket or RFP -->
#76254
### Testing
<!-- How did you test your change? -->
Unit tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83006
Approved by: https://github.com/BowenBao
Part of #79263
Previously, all quantized PyTorch tensors are all casted to the dtypes which comply with ONNX's definition, i.e. `scale` is casted to `double`, and `zero_point` is casted to `int64`. These casts lead to inconsistent dtypes when comparing PyTorch's outputs and ONNX runtime's outputs.
Now, `cast_onnx_accepted` argument is added to `unpack_quantized_tensor` function. When making example inputs for ONNX, we cast them to the ONNX compliant dtypes; otherwise, they are casted to PyTorch default types for quantization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79690
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Add flag (inline_autograd) to enable inline export of model consisting of autograd functions. Currently, this flag should only be used in TrainingMode.EVAL and not for training.
An example:
If a model containing ``autograd.Function`` is as follows
```
class AutogradFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
result = result.log()
ctx.save_for_backward(result)
return result
```
Then the model is exported as
```
graph(%0 : Float):
%1 : Float = ^AutogradFunc(%0)
return (%1)
```
If inline_autograd is set to True, this will be exported as
```
graph(%0 : Float):
%1 : Float = onnx::Exp(%0)
%2 : Float = onnx::Log(%1)
return (%2)
```
If one of the ops within the autograd module is not supported, that particular node is exported as is mirroring ONNX_FALLTHROUGH mode
Fixes: #61813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74765
Approved by: https://github.com/BowenBao, https://github.com/malfet
- Remove wrappers in `__init__` around utils and instead expose those functions directly. Move the docstrings from `__init__` to corresponding functions in utils
- Annotate `torch.onnx.export` types
- Improve docstrings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78231
Approved by: https://github.com/BowenBao
When `TrainingMode.PRESERVE` is set for export, the exporter used to change the model's training mode based on some logic. Now we respect the option and not touch the model's training state.
- Previously `_set_training_mode`'s behavior doesn't match what the global variable expects. This PR removes the deprecated `_set_training_mode` and makes the type correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78583
Approved by: https://github.com/BowenBao
A graph is exported for each set of inputs. The exported graphs are then compared
to each other, and discrepancies are reported. This function first checks the jit
graph, and then the onnx graph.
Unless otherwise specified, the jit/ONNX graph is expected to be the same, regardless
of the inputs it used for exporting. A discrepancy would imply the graph exported is
not accurate when running with other set of inputs, which will typically results in
runtime error or output mismatches.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78323
Approved by: https://github.com/justinchuby, https://github.com/garymm
Use pyupgrade(https://github.com/asottile/pyupgrade) and flynt to modernize python syntax
```sh
pyupgrade --py36-plus --keep-runtime-typing torch/onnx/**/*.py
pyupgrade --py36-plus --keep-runtime-typing test/onnx/**/*.py
flynt torch/onnx/ --line-length 120
```
- Use f-strings for string formatting
- Use the new `super()` syntax for class initialization
- Use dictionary / set comprehension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77935
Approved by: https://github.com/BowenBao
Cleaning up onnx module imports to prepare for updating `__init__`.
- Simplify importing the `_C` and `_C._onnx` name spaces
- Remove alias of the symbolic_helper module in imports
- Remove any module level function imports. Import modules instead
- Alias `symbilic_opsetx` as `opsetx`
- Fix some docstrings
Requires:
- https://github.com/pytorch/pytorch/pull/77448
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77423
Approved by: https://github.com/BowenBao
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
In `_need_symbolic_context`, when the annotation is postponed evaluated, the annotation is a string and not a type. We need to use get_type_hints to get the real type.
For example,
```python
def g(a: int) -> int: return a
def f(a: "int") -> "int": return a
```
we will get the correct type `int` for both g and f with `typing.get_type_hints`. Otherwise, the type for `a` in `f` will be a string and is not comparable to the type `int` - `issubclass` will complain.
This is necessary as we will use postponed typing evaluation to break circular dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77365
Approved by: https://github.com/BowenBao
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73284
Some important ops won't support optional type until opset 16,
so we can't fully test things end-to-end, but I believe this should
be all that's needed. Once ONNX Runtime supports opset 16,
we can do more testing and fix any remaining bugs.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D34625646
Pulled By: malfet
fbshipit-source-id: 537fcbc1e9d87686cc61f5bd66a997e99cec287b
Co-authored-by: BowenBao <bowbao@microsoft.com>
Co-authored-by: neginraoof <neginmr@utexas.edu>
Co-authored-by: Nikita Shulga <nshulga@fb.com>
(cherry picked from commit 822e79f31ae54d73407f34f166b654f4ba115ea5)
Updating the docstrings and type annotations as I walk through the code.
- Turned some comments into docstrings.
- Added type annotations for some functions in utils and the registry
- Removed direct function imports; importing functions makes name space collision easier to happen and refactoring/code analysis harder: https://google.github.io/styleguide/pyguide.html#22-imports
- Formatted touched files with black
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76255
Approved by: https://github.com/BowenBao
Currently `torch.onnx.export(.., operator_export_type=OperatorExportTypes.ONNX_ATEN_FALLBACK)` only issues ATen ops through explicit requests (e.g. `g.at()`) calls inside each op symbolic function. This is done based on specific conditions such as `operator_export_type==OperatorExportTypes.ONNX_ATEN_FALLBACK)` or `is_caffe2_aten_fallback()`
This PR extends the ATen fallback mechanism for scenarios when the symbolic function raises `RuntimeError` during export. The idea is that partial implementation of existing ONNX ops can fallback to ATen as a last resort. That is valuable because each operator can have many input combinations and not all are always implemented.
A minor fix was done to make sure the `overload_name` attribute is added to explicit ATen op fallback requests when a symbolic is not registered to a particular op.
ps: The behavior for builds with BUILD_CAFFE2=1 is not changed to ensure BC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74759
Approved by: https://github.com/garymm, https://github.com/msaroufim
Previously pre-tracing model is required for exporting quantized model.
e.g. calling `traced_m = torch.jit.trace(model, inputs)` and export `traced_m`.
The reason was quantized weights are stored in a unique `PackedParam` structure,
and they need to be handled by tracing to be exportable.
This PR enables export api to call tracing underneath if it detects quantization
in the model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75921
Approved by: https://github.com/garymm
This PR introduces 3 BC changes:
First, this PR propagates `BUILD_CAFFE2` flag to `libtorch` and `libtorch_python`, which is necessary for non-caffe2 ONNX runtimes when using `ONNX_ATEN_FALLBACK` operator export type.
Second, as a complement of https://github.com/pytorch/pytorch/pull/68490, this PR refactors Caffe2's Aten ops symbolics to consider not only the `operator_export_type` (aka `ONNX_ATEN_FALLBACK`) to emit Caffe2 Aten ops, but also whether `BUILD_CAFFE2` (which is called `torch.onnx._CAFFE2_ATEN_FALLBACK` in python binding) is set.
Lastly, it renames `onnx::ATen` to `aten::ATen` for ONNX spec consistency in a BC fashion.
ONNX doesn't have `ATen` op on its spec, but PyTorch ONNX converter emits them. Non-Caffe2 backend engines would be mislead by such operator's name/domain. A non-ideal workaround would be to have Aten ops handled based on its name and ignore the (non-complaint) domain. Moreover, users could incorrectly file bugs to either ONNX or ONNX Runtime when they inspect the model and notice the presence of an unspecified ONNX operator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73954
Approved by: https://github.com/BowenBao, https://github.com/malfet, https://github.com/garymm, https://github.com/jiafatom
Previous logic didn't consider the case for TrainingMode.PRESERVE.
A more direct way is to check `model.training`, which is the accurate
training mode, set by `exporter_context(model, training)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74247
Approved by: https://github.com/garymm
Summary:
Add ONNX exporter logging facility. Supporting both C++/Python logging api. Logging can be turned on/off. Logging output stream can be either set to `stdout` or `stderr`.
A few other changes:
* When exception is raised in passes, the current IR graph being processed will be logged.
* When exception is raised from `_jit_pass_onnx` (the pass that converts nodes from namespace `ATen` to `ONNX`), both ATen IR graph and ONNX IR graph under construction will be logged.
* Exception message for ConstantFolding is truncated to avoid being too verbose.
* Update the final printed IR graph with node name in ONNX ModelProto as node attribute. Torch IR Node does not have name. Adding this to printed IR graph helps debugging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71342
Reviewed By: msaroufim
Differential Revision: D34433473
Pulled By: malfet
fbshipit-source-id: 4b137dfd6a33eb681a5f2612f19aadf5dfe3d84a
(cherry picked from commit 67a8ebed5192c266f604bdcca931df6fe589699f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73280
This PR adds a new attribute overload_name to the Aten node so that third party applications can implement calls to libtorch without using PyTorch source code.
This is necessary because torch's torch::jit::findOperatorFor(fullname) requires a full name, including operator and overload names.
ATen op was originally created for Caffe2, which leveraged the availability of the pytorch yaml files to create calls to the aten oeprators directly, not relying on torch::jit::findOperatorFor
The first part of the PR refactors all symbolics that create Aten ops, so that there is a single helper for this operator. Next all symbolics are updated to pass in the relevant overload name, if empty string is not applicable
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D34625645
Pulled By: malfet
fbshipit-source-id: 37d58cfb5231833768172c122efc42edf7d8609a
(cherry picked from commit e92f09117d3645b38bc3235b30aba4b4c7c71dfa)
Enables local function export to capture annotated attributes.
For example:
```python
class M(torch.nn.Module):
num_layers: int
def __init__(self, num_layers):
super().__init__()
self.num_layers = num_layers
def forward(self, args):
...
```
`num_layers` will now be captured as attribute of local function `M`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72883
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69547
ScriptModule export introduces duplicated ONNX initializers for shared weights, unnecessarily increases ONNX model size. This PR de-duplicates ONNX initializers for model exported in eval mode, by checking if the underlying tensors share the same `data_ptr`, `strides` and `sizes`.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32994271
Pulled By: malfet
fbshipit-source-id: 10ac66638b6255890875272472aa9ed07a5b1d9a
Co-authored-by: BowenBao <bowbao@microsoft.com>
(cherry picked from commit d7cbde940c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68491
* Allows implementing symbolic functions for domains other than `aten`, for example `prim`, in symbolic_opset#.py.
* Allows symbolic function to access extra context if needed, through `SymbolicFunctionState`.
* Particularly, the `prim::PythonOp` special case can access node without the need of passing node through inputs. Updates will be made downstreams, and in a follow-up PR we will remove the previous workaround in exporter.
* `prim::Loop`, `prim::If`, etc are now moved outside of `_run_symbolic_function` from utils.py, and to symbolic_opset9.py.
Motivation for this change:
- Better maintainability and reducing complexity. Easier to add symbolic for operators, both simple and complex ones (that need additional context), without the former needing to know the existence of the latter.
- The design idea was long outdated. prim ops are no longer rare special cases, and they shouldn't all be handled inside `_run_symbolic_function`. As a result this function becomes too clumsy. There were also prim ops symbolic added in symbolic_opset#.py with signature `prim_[opname]`, creating separation and confusion.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483782
Pulled By: malfet
fbshipit-source-id: f9affc31b1570af30ffa6668da9375da111fd54a
Co-authored-by: BowenBao <bowbao@microsoft.com>
(cherry picked from commit 1e04ffd2fd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68490
The use of ATEN as a fallback operator during ONNX conversion is important for increasing operator coverage or even provide more efficient implementations over some ONNX ops.
Currently this feature is available through `OperatorExportTypes.ONNX_ATEN_FALLBACK`,
but it also performs changes to the graph that are runnable by Caffe2, only.
This PR introduces restricts caffe2-specific graph transformations for `ONNX_ATEN_FALLBACK`
operator export type for when pytorch is built with caffe2 support (aka BUILD_CAFFE2=1 during build)
The first version of this PR introduced a new operator export type `ONNX_ATEN__STRICT_FALLBACK`,
which essentially is the same as `ONNX_ATEN_FALLBACK` but without caffe2 transformations.
It was preferred to not introduce a new operator export type, but to refine the existing aten fallback one
## BC-breaking note
### The global constant `torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE` is removed in favor of
a less visible `torch.onnx._CAFFE2_ATEN_FALLBACK`.
`PYTORCH_ONNX_CAFFE2_BUNDLE` is really a dead code flag always set to False.
One alternative would be fixing it, but #66658 disables Caffe2 build by default.
Making a Caffe2 feature a private one seems to make more sense for future deprecation.
### The method `torch.onnx.export` now defaults to ONNX when `operator_export_type` is not specified.
Previously `torch.onnx.export's operator_export_type` intended to default to `ONNX_ATEN_FALLBACK` when `PYTORCH_ONNX_CAFFE2_BUNDLE` was set, but it would never happen as `PYTORCH_ONNX_CAFFE2_BUNDLE` is always undefined
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483781
Pulled By: malfet
fbshipit-source-id: e9b447db9466b369e77d747188685495aec3f124
(cherry picked from commit 5fb1eb1b19)
Cover more cases of scope inferencing where consecutive nodes don't have valid scope information. Usually these nodes are created in some pass where authors forgot to assign meaningful scope to them.
* One rule of `InferScope` is to check if the current node's outputs' users share the same scope. Recursively run `InferScope` on the user nodes if they are missing scope as well. Since the graph is SSA, the depth is finite.
* Fix one pass that missed scope information for a new node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71897
Export should fail if export_modules_as_functions is set and opset_version<15.
This is because opeset_version < 15 implies IR version < 8, which means no local function support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71619
Summary:
For some ONNX exported models, the inputs/outputs names have sometimes a numeric value and this makes pretty hard to inspect the generated graphs in the case of large models.
The solution in this PR was initially submitted to our internal utilities library by take-cheeze https://github.com/pfnet/pytorch-pfn-extras/pull/102
Now we would like to upstream this change by adding an extra kwarg when exporting the model to allow replacing these numeric names with actual debuggable ones.
As an example, the following code shows that the module output is `3`
```python
g, p, o = _model_to_graph(module, torch.ones(1, 10))
for n in g.nodes():
for v in n.outputs():
print(v.debugName())
```
output
```
3
```
With this PR
```
v3_Gemm
```
This allows identifying this out as a value from the associated Gemm layer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68976
Reviewed By: jansel
Differential Revision: D33662246
Pulled By: msaroufim
fbshipit-source-id: 45f56eef2a84d9a318db20c6a6de6c2743b9cd99
(cherry picked from commit 513c1d28f1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69546
The arg is not used and was previously deprecated.
Also remove torch.onnx._export_to_pretty_string. It's redundant with the
public version.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32994270
Pulled By: msaroufim
fbshipit-source-id: f8f3933b371a0d868d9247510bcd73c31a9d6fcc
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}