mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 00:21:07 +01:00
b005ec62b9
31 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
b005ec62b9 |
[BE] Remove dependency on six and future (#94709)
Remove the Python 2 and 3 compatibility library [six](https://pypi.org/project/six) and [future](https://pypi.org/project/future) and `torch._six`. We only support Python 3.8+ now. It's time to retire them. Pull Request resolved: https://github.com/pytorch/pytorch/pull/94709 Approved by: https://github.com/malfet, https://github.com/Skylion007 |
||
|
|
e994e78397 |
Added vectorized horizontal flip path for channels last for NcHW (#91806)
## Description - Added AVX2-only vectorization for horizontal flip op applied on channels last NCHW input, where **2 <= C * sizeof(dtype) <= 16**. PR is a bit faster than Pillow and largely faster (x2 - x5) than Nightly. - ~Still keeping `cpu_vflip_memcpy` code ([it's PR](https://github.com/pytorch/pytorch/pull/89414) was reverted and is under investigations)~ ## Benchmarks ``` [---------------------------------------------------------------------- Horizontal flip ----------------------------------------------------------------------] | torch (2.0.0a0+gitf6d73f3) PR | Pillow (9.4.0) | torch (2.0.0a0+git4386f31) nightly 1 threads: ---------------------------------------------------------------------------------------------------------------------------------------------------- channels=2, size=256, dtype=torch.uint8, mf=channels_last | 31.859 (+-0.498) | | 190.599 (+-7.579) channels=2, size=520, dtype=torch.uint8, mf=channels_last | 60.648 (+-0.074) | | 706.895 (+-11.219) channels=2, size=712, dtype=torch.uint8, mf=channels_last | 95.994 (+-2.510) | | 1340.685 (+-169.279) channels=3, size=256, dtype=torch.uint8, mf=channels_last | 45.490 (+-0.108) | 47.359 (+-0.942) | 179.520 (+-2.916) channels=3, size=520, dtype=torch.uint8, mf=channels_last | 146.802 (+-2.175) | 174.201 (+-4.124) | 707.765 (+-2.691) channels=3, size=712, dtype=torch.uint8, mf=channels_last | 215.148 (+-0.925) | 313.606 (+-3.972) | 1346.678 (+-89.854) channels=3, size=256, dtype=torch.int8, mf=channels_last | 43.618 (+-0.160) | | 191.613 (+-16.252) channels=3, size=520, dtype=torch.int8, mf=channels_last | 147.487 (+-0.691) | | 755.020 (+-25.045) channels=3, size=712, dtype=torch.int8, mf=channels_last | 216.687 (+-0.906) | | 1314.854 (+-31.137) channels=4, size=256, dtype=torch.uint8, mf=channels_last | 32.169 (+-0.092) | | 195.415 (+-3.647) channels=4, size=520, dtype=torch.uint8, mf=channels_last | 89.465 (+-0.154) | | 776.459 (+-14.845) channels=4, size=712, dtype=torch.uint8, mf=channels_last | 152.773 (+-0.610) | | 1456.304 (+-45.280) channels=8, size=256, dtype=torch.uint8, mf=channels_last | 43.444 (+-0.158) | | 163.669 (+-4.580) channels=8, size=520, dtype=torch.uint8, mf=channels_last | 151.285 (+-0.602) | | 642.396 (+-13.500) channels=8, size=712, dtype=torch.uint8, mf=channels_last | 278.471 (+-0.912) | | 1205.472 (+-47.609) channels=16, size=256, dtype=torch.uint8, mf=channels_last | 75.176 (+-0.188) | | 181.278 (+-3.388) channels=16, size=520, dtype=torch.uint8, mf=channels_last | 291.105 (+-1.163) | | 716.906 (+-30.842) channels=16, size=712, dtype=torch.uint8, mf=channels_last | 893.267 (+-10.899) | | 1434.931 (+-40.399) channels=2, size=256, dtype=torch.int16, mf=channels_last | 31.437 (+-0.143) | | 195.299 (+-2.916) channels=2, size=520, dtype=torch.int16, mf=channels_last | 89.834 (+-0.175) | | 774.940 (+-8.638) channels=2, size=712, dtype=torch.int16, mf=channels_last | 154.806 (+-0.550) | | 1443.435 (+-37.799) channels=3, size=256, dtype=torch.int16, mf=channels_last | 70.909 (+-0.146) | | 195.347 (+-1.986) channels=3, size=520, dtype=torch.int16, mf=channels_last | 212.998 (+-1.181) | | 776.282 (+-15.598) channels=3, size=712, dtype=torch.int16, mf=channels_last | 382.991 (+-0.968) | | 1441.674 (+-9.873) channels=4, size=256, dtype=torch.int16, mf=channels_last | 43.574 (+-0.157) | | 163.176 (+-1.941) channels=4, size=520, dtype=torch.int16, mf=channels_last | 151.289 (+-0.557) | | 641.169 (+-9.457) channels=4, size=712, dtype=torch.int16, mf=channels_last | 275.275 (+-0.874) | | 1186.589 (+-12.063) channels=8, size=256, dtype=torch.int16, mf=channels_last | 74.455 (+-0.292) | | 181.191 (+-1.721) channels=8, size=520, dtype=torch.int16, mf=channels_last | 289.591 (+-1.134) | | 715.755 (+-2.368) channels=8, size=712, dtype=torch.int16, mf=channels_last | 923.831 (+-68.807) | | 1437.078 (+-14.649) channels=2, size=256, dtype=torch.int32, mf=channels_last | 44.217 (+-0.203) | | 163.011 (+-1.497) channels=2, size=520, dtype=torch.int32, mf=channels_last | 150.920 (+-0.950) | | 640.761 (+-1.882) channels=2, size=712, dtype=torch.int32, mf=channels_last | 281.648 (+-1.163) | | 1188.464 (+-10.374) channels=3, size=256, dtype=torch.int32, mf=channels_last | 103.708 (+-0.517) | | 165.001 (+-1.315) channels=3, size=520, dtype=torch.int32, mf=channels_last | 409.785 (+-8.004) | | 647.939 (+-11.431) channels=3, size=712, dtype=torch.int32, mf=channels_last | 790.819 (+-16.471) | | 1219.206 (+-9.503) channels=4, size=256, dtype=torch.int32, mf=channels_last | 72.975 (+-0.155) | | 181.298 (+-1.059) channels=4, size=520, dtype=torch.int32, mf=channels_last | 291.584 (+-0.905) | | 716.033 (+-4.824) channels=4, size=712, dtype=torch.int32, mf=channels_last | 938.790 (+-15.930) | | 1434.134 (+-15.060) Times are in microseconds (us). ``` [Source](https://gist.github.com/vfdev-5/8e8c989d35835d7ab20567bff36632be#file-20230123-143303-pr_vs_nightly-md) ## Context: Follow-up work to PRs : https://github.com/pytorch/pytorch/pull/88989, https://github.com/pytorch/pytorch/pull/89414 and https://github.com/pytorch/pytorch/pull/90013 Pull Request resolved: https://github.com/pytorch/pytorch/pull/91806 Approved by: https://github.com/peterbell10, https://github.com/lezcano |
||
|
|
fc21cc82fc |
Enable sparse_dim() and dense_dim() methods for Strided tensors (#86203)
The reason for enabling sparse/dense_dim() for strided tensors is to have more meaningful error messages: For instance, compare ``` NotImplementedError: Could not run 'aten::sparse_dim' with arguments from the 'CPU' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::sparse_dim' is only available for these backends: [SparseCPU, SparseCUDA, SparseMeta, SparseCsrCPU, SparseCsrCUDA, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher]. ``` [master] vs ``` RuntimeError: addmm: matrices expected, got 0D tensor ``` [this PR] where the latter message gives a hint of which function is to blame for dealing with unexpected inputs. Pull Request resolved: https://github.com/pytorch/pytorch/pull/86203 Approved by: https://github.com/cpuhrsch |
||
|
|
1d90d6ee60 |
Setup for running PyTorch tests with TorchDynamo and skips for known failing tests (#80106)
@ezyang I am going to keep adding more skips in this PR for now. And once we have the CI running, I will replace with the appropriate decorators. cc @mlazos , we should add those tests in test_ops.py in this PR as well cc @jansel Pull Request resolved: https://github.com/pytorch/pytorch/pull/80106 Approved by: https://github.com/ezyang, https://github.com/jansel |
||
|
|
70e86b4562 |
[test_shape_ops] Increase system memory requirement (#80369)
Increase system memory requirement for TestShapeOpsCUDA.test_flip_large_tensor_cuda Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com> Fixes https://github.com/pytorch/pytorch/issues/80373 Pull Request resolved: https://github.com/pytorch/pytorch/pull/80369 Approved by: https://github.com/soulitzer |
||
|
|
bfac65dfe5
|
[testing] Update dispatch macros (#74977)
This PR is reland of #74289 Co-authored-by: Khushi Agrawal <khushiagrawal411@gmail.com> |
||
|
|
2e4152b118 |
Revert "[testing] Update dispatch macros"
This reverts commit
|
||
|
|
eed19a0f38 |
[testing] Update dispatch macros
Hi, This PR is the follow-up PR of #71561. (the previous PR had a couple of merge conflicts and was reverted, this PR resolves that). Please take a look. Thanks! cc: @pmeier @mruberry @kshitij12345 Pull Request resolved: https://github.com/pytorch/pytorch/pull/74289 Approved by: https://github.com/pmeier, https://github.com/mruberry |
||
|
|
ef066f0832 |
Revert D34856571: [pytorch][PR] Replace get_all_ type macros with the ATen dispatch macros.
Test Plan: revert-hammer Differential Revision: D34856571 ( |
||
|
|
3ded7b1da3 |
Replace get_all_ type macros with the ATen dispatch macros. (#71561)
Summary: Hi, Team! The PR is motivated from https://github.com/pytorch/pytorch/pull/71153#discussion_r782446738. It aims to replace `get_all` type macros with the ATen dispatch macros. The files it iterates over are: (Thanks, Lezcano, for the idea!!) <details> <summary> `test/test_autograd.py`</summary> <p> ```python 43:from torch.testing._internal.common_dtype import get_all_dtypes 8506: floating_dt = [dt for dt in get_all_dtypes() if dt.is_floating_point] ``` </p> </details> <details> <summary> `test/test_binary_ufuncs.py`</summary> <p> ```python 26: all_types_and_complex_and, integral_types_and, get_all_dtypes, get_all_int_dtypes, get_all_math_dtypes, 27: get_all_complex_dtypes, get_all_fp_dtypes, 935: dtypes(*get_all_dtypes(include_bool=False, include_complex=False)) 1035: dtypes(*get_all_dtypes( 1488: dtypes(*(get_all_dtypes(include_bool=False, include_bfloat16=False))) 1879: dtypes(*product(get_all_dtypes(include_complex=False), get_all_dtypes(include_complex=False))) 1887: dtypes(*(get_all_int_dtypes() + [torch.bool])) 1913: dtypes(*(get_all_fp_dtypes())) 1941: dtypes(*(get_all_fp_dtypes())) 1977: dtypes(*product(get_all_complex_dtypes(), get_all_dtypes())) 2019: dtypes(*product(get_all_fp_dtypes(), get_all_fp_dtypes())) 2048: dtypes(*get_all_dtypes()) 2110: dtypes(*product(get_all_dtypes(include_complex=False), 2111: get_all_dtypes(include_complex=False))) 2128: types = [torch.bool, torch.bfloat16] + get_all_int_dtypes() 2173: if dtypes[1] in get_all_fp_dtypes(): 2178: dtypes(*product(get_all_fp_dtypes(), 2179: get_all_fp_dtypes())) 2260: dtypesIfCUDA(*set(get_all_math_dtypes('cuda')) - {torch.complex64, torch.complex128}) 2261: dtypes(*set(get_all_math_dtypes('cpu')) - {torch.complex64, torch.complex128}) 2273: dtypesIfCUDA(*set(get_all_math_dtypes('cuda')) - {torch.complex64, torch.complex128}) 2274: dtypes(*set(get_all_math_dtypes('cpu')) - {torch.complex64, torch.complex128}) 2307: dtypes(*get_all_math_dtypes('cpu')) 2319: dtypes(*get_all_fp_dtypes(include_bfloat16=False)) 2331: dtypes(*get_all_int_dtypes()) 2356: dtypes(*get_all_dtypes(include_bfloat16=False, include_bool=False, include_complex=False)) 2393: if dtype in get_all_int_dtypes(): 2614: dtypes(*get_all_dtypes()) 2624: dtypes(*tuple(itertools.combinations_with_replacement(get_all_dtypes(), 2))) 2806: dtypes(*list(product(get_all_dtypes(include_complex=False), 2807: get_all_dtypes(include_complex=False)))) 2866: dtypes(*list(product(get_all_complex_dtypes(), 2867: get_all_complex_dtypes()))) 2902: dtypes(*product(get_all_dtypes(), get_all_dtypes())) 2906: dtypes(*product(get_all_dtypes(), get_all_dtypes())) 2910: dtypes(*product(get_all_dtypes(), get_all_dtypes())) 3019: dtypes = [torch.float, torch.double] + get_all_complex_dtypes() 3221: dtypes(*get_all_dtypes(include_complex=False)) 3407: dtypes(*list(product(get_all_dtypes(include_bool=False), 3408: get_all_dtypes(include_bool=False)))) 3504: dtypes(*product(get_all_dtypes(include_complex=False, include_bfloat16=False), 3505: get_all_dtypes(include_complex=False, include_bfloat16=False))) 3516: if x.dtype in get_all_int_dtypes() + [torch.bool]: 3643: dtypes(*product(get_all_dtypes(include_complex=False, 3645: get_all_dtypes(include_complex=False, ``` </p> </details> <details> <summary> `test/test_complex.py`</summary> <p> ```python 6:from torch.testing._internal.common_dtype import get_all_complex_dtypes 11: dtypes(*get_all_complex_dtypes()) ``` </p> </details> <details> <summary> `test/test_foreach.py`</summary> <p> ```python 18: get_all_dtypes, get_all_int_dtypes, get_all_complex_dtypes, get_all_fp_dtypes, 142: if dtype in get_all_int_dtypes(): 179: disable_fastpath = op.ref == torch.div and dtype in get_all_int_dtypes() + [torch.bool] 201: disable_fastpath = op.ref == torch.div and dtype in get_all_int_dtypes() + [torch.bool] 205: disable_fastpath |= dtype in get_all_int_dtypes() + [torch.bool] 211: disable_fastpath |= dtype not in get_all_complex_dtypes() 241: bool_int_div = op.ref == torch.div and dtype in get_all_int_dtypes() + [torch.bool] 246: disable_fastpath |= dtype in get_all_int_dtypes() + [torch.bool] 248: disable_fastpath |= dtype not in get_all_complex_dtypes() 250: disable_fastpath |= True and dtype not in get_all_complex_dtypes() 307: disable_fastpath = dtype in get_all_int_dtypes() + [torch.bool] 365: if opinfo.name == "_foreach_abs" and dtype in get_all_complex_dtypes(): 376: ops(foreach_unary_op_db, dtypes=get_all_dtypes()) 393: dtypes=get_all_dtypes(include_half=True, include_bfloat16=True, include_complex=False)) 401: ops(foreach_minmax_op_db, dtypes=get_all_fp_dtypes(include_bfloat16=True, include_half=True)) 426: if ord in (1, 2) and dtype in torch.testing.get_all_fp_dtypes(): 439: dtypes(*get_all_dtypes()) 449: ops(foreach_binary_op_db, dtypes=get_all_dtypes()) 481: ops(foreach_binary_op_db, dtypes=get_all_dtypes()) 536: if dtype in get_all_int_dtypes() + [torch.bool] and foreach_op == torch._foreach_div: 545: ops(foreach_binary_op_db, dtypes=get_all_dtypes()) 637: ops(foreach_pointwise_op_db, allowed_dtypes=get_all_fp_dtypes(include_half=False, include_bfloat16=False)) ``` </p> </details> <details> <summary> `test/test_linalg.py`</summary> <p> ```python 29: all_types, floating_types, floating_and_complex_types, get_all_dtypes, get_all_int_dtypes, get_all_complex_dtypes, 30: get_all_fp_dtypes, 111: dtypes(*(get_all_dtypes())) 794: float_and_complex_dtypes = get_all_fp_dtypes() + get_all_complex_dtypes() 807: dtypes(*(get_all_int_dtypes())) 828: dtypes(*(get_all_fp_dtypes() + get_all_complex_dtypes())) 841: if dtype in get_all_complex_dtypes(): 844: dtypes(*itertools.product(get_all_dtypes(), 845: get_all_dtypes())) 855: for dtypes0, dtypes1, dtypes2 in product(get_all_dtypes(), repeat=3): 5607: *get_all_fp_dtypes(include_half=not CUDA9, include_bfloat16=(CUDA11OrLater and SM53OrLater))) 5608: dtypes(*(set(get_all_dtypes()) - {torch.half, torch.bool})) 5644: dtypes(*(get_all_complex_dtypes() + get_all_fp_dtypes())) 6255: dtypesIfCUDA(*get_all_complex_dtypes(), 6256: *get_all_fp_dtypes(include_bfloat16=(TEST_WITH_ROCM or (CUDA11OrLater and SM53OrLater)), 6292: dtypesIfCUDA(*get_all_fp_dtypes(include_bfloat16=(TEST_WITH_ROCM or (CUDA11OrLater and SM53OrLater)))) 6323: dtypesIfCUDA(*get_all_complex_dtypes(), 6324: *get_all_fp_dtypes(include_bfloat16=(TEST_WITH_ROCM or (CUDA11OrLater and SM53OrLater)))) 6325: dtypes(*get_all_complex_dtypes(), *get_all_fp_dtypes()) 6358: dtypesIfCUDA(*([torch.float, torch.double] + get_all_complex_dtypes())) 6556: dtypes(*get_all_fp_dtypes(), *get_all_complex_dtypes()) 6668: dtypes(*get_all_fp_dtypes(), *get_all_complex_dtypes()) 6741: dtypes(*get_all_fp_dtypes(), *get_all_complex_dtypes()) ``` </p> </details> <details> <summary> `test/test_nn.py`</summary> <p> ```python 37:from torch.testing._internal.common_dtype import integral_types, get_all_fp_dtypes, get_all_math_dtypes 50: onlyNativeDeviceTypes, deviceCountAtLeast, largeTensorTest, expectedFailureMeta, skipMeta, get_all_device_types, \ 8862: for device in get_all_device_types(): 9629: for dt1 in get_all_math_dtypes(device): 9630: for dt2 in get_all_math_dtypes(device): 9631: for dt3 in get_all_math_dtypes(device): 9648: for input_dtype in get_all_math_dtypes(device): 9664: for input_dtype in get_all_math_dtypes(device): 13015: dtypes(*get_all_fp_dtypes(include_bfloat16=AMPERE_OR_ROCM)) 13034: dtypes(*get_all_fp_dtypes(include_bfloat16=AMPERE_OR_ROCM)) 13159: dtypes(*get_all_fp_dtypes(include_bfloat16=AMPERE_OR_ROCM)) 17400: dtypesIfCUDA(*get_all_fp_dtypes(include_bfloat16=AMPERE_OR_ROCM)) 17768: dtypesIfCUDA(*get_all_fp_dtypes()) 17773: dtypesIfCUDA(*get_all_fp_dtypes()) 17778: dtypesIfCUDA(*get_all_fp_dtypes()) 17783: dtypesIfCUDA(*get_all_fp_dtypes()) 17788: dtypesIfCUDA(*get_all_fp_dtypes()) 17793: dtypesIfCUDA(*get_all_fp_dtypes()) 17798: dtypesIfCUDA(*get_all_fp_dtypes()) 17963: dtypesIfCUDA(*get_all_fp_dtypes()) 17977: dtypesIfCUDA(*get_all_fp_dtypes()) 18684: def test_cross_entropy_loss_prob_target_all_reductions(self, device): ``` </p> </details> <details> <summary> `test/test_numpy_interop.py`</summary> <p> ```python 12:from torch.testing._internal.common_dtype import get_all_dtypes 399: dtypes(*get_all_dtypes()) ``` </p> </details> <details> <summary> `test/test_ops.py`</summary> <p> ```python 12:from torch.testing._internal.common_dtype import floating_and_complex_types_and, get_all_dtypes 86: for dtype in get_all_dtypes(): ``` </p> </details> <details> <summary> `test/test_reductions.py`</summary> <p> ```python 16: get_all_dtypes, get_all_math_dtypes, get_all_int_dtypes, get_all_complex_dtypes, get_all_fp_dtypes, 360: allowed_dtypes=get_all_dtypes(include_bfloat16=False)) 366: allowed_dtypes=get_all_dtypes(include_bfloat16=False)) 394: allowed_dtypes=get_all_dtypes(include_bfloat16=False)) 750: for dtype in [dtype for dtype in get_all_math_dtypes('cpu') if dtype != torch.float16]: 1404: dtypes(*get_all_dtypes(include_bool=False, include_complex=False)) 1457: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False) + 1458: get_all_complex_dtypes())) 1465: return dtype in get_all_int_dtypes() 1494: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False))) 1501: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False))) 1507: dtypes(*(get_all_complex_dtypes())) 1514: dtypes = list(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False)) 1523: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False))) 1531: if dtype in get_all_fp_dtypes(): 1608: dtypes(*(get_all_dtypes(include_half=True, include_bfloat16=False, 1837: dtypes(*get_all_dtypes(include_bool=False, include_complex=False)) 1855: dtypes(*(set(get_all_dtypes(include_bool=False, include_complex=False)) - {torch.uint8})) 3219: for dtype in get_all_dtypes(include_half=True, include_bfloat16=False, ``` </p> </details> <details> <summary> `test/test_serialization.py`</summary> <p> ```python 26:from torch.testing._internal.common_dtype import get_all_dtypes 586: for device, dtype in product(devices, get_all_dtypes()): 589: for other_dtype in get_all_dtypes(): ``` </p> </details> <details> <summary> `test/test_shape_ops.py`</summary> <p> ```python 18:from torch.testing._internal.common_dtype import get_all_dtypes 230: dtypes(*get_all_dtypes(include_complex=False, include_bool=False, include_half=False, 232: dtypesIfCUDA(*get_all_dtypes(include_complex=False, include_bool=False, include_bfloat16=False)) 344: dtypes(*get_all_dtypes()) 443: dtypes(*get_all_dtypes()) 461: dtypes(*get_all_dtypes()) 570: dtypes(*get_all_dtypes(include_complex=False)) ``` </p> </details> <details> <summary> `test/test_sort_and_select.py`</summary> <p> ```python 12: all_types, all_types_and, floating_types_and, get_all_dtypes, get_all_int_dtypes, get_all_fp_dtypes, 136: dtypes(*set(get_all_dtypes()) - {torch.bool, torch.complex64, torch.complex128}) 231: dtypes(*set(get_all_dtypes()) - {torch.bool, torch.complex64, torch.complex128}) 296: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 647: dtypesIfCUDA(*get_all_fp_dtypes()) 678: dtypesIfCUDA(*(get_all_dtypes(include_complex=False, 682: dtypes(*(get_all_dtypes(include_complex=False, include_bool=False, include_half=False, include_bfloat16=False))) 739: dtypesIfCPU(*set(get_all_dtypes()) - {torch.complex64, torch.complex128}) 740: dtypes(*set(get_all_dtypes()) - {torch.bfloat16, torch.complex64, torch.complex128}) 799: dtypesIfCPU(*set(get_all_dtypes()) - {torch.complex64, torch.complex128}) 800: dtypes(*set(get_all_dtypes()) - {torch.bfloat16, torch.complex64, torch.complex128}) ``` </p> </details> <details> <summary> `test/test_sparse.py`</summary> <p> ```python 20:from torch.testing import get_all_complex_dtypes, get_all_fp_dtypes 29: floating_and_complex_types, floating_and_complex_types_and, get_all_dtypes, get_all_int_dtypes, 1963: return dtype in get_all_int_dtypes() 1994: dtypes(*get_all_dtypes(include_bool=False, include_half=False, 2103: return dtype in get_all_int_dtypes() 2138: dtypes(*get_all_dtypes(include_bool=False, include_half=False, 2626: all_sparse_dtypes = get_all_dtypes(include_complex=True) 2633: all_sparse_dtypes = get_all_dtypes(include_complex=True) 3230: dtypes(*get_all_complex_dtypes(), 3231: *get_all_fp_dtypes(include_half=False, include_bfloat16=False)) 3234: *get_all_fp_dtypes( ``` </p> </details> <details> <summary> `test/test_sparse_csr.py`</summary> <p> ```python 7:from torch.testing import get_all_complex_dtypes, get_all_fp_dtypes, floating_and_complex_types, make_tensor 17:from torch.testing._internal.common_dtype import floating_types, get_all_dtypes 120: dtypes(*get_all_dtypes()) 133: dtypes(*get_all_dtypes()) 150: dtypes(*get_all_dtypes()) 180: dtypes(*get_all_dtypes()) 201: dtypes(*get_all_dtypes()) 210: dtypes(*get_all_dtypes()) 225: dtypes(*get_all_dtypes()) 244: dtypes(*get_all_dtypes()) 263: dtypes(*get_all_dtypes()) 285: dtypes(*get_all_dtypes()) 411: dtypes(*get_all_dtypes()) 482: dtypes(*get_all_dtypes()) 502: dtypes(*get_all_dtypes()) 562: dtypes(*get_all_dtypes()) 588: dtypesIfCUDA(*get_all_complex_dtypes(), 589: *get_all_fp_dtypes(include_half=SM53OrLater, include_bfloat16=SM80OrLater)) 745: dtypesIfCUDA(*get_all_complex_dtypes(), 746: *get_all_fp_dtypes(include_half=SM53OrLater and TEST_CUSPARSE_GENERIC, 765: dtypesIfCUDA(*get_all_complex_dtypes(), 766: *get_all_fp_dtypes(include_half=SM53OrLater and TEST_CUSPARSE_GENERIC, 801: *torch.testing.get_all_fp_dtypes(include_bfloat16=SM80OrLater, 841: *torch.testing.get_all_fp_dtypes(include_bfloat16=SM80OrLater, 1182: dtypes(*get_all_dtypes()) 1276: dtypes(*get_all_dtypes(include_bool=False, include_half=False, include_bfloat16=False)) 1286: dtypes(*get_all_dtypes()) ``` </p> </details> <details> <summary> `test/test_tensor_creation_ops.py`</summary> <p> ```python 21: onlyCUDA, skipCPUIf, dtypesIfCUDA, skipMeta, get_all_device_types) 23: get_all_dtypes, get_all_math_dtypes, get_all_int_dtypes, get_all_fp_dtypes, get_all_complex_dtypes 150: for dt in get_all_dtypes(): 160: for dt in get_all_dtypes(): 314: dtypes = [dtype for dtype in get_all_dtypes() if dtype != torch.bfloat16] 1012: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False) + 1013: get_all_complex_dtypes())) 1032: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False) + 1033: get_all_complex_dtypes())) 1050: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False) + 1051: get_all_complex_dtypes())) 1745: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 1779: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 1868: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 1926: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 1954: do_test_empty_full(self, get_all_math_dtypes('cpu'), torch.strided, torch_device) 1956: do_test_empty_full(self, get_all_math_dtypes('cpu'), torch.strided, None) 1957: do_test_empty_full(self, get_all_math_dtypes('cpu'), torch.strided, torch_device) 2538: for device in get_all_device_types(): 2645: for dtype in get_all_dtypes(): 2678: dtypes(*(get_all_fp_dtypes(include_half=False, include_bfloat16=False) + 2679: get_all_complex_dtypes())) 2716: dtypes(*get_all_fp_dtypes(include_half=False, include_bfloat16=False)) 2827: for dt in get_all_dtypes(): 2913: dtypes(*get_all_dtypes(include_bool=False, include_half=False)) 2914: dtypesIfCUDA(*get_all_dtypes(include_bool=False, include_half=True)) 3028: dtypes(*(get_all_fp_dtypes() + get_all_complex_dtypes())) 3033: dtypes(*(get_all_fp_dtypes() + get_all_complex_dtypes())) 3074: dtypes(*get_all_dtypes(include_bool=False, include_half=False, include_complex=False)) 3075: dtypesIfCUDA(*((get_all_int_dtypes() + [torch.float32, torch.float16, torch.bfloat16]) 3077: else get_all_dtypes(include_bool=False, include_half=True, include_complex=False))) 3873: dtypes(*get_all_dtypes()) 3884: dtypes(*get_all_dtypes(include_bool=False)) 3916: for other in get_all_dtypes(): 3922: dtypes(*get_all_dtypes()) 3932: dtypes(*get_all_dtypes(include_bool=False)) 3955: dtypes(*get_all_dtypes(include_bool=False)) 3961: dtypes(*get_all_dtypes(include_bool=False)) 3965: dtypes(*get_all_dtypes()) ``` </p> </details> <details> <summary> `test/test_testing.py`</summary> <p> ```python 25:from torch.testing._internal.common_dtype import get_all_dtypes 31: dtypes(*(get_all_dtypes(include_half=True, include_bfloat16=False, ``` </p> </details> <details> <summary> `test/test_torch.py`</summary> <p> ```python 51: expectedAlertNondeterministic, get_all_device_types, skipXLA) 57: get_all_fp_dtypes, get_all_int_dtypes, get_all_math_dtypes, get_all_dtypes, get_all_complex_dtypes 296: for d in get_all_device_types(): 323: for device in get_all_device_types(): 324: for dt1 in get_all_dtypes(): 325: for dt2 in get_all_dtypes(): 343: all_dtypes = get_all_dtypes() 350: all_dtypes = get_all_dtypes() 781: for dtype in get_all_dtypes(): 986: for device in get_all_device_types(): 1017: for device in get_all_device_types(): 1018: for dtype in get_all_math_dtypes(device): 2792: for device in get_all_device_types(): 3186: dtypes(*get_all_dtypes()) 3195: for error_dtype in get_all_dtypes(): 3203: dtypes(*get_all_dtypes()) 3212: for error_dtype in get_all_dtypes(): 4539: dtypes(*get_all_fp_dtypes()) 4545: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 4577: dtypes(*get_all_fp_dtypes(include_half=False, include_bfloat16=False)) 4578: dtypesIfCPU(*(get_all_fp_dtypes(include_half=False, include_bfloat16=True))) 4579: dtypesIfCUDA(*(get_all_fp_dtypes(include_bfloat16=False))) 4599: dtypes(*(get_all_fp_dtypes(include_half=False, include_bfloat16=False))) 4600: dtypesIfCPU(*(get_all_dtypes(include_half=False, include_bfloat16=False, include_complex=False))) 4601: dtypesIfCUDA(*(get_all_dtypes(include_bfloat16=False, include_complex=False))) 4613: for p_dtype in get_all_fp_dtypes(include_half=device.startswith('cuda'), include_bfloat16=False): 4628: dtypes(*(get_all_fp_dtypes(include_half=False, include_bfloat16=False))) 4629: dtypesIfCUDA(*(get_all_fp_dtypes(include_bfloat16=False))) 4640: dtypes(*get_all_fp_dtypes()) 4723: dtypes(*get_all_fp_dtypes()) 4735: dtypes(*get_all_fp_dtypes(include_bfloat16=False)) 4736: dtypesIfCUDA(*get_all_fp_dtypes()) 4747: dtypes(*get_all_fp_dtypes()) 4761: dtypes(*get_all_fp_dtypes()) 4771: dtypes(*get_all_fp_dtypes()) 4792: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 5302: dtypes(*get_all_dtypes(include_bfloat16=False)) 5322: dtypes(*get_all_dtypes(include_half=False, include_bfloat16=False)) 5323: dtypesIfCPU(*get_all_dtypes(include_bfloat16=False)) 5324: dtypesIfCUDA(*get_all_dtypes(include_bfloat16=False)) 5591: for dt in get_all_dtypes(): 5611: for dt in get_all_dtypes(): 5678: for dt in get_all_dtypes(): 5696: dtypesIfCUDA(*set(get_all_math_dtypes('cuda'))) 5697: dtypes(*set(get_all_math_dtypes('cpu'))) 5746: dtypes(*get_all_dtypes()) 5780: dtypes(*get_all_dtypes()) 5885: dtypes(*get_all_dtypes()) 5902: dtypes(*get_all_dtypes()) 5945: dtypes(*get_all_dtypes()) 5979: dtypes(*get_all_dtypes(include_bool=False)) 6049: dtypes(*get_all_dtypes(include_bool=False)) 6092: dtypes(*(get_all_fp_dtypes(include_bfloat16=False, include_half=False) + 6093: get_all_complex_dtypes())) 6094: dtypesIfCPU(*get_all_dtypes()) 6095: dtypesIfCUDA(*get_all_dtypes()) 6122: dtypes(*(get_all_fp_dtypes(include_bfloat16=False, include_half=False) + 6123: get_all_complex_dtypes())) 6124: dtypesIfCPU(*get_all_dtypes()) 6125: dtypesIfCUDA(*get_all_dtypes()) 6163: dtypes(*(get_all_fp_dtypes(include_bfloat16=False, include_half=False) + 6164: get_all_complex_dtypes())) 6165: dtypesIfCPU(*get_all_dtypes()) 6166: dtypesIfCUDA(*get_all_dtypes()) 6190: dtypes(*(get_all_complex_dtypes() + 6191: get_all_int_dtypes())) 6238: dtypes(*get_all_dtypes()) 6323: dtypes(*get_all_dtypes()) 6389: dtypes(*product(get_all_dtypes(), (torch.uint8, torch.bool))) 6699: dtypesIfCUDA(*set(get_all_math_dtypes('cuda'))) 6700: dtypes(*set(get_all_math_dtypes('cpu'))) 7452: dtypes(*get_all_dtypes(include_bool=False)) 7461: dtypes(*get_all_dtypes(include_bool=False)) 7477: dtypes(*get_all_dtypes(include_bool=False)) 7496: dtypes(*get_all_dtypes(include_bool=False)) 7538: dtypes(*get_all_dtypes(include_bool=False)) 8162: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes() + 8163: get_all_complex_dtypes())) 8175: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes() + 8176: get_all_complex_dtypes())) ``` </p> </details> <details> <summary> `test/test_type_promotion.py`</summary> <p> ```python 14: get_all_dtypes, get_all_math_dtypes, get_all_int_dtypes, get_all_fp_dtypes 187: for dtype in get_all_dtypes(): 262: dtypes1 = get_all_math_dtypes('cuda') 263: dtypes2 = get_all_math_dtypes(device) 339: dtypes(*itertools.product(get_all_dtypes(), get_all_dtypes())) 468: for dt1 in get_all_math_dtypes(device): 469: for dt2 in get_all_math_dtypes(device): 519: for dt1 in get_all_math_dtypes(device): 520: for dt2 in get_all_math_dtypes(device): 528: for dt in get_all_math_dtypes(device): 561: for dtype in get_all_dtypes(): 766: dtypes=get_all_math_dtypes(device)) 771: dtypes=get_all_math_dtypes(device)) 782: dtypes=get_all_math_dtypes(device)) 879: dtypes = get_all_dtypes(include_bfloat16=False) 898: dtypes = get_all_dtypes(include_bfloat16=False, include_bool=False) 965: dtypesIfCUDA(*itertools.product(get_all_dtypes(include_bfloat16=False, include_complex=False), 966: get_all_dtypes(include_bfloat16=False, include_complex=False))) 967: dtypes(*itertools.product(get_all_dtypes(include_half=False, include_bfloat16=False, 969: get_all_dtypes(include_half=False, include_bfloat16=False, 976: return dtype in get_all_int_dtypes() + [torch.bool] 979: return dtype in get_all_fp_dtypes(include_half=True, include_bfloat16=False) ``` </p> </details> <details> <summary> `test/test_unary_ufuncs.py`</summary> <p> ```python 24: floating_types_and, all_types_and_complex_and, floating_and_complex_types_and, get_all_dtypes, get_all_math_dtypes, 25: get_all_int_dtypes, get_all_fp_dtypes, get_all_complex_dtypes 517: dtypes(*(get_all_int_dtypes() + [torch.bool] + 518: get_all_fp_dtypes(include_bfloat16=False))) 596: dtypes(*get_all_fp_dtypes(include_half=True, include_bfloat16=False)) 611: invalid_input_dtypes = get_all_int_dtypes() + \ 612: get_all_complex_dtypes() + \ 619: for dtype in get_all_fp_dtypes(include_half=True, include_bfloat16=False): 1048: dtypes(*get_all_math_dtypes('cpu')) 1182: dtypesIfCUDA(*get_all_fp_dtypes()) 1190: dtypesIfCUDA(*get_all_fp_dtypes()) 1205: dtypesIfCUDA(*get_all_fp_dtypes()) 1215: dtypesIfCUDA(*get_all_fp_dtypes()) 1307: dtypes(*(get_all_dtypes(include_bool=False))) 1349: dtypes(*(get_all_fp_dtypes(include_half=False) + 1350: get_all_complex_dtypes())) 1351: dtypesIfCUDA(*(get_all_fp_dtypes(include_half=True) + 1352: get_all_complex_dtypes())) ``` </p> </details> <details> <summary> `test/test_view_ops.py`</summary> <p> ```python 19: get_all_dtypes, get_all_int_dtypes, get_all_fp_dtypes, get_all_complex_dtypes 124: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 131: dtypes(*get_all_dtypes(include_bfloat16=False)) 213: for view_dtype in [*get_all_fp_dtypes(), *get_all_complex_dtypes()]: 220: dtypes(*get_all_dtypes()) 224: for view_dtype in get_all_dtypes(): 305: dtypes(*get_all_complex_dtypes(include_complex32=True)) 343: dtypes(*get_all_dtypes()) 354: dtypes(*get_all_dtypes()) 364: dtypes(*get_all_dtypes()) 374: dtypes(*get_all_dtypes()) 384: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes())) 395: dtypes(*get_all_complex_dtypes()) 426: dtypes(*get_all_complex_dtypes()) 451: dtypes(*product(get_all_complex_dtypes(), get_all_dtypes())) 1263: dtypes(*(torch.testing.get_all_dtypes())) 1279: dtypes(*(torch.testing.get_all_dtypes())) 1405: dtypes(*(get_all_int_dtypes() + get_all_fp_dtypes(include_bfloat16=False) + 1406: get_all_complex_dtypes())) 1471: dtypes(*get_all_dtypes(include_bfloat16=False)) 1574: dtypes(*get_all_dtypes()) 1601: dtypes(*get_all_dtypes(include_bfloat16=False)) 1632: dtypes(*get_all_dtypes(include_bfloat16=False)) 1711: for dt in get_all_dtypes(): 1717: for dt in get_all_dtypes(): 1724: for dt in get_all_dtypes(): ``` </p> </details> I'm looking forward to your viewpoints. Thanks :) cc: mruberry kshitij12345 anjali411 Pull Request resolved: https://github.com/pytorch/pytorch/pull/71561 Reviewed By: samdow Differential Revision: D34856571 Pulled By: mruberry fbshipit-source-id: 0dca038bcad5cf69906245c496d2e61ac3876335 (cherry picked from commit b058f67b4313143efa714ab105f36e74083131b9) |
||
|
|
0973c5a1cc |
align signature of make_tensor with other creation ops (#72702)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/72702 Test Plan: Imported from OSS Reviewed By: mrshenli Differential Revision: D34457729 Pulled By: mruberry fbshipit-source-id: 83d580c4201eef946dc9cf4b9e28a3d36be55609 (cherry picked from commit aa4cf20fbeb4b795595729b8ac2e6ba7707d8283) |
||
|
|
885a8e53ba |
replace onlyOnCPUAndCUDA with onlyNativeDeviceTypes (#65201)
Summary: Reference https://github.com/pytorch/pytorch/issues/53849 Replace `onlyOnCPUandCUDA` with `onlyNativeDeviceTypes` which includes `cpu, cuda and meta`. Pull Request resolved: https://github.com/pytorch/pytorch/pull/65201 Reviewed By: mrshenli Differential Revision: D31299718 Pulled By: mruberry fbshipit-source-id: 2d8356450c035d6a314209ab51b2c237583920fd |
||
|
|
8a65047acc |
[skip ci] Set test owners for everything considered with module: tests (#66865)
Summary: Action following https://github.com/pytorch/pytorch/issues/66232 cc mruberry Pull Request resolved: https://github.com/pytorch/pytorch/pull/66865 Reviewed By: anjali411 Differential Revision: D31771147 Pulled By: janeyx99 fbshipit-source-id: 8bebe5ac2098364ef1ee93b590abb5f4455b0f89 |
||
|
|
26b7ff5aea |
deprecate dtype getters from torch.testing namespace (#63554)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/63554 Following https://github.com/pytorch/pytorch/pull/61840#issuecomment-884087809, this deprecates all the dtype getters publicly exposed in the `torch.testing` namespace. The reason for this twofold: 1. If someone is not familiar with the C++ dispatch macros PyTorch uses, the names are misleading. For example `torch.testing.floating_types()` will only give you `float32` and `float64` skipping `float16` and `bfloat16`. 2. The dtype getters provide very minimal functionality that can be easily emulated by downstream libraries. We thought about [providing an replacement](https://gist.github.com/pmeier/3dfd2e105842ad0de4505068a1a0270a), but ultimately decided against it. The major problem is BC: by keeping it, either the namespace is getting messy again after a new dtype is added or we need to somehow version the return values of the getters. Test Plan: Imported from OSS Reviewed By: H-Huang Differential Revision: D30662206 Pulled By: mruberry fbshipit-source-id: a2bdb10ab02ae665df1b5b76e8afa9af043bbf56 |
||
|
|
d37636901e |
[Doc] make_tensor to torch.testing module (#63925)
Summary: This PR aims to add `make_tensor` to the `torch.testing` module in PyTorch docs. TODOs: * [x] Add examples cc: pmeier mruberry brianjo Pull Request resolved: https://github.com/pytorch/pytorch/pull/63925 Reviewed By: ngimel Differential Revision: D30633487 Pulled By: mruberry fbshipit-source-id: 8e5a1f880c6ece5925b4039fee8122bd739538af |
||
|
|
1022443168 |
Revert D30279364: [codemod][lint][fbcode/c*] Enable BLACK by default
Test Plan: revert-hammer
Differential Revision:
D30279364 (
|
||
|
|
b004307252 |
[codemod][lint][fbcode/c*] Enable BLACK by default
Test Plan: manual inspection & sandcastle Reviewed By: zertosh Differential Revision: D30279364 fbshipit-source-id: c1ed77dfe43a3bde358f92737cd5535ae5d13c9a |
||
|
|
08020220f3 |
[Testing] Adding reference tests to OpInfo class (#59369)
Summary: This PR will ideally add `ref` argument to `OpInfo` base class. The idea is to add reference checks for all the ops _eligible_. For more discussion, please check https://github.com/pytorch/pytorch/issues/58294 * [x] Migrate (but not removing yet) and modify helper functions from `UnaryUfuncOpInfo` class to `OpInfo` base class. * [x] Test the reference checks for multiple ops. (also decide a list of different and eligible ops for this) * [x] Handle possible edge cases (for example: `uint64` isn't implemented in PyTorch but is there in NumPy, and this needs to be handled -- more on this later) -- _Update_: We decided that these reference tests should only test for values and not types. * [x] Create a sample PR for a single (of all different categories?) on adding reference functions to the eligible ops. -- _Update_: This is being done in this PR only. * [x] ~Remove reference tests from `test_unary_ufuncs.py` and test to make sure that nothing breaks.~ (*Update*: We won't be touching Unary Ufunc reference tests in this PR) * [x] Add comments, remove unnecessary prints/comments (added for debugging). Note: To keep the PR description short, examples of edge cases encountered have been mentioned in the comments below. cc: mruberry pmeier kshitij12345 Pull Request resolved: https://github.com/pytorch/pytorch/pull/59369 Reviewed By: ngimel Differential Revision: D29347252 Pulled By: mruberry fbshipit-source-id: 69719deddb1d23c53db45287a7e66c1bfe7e65bb |
||
|
|
344ecb2e71 |
flip via TI (#59509)
Summary: Resubmit of https://github.com/pytorch/pytorch/issues/58747 Pull Request resolved: https://github.com/pytorch/pytorch/pull/59509 Reviewed By: mruberry Differential Revision: D28918665 Pulled By: ngimel fbshipit-source-id: b045c7b35eaf22e53b1bc359ffbe5a4fda05dcda |
||
|
|
5117ac3bb4 |
Revert D28877076: [pytorch][PR] torch.flip via TI
Test Plan: revert-hammer
Differential Revision:
D28877076 (
|
||
|
|
d82bc3feb8 |
torch.flip via TI (#58747)
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
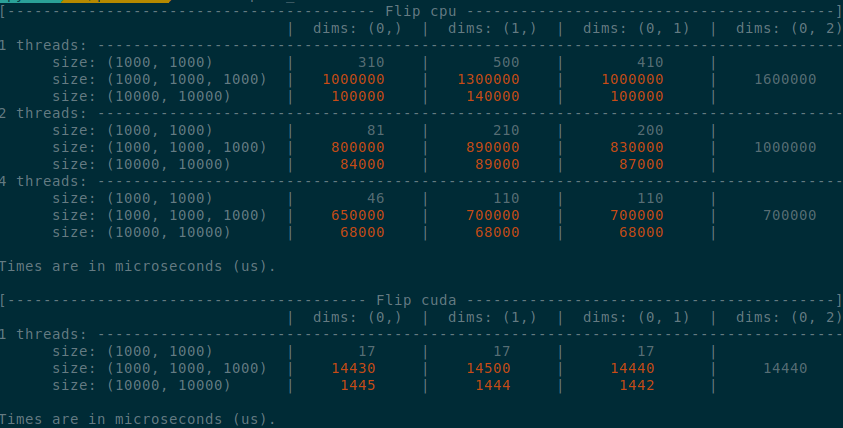
</details>
<details>
<summary>
Benchmark master
</summary>
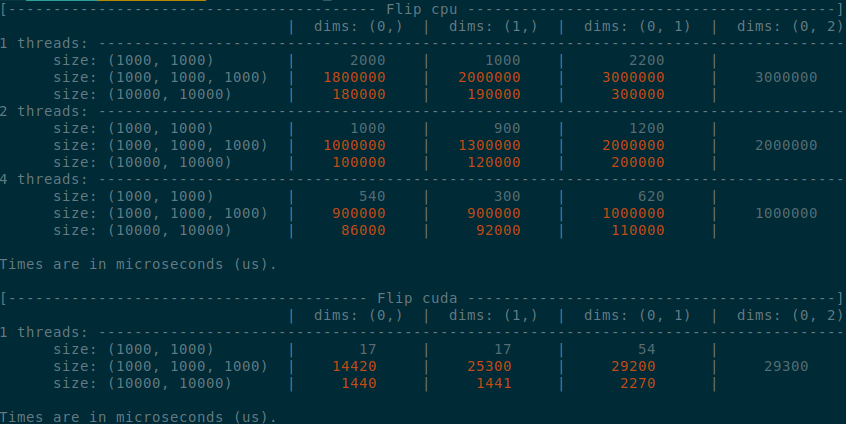
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
|
||
|
|
f7f8540794 |
Fix tensor device in test_kthvalue_overlap (#56869)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/56869 ghstack-source-id: 127914015 Test Plan: auto test Reviewed By: ezyang Differential Revision: D27986559 fbshipit-source-id: f4a638d737b06dd5f384b54e20490d76543d4e78 |
||
|
|
93bf0ae6fc |
Remove legacy constructor calls from pytorch codebase. (#54142)
Summary: Follow up from https://github.com/pytorch/pytorch/issues/53889 Related to https://github.com/pytorch/pytorch/issues/47112 Removing every occurrence of the legacy constructor call present in PyTorch at: - _docs_ - _benchmarks_ - _test_ - _caffe2_ - _CONTRIBUTING.md_ Pull Request resolved: https://github.com/pytorch/pytorch/pull/54142 Reviewed By: ngimel Differential Revision: D27699450 Pulled By: mruberry fbshipit-source-id: 530aa3f5746cc8bc1407d5d51b2bbd8075e30546 |
||
|
|
6d87b3667f |
Added support for TensorList inputs in OpInfo (#54922)
Summary: Stack: * https://github.com/pytorch/pytorch/issues/54954 Fixed OpInfo jit tests failing for TensorList inputs * __#54922 Added support for TensorList inputs in OpInfo__ Updated OpInfo to accept either a `Tensor` or `TensorList` as `sample.input` and added workarounds to make this work with gradcheck. Note: JIT testing support for TensorList inputs will be added in a follow up PR. Fixes https://github.com/pytorch/pytorch/issues/51996 Pull Request resolved: https://github.com/pytorch/pytorch/pull/54922 Reviewed By: H-Huang Differential Revision: D27448952 Pulled By: heitorschueroff fbshipit-source-id: 3f24a56f6180eb2d044dcfc89ba59fce8acfe278 |
||
|
|
7b939d934e |
Simplifes OpInfo test matrix to reduce test time (#53255)
Summary: This PR: - Updates the structure of the SampleInput class to require the "input" attribute be a tensor - Limits unary ufuncs to test only the uint8, long, float16, bfloat16, float and cfloat dtypes by default - Limits variant testing to the float dtype - Removes test_variant_consistency from test_unary_ufuncs.py since it's now redundant with variant testing in test_ops.py - Adds backwards supported testing to clarify failures that were coming from variant testing This should decrease test e2e time. Pull Request resolved: https://github.com/pytorch/pytorch/pull/53255 Reviewed By: ngimel Differential Revision: D27043643 Pulled By: mruberry fbshipit-source-id: 91d6b483ad6e2cd1b9ade939d42082980ae14217 |
||
|
|
de7eeb7752 |
Removes nonzero method warning (#51618)
Summary: Fixes https://github.com/pytorch/pytorch/issues/44284 https://github.com/pytorch/pytorch/pull/45413 incorrectly left this only partially fixed because it did not update the separate list of method signatures that were deprecated. This PR correctly fixes https://github.com/pytorch/pytorch/issues/44284. A test is added for the behavior, but until the WARN_ONCE flag is added it's toothless. Pull Request resolved: https://github.com/pytorch/pytorch/pull/51618 Reviewed By: ngimel Differential Revision: D26220181 Pulled By: mruberry fbshipit-source-id: 397b47ac7e962d108d8fde0f3dc6468d6327d1c3 |
||
|
|
316f0b89c3 |
[testing] Port torch.{repeat, tile} tests to use OpInfo machinery (#50199)
Summary: Reference: https://github.com/pytorch/pytorch/issues/50013 Pull Request resolved: https://github.com/pytorch/pytorch/pull/50199 Reviewed By: ngimel Differential Revision: D25949791 Pulled By: mruberry fbshipit-source-id: 10eaf2d749fac8c08847f50461e72ad1c75c61e3 |
||
|
|
314351d0ef |
Fix Error with torch.flip() for cuda tensors when dims=() (#50325)
Summary: Fixes https://github.com/pytorch/pytorch/issues/49982 The method flip_check_errors was being called in cuda file which had a condition to throw an exception for when dims size is <=0 changed that to <0 and added seperate condition for when equal to zero to return from the method... the return was needed because after this point the method was performing check expecting a non-zero size dims ... Also removed the comment/condition written to point to the issue mruberry kshitij12345 please review this once Pull Request resolved: https://github.com/pytorch/pytorch/pull/50325 Reviewed By: zhangguanheng66 Differential Revision: D25869559 Pulled By: mruberry fbshipit-source-id: a831df9f602c60cadcf9f886ae001ad08b137481 |
||
|
|
5d93e2b818 |
torch.flip and torch.flip{lr, ud}: Half support for CPU and BFloat16 support for CPU & CUDA (#49895)
Summary: Fixes https://github.com/pytorch/pytorch/issues/49889 Also adds BFloat16 support for CPU and CUDA Pull Request resolved: https://github.com/pytorch/pytorch/pull/49895 Reviewed By: mrshenli Differential Revision: D25746272 Pulled By: mruberry fbshipit-source-id: 0b6a9bc13ae60c22729a0aea002ed857c36f14ff |
||
|
|
5c9cef9a6c |
[numpy] Add torch.moveaxis (#48581)
Summary: Reference: https://github.com/pytorch/pytorch/issues/38349 #36048 https://github.com/pytorch/pytorch/pull/41480#issuecomment-734398262 Pull Request resolved: https://github.com/pytorch/pytorch/pull/48581 Reviewed By: bdhirsh Differential Revision: D25276307 Pulled By: mruberry fbshipit-source-id: 3e3e4df1343c5ce5b71457badc43f08c419ec5c3 |
||
|
|
36c87f1243 |
Refactors test_torch.py to be fewer than 10k lines (#47356)
Summary: Creates multiple new test suites to have fewer tests in test_torch.py, consistent with previous test suite creation like test_unary_ufuncs.py and test_linalg.py. Pull Request resolved: https://github.com/pytorch/pytorch/pull/47356 Reviewed By: ngimel Differential Revision: D25202268 Pulled By: mruberry fbshipit-source-id: 75fde3ca76545d1b32b86d432a5cb7a5ba8f5bb6 |
{kind=link}
{kind=link}