Summary:
Fixes https://github.com/pytorch/pytorch/issues/45687
Fix changes the input size check for `InstanceNorm*d` to be more restrictive and correctly reject sizes with only a single spatial element, regardless of batch size, to avoid infinite variance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56659
Reviewed By: pbelevich
Differential Revision: D27948060
Pulled By: jbschlosser
fbshipit-source-id: 21cfea391a609c0774568b89fd241efea72516bb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53964. cc albanD almson
## Major changes:
- Overhauled the actual loss calculation so that the shapes are now correct (in functional.py)
- added the missing doc in nn.functional.rst
## Minor changes (in functional.py):
- I removed the previous check on whether input and target were the same shape. This is to allow for broadcasting, say when you have 10 predictions that all have the same target.
- I added some comments to explain each shape check in detail. Let me know if these should be shortened/cut.
Screenshots of updated docs attached.
Let me know what you think, thanks!
## Edit: Description of change of behaviour (affecting BC):
The backwards-compatibility is only affected for the `reduction='none'` mode. This was the source of the bug. For tensors with size (N, D), the old returned loss had size (N), as incorrect summation was happening. It will now have size (N, D) as expected.
### Example
Define input tensors, all with size (2, 3).
`input = torch.tensor([[0., 1., 3.], [2., 4., 0.]], requires_grad=True)`
`target = torch.tensor([[1., 4., 2.], [-1., 2., 3.]])`
`var = 2*torch.ones(size=(2, 3), requires_grad=True)`
Initialise loss with reduction mode 'none'. We expect the returned loss to have the same size as the input tensors, (2, 3).
`loss = torch.nn.GaussianNLLLoss(reduction='none')`
Old behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([3.7897, 6.5397], grad_fn=<MulBackward0>. This has size (2).`
New behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([[0.5966, 2.5966, 0.5966], [2.5966, 1.3466, 2.5966]], grad_fn=<MulBackward0>)`
`# This has the expected size, (2, 3).`
To recover the old behaviour, sum along all dimensions except for the 0th:
`print(loss(input, target, var).sum(dim=1))`
`# Gives tensor([3.7897, 6.5397], grad_fn=<SumBackward1>.`


Pull Request resolved: https://github.com/pytorch/pytorch/pull/56469
Reviewed By: jbschlosser, agolynski
Differential Revision: D27894170
Pulled By: albanD
fbshipit-source-id: 197890189c97c22109491c47f469336b5b03a23f
Summary:
Match updated `Embedding` docs from https://github.com/pytorch/pytorch/pull/54026 as closely as possible. Additionally, update the C++ side `Embedding` docs, since those were missed in the previous PR.
There are 6 (!) places for docs:
1. Python module form in `sparse.py` - includes an additional line about newly constructed `Embedding`s / `EmbeddingBag`s
2. Python `from_pretrained()` in `sparse.py` (refers back to module docs)
3. Python functional form in `functional.py`
4. C++ module options - includes an additional line about newly constructed `Embedding`s / `EmbeddingBag`s
5. C++ `from_pretrained()` options
6. C++ functional options
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56065
Reviewed By: malfet
Differential Revision: D27908383
Pulled By: jbschlosser
fbshipit-source-id: c5891fed1c9d33b4b8cd63500a14c1a77d92cc78
Summary:
As this diff shows, currently there are a couple hundred instances of raw `noqa` in the codebase, which just ignore all errors on a given line. That isn't great, so this PR changes all existing instances of that antipattern to qualify the `noqa` with respect to a specific error code, and adds a lint to prevent more of this from happening in the future.
Interestingly, some of the examples the `noqa` lint catches are genuine attempts to qualify the `noqa` with a specific error code, such as these two:
```
test/jit/test_misc.py:27: print(f"{hello + ' ' + test}, I'm a {test}") # noqa E999
test/jit/test_misc.py:28: print(f"format blank") # noqa F541
```
However, those are still wrong because they are [missing a colon](https://flake8.pycqa.org/en/3.9.1/user/violations.html#in-line-ignoring-errors), which actually causes the error code to be completely ignored:
- If you change them to anything else, the warnings will still be suppressed.
- If you add the necessary colons then it is revealed that `E261` was also being suppressed, unintentionally:
```
test/jit/test_misc.py:27:57: E261 at least two spaces before inline comment
test/jit/test_misc.py:28:35: E261 at least two spaces before inline comment
```
I did try using [flake8-noqa](https://pypi.org/project/flake8-noqa/) instead of a custom `git grep` lint, but it didn't seem to work. This PR is definitely missing some of the functionality that flake8-noqa is supposed to provide, though, so if someone can figure out how to use it, we should do that instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56272
Test Plan:
CI should pass on the tip of this PR, and we know that the lint works because the following CI run (before this PR was finished) failed:
- https://github.com/pytorch/pytorch/runs/2365189927
Reviewed By: janeyx99
Differential Revision: D27830127
Pulled By: samestep
fbshipit-source-id: d6dcf4f945ebd18cd76c46a07f3b408296864fcb
Summary:
This PR adds a `padding_idx` parameter to `nn.EmbeddingBag` and `nn.functional.embedding_bag`. As with `nn.Embedding`'s `padding_idx` argument, if an embedding's index is equal to `padding_idx` it is ignored, so it is not included in the reduction.
This PR does not add support for `padding_idx` for quantized or ONNX `EmbeddingBag` for opset10/11 (opset9 is supported). In these cases, an error is thrown if `padding_idx` is provided.
Fixes https://github.com/pytorch/pytorch/issues/3194
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49237
Reviewed By: walterddr, VitalyFedyunin
Differential Revision: D26948258
Pulled By: jbschlosser
fbshipit-source-id: 3ca672f7e768941f3261ab405fc7597c97ce3dfc
Summary:
* Lowering NLLLoss/CrossEntropyLoss to ATen dispatch
* This allows the MLC device to override these ops
* Reduce code duplication between the Python and C++ APIs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53789
Reviewed By: ailzhang
Differential Revision: D27345793
Pulled By: albanD
fbshipit-source-id: 99c0d617ed5e7ee8f27f7a495a25ab4158d9aad6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45667
First part of #3867 (Pooling operators still to do)
This adds a `padding='same'` mode to the interface of `conv{n}d`and `nn.Conv{n}d`. This should match the behaviour of `tensorflow`. I couldn't find it explicitly documented but through experimentation I found `tensorflow` returns the shape `ceil(len/stride)` and always adds any extra asymmetric padding onto the right side of the input.
Since the `native_functions.yaml` schema doesn't seem to support strings or enums, I've moved the function interface into python and it now dispatches between the numerically padded `conv{n}d` and the `_conv{n}d_same` variant. Underscores because I couldn't see any way to avoid exporting a function into the `torch` namespace.
A note on asymmetric padding. The total padding required can be odd if both the kernel-length is even and the dilation is odd. mkldnn has native support for asymmetric padding, so there is no overhead there, but for other backends I resort to padding the input tensor by 1 on the right hand side to make the remaining padding symmetrical. In these cases, I use `TORCH_WARN_ONCE` to notify the user of the performance implications.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D27170744
Pulled By: jbschlosser
fbshipit-source-id: b3d8a0380e0787ae781f2e5d8ee365a7bfd49f22
Summary:
I edited the documentation for `nn.SiLU` and `F.silu` to:
- Explain that SiLU is also known as swish and that it stands for "Sigmoid Linear Unit."
- Ensure that "SiLU" is correctly capitalized.
I believe these changes will help users find the function they're looking for by adding relevant keywords to the docs.
Fixes: N/A
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53239
Reviewed By: jbschlosser
Differential Revision: D26816998
Pulled By: albanD
fbshipit-source-id: b4e9976e6b7e88686e3fa7061c0e9b693bd6d198
Summary:
-Lower Relu6 to ATen
-Change Python and C++ to reflect change
-adds an entry in native_functions.yaml for that new function
-this is needed as we would like to intercept ReLU6 at a higher level with an XLA-approach codegen.
-Should pass functional C++ tests pass. But please let me know if more tests are required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52723
Reviewed By: ailzhang
Differential Revision: D26641414
Pulled By: albanD
fbshipit-source-id: dacfc70a236c4313f95901524f5f021503f6a60f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52257
## Background
Reverts MHA behavior for `bias` flag to that of v1.5: flag enables or disables both in and out projection biases.
Updates type annotations for both in and out projections biases from `Tensor` to `Optional[Tensor]` for `torch.jit.script` usage.
Note: With this change, `_LinearWithBias` defined in `torch/nn/modules/linear.py` is no longer utilized. Completely removing it would require updates to quantization logic in the following files:
```
test/quantization/test_quantized_module.py
torch/nn/quantizable/modules/activation.py
torch/nn/quantized/dynamic/modules/linear.py
torch/nn/quantized/modules/linear.py
torch/quantization/quantization_mappings.py
```
This PR takes a conservative initial approach and leaves these files unchanged.
**Is it safe to fully remove `_LinearWithBias`?**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52537
Test Plan:
```
python test/test_nn.py TestNN.test_multihead_attn_no_bias
```
## BC-Breaking Note
In v1.6, the behavior of `MultiheadAttention`'s `bias` flag was incorrectly changed to affect only the in projection layer. That is, setting `bias=False` would fail to disable the bias for the out projection layer. This regression has been fixed, and the `bias` flag now correctly applies to both the in and out projection layers.
Reviewed By: bdhirsh
Differential Revision: D26583639
Pulled By: jbschlosser
fbshipit-source-id: b805f3a052628efb28b89377a41e06f71747ac5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51909
Several scenarios don't work when trying to script `F.normalize`, notably when you try to symbolically trace through it with using the default argument:
```
import torch.nn.functional as F
import torch
from torch.fx import symbolic_trace
def f(x):
return F.normalize(x)
gm = symbolic_trace(f)
torch.jit.script(gm)
```
which leads to the error
```
RuntimeError:
normalize(Tensor input, float p=2., int dim=1, float eps=9.9999999999999998e-13, Tensor? out=None) -> (Tensor):
Expected a value of type 'float' for argument 'p' but instead found type 'int'.
:
def forward(self, x):
normalize_1 = torch.nn.functional.normalize(x, p = 2, dim = 1, eps = 1e-12, out = None); x = None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return normalize_1
Reviewed By: jamesr66a
Differential Revision: D26324308
fbshipit-source-id: 30dd944a6011795d17164f2c746068daac570cea
Summary:
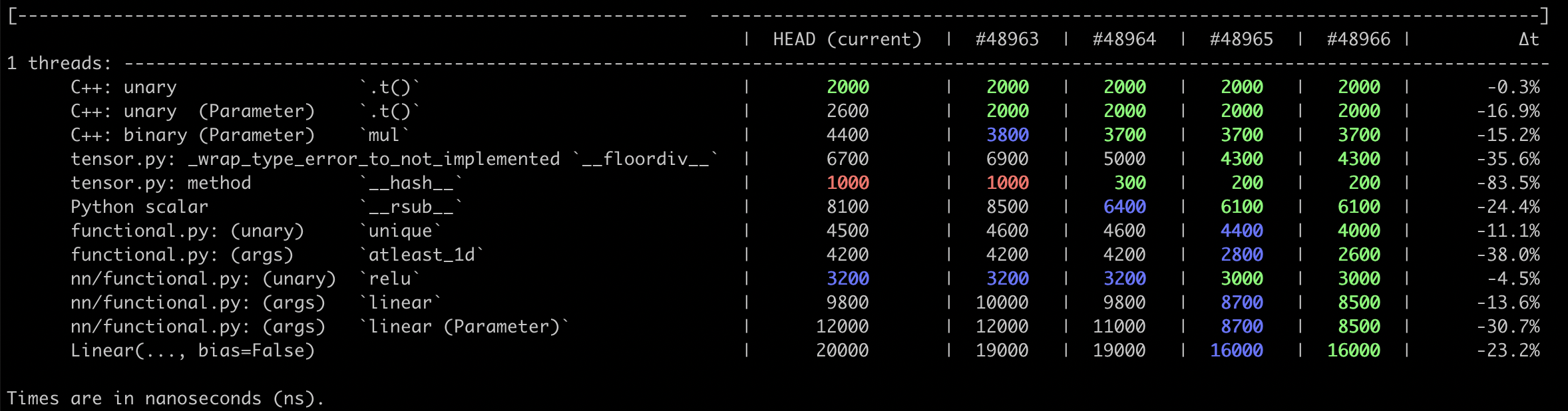
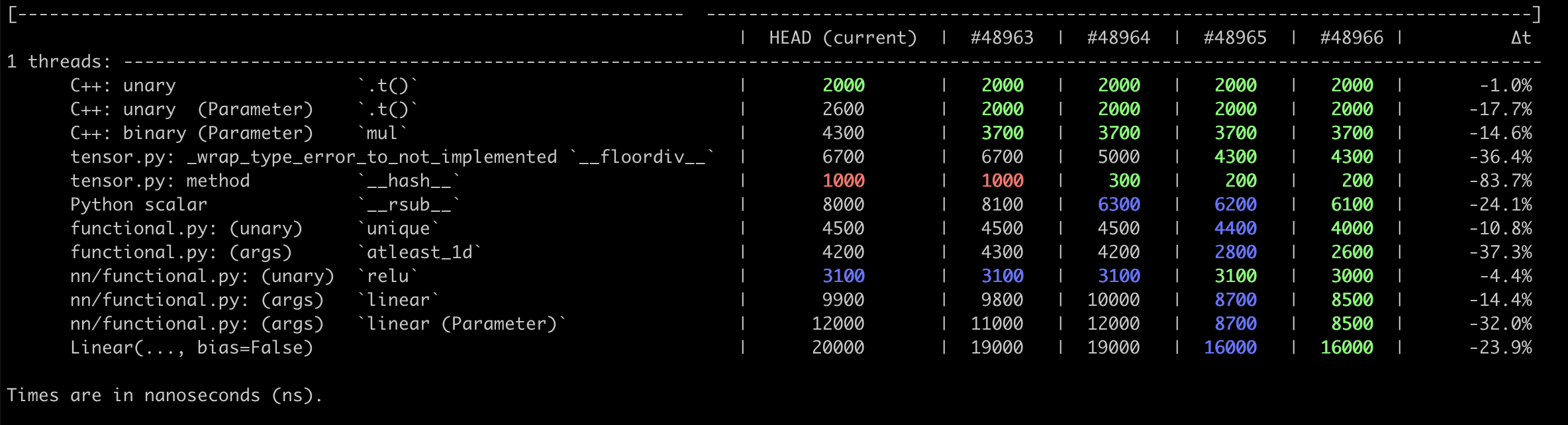
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48965
This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590732
Pulled By: robieta
fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47979
For MHA module, it is preferred to use the combined weight branch as much as possible when query/key/value are same (in case of same values by `torch.equal` or exactly same object by `is` ops). This PR will enable the faster branch when a single object with `nan` is passed to MHA.
For the background knowledge
```
import torch
a = torch.tensor([float('NaN'), 1, float('NaN'), 2, 3])
print(a is a) # True
print(torch.equal(a, a)) # False
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48126
Reviewed By: gchanan
Differential Revision: D25042082
Pulled By: zhangguanheng66
fbshipit-source-id: 6bb17a520e176ddbb326ddf30ee091a84fcbbf27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46758
It's in general helpful to support int32 indices and offsets, especially when such tensors are large and need to be transferred to accelerator backends. Since it may not be very useful to support the combination of int32 indices and int64 offsets, here we enforce that these two must have the same type.
Test Plan: unit tests
Reviewed By: ngimel
Differential Revision: D24470808
fbshipit-source-id: 94b8a1d0b7fc9fe3d128247aa042c04d7c227f0b
Summary:
Fix https://github.com/pytorch/pytorch/issues/44601
I added bicubic grid sampler in both cpu and cuda side, but haven't in AVX2
There is a [colab notebook](https://colab.research.google.com/drive/1mIh6TLLj5WWM_NcmKDRvY5Gltbb781oU?usp=sharing) show some test results. The notebook use bilinear for test, since I could only use distributed version of pytorch in it. You could just download it and modify the `mode_torch=bicubic` to show the results.
There are some duplicate code about getting and setting values, since the helper function used in bilinear at first clip the coordinate beyond boundary, and then get or set the value. However, in bicubic, there are more points should be consider. I could refactor that part after making sure the overall calculation are correct.
Thanks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44780
Reviewed By: mrshenli
Differential Revision: D24681114
Pulled By: mruberry
fbshipit-source-id: d39c8715e2093a5a5906cb0ef040d62bde578567
Summary:
Many of our functions contain same warnings about results reproducibility. Make them use common template.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45748
Reviewed By: colesbury
Differential Revision: D24089114
Pulled By: ngimel
fbshipit-source-id: e6aa4ce6082f6e0f4ce2713c2bf1864ee1c3712a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44486
SmoothL1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the SmoothL1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23630699
Pulled By: gchanan
fbshipit-source-id: 0f94d1a928002122d6b6875182867618e713a917
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43025
- Use new overloads that better reflect the arguments to interpolate.
- More uniform interface for upsample ops allows simplifying the Python code.
- Also reorder overloads in native_functions.yaml to give them priority.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37177
ghstack-source-id: 106938111
Test Plan:
test_nn has pretty good coverage.
Relying on CI for ONNX, etc.
Didn't test FC because this change is *not* forward compatible.
To ensure backwards compatibility, I ran this code before this change
```python
def test_func(arg):
interp = torch.nn.functional.interpolate
with_size = interp(arg, size=(16,16))
with_scale = interp(arg, scale_factor=[2.1, 2.2], recompute_scale_factor=False)
with_compute = interp(arg, scale_factor=[2.1, 2.2])
return (with_size, with_scale, with_compute)
traced_func = torch.jit.trace(test_func, torch.randn(1,1,1,1))
sample = torch.randn(1, 3, 7, 7)
output = traced_func(sample)
assert not torch.allclose(output[1], output[2])
torch.jit.save(traced_func, "model.pt")
torch.save((sample, output), "data.pt")
```
then this code after this change
```python
model = torch.jit.load("model.pt")
sample, golden = torch.load("data.pt")
result = model(sample)
for r, g in zip(result, golden):
assert torch.allclose(r, g)
```
Reviewed By: AshkanAliabadi
Differential Revision: D21209991
fbshipit-source-id: 5b2ebb7c3ed76947361fe532d1dbdd6faa3544c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44471
L1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the L1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23626008
Pulled By: gchanan
fbshipit-source-id: 2828be16b56b8dabe114962223d71b0e9a85f0f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44437
MSELoss had a completely different (and incorrect, see https://github.com/pytorch/pytorch/issues/43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the MSELoss CriterionTests to verify that the target derivative is checked.
TODO:
1) do we still need check_criterion_jacobian when we run grad/gradgrad checks?
2) ensure the Module tests check when target.requires_grad
3) do we actually test when reduction='none' and reduction='mean'?
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23612166
Pulled By: gchanan
fbshipit-source-id: 4f74d38d8a81063c74e002e07fbb7837b2172a10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}