Summary:
**BC-breaking note**
For ease of exposition let a_min be the value of the "min" argument to clamp, and a_max be the value of the "max" argument to clamp.
This PR changes the behavior of torch.clamp to always compute min(max(a, a_min), a_max). torch.clamp currently computes this in its vectorized CPU specializations:
78b95b6204/aten/src/ATen/cpu/vec256/vec256_double.h (L304)
but in other places it clamps differently:
78b95b6204/aten/src/ATen/cpu/vec256/vec256_base.h (L624)78b95b6204/aten/src/ATen/native/cuda/UnaryOpsKernel.cu (L160)
These implementations are the same when a_min < a_max, but divergent when a_min > a_max. This divergence is easily triggered:
```
t = torch.arange(200).to(torch.float)
torch.clamp(t, 4, 2)[0]
: tensor(2.)
torch.clamp(t.cuda(), 4, 2)[0]
: tensor(4., device='cuda:0')
torch.clamp(torch.tensor(0), 4, 2)
: tensor(4)
```
This PR makes the behavior consistent with NumPy's clip. C++'s std::clamp's behavior is undefined when a_min > a_max, but Clang's std::clamp will return 10 in this case (although the program, per the above comment, is in error). Python has no standard clamp implementation.
**PR Summary**
Fixes discrepancy between AVX, CUDA, and base vector implementation for clamp, such that all implementations are consistent and use min(max_vec, max(min_vec, x) formula, thus making it equivalent to numpy.clip in all implementations.
The same fix as in https://github.com/pytorch/pytorch/issues/32587 but isolated to the kernel change only, so that the internal team can benchmark.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43288
Reviewed By: colesbury
Differential Revision: D24079453
Pulled By: mruberry
fbshipit-source-id: 67f30d2f2c86bbd3e87080b32f00e8fb131a53f7
Summary:
This PR adds support for complex-valued input for `torch.symeig`.
TODO:
- [ ] complex cuda tests raise `RuntimeError: _th_bmm_out not supported on CUDAType for ComplexFloat`
Update: Added xfailing tests for complex dtypes on CUDA. Once support for complex `bmm` is added these tests will work.
Fixes https://github.com/pytorch/pytorch/issues/45061.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45121
Reviewed By: mrshenli
Differential Revision: D24049649
Pulled By: anjali411
fbshipit-source-id: 2cd11f0e47d37c6ad96ec786762f2da57f25dac5
Summary:
Per feedback in the recent design review. Also tweaks the documentation to clarify what "deterministic" means and adds a test for the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45410
Reviewed By: ngimel
Differential Revision: D23974988
Pulled By: mruberry
fbshipit-source-id: e48307da9c90418fc6834fbd67b963ba2fe0ba9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45069
`torch.abs` is a `C -> R` function for complex input. Following the general semantics in torch, the in-place version of abs should be disabled for complex input.
Test Plan: Imported from OSS
Reviewed By: glaringlee, malfet
Differential Revision: D23818397
Pulled By: anjali411
fbshipit-source-id: b23b8d0981c53ba0557018824d42ed37ec13d4e2
Summary:
- The thresholds of some tests are bumped up. Depending on the random generator, sometimes these tests fail with things like 0.0059 is not smaller than 0.005. I ran `test_nn.py` and `test_torch.py` for 10+ times to check these are no longer flaky.
- Add `tf32_on_and_off` to new `matrix_exp` tests.
- Disable TF32 on test suites other than `test_nn.py` and `test_torch.py`
cc: ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44240
Reviewed By: mruberry
Differential Revision: D23882498
Pulled By: ngimel
fbshipit-source-id: 44a9ec08802c93a2efaf4e01d7487222478b6df8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39955
resolves https://github.com/pytorch/pytorch/issues/36323 by adding `torch.sgn` for complex tensors.
`torch.sgn` returns `x/abs(x)` for `x != 0` and returns `0 + 0j` for `x==0`
This PR doesn't test the correctness of the gradients. It will be done as a part of auditing all the ops in future once we decide the autograd behavior (JAX vs TF) and add gradchek.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23460526
Pulled By: anjali411
fbshipit-source-id: 70fc4e14e4d66196e27cf188e0422a335fc42f92
Summary:
This PR was originally authored by slayton58. I steal his implementation and added some tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44986
Reviewed By: mruberry
Differential Revision: D23806039
Pulled By: ngimel
fbshipit-source-id: 305d66029b426d8039fab3c3e011faf2bf87aead
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43699
- Changed the order of `TORCH_CHECK` and `if (options.layout() == kSparse && self.is_sparse())`
inside `empty_like` method.
- [x] Added tests
EDIT:
More details on that and why we can not take zeros_like approach.
Python code :
```python
res = torch.zeros_like(input_coalesced, memory_format=torch.preserve_format)
```
is routed to
```c++
// TensorFactories.cpp
Tensor zeros_like(
const Tensor& self,
const TensorOptions& options,
c10::optional<c10::MemoryFormat> optional_memory_format) {
if (options.layout() == kSparse && self.is_sparse()) {
auto res = at::empty({0}, options); // to be resized
res.sparse_resize_and_clear_(
self.sizes(), self.sparse_dim(), self.dense_dim());
return res;
}
auto result = at::empty_like(self, options, optional_memory_format);
return result.zero_();
}
```
and passed to `if (options.layout() == kSparse && self.is_sparse())`
When we call in Python
```python
res = torch.empty_like(input_coalesced, memory_format=torch.preserve_format)
```
it is routed to
```c++
Tensor empty_like(
const Tensor& self,
const TensorOptions& options_,
c10::optional<c10::MemoryFormat> optional_memory_format) {
TORCH_CHECK(
!(options_.has_memory_format() && optional_memory_format.has_value()),
"Cannot set memory_format both in TensorOptions and explicit argument; please delete "
"the redundant setter.");
TensorOptions options =
self.options()
.merge_in(options_)
.merge_in(TensorOptions().memory_format(optional_memory_format));
TORCH_CHECK(
!(options.layout() != kStrided &&
optional_memory_format.has_value()),
"memory format option is only supported by strided tensors");
if (options.layout() == kSparse && self.is_sparse()) {
auto result = at::empty({0}, options); // to be resized
result.sparse_resize_and_clear_(
self.sizes(), self.sparse_dim(), self.dense_dim());
return result;
}
```
cc pearu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44058
Reviewed By: albanD
Differential Revision: D23672494
Pulled By: mruberry
fbshipit-source-id: af232274dd2b516dd6e875fc986e3090fa285658
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44393
torch.quantile now correctly propagates nan and implemented torch.nanquantile similar to numpy.nanquantile.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23649613
Pulled By: heitorschueroff
fbshipit-source-id: 5201d076745ae1237cedc7631c28cf446be99936
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33394 .
This PR does two things:
1. Implement CUDA scatter reductions with revamped GPU atomic operations.
2. Remove support for divide and subtract for CPU reduction as was discussed with ngimel .
I've also updated the docs to reflect the existence of only multiply and add.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41977
Reviewed By: mruberry
Differential Revision: D23748888
Pulled By: ngimel
fbshipit-source-id: ea643c0da03c9058e433de96db02b503514c4e9c
Summary:
per title. If `beta=0` and slow path was taken, `nan` and `inf` in the result were not masked as is the case with other linear algebra functions. Similarly, since `mv` is implemented as `addmv` with `beta=0`, wrong results were sometimes produced for `mv` slow path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44681
Reviewed By: mruberry
Differential Revision: D23708653
Pulled By: ngimel
fbshipit-source-id: e2d5d3e6f69b194eb29b327e1c6f70035f3b231c
Summary:
This PR:
- updates div to perform true division
- makes torch.true_divide an alias of torch.div
This follows on work in previous PyTorch releases that first deprecated div performing "integer" or "floor" division, then prevented it by throwing a runtime error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42907
Reviewed By: ngimel
Differential Revision: D23622114
Pulled By: mruberry
fbshipit-source-id: 414c7e3c1a662a6c3c731ad99cc942507d843927
Summary:
Noticed this bug in `torch.movedim` (https://github.com/pytorch/pytorch/issues/41480). [`std::unique`](https://en.cppreference.com/w/cpp/algorithm/unique) only guarantees uniqueness for _sorted_ inputs. The current check lets through non-unique values when they aren't adjacent to each other in the list, e.g. `(0, 1, 0)` wouldn't raise an exception and instead the algorithm fails later with an internal assert.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44307
Reviewed By: mrshenli
Differential Revision: D23598311
Pulled By: zou3519
fbshipit-source-id: fd6cc43877c42bb243cfa85341c564b6c758a1bf
Summary:
This PR fixes three OpInfo-related bugs and moves some functions from TestTorchMathOps to be tested using the OpInfo pattern. The bugs are:
- A skip test path in test_ops.py incorrectly formatted its string argument
- Decorating the tests in common_device_type.py was incorrectly always applying decorators to the original test, not the op-specific variant of the test. This could cause the same decorator to be applied multiple times, overriding past applications.
- make_tensor was incorrectly constructing tensors in some cases
The functions moved are:
- asin
- asinh
- sinh
- acosh
- tan
- atan
- atanh
- tanh
- log
- log10
- log1p
- log2
In a follow-up PR more or all of the remaining functions in TestTorchMathOps will be refactored as OpInfo-based tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44277
Reviewed By: mrshenli, ngimel
Differential Revision: D23617361
Pulled By: mruberry
fbshipit-source-id: edb292947769967de9383f6a84eb327f027509e0
Summary:
This PR fixes three OpInfo-related bugs and moves some functions from TestTorchMathOps to be tested using the OpInfo pattern. The bugs are:
- A skip test path in test_ops.py incorrectly formatted its string argument
- Decorating the tests in common_device_type.py was incorrectly always applying decorators to the original test, not the op-specific variant of the test. This could cause the same decorator to be applied multiple times, overriding past applications.
- make_tensor was incorrectly constructing tensors in some cases
The functions moved are:
- asin
- asinh
- sinh
- acosh
- tan
- atan
- atanh
- tanh
- log
- log10
- log1p
- log2
In a follow-up PR more or all of the remaining functions in TestTorchMathOps will be refactored as OpInfo-based tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44277
Reviewed By: ngimel
Differential Revision: D23568330
Pulled By: mruberry
fbshipit-source-id: 03e69fccdbfd560217c34ce4e9a5f20e10d05a5e
Summary:
1) Ports nonzero from THC to ATen
2) replaces most thrust uses with cub, to avoid synchronization and to improve performance. There is still one necessary synchronization point, communicating number of nonzero elements from GPU to CPU
3) slightly changes algorithm, now we first compute the number of nonzeros, and then allocate correct-sized output, instead of allocating full-sized output as was done before, to account for possibly all elements being non-zero
4) unfortunately, since the last transforms are still done with thrust, 2) is slightly beside the point, however it is a step towards a future without thrust
4) hard limits the number of elements in the input tensor to MAX_INT. Previous implementation allocated a Long tensor with the size ndim*nelements, so that would be at least 16 GB for a tensor with MAX_INT elements. It is reasonable to say that larger tensors could not be used anyway.
Benchmarking is done for tensors with approximately half non-zeros
<details><summary>Benchmarking script</summary>
<p>
```
import torch
from torch.utils._benchmark import Timer
from torch.utils._benchmark import Compare
import sys
device = "cuda"
results = []
for numel in (1024 * 128,):#, 1024 * 1024, 1024 * 1024 * 128):
inp = torch.randint(2, (numel,), device="cuda", dtype=torch.float)
for ndim in range(2,3):#(1,4):
if ndim == 1:
shape = (numel,)
elif ndim == 2:
shape = (1024, numel // 1024)
else:
shape = (1024, 128, numel // 1024 // 128)
inp = inp.reshape(shape)
repeats = 3
timer = Timer(stmt="torch.nonzero(inp, as_tuple=False)", label="Nonzero", sub_label=f"number of elts {numel}",
description = f"ndim {ndim}", globals=globals())
for i in range(repeats):
results.append(timer.blocked_autorange())
print(f"\rnumel {numel} ndim {ndim}", end="")
sys.stdout.flush()
comparison = Compare(results)
comparison.print()
```
</p>
</details>
### Results
Before:
```
[--------------------------- Nonzero ---------------------------]
| ndim 1 | ndim 2 | ndim 3
1 threads: ------------------------------------------------------
number of elts 131072 | 55.2 | 71.7 | 90.5
number of elts 1048576 | 113.2 | 250.7 | 497.0
number of elts 134217728 | 8353.7 | 23809.2 | 54602.3
Times are in microseconds (us).
```
After:
```
[-------------------------- Nonzero --------------------------]
| ndim 1 | ndim 2 | ndim 3
1 threads: ----------------------------------------------------
number of elts 131072 | 48.6 | 79.1 | 90.2
number of elts 1048576 | 64.7 | 134.2 | 161.1
number of elts 134217728 | 3748.8 | 7881.3 | 9953.7
Times are in microseconds (us).
```
There's a real regression for smallish 2D tensor due to added work of computing number of nonzero elements, however, for other sizes there are significant gains, and there are drastically lower memory requirements. Perf gains would be even larger for tensors with fewer nonzeros.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44259
Reviewed By: izdeby
Differential Revision: D23581955
Pulled By: ngimel
fbshipit-source-id: 0b99a767fd60d674003d83f0848dc550d7a363dc
Summary:
When var and std are called without args (other than unbiased) they currently call into TH or THC. This PR:
- Removes the THC var_all and std_all functions and updates CUDA var and std to use the ATen reduction
- Fixes var's docs, which listed its arguments in the incorrect order
- Adds new tests comparing var and std with their NumPy counterparts
Performance appears to have improved as a result of this change. I ran experiments on 1D tensors, 1D tensors with every other element viewed ([::2]), 2D tensors and 2D transposed tensors. Some notable datapoints:
- torch.randn((8000, 8000))
- var measured 0.0022215843200683594s on CUDA before the change
- var measured 0.0020322799682617188s on CUDA after the change
- torch.randn((8000, 8000)).T
- var measured .015128850936889648 on CUDA before the change
- var measured 0.001912832260131836 on CUDA after the change
- torch.randn(8000 ** 2)
- std measured 0.11031460762023926 on CUDA before the change
- std measured 0.0017833709716796875 on CUDA after the change
Timings for var and std are, as expected, similar.
On the CPU, however, the performance change from making the analogous update was more complicated, and ngimel and I decided not to remove CPU var_all and std_all. ngimel wrote the following script that showcases how single-threaded CPU inference would suffer from this change:
```
import torch
import numpy as np
from torch.utils._benchmark import Timer
from torch.utils._benchmark import Compare
import sys
base = 8
multiplier = 1
def stdfn(a):
meanv = a.mean()
ac = a-meanv
return torch.sqrt(((ac*ac).sum())/a.numel())
results = []
num_threads=1
for _ in range(7):
size = base*multiplier
input = torch.randn(size)
tasks = [("torch.var(input)", "torch_var"),
("torch.var(input, dim=0)", "torch_var0"),
("stdfn(input)", "stdfn"),
("torch.sum(input, dim=0)", "torch_sum0")
]
timers = [Timer(stmt=stmt, num_threads=num_threads, label="Index", sub_label=f"{size}",
description=label, globals=globals()) for stmt, label in tasks]
repeats = 3
for i, timer in enumerate(timers * repeats):
results.append(
timer.blocked_autorange()
)
print(f"\r{i + 1} / {len(timers) * repeats}", end="")
sys.stdout.flush()
multiplier *=10
print()
comparison = Compare(results)
comparison.print()
```
The TH timings using this script on my devfair are:
```
[------------------------------ Index ------------------------------]
| torch_var | torch_var0 | stdfn | torch_sum0
1 threads: ----------------------------------------------------------
8 | 16.0 | 5.6 | 40.9 | 5.0
80 | 15.9 | 6.1 | 41.6 | 4.9
800 | 16.7 | 12.0 | 42.3 | 5.0
8000 | 27.2 | 72.7 | 51.5 | 6.2
80000 | 129.0 | 715.0 | 133.0 | 18.0
800000 | 1099.8 | 6961.2 | 842.0 | 112.6
8000000 | 11879.8 | 68948.5 | 20138.4 | 1750.3
```
and the ATen timings are:
```
[------------------------------ Index ------------------------------]
| torch_var | torch_var0 | stdfn | torch_sum0
1 threads: ----------------------------------------------------------
8 | 4.3 | 5.4 | 41.4 | 5.4
80 | 4.9 | 5.7 | 42.6 | 5.4
800 | 10.7 | 11.7 | 43.3 | 5.5
8000 | 69.3 | 72.2 | 52.8 | 6.6
80000 | 679.1 | 676.3 | 129.5 | 18.1
800000 | 6770.8 | 6728.8 | 819.8 | 109.7
8000000 | 65928.2 | 65538.7 | 19408.7 | 1699.4
```
which demonstrates that performance is analogous to calling the existing var and std with `dim=0` on a 1D tensor. This would be a significant performance hit. Another simple script shows the performance is mixed when using multiple threads, too:
```
import torch
import time
# Benchmarking var and std, 1D with varying sizes
base = 8
multiplier = 1
op = torch.var
reps = 1000
for _ in range(7):
size = base * multiplier
t = torch.randn(size)
elapsed = 0
for _ in range(reps):
start = time.time()
op(t)
end = time.time()
elapsed += end - start
multiplier *= 10
print("Size: ", size)
print("Avg. elapsed time: ", elapsed / reps)
```
```
var cpu TH vs ATen timings
Size: 8
Avg. elapsed time: 1.7853736877441406e-05 vs 4.9788951873779295e-06 (ATen wins)
Size: 80
Avg. elapsed time: 1.7803430557250977e-05 vs 6.156444549560547e-06 (ATen wins)
Size: 800
Avg. elapsed time: 1.8569469451904296e-05 vs 1.2302875518798827e-05 (ATen wins)
Size: 8000
Avg. elapsed time: 2.8756141662597655e-05 vs. 6.97789192199707e-05 (TH wins)
Size: 80000
Avg. elapsed time: 0.00026622867584228516 vs. 0.0002447957992553711 (ATen wins)
Size: 800000
Avg. elapsed time: 0.0010556647777557374 vs 0.00030616092681884767 (ATen wins)
Size: 8000000
Avg. elapsed time: 0.009990205764770508 vs 0.002938544034957886 (ATen wins)
std cpu TH vs ATen timings
Size: 8
Avg. elapsed time: 1.6681909561157225e-05 vs. 4.659652709960938e-06 (ATen wins)
Size: 80
Avg. elapsed time: 1.699185371398926e-05 vs. 5.431413650512695e-06 (ATen wins)
Size: 800
Avg. elapsed time: 1.768803596496582e-05 vs. 1.1279821395874023e-05 (ATen wins)
Size: 8000
Avg. elapsed time: 2.7791500091552735e-05 vs 7.031106948852539e-05 (TH wins)
Size: 80000
Avg. elapsed time: 0.00018650460243225096 vs 0.00024368906021118164 (TH wins)
Size: 800000
Avg. elapsed time: 0.0010522041320800782 vs 0.0003039860725402832 (ATen wins)
Size: 8000000
Avg. elapsed time: 0.009976618766784668 vs. 0.0029211788177490234 (ATen wins)
```
These results show the TH solution still performs better than the ATen solution with default threading for some sizes.
It seems like removing CPU var_all and std_all will require an improvement in ATen reductions. https://github.com/pytorch/pytorch/issues/40570 has been updated with this information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43858
Reviewed By: zou3519
Differential Revision: D23498981
Pulled By: mruberry
fbshipit-source-id: 34bee046c4872d11c3f2ffa1b5beee8968b22050
Summary:
- test beta=0, self=nan
- test transposes
- fixes broadcasting of addmv
- not supporting tf32 yet, will do it in future PR together with other testing fixes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43980
Reviewed By: mruberry
Differential Revision: D23507559
Pulled By: ngimel
fbshipit-source-id: 14ee39d1a0e13b9482932bede3fccb61fe6d086d
Summary:
- This test is very fast and very important, so it makes no sense in marking it as slowTest
- This test is should also run on CUDA
- This test should check alpha and beta support
- This test should check `out=` support
- manual computation should use list instead of index_put because list is much faster
- precision for TF32 needs to be fixed. Will do it in future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43831
Reviewed By: ailzhang
Differential Revision: D23435032
Pulled By: ngimel
fbshipit-source-id: d1b8350addf1e2fe180fdf3df243f38d95aa3f5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44001
This is to align with the naming in numpy and in
https://github.com/pytorch/pytorch/pull/43092
Test Plan:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_aminmax_cpu_float32
python test/test_torch.py TestTorchDeviceTypeCUDA.test_aminmax_cuda_float32
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23465298
fbshipit-source-id: b599035507156cefa53942db05f93242a21c8d06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42894
Continuing the min_max kernel implementation, this PR adds the
CPU path when a dim is specified. Next PR will replicate for CUDA.
Note: after a discussion with ngimel, we are taking the fast path
of calculating the values only and not the indices, since that is what
is needed for quantization, and calculating indices would require support
for reductions on 4 outputs which is additional work. So, the API
doesn't fully match `min.dim` and `max.dim`.
Flexible on the name, let me know if something else is better.
Test Plan:
correctness:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_minmax_cpu_float32
```
performance: seeing a 49% speedup on a min+max tensor with similar shapes
to what we care about for quantization observers (bench:
https://gist.github.com/vkuzo/b3f24d67060e916128a51777f9b89326). For
other shapes (more dims, different dim sizes, etc), I've noticed a
speedup as low as 20%, but we don't have a good use case to optimize
that so perhaps we can save that for a future PR.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23086798
fbshipit-source-id: b24ce827d179191c30eccf31ab0b2b76139b0ad5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42868
Adds a CUDA kernel for the _min_max function.
Note: this is a re-submit of https://github.com/pytorch/pytorch/pull/41805,
was faster to resubmit than to ressurect that one. Thanks to durumu
for writing the original implementation!
Future PRs will add index support, docs, and hook this up to observers.
Test Plan:
```
python test/test_torch.py TestTorchDeviceTypeCUDA.test_minmax_cuda_float32
```
Basic benchmarking shows a 50% reduction in time to calculate min + max:
https://gist.github.com/vkuzo/b7dd91196345ad8bce77f2e700f10cf9
TODO
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23057766
fbshipit-source-id: 70644d2471cf5dae0a69343fba614fb486bb0891
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43270
`torch.conj` is a very commonly used operator for complex tensors, but it's mathematically a no op for real tensors. Switching to tensorflow gradients for complex tensors (as discussed in #41857) would involve adding `torch.conj()` to the backward definitions for a lot of operators. In order to preserve autograd performance for real tensors and maintain numpy compatibility for `torch.conj`, this PR updates `torch.conj()` which behaves the same for complex tensors but performs a view/returns `self` tensor for tensors of non-complex dtypes. The documentation states that the returned tensor for a real input shouldn't be mutated. We could perhaps return an immutable tensor for this case in future when that functionality is available (zdevito ezyang ).
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23460493
Pulled By: anjali411
fbshipit-source-id: 3b3bf0af55423b77ff2d0e29f5d2c160291ae3d9
Summary:
Add a max/min operator that only return values.
## Some important decision to discuss
| **Question** | **Current State** |
|---------------------------------------|-------------------|
| Expose torch.max_values to python? | No |
| Remove max_values and only keep amax? | Yes |
| Should amax support named tensors? | Not in this PR |
## Numpy compatibility
Reference: https://numpy.org/doc/stable/reference/generated/numpy.amax.html
| Parameter | PyTorch Behavior |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
| `axis`: None or int or tuple of ints, optional. Axis or axes along which to operate. By default, flattened input is used. If this is a tuple of ints, the maximum is selected over multiple axes, instead of a single axis or all the axes as before. | Named `dim`, behavior same as `torch.sum` (https://github.com/pytorch/pytorch/issues/29137) |
| `out`: ndarray, optional. Alternative output array in which to place the result. Must be of the same shape and buffer length as the expected output. | Same |
| `keepdims`: bool, optional. If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array. | implemented as `keepdim` |
| `initial`: scalar, optional. The minimum value of an output element. Must be present to allow computation on empty slice. | Not implemented in this PR. Better to implement for all reductions in the future. |
| `where`: array_like of bool, optional. Elements to compare for the maximum. | Not implemented in this PR. Better to implement for all reductions in the future. |
**Note from numpy:**
> NaN values are propagated, that is if at least one item is NaN, the corresponding max value will be NaN as well. To ignore NaN values (MATLAB behavior), please use nanmax.
PyTorch has the same behavior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43092
Reviewed By: ngimel
Differential Revision: D23360705
Pulled By: mruberry
fbshipit-source-id: 5bdeb08a2465836764a5a6fc1a6cc370ae1ec09d
Summary:
Related to https://github.com/pytorch/pytorch/issues/38349
Implement NumPy-like functions `maximum` and `minimum`.
The `maximum` and `minimum` functions compute input tensors element-wise, returning a new array with the element-wise maxima/minima.
If one of the elements being compared is a NaN, then that element is returned, both `maximum` and `minimum` functions do not support complex inputs.
This PR also promotes the overloaded versions of torch.max and torch.min, by re-dispatching binary `torch.max` and `torch.min` to `torch.maximum` and `torch.minimum`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42579
Reviewed By: mrshenli
Differential Revision: D23153081
Pulled By: mruberry
fbshipit-source-id: 803506c912440326d06faa1b71964ec06775eac1
Summary:
These tests are failing on one of my system that does not have lapack
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43566
Reviewed By: ZolotukhinM
Differential Revision: D23325378
Pulled By: mruberry
fbshipit-source-id: 5d795e460df0a2a06b37182d3d4084d8c5c8e751
Summary:
As part of our continued refactoring of test_torch.py, this takes tests for tensor creation ops like torch.eye, torch.randint, and torch.ones_like and puts them in test_tensor_creation_ops.py. There hare three test classes in the new test suite: TestTensorCreation, TestRandomTensorCreation, TestLikeTensorCreation. TestViewOps and tests for construction of tensors from NumPy arrays have been left in test_torch.py. These might be refactored separately into test_view_ops.py and test_numpy_interop.py in the future.
Most of the tests ported from test_torch.py were left as is or received a signature change to make them nominally "device generic." Future work will need to review test coverage and update the tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43104
Reviewed By: ngimel
Differential Revision: D23280358
Pulled By: mruberry
fbshipit-source-id: 469325dd1a734509dd478cc7fe0413e276ffb192
Summary:
This PR:
- ports the tests in TestTorchMathOps to test_unary_ufuncs.py
- removes duplicative tests for the tested unary ufuncs from test_torch.py
- adds a new test, test_reference_numerics, that validates the behavior of our unary ufuncs vs. reference implementations on empty, scalar, 1D, and 2D tensors that are contiguous, discontiguous, and that contain extremal values, for every dtype the unary ufunc supports
- adds support for skipping tests by regex, this behavior is used to make the test suite pass on Windows, MacOS, and ROCm builds, which have a variety of issues, and on Linux builds (see https://github.com/pytorch/pytorch/issues/42952)
- adds a new OpInfo helper, `supports_dtype`, to facilitate test writing
- extends unary ufunc op info to include reference, domain, and extremal value handling information
- adds OpInfos for `torch.acos` and `torch.sin`
These improvements reveal that our testing has been incomplete on several systems, especially with larger float values and complex values, and several TODOs have been added for follow-up investigations. Luckily when writing tests that cover many ops we can afford to spend additional time crafting the tests and ensuring coverage.
Follow-up PRs will:
- refactor TestTorchMathOps into test_unary_ufuncs.py
- continue porting tests from test_torch.py to test_unary_ufuncs.py (where appropriate)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42965
Reviewed By: pbelevich
Differential Revision: D23238083
Pulled By: mruberry
fbshipit-source-id: c6be317551453aaebae9d144f4ef472f0b3d08eb
Summary:
Add ComplexHalf case to toValueType, which fixes the logic how view_as_real and view_as_complex slices complex tensor to the floating point one, as it is used to generate tensor of random complex values, see:
018b4d7abb/aten/src/ATen/native/DistributionTemplates.h (L200)
Also add ability to convert python complex object to `c10::complex<at::Half>`
Add `torch.half` and `torch.complex32` to the list of `test_randn` dtypes
Fixes https://github.com/pytorch/pytorch/issues/43143
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43279
Reviewed By: mrshenli
Differential Revision: D23230296
Pulled By: malfet
fbshipit-source-id: b4bb66c4c81dd867e72ab7c4563d73f6a4d80a44
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41314 among other things.
This PR streamlines layout propagation logic in TensorIterator and removes almost all cases of channels-last hardcoding. The new rules and changes are as follows:
1) behavior of undefined `output` and defined output of the wrong (e.g. 0) size is always the same (before this PR the behavior was divergent)
2) in obvious cases (unary operation on memory-dense tensors, binary operations on memory-dense tensors with the same layout) strides are propagated (before propagation was inconsistent) (see footnote)
3) in other cases the output permutation is obtained as inverse permutation of sorting inputs by strides. Sorting is done with comparator obeying the following rules: strides of broadcasted dimensions are set to 0, and 0 compares equal to anything. Strides of not-broadcasted dimensions (including dimensions of size `1`) participate in sorting. Precedence is given to the first input, in case of a tie in the first input, first the corresponding dimensions are considered, and if that does not indicate that swap is needed, strides of the same dimension in subsequent inputs are considered. See changes in `reorder_dimensions` and `compute_strides`. Note that first inspecting dimensions of the first input allows us to better recover it's permutation (and we select this behavior because it more reliably propagates channels-last strides) but in some rare cases could result in worse traversal order for the second tensor.
These rules are enough to recover previously hard-coded behavior related to channels last, so all existing tests are passing.
In general, these rules will produce intuitive results, and in most cases permutation of the full size input (in case of broadcasted operation) will be recovered, or permutation of the first input (in case of same sized inputs) will be recovered, including cases with trivial (1) dimensions. As an example of the latter, the following tensor
```
x=torch.randn(2,1,3).permute(1,0,2)
```
will produce output with the same stride (3,3,1) in binary operations with 1d tensor. Another example is a tensor of size N1H1 that has strides `H,H,1,1` when contiguous and `H, 1, 1, 1` when channels-last. The output retains these strides in binary operations when another 1d tensor is broadcasted on this one.
Footnote: for ambiguous cases where all inputs are memory dense and have the same physical layout that nevertheless can correspond to different permutations, such as e.g. NC11-sized physically contiguous tensors, regular contiguous tensor is returned, and thus permutation information of the input is lost (so for NC11 channels-last input had the strides `C, 1, C, C`, but output will have the strides `C, 1, 1, 1`). This behavior is unchanged from before and consistent with numpy, but it still makes sense to change it. The blocker for doing it currently is performance of `empty_strided`. Once we make it on par with `empty` we should be able to propagate layouts in these cases. For now, to not slow down common contiguous case, we default to contiguous.
The table below shows how in some cases current behavior loses permutation/stride information, whereas new behavior propagates permutation.
| code | old | new |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------|------------------------------------------------------|
| #strided tensors<br>a=torch.randn(2,3,8)[:,:,::2].permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (2, 24, 8) <br>(6, 3, 1) <br>(1, 12, 4) <br>(6, 3, 1) | (2, 24, 8)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
| #memory dense tensors<br>a=torch.randn(3,1,1).as_strided((3,1,1), (1,3,3))<br>print(a.stride(), (a+torch.randn(1)).stride())<br>a=torch.randn(2,3,4).permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (1, 3, 3) (1, 1, 1)<br>(1, 12, 4)<br>(6, 3, 1)<br>(1, 12, 4)<br>(6, 3, 1) | (1, 3, 3) (1, 3, 3)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42922
Reviewed By: ezyang
Differential Revision: D23148204
Pulled By: ngimel
fbshipit-source-id: 670fb6188c7288e506e5ee488a0e11efc8442d1f
Summary:
https://github.com/pytorch/pytorch/issues/40980
I have a few questions during implementing Polygamma function...
so, I made PR prior to complete it.
1. some code blocks brought from cephes library(and I did too)
```
/*
* The following function comes with the following copyright notice.
* It has been released under the BSD license.
*
* Cephes Math Library Release 2.8: June, 2000
* Copyright 1984, 1987, 1992, 2000 by Stephen L. Moshier
*/
```
is it okay for me to use cephes code with this same copyright notice(already in the Pytorch codebases)
2. There is no linting in internal Aten library. (as far as I know, I read https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md)
How do I'm sure my code will follow appropriate guidelines of this library..?
3. Actually, there's a digamma, trigamma function already
digamma is needed, however, trigamma function becomes redundant if polygamma function is added.
it is okay for trigamma to be there or should be removed?
btw, CPU version works fine with 3-rd order polygamma(it's what we need to play with variational inference with beta/gamma distribution) now and I'm going to finish GPU version soon.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42499
Reviewed By: gchanan
Differential Revision: D23110016
Pulled By: albanD
fbshipit-source-id: 246f4c2b755a99d9e18a15fcd1a24e3df5e0b53e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42563
Moved logic for non-named unflatten from python nn module to aten/native to be reused by the nn module later. Fixed some inconsistencies with doc and code logic.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23030301
Pulled By: heitorschueroff
fbshipit-source-id: 7c804ed0baa5fca960a990211b8994b3efa7c415
Summary:
Addresses some comments that were left unaddressed after PR https://github.com/pytorch/pytorch/issues/41377 was merged:
* Use `check_output` instead of `Popen` to run each subprocess sequentially
* Use f-strings rather than old python format string style
* Provide environment variables to subprocess through the `env` kwarg
* Check for correct error behavior inside the subprocess, and raise another error if incorrect. Then the main process fails the test if any error is raised
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42627
Reviewed By: malfet
Differential Revision: D22969231
Pulled By: ezyang
fbshipit-source-id: 38d5f3f0d641c1590a93541a5e14d90c2e20acec
Summary:
Previously, `at::native::embedding` implicitly assumed that the `weight` argument would be 1-D or greater. Given a 0-D tensor, it would segfault. This change makes it throw a RuntimeError instead.
Fixes https://github.com/pytorch/pytorch/issues/41780
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42550
Reviewed By: smessmer
Differential Revision: D23040744
Pulled By: albanD
fbshipit-source-id: d3d315850a5ee2d2b6fcc0bdb30db2b76ffffb01
Summary:
Per title. Also updates our guidance for adding aliases to clarify interned_string and method_test requirements. The alias is tested by extending test_clamp to also test clip.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42770
Reviewed By: ngimel
Differential Revision: D23020655
Pulled By: mruberry
fbshipit-source-id: f1d8e751de9ac5f21a4f95d241b193730f07b5dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42383
Test Plan - Updated existing tests to run for complex dtypes as well.
Also added tests for `torch.addmm`, `torch.badmm`
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22960339
Pulled By: anjali411
fbshipit-source-id: 0805f21caaa40f6e671cefb65cef83a980328b7d
Summary:
For CUDA >= 10.2, the `CUBLAS_WORKSPACE_CONFIG` environment variable must be set to either `:4096:8` or `:16:8` to ensure deterministic CUDA stream usage. This PR adds some logic inside `torch.set_deterministic()` to raise an error if this environment variable is not set properly and CUDA >= 10.2.
Issue https://github.com/pytorch/pytorch/issues/15359
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41377
Reviewed By: malfet
Differential Revision: D22758459
Pulled By: ezyang
fbshipit-source-id: 4b96f1e9abf85d94ba79140fd927bbd0c05c4522
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42418.
The problem was that the non-contiguous batched matrices were passed to `gemmStridedBatched`.
The following code fails on master and works with the proposed patch:
```python
import torch
x = torch.tensor([[1., 2, 3], [4., 5, 6]], device='cuda:0')
c = torch.as_strided(x, size=[2, 2, 2], stride=[3, 1, 1])
torch.einsum('...ab,...bc->...ac', c, c)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42425
Reviewed By: glaringlee
Differential Revision: D22925266
Pulled By: ngimel
fbshipit-source-id: a72d56d26c7381b7793a047d76bcc5bd45a9602c
Summary:
Segfault happens when one tries to deallocate uninitialized generator.
Make `THPGenerator_dealloc` UBSAN-safe by moving implicit cast in the struct definition to reinterpret_cast
Add `TestTorch.test_invalid_generator_raises` that validates that Generator created on invalid device is handled correctly
Fixes https://github.com/pytorch/pytorch/issues/42281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42510
Reviewed By: pbelevich
Differential Revision: D22917469
Pulled By: malfet
fbshipit-source-id: 5eaa68eef10d899ee3e210cb0e1e92f73be75712
Summary:
Segfault happens when one tries to deallocate unintialized generator
Add `TestTorch.test_invalid_generator_raises` that validates that Generator created on invalid device is handled correctly
Fixes https://github.com/pytorch/pytorch/issues/42281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42490
Reviewed By: seemethere
Differential Revision: D22908795
Pulled By: malfet
fbshipit-source-id: c5b6a35db381738c0fc984aa54e5cab5ef2cbb76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38697
Benchmark (gcc 8.3, Debian Buster, turbo off, Release build, Intel(R)
Xeon(R) E-2136, Parallelization using OpenMP):
```python
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.uint8', 'torch.int8', 'torch.int16', 'torch.int32', 'torch.int64'):
for n, t in [(40_000, 50000),
(400_000, 5000)]:
print(f'torch.arange(0, {n}, dtype={dtype}) for {t} times')
print(timeit.timeit(f'torch.arange(0, {n}, dtype={dtype})', setup=f'import torch', number=t))
```
Before:
```
torch.arange(0, 40000, dtype=torch.double) for 50000 times
1.587841397995362
torch.arange(0, 400000, dtype=torch.double) for 5000 times
0.47885190199303906
torch.arange(0, 40000, dtype=torch.float) for 50000 times
1.5519152240012772
torch.arange(0, 400000, dtype=torch.float) for 5000 times
0.4733216500026174
torch.arange(0, 40000, dtype=torch.uint8) for 50000 times
1.426058754004771
torch.arange(0, 400000, dtype=torch.uint8) for 5000 times
0.43596178699226584
torch.arange(0, 40000, dtype=torch.int8) for 50000 times
1.4289699140063021
torch.arange(0, 400000, dtype=torch.int8) for 5000 times
0.43451592899509706
torch.arange(0, 40000, dtype=torch.int16) for 50000 times
0.5714442400058033
torch.arange(0, 400000, dtype=torch.int16) for 5000 times
0.14837959500437137
torch.arange(0, 40000, dtype=torch.int32) for 50000 times
0.5964003179979045
torch.arange(0, 400000, dtype=torch.int32) for 5000 times
0.15676555599202402
torch.arange(0, 40000, dtype=torch.int64) for 50000 times
0.8390555799996946
torch.arange(0, 400000, dtype=torch.int64) for 5000 times
0.23184613398916554
```
After:
```
torch.arange(0, 40000, dtype=torch.double) for 50000 times
0.6895066159922862
torch.arange(0, 400000, dtype=torch.double) for 5000 times
0.16820953000569716
torch.arange(0, 40000, dtype=torch.float) for 50000 times
1.3640095089940587
torch.arange(0, 400000, dtype=torch.float) for 5000 times
0.39255041000433266
torch.arange(0, 40000, dtype=torch.uint8) for 50000 times
0.3422072059911443
torch.arange(0, 400000, dtype=torch.uint8) for 5000 times
0.0605111670010956
torch.arange(0, 40000, dtype=torch.int8) for 50000 times
0.3449254590086639
torch.arange(0, 400000, dtype=torch.int8) for 5000 times
0.06115841199061833
torch.arange(0, 40000, dtype=torch.int16) for 50000 times
0.7745441729930462
torch.arange(0, 400000, dtype=torch.int16) for 5000 times
0.22106765500211623
torch.arange(0, 40000, dtype=torch.int32) for 50000 times
0.720475220005028
torch.arange(0, 400000, dtype=torch.int32) for 5000 times
0.20230313099455088
torch.arange(0, 40000, dtype=torch.int64) for 50000 times
0.8144655400101328
torch.arange(0, 400000, dtype=torch.int64) for 5000 times
0.23762561299372464
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22291236
Pulled By: VitalyFedyunin
fbshipit-source-id: 134dd08b77b11e631d914b5500ee4285b5d0591e
Summary:
`abs` doesn't have an signed overload across all compilers, so applying abs on uint8_t can be ambiguous: https://en.cppreference.com/w/cpp/numeric/math/abs
This may cause unexpected issue when the input is uint8 and is greater
than 128. For example, on MSVC, applying `std::abs` on an unsigned char
variable
```c++
#include <cmath>
unsigned char a(unsigned char x) {
return std::abs(x);
}
```
gives the following warning:
warning C4244: 'return': conversion from 'int' to 'unsigned char',
possible loss of data
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42254
Reviewed By: VitalyFedyunin
Differential Revision: D22860505
Pulled By: mruberry
fbshipit-source-id: 0076d327bb6141b2ee94917a1a21c22bd2b7f23a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40986.
TensorIterator's test for a CUDA kernel getting too many CPU scalar inputs was too permissive. This update limits the check to not consider outputs and to only be performed if the kernel can support CPU scalars.
A test is added to verify the appropriate error message is thrown in a case where the old error message was thrown previously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42360
Reviewed By: ngimel
Differential Revision: D22868536
Pulled By: mruberry
fbshipit-source-id: 2bc8227978f8f6c0a197444ff0c607aeb51b0671
Summary:
**BC-Breaking Note:**
BC breaking changes in the case where keepdim=True. Before this change, when calling `torch.norm` with keepdim=True and p='fro' or p=number, leaving all other optional arguments as their default values, the keepdim argument would be ignored. Also, any time `torch.norm` was called with p='nuc', the result would have one fewer dimension than the input, and the dimensions could be out of order depending on which dimensions were being reduced. After the change, for each of these cases, the result has the same number and order of dimensions as the input.
**PR Summary:**
* Fix keepdim behavior
* Throw descriptive errors for unsupported sparse norm args
* Increase unit test coverage for these cases and for complex inputs
These changes were taken from part of PR https://github.com/pytorch/pytorch/issues/40924. That PR is not going to be merged because it overrides `torch.norm`'s interface, which we want to avoid. But these improvements are still useful.
Issue https://github.com/pytorch/pytorch/issues/24802
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41956
Reviewed By: albanD
Differential Revision: D22837455
Pulled By: mruberry
fbshipit-source-id: 509ecabfa63b93737996f48a58c7188b005b7217
Summary:
See https://github.com/pytorch/pytorch/issues/41027.
This adds a helper to resize output to ATen/native/Resize.* and updates TensorIterator to use it. The helper throws a warning if a tensor with one or more elements needs to be resized. This warning indicates that these resizes will become an error in a future PyTorch release.
There are many functions in PyTorch that will resize their outputs and don't use TensorIterator. For example,
985fd970aa/aten/src/ATen/native/cuda/NaiveConvolutionTranspose2d.cu (L243)
And these functions will need to be updated to use this helper, too. This PR avoids their inclusion since the work is separable, and this should let us focus on the function and its behavior in review. A TODO appears in the code to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42079
Reviewed By: VitalyFedyunin
Differential Revision: D22846851
Pulled By: mruberry
fbshipit-source-id: d1a413efb97e30853923bce828513ba76e5a495d
Summary:
After being deprecated in 1.5 and throwing a runtime error in 1.6, we can now enable torch.full inferring its dtype when given bool and integer fill values. This PR enables that inference and updates the tests and docs to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41912
Reviewed By: albanD
Differential Revision: D22836802
Pulled By: mruberry
fbshipit-source-id: 33dfbe4d4067800c418b314b1f60fab8adcab4e7
Summary:
In preparation for creating the new torch.fft namespace and NumPy-like fft functions, as well as supporting our goal of refactoring and reducing the size of test_torch.py, this PR creates a test suite for our spectral ops.
The existing spectral op tests from test_torch.py and test_cuda.py are moved to test_spectral_ops.py and updated to run under the device generic test framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42157
Reviewed By: albanD
Differential Revision: D22811096
Pulled By: mruberry
fbshipit-source-id: e5c50f0016ea6bb8b093cd6df2dbcef6db9bb6b6
Summary:
After being deprecated in 1.5 and throwing a runtime error in 1.6, we can now enable torch.full inferring its dtype when given bool and integer fill values. This PR enables that inference and updates the tests and docs to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41912
Reviewed By: pbelevich
Differential Revision: D22790718
Pulled By: mruberry
fbshipit-source-id: 8d1eb01574b1977f00bc0696974ac38ffdd40d9e
Summary:
This uses cub for cum* operations, because, unlike thrust, cub is non-synchronizing.
Cub does not support more than `2**31` element tensors out of the box (in fact, due to cub bugs the cutoff point is even smaller)
so to support that I split the tensor into `2**30` element chunks, and modify the first value of the second and subsequent chunks to contain the cumsum result of the previous chunks. Since modification is done inplace on the source tensor, if something goes wrong and we error out before the source tensor is reverted back to its original state, source tensor will be corrupted, but in most cases errors will invalidate the full coda context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42036
Reviewed By: ajtulloch
Differential Revision: D22749945
Pulled By: ngimel
fbshipit-source-id: 9fc9b54d466df9c8885e79c4f4f8af81e3f224ef
Summary:
**BC-Breaking Note**
This PR changes the behavior of the torch.tensor, torch.as_tensor, and sparse constructors. When given a tensor as input and a device is not explicitly specified, these constructors now always infer their device from the tensor. Historically, if the optional dtype kwarg was provided then these constructors would not infer their device from tensor inputs. Additionally, for the sparse ctor a runtime error is now thrown if the indices and values tensors are on different devices and the device kwarg is not specified.
**PR Summary**
This PR's functional change is a single line:
```
auto device = device_opt.has_value() ? *device_opt : (type_inference ? var.device() : at::Device(computeDeviceType(dispatch_key)));
```
=>
```
auto device = device_opt.has_value() ? *device_opt : var.device();
```
in `internal_new_from_data`. This line entangled whether the function was performing type inference with whether it inferred its device from an input tensor, and in practice meant that
```
t = torch.tensor((1, 2, 3), device='cuda')
torch.tensor(t, dtype=torch.float64)
```
would return a tensor on the CPU, not the default CUDA device, while
```
t = torch.tensor((1, 2, 3), device='cuda')
torch.tensor(t)
```
would return a tensor on the device of `t`!
This behavior is niche and odd, but came up while aocsa was fixing https://github.com/pytorch/pytorch/issues/40648.
An additional side affect of this change is that the indices and values tensors given to a sparse constructor must be on the same device, or the sparse ctor must specify the dtype kwarg. The tests in test_sparse.py have been updated to reflect this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41984
Reviewed By: ngimel
Differential Revision: D22721426
Pulled By: mruberry
fbshipit-source-id: 909645124837fcdf3d339d7db539367209eccd48
Summary:
so that testing _min_max on the different devices is easier, and min/max operations have better CUDA test coverage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41908
Reviewed By: mruberry
Differential Revision: D22697032
Pulled By: ngimel
fbshipit-source-id: a796638fdbed8cda90a23f7ff4ee167f45530914
Summary:
This pull request enables the following tests from test_torch, previously skipped on ROCm:
test_pow_-2_cuda_float32/float64
test_sum_noncontig_cuda_float64
test_conv_transposed_large
The first two tests experienced precision issues on earlier ROCm version, whereas the conv_transposed test was hitting a bug in MIOpen which is fixed with the version shipping with ROCm 3.5
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41611
Reviewed By: xw285cornell
Differential Revision: D22672690
Pulled By: ezyang
fbshipit-source-id: 5585387c048f301a483c4c0566eb9665555ef874
Summary:
Reland PR https://github.com/pytorch/pytorch/issues/40056
A new overload of upsample_linear1d_backward_cuda was added in a recent commit, so I had to add the nondeterministic alert to it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41538
Reviewed By: zou3519
Differential Revision: D22608376
Pulled By: ezyang
fbshipit-source-id: 54a2aa127e069197471f1feede6ad8f8dc6a2f82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41828
This reverts commit fe66bdb498.
This also makes a sense to THTensorEvenMoreMath because sumall was removed, see THTensor_wrap.
Test Plan: Imported from OSS
Reviewed By: orionr
Differential Revision: D22657473
Pulled By: malfet
fbshipit-source-id: 95a806cedf1a3f4df91e6a21de1678252b117489
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41570
For min/max based quantization observers, calculating min and max of a tensor
takes most of the runtime. Since the calculation of min and max is done
on the same tensor, we can speed this up by only reading the tensor
once, and reducing with two outputs.
One question I had is whether we should put this into the quantization
namespace, since the use case is pretty specific.
This PR implements the easier CPU path to get an initial validation.
There is some needed additional work in future PRs, which durumu will
take a look at:
* CUDA kernel and tests
* making this work per channel
* benchmarking on observer
* benchmarking impact on QAT overhead
Test Plan:
```
python test/test_torch.py TestTorch.test_min_and_max
```
quick bench (not representative of real world use case):
https://gist.github.com/vkuzo/7fce61c3456dbc488d432430cafd6eca
```
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=1 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.0390) tensor(-5.4485) tensor([-5.4485, 5.0390])
min and max separate 11.90243935585022
min and max combined 6.353186368942261
% decrease 0.466228209277153
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=4 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.5586) tensor(-5.3983) tensor([-5.3983, 5.5586])
min and max separate 3.468616485595703
min and max combined 1.8227086067199707
% decrease 0.4745142294372342
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=8 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.2146) tensor(-5.2858) tensor([-5.2858, 5.2146])
min and max separate 1.5707778930664062
min and max combined 0.8645427227020264
% decrease 0.4496085496757899
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D22589349
fbshipit-source-id: c2e3f1b8b5c75a23372eb6e4c885f842904528ed
Summary:
The test loops over `upper` but does not use it effectively running the same test twice which increases test times for no gain.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41583
Reviewed By: soumith, seemethere, izdeby
Differential Revision: D22598475
Pulled By: zou3519
fbshipit-source-id: d100f20143293a116ff3ba08b0f4eaf0cc5a8099
Summary:
https://github.com/pytorch/pytorch/issues/38349
mruberry
Not entirely sure if all the changes are necessary in how functions are added to Pytorch.
Should it throw an error when called with a non-complex tensor? Numpy allows non-complex arrays in its imag() function which is used in its isreal() function but Pytorch's imag() throws an error for non-complex arrays.
Where does assertONNX() get its expected output to compare to?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41298
Reviewed By: ngimel
Differential Revision: D22610500
Pulled By: mruberry
fbshipit-source-id: 817d61f8b1c3670788b81690636bd41335788439
Summary:
lcm was missing an abs. This adds it plus extends the test for NumPy compliance. Also includes a few doc fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41552
Reviewed By: ngimel
Differential Revision: D22580997
Pulled By: mruberry
fbshipit-source-id: 5ce1db56f88df4355427e1b682fcf8877458ff4e
Summary:
Before, inverse for division by scalar is calculated in the precision of the non-scalar operands, which can lead to underflow:
```
>>> x = torch.tensor([3388.]).half().to(0)
>>> scale = 524288.0
>>> x.div(scale)
tensor([0.], device='cuda:0', dtype=torch.float16)
>>> x.mul(1. / scale)
tensor([0.0065], device='cuda:0', dtype=torch.float16)
```
This PR makes results of multiplication by inverse and division the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41446
Reviewed By: ezyang
Differential Revision: D22542872
Pulled By: ngimel
fbshipit-source-id: b60e3244809573299c2c3030a006487a117606e9
Summary:
Implementing the quantile operator similar to [numpy.quantile](https://numpy.org/devdocs/reference/generated/numpy.quantile.html).
For this implementation I'm reducing it to existing torch operators to get free CUDA implementation. It is more efficient to implement multiple quickselect algorithm instead of sorting but this can be addressed in a future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39417
Reviewed By: mruberry
Differential Revision: D22525217
Pulled By: heitorschueroff
fbshipit-source-id: 27a8bb23feee24fab7f8c228119d19edbb6cea33
Summary:
The test was always running on the CPU. This actually caused it to throw an error on non-MKL builds, since the CUDA test (which ran on the CPU) tried to execute but the test requires MKL (a requirement only checked for the CPU variant of the test).
Fixes https://github.com/pytorch/pytorch/issues/41402.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41523
Reviewed By: ngimel
Differential Revision: D22569344
Pulled By: mruberry
fbshipit-source-id: e9908c0ed4b5e7b18cc7608879c6213fbf787da2
Summary:
This test function is confusing since our `assertEqual` behavior allows for tolerance to be specified, and this is a redundant mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41514
Reviewed By: ngimel
Differential Revision: D22569348
Pulled By: mruberry
fbshipit-source-id: 2b2ff8aaa9625a51207941dfee8e07786181fe9f
Summary:
The contiguity preprocessing was mistakenly removed in
cd48fb5030 . It causes erroneous output
when the output tensor is not contiguous. Here we restore this
preprocessing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41286
Reviewed By: zou3519
Differential Revision: D22550822
Pulled By: ezyang
fbshipit-source-id: ebad4e2ba83d2d808e3f958d4adc9a5513a95bec
Summary:
Fixes https://github.com/pytorch/pytorch/issues/36403
Copy-paste of the issue description:
* Escape hatch: Introduce unsafe_* version of the three functions above that have the current behavior (outputs not tracked as views). The documentation will explain in detail why they are unsafe and when it is safe to use them. (basically, only the outputs OR the input can be modified inplace but not both. Otherwise, you will get wrong gradients).
* Deprecation: Use the CreationMeta on views to track views created by these three ops and throw warning when any of the views is modified inplace saying that this is deprecated and will raise an error soon. For users that really need to modify these views inplace, they should look at the doc of the unsafe_* version to make sure their usecase is valid:
* If it is not, then pytorch is computing wrong gradients for their use case and they should not do inplace anymore.
* If it is, then they can use the unsafe_* version to keep the current behavior.
* Removal: Use the CreationMeta on view to prevent any inplace on these views (like we do for all other views coming from multi-output Nodes). The users will still be able to use the unsafe_ versions if they really need to do this.
Note about BC-breaking:
- This PR changes the behavior of the regular function by making them return proper views now. This is a modification that the user will be able to see.
- We skip all the view logic for these views and so the code should behave the same as before (except the change in the `._is_view()` value).
- Even though the view logic is not performed, we do raise deprecation warnings for the cases where doing these ops would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39299
Differential Revision: D22432885
Pulled By: albanD
fbshipit-source-id: 324aef091b32ce69dd067fe9b13a3f17d85d0f12
Summary:
Resubmit #40927
Closes https://github.com/pytorch/pytorch/issues/24679, closes https://github.com/pytorch/pytorch/issues/24678
`addbmm` depends on `addmm` so needed to be ported at the same time. I also removed `THTensor_(baddbmm)` which I noticed had already been ported so was just dead code.
After having already written this code, I had to fix merge conflicts with https://github.com/pytorch/pytorch/issues/40354 which revealed there was already an established place for cpu blas routines in ATen. However, the version there doesn't make use of ATen's AVX dispatching so thought I'd wait for comment before migrating this into that style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40927
Reviewed By: ezyang
Differential Revision: D22468490
Pulled By: ngimel
fbshipit-source-id: f8a22be3216f67629420939455e31a88af20201d
Summary:
Per title. `lgamma` produces a different result for `-inf` compared to scipy, so there comparison is skipped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41225
Differential Revision: D22473346
Pulled By: ngimel
fbshipit-source-id: e4ebda1b10e2a061bd4cef38d1d7b5bf0f581790
Summary:
When we return to Python from C++ in PyTorch and have warnings and and error, we have the problem of what to do when the warnings throw because we can only throw one error.
Previously, if we had an error, we punted all warnings to the C++ warning handler which would write them to stderr (i.e. system fid 2) or pass them on to glog.
This has drawbacks if an error happened:
- Warnings are not handled through Python even if they don't raise,
- warnings are always printed with no way to suppress this,
- the printing bypasses sys.stderr, so Python modules wanting to
modify this don't work (with the prominent example being Jupyter).
This patch does the following instead:
- Set the warning using standard Python extension mechanisms,
- if Python decides that this warning is an error and we have a
PyTorch error, we print the warning through Python and clear
the error state (from the warning).
This resolves the three drawbacks discussed above, in particular it fixes https://github.com/pytorch/pytorch/issues/37240 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41116
Differential Revision: D22456393
Pulled By: albanD
fbshipit-source-id: c3376735723b092efe67319321a8a993402985c7
Summary:
Closes https://github.com/pytorch/pytorch/issues/24679, closes https://github.com/pytorch/pytorch/issues/24678
`addbmm` depends on `addmm` so needed to be ported at the same time. I also removed `THTensor_(baddbmm)` which I noticed had already been ported so was just dead code.
After having already written this code, I had to fix merge conflicts with https://github.com/pytorch/pytorch/issues/40354 which revealed there was already an established place for cpu blas routines in ATen. However, the version there doesn't make use of ATen's AVX dispatching so thought I'd wait for comment before migrating this into that style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40927
Differential Revision: D22418756
Pulled By: ezyang
fbshipit-source-id: 44e7bb5964263d73ae8cc6adc5f6d4e966476ae6
Summary:
Most time-consuming tests in test_nn (taking about half the time) were gradgradchecks on Conv3d. Reduce their sizes, and, most importantly, run gradgradcheck single-threaded, because that cuts the time of conv3d tests by an order of magnitude, and barely affects other tests.
These changes bring test_nn time down from 1200 s to ~550 s on my machine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40999
Differential Revision: D22396896
Pulled By: ngimel
fbshipit-source-id: 3b247caceb65d64be54499de1a55de377fdf9506
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40513
This PR makes the following changes:
1. Complex Printing now uses print formatting for it's real and imaginary values and they are joined at the end.
2. Adding 1. naturally fixes the printing of complex tensors in sci_mode=True
```
>>> torch.tensor(float('inf')+float('inf')*1j)
tensor(nan+infj)
>>> torch.randn(2000, dtype=torch.cfloat)
tensor([ 0.3015-0.2502j, -1.1102+1.2218j, -0.6324+0.0640j, ...,
-1.0200-0.2302j, 0.6511-0.1889j, -0.1069+0.1702j])
>>> torch.tensor([1e-3, 3+4j, 1e-5j, 1e-2+3j, 5+1e-6j])
tensor([1.0000e-03+0.0000e+00j, 3.0000e+00+4.0000e+00j, 0.0000e+00+1.0000e-05j,
1.0000e-02+3.0000e+00j, 5.0000e+00+1.0000e-06j])
>>> torch.randn(3, dtype=torch.cfloat)
tensor([ 1.0992-0.4459j, 1.1073+0.1202j, -0.2177-0.6342j])
>>> x = torch.tensor([1e2, 1e-2])
>>> torch.set_printoptions(sci_mode=False)
>>> x
tensor([ 100.0000, 0.0100])
>>> x = torch.tensor([1e2, 1e-2j])
>>> x
tensor([100.+0.0000j, 0.+0.0100j])
```
Test Plan: Imported from OSS
Differential Revision: D22309294
Pulled By: anjali411
fbshipit-source-id: 20edf9e28063725aeff39f3a246a2d7f348ff1e8
Summary:
This PR implements gh-33389.
As a result of this PR, users can now specify various reduction modes for scatter operations. Currently, `add`, `subtract`, `multiply` and `divide` have been implemented, and adding new ones is not hard.
While we now allow dynamic runtime selection of reduction modes, the performance is the same as as was the case for the `scatter_add_` method in the master branch. Proof can be seen in the graph below, which compares `scatter_add_` in the master branch (blue) and `scatter_(reduce="add")` from this PR (orange).
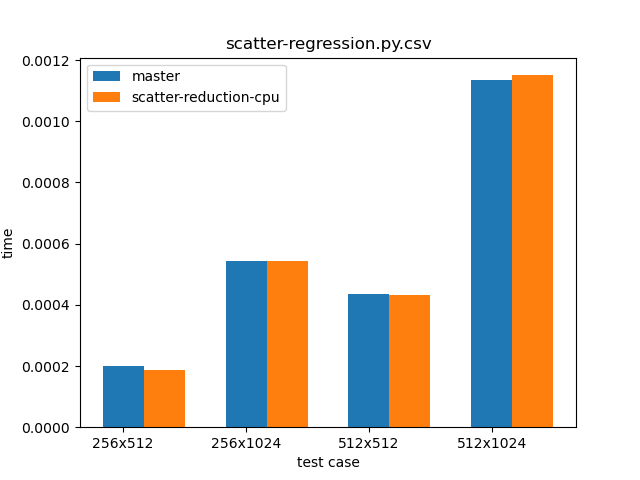
The script used for benchmarking is as follows:
``` python
import os
import sys
import torch
import time
import numpy
from IPython import get_ipython
Ms=256
Ns=512
dim = 0
top_power = 2
ipython = get_ipython()
plot_name = os.path.basename(__file__)
branch = sys.argv[1]
fname = open(plot_name + ".csv", "a+")
for pM in range(top_power):
M = Ms * (2 ** pM)
for pN in range(top_power):
N = Ns * (2 ** pN)
input_one = torch.rand(M, N)
index = torch.tensor(numpy.random.randint(0, M, (M, N)))
res = torch.randn(M, N)
test_case = f"{M}x{N}"
print(test_case)
tobj = ipython.magic("timeit -o res.scatter_(dim, index, input_one, reduce=\"add\")")
fname.write(f"{test_case},{branch},{tobj.average},{tobj.stdev}\n")
fname.close()
```
Additionally, one can see that various reduction modes take almost the same time to execute:
```
op: add
70.6 µs ± 27.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
26.1 µs ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: subtract
71 µs ± 20.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
26.4 µs ± 34.4 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: multiply
70.9 µs ± 31.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
27.4 µs ± 29.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: divide
164 µs ± 48.8 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
52.3 µs ± 132 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Script:
``` python
import torch
import time
import numpy
from IPython import get_ipython
ipython = get_ipython()
nrows = 3000
ncols = 10000
dims = [nrows, ncols]
res = torch.randint(5, 10, dims)
idx1 = torch.randint(dims[0], (1, dims[1])).long()
src1 = torch.randint(5, 10, (1, dims[1]))
idx2 = torch.randint(dims[1], (dims[0], 1)).long()
src2 = torch.randint(5, 10, (dims[0], 1))
for op in ["add", "subtract", "multiply", "divide"]:
print(f"op: {op}")
ipython.magic("timeit res.scatter_(0, idx1, src1, reduce=op)")
ipython.magic("timeit res.scatter_(1, idx2, src2, reduce=op)")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36447
Differential Revision: D22272631
Pulled By: ngimel
fbshipit-source-id: 3cdb46510f9bb0e135a5c03d6d4aa5de9402ee90
Summary:
BC-breaking NOTE:
In PyTorch 1.6 bool and integral fill values given to torch.full must set the dtype our out keyword arguments. In prior versions of PyTorch these fill values would return float tensors by default, but in PyTorch 1.7 they will return a bool or long tensor, respectively. The documentation for torch.full has been updated to reflect this.
PR NOTE:
This PR causes torch.full to throw a runtime error when it would have inferred a float dtype by being given a boolean or integer value. A versioned symbol for torch.full is added to preserve the behavior of already serialized Torchscript programs. Existing tests for this behavior being deprecated have been updated to reflect it now being unsupported, and a couple new tests have been added to validate the versioned symbol behavior. The documentation of torch.full has also been updated to reflect this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40364
Differential Revision: D22176640
Pulled By: mruberry
fbshipit-source-id: b20158ebbcb4f6bf269d05a688bcf4f6c853a965
Summary:
Updates concat kernel for contiguous input to support channels_last contig tensors.
This was tried on squeezenet model on pixel-2 device. It improves model perf by about 25%.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39448
Test Plan: test_cat_in_channels_last
Differential Revision: D22160526
Pulled By: kimishpatel
fbshipit-source-id: 6eee6e74b8a5c66167828283d16a52022a16997f
Summary:
Many of them have already been migrated to ATen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39102
Differential Revision: D22162193
Pulled By: VitalyFedyunin
fbshipit-source-id: 80db9914fbd792cd610c4e8ab643ab97845fac9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38490
A meta tensor is a tensor that is a lot like a normal tensor,
except it doesn't actually have any data associated with it.
You can use them to carry out shape/dtype computations without
actually having to run the actual code; for example, this could
be used to do shape inference in a JIT analysis pass.
Check out the description in DispatchKey.h for more information.
Meta tensors are part of a larger project to rationalize how we
write kernels so that we don't have to duplicate shape logic
in CPU kernel, CUDA kernel and meta kernel (this PR makes the
duplication problem worse!) However, that infrastructure can
be built on top of this proof of concept, which just shows how
you can start writing meta kernels today even without this
infrastructure.
There are a lot of things that don't work:
- I special cased printing for dense tensors only; if you try to
allocate a meta sparse / quantized tensor things aren't going
to work.
- The printing formula implies that torch.tensor() can take an
ellipsis, but I didn't add this.
- I wrote an example formula for binary operators, but it isn't
even right! (It doesn't do type promotion of memory layout
correctly). The most future proof way to do it right is to
factor out the relevant computation out of TensorIterator,
as it is quite involved.
- Nothing besides torch.add works right now
- Meta functions are ALWAYS included in mobile builds (selective
build doesn't work on them). This isn't a big deal for now
but will become more pressing as more meta functions are added.
One reason I'm putting up this PR now is to check with Yinghai Lu
if we can unblock shape inference for accelerators, while we are
still working on a long term plan for how to unify all shape
computation across our kernels.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21935609
Pulled By: ezyang
fbshipit-source-id: f7d8636eeb8516b6bc296db99a16e56029972eee
Summary:
Enable ops used in BERT which were missed in one of my earlier PRs.
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40236
Differential Revision: D22143965
Pulled By: ezyang
fbshipit-source-id: 5464ed021687fec1485e1c061e5a7aba71687fc4
Summary:
https://github.com/pytorch/pytorch/issues/39963 erroneously removed template specialization to compute offsets, causing cases relying on this specialization (topk for 4d+ tensors with topk dimension >= 1024/2048 depending on the type) to produce bogus results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40349
Differential Revision: D22153756
Pulled By: ngimel
fbshipit-source-id: cac04969acb6d7733a7da2c1784df7d30fda1606
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37968
Modify memory format promotion rules to avoid promoting when one of the input is ambiguous. New rules are:
Ambiguous + Contiguous = Contiguous
Ambiguous + Channels Last = Channels Last
Contiguous + Ambiguous ( NC11 ) = Contiguous
Contiguous + Channels Last = Contiguous ( + Warning ) Before this PR: Channels Last
Channels Last + Contiguous = Channels Last ( + Warning )
Channels Last + Ambiguous = Channels Last
Bias + Channels Last = Channels Last
Channels Last + Bias = Channels Last
Test Plan: Imported from OSS
Differential Revision: D21819573
Pulled By: VitalyFedyunin
fbshipit-source-id: 7381aad11720b2419fb37a6da6ff4f54009c6532
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40187
There were two issues:
1) The hand-written definition included an ambiguous default, which made the deprecated signature not selected. This didn't match the handwritten torch.nonzero, now they do.
2) A parsing bug for empty argument lists meant the signature wasn't being marked as deprecated.
Test Plan: Imported from OSS
Differential Revision: D22118236
Pulled By: gchanan
fbshipit-source-id: a433ce9069fef28aea97cbd76f2adf5a285abd73
Summary:
Closes gh-35418,
PR gh-16414 added [the `CMAKE_INSTALL_RPATH_USE_LINK_PATH`directive](https://github.com/pytorch/pytorch/pull/16414/files#diff-dcf5891602b4162c36c2125c806639c5R16) which is non-standard and will cause CMake to write an `RPATH` entry for libraries outside the current build. Removing it leaves an RPATH entry for `$ORIGIN` but removes the entries for things like `/usr/local/cuda-10.2/lib64/stubs:/usr/local/cuda-10.2/lib64` for `libcaffe2_nvrtc.so` on linux.
The added test fails before this PR, passes after. It is equivalent to checking `objdump -p torch/lib/libcaffe2_nvrtc.so | grep RPATH` for an external path to the directory where cuda "lives"
I am not sure if it solve the `rpath/libc++.1.dylib` problem for `_C.cpython-37m-darwin.so` on macOS in issue gh-36941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37737
Differential Revision: D22068657
Pulled By: ezyang
fbshipit-source-id: b04c529572a94363855f1e4dd3e93c9db3c85657
Summary:
Closes gh-39060
The `TensorIterator` splitting is based on `can_use_32bit_indexing` which assumes 32-bit signed ints, so we can get away with just 2**31 as the axis length. Also tested on an old commit that I can reproduce the test failure on just a 1d tensor, overall quartering the memory requirement for the test.
4c7d81f847/aten/src/ATen/native/TensorIterator.cpp (L879)
For reference, the test was first added in gh-33310.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40036
Differential Revision: D22068690
Pulled By: ezyang
fbshipit-source-id: 83199fd31647d1ef106b08f471c0e9517d3516e3
Summary:
Currently compare_with_numpy requires a device and dtype, but these arguments are ignored if a tensor is provided. This PR updates the function to only take device and dtype if a tensor-like object is given. This should prevent confusion that you could, for example, pass a CPU float tensor but provided a CUDA device and integer dtype.
Several tests are updated to reflect this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40064
Differential Revision: D22058072
Pulled By: mruberry
fbshipit-source-id: b494bb759855977ce45b79ed3ffb0319a21c324c
Summary:
Adds `torch.experimental.deterministic` flag to enforce deterministic algorithms across all of pytorch.
Adds `torch.experimental.deterministic_error_level` to allow users to choose between error/warning/silent if determinism for an operation is not available.
Adds `torch.experimental.alert_not_deterministic()` which should be called within operations that are not deterministic.
Offers both Python and ATen interfaces
Issue https://github.com/pytorch/pytorch/issues/15359
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38683
Differential Revision: D21998093
Pulled By: ezyang
fbshipit-source-id: 23aabbddd20f6199d846f97764ff24d728163737
Summary:
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import time
import torch
import numpy as np
for n, t in [(500_000, 10),
(1_000_000, 10)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.from_numpy(np.random.rand(n)).to(dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
print(f'Took:', time.time() - start)
print('****' * 10)
for n, t in [(50_000, 100),
(100_000, 100)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.rand(n, device='cuda', dtype=dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# torch.cuda.synchronize()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
# torch.cuda.synchronize()
print(f'CUDA Took:', time.time() - start)
```
Before:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 80.64455389976501
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 3.7778031826019287
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 5.045570611953735
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.53191947937012
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 7.640851736068726
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 10.399673461914062
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 4.873984098434448
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 4.713594436645508
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 11.167185068130493
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 7.195427417755127
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 7.669712066650391
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 20.20938801765442
```
After:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 81.09321522712708
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 0.06062650680541992
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 0.0862889289855957
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.85304307937622
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 0.13271093368530273
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 0.17215657234191895
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 0.035035133361816406
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 0.03631949424743652
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 0.05507040023803711
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 0.05105161666870117
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 0.05449223518371582
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 0.09161853790283203
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39742
Differential Revision: D21976915
Pulled By: ngimel
fbshipit-source-id: 34431f814f31b6dfd6179a89f8e4fa574da7a306
Summary:
**1.6 Deprecation Note**
In PyTorch 1.6 attempting to divide two integer tensors or an integer tensor and an integer scalar will throw a runtime error. This behavior was deprecated with a warning in PyTorch 1.5. In PyTorch 1.7 torch.div and the division operator will always perform true division like Python3 and NumPy.
To divide integer values use either torch.true_divide, for true division, or torch.floor_divide (the // operator) for floor division.
**PR Summary**
This PR updates the warning message when performing integer division to be a runtime error. Because some serialized Torchscript programs may rely on torch.div's historic behavior it also implements a "versioned symbol" for div that lets those models retain their current behavior. Extensive tests of this behavior are the majority of this PR.
Note this change bumps the produced file format version to delineate which programs should have their historic div behavior preserved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38620
Differential Revision: D21612598
Pulled By: mruberry
fbshipit-source-id: c9c33591abce2f7e97f67f0f859901f5b03ed47d
Summary:
**BC breaking note:**
In PyTorch 1.5 passing the out= kwarg to some functions, like torch.add, could affect the computation. That is,
```
out = torch.add(a, b)
```
could produce a different tensor than
```
torch.add(a, b, out=out)
```
This is because previously the out argument participated in the type promotion rules. For greater consistency with NumPy, Python, and C++, in PyTorch 1.6 the out argument no longer participates in type promotion, and has no effect on the computation performed.
**ORIGINAL PR NOTE**
This PR effectively rewrites Tensor Iterator's "compute_types" function to both clarify its behavior and change how our type promotion works to never consider the out argument when determining the iterator's "common dtype," AKA its "computation type." That is,
```
a = op(b, c)
```
should always produce the same result as
```
op(b, c, out=a)
```
This is consistent with NumPy and programming languages like Python and C++.
The conceptual model for this change is that a TensorIterator may have a "common computation type" that all inputs are cast to and its computation performed in. This common computation type, if it exists, is determined by applying our type promotion rules to the inputs.
A common computation type is natural for some classes of functions, like many binary elementwise functions (e.g. add, sub, mul, div...). (NumPy describes these as "universal functions.") Many functions, however, like indexing operations, don't have a natural common computation type. In the future we'll likely want to support setting the TensorIterator's common computation type explicitly to enable "floating ufuncs" like the sin function that promote integer types to the default scalar type. Logic like that is beyond the type promotion system, which can only review inputs.
Implementing this change in a readable and maintainable manner was challenging because compute_types() has had many small modifications from many authors over ~2 year period, and the existing logic was in some places outdated and in other places unnecessarily complicated. The existing "strategies" approach also painted with a broad brush, and two of them no longer made conceptual sense after this change. As a result, the new version of this function has a small set of flags to control its behavior. This has the positive effect of disentangling checks like all operands having the same device and their having the same dtype.
Additional changes in this PR:
- Unary operations now support out arguments with different dtypes. Like binary ops they check canCast(computation type, out dtype).
- The dtype checking for lerp was outdated and its error message included the wrong variable. It has been fixed.
- The check for whether all tensors are on the same device has been separated from other checks. TensorIterators used by copy disable this check.
- As a result of this change, the output dtype can be computed if only the input types are available.
- The "fast path" for checking if a common dtype computation is necessary has been updated and simplified to also handle zero-dim tensors.
- A couple helper functions for compute_types() have been inlined to improve readability.
- The confusingly named and no longer used promote_gpu_output_dtypes_ has been removed. This variable was intended to support casting fp16 reductions on GPU, but it has become a nullop. That logic is now implemented here: 856215509d/aten/src/ATen/native/ReduceOpsUtils.h (L207).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39655
Differential Revision: D21970878
Pulled By: mruberry
fbshipit-source-id: 5e6354c78240877ab5d6b1f7cfb351bd89049012
Summary:
It's better to have skipping logic explicitly defined in test decorators rather than in some hard-to-find blacklists
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39693
Differential Revision: D21947893
Pulled By: malfet
fbshipit-source-id: 3d0855eda7e10746ead80fccf84a8db8bf5a3ef1
Summary:
This PR aims to add `arcosh`, `arcsinh` and `arctanh` support. Please see issue https://github.com/pytorch/pytorch/issues/38349 for more details.
**TODOs:**
* [x] Add test cases for `arcosh`, `arcsinh` and `arctanh`. (need help)
* [x] Overload ops if `std::op` does not work with `thrust::complex` types (like for `sinh`, `cosh`).
Note: `std::acosh, std::asinh, std::atanh` do not support `thrust::complex` types. Added support for complex types for these 3 ops (`arccosh, arcsinh, arctanh`)
cc: mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38388
Differential Revision: D21882055
Pulled By: mruberry
fbshipit-source-id: d334590b47c5a89e491a002c3e41e6ffa89000e3
Summary:
Re-enable some test cases in `test_memory_format_operators` since their corresponding issue has been fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38648
Differential Revision: D21689085
Pulled By: VitalyFedyunin
fbshipit-source-id: 0aa09e0bf31ba98c8ad0191ac3afd31dda0f1d42
Summary:
Cut from https://github.com/pytorch/pytorch/pull/38994.
This is a helper function for comparing torch and NumPy behavior. It updates the existing and increasingly popular _np_compare function and moves it to be a method on TestCase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39179
Differential Revision: D21855082
Pulled By: mruberry
fbshipit-source-id: edca3b78ae392d32243b02bf61960898b6ba590f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32866, resubmit of https://github.com/pytorch/pytorch/issues/38970
The memory error in the issue is caused by int overflowing in col2vol. This version using mixed 32-bit and 64-bit indexing calculation lifts the maximum indexing possible without compromising the performance of ConvTranspose3d. vs 20-30% regression with pure 64-bit indexing.
This requires that input.numel() <= UINT_MAX, and channels * kernel.numel() <= UINT_MAX otherwise it raises an error. Previously, the code would crash or give incorrect results unless input.numel() * kernel.numel() <= INT_MAX.
Note that the test is a minimised reproducer for the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39198
Differential Revision: D21817836
Pulled By: ezyang
fbshipit-source-id: b9adfe9f9dd00f04435be132966b33ac6b9efbef
Summary:
The test is currently only enabled for CPU, and it will be enabled for CUDA after the migration of `min` and `max` from THC to ATen is done.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38850
Differential Revision: D21819388
Pulled By: ngimel
fbshipit-source-id: 406343e96bccbf9139eb1f8f2d49ed530dd83d62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39033
Added `real` and `imag` views as tensor attributes. Right now, tensor.imag is disabled for real tensors. This is because if we return a new tensor of zeros, the user would be able to update the tensor returned by tensor.imag which should not be allowed as numpy returns a read-only array, and pytorch doesn't support read-only tensors yet.
TODO in follow-up PRs:
1. add a setter for `real` and `imag`
2. add special case in codegen for `real` and `imag` backward functions.
3. remove `copy_real` and `copy_imag` methods.
Test Plan: Imported from OSS
Differential Revision: D21767542
Pulled By: anjali411
fbshipit-source-id: 539febf01f01ff055e3fbc7e9ff01fd3fe729056
Summary:
Adds complex support to `cumsum`, `cumprod` and relevant test update in `test_torch::tensor_op_tests`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39063
Differential Revision: D21771186
Pulled By: anjali411
fbshipit-source-id: 632916d4bdbd1c0941001898ab8146be2b7884fc
Summary:
**BC-breaking note:**
In previous versions of PyTorch zero dimensional CUDA tensors could be moved across devices implicitly. For example,
```
torch.tensor(5, device='cuda:0') + torch.tensor((1, 1), device='cuda:1')
```
would work, even though the tensors are on different CUDA devices. This is a frequent source of user confusion, however, and PyTorch generally does not move data across devices without it being explicit. This functionality is removed in PyTorch 1.6.
**PR Summary:**
Today in PyTorch we allow implicit data movement of zero dimensional CUDA tensors. For example, we allow:
```
torch.tensor(5, device='cuda:0') + torch.tensor((1, 1), device='cuda:1')
```
and
```
torch.tensor(2, device='cuda') + torch.tensor((3, 5))
```
In both of these cases TensorIterator would move the zero dim CUDA tensor to the device of the non-scalar tensor (cuda:1 in the first snippet, the CPU in the second snippet).
One of PyTorch's fundamental rules, however, is that it does not perform implicit data movement like this, and this change will causes these cases to throw an error. New tests for this behavior are added to test_torch.py, and tests of the old behavior are removed in test_torch.py and test_autograd.py. A cpp test in tensor_iterator_test.cpp is modified to account for the new behavior.
This addresses https://github.com/pytorch/pytorch/issues/36722.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38998
Differential Revision: D21757617
Pulled By: mruberry
fbshipit-source-id: 2498f07f4938d6de691fdbd5155ad2e881ff7fdb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32866
The memory error in the issue is caused by `int` overflowing in `col2vol`. This version using mixed 32-bit and 64-bit indexing calculation lifts the maximum indexing possible without compromising the performance of `ConvTranspose3d`. vs 20-30% regression with pure 64-bit indexing.
This requires that `input.numel() <= UINT_MAX`, and `channels * kernel.numel() <= UINT_MAX` otherwise it raises an error. Previously, the code would crash or give incorrect results unless `input.numel() * kernel.numel() <= INT_MAX`.
Note that the test is a minimised reproducer for the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38970
Differential Revision: D21748644
Pulled By: ezyang
fbshipit-source-id: 95060423219dc647595e1a24b3dcac520d3aecba
Summary:
`_TestTorchMixin` is base class which is instantiated across multiple types.
It was inherited from `object` in order to hide it from unittest test discovery mechanism.
But this approach makes it almost impossible to use static code analyzer on the class.
This PR implements alternative approach by hiding base class into inner class, per https://stackoverflow.com/a/25695512
Change imported class access path in `test_cuda.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39110
Test Plan:
run `test_torch.py --discover-tests` and `test_cuda.py --discover-tests` before and after change:
```
$ python test_torch.py --discover-tests|md5sum
2ca437bb5d65700763ce04cdacf6de3e -
$ python test_cuda.py --discover-tests|md5sum
b17df916fb0eeb6f0dd7222d7dae392c -
```
Differential Revision: D21759265
Pulled By: malfet
fbshipit-source-id: b01b06111469e551f7b78387449975e5248f6b9e
Summary:
1.6 Deprecation Note:
In 1.6 attempting to perform integer division using addcdiv will throw a RuntimeError, and in 1.7 the behavior will change so that addcdiv always performs a true division of its tensor1 and tensor2 inputs. See the warning in torch.addcdiv's documentation for more information.
PR Summary:
This PR updates the warning that appears when addcdiv performs integer division to throw a RuntimeError. This is intended to prevent silent errors when torch.addcdiv's behavior is changed to always perform true division in 1.7. The documentation is updated (slightly) to reflect this, as our the addcdiv tests in test_torch and test_type_promotion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38762
Differential Revision: D21657585
Pulled By: mruberry
fbshipit-source-id: c514b44409706f2bcfeca4473424b30cc48aafbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37181
Now that assertEquals considers dtypes in determining tolerance, most
tests don't need explicitly set precision.
Those that do are a few half precision tests on cuda. In this PR, those
are broken out to be handled explicitly, though we may also want to
consider further loosening the tolerance on half-precision.
Test Plan: Imported from OSS
Differential Revision: D21728402
Pulled By: nairbv
fbshipit-source-id: 85f3daf63f1bdbb5101e8dea8c125f13448ca228
Summary:
This updates assertEqual and assertEqual-like functions to either require both or neither of atol and rtol be specified. This should improve clarity around handling precision in the test suite, and it allows us to remove the legacy positional atol argument from assertEqual. In addition, the "message" kwarg is replace with a kwarg-only "msg" argument whose name is consistent with unittest's assertEqual argument.
In the future we could make "msg" an optional third positional argument to be more consistent with unittest's assertEqual, but requiring it be specified should be clear, and we can easily update the signature to make "msg" an optional positional argument in the future, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38872
Differential Revision: D21740237
Pulled By: mruberry
fbshipit-source-id: acbc027aa1d7877a49664d94db9a5fff91a07042
Summary:
This updates assertEqual and assertEqual-like functions to either require both or neither of atol and rtol be specified. This should improve clarity around handling precision in the test suite, and it allows us to remove the legacy positional atol argument from assertEqual. In addition, the "message" kwarg is replace with a kwarg-only "msg" argument whose name is consistent with unittest's assertEqual argument.
In the future we could make "msg" an optional third positional argument to be more consistent with unittest's assertEqual, but requiring it be specified should be clear, and we can easily update the signature to make "msg" an optional positional argument in the future, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38872
Differential Revision: D21717199
Pulled By: mruberry
fbshipit-source-id: 9feb856f94eee911b44f6c7140a1d07c1b026d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37098
### **Cherry-picked from another stack:**
Some code review already occurred here: https://github.com/pytorch/pytorch/pull/32582
### Summary:
Fixes: https://github.com/pytorch/pytorch/issues/32436
The issue caused incorrect handling of dtypes for scalar ** tensor.
e.g. before this change:
```
>>> 5.5 ** torch.ones(5, dtype=torch.int32)
tensor([5, 5, 5, 5, 5], dtype=torch.int32)
```
should return a float tensor.
Also fixes a number of incorrect cases:
* tensors to negative powers were giving incorrect results (1 instead
of 0 or error)
* Behavior wasn't consistent between cuda/cpu
* large_value ** 1 in some cases gave a result not equal
to large_value because of truncation in conversion to double and back.
BC-breaking:
Previously incorrect behavior (in 1.4):
```
>>> a
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
>>> a.pow_(.5)
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
```
After this change:
`RuntimeError: result type Float can't be cast to the desired output type Int`
Test Plan: Imported from OSS
Differential Revision: D21686207
Pulled By: nairbv
fbshipit-source-id: e797e7b195d224fa46404f668bb714e312ea78ac
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/36900
Since I feel this PR is already large enough, I didn't migrate max in this PR. Legacy code is not cleaned up either. All these remaining work will be done in later PRs after this is merged.
Benchmark on an extreme case
```python
import torch
print(torch.__version__)
t = torch.randn(100000, 2, device='cuda')
warmup = torch.arange(100000000)
torch.cuda.synchronize()
%timeit t.min(dim=0); torch.cuda.synchronize()
```
Before: 4ms; After: 24.5us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38440
Differential Revision: D21560691
Pulled By: ngimel
Summary:
This PR fixes the tolerance values for some of the bfloat16 div tests that were enabled on ROCm with incorrect tolerance values in the PR https://github.com/pytorch/pytorch/pull/38621
Also disabled(to unblock CI) `test_addcdiv*` for which the error is large when absolute values in the tensor are higher. This will have to be investigated further.
ezyang jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38823
Differential Revision: D21686290
Pulled By: ezyang
fbshipit-source-id: 85472680e1886bdc7c227ed2656e0b4fd5328e46
Summary:
This PR ports `masked_select` from TH to ATen and optimize the performance on CPU with TensorIterator.
https://github.com/pytorch/pytorch/issues/33053
1. single socket run: up to **5.4x** speedup;
2. single core run: up to **1.16x** speedup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33269
Differential Revision: D20922288
Pulled By: ngimel
fbshipit-source-id: 38e183a4e3599bba29bbbebe36264026abe1c50e
Summary:
Updates our tests in preparation of integer division using torch.div and torch.addcdiv throwing a runtime error by avoiding integer division using torch.div. This creates a brief period where integer division using torch.div is untested, but that should be OK (since it will soon throw a runtime error).
These callsites were identified using https://github.com/pytorch/pytorch/issues/36897.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38621
Differential Revision: D21612823
Pulled By: mruberry
fbshipit-source-id: 749c03a69feae02590b4395335163d9bf047e162
Summary:
floordiv was missing a couple dunder registrations, which was causing __ifloordiv__ to not be called when it should. This adds the appropriate registrations and adds a test verifying that the inplace dunders are actually occuring inplace.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38695
Differential Revision: D21633980
Pulled By: mruberry
fbshipit-source-id: a423f5ec327cdc062fd6d9d56abd36fe44ac8198
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37984
- `NumericUtils.h`
CUDA distribution kernels had two variants of transformation labdas(`uniform`/`normal` -> `lognormal`/`exponential`/`cauchy`/`geometric`...): for double-precision and optimized for CUDA single precision. It was done by using `::log`/`__logf`, `::exp`/`__expf` and `::tan/__tanf`. I moved them to `NumericUtils.h` and called them `at::exp`, `at::log` and `at::tan`. It allowed to unify CPU/CUDA transformation templates in `TransformationHelper.h`.
- `DistributionsHelper.h`
Made `normal_distribution`, `geometric_distribution`, `exponential_distribution`, `cauchy_distribution`, `lognormal_distribution` C10_HOST_DEVICE compatible to reuse them in CPU/CUDA distribution kernels.
Replaced explicit math with transformations from `TransformationHelper.h`
- `TransformationHelper.h`
Renamed `*_transformation` to `transformation::*`
Added clear unified host/device transformations templates `normal`, `cauchy`, `exponential`, `geometric`, `log_normal` which are used by both CPU and CUDA distribution kernels and custom PRNG distribution kernels.
- `cpu/DistributionTemplates.h`
Unified `normal_kernel`, `cauchy_kernel`, `log_normal_kernel`, `geometric_kernel`, `exponential_kernel`.
- `cuda/DistributionTemplates.h`
Extracted `UNIFORM_AND_TRANSFORM` and `NORMAL_AND_TRANSFORM` macros to reuse code between distribution kernel templates.
Unified transformation labdas(`uniform`/`normal` -> `lognormal`/`exponential`/`cauchy`/`geometric`...)
- `test_torch.py`
Added `scipy.stats.kstest` [Kolmogorov–Smirnov](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test) tests for `uniform`/`normal`/`lognormal`/`exponential`/`cauchy` distributions and [Chi-squared](https://en.wikipedia.org/wiki/Chi-squared_test) test for `geometric` one. To make sure that our distributions are correct.
- `cpu_rng_test.cpp`, `rng_test.h`
Fixed random_()'s from and to bounds issue for floating-point types, fixed cast/overflow warnings
- `THTensorRandom.h`, `THVector.h`
Moved unnecessary includes to `THTensorRandom.cpp`
Test Plan: Imported from OSS
Differential Revision: D21477955
Pulled By: pbelevich
fbshipit-source-id: 7b793d1761a7a921c4b4a4a7d21d5d6c48f03e72
Summary:
Edit: this has been updated to reflect the PR's current status, which has changed after review.
This PR updates the behavior of the assertEqual, assertNotEqual, and assert_allclose to be consistent with each other and torch.isclose. It corrects several additional bugs in the current implementations and adds extensive testing and comments, too.
These updates follow from changes to assertEqual like https://github.com/pytorch/pytorch/pull/34258 and https://github.com/pytorch/pytorch/pull/37069, and from our discussion of torch.isclose for complex tensors (see https://github.com/pytorch/pytorch/issues/36462), where we decided to implement a NumPy-compatible mathematical notion of "closeness" for complex tensors that is not a great fit for our testing framework.
The detailed changelist is:
- New test framework functions for comparing tensors and scalars
- Tensors are compared using isclose; the real and imaginary parts of complex tensors are compared independently
- Scalars are compared using the same algorithm
- assertEqual and assert_allclose now use this common comparison function, instead of each implementing their own with divergent behavior
- assertEqual-like debug messages are now available for all tensor and scalar comparisons, with additional context when comparing the components of sparse, quantized, and complex tensors
- Extensive testing of the comparison behavior and debug messages
- Small Updates
- assertEqual now takes an "exact_device" argument, analogous to "exact_dtype", which should be useful in multidevice tests
- assertEqual now takes an "equal_nan" argument for argument consistency with torch.isclose
- assertEqual no longer takes the "allow_inf" keyword, which misleadingly only applied to scalar comparisons, was only ever set (rarely) to true, and is not supported by torch.isclose
- Bug fixes:
- the exact_dtype attribute has been removed (no longer needed after https://github.com/pytorch/pytorch/pull/38103)
- message arguments passed to assertEqual are now handled correctly
- bool x other dtype comparisons are now supported
- uint8 and int8 tensor comparisons now function properly
- rtol for integer comparisons is now supported (default is zero)
- rtol and atol for scalar comparisons are now supported
- complex scalar comparisons are now supported, analogous to complex tensor comparisons
- assertNotEqual is now equivalent to the logical negation of assertEqual
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37294
Differential Revision: D21596830
Pulled By: mruberry
fbshipit-source-id: f2576669f7113a06f82581fc71883e6b772de19b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38505
This takes the testing of https://github.com/pytorch/pytorch/pull/38275, but doesn't include the kernel changes which are still being worked out.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D21580574
Pulled By: gchanan
fbshipit-source-id: f12317259cb7373989f6c9ad345b19aaac524851
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38400
* #38399 Added autograd tests, disabled jit autograd tests for complex and added a separate list for tests for complex dtype only
Test Plan: Imported from OSS
Differential Revision: D21572209
Pulled By: anjali411
fbshipit-source-id: 7036029e9f8336139f5d54e0dfff9759f3bf8376
Summary:
Together with https://github.com/pytorch/pytorch/issues/37758, this fixes https://github.com/pytorch/pytorch/issues/37743 and fixes https://github.com/pytorch/pytorch/issues/24861.
This follows the CUDA fix in https://github.com/pytorch/pytorch/issues/37758, vectorised using a `blendv` to replace the if conditionals.
Most of the complication is from `remainder` supporting `at::Half` where `fmod` doesn't. I've now got `fmod` working on `Vec256<at::Half>` as well as enabling half dispatch for `fmod` so it matches `remainder`.
I also added `fmod` support to `Vec256<at::BFloat16>` before realising that `remainder` doesn't support `BFloat16` anyway. I could also enable `BFloat16` if that's desirable. If not, I don't think `Vec256<BFloat16>` should be missing `fmod` anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38293
Differential Revision: D21539801
Pulled By: ezyang
fbshipit-source-id: abac6a3ed2076932adc459174cd3d8d510f3e1d5
Summary:
Closes https://github.com/pytorch/pytorch/issues/24561
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.exp(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.exp(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.exp(a) a.numel() == 10000 for 20000 times torch.half
0.3001665159999902
torch.exp(a) a.numel() == 10000 for 20000 times torch.float
0.28265794499998265
torch.exp(a) a.numel() == 10000 for 20000 times torch.double
0.3432170909998149
torch.exp(a) a.numel() == 100000 for 20000 times torch.half
0.32273333800003456
torch.exp(a) a.numel() == 100000 for 20000 times torch.float
0.31498759600003723
torch.exp(a) a.numel() == 100000 for 20000 times torch.double
1.079708754999956
```
After:
```
torch.exp(a) a.numel() == 10000 for 20000 times torch.half
0.27996097300092515
torch.exp(a) a.numel() == 10000 for 20000 times torch.float
0.2774473429999489
torch.exp(a) a.numel() == 10000 for 20000 times torch.double
0.33066844799941464
torch.exp(a) a.numel() == 100000 for 20000 times torch.half
0.27641824200145493
torch.exp(a) a.numel() == 100000 for 20000 times torch.float
0.27805968599932385
torch.exp(a) a.numel() == 100000 for 20000 times torch.double
1.0644143180015817
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36652
Differential Revision: D21164653
Pulled By: VitalyFedyunin
fbshipit-source-id: 42c7b24b0d85ff1d390231f1457968a8869b8db3
Summary:
Before, multinomial kernels did not advance random states enough, which lead to the same sequence being generated over and over with a shift of 4. This PR fixes that.
Fixes https://github.com/pytorch/pytorch/issues/37403
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38046
Differential Revision: D21516542
Pulled By: ngimel
fbshipit-source-id: 23248a8c3a5c44316c4c35cd71a8c3b5f76c90f2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38018
when calling `eq_with_nan(v, kValue)` having `v` and `kValue` both `nan` is returning `false` when it should be `true`.
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/SortingKthValue.cu#L76
The implementation is using intrinsics such as `__double_as_longlong` and comparing their bit representations. But the values of the bits obtained for both nans are different.
`9221120237041090560` for `v`
`9223372036854775807` for `kValue`
two different nans have different bit representations, so we have to do additional comparisons to fix this.
I changed this comparison and it seems to be working now.
However, when compared to a CPU implementation, the returned indices for the values seems to be random but valid.
Probably this is an effect of the comparison order in the Cuda version.
I am not sure if this is ok since all the indices point to valid elements.
For the snippet in the issue I get the following:
```
# CUDA Values
tensor([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan],
device='cuda:0', dtype=torch.float64)
# CUDA indices
tensor([304, 400, 400, 528, 304, 304, 528, 336, 304, 432, 400, 280, 280, 336,
304, 336, 400, 304, 336, 560], device='cuda:0')
```
```
# CPU values
tensor([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan],
dtype=torch.float64)
# CPU indices
tensor([515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515,
515, 515, 515, 515, 515, 515])
```
Also, maybe its better to change the `eq_with_nan` implementations to address this instead?
I am not sure if this will cause code to break in other places though ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38216
Differential Revision: D21517617
Pulled By: ngimel
fbshipit-source-id: deeb7bb0ac519a03aa0c5f365005a9150e6404e6
Summary:
Reland of https://github.com/pytorch/pytorch/issues/38140. It got reverted since it broke slow tests which were only run on master branch(thanks mruberry !). Enabling all CI tests in this PR to make sure they pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38288
Reviewed By: mruberry
Differential Revision: D21524923
Pulled By: ailzhang
fbshipit-source-id: 3a9ecc7461781066499c677249112434b08d2783
Summary:
I'm mostly done with cleaning up test/ folder. There're a bunch of remaining callsites but they're "valid" in testing `type()` functionalities. We cannot remove them until it's fully deprecated.
Next PR would mainly focus on move some callsites to an internal API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38140
Differential Revision: D21483808
Pulled By: ailzhang
fbshipit-source-id: 12f5de6151bae59374cfa0372e827651de7e1c0f
Summary:
`is_tensor` doesn't really have a reason to exist anymore (other than
backwards compatibility) and is worse for typechecking with mypy (see
gh-32824). Given that it may not be obvious what the fix is once mypy
gives an error, make the change in a number of places at once, and add
a note on this to the `is_tensor` docstring.
Recommending an isinstance check instead has been done for quite a
while, e.g. https://github.com/pytorch/pytorch/pull/7769#discussion_r190458971
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38062
Differential Revision: D21470963
Pulled By: ezyang
fbshipit-source-id: 98dd60d32ca0650abd2de21910b541d32b0eea41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38033
Pickles require class names to be actually accessible from the module
in question. _VariableFunction was not! This fixes it.
Fixes https://github.com/pytorch/pytorch/issues/37703
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21458068
Pulled By: ezyang
fbshipit-source-id: 2a5ac41f9d1972e300724981b9b4b84364ddc18c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37157 on my machine.
This was annoying to track down. The essence is that cublas expects column major inputs and Pytorch tensors are usually row major. Cublas lets you request that it act on transposed data, and the erroring `gemv` calls in https://github.com/pytorch/pytorch/issues/37157 make that request. The problem is, [cublasSgemv and cublasDgemv](https://docs.nvidia.com/cuda/cublas/index.html#cublas-lt-t-gt-gemv) (called by [`gemv<float>`](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L318)) and `gemv<double>`) regard their `m, n` arguments values as _pre_-transpose sizes, while [cublasGemmEx](https://docs.nvidia.com/cuda/cublas/index.html#cublas-GemmEx) (called by `gemv<at::Half>`, see [here](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L342)) and [here](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L229))) regards its `m, k` argument values as _post_-transpose sizes. This is inconsistent. It turns out the `gemv<float>/<double>` calls are configured correctly and the `gemv<at::Half>` calls aren't.
Strikethrough text below is no longer accurate, ngimel suggested a better way to handle gemv->gemm forwarding. [Comments in code](https://github.com/pytorch/pytorch/pull/37569/files#diff-686aa86335f96b4ecb9b37f562feed12R323-R348) provide an up-to-date explanation.
Keeping out-of-date strikethrough text because I don't have the heart to delete it all and because it captures an intermediate state of my brain that will help orient me if i ever have to fix this again.
~~To convince myself this PR keeps `at::cuda::blas::gemv`'s external API consistent across dtypes, I need to think through what happens when a pytorch tensor input of size `(a,b)` multiples a vector of size `(b,)` for 4 cases:~~
### ~~1. input is row-major (needs cublas internal transpose)~~
#### ~~1a. input is float or double~~
~~`gemv<float>/<double>` call `cublasS/Dgemv`, forwarding `trans`,** `m`, and `n` directly.~~
~~`cublasS/Ggemv` expects "a m × n matrix stored in column-major format" (so m is the input's fast dim). Input has size `(a, b)` in row-major format. We can reinterpret it as a column-major matrix with size `(b, a)` without any memory movement. So the gemv call should supply `m=b`, `n=a`. However, we're not trying to multiply a matrix `(b, a)` x a vector `(b,)`, we're trying to sum across `b` for matrix and vector. So we also request that cublas transpose the matrix internally by supplying `trans='t'` to `blas::gemv`, which becomes `trans=CUBLAS_OP_T` to the `cublasS/Ggemv`.~~
~~As long as the code calling `blas::gemv` thinks carefully and passes `trans='t'`, `m=b`, `n=a`, cublas carries out `(a, b) x (b,)` and all is well.~~
#### ~~1b. input is half or bfloat16~~
~~`blas::gemv<at::Half>` takes a different code path, calling `gemm<at::Half>` which calls `cublasGemmEx`. The job of this PR is to make sure the exterior `blas::gemv` caller's carefully thought-out argument choices (`trans='t'`, `m=b`, `n=a`) remain correct.~~
~~`cublasGemmEx` takes args `transa, transb, m, n, k, ....others we don't care about` and carries out~~
```
C = α op ( A ) op ( B ) + β C
where α and β are scalars, and A , B and C are matrices stored in column-major format with
dimensions op ( A ) m × k , op ( B ) k × n and C m × n Also, for matrix A
A if transa == CUBLAS_OP_N
op ( A ) = A^T if transa == CUBLAS_OP_T ...
```
~~`gemv<at::Half>` hacks a gemv by calling gemm such that the raw gemm's `m` is the output dim, `k` is the summed dim, and `n=1`, . Reasonable, as long as we get the values right, given that we also need to transpose the input.~~
~~To conform with cublas docs we interpret input as column-major with size `(b, a)`. As for the `<float>/<double>` gemv we want cublas to carry out input (interpreted as column major), internally transposed, times vector of size `(b,)`. In other words we want cublas to apply `op(A) x B`, where op is transpose and `A` is input interpreted as column major. Docs define `m` and `k` by saying `op(A)` has dims `m x k` **(`m` and `k` are _post_-`op` sizes)**. `A` was `(b, a)`, `op(A)` is `(a, b)`, so the correct thing is to supply `m=a`, `k=b` to the underlying gemm. **For the `<float>/<double>` gemv, we passed `m=b`, not `m=a`, to the raw `cublasS/Dgemv`.**~~
~~The exterior `blas::gemv` must have been called with `trans='t'`, `m=b`, `n=a` (as required by the `<float>/<double>` versions). So when gemv is about to call gemm, **we [swap](https://github.com/pytorch/pytorch/pull/37569/files#diff-686aa86335f96b4ecb9b37f562feed12R330) the local values of `m` and `n` so that `m=a`, `n=b`,** then put `m (=a)` in the gemm's `m` spot, 1 in the gemm's `n` spot, and `n (=b)` in the gemm's `k` spot. All is well (we made the right gemm call after ingesting the same arg values as `blas::gemv<float>/<double>`).~~
### ~~2. input is column-major (doesn't need cublas transpose)~~
#### ~~2a. input is float or double~~
~~input is `(a,b)`, already column-major with strides `(1,a)`. Code calling `blas::gemv` supplies `trans='n'` (which becomes `CUBLAS_OP_N`, no internal transpose), `m=a`, `n=b`.~~
#### ~~2b. input is half or bfloat16~~
~~`blas::gemv` should pass `transa='n'`, `m=a`, `n=1`, `k=b` to the underlying gemm. The exterior `blas::gemv` must have been called with `trans='t'`, `m=a`, `n=b` (as required by the `<float>/<double>` versions). So **in this case we _don't_ swap `blas::gemv`'s local values of `m` and `n`.** We directly put `m (=a)` in the gemm's `m` spot, 1 in the gemm's `n` spot, and `n (=b)` in the gemm's `k` spot. All is well (we made the right gemm call after ingesting the same arg values as `blas::gemv<float>/<double>`).~~
~~** `trans` is a string `t` or `n` in the `at::cuda::blas::gemv` API, which gets [converted](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L314)) to a corresponding cublas enum value `CUBLAS_OP_T` (do transpose internally) or `CUBLAS_OP_N` (don't transpose internally) just before the raw cublas call.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37569
Differential Revision: D21405955
Pulled By: ngimel
fbshipit-source-id: e831414bbf54860fb7a4dd8d5666ef8081acd3ee
Summary:
Closes https://github.com/pytorch/pytorch/issues/24558
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.erf(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.erf(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.erf(a) a.numel() == 10000 for 20000 times torch.half
0.29057903600187274
torch.erf(a) a.numel() == 10000 for 20000 times torch.float
0.2836507789979805
torch.erf(a) a.numel() == 10000 for 20000 times torch.double
0.44974555500084534
torch.erf(a) a.numel() == 100000 for 20000 times torch.half
0.31807255600142526
torch.erf(a) a.numel() == 100000 for 20000 times torch.float
0.3216503109979385
torch.erf(a) a.numel() == 100000 for 20000 times torch.double
2.0413486910001666
```
After:
```
torch.erf(a) a.numel() == 10000 for 20000 times torch.half
0.2867302739996376
torch.erf(a) a.numel() == 10000 for 20000 times torch.float
0.28851128199858067
torch.erf(a) a.numel() == 10000 for 20000 times torch.double
0.4592030350013374
torch.erf(a) a.numel() == 100000 for 20000 times torch.half
0.28704102400115517
torch.erf(a) a.numel() == 100000 for 20000 times torch.float
0.29036039400125446
torch.erf(a) a.numel() == 100000 for 20000 times torch.double
2.04035638699861
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36724
Differential Revision: D21164626
Pulled By: VitalyFedyunin
fbshipit-source-id: e6f3390b2bbb6e8d21e18ffe15f5d49a170fae83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37537
The documentation states that `random_()` samples "from the discrete uniform distribution". Floating-point types can support _discrete_ _uniform_ distribution only within range [-(2^digits), 2^digits], where `digits = std::numeric_limits<fp_type>::digits`, or
- [-(2^53), 2^53] for double
- [-(2^24), 2^24] for double
- [-(2^11), 2^11] for half
- [-(2^8), 2^8] for bfloat16
The worst scenario is when the floating-point type can not represent numbers between `from` and `to`. E.g.
```
torch.empty(10, dtype=torch.float).random_(16777217, 16777218)
tensor([16777216., 16777216., 16777216., 16777216., 16777216., 16777216.,
16777216., 16777216., 16777216., 16777216.])
```
Because 16777217 can not be represented in float
Test Plan: Imported from OSS
Differential Revision: D21380387
Pulled By: pbelevich
fbshipit-source-id: 80d77a5b592fff9ab35155a63045b71dcc8db2fd
Summary:
This pull request fixes and re-enables two of the tests disabled in https://github.com/pytorch/pytorch/issues/37427
1. `test_sparse_add_out_bfloat16` in test_sparse.py fixed to use updated `atol` argument instead of `prec` for `assertEqual`
2. The conversion of `flt_min` to `int64` is divergent on HIP compared to numpy. The change removes that conversion from the `test_float_to_int_conversion_finite` test case in test_torch.py
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37616
Differential Revision: D21379876
Pulled By: ezyang
fbshipit-source-id: 2bfb41d67874383a01330c5d540ee516b3b07dcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37507
Replace `TORCH_WARN` with `TORCH_CHECK` if `Tensor.random_()`'s `from` or `to-1` is out of bounds for tensor's dtype. Previously warning said "This warning will become an error in version 1.6 release, please fix the code in advance", so the time has come.
Related to #33106
Test Plan: Imported from OSS
Differential Revision: D21349413
Pulled By: pbelevich
fbshipit-source-id: ac7c196a48fc58634611e427e65429a948119e40
Summary:
Following up on this: https://github.com/pytorch/pytorch/pull/35851 cross dtype storage copy is not being used internally, so I have not included cross dtype copy for complex.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35771
Differential Revision: D21319650
Pulled By: anjali411
fbshipit-source-id: 07c72996ee598eba0cf401ad61534494d6f5b5b3
Summary:
Closes https://github.com/pytorch/pytorch/issues/24641
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.tan(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.tan(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.tan(a) a.numel() == 10000 for 20000 times torch.half
0.28325206200003095
torch.tan(a) a.numel() == 10000 for 20000 times torch.float
0.28363607099998944
torch.tan(a) a.numel() == 10000 for 20000 times torch.double
0.43924326799998425
torch.tan(a) a.numel() == 100000 for 20000 times torch.half
0.3754699589999859
torch.tan(a) a.numel() == 100000 for 20000 times torch.float
0.38143782899999223
torch.tan(a) a.numel() == 100000 for 20000 times torch.double
1.7672172019999834
```
After:
```
torch.tan(a) a.numel() == 10000 for 20000 times torch.half
0.28982524599996395
torch.tan(a) a.numel() == 10000 for 20000 times torch.float
0.29121579000002384
torch.tan(a) a.numel() == 10000 for 20000 times torch.double
0.4599610559998837
torch.tan(a) a.numel() == 100000 for 20000 times torch.half
0.3557764019997194
torch.tan(a) a.numel() == 100000 for 20000 times torch.float
0.34793807599999127
torch.tan(a) a.numel() == 100000 for 20000 times torch.double
1.7564662459999454
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36906
Differential Revision: D21335320
Pulled By: VitalyFedyunin
fbshipit-source-id: efab9c175c60fb09223105380d48b93a81994fb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27957
Benchmark (gcc 8.3, Debian Buster, turbo off, Release build, Intel(R) Xeon(R) E-2136):
```python
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.uint8', 'torch.int8', 'torch.int16', 'torch.int32', 'torch.int64'):
for n, t in [(40_000, 50000),
(400_000, 5000)]:
print(f'torch.linspace(0, 10, {n}, dtype={dtype}) for {t} times')
print(timeit.timeit(f'torch.linspace(0, 10, {n}, dtype={dtype})', setup=f'import torch', number=t))
```
Before:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.3964195849839598
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
1.2374563289922662
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.8631796519621275
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
1.6991038109990768
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.8358083459897898
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.7214750979910605
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.8356257299892604
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.706238206999842
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
1.7463878280250356
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
1.6172360889613628
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
1.8656846070080064
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
1.714238062966615
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
1.8272205490502529
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
1.6409171230043285
```
After:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.0077099470072426
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
0.8227124120458029
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.0058343949494883
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
0.8376779520185664
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.903041019977536
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.7576498500420712
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.7628699769848026
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.6204477970022708
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
2.0970272019621916
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
1.9493417189805768
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
2.29020385700278
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
2.1212510910118
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
2.3479344319785014
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
2.156775983981788
```
Test Plan: Imported from OSS
Differential Revision: D20773454
Pulled By: VitalyFedyunin
fbshipit-source-id: ebeef59a90edde581669cc2afcc3d65929c8ac79
Summary:
Benchmark with same build settings on same system.
Closes https://github.com/pytorch/pytorch/issues/24545
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.cos(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.cos(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.cos(a) a.numel() == 10000 for 20000 times torch.half
0.2797315450006863
torch.cos(a) a.numel() == 10000 for 20000 times torch.float
0.283109110998339
torch.cos(a) a.numel() == 10000 for 20000 times torch.double
0.3648525129974587
torch.cos(a) a.numel() == 100000 for 20000 times torch.half
0.34239949499897193
torch.cos(a) a.numel() == 100000 for 20000 times torch.float
0.33680364199972246
torch.cos(a) a.numel() == 100000 for 20000 times torch.double
1.0512770260102116
```
After:
```
torch.cos(a) a.numel() == 10000 for 20000 times torch.half
0.285825898999974
torch.cos(a) a.numel() == 10000 for 20000 times torch.float
0.2781305120001889
torch.cos(a) a.numel() == 10000 for 20000 times torch.double
0.34188826099989456
torch.cos(a) a.numel() == 100000 for 20000 times torch.half
0.29040409300023384
torch.cos(a) a.numel() == 100000 for 20000 times torch.float
0.28678944200009937
torch.cos(a) a.numel() == 100000 for 20000 times torch.double
1.065477349000048
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36653
Differential Revision: D21164675
Pulled By: VitalyFedyunin
fbshipit-source-id: 5dd5d3af47c2a5527e1f4ab7669c2ed9a2293cee
Summary:
Adds support for generating Vandermonde matrices based off of the Numpy implementation found [here](https://github.com/numpy/numpy/blob/v1.17.0/numpy/lib/twodim_base.py#L475-L563).
Adds test to ensure generated matrix matches expected Numpy implementation. Note test are only limited to torch.long and torch.double due to differences in now PyTorch and Numpy deal with type promotion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36725
Differential Revision: D21075138
Pulled By: jessebrizzi
fbshipit-source-id: 6bb1559e8247945714469b0e2b07c6f4d5fd1fd0
Summary:
Added enough operators to make sure that all unit tests from ATen/basic are passing, except for MM and IntArrayRefExpansion
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37121
Test Plan: `./bin/basic --gtest_filter=--gtest_filter=BasicTest.BasicTestHalfCPU` + `python -c "import torch; x = torch.tensor([2], dtype=torch.half); print(torch.isfinite(x+x))"`
Differential Revision: D21296863
Pulled By: malfet
fbshipit-source-id: e03d7a6939df11f611a9b317543bac52403cd009
Summary:
This pull request disables the unit tests that were observed to be failing once `test2` was enabled. These tests will be one by one looked at and fixed at the earliest, but until then disabling them to unblock `test2`
The pull request also disables fftPlanDestroy for rocFFT to avoid double-freeing FFT handles
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37427
Differential Revision: D21302909
Pulled By: ezyang
fbshipit-source-id: ecadda3778e65b7f4f97e24b932b96b9ce928616
Summary:
dylanbespalko anjali411
Not sure if the test should be added to `test_torch` or `test_complex`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36749
Differential Revision: D21290529
Pulled By: anjali411
fbshipit-source-id: 07bc282e4c9480cd015ec5db104e79728437cd90
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37084
There are 3 alternatives for this design.
This PR and the first one.
When a tensor is a scalar `ndim==0`, accessing view_offsets_[0] when doing reductions, yields an invalid offset for the index which is the output of `argmax` and `argmin`.
fba9b9a023/aten/src/ATen/native/cpu/Reduce.h (L217)
This also happens in cuda code:
fba9b9a023/aten/src/ATen/native/cuda/Reduce.cuh (L797)
The second alternative is to check the size of `view_offsets` before accessing it. But this introduces some burden.
The third alternative is related to the way that inputs are treated in `argmax` and `argmin`
depending on the `dim` argument value.
fba9b9a023/aten/src/ATen/native/ReduceOps.cpp (L775-L780)
If `dim` is not specified, then the scalar gets reshaped into a 1-dim tensor and everything works properly, since now `view_offsets` has an actual entry.
If dim is specified, then the input remains as a scalar causing the issue we see here.
This PR tries to solve it in a generic way for every case so I went with option 1. I am willing to discuss it and change if you think that the other alternatives are better.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37214
Differential Revision: D21258320
Pulled By: ngimel
fbshipit-source-id: 46223412187bbba4bfa7337e3f1d2518db72dea2
Summary:
Today in PyTorch, warnings triggered in C++ are printed to Python users like this:
`../aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.`
This may be unhelpful to Python users, who have complained it's difficult to relate these messages back to their programs. After this PR, warnings that go through the PyWarningHandler and allow it to add context print like this:
```
test/test_torch.py:16463: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. (Triggered internally at ../aten/src/ATen/native/BinaryOps.cpp:81.)
cpu_result = getattr(cpu_tensor, op_str)(*cpu_args)
```
This relates the warning back to the user's program. The information about the cpp file and line number is preserved in the body of the warning message.
Some warnings, like those generated in the JIT, already account for a user's Python context, and so they specify that they should be printed verbatim and are unaffected by this change. Warnings originating in Python and warnings that go through c10's warning handler, which prints to cerr, are also unaffected.
A test is added to test_torch.py for this behavior. The test relies on uint8 indexing being deprecated and its warning originating from its current header file, which is an unfortunate dependency. We could implement a `torch.warn` function, instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36052
Differential Revision: D20887740
Pulled By: mruberry
fbshipit-source-id: d3515c6658a387acb7fccaf83f23dbb452f02847
Summary:
Resolves https://github.com/pytorch/pytorch/issues/36730https://github.com/pytorch/pytorch/issues/36057
Partially resolves: https://github.com/pytorch/pytorch/issues/36671
```
>>> 2j / torch.tensor([4], dtype = torch.complex64)
tensor([(0.0000+0.5000j)], dtype=torch.complex64)
>>> 1 / torch.tensor(3+4j)
tensor((0.1200-0.1600j), dtype=torch.complex64)
```
rdiv is more generally broken for all dtypes because it doesn't promote the types properly
eg.
```
>>> 1 / torch.tensor(2)
tensor(0)
>>> 2j / torch.tensor(4)
tensor(0)
```
so that issue should be fixed in a separate PR
Adding CPU acc types for complex
Added cumsum, cumprod for complex dtypes
Added complex dtypes to get_all_math_dtypes to expand testing for complex dtypes
Old PR - https://github.com/pytorch/pytorch/pull/36747
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37193
Differential Revision: D21229373
Pulled By: anjali411
fbshipit-source-id: 8a086136d8c10dabe62358d276331e3f22bb2342
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37128
In certain build modes (in fbcode, building a .par) the mechanism to get test output "expect" files doesn't work.
All other tests in test_torch.py already had assertExpectedInline instead of assertExpected, with the expected result inline in the file.
There was no equivalent for assertExpectedRaises, so I added one, and changed the tests for test_is_nonzero (the only test using this)
Test Plan: CI, specifically the test test_is_nonzero should pass
Reviewed By: malfet
Differential Revision: D21197651
fbshipit-source-id: 2a07079efdcf1f0b0abe60e92cadcf55d81d4b13
Summary:
Closes https://github.com/pytorch/pytorch/issues/24642
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.tanh(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.tanh(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.tanh(a) a.numel() == 10000 for 20000 times torch.half
0.2816318240002147
torch.tanh(a) a.numel() == 10000 for 20000 times torch.float
0.2728829070001666
torch.tanh(a) a.numel() == 10000 for 20000 times torch.double
0.39797203200214426
torch.tanh(a) a.numel() == 100000 for 20000 times torch.half
0.3228214350019698
torch.tanh(a) a.numel() == 100000 for 20000 times torch.float
0.31780802399953245
torch.tanh(a) a.numel() == 100000 for 20000 times torch.double
1.3745740449994628
```
After:
```
torch.tanh(a) a.numel() == 10000 for 20000 times torch.half
0.27825374500025646
torch.tanh(a) a.numel() == 10000 for 20000 times torch.float
0.27764024499992956
torch.tanh(a) a.numel() == 10000 for 20000 times torch.double
0.3771585260001302
torch.tanh(a) a.numel() == 100000 for 20000 times torch.half
0.2995866400015075
torch.tanh(a) a.numel() == 100000 for 20000 times torch.float
0.28355561699936516
torch.tanh(a) a.numel() == 100000 for 20000 times torch.double
1.393811182002537
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36995
Differential Revision: D21163353
Pulled By: ngimel
fbshipit-source-id: e2216ff62cdfdd13b6a56daa63d4ef1440d991d4
Summary:
Fixes a safety issue (Nonsense values and segfaults) introduced by https://github.com/pytorch/pytorch/pull/36875 when in-place gather tries to use incorrect shapes.
Consider the following block of code:
```
k0 = 8
k1 = 8
m = 100
x = torch.rand((k0, k1))
ind = torch.randint(0, k0, (m, k1))
output = torch.empty((m, k1))
print(torch.gather(x, 0, ind, out=output))
print(torch.gather(x, 1, ind, out=output))
```
The first gather is legal, the second is not. (`ind` and `output` need to be transposed) Previously this was caught when the kernel tried to restride inputs for TensorIterator, but we can no longer rely on those checks and must test explicitly. If `m` is small the second gather returns gibberish; if it is large enough to push the read out of memory block the program segfaults.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37102
Differential Revision: D21190580
Pulled By: robieta
fbshipit-source-id: 80175620d24ad3380d78995f7ec7dbf2627d2998
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/24605https://github.com/pytorch/pytorch/issues/24535https://github.com/pytorch/pytorch/issues/24739https://github.com/pytorch/pytorch/issues/24680https://github.com/pytorch/pytorch/issues/30986
This does not fix https://github.com/pytorch/pytorch/issues/29984, it will be fixed in later PR.
Most of this PR is just following the same logic inside TH and THC except the handle of n-dimensional zero-sized tensor, in specific the case:
```
(m,).addmv((m, 0), (0,), beta, alpha)
```
# Legacy code bugs and how this PR deal with it
The above case is a case where BLAS often have a mismatch of semantics with PyTorch: For BLAS and cuBLAS, the above is a noop, but for PyTorch, it is a scalar-vector multiplication `output = beta * input`. The handle of this case is already very poor in legacy code and it is poorly tested:
For the CPU implementation, there are two code paths:
- Path 1: when dtype is float or double and `USE_BLAS`, then use BLAS
- Path 2: when other dtypes or not `USE_BLAS`, use a fallback kernel in PyTorch
For the CUDA implementation, there are also two code paths:
- Path 1: when float or double, then use `cublasSgemv` or `cublasDgemv` in cuBlas
- Path 2: when half, dispatch to `addmm`
`test_blas_alpha_beta_empty` is supposed to cover all cases, but unfortunately, it only tests the Path 1 of CUDA and Path 1 of CPU, and both uncovered paths (path 2 for CPU and path 2 for CUDA) are buggy in legacy code. In this PR, I expanded the coverage of `test_blas_alpha_beta_empty`, but unfortunately, I have to skip the `half` dtype on CUDA 9. See the description below for detail:
## Bug on CPU implementation
For the CPU implementation, the fallback kernel in path 2 already has the same semantics as PyTorch, not BLAS. But the code that tries to correct BLAS semantics to match PyTorch also runs on this case, leading to double correction, that is, `output = beta * input` now becomes `output = beta * beta * input`.
This leads to the issue https://github.com/pytorch/pytorch/issues/30986 I just opened, and it is fixed in this PR.
## Bug on CUDA implementation
For the CUDA implementation, path 2 dispatches to
```
(m, 1).addmm((m, 0), (0, 1), beta, alpha)
```
But unfortunately, for some old CUDA version when on old GPU on half dtype, the above is also noop, which is definitely not correct.
But from what I see, on newer CUDA version or newer GPU, this is not a problem. This is a bug of PyTorch in `addmm`, so I opened a new issue https://github.com/pytorch/pytorch/issues/31006 to track this problem. But this is highly likely a dependency bug for PyTorch originating from cuBLAS, and it is only on a rarely used edge case on old hardware and software, so this issue would be a `won't_fix` unless some real requirements strongly indicate that this should be fixed.
This issue is already with legacy code, and this PR does not make it worse. To prevent this issue from bothering us, I disable the test of `half` dtype for CUDA 9 when expanding the coverage of `test_blas_alpha_beta_empty`.
I promote a CircleCI CUDA 10.1 test to `XImportant` so that it runs on PRs, because the path 2 of CUDA implementation is only covered by this configuration. Let me know if I should revert this change.
## An additional problem
In legacy code for `addmv`, dtype `bfloat16` is enabled and dispatch to `addmm`, but `addmm` does not support `bfloat16` from what I test. I do the same thing in the new code. Let me know if I should do it differently.
# Benchmark
Code:
```python
import torch
print(torch.__version__)
for i in range(1000):
torch.arange(i, device='cuda')
print('cpu')
for i in 10, 100, 1000, 10000:
a = torch.randn((i,))
b = torch.randn((i, i))
c = torch.randn((i,))
%timeit a.addmv(b, c, alpha=1, beta=2)
print('cuda')
for i in 10, 100, 1000, 10000:
a = torch.randn((i,)).cuda()
b = torch.randn((i, i)).cuda()
c = torch.randn((i,)).cuda()
torch.cuda.synchronize()
%timeit a.addmv(b, c, alpha=1, beta=2); torch.cuda.synchronize()
```
Before:
```
1.5.0a0+2b45368
cpu
2.74 µs ± 30.8 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
8.5 µs ± 85.5 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
686 µs ± 2.95 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
74 ms ± 410 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
cuda
The slowest run took 4.81 times longer than the fastest. This could mean that an intermediate result is being cached.
27.6 µs ± 23 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
17.3 µs ± 151 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
20.5 µs ± 369 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
756 µs ± 6.81 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After:
```
1.5.0a0+66b4034
cpu
3.29 µs ± 20 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
9.09 µs ± 7.41 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
687 µs ± 7.01 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
73.8 ms ± 453 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
cuda
18.2 µs ± 478 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
17.7 µs ± 299 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
21.5 µs ± 2.38 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
751 µs ± 35.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30898
Differential Revision: D20660338
Pulled By: anjali411
fbshipit-source-id: db1f521f124198f63545064026f93fcb16b68f18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36680
If torch compiled without MKL, this test fails with torch.fft requiring MKL support
Test Plan: CI
Reviewed By: malfet
Differential Revision: D21051362
fbshipit-source-id: dd2e2c7d323622c1c25fc4c817b85d83d2241b3a
Summary:
Closes https://github.com/pytorch/pytorch/issues/24546
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.cosh(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.cosh(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.cosh(a) a.numel() == 10000 for 20000 times torch.half
0.2813017509997735
torch.cosh(a) a.numel() == 10000 for 20000 times torch.float
0.28355878599904827
torch.cosh(a) a.numel() == 10000 for 20000 times torch.double
0.27810572300040803
torch.cosh(a) a.numel() == 100000 for 20000 times torch.half
0.3239932899996347
torch.cosh(a) a.numel() == 100000 for 20000 times torch.float
0.321233343998756
torch.cosh(a) a.numel() == 100000 for 20000 times torch.double
0.5546665399997437
```
After:
```
torch.cosh(a) a.numel() == 10000 for 20000 times torch.half
0.2905335750001541
torch.cosh(a) a.numel() == 10000 for 20000 times torch.float
0.27596429500044906
torch.cosh(a) a.numel() == 10000 for 20000 times torch.double
0.30358699899989006
torch.cosh(a) a.numel() == 100000 for 20000 times torch.half
0.30139567500009434
torch.cosh(a) a.numel() == 100000 for 20000 times torch.float
0.30246640400036995
torch.cosh(a) a.numel() == 100000 for 20000 times torch.double
0.5403946970000106
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36654
Differential Revision: D21164606
Pulled By: VitalyFedyunin
fbshipit-source-id: 55e88f94044957f81599ae3c12cda38a3e2c985c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35615
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Now we can clean up a lot of cruft that we put in place to support it.
These changes were all done manually, and I skipped anything that seemed
like it would take more than a few seconds, so I think it makes sense to
review it manually as well (though using side-by-side view and ignoring
whitespace change might be helpful).
Test Plan: CI
Differential Revision: D20842886
Pulled By: dreiss
fbshipit-source-id: 8cad4e87c45895e7ce3938a88e61157a79504aed
Summary:
Resolves https://github.com/pytorch/pytorch/issues/36730https://github.com/pytorch/pytorch/issues/36057
Partially resolves: https://github.com/pytorch/pytorch/issues/36671
```
>>> 2j / torch.tensor([4], dtype = torch.complex64)
tensor([(0.0000+0.5000j)], dtype=torch.complex64)
>>> 1 / torch.tensor(3+4j)
tensor((0.1200-0.1600j), dtype=torch.complex64)
```
rdiv is more generally broken for all dtypes because it doesn't promote the types properly
eg.
```
>>> 1 / torch.tensor(2)
tensor(0)
>>> 2j / torch.tensor(4)
tensor(0)
```
so that issue should be fixed in a separate PR
Adding CPU acc types for complex
Added cumsum, cumprod for complex dtypes
Added complex dtypes to get_all_math_dtypes to expand testing for complex dtypes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36747
Differential Revision: D21138687
Pulled By: anjali411
fbshipit-source-id: ad3602ccf86c70294a6e71e564cb0d46c393dfab
Summary:
Previously torch.isclose would RuntimeError when called on complex tensors. This update updates torch.isclose to run on complex tensors and be consistent with [NumPy](https://numpy.org/doc/1.18/reference/generated/numpy.isclose.html). However, NumPy's handling of NaN, -inf, and inf values is odd, so I adopted Python's [cmath.isclose](https://docs.python.org/3/library/cmath.html) behavior when dealing with them. See https://github.com/numpy/numpy/issues/15959 for more on NumPy's behavior.
While implementing complex isclose I also simplified the isclose algorithm to:
- A is close to B if A and B are equal, if equal_nan is true then NaN is equal to NaN
- If A and B are finite, then A is close to B if `abs(a - b) <= (atol + abs(rtol * b))`
This PR also documents torch.isclose, since it was undocumented, and adds multiple tests for its behavior to test_torch.py since it had no dedicated tests.
The PR leaves equal_nan=True with complex inputs an error for now, pending the outcome of https://github.com/numpy/numpy/issues/15959.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36456
Differential Revision: D21159853
Pulled By: mruberry
fbshipit-source-id: fb18fa7048e6104cc24f5ce308fdfb0ba5e4bb30
Summary:
Addresses https://github.com/pytorch/pytorch/issues/36807. Also updates the cast testing to catch issues like this better.
In the future a more constexpr based approach to casting would be nice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36832
Differential Revision: D21120822
Pulled By: mruberry
fbshipit-source-id: 9504ddd36cfe6d9f9f545fc277fef36855c1b221
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34258
This PR allows both atol and rtol to be specified, uses defaults based on the prior analysis (spreadsheet attached to https://github.com/pytorch/pytorch/pull/32538), but retains the absolute tolerance behavior in cases where precision was previously specified explicitly.
Test Plan: Imported from OSS
Differential Revision: D21110255
Pulled By: nairbv
fbshipit-source-id: 57b3a004c7d5ac1be80ee765f03668b1b13f4a7e
Summary:
Implements complex isfinite and isinf, consistent with NumPy.
A complex value is finite if and only if both its real and imaginary part are finite.
A complex value is infinite if and only if its real or imaginary part are infinite.
Old isfinite, isinf, and isnan tests are modernized and instead of fixtures the torch results are compared with NumPy. A new test is added for complex isfinite, isinf, and isnan. The docs for each function are updated to clarify what finite, infinite, and NaN values are.
The new tests rely on a new helper, _np_compare, that we'll likely want to generalize in the near future and use in more tests.
Addresses part of the complex support tasks. See https://github.com/pytorch/pytorch/issues/33152.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36648
Differential Revision: D21054766
Pulled By: mruberry
fbshipit-source-id: d947707c5437385775c82f4e6c722349ca5a2174
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36351
Adds CUDA kernels for hardsigmoid, to enable its use in training.
Note: the update to the cpu backward pass is to keep the cpu vs cuda
logic consistent, no change in functionality.
Test Plan:
add CI for the forward pass
run this for the backward pass:
https://gist.github.com/vkuzo/95957d365600f9ad10d25bd20f58cc1a
Imported from OSS
Differential Revision: D20955589
fbshipit-source-id: dc198aa6a58e1a7996e1831f1e479c398ffcbc90
{kind=link}