mingfeima
84b1c9798c
add BFloat16 support for AvgPool2d on CPU ( #66927 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/66927
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33353198
Pulled By: VitalyFedyunin
fbshipit-source-id: 1aeaa4bb90ac99210b8f6051c09d6995d06ce3a1
2022-01-14 07:59:10 -08:00
mingfeima
910c01020e
add BFloat16 support for AdaptiveMaxPool2d on CPU ( #66929 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/66929
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33353199
Pulled By: VitalyFedyunin
fbshipit-source-id: d402d5deb7ca766259ca42118ddc16625e134c4c
2022-01-13 20:00:42 -08:00
Jake Tae
eac3decf93
ModuleList concatenation ( #70887 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70441 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70887
Reviewed By: ejguan
Differential Revision: D33555431
Pulled By: albanD
fbshipit-source-id: ce42459ee46a611e98e89f02686acbac16b6b668
2022-01-13 15:31:07 -08:00
mingfeima
385773cb77
add BFloat16 support for MaxPool2d on CPU ( #56903 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/56903
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D28836791
Pulled By: VitalyFedyunin
fbshipit-source-id: e03d55cc30dfa3628f096938fbad34b1031948af
2022-01-12 14:20:20 -08:00
Ilya Persky
a8612cd72a
Skip failing tests in test_nn if compiled without LAPACK ( #70913 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70912
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70913
Reviewed By: mruberry
Differential Revision: D33534840
Pulled By: albanD
fbshipit-source-id: 0facf5682140ecd7a78edb34b9cd997f9319e084
2022-01-11 12:21:18 -08:00
George Qi
d7db5fb462
ctc loss no batch dim support ( #70092 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/70092
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33280068
Pulled By: george-qi
fbshipit-source-id: 3278fb2d745a396fe27c00fb5f40df0e7f584f81
2022-01-07 14:33:22 -08:00
Bin Bao
f135438d3b
Dispatch to at::convolution intead of at::_convolution in _convolution_double_backward ( #70661 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70661
Dispatching to at::convolution can make Lazy Tensor trace the right convolution op.
Test Plan: pytest test/test_nn.py -k test_conv_double_backward_strided_with_3D_input_and_weight
Reviewed By: wconstab, jbschlosser
Differential Revision: D33428780
Pulled By: desertfire
fbshipit-source-id: 899e4135588ea33fff23d16103c25d9bcd3f902c
2022-01-07 07:53:46 -08:00
Joel Schlosser
e6befbe85c
Add flag to optionally average output attention weights across heads ( #70055 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70055
Reviewed By: bhosmer
Differential Revision: D33457866
Pulled By: jbschlosser
fbshipit-source-id: 17746b3668b0148c1e1ed8333227b7c42f1e3bf5
2022-01-06 17:32:37 -08:00
Joel Schlosser
7b8f73dd32
No-batch-dim support for ConvNd ( #70506 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/70506
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33355034
Pulled By: jbschlosser
fbshipit-source-id: 5a42645299b1d82cee7d461826acca1c5b35a71c
2022-01-06 16:53:50 -08:00
Jake Tae
b7742b437a
Allow RNN hidden_size to be 0 ( #70556 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56767 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70556
Reviewed By: ngimel
Differential Revision: D33455156
Pulled By: jbschlosser
fbshipit-source-id: 5dc57b09d7beb6ae81dfabc318e87c109bb4e6ae
2022-01-06 14:18:36 -08:00
Jane Xu
c00d33033c
Remove repeat test for types in test nn ( #70872 )
...
Summary:
Helps fix a part of https://github.com/pytorch/pytorch/issues/69865
The first commit just migrates everything as is.
The second commit uses the "device" variable instead of passing "cuda" everywhere
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70872
Reviewed By: jbschlosser
Differential Revision: D33455941
Pulled By: janeyx99
fbshipit-source-id: 9d9ec8c95f1714c40d55800e652ccd69b0c314dc
2022-01-06 09:20:02 -08:00
soulitzer
3051aabd0e
Add forward AD formulas for convolution and some others ( #69956 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69956
Test Plan: Imported from OSS
Reviewed By: albanD, bdhirsh
Differential Revision: D33235974
Pulled By: soulitzer
fbshipit-source-id: ea60d687edc5d62d92f3fd3cb6640421d32c908c
2022-01-06 08:39:51 -08:00
Joel Schlosser
b60b1b100f
Set cuDNN deterministic flag for test_conv_double_backward_cuda ( #69941 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/69833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69941
Reviewed By: george-qi
Differential Revision: D33430727
Pulled By: jbschlosser
fbshipit-source-id: 4a250bd0e5460ee631730afe0ab68ba72f37d292
2022-01-05 10:05:56 -08:00
kshitij12345
7bfaa230be
[nn] adaptive_avg_pool{1/2/3}d : Error on negative output_size ( #70488 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70232
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70488
Reviewed By: H-Huang
Differential Revision: D33367289
Pulled By: jbschlosser
fbshipit-source-id: 6b7b89d72c4e1e049ad6a0addb22a261c28ddb4c
2021-12-30 14:42:11 -08:00
mingfeima
401a6b682b
add BFloat16 support for AdaptiveAvgPool2d on CPU ( #56902 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/56902
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D28836789
Pulled By: VitalyFedyunin
fbshipit-source-id: caac5e5b15190b8010bbfbc6920aa44032208ee7
2021-12-30 11:58:37 -08:00
vfdev
d2abf3f981
Added antialias flag to interpolate (CPU only, bicubic) ( #68819 )
...
Summary:
Description:
- Added antialias flag to interpolate (CPU only)
- forward and backward for bicubic mode
- added tests
Previous PR for bilinear, https://github.com/pytorch/pytorch/pull/65142
### Benchmarks
<details>
<summary>
Forward pass, CPU. PTH interpolation vs PIL
</summary>
Cases:
- PTH RGB 3 Channels, float32 vs PIL RGB uint8 (apples vs pears)
- PTH 1 Channel, float32 vs PIL 1 Channel Float
Code: https://gist.github.com/vfdev-5/b173761a567f2283b3c649c3c0574112
```
Torch config: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_61,code=sm_61
- CuDNN 8.0.5
- Build settings: BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.11.0, USE_CUDA=1, USE_CUDNN=1, USE_EIGEN_FOR_BLAS=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=OFF, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=0, USE_OPENMP=ON, USE_ROCM=OFF,
Num threads: 1
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (320, 196) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 4.5 | 5.2
channels_last non-contiguous torch.float32 | 4.5 | 5.3
Times are in milliseconds (ms).
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (460, 220) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 5.7 | 6.4
channels_last non-contiguous torch.float32 | 5.7 | 6.4
Times are in milliseconds (ms).
[------------------- Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (120, 96) --------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.0 | 4.0
channels_last non-contiguous torch.float32 | 2.9 | 4.1
Times are in milliseconds (ms).
[------------------ Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (1200, 196) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 14.7 | 17.1
channels_last non-contiguous torch.float32 | 14.8 | 17.2
Times are in milliseconds (ms).
[------------------ Downsampling (bicubic): torch.Size([1, 3, 906, 438]) -> (120, 1200) -------------------]
| Reference, PIL 8.4.0, mode: RGB | 1.11.0a0+gitb0bdf58
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.5 | 3.9
channels_last non-contiguous torch.float32 | 3.5 | 3.9
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (320, 196) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 2.4 | 1.8
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (460, 220) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 3.1 | 2.2
Times are in milliseconds (ms).
[---------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (120, 96) ----------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.6 | 1.4
Times are in milliseconds (ms).
[--------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (1200, 196) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 7.9 | 5.7
Times are in milliseconds (ms).
[--------- Downsampling (bicubic): torch.Size([1, 1, 906, 438]) -> (120, 1200) ---------]
| Reference, PIL 8.4.0, mode: F | 1.11.0a0+gitb0bdf58
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.7 | 1.3
Times are in milliseconds (ms).
```
</details>
Code is moved from torchvision: https://github.com/pytorch/vision/pull/3810 and https://github.com/pytorch/vision/pull/4208
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68819
Reviewed By: mikaylagawarecki
Differential Revision: D33339117
Pulled By: jbschlosser
fbshipit-source-id: 6a0443bbba5439f52c7dbc1be819b75634cf67c4
2021-12-29 14:04:43 -08:00
George Qi
8af39b7668
AdaptiveLogSoftmaxWithLoss no_batch_dim support ( #69054 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69054
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33200166
Pulled By: george-qi
fbshipit-source-id: 9d953744351a25f372418d2a64e8402356d1e9b7
2021-12-29 10:25:26 -08:00
soulitzer
3116d87024
Add forward AD formulas for {adaptive_,fractional_,}max_pool{2,3}d_{backward,} ( #69884 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69884
Also fixes: https://github.com/pytorch/pytorch/issues/69322 , https://github.com/pytorch/pytorch/issues/69325
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D33093039
Pulled By: soulitzer
fbshipit-source-id: b9a522a00f4e9e85974888de5058de07280f8f66
2021-12-23 15:51:09 -08:00
soulitzer
5651e1e3ad
Add auto_linear formulas and some others ( #69727 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69727
Still need to test the backward ones. We would need to update gradgradcheck to check forward over backward.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33031728
Pulled By: soulitzer
fbshipit-source-id: 86c59df5d2196b5c8dbbb1efed9321e02ab46d30
2021-12-20 12:15:25 -08:00
Albert Liang
0d06616c47
Add dict methods to ParameterDict ( #69403 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68476
We implemented all of the following `dict` methods for `ParameterDict`
- `get `
- `setdefault`
- `popitem`
- `fromkeys`
- `copy`
- `__or__`
- `__ior__`
- `__reversed__`
- `__ror__`
The behavior of these new methods matches the expected behavior of python `dict` as defined by the language itself: https://docs.python.org/3/library/stdtypes.html#typesmapping
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69403
Reviewed By: albanD
Differential Revision: D33187111
Pulled By: jbschlosser
fbshipit-source-id: ecaa493837dbc9d8566ddbb113b898997e2debcb
2021-12-17 10:15:47 -08:00
Rui Zhu
46ace4ac33
Add support for masked_softmax when softmax_elements > 1024 & corresponding unit tests ( #69924 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69924
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32819181
fbshipit-source-id: 6838a11d3554ec8e1bd48f1c2c7b1ee3a4680995
2021-12-15 16:44:15 -08:00
kshitij12345
e8d5c7cf7f
[nn] mha : no-batch-dim support (python) ( #67176 )
...
Summary:
Reference: https://github.com/pytorch/pytorch/issues/60585
* [x] Update docs
* [x] Tests for shape checking
Tests take roughly 20s on system that I use. Below is the timings for slowest 20 tests.
```
pytest test/test_modules.py -k _multih --durations=20
============================================================================================== test session starts ===============================================================================================
platform linux -- Python 3.10.0, pytest-6.2.5, py-1.10.0, pluggy-1.0.0
rootdir: /home/kshiteej/Pytorch/pytorch_no_batch_mha, configfile: pytest.ini
plugins: hypothesis-6.23.2, repeat-0.9.1
collected 372 items / 336 deselected / 36 selected
test/test_modules.py ..............ssssssss.............. [100%]
================================================================================================ warnings summary ================================================================================================
../../.conda/envs/pytorch-cuda-dev/lib/python3.10/site-packages/torch/backends/cudnn/__init__.py:73
test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float32
/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.10/site-packages/torch/backends/cudnn/__init__.py:73: UserWarning: PyTorch was compiled without cuDNN/MIOpen support. To use cuDNN/MIOpen, rebuild PyTorch making sure the library is visible to the build system.
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/warnings.html
============================================================================================== slowest 20 durations ==============================================================================================
8.66s call test/test_modules.py::TestModuleCUDA::test_gradgrad_nn_MultiheadAttention_cuda_float64
2.02s call test/test_modules.py::TestModuleCPU::test_gradgrad_nn_MultiheadAttention_cpu_float64
1.89s call test/test_modules.py::TestModuleCUDA::test_grad_nn_MultiheadAttention_cuda_float64
1.01s call test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float32
0.51s call test/test_modules.py::TestModuleCPU::test_grad_nn_MultiheadAttention_cpu_float64
0.46s call test/test_modules.py::TestModuleCUDA::test_forward_nn_MultiheadAttention_cuda_float32
0.45s call test/test_modules.py::TestModuleCUDA::test_non_contiguous_tensors_nn_MultiheadAttention_cuda_float64
0.44s call test/test_modules.py::TestModuleCUDA::test_non_contiguous_tensors_nn_MultiheadAttention_cuda_float32
0.21s call test/test_modules.py::TestModuleCUDA::test_pickle_nn_MultiheadAttention_cuda_float64
0.21s call test/test_modules.py::TestModuleCUDA::test_pickle_nn_MultiheadAttention_cuda_float32
0.18s call test/test_modules.py::TestModuleCUDA::test_forward_nn_MultiheadAttention_cuda_float64
0.17s call test/test_modules.py::TestModuleCPU::test_non_contiguous_tensors_nn_MultiheadAttention_cpu_float32
0.16s call test/test_modules.py::TestModuleCPU::test_non_contiguous_tensors_nn_MultiheadAttention_cpu_float64
0.11s call test/test_modules.py::TestModuleCUDA::test_factory_kwargs_nn_MultiheadAttention_cuda_float64
0.08s call test/test_modules.py::TestModuleCPU::test_pickle_nn_MultiheadAttention_cpu_float32
0.08s call test/test_modules.py::TestModuleCPU::test_pickle_nn_MultiheadAttention_cpu_float64
0.06s call test/test_modules.py::TestModuleCUDA::test_repr_nn_MultiheadAttention_cuda_float64
0.06s call test/test_modules.py::TestModuleCUDA::test_repr_nn_MultiheadAttention_cuda_float32
0.06s call test/test_modules.py::TestModuleCPU::test_forward_nn_MultiheadAttention_cpu_float32
0.06s call test/test_modules.py::TestModuleCPU::test_forward_nn_MultiheadAttention_cpu_float64
============================================================================================ short test summary info =============================================================================================
=========================================================================== 28 passed, 8 skipped, 336 deselected, 2 warnings in 19.71s ===========================================================================
```
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67176
Reviewed By: dagitses
Differential Revision: D33094285
Pulled By: jbschlosser
fbshipit-source-id: 0dd08261b8a457bf8bad5c7f3f6ded14b0beaf0d
2021-12-14 13:21:21 -08:00
Rui Zhu
1a299d8f1b
Add support for transformer layout of masked_softmax ( #69272 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69272
In transformer encoder and MHA, masked_softmax's mask is a 2D tensor (B, D), where input is a 4D tensor (B, H, D, D).
This mask could be simply broadcasted to a (B, H, D, D) like input, and then do a regular masked_softmax, however it will bring the problem of non-contiguous mask & consume more memory.
In this diff, we maintained mask's shape unchanged, while calc the corresponding mask for input in each cuda thread.
This new layout is not currently supported in CPU yet.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32605557
fbshipit-source-id: ef37f86981fdb2fb264d776f0e581841de5d68d2
2021-12-14 10:51:58 -08:00
Joel Schlosser
fc37e5b3ed
Hook up general convolution to convolution_backward ( #69584 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69584
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32936380
Pulled By: jbschlosser
fbshipit-source-id: c6fdd88db33bd1a9d0eabea47ae09a4d5b170e92
2021-12-12 17:30:01 -08:00
Joel Schlosser
f0e98dcbd3
General convolution_backward function ( #69044 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69044
Test Plan: Imported from OSS
Reviewed By: zou3519, albanD, H-Huang
Differential Revision: D32708818
Pulled By: jbschlosser
fbshipit-source-id: e563baa3197811d8d51553fc83718ace2f8d1b7a
2021-12-12 15:53:38 -08:00
Rui Zhu
aab67c6dff
Add native masked_softmax ( #69268 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69268
This diff enabled native masked softmax on CUDA, also expanded our current warp_softmax to accept masking.
The mask in this masked softmax has to be the same shape as input, and has to be contiguous.
In a following diff I will submit later, I will have encoder mask layout included, where input is BHDD and mask is BD.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32338419
fbshipit-source-id: 48c3fde793ad4535725d9dae712db42e2bdb8a49
2021-12-09 23:29:45 -08:00
kshitij12345
7407e3d6fd
[fix] cross_entropy : fix weight with ignore_index and label_smoothing ( #69511 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/69339
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69511
Reviewed By: mrshenli
Differential Revision: D32951935
Pulled By: jbschlosser
fbshipit-source-id: 482eae851861a32f96bd6231dd3448fb6d44a015
2021-12-08 12:08:33 -08:00
jjsjann123
3c1e2ff9eb
fixing layer_norm cuda bug ( #69210 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/69208
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69210
Reviewed By: H-Huang
Differential Revision: D32764811
Pulled By: ngimel
fbshipit-source-id: fb4201fe5f2284fcb22e36bc1029eef4a21b09bf
2021-12-01 15:46:47 -08:00
Kurt Mohler
d507fd63f3
Check that block height and width are positive in nn.Fold ( #69048 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68875
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69048
Reviewed By: samdow
Differential Revision: D32729307
Pulled By: jbschlosser
fbshipit-source-id: 162cafb005873012d900d86997d07640967038c0
2021-12-01 10:08:47 -08:00
Omkar Salpekar
8e343ba5db
Revert D32611368: [pytorch][PR] Initial version of general convolution_backward
...
Test Plan: revert-hammer
Differential Revision:
D32611368 (445b31abff
2021-11-23 13:39:36 -08:00
Joel Schlosser
445b31abff
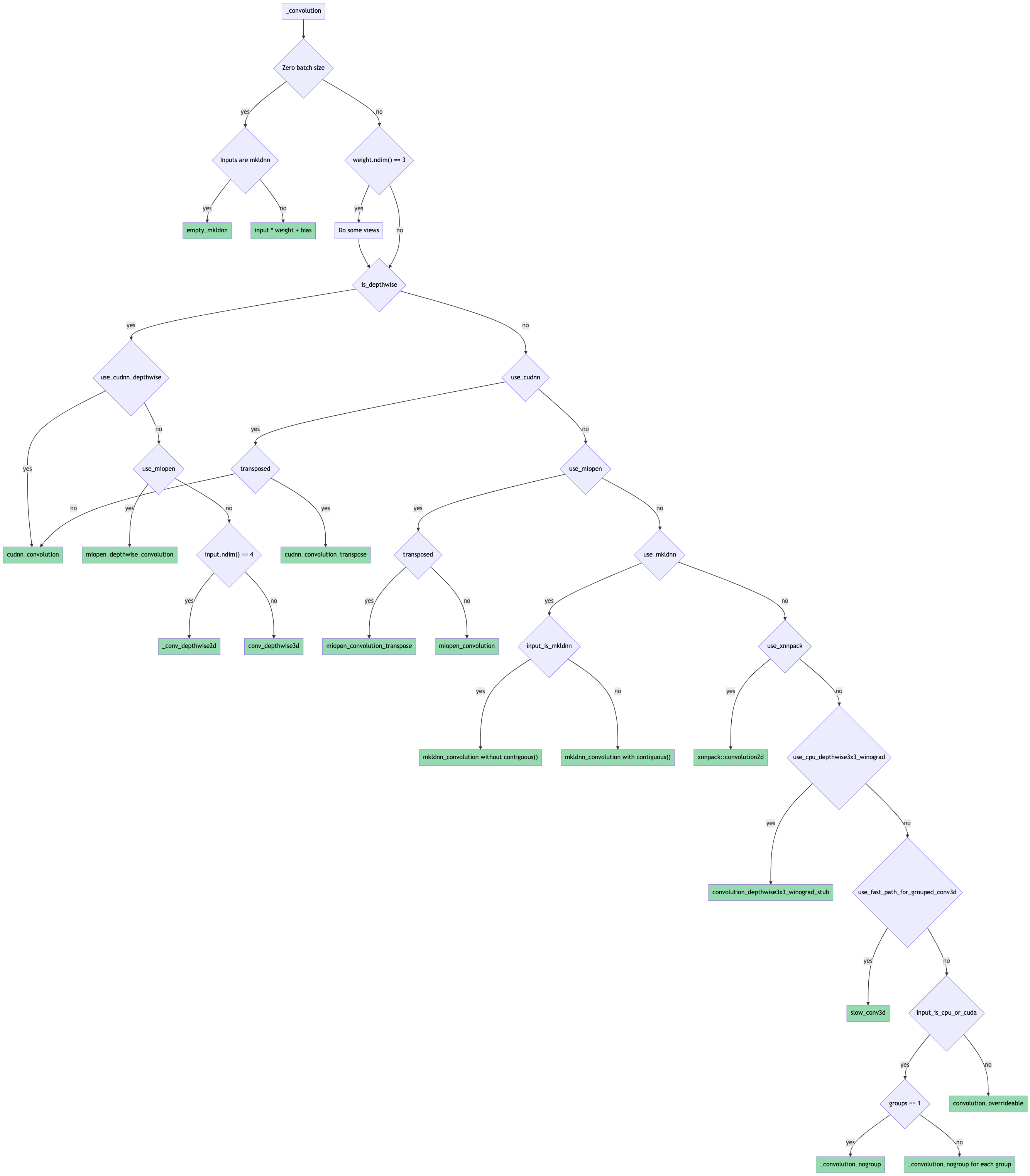
Initial version of general convolution_backward ( #65219 )
...
Summary:
Towards [convolution consolidation](https://fb.quip.com/tpDsAYtO15PO ).
Introduces the general `convolution_backward` function that uses the factored-out backend routing logic from the forward function.
Some notes:
* `finput` is now recomputed in the backward pass for the slow 2d / 3d kernels instead of being saved from the forward pass. The logic for is based on the forward computation and is present in `compute_finput2d` / `compute_finput3d` functions in `ConvUtils.h`.
* Using structured kernels for `convolution_backward` requires extra copying since the backend-specific backward functions return tensors. Porting to structured is left as future work.
* The tests that check the routing logic have been renamed from `test_conv_backend_selection` -> `test_conv_backend` and now also include gradcheck validation using an `autograd.Function` hooking up `convolution` to `convolution_backward`. This was done to ensure that gradcheck passes for the same set of inputs / backends.
The forward pass routing is done as shown in this flowchart (probably need to download it for it to be readable since it's ridiculous):
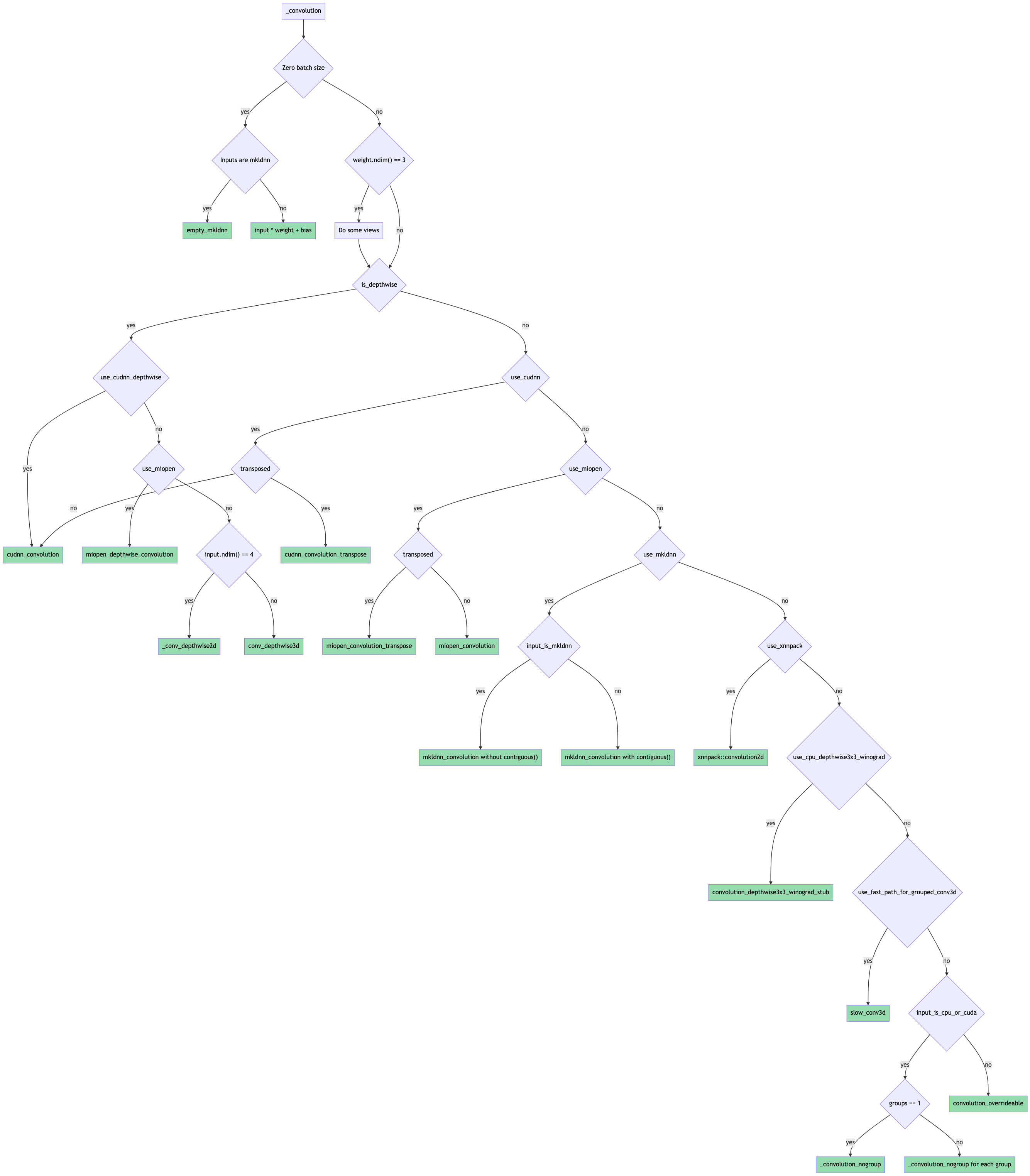
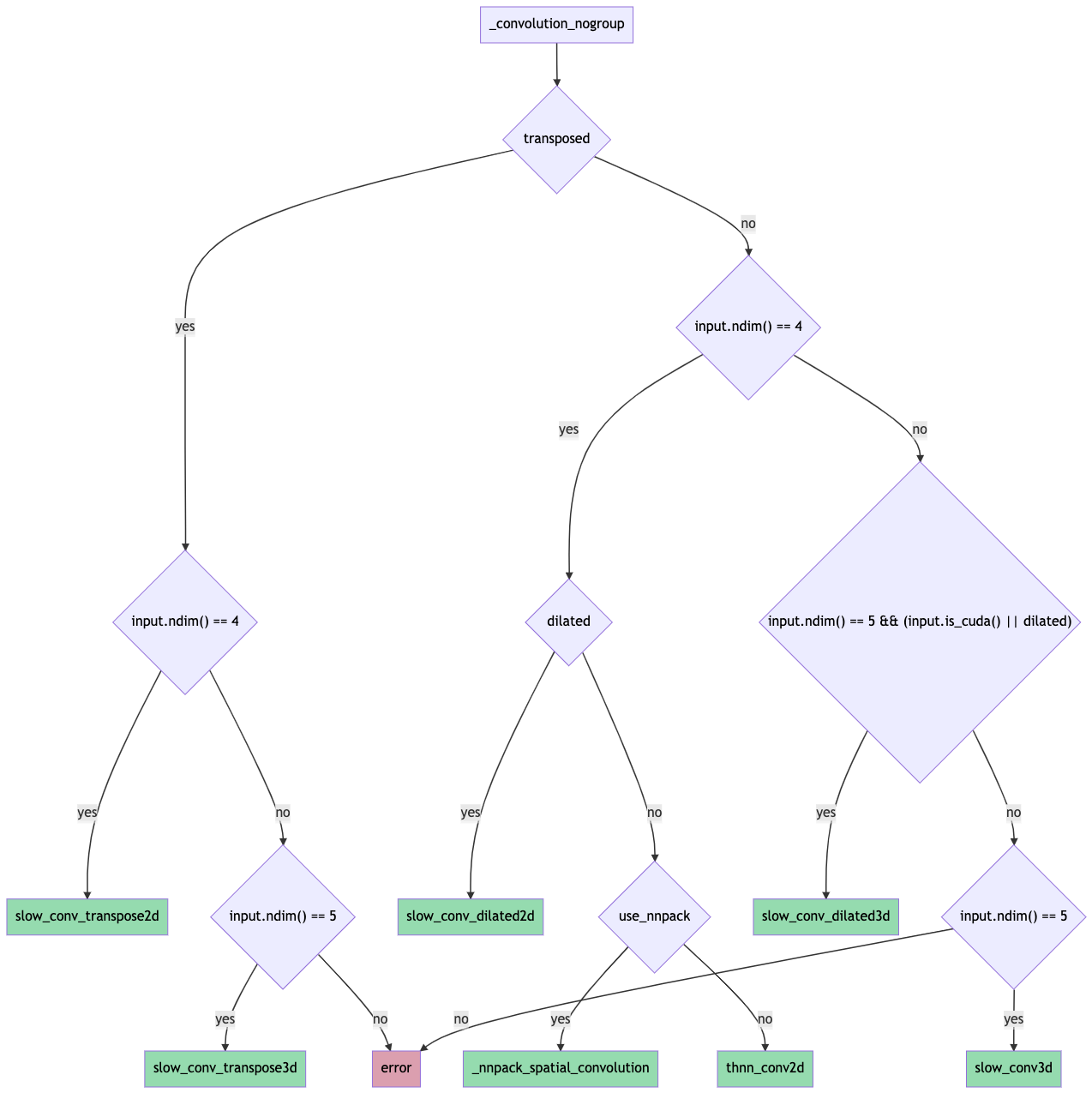
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65219
Reviewed By: mruberry
Differential Revision: D32611368
Pulled By: jbschlosser
fbshipit-source-id: 26d759b7c908ab8f19ecce627acea7bd3d5f59ba
2021-11-23 08:19:45 -08:00
soulitzer
7bb401a4c9
Add forward AD support for miscellanous operators ( #67820 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67820
Original PR here: https://github.com/pytorch/pytorch/pull/67040
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32314423
Pulled By: soulitzer
fbshipit-source-id: ecd898dc903692cab084f6922a1d86986f957b1b
2021-11-19 14:31:06 -08:00
jiej
ca92111758
Add native_dropout ( #63937 )
...
Summary:
Adds native_dropout to have a reasonable target for torchscript in auto diff. native_dropout has scale and train as arguments in its signature, this makes native_dropout more consistent with other operators and removes conditionals in the autodiff definition.
cc gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63937
Reviewed By: mruberry
Differential Revision: D32477657
Pulled By: ngimel
fbshipit-source-id: d37b137a37acafa50990f60c77f5cea2818454e4
2021-11-18 19:41:10 -08:00
kshitij12345
d5d2096dab
[testing] make @dtypes mandatory when using @dtypesIf ( #68186 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53647
With this if a test forgets to add `dtypes` while using `dtypesIf`, following error is raised
```
AssertionError: dtypes is mandatory when using dtypesIf however 'test_exponential_no_zero' didn't specify it
```
**Tested Locally**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68186
Reviewed By: VitalyFedyunin
Differential Revision: D32468581
Pulled By: mruberry
fbshipit-source-id: 805e0855f988b77a5d8d4cd52b31426c04c2200b
2021-11-18 08:29:31 -08:00
vfdev-5
3da2e09c9b
Added antialias flag to interpolate (CPU only, bilinear) ( #65142 )
...
Summary:
Description:
- Added antialias flag to interpolate (CPU only)
- forward and backward for bilinear mode
- added tests
### Benchmarks
<details>
<summary>
Forward pass, CPU. PTH interpolation vs PIL
</summary>
Cases:
- PTH RGB 3 Channels, float32 vs PIL RGB uint8 (apply vs pears)
- PTH 1 Channel, float32 vs PIL 1 Channel Float
Code: https://gist.github.com/vfdev-5/b173761a567f2283b3c649c3c0574112
```
# OMP_NUM_THREADS=1 python bench_interp_aa_vs_pillow.py
Torch config: PyTorch built with:
- GCC 9.3
- C++ Version: 201402
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_75,code=sm_75
- CuDNN 8.0.5
- Build settings: BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_PYTORCH_QNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.0, USE_CUDA=1, USE_CUDNN=1, USE_EIGEN_FOR_BLAS=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=OFF, USE_MKLDNN=OFF, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=0, USE_OPENMP=ON,
Num threads: 1
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (320, 196) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 2.9 | 3.1
channels_last non-contiguous torch.float32 | 2.6 | 3.6
Times are in milliseconds (ms).
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (460, 220) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 3.4 | 4.0
channels_last non-contiguous torch.float32 | 3.4 | 4.8
Times are in milliseconds (ms).
[------------------------ Downsampling: torch.Size([1, 3, 906, 438]) -> (120, 96) -------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 1.6 | 1.8
channels_last non-contiguous torch.float32 | 1.6 | 1.9
Times are in milliseconds (ms).
[----------------------- Downsampling: torch.Size([1, 3, 906, 438]) -> (1200, 196) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 9.0 | 11.3
channels_last non-contiguous torch.float32 | 8.9 | 12.5
Times are in milliseconds (ms).
[----------------------- Downsampling: torch.Size([1, 3, 906, 438]) -> (120, 1200) ------------------------]
| Reference, PIL 8.3.2, mode: RGB | 1.10.0a0+git1e87d91
1 threads: -------------------------------------------------------------------------------------------------
channels_first contiguous torch.float32 | 2.1 | 1.8
channels_last non-contiguous torch.float32 | 2.1 | 3.4
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (320, 196) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.2 | 1.0
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (460, 220) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 1.4 | 1.3
Times are in milliseconds (ms).
[--------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (120, 96) ---------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 719.9 | 599.9
Times are in microseconds (us).
[-------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (1200, 196) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 3.7 | 3.5
Times are in milliseconds (ms).
[-------------- Downsampling: torch.Size([1, 1, 906, 438]) -> (120, 1200) --------------]
| Reference, PIL 8.3.2, mode: F | 1.10.0a0+git1e87d91
1 threads: ------------------------------------------------------------------------------
contiguous torch.float32 | 834.4 | 605.7
Times are in microseconds (us).
```
</details>
Code is moved from torchvision: https://github.com/pytorch/vision/pull/4208
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65142
Reviewed By: mrshenli
Differential Revision: D32432405
Pulled By: jbschlosser
fbshipit-source-id: b66c548347f257c522c36105868532e8bc1d4c6d
2021-11-17 09:10:15 -08:00
vfdev-5
6adbe044e3
Added nearest-exact interpolation mode ( #64501 )
...
Summary:
Added "nearest-exact" interpolation mode to fix the issues: https://github.com/pytorch/pytorch/issues/34808 and https://github.com/pytorch/pytorch/issues/62237 .
Description:
As we can not fix "nearest" mode without large impact on already trained model [it was suggested](https://github.com/pytorch/pytorch/pull/64501#pullrequestreview-749771815 ) to introduce new mode instead of fixing exising "nearest" mode.
- New mode "nearest-exact" performs index computation for nearest interpolation to match scikit-image, pillow, TF2 and while "nearest" mode still match opencv INTER_NEAREST, which appears to be buggy, see https://ppwwyyxx.com/blog/2021/Where-are-Pixels/#Libraries .
"nearest":
```
input_index_f32 = output_index * scale
input_index = floor(input_index_f32)
```
"nearest-exact"
```
input_index_f32 = (output_index + 0.5) * scale - 0.5
input_index = round(input_index_f32)
```
Comparisions with other libs: https://gist.github.com/vfdev-5/a5bd5b1477b1c82a87a0f9e25c727664
PyTorch version | 1.9.0 "nearest" | this PR "nearest" | this PR "nearest-exact"
---|---|---|---
Resize option: | |
OpenCV INTER_NEAREST result mismatches | 0 | 0 | 10
OpenCV INTER_NEAREST_EXACT result mismatches | 9 | 9 | 9
Scikit-Image result mismatches | 10 | 10 | 0
Pillow result mismatches | 10 | 10 | 7
TensorFlow result mismatches | 10 | 10 | 0
Rescale option: | | |
size mismatches (https://github.com/pytorch/pytorch/issues/62396 ) | 10 | 10 | 10
OpenCV INTER_NEAREST result mismatches | 3 | 3| 5
OpenCV INTER_NEAREST_EXACT result mismatches | 3 | 3| 4
Scikit-Image result mismatches | 4 | 4 | 0
Scipy result mismatches | 4 | 4 | 0
TensorFlow: no such option | - | -
Versions:
```
skimage: 0.19.0.dev0
opencv: 4.5.4-dev
scipy: 1.7.2
Pillow: 8.4.0
TensorFlow: 2.7.0
```
Implementations in other libs:
- Pillow:
- ee079ae67e/src/libImaging/Geometry.c (L889-L899)ee079ae67e/src/libImaging/Geometry.c (L11)38fae50c3f/skimage/transform/_warps.py (L180-L188)47bb6febaa/scipy/ndimage/src/ni_interpolation.c (L775-L779)47bb6febaa/scipy/ndimage/src/ni_interpolation.c (L479)https://github.com/pytorch/pytorch/pull/64501
Reviewed By: anjali411
Differential Revision: D32361901
Pulled By: jbschlosser
fbshipit-source-id: df906f4d25a2b2180e1942ffbab2cc14600aeed2
2021-11-15 14:28:19 -08:00
yanbing-j
12026124cc
Avoid the view for mkldnn case in 1D convolution ( #68166 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68166
Reviewed By: mrshenli
Differential Revision: D32432444
Pulled By: jbschlosser
fbshipit-source-id: fc4e626d497d9e4597628a18eb89b94518bb3b33
2021-11-15 11:56:45 -08:00
eqy
a1ace029e2
Add host-side memory requirement for test_softmax_64bit_indexing ( #67922 )
...
Summary:
https://github.com/pytorch/pytorch/issues/67910
The original `largeTensorTest` decorator didn't account for the additional host-side memory requirements.
Thanks crcrpar for raising the issue, CC ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67922
Reviewed By: malfet
Differential Revision: D32308602
Pulled By: mruberry
fbshipit-source-id: 97b7d2c39fe63c1a8269402f72186026a89f6b4c
2021-11-11 09:24:15 -08:00
Dani El-Ayyass
f171c78c04
add unpack_sequence and unpad_sequence functions ( #66550 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/66549
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66550
Reviewed By: malfet
Differential Revision: D32299193
Pulled By: jbschlosser
fbshipit-source-id: 96c92d73d3d40b7424778b2365e0c8bb1ae56cfb
2021-11-10 15:15:08 -08:00
Joel Schlosser
9a2db6f091
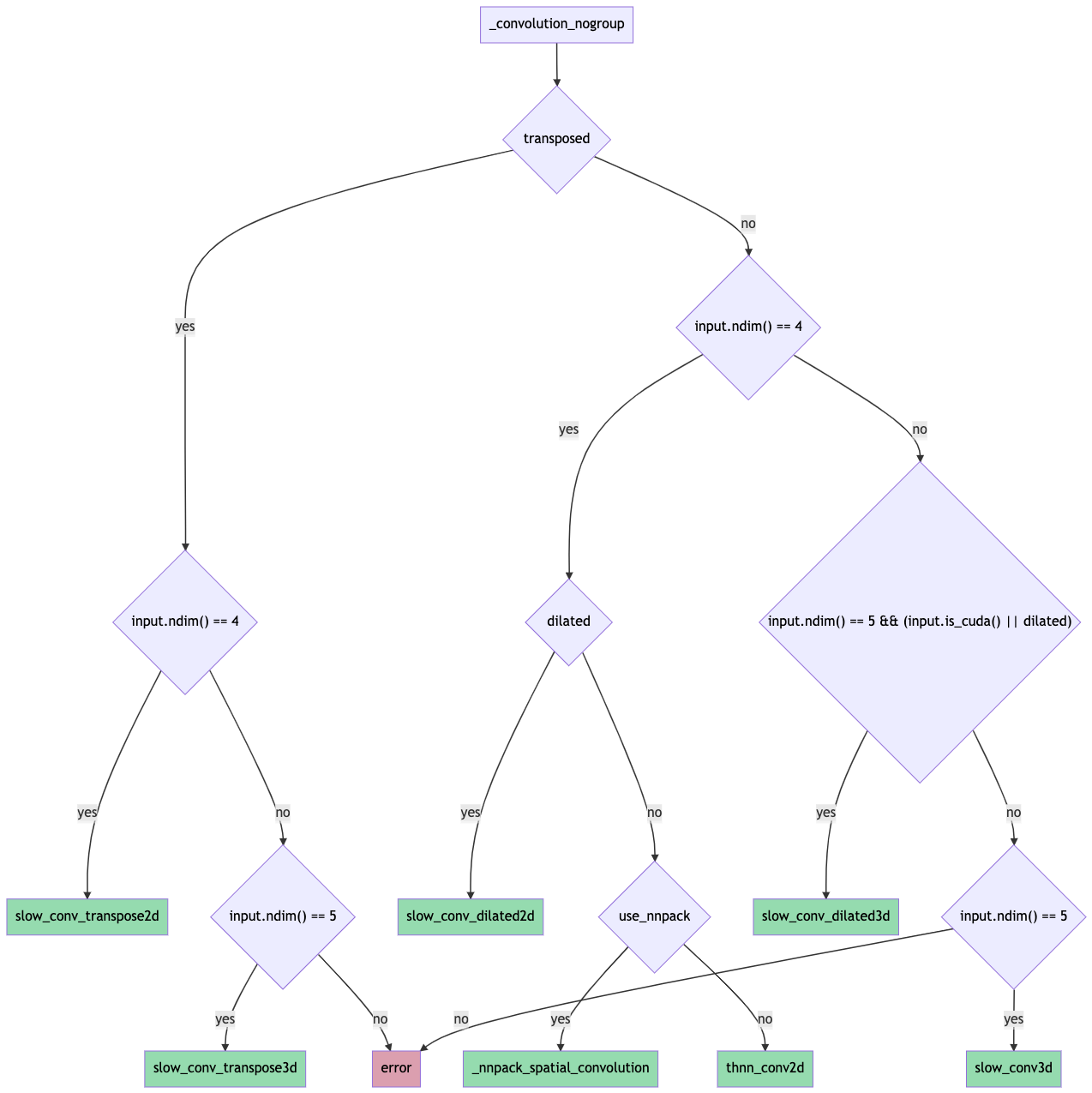
Factor backend routing logic out of convolution forward ( #67790 )
...
Summary:
This PR introduces a new function `_select_conv_backend` that returns a `ConvBackend` enum representing the selected backend for a given set of convolution inputs and params.
The function and enum are exposed to python for testing purposes through `torch/csrc/Module.cpp` (please let me know if there's a better place to do this).
A new set of tests validates that the correct backend is selected for several sets of inputs + params. Some backends aren't tested yet:
* nnpack (for mobile)
* xnnpack (for mobile)
* winograd 3x3 (for mobile)
Some flowcharts for reference:
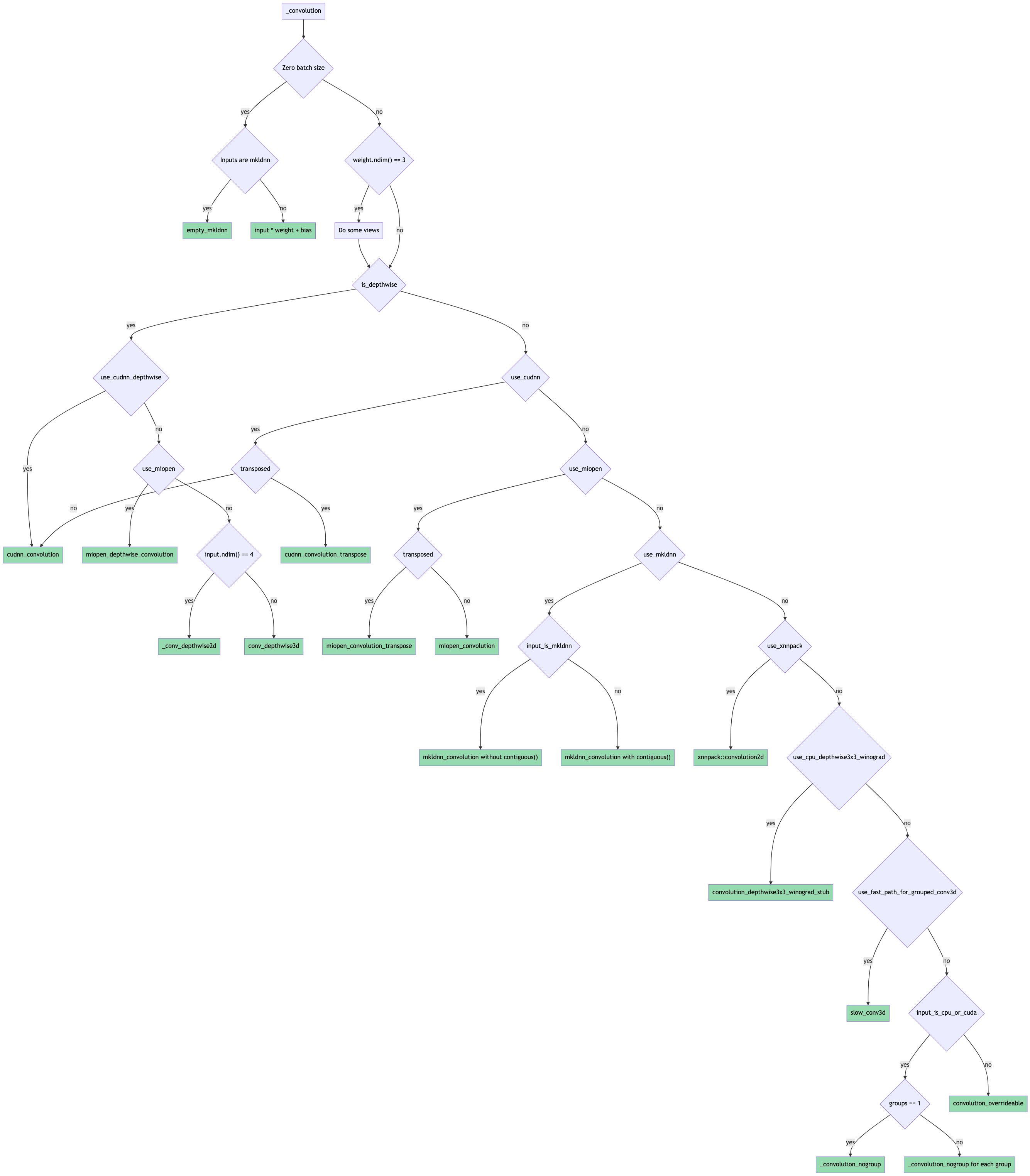
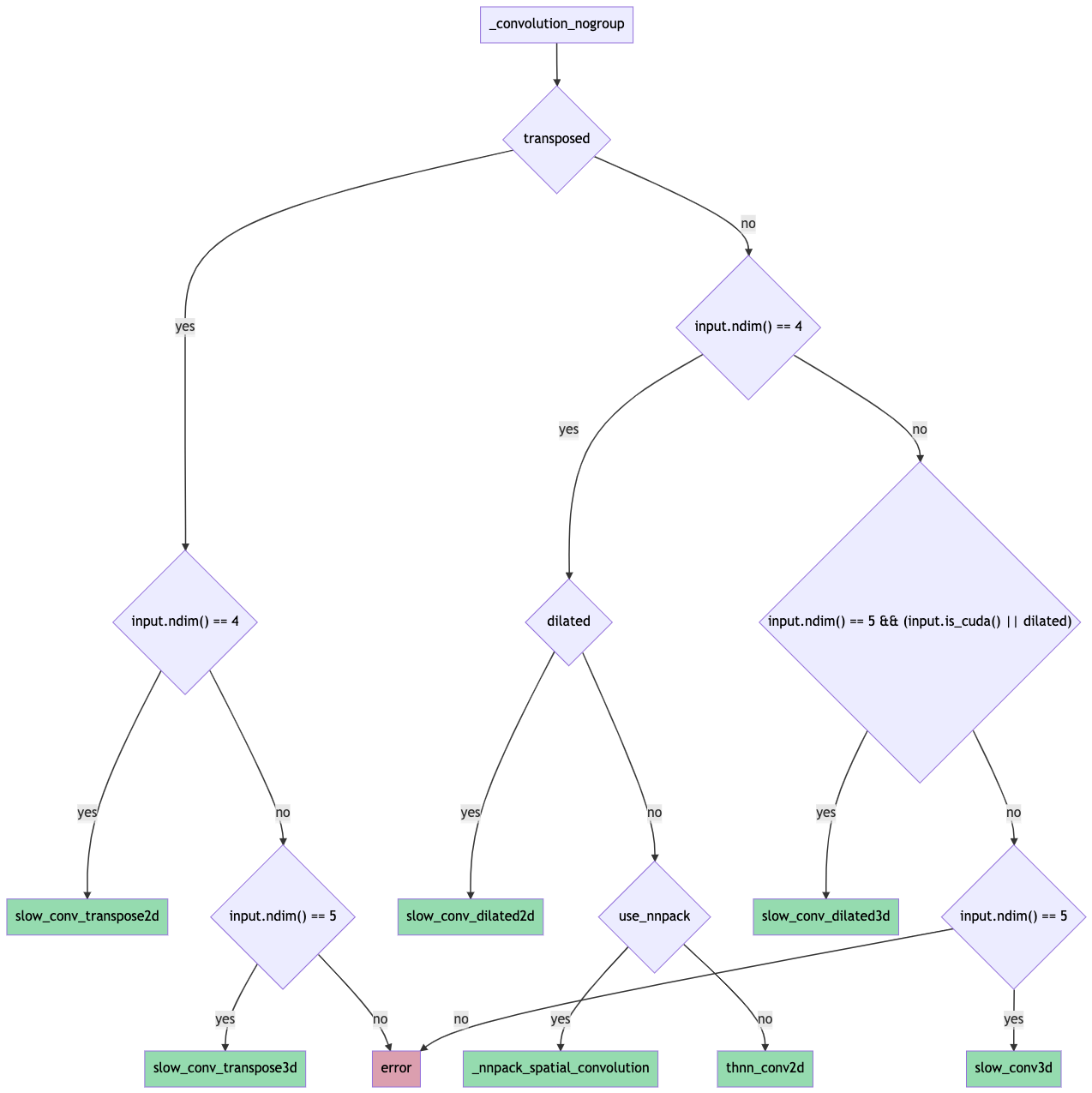
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67790
Reviewed By: zou3519
Differential Revision: D32280878
Pulled By: jbschlosser
fbshipit-source-id: 0ce55174f470f65c9b5345b9980cf12251f3abbb
2021-11-10 07:53:55 -08:00
Xiao Wang
f6a4c80a5a
Refactor cuDNN Convolution memory format and Conv-Bias-Relu code ( #65594 )
...
Summary:
This PR makes several changes:
- Changed function `bool cudnn_conv_use_channels_last(...)` to `at::MemoryFormat cudnn_conv_suggest_memory_format(...)`
- Removed `resize_` in cudnn convolution code. Added a new overloading method `TensorDescriptor::set` that also passes the desired memory format of the tensor.
- Disabled the usage of double + channels_last on cuDNN Conv-Relu and Conv-Bias-Relu. Call `.contiguous(memory_format)` before passing data to cuDNN functions.
- Disabled the usage of cuDNN fused Conv-Bias-Relu in cuDNN < 8.0 version due to a CUDNN_STATUS_NOT_SUPPORTED error. Instead, use the native fallback path.
- Let Conv-Bias-Relu code respect the global `allow_tf32` flag.
From cuDNN document, double + NHWC is genenrally not supported.
Close https://github.com/pytorch/pytorch/pull/66968
Fix https://github.com/pytorch/pytorch/issues/55301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65594
Reviewed By: jbschlosser, malfet
Differential Revision: D32175766
Pulled By: ngimel
fbshipit-source-id: 7ba079c9f7c46fc56f8bfef05bad0854acf380d7
2021-11-05 11:50:55 -07:00
Alban Desmaison
bb8978f605
Revert D32175963: Converting hardswish to strucutred kernels with metatensor support
...
Test Plan: revert-hammer
Differential Revision:
D32175963 (57335a9ee3
2021-11-05 07:04:40 -07:00
John Clow
57335a9ee3
Converting hardswish to strucutred kernels with metatensor support ( #66899 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/66899
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32175963
Pulled By: Gamrix
fbshipit-source-id: f4d749c6aeaf064084be72361607ea4f3f6bc91d
2021-11-04 19:02:00 -07:00
soulitzer
83e8612d11
Clean up test autograd ( #67413 )
...
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/66066
This PR:
- cleans up op-specific testing from test_autograd. test_autograd should be reserved for testing generic autograd functionality
- tests related to an operator are better colocated
- see the tracker for details
What to think about when moving tests to their correct test suite:
- naming, make sure its not too generic
- how the test is parametrized, sometimes we need to add/remove a device/dtype parameter
- can this be merged with existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67413
Reviewed By: jbschlosser, albanD
Differential Revision: D32031480
Pulled By: soulitzer
fbshipit-source-id: 8e13da1e58a38d5cecbfdfd4fe2b4fe6f816897f
2021-11-03 15:26:09 -07:00
Xiao Wang
31cf3d6aad
Fix adaptive_max_pool2d for channels-last on CUDA ( #67697 )
...
Summary:
Fix https://github.com/pytorch/pytorch/issues/67239
The CUDA kernels for `adaptive_max_pool2d` (forward and backward) were written for contiguous output. If outputs are non-contiguous, first create a contiguous copy and let the kernel write output to the contiguous memory space. Then copy the output from contiguous memory space to the original non-contiguous memory space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67697
Reviewed By: ejguan
Differential Revision: D32112443
Pulled By: ngimel
fbshipit-source-id: 0e3bf06d042200c651a79d13b75484526fde11fe
2021-11-03 09:47:29 -07:00
John Shen
234bd6dc56
[quantized] Add bilinear quantized grid_sample ( #66879 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66879
This adds a quantized implementation for bilinear gridsample. Bicubic interpolation cannot be supported as easily since we rely on the linearity of quantization to operate on the raw values, i.e.
f(q(a), q(b)) = q(f(a, b)) where f is the linear interpolation function.
ghstack-source-id: 141321116
Test Plan: test_quantization
Reviewed By: kimishpatel
Differential Revision: D31656893
fbshipit-source-id: d0bc31da8ce93daf031a142decebf4a155943f0f
2021-11-01 14:44:26 -07:00
kshitij12345
885a8e53ba
replace onlyOnCPUAndCUDA with onlyNativeDeviceTypes ( #65201 )
...
Summary:
Reference https://github.com/pytorch/pytorch/issues/53849
Replace `onlyOnCPUandCUDA` with `onlyNativeDeviceTypes` which includes `cpu, cuda and meta`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65201
Reviewed By: mrshenli
Differential Revision: D31299718
Pulled By: mruberry
fbshipit-source-id: 2d8356450c035d6a314209ab51b2c237583920fd
2021-11-01 09:22:34 -07:00
Joel Schlosser
16d937b0df
Fix strided _conv_double_backward() with 3D input / weight ( #67283 )
...
Summary:
Removes the 3D special case logic in `_convolution_double_backward()` that never worked.
The logic was never called previously since `convolution()` expands input / weight from 3D -> 4D before passing them to backends; backend-specific backward calls thus save the 4D version to pass to `_convolution_double_backward()`.
The new general `convolution_backward()` saves the original 3D input / weight, uncovering the bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67283
Reviewed By: anjali411
Differential Revision: D32021100
Pulled By: jbschlosser
fbshipit-source-id: 0916bcaa77ef49545848b344d6385b33bacf473d
2021-10-29 09:48:53 -07:00
Sameer Deshmukh
edd4d246c3
Accept 0-dim channel inputs in convolution layer ( #66256 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56998 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66256
Reviewed By: mrshenli
Differential Revision: D31859428
Pulled By: jbschlosser
fbshipit-source-id: 034b6c1ce35aac50eabfa09bbcd8b1e3c8b171bd
2021-10-25 08:12:29 -07:00
Eddie Yan
d9c4b3feab
Do rowwisemoments computation in float for half LayerNorm ( #66920 )
...
Summary:
https://github.com/pytorch/pytorch/issues/66707
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66920
Reviewed By: mrshenli
Differential Revision: D31850612
Pulled By: ngimel
fbshipit-source-id: a95a33567285dcf9ee28d33f503cead3268960f9
2021-10-22 09:50:42 -07:00
{kind=link}
{kind=link}
{kind=link}
{kind=link}