Summary:
Building on top of the work of anjali411 (https://github.com/pytorch/pytorch/issues/46640)
Things added in this PR:
1. Modify backward and double-backward formulas
2. Add complex support for `new module tests` and criterion tests (and add complex tests for L1)
3. Modify some existing tests to support complex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49912
Reviewed By: zhangguanheng66
Differential Revision: D25853036
Pulled By: soulitzer
fbshipit-source-id: df619f1b71c450ab2818eb17804e0c55990aa8ad
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42855. Previously, back quotes weren't rendering correctly in
equations. This is because we were quoting things like `'mean'`. In
order to backquote properly in latex in text-mode, the back-quote needs
to be written as a back-tick.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45662
Test Plan:
- built docs locally and viewed the changes.
For NLLLoss (which is not the original module mentioned in the issue, but it has the same problem), we can see how the back quotes now render properly:

Reviewed By: glaringlee
Differential Revision: D24049880
Pulled By: zou3519
fbshipit-source-id: 61a1257994144549eb8f29f19d639aea962dfec0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45377
This PR adds a C++ implementation of the TripletMarginWithDistanceLoss, for which the Python implementation was introduced in PR #43680. It's based on PR #44072, but I'm resubmitting this to unlink it from Phabricator.
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D24003973
fbshipit-source-id: 2d9ada7260a6f27425ff2fdbbf623dad0fb79405
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45532
- updated documentation
- explicitly not supporting negative values for beta (previously the
result was incorrect)
- Removing default value for beta in the backwards function, since it's
only used internally by autograd (as per convention)
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D24002415
Pulled By: bdhirsh
fbshipit-source-id: 980c141019ec2d437b771ee11fc1cec4b1fcfb48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42884
I did some additional research and considering the first few lines of the docs (`Creates a criterion that measures the loss given inputs x1, x2, two 1D mini-batch Tensors, and a label 1D mini-batch tensor y (containing 1 or -1`) and the provided tests, this loss should be used primarily with 1-D tensors. More advanced users (that may use this loss in non-standard ways) can easily check the source and see that the definition accepts inputs/targets of arbitrary dimension as long as they match in shape or are broadcastable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43131
Reviewed By: colesbury
Differential Revision: D23192011
Pulled By: mrshenli
fbshipit-source-id: c412c28daf9845c0142ea33b35d4287e5b65fbb9
Summary:
Current losses in PyTorch only include a (partial) implementation of Huber loss through `smooth l1` based on Fast RCNN - which essentially uses a delta value of 1. Changing/Renaming the [`_smooth_l1_loss()`](3e1859959a/torch/nn/functional.py (L2487)) and refactoring to include delta, enables to use the actual function.
Supplementary to this, I have also made a functional and criterion versions for anyone that wants to set the delta explicitly - based on the functional `smooth_l1_loss()` and the criterion `Smooth_L1_Loss()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37599
Differential Revision: D21559311
Pulled By: vincentqb
fbshipit-source-id: 34b2a5a237462e119920d6f55ba5ab9b8e086a8c
Summary:
xref gh-38010 and gh-38011.
After this PR, there should be only two warnings:
```
pytorch/docs/source/index.rst:65: WARNING: toctree contains reference to nonexisting \
document 'torchvision/index'
WARNING: autodoc: failed to import class 'tensorboard.writer.SummaryWriter' from module \
'torch.utils'; the following exception was raised:
No module named 'tensorboard'
```
If tensorboard and torchvision are prerequisites to building docs, they should be added to the `requirements.txt`.
As for breaking up quantization into smaller pieces: I split out the list of supported operations and the list of modules to separate documents. I think this makes the page flow better, makes it much "lighter" in terms of page cost, and also removes some warnings since the same class names appear in multiple sub-modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41321
Reviewed By: ngimel
Differential Revision: D22753099
Pulled By: mruberry
fbshipit-source-id: d504787fcf1104a0b6e3d1c12747ec53450841da
Summary:
Based on discussion with jlucier (https://github.com/pytorch/pytorch/pull/38925#issuecomment-655859195) . `batch_size` change isn't made because data loader only has the notion of `batch_sampler`, not batch size. If `batch_size` dependent sharding is needed, users can still access it from their own code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41175
Differential Revision: D22456525
Pulled By: zou3519
fbshipit-source-id: 5281fcf14807f219de06e32107d5fe7d5b6a8623
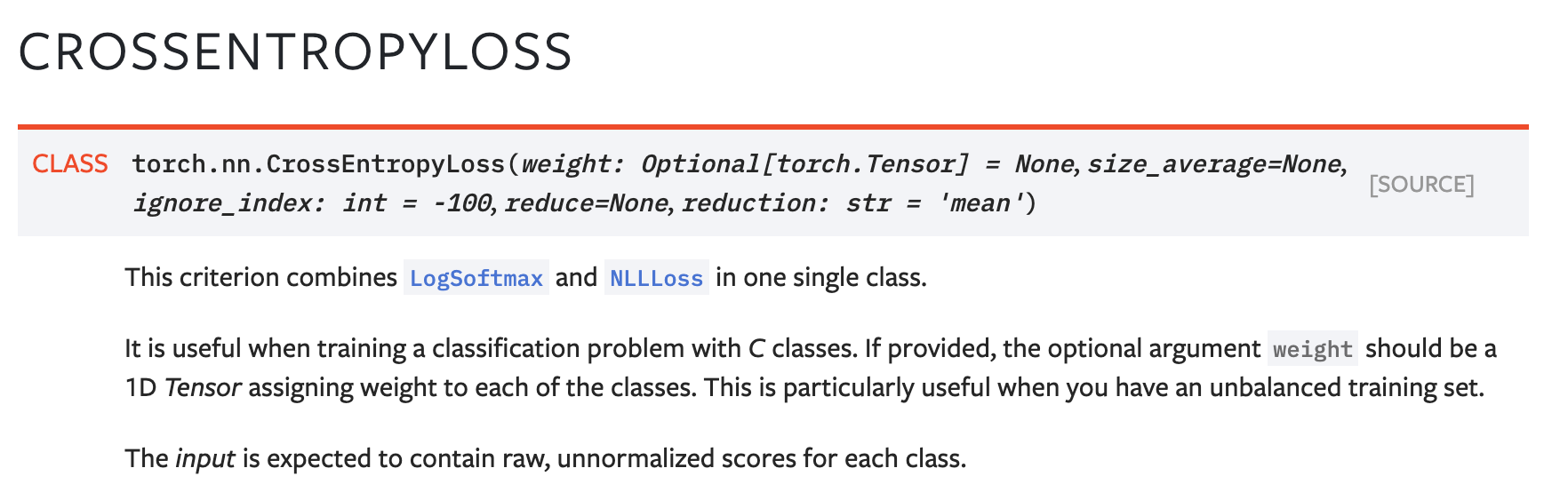
Summary:
Closes https://github.com/pytorch/pytorch/issues/40560
This adds the equation for the weighted mean to `CrossEntropyLoss`'s docs and the `reduction` argument for `CrossEntropyLoss` and `NLLLoss` no longer describes a non-weighted mean of the outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40991
Differential Revision: D22395805
Pulled By: ezyang
fbshipit-source-id: a623b6dd2aab17220fe0bf706bd9b62d6ba531fd
Summary:
Apologize if this seems trivial, but i'd like to fix them on my way of reading some of the source code. Thanks!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40692
Differential Revision: D22284651
Pulled By: mrshenli
fbshipit-source-id: 4259d1808aa4d15a02cfd486cfb44dd75fdc58f8
Summary:
This is just a minor doc fix:
the `MarginRankingLoss` takes 2 input samples `x1` and `x2`, not just `x`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40285
Reviewed By: ezyang
Differential Revision: D22195069
Pulled By: zou3519
fbshipit-source-id: 909f491c94dca329a37216524f4088e9096e0bc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38211
Just because the annotations are inline doesn't mean the files type
check; most of the newly annotated files have type errors and I
added exclusions for them in mypy.ini. The payoff of moving
all of these modules inline is I can delete the relevant code
generation logic for the pyi files (which was added ignore
annotations that weren't actually relevant anymore.)
For the most part the translation was completely mechanical, but there
were two hairy issues. First, I needed to work around a Python 3.6 and
earlier bug where Generic has a nontrivial metaclass. This fix is in
torch/jit/__init__.py. Second, module.py, we need to apply the same
fix for avoiding contravariance checks that the pyi file used to have;
this is done by declaring forward as a variable (rather than a
function), which appears to be sufficient enough to get mypy to not
contravariantly check input arguments.
Because we aren't actually typechecking these modules in most
cases, it is inevitable that some of these type annotations are wrong.
I slavishly copied the old annotations from the pyi files unless there
was an obvious correction I could make. These annotations will probably
need fixing up later.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21497397
Pulled By: ezyang
fbshipit-source-id: 2b08bacc152c48f074e7edc4ee5dce1b77d83702
Summary:
xref gh-32838, gh-34032
This is a major refactor of parts of the documentation to split it up using sphinx's `autosummary` feature which will build out `autofuction` and `autoclass` stub files and link to them. The end result is that the top module pages like torch.nn.rst and torch.rst are now more like table-of-contents to the actual single-class or single-function documentations pages.
Along the way, I modified many of the docstrings to eliminate sphinx warnings when building. I think the only thing I changed from a non-documentation perspective is to add names to `__all__` when adding them to `globals()` in `torch.__init__.py`
I do not know the CI system: are the documentation build artifacts available after the build, so reviewers can preview before merging?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37419
Differential Revision: D21337640
Pulled By: ezyang
fbshipit-source-id: d4ad198780c3ae7a96a9f22651e00ff2d31a0c0f
Summary:
In the examples of `BCEWithLogitsLoss`, `0.999` is passed as the prediction value. The value `0.999` seems to be a probability, but actually it's not. I think it's better to pass a value that is greater than 1, not to confuse readers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34053
Differential Revision: D20195456
Pulled By: ezyang
fbshipit-source-id: 3abbda6232ee1ab141d202d0ce1177526ad59c53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32745
Some parameters (like `bias` in conv) are optional. To achieve this
previously, you had to add `bias` as a constant, which would invoke some
pretty weird behavior in the frontend, summarized as:
```
if bias is not None:
add it as a parameter normally
else: # bias is None
add it as a constant with the value None
```
There are several things bad about this:
1. Bias is not a constant. Marking it `__constants__` is confusing.
2. It basically relies on an implementation detail (the frontend
processes parameters before constants) to work.
Okay, whatever. I don't even know why we did this originally, but
getting rid of it doesn't break anything, so I assume improved NoneType
refinement has made this a non-issue.
Note on perf: this will make no difference; if bias was `None` it's still
folded out today, if bias is a Tensor it would be added as a parameter
both before and after this change
Test Plan: Imported from OSS
Differential Revision: D19628634
Pulled By: suo
fbshipit-source-id: d9128a09c5d096b938fcf567b8c23b09ac9ab37f
Summary:
Reference: https://github.com/pytorch/pytorch/issues/31385
In the current documentation for NLLLoss, it's unclear what `y` refers to in the math section of the loss description. There was an issue(https://github.com/pytorch/pytorch/issues/31295) filed earlier where there was a confusion if the loss returned for reduction=mean is right or not, perhaps because of lack in clarity of formula symbol description in the current documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31488
Differential Revision: D19181391
Pulled By: anjali411
fbshipit-source-id: 8b75f97aef93c92c26ecbce55b3faf2cd01d3e74
Summary:
* Deletes all weak script decorators / associated data structures / methods
* In order to keep supporting the standard library in script, this enables recursive script on any function defined in `torch.nn`
* Most changes in `torch/nn` are the result of `ag -Q "weak" torch/nn/ -l | xargs sed -i '/weak/d'`, only `rnn.py` needed manual editing to use the `ignore` and `export` to continue supporting the overloaded `forward` methods
* `Sequential`/`ModuleList` no longer need to be added to constants since they are compiled on demand
This should also fix https://github.com/pytorch/pytorch/issues/22212
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22212
Differential Revision: D15988346
Pulled By: driazati
fbshipit-source-id: af223e3ad0580be895377312949997a70e988e4f
Summary:
Previously, we didn't work when 2d target tensors had extra columns at the end. Now we just ignore those.
Also fix the confusion in the doc example regarding the number of classes.
Thank you, ypw-rich for the report with reproducing example.
Fixes: #20522
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20971
Differential Revision: D15535481
Pulled By: ezyang
fbshipit-source-id: 397e44e20165fc4fa2547bee9390d4c0b688df93
Summary:
Change `Inputs` to `Shape` to unify the format of CTCLoss `class`, and add the type of `Output` in `Shape`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20422
Differential Revision: D15393484
Pulled By: ezyang
fbshipit-source-id: 5b49647f9740de77db49a566fa2de74fcecd9110
Summary:
I fixed a mistake in the explanation of `pos_weight` argument in `BCEWithLogitsLoss` and added an example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19212
Differential Revision: D14923431
Pulled By: ezyang
fbshipit-source-id: 15696c67d56789102ac72afbe9bdd7b667eae5a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
This is meant to resolve#18249, where I pointed out a few things that could improve the CTCLoss docs.
My main goal was to clarify:
- Target sequences are sequences of class indices, excluding the blank index
- Lengths of `target` and `input` are needed for masking unequal length sequences, and do not necessarily = S, which is the length of the longest sequence in the batch.
I thought about Thomas's suggestion to link the distill.pub article, but I'm not sure about it. I think that should be up to y'all to decide.
I have no experience with .rst, so it might not render as expected :)
t-vi ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18415
Differential Revision: D14691969
Pulled By: soumith
fbshipit-source-id: 381a2d52307174661c58053ae9dfae6e40cbfd46
Summary:
Fix#17801 to add an exception regarding `ignore_index` in the documentation for `torch.nn.CrossEntropyLoss` and `torch.nn.NLLLoss`
If any other files/functions are hit, I'd be glad to incorporate the changes there too! 😊
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18117
Differential Revision: D14542079
Pulled By: ezyang
fbshipit-source-id: 7b918ac61f441dde7d3d6782d080c500cf2097f1
Summary:
Fix#16428 by correcting type of 'swap' from `float` to `bool`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18115
Differential Revision: D14516615
Pulled By: ezyang
fbshipit-source-id: c61a45d533f3a443edf3c31c1ef3d9742bf46d2b
Summary:
Fixes some minor grammatical mistakes in the doc of `loss.py`.
I think in the doc:
> Note that for some losses, there multiple elements per sample.
the "are" is lost between "there" and "multiple".
This mistake takes place in all the descriptions of parameter `size_average` and there are 17 of them.
It's minor but perfects the doc I think. 😁
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17892
Differential Revision: D14418177
Pulled By: ezyang
fbshipit-source-id: 412759f2f9b215819463bf8452ab0e0513218cd6
Summary:
In the loss doc description, replace the deprecated 'reduct' and 'size_average' parameters with the 'reduction' parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17300
Differential Revision: D14195789
Pulled By: soumith
fbshipit-source-id: 625e650ec20f13b2d22153a4a535656cf9c8f0eb
{kind=link}
{kind=link}