albanD
9920ae665b
Make te a hidden package for now ( #51690 )
...
Summary:
As discussed with suo , having it in `torch._C.XX` means that it automatically gets added to `torch.XX` which is unfortunate. Making it `torch._C._XX` means that it won't be added to `torch.`.
Let me know if that approach to hide it is not good and we can update that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51690
Reviewed By: gchanan
Differential Revision: D26243207
Pulled By: albanD
fbshipit-source-id: 3eb91a96635e90a6b98df799e3a732833dd280d5
2021-02-04 07:58:38 -08:00
Bert Maher
a23e82df10
[nnc] Tweak log_nnc_sleef so vectorization kicks in ( #51491 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51491
The vectorizer heuristic is pretty dumb and only kicks in if the
unroll factor is exactly 8 or 4.
It's still slower than direct implementation, which isn't surprising.
ghstack-source-id: 120783426
Test Plan:
`buck run mode/opt //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench`
Before:
```
---------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
---------------------------------------------------------------------------
log_nnc_sleef/64 438 ns 438 ns 1795511 log/s=146.259M/s
log_nnc_sleef/512 3196 ns 3195 ns 210032 log/s=160.235M/s
log_nnc_sleef/8192 77467 ns 77466 ns 8859 log/s=105.749M/s
log_nnc_sleef/32768 310206 ns 310202 ns 2170 log/s=105.634M/s
log_nnc_fast/64 100 ns 100 ns 7281074 log/s=637.144M/s
log_nnc_fast/512 546 ns 546 ns 1335816 log/s=938.361M/s
log_nnc_fast/8192 7360 ns 7359 ns 91971 log/s=1.11316G/s
log_nnc_fast/32768 30793 ns 30792 ns 22633 log/s=1064.17M/s
log_aten/64 427 ns 427 ns 1634897 log/s=150.021M/s
log_aten/512 796 ns 796 ns 877318 log/s=643.566M/s
log_aten/8192 6690 ns 6690 ns 102649 log/s=1.22452G/s
log_aten/32768 25357 ns 25350 ns 27808 log/s=1.29263G/s
```
After:
```
---------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
---------------------------------------------------------------------------
log_nnc_sleef/64 189 ns 188 ns 3872475 log/s=340.585M/s
log_nnc_sleef/512 1307 ns 1307 ns 557770 log/s=391.709M/s
log_nnc_sleef/8192 20259 ns 20257 ns 34240 log/s=404.404M/s
log_nnc_sleef/32768 81556 ns 81470 ns 8767 log/s=402.209M/s
log_nnc_fast/64 110 ns 110 ns 6564558 log/s=581.116M/s
log_nnc_fast/512 554 ns 554 ns 1279304 log/s=923.376M/s
log_nnc_fast/8192 7774 ns 7774 ns 91421 log/s=1053.75M/s
log_nnc_fast/32768 31008 ns 31006 ns 21279 log/s=1056.83M/s
```
Reviewed By: bwasti
Differential Revision: D26139067
fbshipit-source-id: db31897ee9922695ff9dff4ff46e3d3fbd61f4c2
2021-02-01 16:35:37 -08:00
Marat Subkhankulov
721ba97eb6
Create op benchmark for stack ( #51263 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51263
- Add benchmark for stack op
Test Plan:
```
buck build mode/opt //caffe2/benchmarks/operator_benchmark/pt:stack_test --show-output
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/stack_test.par --tag_filter=static_runtime | grep Execution
Forward Execution Time (us) : 6.380
Forward Execution Time (us) : 6.553
Forward Execution Time (us) : 14.904
Forward Execution Time (us) : 5.657
Forward Execution Time (us) : 5.612
Forward Execution Time (us) : 6.051
Forward Execution Time (us) : 4.225
Forward Execution Time (us) : 4.240
Forward Execution Time (us) : 6.280
Forward Execution Time (us) : 6.267
Forward Execution Time (us) : 418.932
Forward Execution Time (us) : 417.694
Forward Execution Time (us) : 1592.455
Forward Execution Time (us) : 2919.261
Forward Execution Time (us) : 211.458
Forward Execution Time (us) : 211.518
Forward Execution Time (us) : 783.953
Forward Execution Time (us) : 1457.823
Forward Execution Time (us) : 2032.816
Forward Execution Time (us) : 2090.662
Forward Execution Time (us) : 6487.098
Forward Execution Time (us) : 11874.702
Forward Execution Time (us) : 2123.830
Forward Execution Time (us) : 2195.453
Forward Execution Time (us) : 6435.978
Forward Execution Time (us) : 11852.205
Forward Execution Time (us) : 2036.526
Forward Execution Time (us) : 2055.618
Forward Execution Time (us) : 6417.192
Forward Execution Time (us) : 12468.744
Forward Execution Time (us) : 4959.704
Forward Execution Time (us) : 5121.823
Forward Execution Time (us) : 5082.105
Forward Execution Time (us) : 5395.936
Forward Execution Time (us) : 5162.756
Forward Execution Time (us) : 23798.080
Forward Execution Time (us) : 4957.921
Forward Execution Time (us) : 4971.234
Forward Execution Time (us) : 5005.909
Forward Execution Time (us) : 5159.614
Forward Execution Time (us) : 5013.221
Forward Execution Time (us) : 20238.741
Forward Execution Time (us) : 7632.439
Forward Execution Time (us) : 7589.376
Forward Execution Time (us) : 7859.937
Forward Execution Time (us) : 8214.213
Forward Execution Time (us) : 11606.562
Forward Execution Time (us) : 34612.919
```
Reviewed By: hlu1
Differential Revision: D25859143
fbshipit-source-id: a1b735ce87f57b5eb67e223e549248a2cd7663c1
2021-01-30 10:32:14 -08:00
Hao Lu
11cda929fb
[StaticRuntime] Fix bug in MemoryPlanner ( #51342 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51342
There is a subtle bug with the MemoryPlanner with regard to view ops with out variant.
```
def forward(self, a: Tensor, shape: List[int]):
b = a.reshape(shape)
return b + b
```
In this case, if we replace reshape with the out variant, b would be managed by the MemoryPlanner and the storage of its output would have been set to nullptr right after inference by the MemoryPlanner if opts.cleanup_activations is true. Because b is a view of a, the storage of a is also set to nullptr, and this violates the API which promises that a is const.
To fix this bug, I changed the MemoryPlanner so that it puts b in the unmanaged part.
Test Plan:
Add unit test to enforce the constness of inputs
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
```
Reviewed By: ajyu
Differential Revision: D26144203
fbshipit-source-id: 2dbacccf7685d0fe0f0b1195166e0510b2069fe3
2021-01-29 21:16:02 -08:00
Rohan Varma
5021582fe6
Fix benchmarks/distributed/ddp/benchmark.py ( #51095 )
...
Summary:
Fixes the issue reported in https://github.com/pytorch/pytorch/issues/50679 by using built-in object-based collectives. User has verified this patch works
Test with:
RANK=0 python3 pytorch-dist-benchmark.py --world-size 2 --master-addr 127.0.0.1 --master-port 23456
RANK=1 python3 pytorch-dist-benchmark.py --world-size 2 --master-addr 127.0.0.1 --master-port 23456
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51095
Reviewed By: SciPioneer
Differential Revision: D26070275
Pulled By: rohan-varma
fbshipit-source-id: 59abcaac9e395bcdd8a018bf6ba07521d94b2fdf
2021-01-29 11:10:13 -08:00
Pritam Damania
96cedefd8e
[Pipe] Refactor convert_to_balance under non-test package. ( #50860 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50860
Since fairscale.nn.Pipe still uses 'balance' and 'devices' parameters,
other frameworks like fairseq still use these parameters. As a result, the
`convert_to_balance` method is a nice utility to use for migrating to PyTorch
Pipe without changing a lot of code in other frameworks.
In addition to this I've renamed the method to be more illustrative of what it
does and also allowed an optional devices parameter.
ghstack-source-id: 120430775
Test Plan:
1) waitforbuildbot
2) Tested with fairseq
Reviewed By: SciPioneer
Differential Revision: D25987273
fbshipit-source-id: dccd42cf1a74b08c876090d3a10a94911cc46dd8
2021-01-28 12:10:21 -08:00
Hao Lu
d035d56bfb
[StaticRuntime] Add out variant for reshape and flatten ( #51249 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51249
- Add out variant for reshape and flatten. reshape and flatten only create tensor views when it can. In cases where it can't, it does a copy. The out variant reuses the TensorImpl for both cases. The difference is that the TensorImpl is a view in the first case, but a normal TensorImpl in the second case.
- Create a separate registry for the view ops with out variants. Because Tensor views can't participate in memory reuse (memonger), we need to track these ops separately.
- The MemoryPlanner does not track the StorageImpl of tensor views because they don't own the storage, however, in cases where reshape does not create a view, the MemoryPlanner does manage the output tensor.
Reviewed By: ajyu
Differential Revision: D25992202
fbshipit-source-id: dadd63b78088c129e491d78abaf8b33d8303ca0d
2021-01-27 22:44:11 -08:00
Vasiliy Kuznetsov
983b8e6b62
fake_quant: add a more memory efficient version ( #50561 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50561
Not for review yet, a bunch of TODOs need finalizing.
tl;dr; add an alternative implementation of `fake_quantize` which saves
a ask during the forward pass and uses it to calculate the backward.
There are two benefits:
1. the backward function no longer needs the input Tensor, and it can be
gc'ed earlier by autograd. On MobileNetV2, this reduces QAT overhead
by ~15% (TODO: link, and absolute numbers). We add an additional mask Tensor
to pass around, but its size is 4x smaller than the input tensor. A
future optimization would be to pack the mask bitwise and unpack in the
backward.
2. the computation of `qval` can be done only once in the forward and
reused in the backward. No perf change observed, TODO verify with better
matrics.
TODO: describe in more detail
Test Plan:
OSS / torchvision / MobileNetV2
```
python references/classification/train_quantization.py
--print-freq 1
--data-path /data/local/packages/ai-group.imagenet-256-smallest-side/prod/
--output-dir ~/nfs/pytorch_vision_tests/
--backend qnnpack
--epochs 5
TODO paste results here
```
TODO more
Imported from OSS
Reviewed By: ngimel
Differential Revision: D25918519
fbshipit-source-id: ec544ca063f984de0f765bf833f205c99d6c18b6
2021-01-27 19:36:04 -08:00
Mikhail Zolotukhin
e975169426
[TensorExpr] Redesign Tensor class. ( #50995 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50995
This change makes 'Tensor' a thin wrapper over 'Buf' and 'Stmt', and
merges it with recently introduced 'CompoundTensor'. A statement for the
tensor is either passed directly to the Tensor constructor (akin to
'CompoundTensor'), or is built immediately in constructor.
LoopNest is no longer responsible for constructing statements from
tensors - it simply stitches already constructed statements contained in
Tensors. This has a side effect that now we cannot construct several
loopnests from the same tensors - we need to explicitly clone statements
if we want to do that. A special copy constructor was added to LoopNest
to make it more convenient (note: this only affects tests, we don't
usually create multiple loopnests in other places).
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26038223
Pulled By: ZolotukhinM
fbshipit-source-id: 27a2e5900437cfb0c151e8f89815edec53608e17
2021-01-27 16:14:22 -08:00
Nikita Shulga
97ea95ddd7
Delete tabs from becnh_approx.cpp ( #51157 )
...
Summary:
Introduced by D25981260 (f08464f31dhttps://github.com/pytorch/pytorch/pull/51157
Reviewed By: bwasti
Differential Revision: D26090008
Pulled By: malfet
fbshipit-source-id: b63f1bb1683c7261902de7eaab24a05a5159ce7e
2021-01-26 15:53:47 -08:00
Bert Maher
c4029444d1
[nnc] Per-operator benchmarks ( #51093 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51093
Operator level benchmarks comparing eager-mode PyTorch to
NNC-generated fused kernels. We wouldn't normally see these in isolation, but
it points out where NNC is falling short (or doing well).
I threw in a composed hardswish for fun, because it's my favorite activation
function.
Notably, it exposes a bug in our build process that's preventing vectorization
from using `sleef`, so we're using scalar calls to libm with predictably lousy
performance. Fix incoming.
This benchmark is similar to the pure NNC approach in `microbenchmarks.py`, but
will include the overhead of dispatching the fused kernel through TorchScript.
ghstack-source-id: 120403675
Test Plan:
```
op eager nnc speedup
hardswish 0.187 0.051 3.70
hardswish 0.052 0.052 1.00
sigmoid 0.148 1.177 0.13
reciprocal 0.049 0.050 0.98
neg 0.038 0.037 1.02
relu 0.037 0.036 1.03
isnan 0.119 0.020 5.86
log 0.082 1.330 0.06
log10 0.148 1.848 0.08
log1p 0.204 1.413 0.14
log2 0.285 1.167 0.24
exp 0.063 1.123 0.06
expm1 0.402 1.417 0.28
erf 0.167 0.852 0.20
erfc 0.181 1.098 0.16
cos 0.124 0.793 0.16
sin 0.126 0.838 0.15
tan 0.285 1.777 0.16
acos 0.144 1.358 0.11
asin 0.126 1.193 0.11
cosh 0.384 1.761 0.22
sinh 0.390 2.279 0.17
atan 0.240 1.564 0.15
tanh 0.320 2.259 0.14
sqrt 0.043 0.069 0.63
rsqrt 0.118 0.117 1.01
abs 0.038 0.037 1.03
ceil 0.038 0.038 1.01
floor 0.039 0.039 1.00
round 0.039 0.292 0.13
trunc 0.040 0.036 1.12
lgamma 2.045 2.721 0.75
```
Reviewed By: zheng-xq
Differential Revision: D26069791
fbshipit-source-id: 236e7287ba1b3f67fdcb938949a92bbbdfa13dba
2021-01-26 14:10:08 -08:00
Bram Wasti
f08464f31d
[nnc] Add benchmarks
...
Summary: Adding a set of benchmarks for key operators
Test Plan:
buck build mode/opt -c 'fbcode.caffe2_gpu_type=none' caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench
OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 numactl -C 3 ./buck-out/gen/caffe2/benchmarks/cpp/tensorexpr/tensorexpr_bench
Reviewed By: ZolotukhinM
Differential Revision: D25981260
fbshipit-source-id: 17681fc1527f43ccf9bcc80704415653a627b396
2021-01-26 13:51:33 -08:00
Horace He
4cca08368b
Adds per-op microbenchmarks for NNC ( #50845 )
...
Summary:
Runs through vast majority of primitive ops that exist in NNC and benchmarks them against PyTorch ops on CPU. Dumps out a plot like this.
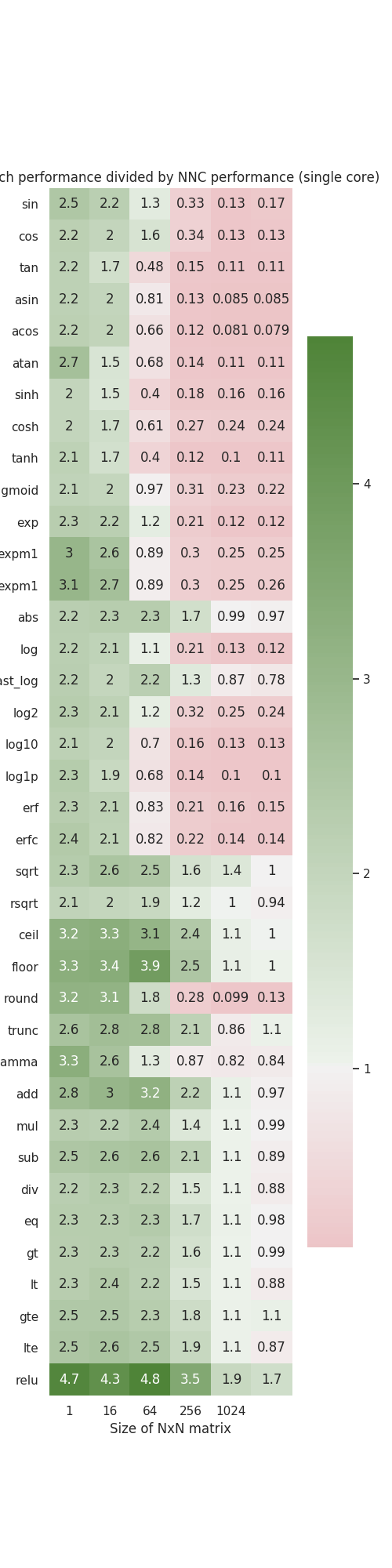
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50845
Reviewed By: ngimel
Differential Revision: D25989080
Pulled By: Chillee
fbshipit-source-id: 6d6a39eb06b3de9a999993224d5e718537c0c8c4
2021-01-21 13:21:01 -08:00
Xiaoqiang Zheng
b96a6516a6
Add CPP Full Reduction Benchmarks. ( #50193 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50193
* Supports aten, native reference implementation, and NNC TE implementations.
* Support functionality checks against aten, in addition to performance checks.
Test plans:
* After enable "BUILD_TENSOREXPR_BENCHMARK" in CMakeLists.txt,
* bin/tensorexpr_bench --benchmark_filter=Reduce1D
Measurements:
On a Broadwell E5-2686 CPU,
Reduce1D/Torch/16777216 5638547 ns 5638444 ns 119 BYTES=11.902G/s
Reduce1D/Naive/16777216 19308235 ns 19308184 ns 36 BYTES=3.47567G/s
Reduce1D/NativeRfactor/16777216 8433348 ns 8433038 ns 85 BYTES=7.95785G/s
Reduce1D/NativeVector/16777216 5608836 ns 5608727 ns 124 BYTES=11.9651G/s
Reduce1D/NativeTiled/16777216 5550233 ns 5550221 ns 126 BYTES=12.0912G/s
Reduce1D/TeNaive/16777216 21451047 ns 21450752 ns 33 BYTES=3.12851G/s
Reduce1D/TeSplitTail/16777216 23701732 ns 23701229 ns 30 BYTES=2.83145G/s
Reduce1D/TeSplitMask/16777216 23683589 ns 23682978 ns 30 BYTES=2.83363G/s
Reduce1D/TeRfactorV2/16777216 5378019 ns 5377909 ns 131 BYTES=12.4786G/s
Result summary:
* The single-threaded performance with NNC TeRfactorV2 matches and exceeds Aten and avx2 naive counterpart.
Follow-up items:
* rfactor does not work well with split
* We don't have a multi-threaded implementation yet.
* Missing "parallel" scheduling primitive, which is not different from what we need for pointwise ops.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25821880
Pulled By: zheng-xq
fbshipit-source-id: 8df3f40d1eed8749c8edcaacae5f0544dbf6bed3
2021-01-21 10:00:50 -08:00
Xiaoqiang Zheng
88b36230f5
Add full reduction benchmark. ( #50057 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50057
As part of the effort to calibrate TE reduction performance, adding a full reduction benchmark.
Also add a "skip_input_transformation" option.
Fixed other reduction benchmarks to accept specific benchmarks that was listed.
Test plans:
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce_full
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce_full_fwd_cpu_16777216_s1
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce_full_fwd_cpu_16777216_s0
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce2d_inner
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce2d_inner_fwd_cpu_640_524288
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce2d_outer
* python -m benchmarks.tensorexpr --device=cpu --mode=fwd reduce2d_outer_fwd_cpu_640_524288
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25774138
Pulled By: zheng-xq
fbshipit-source-id: fd4598e5c29991be476e42235a059e8021d4f083
2021-01-21 09:56:46 -08:00
Marat Subkhankulov
dea9af5c06
Cat benchmark: use mobile feed tensor shapes and torch.cat out-variant ( #50778 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50778
- use tensor shapes from ctr_mobilefeed merge net
- use pt cat out-variant for a fairer comparison otherwise benchmark includes time to construct result tensor
Test Plan:
turbo off, devbig machine
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/c2/concat_test.par --tag_filter=static_runtime
```
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : static_runtime
# Benchmarking Caffe2: concat
# Name: concat_sizes(1,40)_N5_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: (1, 40), N: 5, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 0.619
# Benchmarking Caffe2: concat
# Name: concat_sizes[(1,160),(1,14)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(1, 160), (1, 14)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 0.369
# Benchmarking Caffe2: concat
# Name: concat_sizes[(1,20,40),(1,4,40),(1,5,40)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(1, 20, 40), (1, 4, 40), (1, 5, 40)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 0.590
# Benchmarking Caffe2: concat
# Name: concat_sizes[(1,580),(1,174)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(1, 580), (1, 174)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 0.412
# Benchmarking Caffe2: concat
# Name: concat_sizes(20,40)_N5_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: (20, 40), N: 5, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 2.464
# Benchmarking Caffe2: concat
# Name: concat_sizes[(20,160),(20,14)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(20, 160), (20, 14)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 1.652
# Benchmarking Caffe2: concat
# Name: concat_sizes[(20,20,40),(20,4,40),(20,5,40)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(20, 20, 40), (20, 4, 40), (20, 5, 40)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 9.312
# Benchmarking Caffe2: concat
# Name: concat_sizes[(20,580),(20,174)]_N-1_axis1_add_axis0_devicecpu_dtypefloat
# Input: sizes: [(20, 580), (20, 174)], N: -1, axis: 1, add_axis: 0, device: cpu, dtype: float
Forward Execution Time (us) : 6.532
```
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/cat_test.par --tag_filter=static_runtime
```
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : static_runtime
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(1,160),(1,14)]_N-1_dim1_cpu
# Input: sizes: [(1, 160), (1, 14)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 3.313
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(1,20,40),(1,4,40),(1,5,40)]_N-1_dim1_cpu
# Input: sizes: [(1, 20, 40), (1, 4, 40), (1, 5, 40)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 3.680
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(1,580),(1,174)]_N-1_dim1_cpu
# Input: sizes: [(1, 580), (1, 174)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 3.452
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(20,160),(20,14)]_N-1_dim1_cpu
# Input: sizes: [(20, 160), (20, 14)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 4.653
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(20,20,40),(20,4,40),(20,5,40)]_N-1_dim1_cpu
# Input: sizes: [(20, 20, 40), (20, 4, 40), (20, 5, 40)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 7.364
# Benchmarking PyTorch: cat
# Mode: Eager
# Name: cat_sizes[(20,580),(20,174)]_N-1_dim1_cpu
# Input: sizes: [(20, 580), (20, 174)], N: -1, dim: 1, device: cpu
Forward Execution Time (us) : 7.055
```
Reviewed By: hlu1
Differential Revision: D25839036
fbshipit-source-id: 7a6a234f41dfcc56246a80141fe0c84f769a5a85
2021-01-19 22:50:28 -08:00
Nikita Shulga
171f265d80
Back out "Revert D25717510: Clean up some type annotations in benchmarks/fastrnns" ( #50556 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50556
Original commit changeset: 2bcc19cd4340
Test Plan: Soft revert hammer
Reviewed By: walterddr, seemethere
Differential Revision: D25917129
fbshipit-source-id: e5caad77655789d607b84eee820aa7c960e00f51
2021-01-14 15:15:03 -08:00
Bert Maher
468c99fba4
Reapply D25856891: [te] Benchmark comparing fused overhead to unfused ( #50543 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50543
Original commit changeset: 2d2f07f79986
Was part of a stack that got reverted. This is just a benchmark.
ghstack-source-id: 119825594
Test Plan: CI
Reviewed By: navahgar
Differential Revision: D25912439
fbshipit-source-id: 5d9ca45810fff8931a3cfbd03965e11050180676
2021-01-14 14:17:45 -08:00
Mike Ruberry
2639f1d4a6
Revert D25717510: Clean up some type annotations in benchmarks/fastrnns
...
Test Plan: revert-hammer
Differential Revision:
D25717510 (7d0eecc666
2021-01-14 07:23:45 -08:00
Mike Ruberry
4ee631cdf0
Revert D25856891: [te] Benchmark comparing fused overhead to unfused
...
Test Plan: revert-hammer
Differential Revision:
D25856891 (36ae3feb22
2021-01-14 04:33:35 -08:00
Nikita Shulga
a3f9cf9497
Fix fastrnn benchmark regression introduced by 49946 ( #50517 )
...
Summary:
Simply add missing `from typing import List, Tuple` and `from torch import Tensor`
Fixes regression introduced by https://github.com/pytorch/pytorch/pull/49946
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50517
Reviewed By: gchanan
Differential Revision: D25908379
Pulled By: malfet
fbshipit-source-id: a44b96681b6121e61b69f960f81c0cad3f2a8d20
2021-01-13 19:10:11 -08:00
Bert Maher
36ae3feb22
[te] Benchmark comparing fused overhead to unfused ( #50305 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50305
That's it
ghstack-source-id: 119631533
Test Plan:
```
buck run //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench -- --benchmark_filter=Overhead
```
```
Run on (24 X 2394.67 MHz CPU s)
2021-01-08 16:06:17
-------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------
FusedOverhead 2157 ns 2157 ns 311314
UnfusedOverhead 2443 ns 2443 ns 311221
```
Reviewed By: ZolotukhinM
Differential Revision: D25856891
fbshipit-source-id: 0e99515ec2e769a04929157d46903759c03182a3
2021-01-13 12:09:37 -08:00
Richard Barnes
7d0eecc666
Clean up some type annotations in benchmarks/fastrnns ( #49946 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49946
Upgrades type annotations from Python2 to Python3
Test Plan: Sandcastle tests
Reviewed By: xush6528
Differential Revision: D25717510
fbshipit-source-id: 4f6431d140e3032b4ca55587f9602aa0ea38c671
2021-01-13 09:57:14 -08:00
Marat Subkhankulov
49896c48e0
Caffe2 Concat operator benchmark ( #50449 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50449
Port caffe2 operator benchmark from torch.cat to caffe2 concat to measure the difference in performance.
previous diff abandoned to rerun github CI tests. D25738076
Test Plan:
Tested on devbig by running both pt and c2 benchmarks. Compiled with mode/opt
Inputs:
```
size, number of inputs, cat dimension, device
----------------------------------------------------
(1, 1, 1), N: 2, dim: 0, device: cpu
(512, 512, 2), N: 2, dim: 1, device: cpu
(128, 1024, 2), N: 2, dim: 1, device: cpu
(1024, 1024, 2), N: 2, dim: 0, device: cpu
(1025, 1023, 2), N: 2, dim: 1, device: cpu
(1024, 1024, 2), N: 2, dim: 2, device: cpu
[<function <lambda> at 0x7f922718e8c0>, 111, 65], N: 5, dim: 0, device: cpu
[96, <function <lambda> at 0x7f9226dad710>, 64], N: 5, dim: 1, device: cpu
[128, 64, <function <lambda> at 0x7f91a3625ef0>], N: 5, dim: 2, device: cpu
[<function <lambda> at 0x7f91a3625f80>, 32, 64], N: 50, dim: 0, device: cpu
[32, <function <lambda> at 0x7f91a3621050>, 64], N: 50, dim: 1, device: cpu
[33, 65, <function <lambda> at 0x7f91a36210e0>], N: 50, dim: 2, device: cpu
(64, 32, 4, 16, 32), N: 2, dim: 2, device: cpu
(16, 32, 4, 16, 32), N: 8, dim: 2, device: cpu
(9, 31, 5, 15, 33), N: 17, dim: 4, device: cpu
[<function <lambda> at 0x7f91a3621170>], N: 100, dim: 0, device: cpu
[<function <lambda> at 0x7f91a3621200>], N: 1000, dim: 0, device: cpu
[<function <lambda> at 0x7f91a3621290>], N: 2000, dim: 0, device: cpu
[<function <lambda> at 0x7f91a3621320>], N: 3000, dim: 0, device: cpu
```
```
pytorch: MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/cat_test.par --tag_filter=all
caffe2: MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/c2/concat_test.par --tag_filter=all
```
```
Metric: Forward Execution Time (us)
pytorch | caffe2
--------------------------------
4.066 | 0.312
351.507 | 584.033
184.649 | 292.157
9482.895 | 6845.112
9558.988 | 6847.511
13730.016 | 14118.505
6324.371 | 4840.883
4613.497 | 3702.213
7504.718 | 7889.751
9882.978 | 7364.350
10087.076 | 7483.178
16849.556 | 18092.295
19181.075 | 13363.742
19296.508 | 13466.863
34157.449 | 56320.073
176.483 | 267.106
322.247 | 352.782
480.064 | 460.214
607.381 | 476.908
```
Reviewed By: hlu1
Differential Revision: D25890595
fbshipit-source-id: f53e125c0680bc2ebf722d1da5ec964bec585fdd
2021-01-12 18:27:44 -08:00
Oscar Sandoval
09f4844c1f
Pytorch Distributed RPC Reinforcement Learning Benchmark (Throughput and Latency) ( #46901 )
...
Summary:
A Pytorch Distributed RPC benchmark measuring Agent and Observer Throughput and Latency for Reinforcement Learning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46901
Reviewed By: mrshenli
Differential Revision: D25869514
Pulled By: osandoval-fb
fbshipit-source-id: c3b36b21541d227aafd506eaa8f4e5f10da77c78
2021-01-11 19:02:36 -08:00
Fritz Obermeyer
093aca082e
Enable distribution validation if __debug__ ( #48743 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47123
Follows https://github.com/pyro-ppl/pyro/pull/2701
This turns on `Distribution` validation by default. The motivation is to favor beginners by providing helpful error messages. Advanced users focused on speed can disable validation by calling
```py
torch.distributions.Distribution.set_default_validate_args(False)
```
or by disabling individual distribution validation via `MyDistribution(..., validate_args=False)`.
In practice I have found many beginners forget or do not know about validation. Therefore I have [enabled it by default](https://github.com/pyro-ppl/pyro/pull/2701 ) in Pyro. I believe PyTorch could also benefit from this change. Indeed validation caught a number of bugs in `.icdf()` methods, in tests, and in PPL benchmarks, all of which have been fixed in this PR.
## Release concerns
- This may slightly slow down some models. Concerned users may disable validation.
- This may cause new `ValueErrors` in models that rely on unsupported behavior, e.g. `Categorical.log_prob()` applied to continuous-valued tensors (only {0,1}-valued tensors are supported).
We should clearly note this change in release notes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48743
Reviewed By: heitorschueroff
Differential Revision: D25304247
Pulled By: neerajprad
fbshipit-source-id: 8d50f28441321ae691f848c55f71aa80cb356b41
2021-01-05 13:59:10 -08:00
Samuel Marks
e6779d4357
[*.py] Rename "Arguments:" to "Args:" ( #49736 )
...
Summary:
I've written custom parsers and emitters for everything from docstrings to classes and functions. However, I recently came across an issue when I was parsing/generating from the TensorFlow codebase: inconsistent use of `Args:` and `Arguments:` in its docstrings.
```sh
(pytorch#c348fae)$ for name in 'Args:' 'Arguments:'; do
printf '%-10s %04d\n' "$name" "$(rg -IFtpy --count-matches "$name" | paste -s -d+ -- | bc)"; done
Args: 1095
Arguments: 0336
```
It is easy enough to extend my parsers to support both variants, however it looks like `Arguments:` is wrong anyway, as per:
- https://google.github.io/styleguide/pyguide.html#doc-function-args @ [`ddccc0f`](https://github.com/google/styleguide/blob/ddccc0f/pyguide.md )
- https://chromium.googlesource.com/chromiumos/docs/+/master/styleguide/python.md#describing-arguments-in-docstrings @ [`9fc0fc0`](https://chromium.googlesource.com/chromiumos/docs/+/9fc0fc0/styleguide/python.md )
- https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html @ [`c0ae8e3`](https://github.com/sphinx-contrib/napoleon/blob/c0ae8e3/docs/source/example_google.rst )
Therefore, only `Args:` is valid. This PR replaces them throughout the codebase.
PS: For related PRs, see tensorflow/tensorflow/pull/45420
PPS: The trackbacks automatically appearing below are sending the same changes to other repositories in the [PyTorch](https://github.com/pytorch ) organisation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49736
Reviewed By: albanD
Differential Revision: D25710534
Pulled By: soumith
fbshipit-source-id: 61e8ff01abb433e9f78185c2d1d0cbd7c22c1619
2020-12-28 09:34:47 -08:00
skyline75489
46b83212d1
Remove unused six code for Python 2/3 compatibility ( #48077 )
...
Summary:
This is basically a reborn version of https://github.com/pytorch/pytorch/issues/45254 .
Ref: https://github.com/pytorch/pytorch/issues/42919
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48077
Reviewed By: ngimel
Differential Revision: D25687042
Pulled By: bugra
fbshipit-source-id: 05f20a6f3c5212f73d0b1505b493b720e6cf74e5
2020-12-22 18:07:08 -08:00
Alexander
44ce0b8883
Sparse-sparse matrix multiplication (CPU/CUDA) ( #39526 )
...
Summary:
This PR implements matrix multiplication support for 2-d sparse tensors using the COO sparse format.
The current implementation of `torch.sparse.mm` support this configuration,
`torch.sparse.mm(sparse_matrix1, sparse_matrix2.to_dense())`, but this could spend a lot of memory when sparse_matrix2's shape is large.
This implementation extends `torch.sparse.mm` function to support `torch.sparse.mm(sparse_matrix1, sparse_matrix2)`
Resolves #[20988](https://github.com/pytorch/pytorch/issues/20988 ) for CPU/CUDA.
- [x] sparse matmul
- [x] CPU/CUDA C++ implementation
- [x] unittests
- [x] update torch.sparse.mm documentation
- [x] autograd support
The CPU sparse-sparse matmul was implemented taking as a reference this work "Sparse Matrix Multiplication Package (SMMP)". The GPU sparse-sparse matmul is based on cuSparse, there is specific code for CUSPARSE when CUSPARSE_VERSION >= 11 and old version of CUSPARSE. Both CPU/CUDA rely on the sparse-sparse matmul algorithm using the CSR indices format as it is one of the fastest algorithm.
Here it is the latest benchmark (script is here) results for torch.sparse.mm (CUDA) and torch.sparse.mm (CPU) and scipy, values are float32 scalars:
size | density | sparse.mm(CUDA) | sparse.mm(CPU) | scipy_coo_matmul
-- | -- | -- | -- | --
(32, 10000) | 0.01 | 822.7 | 79.4 | 704.1
(32, 10000) | 0.05 | 1741.1 | 402.6 | 1155.3
(32, 10000) | 0.1 | 2956.8 | 840.8 | 1885.4
(32, 10000) | 0.25 | 6417.7 | 2832.3 | 4665.2
(512, 10000) | 0.01 | 1010.2 | 3941.3 | 26937.7
(512, 10000) | 0.05 | 2216.2 | 26903.8 | 57343.7
(512, 10000) | 0.1 | 4868.4 | 87773.7 | 117477.0
(512, 10000) | 0.25 | 16639.3 | 608105.0 | 624290.4
(1024, 10000) | 0.01 | 1224.8 | 13088.1 | 110379.2
(1024, 10000) | 0.05 | 3897.5 | 94783.9 | 236541.8
(1024, 10000) | 0.1 | 10559.1 | 405312.5 | 525483.4
(1024, 10000) | 0.25 | 57456.3 | 2424337.5 | 2729318.7
A new backward algorithm was implemented using only `sparse @ sparse` and `sparse_mask` operations. Here is some benchmarking:
```
[------------------------- sparse.mm-backward -------------------------]
| sparse.backward | dense.backward
-----------------------------------------------------------------------
(32, 10000) | 0.01 | 13.5 | 2.4
(32, 10000) | 0.05 | 52.3 | 2.4
(512, 10000) | 0.01 | 1016.8 | 491.5
(512, 10000) | 0.05 | 1604.3 | 492.3
(1024, 10000) | 0.01 | 2384.1 | 1963.7
(1024, 10000) | 0.05 | 3965.8 | 1951.9
```
I added new benchmark tests. Now I am using a real dataset used in recent studies [1, 2] with different sparsity levels.
```
[---------------------------------- matmul ---------------------------------]
| 0.5 | 0.7 | 0.8 | 0.9 | 0.95 | 0.98
1 threads: ------------------------------------------------------------------
(cpu) torch | 5.4 | 5.4 | 5.2 | 5.3 | 5.3 | 5.4
torch.sparse | 122.2 | 51.9 | 27.5 | 11.4 | 4.9 | 1.8
scipy | 150.1 | 87.4 | 69.2 | 56.8 | 38.4 | 17.1
(cuda) torch | 1.3 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1
torch.sparse | 20.0 | 8.4 | 5.1 | 2.5 | 1.5 | 1.1
[----------------------------------- backward -----------------------------------]
| 0.5 | 0.7 | 0.8 | 0.9 | 0.95 | 0.98
1 threads: -----------------------------------------------------------------------
(cpu) torch | 17.7 | 17.9 | 17.7 | 17.7 | 17.6 | 17.9
torch.sparse | 672.9 | 432.6 | 327.5 | 230.8 | 176.7 | 116.7
(cuda) torch | 3.8 | 3.6 | 3.5 | 3.5 | 3.6 | 3.5
torch.sparse | 68.8 | 46.2 | 35.6 | 24.2 | 17.8 | 11.9
Times are in milliseconds (ms).
```
In summary, I can say that the new `sparse @ sparse` backward algorithm is better as it is more about saving space than performance. Moreover, it is better than other options tested before.
## **References**
1. Trevor Gale, Matei Zaharia, Cliff Young, Erich Elsen. **Sparse GPU Kernels for Deep Learning.** Proceedings of the International Conference for High Performance Computing, 2020. [https://github.com/google-research/google-research/tree/master/sgk ](https://github.com/google-research/google-research/tree/master/sgk )
2. Trevor Gale, Erich Elsen, Sara Hooker. **The State of Sparsity in Deep Neural Networks.** [https://github.com/google-research/google-research/tree/master/state_of_sparsity ](https://github.com/google-research/google-research/tree/master/state_of_sparsity )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39526
Reviewed By: mruberry
Differential Revision: D25661239
Pulled By: ngimel
fbshipit-source-id: b515ecd66d25f347d637e159d51aa45fb43b6938
2020-12-21 11:53:55 -08:00
mrshenli
e4eaa6de5f
Fix lint ( #49629 )
...
Summary:
Fix lint on master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49629
Reviewed By: rohan-varma
Differential Revision: D25654199
Pulled By: mrshenli
fbshipit-source-id: 2ab5669ad47996c0ca0f9b6611855767d5af0506
2020-12-18 19:26:06 -08:00
Pritam Damania
159de1f1d6
Add benchmark for torch.distributed.pipeline.sync.Pipe ( #49577 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49577
Repurposing the benchmarking from
https://github.com/facebookresearch/fairscale/blob/master/benchmarks/pipe.py
and pulling in a stripped down version of the benchmark into PyTorch.
Sample output:
```
Running benchmark with args: Namespace(batch_size=8, checkpoint='never', chunks=4, host='localhost', max_batch=10, num_decoder_layers=10, num_devices=4)
Number of parameters for model: 292833040
| batch 1 | wps 3593.07 | loss 25.98 | ppl 192556591553.37
| batch 2 | wps 4405.16 | loss 19.36 | ppl 256201548.33
| batch 3 | wps 4404.98 | loss 23.56 | ppl 17111244076.37
| batch 4 | wps 4413.25 | loss 27.11 | ppl 594561327825.83
| batch 5 | wps 4408.53 | loss 25.92 | ppl 181277705101.33
| batch 6 | wps 4385.64 | loss 24.92 | ppl 66592883598.50
| batch 7 | wps 4434.11 | loss 24.75 | ppl 56113635884.68
| batch 8 | wps 4441.25 | loss 24.88 | ppl 63666024212.82
| batch 9 | wps 4425.49 | loss 25.35 | ppl 101959669008.98
| batch 10 | wps 4421.05 | loss 25.34 | ppl 101597621863.94
Peak memory usage for GPUs: cuda:0: 2.38GiB, cuda:1: 3.04GiB, cuda:2: 3.04GiB, cuda:3: 3.67GiB,
```
ghstack-source-id: 118939686
Test Plan: sentinel
Reviewed By: rohan-varma
Differential Revision: D25628721
fbshipit-source-id: 41c788eed4f852aef019aec18a84cb25ad254f3a
2020-12-18 18:33:47 -08:00
Shijun Kong
2de345d44d
Add op bench for caffe2 quantile op ( #49598 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49598
Add op bench for caffe2 quantile op
Test Plan: `buck run mode/opt caffe2/benchmarks/operator_benchmark/c2:quantile_op_test -- --wramup_iterations=10000 --iterations=10000`
Reviewed By: radkris-git
Differential Revision: D25590085
fbshipit-source-id: 0db58ac87c595b2bf2958f6299a1bf2ccea019db
2020-12-18 08:32:59 -08:00
Bram Wasti
1047957831
[te][reapply] Add fast log approximation based on sleef ( #49575 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49575
This is a fast log implementations
benchmark:
```
buck run mode/opt //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench -c 'fbcode.caffe2_gpu_type=none'
```
Test Plan: buck test mode/no-gpu //caffe2/test/cpp/tensorexpr:tensorexpr -- *.fastLogFloat
Reviewed By: bertmaher
Differential Revision: D25627157
fbshipit-source-id: a4920f4f4005ce617d372b375e790ca966275cd9
2020-12-17 17:02:00 -08:00
Edward Yang
ea4ccc730e
Revert D25445815: [te] Add fast log approximation based on sleef
...
Test Plan: revert-hammer
Differential Revision:
D25445815 (1329066b69
2020-12-17 15:03:17 -08:00
Bram Wasti
1329066b69
[te] Add fast log approximation based on sleef
...
Summary:
This is a fast log implementations
benchmark:
```
buck run mode/opt //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench -c 'fbcode.caffe2_gpu_type=none'
```
Test Plan: buck test mode/no-gpu //caffe2/test/cpp/tensorexpr:tensorexpr -- *.fastLogFloat
Reviewed By: bertmaher
Differential Revision: D25445815
fbshipit-source-id: 20696eacd12a55e797f606f4a6dbbd94c9652888
2020-12-17 14:28:34 -08:00
Ansha Yu
cb3169d7a8
[aten] index_select dim 1 ( #47077 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47077
Add benchmarks for pt index_select, batch_index_select, and c2's BatchGather
Add batch_index_select implementation based on the C2 BatchGather implementation
This currently falls back to index_select for backwards and cuda implementations.
Alternatively, we can look into the specifics of why index_select is slower and
replace the original implementation instead.
Test Plan:
./buck-out/opt/gen/caffe2/benchmarks/operator_benchmark/c2/batch_gather_test.par
./buck-out/opt/gen/caffe2/benchmarks/operator_benchmark/pt/index_select_test.par
PT results comparing without fix, block_size 1 only, and all dim=1
```
# no optimization
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K1_dim1_cpu
# Input: M: 256, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 353.450
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K1_dim1_cpu
# Input: M: 512, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 862.492
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K2_dim1_cpu
# Input: M: 256, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 4555.344
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K2_dim1_cpu
# Input: M: 512, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 11003.279
```
```
# block size 1 only
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K1_dim1_cpu
# Input: M: 256, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 129.240
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K1_dim1_cpu
# Input: M: 512, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 266.776
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K2_dim1_cpu
# Input: M: 256, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 4508.593
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K2_dim1_cpu
# Input: M: 512, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 10391.655
```
```
# dim 1
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M8_N8_K1_dim1_cpu
# Input: M: 8, N: 8, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 3.736
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K1_dim1_cpu
# Input: M: 256, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 130.460
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K1_dim1_cpu
# Input: M: 512, N: 512, K: 1, dim: 1, device: cpu
Forward Execution Time (us) : 267.706
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M8_N8_K2_dim1_cpu
# Input: M: 8, N: 8, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 4.187
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M256_N512_K2_dim1_cpu
# Input: M: 256, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 1739.550
# Benchmarking PyTorch: index_select
# Mode: Eager
# Name: index_select_M512_N512_K2_dim1_cpu
# Input: M: 512, N: 512, K: 2, dim: 1, device: cpu
Forward Execution Time (us) : 3468.332
```
C2 results:
```# Benchmarking Caffe2: batch_gather
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1203 13:19:35.310904 782584 init.h:137] Caffe2 GlobalInit should be run before any other API calls.
# Name: batch_gather_M8_N8_K1_devicecpu
# Input: M: 8, N: 8, K: 1, device: cpu
Forward Execution Time (us) : 0.308
# Benchmarking Caffe2: batch_gather
# Name: batch_gather_M256_N512_K1_devicecpu
# Input: M: 256, N: 512, K: 1, device: cpu
Forward Execution Time (us) : 90.517
# Benchmarking Caffe2: batch_gather
# Name: batch_gather_M512_N512_K1_devicecpu
# Input: M: 512, N: 512, K: 1, device: cpu
Forward Execution Time (us) : 200.009
# Benchmarking Caffe2: batch_gather
# Name: batch_gather_M8_N8_K2_devicecpu
# Input: M: 8, N: 8, K: 2, device: cpu
Forward Execution Time (us) : 0.539
# Benchmarking Caffe2: batch_gather
# Name: batch_gather_M256_N512_K2_devicecpu
# Input: M: 256, N: 512, K: 2, device: cpu
Forward Execution Time (us) : 1001.540
# Benchmarking Caffe2: batch_gather
# Name: batch_gather_M512_N512_K2_devicecpu
# Input: M: 512, N: 512, K: 2, device: cpu
Forward Execution Time (us) : 2005.870
```
buck test dper3/dper3/modules/low_level_modules/tests:single_operators_test -- test_batch_gather
Reviewed By: hlu1
Differential Revision: D24630227
fbshipit-source-id: cd205a30d96a33d239f3266820ada9a90093cf91
2020-12-14 15:39:33 -08:00
Bram Wasti
f4226b5c90
[static runtime] add static subgraph fusion pass ( #49185 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49185
This diff adds a fusion feature that will let us use static runtime for *parts* of the graph. This will prove useful in cases where fully eliminating control flow is hard etc.
TODO:
[x] factor out into separate fusion file
[x] add python test case
[x] add graph that isn't fully lowered test case
[x] add graph that has weird list/tuple outputs test case
the loop example looks quite good:
```
graph(%a.1 : Tensor,
%b.1 : Tensor,
%iters.1 : int):
%12 : bool = prim::Constant[value=1]() # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:110:4
%c.2 : Tensor = prim::StaticSubgraph_0(%a.1, %b.1)
%c : Tensor = prim::Loop(%iters.1, %12, %c.2) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:110:4
block0(%i : int, %c.12 : Tensor):
%c.10 : Tensor = prim::StaticSubgraph_1(%a.1, %c.12, %b.1)
-> (%12, %c.10)
return (%c)
with prim::StaticSubgraph_0 = graph(%0 : Tensor,
%4 : Tensor):
%5 : int = prim::Constant[value=2]()
%6 : Tensor = aten::mul(%4, %5) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:109:12
%2 : int = prim::Constant[value=1]()
%c.2 : Tensor = aten::add(%0, %6, %2) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:109:8
return (%c.2)
with prim::StaticSubgraph_1 = graph(%1 : Tensor,
%7 : Tensor,
%8 : Tensor):
%9 : int = prim::Constant[value=1]()
%c.4 : Tensor = aten::add(%7, %8, %9) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:111:12
%5 : int = prim::Constant[value=2]()
%c.7 : Tensor = aten::mul_(%c.4, %5) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:112:8
%2 : int = prim::Constant[value=1]()
%c.10 : Tensor = aten::sub_(%c.7, %1, %2) # /data/users/bwasti/fbsource/fbcode/buck-out/dev/gen/caffe2/test/static_runtime#binary,link-tree/test_static_runtime.py:113:8
return (%c.10)
```
(Note: this ignores all push blocking failures!)
Test Plan:
buck test mode/no-gpu //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test mode/no-gpu caffe2/test:static_runtime
Reviewed By: bertmaher
Differential Revision: D25385702
fbshipit-source-id: 2f24af4f11d92a959167facd03fbd24f464a6098
2020-12-10 14:03:11 -08:00
Edward Yang
16b8e6ab01
Class-based structured kernels, with migration of add to framework ( #48718 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48718
This PR rewrites structured kernels to do the class-based mechanism (instead of defining a meta and impl function, they are methods on a class), and adds enough customizability on the class to support TensorIterator. To show it works, add is made a structured kernel. Don't forget to check https://github.com/pytorch/rfcs/pull/9 for a mostly up-to-date high level description of what's going on here.
High level structure of this PR (the order you should review files):
* TensorMeta.h - TensorMeta is deleted entirely; instead, meta functions will call `set_output` to allocate/resize their outputs. MetaBase gets a new `maybe_get_output` virtual method for retrieving the (possibly non-existent) output tensor in a meta function; this makes it easier to do special promotion behavior, e.g., as in TensorIterator.
* TensorIterator.cpp - Two major changes: first, we add TensorIteratorBase::set_output, which is a "light" version of TensorIterator::set_output; it sets up the internal data structures in TensorIterator, but it doesn't do allocation (that is assumed to have been handled by the structured kernels framework). The control flow here is someone will call the subclassed set_output, which will allocate output, and then we will call the parent class (TensorIteratorBase) to populate the fields in TensorIterator so that other TensorIterator phases can keep track of it. Second, we add some tests for meta tensors, and skip parts of TensorIterator which are not necessary when data is not available.
* tools/codegen/model.py - One new field in native_functions.yaml, structured_inherits. This lets you override the parent class of a structured meta class; normally it's MetaBase, but you can make it point at TensorIteratorBase instead for TensorIterator based kernels
* tools/codegen/gen.py - Now generate all of the classes we promised. It's kind of hairy because this is the first draft. Check the RFC for what the output looks like, and then follow the logic here. There are some complications: I need to continue to generate old style wrapper functions even if an operator is structured, because SparseCPU/SparseCUDA/etc won't actually use structured kernels to start. The most complicated code generation is the instantiation of `set_output`, which by in large replicates the logic in `TensorIterator::set_output`. This will continue to live in codegen for the forseeable future as we would like to specialize this logic per device.
* aten/src/ATen/native/UpSampleNearest1d.cpp - The previous structured kernel is ported to the new format. The changes are very modest.
* aten/src/ATen/native/BinaryOps.cpp - Add is ported to structured.
TODO:
* Work out an appropriate entry point for static runtime, since native:: function stubs no longer are generated
* Refactor TensorIteratorConfig construction into helper functions, like before
* Make Tensor-Scalar addition structured to fix perf regression
* Fix `verify_api_visibility.cpp`
* Refactor tools/codegen/gen.py for clarity
* Figure out why header changes resulted in undefined reference to `at::Tensor::operator[](long) const`
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25278031
Pulled By: ezyang
fbshipit-source-id: 57c43a6e5df21929b68964d485995fbbae4d1f7b
2020-12-09 15:39:12 -08:00
Brian Hirsh
c7cc8a48c0
migrating some straggler pytorch ops in fbcode to the new registration API ( #48954 )
...
Summary:
I already migrated the majority of fbcode ops to the new registration API, but there are a few stragglers (mostly new files that were created in the last two weeks).
The goal is mostly to stamp out as much of the legacy registration API usage as possible, so that people only see the new API when they look around the code for examples of how to register their own ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48954
ghstack-source-id: 118140663
Test Plan: Ran buck targets for each file that I migrated
Reviewed By: ezyang
Differential Revision: D25380422
fbshipit-source-id: 268139a1d7b9ef14c07befdf9e5a31f15b96a48c
2020-12-09 14:42:29 -08:00
Nikolay Korovaiko
195ab5e864
remove non-default settings in fuser.py ( #48862 )
...
Summary:
I've noticed we are setting `_jit_set_num_profiled_runs` to 2 (which isn't our default) and sometimes we don't. We are also setting `_jit_set_bailout_depth` to 20 which **is** our default. I suggest we remove this logic altogether.
I did a quick run to see if there's any impact and thankfully, the numbers seem to be consistent, but we should try avoding testing configurations that aren't default or aren't considered to become default.
numactl -C 3 python -m fastrnns.bench --fuser=te --executor=profiling
non-defaults:
```
Namespace(cnns=None, cuda_pointwise_block_count=None, cuda_pointwise_block_size=None, cuda_pointwise_loop_level=None, device='cuda', executor='profiling', fuser='te', group=['cnns', 'rnns'], hiddenSize=512, inputSize=512, miniBatch=64, nloops=100, numLayers=1, print_json=None, rnns=None, sep=' ', seqLength=100, variable_lstms=False, warmup=10)
Benchmarking LSTMs...
name avg_fwd std_fwd info_fwd avg_bwd std_bwd info_bwd
cudnn 5.057 0.06287 None 7.322 0.07404 None
aten 5.602 0.06303 None 13.64 0.4078 None
jit 7.019 0.07995 None 13.77 0.554 None
jit_premul 5.324 0.06203 None 12.01 0.2996 None
jit_premul_bias 5.148 0.08061 None 11.62 0.4104 None
jit_simple 6.69 0.2317 None 13.37 0.3791 None
jit_multilayer 7.006 0.251 None 13.67 0.2239 None
py 19.05 0.1119 None 28.28 0.6346 None
Benchmarking ResNets...
name avg_fwd std_fwd info_fwd avg_bwd std_bwd info_bwd
resnet18 8.712 0.01628 None 19.93 0.03512 None
resnet18_jit 8.688 0.01374 None 19.79 0.07518 None
resnet50 31.04 0.08049 None 66.44 0.08187 None
resnet50_jit 31.11 0.07171 None 66.45 0.09157 None
```
defaults:
```
Namespace(cnns=None, cuda_pointwise_block_count=None, cuda_pointwise_block_size=None, cuda_pointwise_loop_level=None, device='cuda', executor='profiling', fuser='te', group=['cnns', 'rnns'], hiddenSize=512, inputSize=512, miniBatch=64, nloops=100, numLayers=1, print_json=None, rnns=None, sep=' ', seqLength=100, variable_lstms=False, warmup=10)
Benchmarking LSTMs...
name avg_fwd std_fwd info_fwd avg_bwd std_bwd info_bwd
cudnn 5.086 0.115 None 7.394 0.1743 None
aten 5.611 0.2559 None 13.54 0.387 None
jit 7.062 0.3358 None 13.24 0.3688 None
jit_premul 5.379 0.2086 None 11.57 0.3987 None
jit_premul_bias 5.202 0.2127 None 11.13 0.06748 None
jit_simple 6.648 0.05794 None 12.84 0.3047 None
jit_multilayer 6.964 0.1104 None 13.24 0.3283 None
py 19.14 0.09959 None 28.17 0.4946 None
Benchmarking ResNets...
name avg_fwd std_fwd info_fwd avg_bwd std_bwd info_bwd
resnet18 8.713 0.01563 None 19.93 0.02759 None
resnet18_jit 8.697 0.01792 None 19.78 0.06916 None
resnet50 31.14 0.07431 None 66.57 0.07418 None
resnet50_jit 31.21 0.0677 None 66.56 0.08655 None
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48862
Reviewed By: bertmaher
Differential Revision: D25342097
Pulled By: Krovatkin
fbshipit-source-id: 8d2f72c2770793ec8cecee9dfab9aaaf2e1ad2b1
2020-12-05 20:58:39 -08:00
elfringham
db1b0b06c4
Flake8 fixes ( #48453 )
...
Summary:
Quiet errors from flake8. Only a couple of code changes for deprecated Python syntax from before 2.4. The rest is just adding noqa markers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48453
Reviewed By: mruberry
Differential Revision: D25181871
Pulled By: ngimel
fbshipit-source-id: f8d7298aae783b1bce2a46827b088fc390970641
2020-11-25 19:09:50 -08:00
Ilia Cherniavskii
f7a8bf2855
Use libkineto in profiler ( #46470 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46470
Adding ability to use Kineto (CUPTI) to profile CUDA kernels
Test Plan:
USE_KINETO=1 USE_CUDA=1 USE_MKLDNN=1 BLAS=MKL BUILD_BINARY=1 python setup.py develop install
python test/test_profiler.py
python test/test_autograd.py -k test_profile
python test/test_autograd.py -k test_record
```
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Memcpy HtoD (Pageable -> Device) 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 33.33% 2.000us 1.000us 2
sgemm_32x32x32_NN 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 33.33% 2.000us 2.000us 1
void at::native::vectorized_elementwise_kernel<4, at... 0.00% 0.000us 0.00% 0.000us 0.000us 1.000us 16.67% 1.000us 1.000us 1
Memcpy DtoH (Device -> Pageable) 0.00% 0.000us 0.00% 0.000us 0.000us 1.000us 16.67% 1.000us 1.000us 1
aten::randn 5.17% 74.000us 6.71% 96.000us 48.000us 0.000us 0.00% 0.000us 0.000us 2
aten::empty 1.33% 19.000us 1.33% 19.000us 4.750us 0.000us 0.00% 0.000us 0.000us 4
aten::normal_ 1.05% 15.000us 1.05% 15.000us 7.500us 0.000us 0.00% 0.000us 0.000us 2
aten::to 77.90% 1.114ms 91.61% 1.310ms 436.667us 0.000us 0.00% 3.000us 1.000us 3
aten::empty_strided 2.52% 36.000us 2.52% 36.000us 12.000us 0.000us 0.00% 0.000us 0.000us 3
aten::copy_ 2.73% 39.000us 11.19% 160.000us 53.333us 0.000us 0.00% 3.000us 1.000us 3
cudaMemcpyAsync 4.34% 62.000us 4.34% 62.000us 20.667us 0.000us 0.00% 0.000us 0.000us 3
cudaStreamSynchronize 1.61% 23.000us 1.61% 23.000us 7.667us 0.000us 0.00% 0.000us 0.000us 3
aten::mm 0.21% 3.000us 7.20% 103.000us 103.000us 0.000us 0.00% 2.000us 2.000us 1
aten::stride 0.21% 3.000us 0.21% 3.000us 1.000us 0.000us 0.00% 0.000us 0.000us 3
cudaLaunchKernel 2.45% 35.000us 2.45% 35.000us 17.500us 0.000us 0.00% 0.000us 0.000us 2
aten::add 0.49% 7.000us 4.27% 61.000us 61.000us 0.000us 0.00% 1.000us 1.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
```
benchmark: https://gist.github.com/ilia-cher/a5a9eb6b68504542a3cad5150fc39b1a
Reviewed By: Chillee
Differential Revision: D25142223
Pulled By: ilia-cher
fbshipit-source-id: b0dff46c28da5fb0a8e01cf548aa4f2b723fde80
2020-11-25 04:32:16 -08:00
Hao Lu
c5dae335e4
[PT][StaticRuntime] Move prim op impl to ops.cpp ( #48210 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48210
- Move prim op implementation from `ProcessedNode::run` to `getNativeOperation`
- Add out variant for `prim::listConstruct`
Test Plan:
```
buck test //caffe2/test:static_runtime
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test //caffe2/caffe2/fb/predictor:pytorch_predictor_test
buck run mode/dev //caffe2/caffe2/fb/predictor:ptvsc2_predictor_bench -- \
--scripted_model=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/traced_precomputation.pt \
--pt_inputs=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/container_precomputation_bs1.pt \
--iters=1 --warmup_iters=1 --num_threads=1 --pt_enable_static_runtime=true \
--pt_cleanup_activations=true --pt_enable_out_variant=true
```
Reviewed By: ajyu
Differential Revision: D24748947
fbshipit-source-id: 12caeeae87b69e60505a6cea31786bd96f5c8684
2020-11-18 23:07:39 -08:00
Bert Maher
464d23e6b4
[te][benchmark] Add more optimized versions of gemm ( #48159 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/48159
Test Plan: Imported from OSS
Reviewed By: Chillee, ngimel
Differential Revision: D25059742
Pulled By: bertmaher
fbshipit-source-id: f197347f739c5bd2a4182c59ebf4642000c3dd55
2020-11-18 12:21:08 -08:00
Bram Wasti
cb046f7bd2
[static runtime] Initial memonger ( #47759 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47759
Parity reached :)
*/0 -> no memonger
*/1 -> memonger on
We can see that the impact is large when activations don't all fit in cache (6x speed up on this micro bench)
```
BM_long_static_memory_optimization/2/0 8563 ns 8559 ns 86370
BM_long_static_memory_optimization/8/0 8326 ns 8322 ns 84099
BM_long_static_memory_optimization/32/0 11446 ns 11440 ns 56107
BM_long_static_memory_optimization/512/0 6116629 ns 6113108 ns 128
BM_long_static_memory_optimization/2/1 8151 ns 8149 ns 87000
BM_long_static_memory_optimization/8/1 7905 ns 7902 ns 85124
BM_long_static_memory_optimization/32/1 10652 ns 10639 ns 66055
BM_long_static_memory_optimization/512/1 1101415 ns 1100673 ns 641
```
TODO:
[x] implementation
[x] enable/disable flag
[x] statistics about memory saved
[x] additional models
Test Plan:
```
buck test //caffe2/test:static_runtime
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test //caffe2/caffe2/fb/predictor:pytorch_predictor_test
```
Reviewed By: yinghai
Differential Revision: D24824445
fbshipit-source-id: db1f5239f72cbd1a9444017e20d5a107c3b3f043
2020-11-17 13:55:49 -08:00
Katy Voor
fe7d1d7d0e
Add LeakyReLU operator to static runtime ( #47798 )
...
Summary:
- Add LeakyReLU operator to static runtime
- Add LeakyReLU benchmark
- Add LeakyReLU correctness test case
Static Runtime
```
------------------------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------------------------
BM_leaky_relu/1 4092 ns 4092 ns 172331
BM_leaky_relu/8 4425 ns 4425 ns 158434
BM_leaky_relu/20 4830 ns 4830 ns 145335
BM_leaky_relu_const/1 3545 ns 3545 ns 198054
BM_leaky_relu_const/8 3825 ns 3825 ns 183074
BM_leaky_relu_const/20 4222 ns 4222 ns 165999
```
Interpreter
```
------------------------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------------------------
BM_leaky_relu/1 7183 ns 7182 ns 96377
BM_leaky_relu/8 7580 ns 7580 ns 91588
BM_leaky_relu/20 8066 ns 8066 ns 87183
BM_leaky_relu_const/1 6466 ns 6466 ns 107925
BM_leaky_relu_const/8 7063 ns 7063 ns 98768
BM_leaky_relu_const/20 7380 ns 7380 ns 94564
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47798
Reviewed By: ezyang
Differential Revision: D24927043
Pulled By: kavoor
fbshipit-source-id: 69b12cc57f725f1dc8d68635788813710a74dc2b
2020-11-13 22:05:52 -08:00
Yang Wang
0125e14c9a
[OpBench] change relu entry point after D24747035
...
Summary: D24747035 (1478e5ec2a
2020-11-13 15:38:27 -08:00
Richard Zou
d4db4718fa
Revert D24873991: Profiler benchmark fix
...
Test Plan: revert-hammer
Differential Revision:
D24873991 (a97c7e2ef0
2020-11-13 08:37:14 -08:00
Yang Wang
9ee4f499f0
[OpBench] add _consume_op.list for processing input with type of List[Tensor] ( #47890 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47890
As titled. In order to fix issue when running `chunk_test`, `split_test`, `qobserver` , `sort in qunary` in jit mode, because the output of `chunk_op` is a list of tensors which can not be handled by the current `_consume_op`
Test Plan:
OSS:
python3 -m benchmark_all_test --iterations 1 --warmup_iterations 1 --use_jit
Reviewed By: mingzhe09088
Differential Revision: D24774105
fbshipit-source-id: 210a0345b8526ebf3c24f4d0794e20b2ff6cef3d
2020-11-12 23:29:40 -08:00
Ilia Cherniavskii
a97c7e2ef0
Profiler benchmark fix ( #47713 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47713
Fix the import and also always use internal Timer
Test Plan: python benchmarks/profiler_benchmark/profiler_bench.py
Reviewed By: dzhulgakov
Differential Revision: D24873991
Pulled By: ilia-cher
fbshipit-source-id: 1c3950d7d289a4fb5bd7043ba2d842a35c263eaa
2020-11-12 21:47:30 -08:00
{kind=link}