Summary:
Improve handling of mixed-type tensor operations.
This PR affects the arithmetic (add, sub, mul, and div) operators implemented via TensorIterator (so dense but not sparse tensor ops).
For these operators, we will now promote to reasonable types where possible, following the rules defined in https://github.com/pytorch/pytorch/issues/9515, and error in cases where the cast would require floating point -> integral or non-boolean to boolean downcasts.
The details of the promotion rules are described here:
https://github.com/nairbv/pytorch/blob/promote_types_strict/docs/source/tensor_attributes.rst
Some specific backwards incompatible examples:
* now `int_tensor * float` will result in a float tensor, whereas previously the floating point operand was first cast to an int. Previously `torch.tensor(10) * 1.9` => `tensor(10)` because the 1.9 was downcast to `1`. Now the result will be the more intuitive `tensor(19)`
* Now `int_tensor *= float` will error, since the floating point result of this operation can't be cast into the in-place integral type result.
See more examples/detail in the original issue (https://github.com/pytorch/pytorch/issues/9515), in the above linked tensor_attributes.rst doc, or in the test_type_promotion.py tests added in this PR:
https://github.com/nairbv/pytorch/blob/promote_types_strict/test/test_type_promotion.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22273
Reviewed By: gchanan
Differential Revision: D16582230
Pulled By: nairbv
fbshipit-source-id: 4029cca891908cdbf4253e4513c617bba7306cb3
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
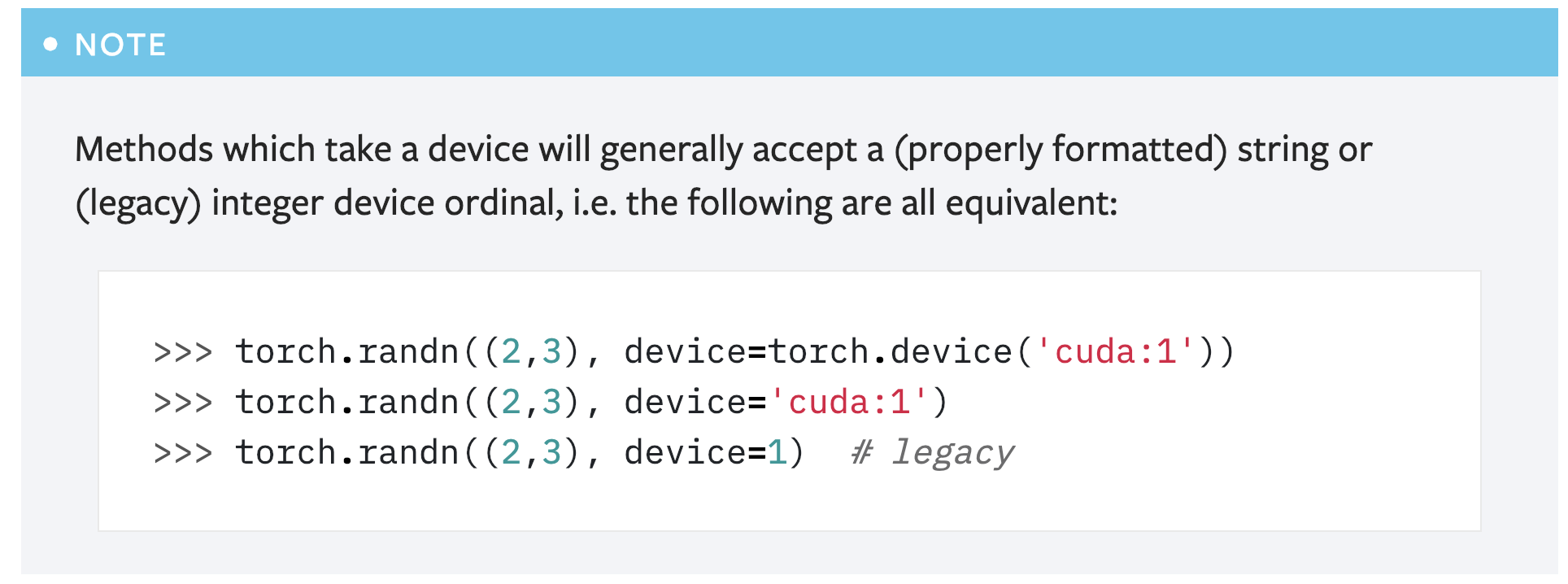
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
{kind=link}
{kind=link}