Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
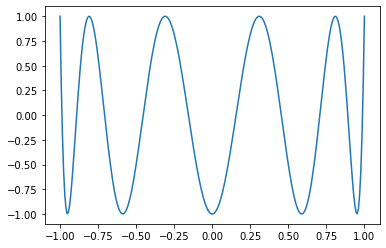
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
Change our representation of sizes and strides to contain SymInts
instead of int64_t.
Right now it's not actually possible to create a Tensor with symbolic
shape, so this change is intended to be a no-op.
But the intended behavior is:
- If you create a Tensor with symbolic shape, a `CustomSizes` policy
will be set, and the `has_symbolic_sizes_strides_` bit will be set. (not
currently implemented)
- Calling any TensorImpl function that naively interacts with sizes and
strides will throw. For hot-path functions (`sizes()`, `strides()`), we
make use of the existing policy check to throw. For others, we just have
a regular `TORCH_CHECK(!has_symbolic_sizes_strides_)`.
This also undoes the explicit constructor I made in
https://github.com/pytorch/pytorch/pull/77666; it ended up being more
annoying than useful when making these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78272
Approved by: https://github.com/Krovatkin, https://github.com/Chillee
Allows to choose the BLAS backend with Eigen. Previously this was a CMake option only and the env variable was ignored.
Related to f1f3c8b0fa
The claimed options BLAS=BLIS WITH_BLAS=blis are misleading: When BLAS=BLIS is set the WITH_BLAS option does not matter at all, it would only matter for BLAS=Eigen hence this issue went undetected so far.
Supersedes #59220
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78037
Approved by: https://github.com/adamjstewart, https://github.com/janeyx99
Euler beta function:
```Python
torch.special.beta(input, other, *, out=None) → Tensor
```
`reentrant_gamma` and `reentrant_ln_gamma` implementations (using Stirling’s approximation) are provided. I started working on this before I realized we were missing a gamma implementation (despite providing incomplete gamma implementations). Uses the coefficients computed by Steve Moshier to replicate SciPy’s implementation. Likewise, it mimics SciPy’s behavior (instead of the behavior in Cephes).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78031
Approved by: https://github.com/mruberry
Add codegen infrastructure to generate IR nodes for non-native ops.
The proposed change is to add a `non_native` key to the `{backend}_native_functions.yaml` file that contains schema definitions similar to what is found in `native_functions.yaml`. e.g.
```
non_native:
...
- func: expand(Tensor input, int[] size, bool is_scalar_expand) -> Tensor
...
```
these definitions are parsed into a `LazyIrSchema` that can be used for generating IR nodes using `GenLazyIR`.
Fixes#74628
CC: @wconstab @desertfire @henrytwo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76535
Approved by: https://github.com/wconstab
Change our representation of sizes and strides to contain SymInts
instead of int64_t.
Right now it's not actually possible to create a Tensor with symbolic
shape, so this change is intended to be a no-op.
But the intended behavior is:
- If you create a Tensor with symbolic shape, a `CustomSizes` policy
will be set, and the `has_symbolic_sizes_strides_` bit will be set. (not
currently implemented)
- Calling any TensorImpl function that naively interacts with sizes and
strides will throw. For hot-path functions (`sizes()`, `strides()`), we
make use of the existing policy check to throw. For others, we just have
a regular `TORCH_CHECK(!has_symbolic_sizes_strides_)`.
This also undoes the explicit constructor I made in
https://github.com/pytorch/pytorch/pull/77666; it ended up being more
annoying than useful when making these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77994
Approved by: https://github.com/Krovatkin
Double-header bug fix:
- As reported by jansel, dtypes are still showing up as integers
when the schema is an optional dtype. This is simple enough to
fix and I added a test for it. But while I was at it...
- I noticed that the THPMemoryFormat_new idiom with "unused" name
doesn't actually work, the repr of the returned memory format
object is wrong and this shows up when we try to log the args/kwargs.
So I fixed memory format to do it properly along with everything
else.
Fixes https://github.com/pytorch/pytorch/issues/77135
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77543
Approved by: https://github.com/albanD, https://github.com/jansel
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
Since clamp_min and maximum is the same op, reuse the same kernel (it also correctly propagate nans from both input and boundary, clamp* propagated from input only).
Also fixed codegen to make Tensor? overloads come before Scalar? overloads, cc @alband.
Fixes#67428 and #76795 (scalar overloads for clamp* are still not fixed, will do in the next PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77306
Approved by: https://github.com/albanD
Consider the following JIT graph, where the type of `%a` and `%b` are out of sync with tuple `%c`.
Before:
```
graph(%a : Float(123), %b : Float(4, 5, 6)):
c : (Tensor, Tensor) = prim::TupleConstruct(%a, %b)
return (%c)
```
After:
```
graph(%a : Float(123), %b : Float(4, 5, 6)):
c : (Float(123), Float(4, 5, 6)) = prim::TupleConstruct(%a, %b)
return (%c)
```
This PR adds a pass `RefineTypes(...)` to update all such instances with the correct type. This is also available via Python by using `torch._C._jit_pass_refine_types(...)`.
A unit test has been added for unnamed tuples, but no test exists for `NamedTuple` (though it was tested manually) since it isn't supported by the parser:
```
RuntimeError:
unknown type specifier:
graph(%a : Float(123), %b : Float(4, 5, 6)):
%c : NamedTuple(Tensor : Tuple, Tensor : Tuple) = prim::TupleConstruct(%a, %b)
~~~~~~~~~~ <--- HERE
return (%c)
```
cc: @ke1337 @antoniojkim @wconstab @eellison
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76919
Approved by: https://github.com/eellison
Adds the ability to grab the git tag when using
`generate_torch_version.py` so that users who build from source on a
specific tag will get the version that they expect.
Behavior is now this:
1. Check if git tag is available on current commit
2. If tag available use tagged version, do not attempt to grab other versions
3. If tag is not available, use previous workflow for determining version
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Fixes https://github.com/pytorch/pytorch/issues/77052
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77279
Approved by: https://github.com/ezyang
This is convenient for cases where we don't have Storage bound
correctly (e.g., meta tensors). It is also consistent with a universe
where we get rid of storages, although arguably this is never
gonna happen.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77007
Approved by: https://github.com/ngimel
Summary:
For some reason `aten/src/ATen/native/BatchLinearAlgebraKernel.cpp` were part of `aten_cpu_source_non_codegen_list` rather than `aten_native_source_non_codegen_list`
Fixes linking issues after https://github.com/pytorch/pytorch/pull/67833
```
stderr: ld.lld: error: undefined symbol: at::TensorIteratorBase::for_each(c10::function_ref<void (char**, long long const*, long long, long long)>, long long)
>>> referenced by TensorIterator.h:352 (buck-out/gen/fe3a39b8/xplat/caffe2/aten_headerAndroid#header-mode-symlink-tree-with-header-map,headers/ATen/TensorIterator.h:352)
>>> buck-out/gen/fe3a39b8/xplat/caffe2/aten_cpuAndroid#android-x86,compile-pic-BatchLinearAlgebraKernel.cpp.o93aa6b34/aten/src/ATen/native/BatchLinearAlgebraKernel.cpp.o:(at::native::(anonymous namespace)::unpack_pivots_cpu_kernel(at::TensorIterator&, long long))
clang: error: linker command failed with exit code 1 (use -v to see invocation)
When running <c++ link>.
When building rule //xplat/caffe2:aten_cpuAndroid#android-x86,shared (ovr_config//platform/android:fbsource-base)."
```
Test Plan: CI
Reviewed By: dreiss, cccclai
Differential Revision: D36215453
fbshipit-source-id: 5f9c7cab742bb87a70b5acda46ef85817e50575c
(cherry picked from commit a1691c34f6bae484f710ac9321bfd8a8c999189e)
grep_linter.py was using the `-P` flag of `grep`, which is available in
GNU grep but notably *not* available in the BSD grep that is installed
on Macs.
Use `-E` instead, which uses ERE instead of PCRE. Sadly we were actually
using two PCRE features in our linters:
- Negative lookaheads. I changed these to less-accurate-but-still-good-enough
versions that use `[^...]` expressions.
- Apparently ERE doesn't support the `\t` atom lol. So I used a literal tab
character instead (and then had to disable the TAB linter for
`.lintrunner.toml` lol.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76947
Approved by: https://github.com/ezyang
- Run attempt detection was broken because it was comparing a str
(retrieved from the CLI input) to an int (retrieved from the
filename). Make them both ints so they will actually compare equal.
- `root.findall` only searches direct children, which didn't work for cpp
unittests and pytest-generated reports. Change to `root.iter` which
does a recursive search.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76982
Approved by: https://github.com/janeyx99
Summary: Currently OpKind is stored as an object field called op_ for each IR
node, and one usage of op_ is to avoid dynamic_cast in NodeCast when we
need to downcast a base-node pointer into a concrete sub-node pointer.
As a result, we need to construct and pass in an op when downcasting
nodes, and this becomes quite anonnying when we start to implement the
trie-based IR node reusing. More importantly, the op for each subclass
should be unique for that subclass and thus making it a const static field
is a more logical design.
In this PR, we still keep the object-level op_ for easier XLA adoption. As
furture work, we can come back to remove op_, make the op() method
virtual, and get rid of OpKind in all the node constructors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76711
Approved by: https://github.com/wconstab, https://github.com/JackCaoG
This PR allows user to author a CUDA kernel in python.
```
from torch.cuda.jiterator import create_jit_fn
code_string = "template <typename T> T my_kernel(T x, T y, T alpha) { return -x * y + x - y + alpha; }"
jitted_fn = create_jit_fn(code_string, alpha=0)
a = torch.rand(3, device='cuda')
b = torch.rand(3, device='cuda')
result = jitted_fn(a, b, alpha=1.0)
```
Limitations:
- Only supports elementwise kernel
- 1~8 tensor inputs (empty input, e.g. factory methods, is not supported)
- inputs tensors must live in cuda device
- cpu Scalar is not supported
- kwargs must be pre-declared when calling create_jit_fn
- kwargs must be convertible to at::Scalar, one of float64, int64_t, bool. (complex not support for now)
TODOs:
- [x] consolidate union and c10::variant implementation
- [x] plug into existing op testing framework
- [ ] rename files, place files in the right folder
- [ ] place util functions in the right file
- [x] enforce assumptions in python interface e.g <8 inputs, kwargs types
- [x] Add user-facing documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76394
Approved by: https://github.com/mruberry
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72935
Approved by: https://github.com/IvanYashchuk, https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
We derive and implement a more concise rule for the forward and backward
derivatives of the QR decomposition. While doing this we:
- Fix the composite compliance of `linalg.qr` and we make it support batches
- Improve the performance and simplify the implementation of both foward and backward
- Avoid saving the input matrix for the backward computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76115
Approved by: https://github.com/nikitaved, https://github.com/albanD
Summary: TrieCache provides a way to look up an IR node before we
actually create it. If the lookup hits in TrieCache, we reuse the
existing node and move the current pointer in TrieCache to point to that
node; if the lookup misses, we create a new node and insert it into TrieCache.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76542
Approved by: https://github.com/wconstab, https://github.com/JackCaoG
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75800
This leads to more similarities between OSS CMake and eventually OSS
Bazel. We will be able to generate files with the same names and not
have different file lists between the builds.
ghstack-source-id: 155300043
Test Plan: Verified locally and in CI.
Reviewed By: dreiss
Differential Revision: D35648586
fbshipit-source-id: 9f1638b5665ebcc64466883f65ef24a2bfd05228
(cherry picked from commit 7f2acff1baa8dfafddefdc720714f8d39feda436)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76720
This PR fixes an issue in hipify_python introduced by https://github.com/pytorch/pytorch/pull/76141.
https://github.com/pytorch/pytorch/pull/76141 made all the `includes` paths "absolute", but this was not done for `args.extra_include_dir`; `new_dir`, which is a relative path, is directly added to `includes`. This PR fixes it by passing the absolute path (`abs_new_dir`).
Test Plan: CI
Reviewed By: albanD
Differential Revision: D36089556
fbshipit-source-id: 1607075a4cb13696c1b25923f56b08a8cb3c6578
(cherry picked from commit 2ca648728f01c03320015f90d33404e75f978206)
This functionality does not seem to be used
and there are some requests to update dependency.
Add `third_party` to torch_cpu include directories if compiling with
Caffe2 support, as `caffe2/quantization/server/conv_dnnlowp_op.cc` depends on `third_party/fbgemm/src/RefImplementations.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75394
Approved by: https://github.com/janeyx99, https://github.com/seemethere
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76173
We need this facility temporarily to sequence some changes without
breakage. This is generally not a good idea since the main purpose of
this effort is to replicate builds in OSS Bazel.
ghstack-source-id: 155215491
Test Plan: Manual test and rely on CI.
Reviewed By: dreiss
Differential Revision: D35815290
fbshipit-source-id: 89bacda373e7ba03d6a3fcbcaa5af42ae5eac154
(cherry picked from commit 1b808bbc94c939da1fd410d81b22d43bdfe1cda0)
{kind=link}
{kind=link}