momohatt
a23e8099dd
Fix typo ( #34008 )
...
Summary:
This PR removes apparently unnecessary dots in the documentation of `torch.t`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34008
Differential Revision: D20195084
Pulled By: ezyang
fbshipit-source-id: a34022de6b7a32d05a0bb3da197ee3507f4b8d8e
2020-03-03 07:38:40 -08:00
anjali411
13e4ee7883
Added tensor.is_complex(), is_complex and dtype.is_complex py binding, tensor printing, and dixed the scalar type returned for complex float ( #33268 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33268
Test Plan: Imported from OSS
Differential Revision: D19907698
Pulled By: anjali411
fbshipit-source-id: c3ce2e99fc09da91a90a8fb94e5525a00bb23703
2020-02-20 13:38:01 -08:00
Matthew Haines
1d9fcf8bd2
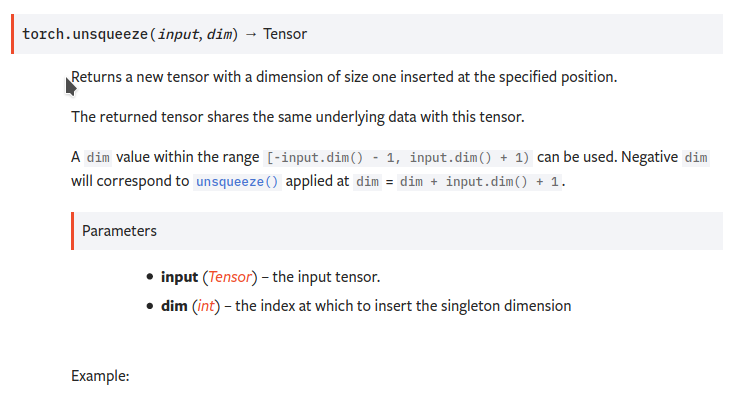
Correct documentation for torch.unsqueeze ( #33478 )
...
Summary:
"out" argument in torch.unsqueeze is not actually implemented, fixed documentation https://github.com/pytorch/pytorch/issues/29800
After: 
Before: 
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33478
Differential Revision: D19978477
Pulled By: yf225
fbshipit-source-id: 42337326c1ec04975307366c94591ee32a11b091
2020-02-19 14:01:06 -08:00
anjali411
a8bd1d24c9
[Documentation] cummin doc fix ( #33492 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33492
Differential Revision: D19976082
Pulled By: anjali411
fbshipit-source-id: c9f8f541783fded98b8aba54e293f824c926496e
2020-02-19 13:51:38 -08:00
anjali411
da015c77a1
Cummax and Cummin doc update and performance benchmark ( #32537 )
...
Summary:
[CPU] Benchmark results for cummax, cummin:
In [1]: import torch
In [2]: x=torch.randn(5,6,7).cuda()
In [3]: %timeit x.cummax(0)
134 µs ± 1.59 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [4]: %timeit x.max(0)
114 µs ± 560 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [5]: %timeit x.cummax(1)
134 µs ± 760 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [6]: %timeit x.max(1)
118 µs ± 514 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [7]: %timeit x.cumsum(0)
97.1 µs ± 6.93 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [8]: %timeit x.cumprod(0)
83.6 µs ± 689 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [9]: %timeit x.cumprod(1)
86.3 µs ± 528 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [10]: y=torch.randn(5,6,7)
In [11]: %timeit y.cummax(0)
148 µs ± 1.43 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [12]: %timeit y.max(0)
111 µs ± 125 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [13]: %timeit y.cumsum(0)
54.8 µs ± 311 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [14]: %timeit y.cumprod(0)
56.2 µs ± 836 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32537
Differential Revision: D19951171
Pulled By: anjali411
fbshipit-source-id: cf972c550189473e9ce62e24ac7dd34b9373fef9
2020-02-18 14:12:25 -08:00
Mike Ruberry
aa3c871739
Adds TestViewOps, updates documentation ( #32512 )
...
Summary:
Understanding which ops return views and which return tensors with new storage is a common user issue, and an issue for developers connecting accelerators to PyTorch, too. This generic test suite verifies that ops which should return views do (and a few ops that shouldn't don't). The documentation has also been updated for .t(), permute(), unfold(), and select() to clarify they return views.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32512
Differential Revision: D19659454
Pulled By: mruberry
fbshipit-source-id: b4334be9b698253a979e1bb8746fdb3ca24aa4e3
2020-02-04 11:10:34 -08:00
kngwyu
3fa907c145
[docs] Fix argument type of torch.masked_select ( #30385 )
...
Summary:
This should be `BoolTensor`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30385
Differential Revision: D19698414
Pulled By: ezyang
fbshipit-source-id: 68f1e10eb9d4b99552bb158f6ad7e6ff0f7cc1c4
2020-02-03 11:15:11 -08:00
Hong Xu
666e5430f8
Clean up mvlgamma doc (including a weird way to link to reference) ( #32667 )
...
Summary:
Intentionally left blank
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32667
Differential Revision: D19594683
Pulled By: ezyang
fbshipit-source-id: 5a6eb0a74f569d3c0db2a35e0ed4b329792a18e4
2020-01-27 20:12:17 -08:00
Stas Bekman
8abaa322da
fix torch.eq() doc entry ( #32399 )
...
Summary:
fix `torch.eq()` entry example to match the current output (boolean, instead of uint8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32399
Differential Revision: D19498104
Pulled By: ezyang
fbshipit-source-id: e7ec1263226766a5c549feed16d22f8f172aa1a3
2020-01-22 07:43:10 -08:00
anjali411
5b815d980e
Added cummin
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32238
Differential Revision: D19416791
Pulled By: anjali411
fbshipit-source-id: 5aadc0a7a55af40d76f444ab7d7d47ec822f55a5
2020-01-17 10:51:58 -08:00
anjali411
8dc67a014f
Add cummax
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32169
Differential Revision: D19393236
Pulled By: anjali411
fbshipit-source-id: 5dac6b0a4038eb48458d4a0b253418daeccbb6bc
2020-01-14 17:19:10 -08:00
Peter Bell
b0ac425dc4
Emit warning from deprecated torch function signatures ( #32009 )
...
Summary:
Continuation of https://github.com/pytorch/pytorch/issues/31514 , fixes https://github.com/pytorch/pytorch/issues/28430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32009
Test Plan:
I verified that the deprecation warnings only occur once on a relevant workflow. Built with:
```
buck build mode/opt //vision/fair/detectron2/tools:train_net
```
Ran with:
```
DETECTRON2_ENV_MODULE=detectron2.fb.env ~/local/train_net.par --config-file configs/quick_schedules/retinanet_R_50_FPN_instant_test.yaml --num-gpus 1 SOLVER.IMS_PER_BATCH 2
```
Inspected log:
```
[01/14 07:28:13 d2.engine.train_loop]: Starting training from iteration 0
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1299: UserWarning: This overload of add is deprecated:
add(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add(Tensor other, Number alpha)
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1334: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, Number alpha)
[01/14 07:28:25 d2.utils.events]: eta: 0:00:10 iter: 19 total_loss: 1.699 loss_cls: 1.185 loss_box_reg: 0.501 time: 0.5020 data_time: 0.0224 lr: 0.000100 max_mem: 3722M
[01/14 07:28:35 fvcore.common.checkpoint]: Saving checkpoint to ./output/model_final.pth
```
Differential Revision: D19373523
Pulled By: ezyang
fbshipit-source-id: 75756de129645501f43ecc4e3bf8cc0f78c40b90
2020-01-14 11:44:29 -08:00
vishwakftw
77c2c78e01
Fix typographical error in torch.triu docstring ( #32067 )
...
Summary:
below --> above
Fixes https://github.com/pytorch/pytorch/issues/32032
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32067
Differential Revision: D19355788
Pulled By: zou3519
fbshipit-source-id: dc7a2538a78cd11e72d47ad923ef50599a5a87e2
2020-01-13 07:21:33 -08:00
anjali411
638e4ad8b9
Updated function definition for torch.mode and torch.median in torch docs ( #32003 )
...
Summary:
Issue: https://github.com/pytorch/pytorch/issues/32002
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32003
Differential Revision: D19334306
Pulled By: anjali411
fbshipit-source-id: fe6a7cc7295b2d582a0b528f353ec64d9085e8c5
2020-01-10 13:13:54 -08:00
TH3CHARLie
1296e2d55e
C++ API parity: isinf ( #31099 )
...
Summary:
fixes https://github.com/pytorch/pytorch/issues/31021 , port the legacy binding method of `isinf` to C++ therefore support JIT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31099
Differential Revision: D19314733
Pulled By: yf225
fbshipit-source-id: 5725c51d19c33b4fddd0fc9e7034078580bd534e
2020-01-09 13:16:13 -08:00
xiaobing.zhang
9ba6a768de
Add op bitwise_or ( #31559 )
...
Summary:
ezyang , this PR add bitwise_or operator as https://github.com/pytorch/pytorch/pull/31104 .
Benchmark script :
```
import timeit
import torch
torch.manual_seed(1)
for n, t in [(10, 100000),(1000, 10000)]:
print('__or__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a | b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}")', number=t))
for n, t in [(10, 100000),(1000, 10000)]:
print('__ior__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a | b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.tensor(5, dtype = {dtype}, device="{device}")', number=t))
```
Device: **Tesla P100, skx-8180**
Cuda verison: **9.0.176**
Before:
```
__or__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.17616272252053022
device: cpu, dtype: torch.uint8, 100000 times 0.17148233391344547
device: cpu, dtype: torch.int16, 100000 times 0.17616403382271528
device: cpu, dtype: torch.int32, 100000 times 0.17717823758721352
device: cpu, dtype: torch.int64, 100000 times 0.1801931718364358
device: cuda, dtype: torch.int8, 100000 times 1.270583058707416
device: cuda, dtype: torch.uint8, 100000 times 1.2636413089931011
device: cuda, dtype: torch.int16, 100000 times 1.2839747751131654
device: cuda, dtype: torch.int32, 100000 times 1.2548385225236416
device: cuda, dtype: torch.int64, 100000 times 1.2650810535997152
__or__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.031136621721088886
device: cpu, dtype: torch.uint8, 10000 times 0.030786747112870216
device: cpu, dtype: torch.int16, 10000 times 0.02391665056347847
device: cpu, dtype: torch.int32, 10000 times 0.024147341027855873
device: cpu, dtype: torch.int64, 10000 times 0.024414129555225372
device: cuda, dtype: torch.int8, 10000 times 0.12741921469569206
device: cuda, dtype: torch.uint8, 10000 times 0.1249831635504961
device: cuda, dtype: torch.int16, 10000 times 0.1283819805830717
device: cuda, dtype: torch.int32, 10000 times 0.12591975275427103
device: cuda, dtype: torch.int64, 10000 times 0.12655890546739101
__ior__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.3908365070819855
device: cpu, dtype: torch.uint8, 100000 times 0.38267823681235313
device: cpu, dtype: torch.int16, 100000 times 0.38239253498613834
device: cpu, dtype: torch.int32, 100000 times 0.3817988149821758
device: cpu, dtype: torch.int64, 100000 times 0.3901665909215808
device: cuda, dtype: torch.int8, 100000 times 1.4211318120360374
device: cuda, dtype: torch.uint8, 100000 times 1.4215159295126796
device: cuda, dtype: torch.int16, 100000 times 1.4307750314474106
device: cuda, dtype: torch.int32, 100000 times 1.4123614141717553
device: cuda, dtype: torch.int64, 100000 times 1.4480243818834424
__ior__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.06468924414366484
device: cpu, dtype: torch.uint8, 10000 times 0.06442475505173206
device: cpu, dtype: torch.int16, 10000 times 0.05267547257244587
device: cpu, dtype: torch.int32, 10000 times 0.05286940559744835
device: cpu, dtype: torch.int64, 10000 times 0.06211103219538927
device: cuda, dtype: torch.int8, 10000 times 0.15332304500043392
device: cuda, dtype: torch.uint8, 10000 times 0.15353196952492
device: cuda, dtype: torch.int16, 10000 times 0.15300503931939602
device: cuda, dtype: torch.int32, 10000 times 0.15274472255259752
device: cuda, dtype: torch.int64, 10000 times 0.1512152962386608
```
After:
```
__or__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.2465507509186864
device: cpu, dtype: torch.uint8, 100000 times 0.2472386620938778
device: cpu, dtype: torch.int16, 100000 times 0.2469814233481884
device: cpu, dtype: torch.int32, 100000 times 0.2535214088857174
device: cpu, dtype: torch.int64, 100000 times 0.24855613708496094
device: cuda, dtype: torch.int8, 100000 times 1.4351346511393785
device: cuda, dtype: torch.uint8, 100000 times 1.4434308474883437
device: cuda, dtype: torch.int16, 100000 times 1.4520929995924234
device: cuda, dtype: torch.int32, 100000 times 1.4456610176712275
device: cuda, dtype: torch.int64, 100000 times 1.4580101007595658
__or__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.029985425993800163
device: cpu, dtype: torch.uint8, 10000 times 0.03024935908615589
device: cpu, dtype: torch.int16, 10000 times 0.026356655173003674
device: cpu, dtype: torch.int32, 10000 times 0.027377349324524403
device: cpu, dtype: torch.int64, 10000 times 0.029163731262087822
device: cuda, dtype: torch.int8, 10000 times 0.14540370367467403
device: cuda, dtype: torch.uint8, 10000 times 0.1456305105239153
device: cuda, dtype: torch.int16, 10000 times 0.1450125053524971
device: cuda, dtype: torch.int32, 10000 times 0.1472016740590334
device: cuda, dtype: torch.int64, 10000 times 0.14709716010838747
__ior__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.27195510920137167
device: cpu, dtype: torch.uint8, 100000 times 0.2692424338310957
device: cpu, dtype: torch.int16, 100000 times 0.27726674638688564
device: cpu, dtype: torch.int32, 100000 times 0.2815811652690172
device: cpu, dtype: torch.int64, 100000 times 0.2852728571742773
device: cuda, dtype: torch.int8, 100000 times 1.4743850827217102
device: cuda, dtype: torch.uint8, 100000 times 1.4766502184793353
device: cuda, dtype: torch.int16, 100000 times 1.4774163831025362
device: cuda, dtype: torch.int32, 100000 times 1.4749693805351853
device: cuda, dtype: torch.int64, 100000 times 1.5772947426885366
__ior__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.03614502027630806
device: cpu, dtype: torch.uint8, 10000 times 0.03619729354977608
device: cpu, dtype: torch.int16, 10000 times 0.0319912089034915
device: cpu, dtype: torch.int32, 10000 times 0.03319283854216337
device: cpu, dtype: torch.int64, 10000 times 0.0343862259760499
device: cuda, dtype: torch.int8, 10000 times 0.1581476852297783
device: cuda, dtype: torch.uint8, 10000 times 0.15974601730704308
device: cuda, dtype: torch.int16, 10000 times 0.15957212820649147
device: cuda, dtype: torch.int32, 10000 times 0.16002820804715157
device: cuda, dtype: torch.int64, 10000 times 0.16129320487380028
```
Fix https://github.com/pytorch/pytorch/issues/24511 , https://github.com/pytorch/pytorch/issues/24515 , https://github.com/pytorch/pytorch/issues/24658 , https://github.com/pytorch/pytorch/issues/24662 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31559
Differential Revision: D19315875
Pulled By: ezyang
fbshipit-source-id: 4a3ca88fdafbeb796079687e676228111eb44aad
2020-01-08 15:06:30 -08:00
Edward Yang
5dfcfeebb8
Revert D19298735: Emit warning from deprecated torch function signatures
...
Test Plan: revert-hammer
Differential Revision:
D19298735
Original commit changeset: 03cb78af1765
fbshipit-source-id: 304a6d4412f53a8fc822d36897c96815432e0f70
2020-01-08 13:04:41 -08:00
Peter Bell
0e5a6700cc
Emit warning from deprecated torch function signatures ( #31514 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28430
The unpythonic signatures for functions such as `torch.addcdiv` are already seperated in [`deprecated.yaml`] and the signatures marked as deprecated in `PythonArgParser`. However, nothing was done with this information previously. So, this now emits a warning when the deprecated signatures are used.
One minor complication is that if all arguments are passed as keyword args then there is nothing to differentiate the deprecated overload. This can lead to false warnings being emitted. So, I've also modified `PythonArgParser` to prefer non-deprecated signatures.
[`deprecated.yaml`]: https://github.com/pytorch/pytorch/blob/master/tools/autograd/deprecated.yaml
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31514
Differential Revision: D19298735
Pulled By: ezyang
fbshipit-source-id: 03cb78af17658eaab9d577cd2497c6f413f07647
2020-01-07 10:57:53 -08:00
xiaobing.zhang
b47e9b97a2
Add op bitwise_and ( #31104 )
...
Summary:
Refer to https://github.com/pytorch/pytorch/pull/25665 , add `bitwise_and` operator.
Benchmark script :
```
import timeit
#for __and__
for n, t in [(10, 100000),(1000, 10000)]:
print('__and__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a & b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}")', number=t))
#for __iand__
for n, t in [(10, 100000),(1000, 10000)]:
print('__iand__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a & b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.tensor(5, dtype = {dtype}, device="{device}")', number=t))
```
Device: **Tesla P100, skx-8180**
Cuda verison: **9.0.176**
Before:
```
__and__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.1766007635742426
device: cpu, dtype: torch.uint8, 100000 times 0.17322628945112228
device: cpu, dtype: torch.int16, 100000 times 0.17650844901800156
device: cpu, dtype: torch.int32, 100000 times 0.17711848113685846
device: cpu, dtype: torch.int64, 100000 times 0.18240160401910543
device: cuda, dtype: torch.int8, 100000 times 1.273967768996954
device: cuda, dtype: torch.uint8, 100000 times 1.2778537990525365
device: cuda, dtype: torch.int16, 100000 times 1.2753686187788844
device: cuda, dtype: torch.int32, 100000 times 1.2797665279358625
device: cuda, dtype: torch.int64, 100000 times 1.2933144550770521
__and__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.031139614060521126
device: cpu, dtype: torch.uint8, 10000 times 0.03091452084481716
device: cpu, dtype: torch.int16, 10000 times 0.022756479680538177
device: cpu, dtype: torch.int32, 10000 times 0.025045674294233322
device: cpu, dtype: torch.int64, 10000 times 0.024164282716810703
device: cuda, dtype: torch.int8, 10000 times 0.12820732593536377
device: cuda, dtype: torch.uint8, 10000 times 0.12775669433176517
device: cuda, dtype: torch.int16, 10000 times 0.12697868794202805
device: cuda, dtype: torch.int32, 10000 times 0.12832533661276102
device: cuda, dtype: torch.int64, 10000 times 0.1280576130375266
__iand__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.3687064303085208
device: cpu, dtype: torch.uint8, 100000 times 0.36253443732857704
device: cpu, dtype: torch.int16, 100000 times 0.362891579978168
device: cpu, dtype: torch.int32, 100000 times 0.37680106051266193
device: cpu, dtype: torch.int64, 100000 times 0.3689364707097411
device: cuda, dtype: torch.int8, 100000 times 1.419940729625523
device: cuda, dtype: torch.uint8, 100000 times 1.4247053815051913
device: cuda, dtype: torch.int16, 100000 times 1.4191444097086787
device: cuda, dtype: torch.int32, 100000 times 1.4305962566286325
device: cuda, dtype: torch.int64, 100000 times 1.4567416654899716
__iand__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.06224383972585201
device: cpu, dtype: torch.uint8, 10000 times 0.06205617543309927
device: cpu, dtype: torch.int16, 10000 times 0.05016433447599411
device: cpu, dtype: torch.int32, 10000 times 0.05216377507895231
device: cpu, dtype: torch.int64, 10000 times 0.06139362137764692
device: cuda, dtype: torch.int8, 10000 times 0.14827249851077795
device: cuda, dtype: torch.uint8, 10000 times 0.14801877550780773
device: cuda, dtype: torch.int16, 10000 times 0.14952312968671322
device: cuda, dtype: torch.int32, 10000 times 0.14999118447303772
device: cuda, dtype: torch.int64, 10000 times 0.14951884001493454
```
After:
```
__and__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.23157884553074837
device: cpu, dtype: torch.uint8, 100000 times 0.23063660878688097
device: cpu, dtype: torch.int16, 100000 times 0.23005440644919872
device: cpu, dtype: torch.int32, 100000 times 0.23748818412423134
device: cpu, dtype: torch.int64, 100000 times 0.24106105230748653
device: cuda, dtype: torch.int8, 100000 times 1.4394256137311459
device: cuda, dtype: torch.uint8, 100000 times 1.4436759827658534
device: cuda, dtype: torch.int16, 100000 times 1.4631587155163288
device: cuda, dtype: torch.int32, 100000 times 1.459101552143693
device: cuda, dtype: torch.int64, 100000 times 1.4784048134461045
__and__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.028442862443625927
device: cpu, dtype: torch.uint8, 10000 times 0.028130197897553444
device: cpu, dtype: torch.int16, 10000 times 0.025318274274468422
device: cpu, dtype: torch.int32, 10000 times 0.02519288007169962
device: cpu, dtype: torch.int64, 10000 times 0.028299466706812382
device: cuda, dtype: torch.int8, 10000 times 0.14342594426125288
device: cuda, dtype: torch.uint8, 10000 times 0.145280827768147
device: cuda, dtype: torch.int16, 10000 times 0.14673697855323553
device: cuda, dtype: torch.int32, 10000 times 0.14499565307050943
device: cuda, dtype: torch.int64, 10000 times 0.14582364354282618
__iand__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.25548241566866636
device: cpu, dtype: torch.uint8, 100000 times 0.2552562616765499
device: cpu, dtype: torch.int16, 100000 times 0.25905191246420145
device: cpu, dtype: torch.int32, 100000 times 0.26635489892214537
device: cpu, dtype: torch.int64, 100000 times 0.26269810926169157
device: cuda, dtype: torch.int8, 100000 times 1.485458506271243
device: cuda, dtype: torch.uint8, 100000 times 1.4742380809038877
device: cuda, dtype: torch.int16, 100000 times 1.507783885113895
device: cuda, dtype: torch.int32, 100000 times 1.4926990242674947
device: cuda, dtype: torch.int64, 100000 times 1.519851053133607
__iand__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.03425929415971041
device: cpu, dtype: torch.uint8, 10000 times 0.03293587639927864
device: cpu, dtype: torch.int16, 10000 times 0.029559112153947353
device: cpu, dtype: torch.int32, 10000 times 0.030915481969714165
device: cpu, dtype: torch.int64, 10000 times 0.03292469773441553
device: cuda, dtype: torch.int8, 10000 times 0.15792148280888796
device: cuda, dtype: torch.uint8, 10000 times 0.16000914946198463
device: cuda, dtype: torch.int16, 10000 times 0.1600684942677617
device: cuda, dtype: torch.int32, 10000 times 0.16162546630948782
device: cuda, dtype: torch.int64, 10000 times 0.1629159888252616
```
Fix https://github.com/pytorch/pytorch/issues/24508 , https://github.com/pytorch/pytorch/issues/24509 , https://github.com/pytorch/pytorch/issues/24655 , https://github.com/pytorch/pytorch/issues/24656 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31104
Differential Revision: D18938930
Pulled By: VitalyFedyunin
fbshipit-source-id: a77e805a0b84e8ace16c6e648c2f67dad44f2e44
2020-01-03 10:32:36 -08:00
Tongzhou Wang
f56c59ead6
clarify when to use as_tuple in torch.nonzero
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31798
Differential Revision: D19272332
Pulled By: zou3519
fbshipit-source-id: 954d086a7b9f1a719e0dac303a4253bf7ec8e9f4
2020-01-03 07:43:35 -08:00
vishwakftw
22d84204f7
Expose torch.poisson in documentation ( #31667 )
...
Summary:
Changelog:
- Add doc string for torch.poisson briefing current behavior
- Check for non-positive entries in the tensor passed as input to torch.poisson
Closes https://github.com/pytorch/pytorch/issues/31646
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31667
Differential Revision: D19247371
Pulled By: ngimel
fbshipit-source-id: b53d105e73bf59a45beeb566f47365c3eb74efca
2019-12-28 21:32:26 -08:00
WANG
3b7916fccd
Modify the order of arguments position of torch.std and torch.std_mean in doc ( #31677 )
...
Summary:
Change log:
- [x] Change the order of arguments position of torch.std and torch.std_mean in doc.
- [x] Correct a spelling mistake of torch.std_mean in doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31677
Differential Revision: D19247372
Pulled By: ngimel
fbshipit-source-id: 8685f5207c39be524cdc81250430beac9d75f330
2019-12-28 20:36:26 -08:00
nikitaved
0414463007
doc fix for max method: a warning about different behaviour on CPU and GPU ( #31115 )
...
Summary:
Fixes [30708](https://github.com/pytorch/pytorch/issues/30708 ),
Adds warning regarding different behaviour of the method depending on device type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31115
Differential Revision: D18937365
Pulled By: zou3519
fbshipit-source-id: 7c731dd80f8b371de08d7fdfcc2196be15a593e1
2019-12-11 16:02:33 -08:00
TH3CHARLie
5edfe9cb80
add torch.square ( #30719 )
...
Summary:
fixes https://github.com/pytorch/pytorch/issues/30524
This adds an new operator `torch.square` to PyTorch
I think it is ready for the first-time review now albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30719
Differential Revision: D18909268
Pulled By: albanD
fbshipit-source-id: 5626c445d8db20471a56fc1d7a3490e77812662b
2019-12-10 15:22:46 -08:00
Hong Xu
394d2f7037
Fix the rendering of the doc of max. ( #30779 )
...
Summary:
Close https://github.com/pytorch/pytorch/issues/30731
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30779
Differential Revision: D18837317
Pulled By: zou3519
fbshipit-source-id: b9b5ba414756a68d4b39a7a7c2d89fee1e3c040f
2019-12-10 10:48:16 -08:00
Elias Ellison
f48a8901c5
Add floor_divide function ( #30493 )
...
Summary:
Adds `torch.floor_divide` following the numpy's `floor_divide` api. I only implemented the out-of-place version, I can add the inplace version if requested.
Also fixes https://github.com/pytorch/pytorch/issues/27512
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30493
Differential Revision: D18896211
Pulled By: eellison
fbshipit-source-id: ee401c96ab23a62fc114ed3bb9791b8ec150ecbd
2019-12-10 07:51:39 -08:00
Michael Suo
62b10721fb
Actually make flake8 do something ( #30892 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30892
Fixes all outstanding lints and actually installs a properly configured
flake8
Test Plan: Imported from OSS
Differential Revision: D18862825
Pulled By: suo
fbshipit-source-id: 08e9083338a7309272e17bb803feaa42e348aa85
2019-12-06 17:50:50 -08:00
Tongzhou Wang
a68b790293
fix ref to nonexistent torch.repeat
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30614
Differential Revision: D18808517
Pulled By: ezyang
fbshipit-source-id: 27f9bda6fbbd1c3c751a0e96fdc336bf724c0b31
2019-12-04 07:27:01 -08:00
Tongzhou Wang
ec7bb9de1c
format tri[lu]_indices doc better
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30377
Differential Revision: D18689152
Pulled By: zou3519
fbshipit-source-id: 7fab1e39ecd39ef6a3869befcbe217f8d3b6a87e
2019-12-04 07:16:34 -08:00
Hong Xu
bb5dcaf24f
Add logical_and and logical_or ( #30521 )
...
Summary:
With the CI failure caused in 8bbafa0b32https://github.com/pytorch/pytorch/pull/30521
Differential Revision: D18770151
Pulled By: ailzhang
fbshipit-source-id: 02f0fe1d5718c34d24da6dbb5884ee8b247ce39a
2019-12-03 18:24:54 -08:00
Brian Wignall
e7fe64f6a6
Fix typos ( #30606 )
...
Summary:
Should be non-semantic.
Uses https://en.wikipedia.org/wiki/Wikipedia:Lists_of_common_misspellings/For_machines to find likely typos.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30606
Differential Revision: D18763028
Pulled By: mrshenli
fbshipit-source-id: 896515a2156d062653408852e6c04b429fc5955c
2019-12-02 20:17:42 -08:00
Richard Zou
ec5c08de74
Revert D18580867: Add logical_and and logical_or
...
Test Plan: revert-hammer
Differential Revision:
D18580867
Original commit changeset: 7e4d7c37da4d
fbshipit-source-id: 81fb604c7aef8d847f518f5faa016e7bd0423016
2019-11-27 09:27:00 -08:00
Hong Xu
8bbafa0b32
Add logical_and and logical_or ( #28162 )
...
Summary:
Superseding https://github.com/pytorch/pytorch/issues/24379 as type promotion has been implemented.
Close https://github.com/pytorch/pytorch/issues/24379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28162
Differential Revision: D18580867
Pulled By: ailzhang
fbshipit-source-id: 7e4d7c37da4dc8df87314bd4f1f6a7539e46586a
2019-11-26 17:38:22 -08:00
vishwakftw
dcd9f49809
Specify ordering on singular values and eigenvalues output from torch… ( #30389 )
...
Summary:
….svd/symeig respectively
Changelog:
- Adds a note to docstrings of the both functions specifying the ordering
Fixes https://github.com/pytorch/pytorch/issues/30301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30389
Differential Revision: D18707608
Pulled By: zou3519
fbshipit-source-id: b0f73631578f39a24fae9af4997c6491de8be9a8
2019-11-26 10:23:47 -08:00
Zhang Zhi
ab2ec4d835
Fix inexistent parameter in document ( #24335 )
...
Summary:
There is no `out` argument to `argsort` according to the source code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24335
Differential Revision: D16829134
Pulled By: vincentqb
fbshipit-source-id: 8f91154984cd4a753ba1d6105fb8a9bfa0da22b3
2019-11-26 06:53:17 -08:00
Pavel Belevich
cc81769e10
C++ API parity: isfinite
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30083
Test Plan: Imported from OSS
Differential Revision: D18594723
Pulled By: pbelevich
fbshipit-source-id: 5970e0aa6ef8994e9c4a741784fd053383aaceb7
2019-11-19 20:00:05 -08:00
Will Feng
3bd0f476d4
Revert D18233037: C++ API parity: isfinite
...
Test Plan: revert-hammer
Differential Revision:
D18233037
Original commit changeset: c76b9467bbc1
fbshipit-source-id: 97d2cfa9de767a8c3a0ca919f9d768e959fa484e
2019-11-18 20:26:19 -08:00
Pavel Belevich
8df5e10ee9
C++ API parity: isfinite
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/28918
Test Plan: Imported from OSS
Differential Revision: D18233037
Pulled By: pbelevich
fbshipit-source-id: c76b9467bbc1fbb2c9bf49855895c98438b36c12
2019-11-18 19:06:57 -08:00
SsnL
38340f59fd
randint accept generator=None ( #29748 )
...
Summary:
This PR fixes the inconsistent behavior of `randint`'s `generator=` kwarg. It does not accept `None`, which is inconsistent with how other random functions behave:
```
In [12]: torch.randint(0, 4, size=(2,3), generator=torch.Generator())
Out[12]:
tensor([[2, 0, 1],
[0, 1, 3]])
In [13]: torch.randint(0, 4, size=(2,3), generator=None)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-a6bc6525a1e1> in <module>
----> 1 torch.randint(0, 4, size=(2,3), generator=None)
TypeError: randint() received an invalid combination of arguments - got (int, int, generator=NoneType, size=tuple), but expected one of:
* (int high, tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (int high, tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (int low, int high, tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (int low, int high, tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Other random functions work fine:
```
In [9]: torch.bernoulli(torch.ones(3))
Out[9]: tensor([1., 1., 1.])
In [10]: torch.bernoulli(torch.ones(3), generator=None)
Out[10]: tensor([1., 1., 1.])
```
This PR also documents the `generator=` kwarg, and fixes https://github.com/pytorch/pytorch/issues/29683 since it's a related easy fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29748
Differential Revision: D18529951
Pulled By: ezyang
fbshipit-source-id: e956cc989decc94e9483fd4a30f9255240d7c07e
2019-11-18 08:07:29 -08:00
Hong Xu
bd0394d473
Add op bitwise_xor to replace __xor__ and __ixor__ ( #25665 )
...
Summary:
We define `bitwise_xor` instead of
`__xor__` and `__ixor__`. The reason is that (a) it is not idiomatic to call
functions starting and ending with double underscores, and that (b) the
types of argument that we can add is limited (e.g., no out), and that (c) consistent with the naming of `bitwise_not` and numpy.
Fix https://github.com/pytorch/pytorch/issues/24513 , Fix https://github.com/pytorch/pytorch/issues/24517 , Fix https://github.com/pytorch/pytorch/issues/24660 , Fix https://github.com/pytorch/pytorch/issues/24664
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25665
Differential Revision: D17577143
Pulled By: VitalyFedyunin
fbshipit-source-id: 042f6385f9305bd66d50a8ce82e28f40a23a7266
2019-11-12 16:14:04 -08:00
Alban Desmaison
1dcf1b8938
Update pinverse doc for recent commit
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/28877
Differential Revision: D18225510
Pulled By: albanD
fbshipit-source-id: 698af06ac9e4259eed93d146edb3a7fb13e39242
2019-10-31 07:36:35 -07:00
Dylan Bespalko
f8b758b141
CPU-Strided-Complex Support for reduce ops and linpack ops ( #27653 )
...
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex )
Changes so far:
- [x] Renamed references to variable "I" that may be confused for "I" defined in complex.h. I did this to avoid crazy CI failures messages as complex.h is included by more source files.
- aten/src/ATen/native/cpu/Loops.h (Renamed I to INDEX)
- aten/src/ATen/native/cuda/Loops.cuh (Renamed I to INDEX)
- aten/src/ATen/core/ivalue_inl.h (Renamed I to INDEX)
- c10/util/Array.h (Renamed I to INDEX)
- c10/util/C++17.h (Renamed I to INDEX)
- c10/util/Metaprogramming.h (Renamed I to INDEX)
- c10/util/SmallVector.h (custom renaming)
- [x] Added complex support of Linear Algebra Ops.
- SVD needed to be modified to support mixed data types
- Example U(std::complex<double)), S(double), V(std::complex<double>)
- See before and after benchmark below (No observable change in performance).
- [x] Added complex support of Reduce Ops.
- var/std computations could have been faster if it was possible to interpret std::complex<double> Tensor as a double Tensor.
- [x] Added complex derivative support for autograd functionality.
- derivatives are the same as defined by numpy autograd library for real(), imag(), conj(), angle(). These functions only affect complex numbers.
- derivative of abs() has not been modified to not interfere with existing code.
- Autograd defines abs() for complex numbers and fabs() for real numbers. I will look into this further down the road.
----------------------------------------
PyTorch/Caffe2 Operator Micro-benchmarks Before Changes
----------------------------------------
Tag : short
Benchmarking PyTorch: svd
Mode: Eager
Name: svd_M512_N512
Input: M: 512, N: 512
Forward Execution Time (us) : 162339.425
Forward Execution Time (us) : 162517.479
Forward Execution Time (us) : 162847.775
----------------------------------------
PyTorch/Caffe2 Operator Micro-benchmarks After Changes
----------------------------------------
Tag : short
Benchmarking PyTorch: svd
Mode: Eager
Name: svd_M512_N512
Input: M: 512, N: 512
Forward Execution Time (us) : 162032.117
Forward Execution Time (us) : 161943.484
Forward Execution Time (us) : 162513.786
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27653
Differential Revision: D17907886
Pulled By: ezyang
fbshipit-source-id: a88b6d0427591ec1fba09e97c880f535c5d0e513
2019-10-24 09:31:06 -07:00
Nathan Goldbaum
139fec2d14
remove type information from docstrings of quantization functions ( #28556 )
...
Summary:
Following from https://github.com/pytorch/pytorch/issues/28479 let's remove the type information from the docstrings of these functions as well, making them valid python signatures matching the other signatures in the docstrings for the torch API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28556
Differential Revision: D18115641
Pulled By: ezyang
fbshipit-source-id: e4c3d56981b16f5acabe8be7bfbe6ae506972d7f
2019-10-24 08:13:48 -07:00
vishwakftw
657430e1f0
Return 0-numel empty tensor from symeig when eigenvectors=False ( #28338 )
...
Summary:
Changelog:
- Changes the behavior of returning a zero tensor when eigenvectors=False, matching behavior of torch.eig
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28338
Test Plan: - test_symeig has been modified appropriately for this change
Differential Revision: D18085280
Pulled By: ezyang
fbshipit-source-id: 43129a96dd01743997157974100e5a7270742b46
2019-10-23 11:44:57 -07:00
Nathan Goldbaum
9d767db493
remove extraneous type information from torch.matrix_rank documentation ( #28479 )
...
Summary:
The types don't appear in the docstrings for other functions in the `torch` namespace so I think this was included here because of a copy/paste error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28479
Differential Revision: D18086150
Pulled By: ezyang
fbshipit-source-id: 2481bccba6df36b12779a330f8c43d4aea68495f
2019-10-23 11:08:30 -07:00
Igor Fedan
12dde7f58a
cdist performance improvement for euclidean distance ( #25799 )
...
Summary:
jacobrgardner https://github.com/pytorch/pytorch/issues/15253#issuecomment-491467128 preposed a way to speedup euclidean distance calculation. This PR is implementation of this solution for normal and batch version.
Also simonepri provided performance metrics https://github.com/pytorch/pytorch/issues/15253#issuecomment-502363581
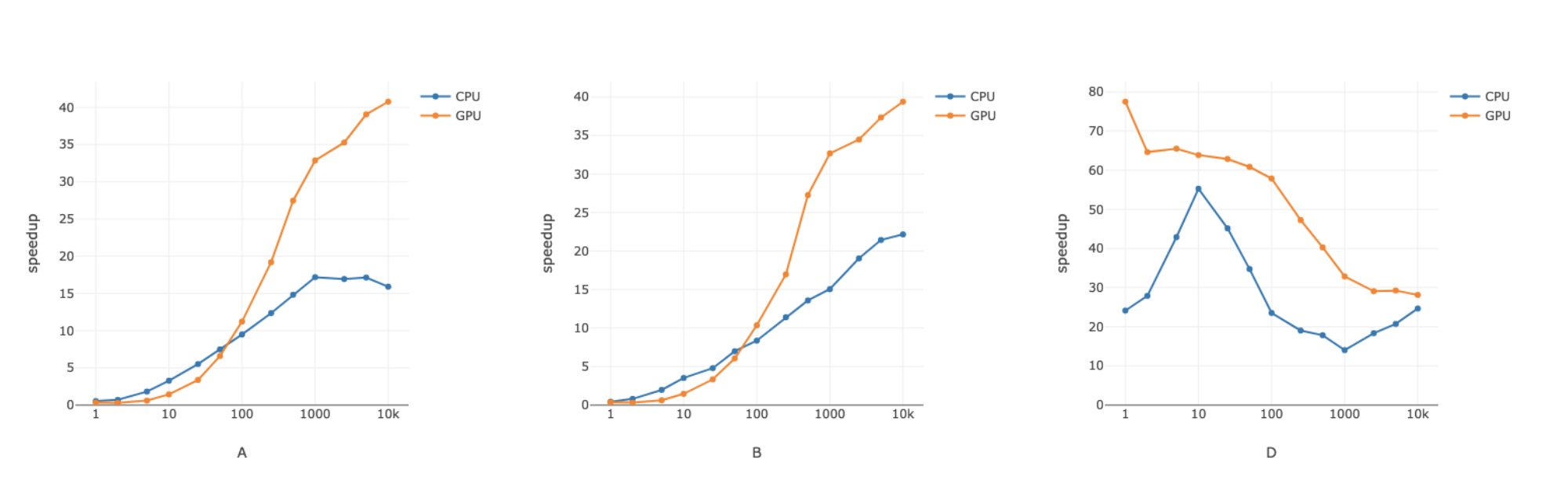
Current implementation has speedup comparing to jacobrgardner approach
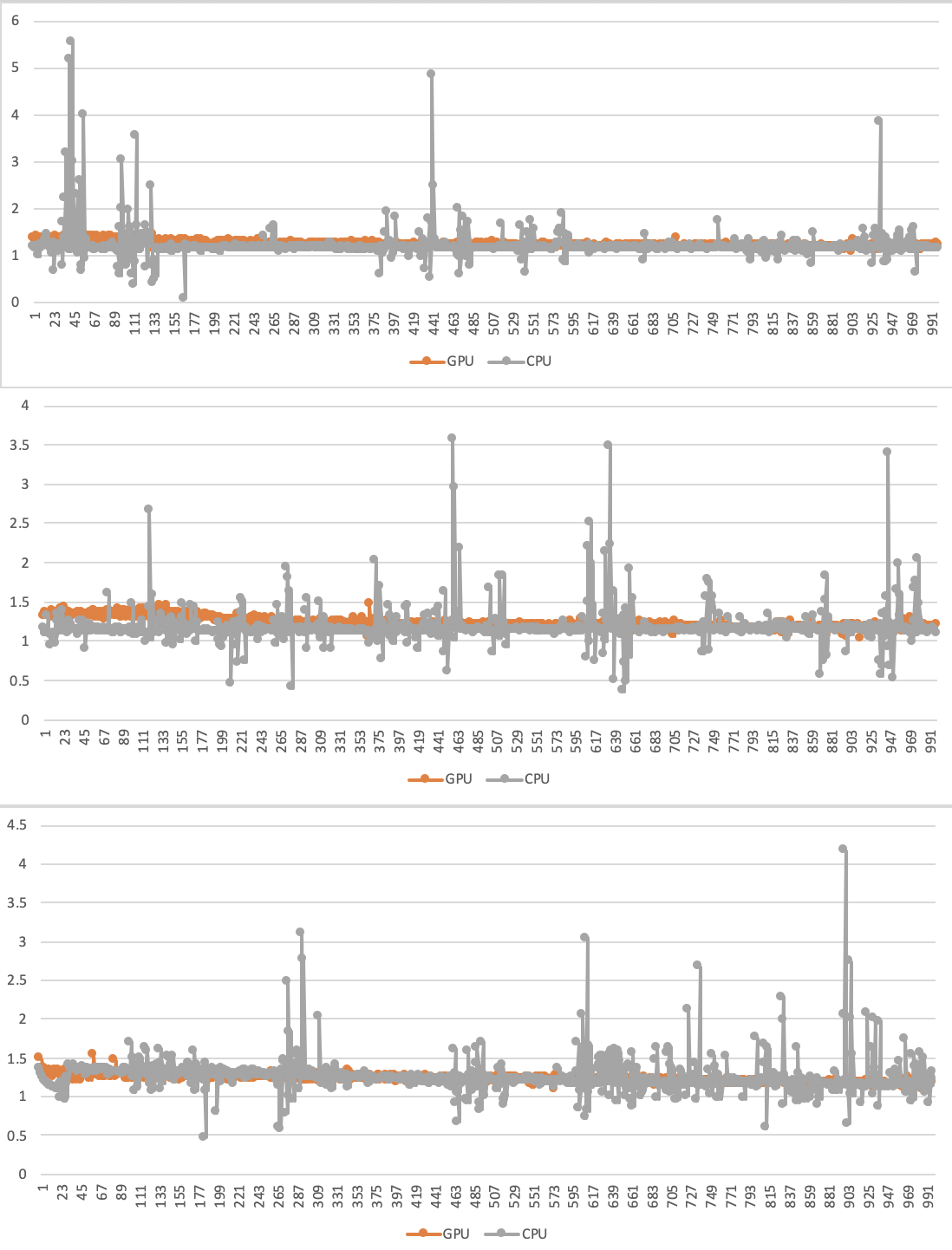
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25799
Differential Revision: D17964982
Pulled By: ifedan
fbshipit-source-id: bf7bd0dbfca51fd39e667da55139347480f30a2f
2019-10-17 14:56:54 -07:00
Hong Xu
cbb4c87d43
Improve the doc and test of logical_xor ( #28031 )
...
Summary:
Following up https://github.com/pytorch/pytorch/issues/27248 . per suggestion by gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28031
Differential Revision: D17962226
Pulled By: gchanan
fbshipit-source-id: 788e4e1fc78b1cfc7915aedaa10c8656b19edc4d
2019-10-16 13:57:53 -07:00
Hong Xu
e6a71405a0
Let logical_xor support non-bool tensors (again) ( #27248 )
...
Summary:
f362a5a04b5ca612b55ehttps://github.com/pytorch/pytorch/issues/25254 ). Now we come back to this by reusing the underlying code in
comparison operators: Logical operators on non-bool variables are
essentially comparison operators that semantically output bool
values. Compared with the previous implementation, we compromise by
always applying XOR on the same input type, while output can be either
the input type or the bool type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27248
Differential Revision: D17929356
Pulled By: ezyang
fbshipit-source-id: dbac08c7614b36f05d24c69104fee9df9ca523d5
2019-10-15 10:56:32 -07:00
vishwakftw
ad47788647
Add Polygamma to the docs ( #27696 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25347
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27696
Differential Revision: D17916790
Pulled By: ezyang
fbshipit-source-id: ac2635a300b1ef0ab437e3ffac152239754fe828
2019-10-15 07:00:57 -07:00
vishwakftw
82a69a690f
Add documentation for torch.lgamma ( #27812 )
...
Summary:
Changelog:
- Add doc string in _torch_docs.py, _tensor_docs.py
- Expose in docs/source/torch.rst, docs/source/tensors.rst
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27812
Test Plan:
- Remove `lgamma`, `lgamma_` from the blacklist
Fixes https://github.com/pytorch/pytorch/issues/27783
Differential Revision: D17907630
Pulled By: ezyang
fbshipit-source-id: 14e662a4e5262126889a437e5c4bfb21936730e8
2019-10-14 08:47:04 -07:00
{kind=link}
{kind=link}
{kind=link}
{kind=link}