This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
Previously when we recorded a free action in a memory trace, we would provide
the stack for when the block was allocated. This is faster because we do not
have to record stacks for free, which would otherwise double the number of stacks
collected. However, sometimes knowing the location of a free is useful for
figuring out why a tensor was live. So this PR adds this behavior. If
performance ends up being a concern the old behavior is possible by passing
"alloc" to the context argument rather than "all".
Also refactors some of glue logic to be consistent across C++ and Python and
routes the Python API through the C++ version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106758
Approved by: https://github.com/albanD
This PR:
- adds a capturable API for NAdam similar to Adam(W)
- adds tests accordingly
- discovered and fixed bugs in the differentiable implementation (now tested through the capturable codepath).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106615
Approved by: https://github.com/albanD
We want to display the stack for the original cudaMalloc that created a segment.
Previously we could only report the last time the segment memory was used,
or the record of the segment_alloc could appear in the list of allocator actions.
This PR ensure regardless of whether we still have the segment_alloc action,
the context for a segment is still available. The visualizer is updated to
be able to incorporate this information.
This PR adds a new field to Block. However the previous stacked cleanup PR
removed a field of the same size, making the change to Block size-neutral.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106113
Approved by: https://github.com/aaronenyeshi
For free blocks of memory in the allocator, we previously kept a linked list
of the stack frames of previous allocations that lived there. This was only
ever used in one flamegraph visualization and never proved useful at
understanding what was going on. When memory history tracing was added, it
became redundant, since we can see the history of the free space from recording
the previous actions anyway.
This patch removes this functionality and simplifies the snapshot format:
allocated blocks directly have a 'frames' attribute rather than burying stack frames in the history.
Previously the memory history tracked the real size of allocations before rounding.
Since history was added, 'requested_size' has been added directly to the block which records the same information,
so this patch also removes that redundancy.
None of this functionality has been part of a PyTorch release with BC guarentees, so it should be safe to alter
this part of the format.
This patch also updates our visualization tools to work with the simplified format. Visualization tools keep
support for the old format in `_legacy` functions so that during the transition old snapshot files can still be read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106079
Approved by: https://github.com/eellison
Mostly refactor, that moves all the tests from `test_cuda` that benefit from multiGPU environment into its own file.
- Add `TestCudaMallocAsync` class for Async tests ( to separate them from `TestCudaComm`)
- Move individual tests from `TestCuda` to `TestCudaMultiGPU`
- Move `_create_scaling_models_optimizers` and `_create_scaling_case` to `torch.testing._internal.common_cuda`
- Add newly created `test_cuda_multigpu` to the multigpu periodic test
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at f4d46fa</samp>
This pull request fixes a flaky test and improves the testing of gradient scaling on multiple GPUs. It adds verbose output for two CUDA tests, and refactors some common code into helper functions in `torch/testing/_internal/common_cuda.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104059
Approved by: https://github.com/huydhn
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulation of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Reland to make windows skip the test.
This reverts commit 7b3b6dd426.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104051
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulatin of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102656
Approved by: https://github.com/aaronenyeshi
This replaces the invidual visualization routines in _memory_viz.py with
a single javascript application.
The javascript application can load pickled snapshot dumps directly using
drag/drop, requesting them via fetch, or by embedding them in a webpage.
The _memory_viz.py commands use the embedding approach.
We can also host MemoryViz.js on a webpage to use the drag/drop approach, e.g.
https://zdevito.github.io/assets/viz/
(eventually this should be hosted with the pytorch docs).
All views/multiple cuda devices are supported on one page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103565
Approved by: https://github.com/eellison, https://github.com/albanD
Skip all cuda graph-related unit tests by setting env var `PYTORCH_TEST_SKIP_CUDAGRAPH=1`
This PR refactors the `TEST_CUDA` python variable in test_cuda.py into common_utils.py. This PR also creates a new python variable `TEST_CUDA_GRAPH` in common_utils.py, which has an env var switch to turn off all cuda graph-related tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103032
Approved by: https://github.com/malfet
Do not try to parse raised exception for no good reason
Add short description
Reduce script to a single line
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ea4164e</samp>
> _`test_no_triton_on_import`_
> _Cleans up the code, adds docs_
> _No hidden errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102674
Approved by: https://github.com/cpuhrsch, https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08f7a6a</samp>
This pull request adds support for triton kernels in `torch` and `torch/cuda`, and refactors and tests the existing triton kernel for BSR matrix multiplication. It also adds a test case to ensure that importing `torch` does not implicitly import `triton`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98403
Approved by: https://github.com/malfet, https://github.com/cpuhrsch
On Arm, I got
```
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5260, in test_cpp_memory_snapshot_pickle
mem = run()
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5257, in run
t = the_script_fn()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 496, in prof_func_call
return prof_callable(func_call, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 493, in prof_callable
return callable(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5254, in the_script_fn
@torch.jit.script
def the_script_fn():
return torch.rand(311, 411, device='cuda')
~~~~~~~~~~ <--- HERE
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
dfe484a3b3/torch/csrc/profiler/unwind/unwind.cpp (L4-L24) seems related
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101366
Approved by: https://github.com/zdevito
When we run cudagraph trees we are not allowed to have permanent workspace allocations like in cublas because we might need to reclaim that memory for a previous cudagraph recording, and it is memory that is not accounted for in output weakrefs so it does not work with checkpointing. Previously, I would check that we didn't have any additional allocations through snapshotting. This was extremely slow so I had to turn it off.
This PR first does the quick checking to see if we are in an error state, then if we are does the slow logic of creating snapshot. Also turns on history recording so we get a stacktrace of where the bad allocation came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99985
Approved by: https://github.com/zdevito
Why?
* To reduce the latency of hot path in https://github.com/pytorch/pytorch/pull/97377
Concern - I had to add `set_offset` in all instances of `GeneratorImpl`. I don't know if there is a better way.
~~~~
import torch
torch.cuda.manual_seed(123)
print(torch.cuda.get_rng_state())
torch.cuda.set_rng_state_offset(40)
print(torch.cuda.get_rng_state())
tensor([123, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
tensor([123, 0, 0, 0, 0, 0, 0, 0, 40, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
~~~~
Reland of https://github.com/pytorch/pytorch/pull/98965
(cherry picked from commit 8214fe07e8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99565
Approved by: https://github.com/anijain2305
Common advice we give for handling memory fragmentation issues is to
allocate a big block upfront to reserve memory which will get split up later.
For programs with changing tensor sizes this can be especially helpful to
avoid OOMs that happen the first time we see a new largest input and would
otherwise have to allocate new segments.
However the issue with allocating a block upfront is that is nearly impossible
to correctly estimate the size of that block. If too small, space in the block
will run out and the allocator will allocate separate blocks anyway. Too large,
and other non-PyTorch libraries might stop working because they cannot allocate
any memory.
This patch provides the same benefits as using a pre-allocating block but
without having to choose its size upfront. Using the cuMemMap-style APIs,
it adds the ability to expand the last block in a segment when more memory is
needed.
Compared to universally using cudaMallocAsync to avoid fragmentation,
this patch can fix this common fragmentation issue while preserving most
of the existing allocator behavior. This behavior can be enabled and disabled dynamically.
This should allow users to, for instance, allocate long-lived parameters and state in individual buffers,
and put temporary state into the large expandable blocks, further reducing
fragmentation.
See inline comments for information about the implementation and its limitations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96995
Approved by: https://github.com/eellison
CUDA Graph Trees
Design doc: https://docs.google.com/document/d/1ZrxLGWz7T45MSX6gPsL6Ln4t0eZCSfWewtJ_qLd_D0E/edit
Not currently implemented :
- Right now, we are using weak tensor refs from outputs to check if a tensor has dies. This doesn't work because a) aliasing, and b) aot_autograd detaches tensors (see note [Detaching saved tensors in AOTAutograd]). Would need either https://github.com/pytorch/pytorch/issues/91395 to land to use storage weak refs or manually add a deleter fn that does what I want. This is doable but theres some interactions with the caching allocator checkpointing so saving for a stacked pr.
- Reclaiming memory from the inputs during model recording. This isn't terribly difficult but deferring to another PR. You would need to write over the input memory during warmup, and therefore copy the inputs to cpu. Saving for a stacked pr.
- Warning on overwriting previous generation outputs. and handling nested torch.compile() calls in generation tracking
Differential Revision: [D43999887](https://our.internmc.facebook.com/intern/diff/D43999887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89146
Approved by: https://github.com/ezyang
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
When we checkpoint the state of the private pool allocator, we will need to make sure that its current live allocated blocks will get properly cleaned up when the tensors they correspond to die. Return DataPtrs for these new allocated blocks that the callee can swap onto live Tensors.
The exact api for setting the checkpoint can be manipulated after this as the cudagraph implementation is built out, but this at least shows its sufficiently general.
This should be the last PR touching cuda caching allocator necessary for new cudagraphs integration.
Differential Revision: [D43999888](https://our.internmc.facebook.com/intern/diff/D43999888)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95020
Approved by: https://github.com/zdevito
Copying note from cuda caching allocator:
```
* Note [Checkpointing PrivatePoolState]
*
* Refer above to Note [Interaction with CUDA graph capture]. Allocations made
* during graph capture are made from a separate private pool. During graph
* capture allocations behave as usual. During graph replay the allocator
* state does not change even as new tensors are created. The private pool
* will not free its blocks to the main caching allocator until cuda graph use
* is finished to prevent an allocation from eager clobbering the memory from
* a live but unaccounted for tensor that was created during replay.
*
* `make_graphed_callables`, a series of separate callables chained in
* successive cuda graphs, can share a memory pool because after a cuda graph
* recording the allocations in the shared private pool exactly reflect the
* tensors that are allocated.
*
* We would like to extend callable chaining to support a graphed callable
* tree. In this scenario, we have a tree of callable chains which will be
* captured with cuda graphs. In the diagram below, we have a tree with four
* callables, A, B, C, and D. Suppose we have captured, and subsequently
* replayed, A, B, and C. Then on a new invocation, we replay A and B, but
* would now like to record D. At this point the private pool will not reflect
* any of the live tensors created during graph replay. Allocations made
* during a new recording with the pool could overwrite those live tensors.
*
* In order to record a new graph capture after replaying prior callables in
* the tree, we need the allocator to reflect the state of the live tensors.
* We checkpoint the state of the private after each recording, and then
* reapply it when we are starting a new recording chain. Additionally, we
* must free the allocations for any tensors that died between the end of our
* previous graph replaying and our new recording (TODO). All of the allocated
* segments that existed in the checkpointed state must still exist in the
* pool. There may also exist new segments, which we will free (TODO : link
* note [live tensors between iterations] when it exists).
*
*
* ---------------> A ---------------> B ---------------> C
* |
* |
* |
* |
* ---------------> D
```
A few TODOs:
- need to add logic for freeing tensors that have died between a last replay and current new recording
- Add logic for free that might be called on a pointer multiple times (because we are manually freeing live tensors)
The two scenarios above have not been exercised in the tests yet.
Differential Revision: [D43999889](https://our.internmc.facebook.com/intern/diff/D43999889)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94653
Approved by: https://github.com/zdevito
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
With the release of ROCm 5.3 hip now supports a hipGraph implementation.
All necessary backend work and hipification is done to support the same functionality as cudaGraph.
Unit tests are modified to support a new TEST_GRAPH feature which allows us to create a single check for graph support instead of attempted to gather the CUDA level in annotations for every graph test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88202
Approved by: https://github.com/jithunnair-amd, https://github.com/pruthvistony, https://github.com/malfet
Summary:
The caching allocator can be configured to round memory allocations in order to reduce fragmentation. Sometimes however, the overhead from rounding can be higher than the fragmentation it helps reduce.
We have added a new stat to CUDA caching allocator stats to help track if rounding is adding too much overhead and help tune the roundup_power2_divisions flag:
- "requested_bytes.{current,peak,allocated,freed}": memory requested by client code, compare this with allocated_bytes to check if allocation rounding adds too much overhead
Test Plan: Added test case in caffe2/test/test_cuda.py
Differential Revision: D40810674
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88575
Approved by: https://github.com/zdevito
Follow-up of #86167 ; The number of pools was mistakenly ignored and the default workspace size appears to be too small to match selected cuBLAS kernels before the explicit allocation change.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89027
Approved by: https://github.com/ngimel
Essentially the same change as #67946, except that the default is to disallow reduced precision reductions in `BFloat16` GEMMs (for now). If performance is severely regressed, we can change the default, but this option appears to be necessary to pass some `addmm` `BFloat16` tests on H100.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89172
Approved by: https://github.com/ngimel
Summary:
1. use pytree to allow any input format for make_graphed_callables
2. add allow_unused_input argument for make_graphed_callables
Test Plan: buck2 test mode/dev-nosan //caffe2/test:cuda -- --print-passing-details
Differential Revision: D42077976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90941
Approved by: https://github.com/ngimel
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
Fixes#87894
This PR adds a warning if captured graph is empty (consists of zero nodes).
The example snippet where would it be useful:
```python
import torch
x = torch.randn(10)
z = torch.zeros(10)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
z = x * x
# Warn user
```
and in #87894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88754
Approved by: https://github.com/ezyang
Summary:
Improved roundup_power2_divisions knob so it allows better control of rouding in the PyTorch CUDA Caching Allocator.
This new version allows setting the number of divisions per power of two interval starting from 1MB and ending at 64GB and above. An example use case is when rouding is desirable for small allocations but there are also very large allocations which are persistent, thus would not benefit from rounding and take up extra space.
Test Plan: Tested locally
Differential Revision: D40103909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87290
Approved by: https://github.com/zdevito
As per #87979, `custom_bwd` seems to forcefully use `torch.float16` for `torch.autograd.Function.backward` regardless of the `dtype` used in the forward.
Changes:
- store the `dtype` in `args[0]`
- update tests to confirm the dtype of intermediate result tensors that are outputs of autocast compatible `torch` functions
cc @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88029
Approved by: https://github.com/ngimel
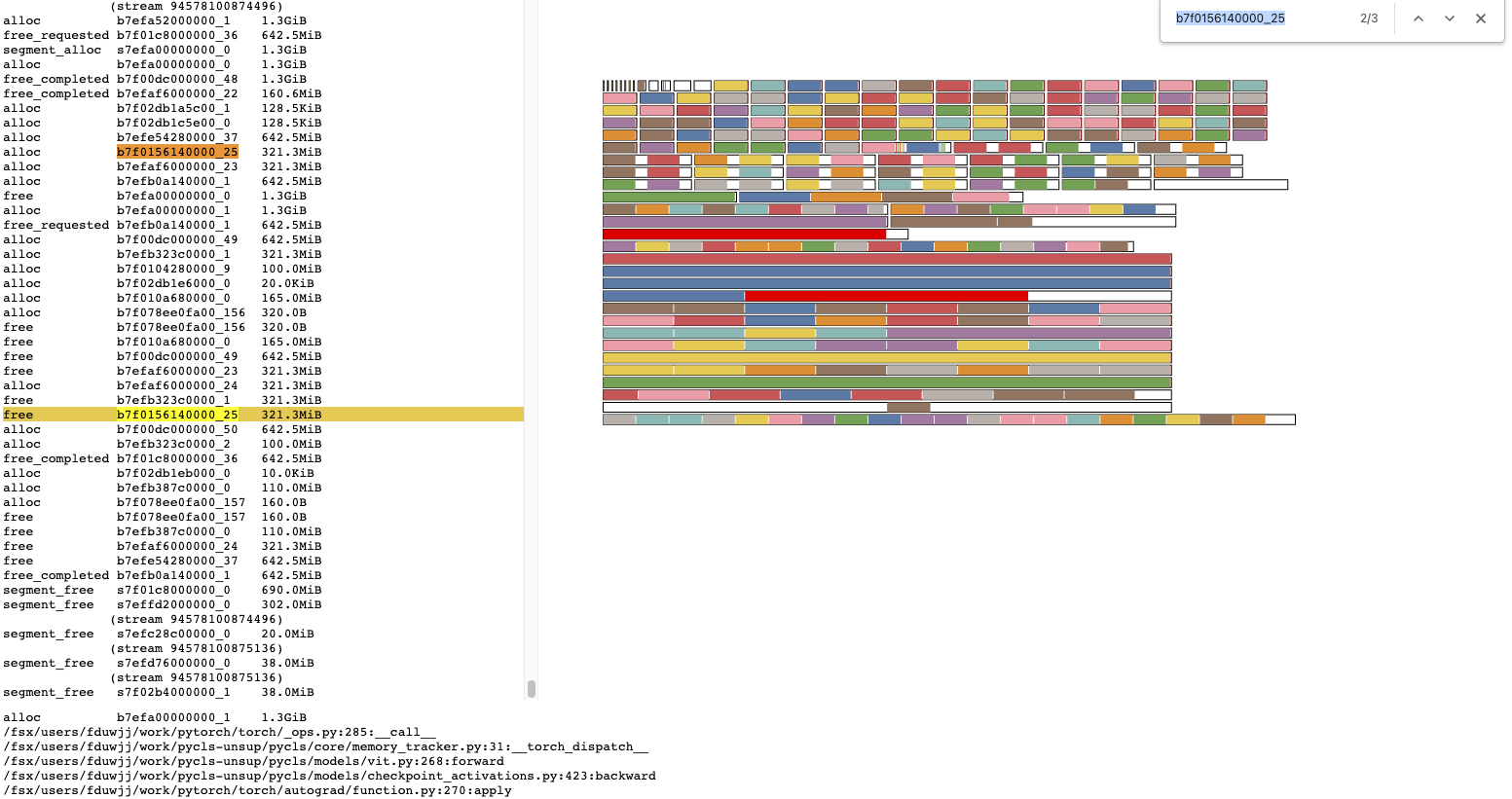
We currently can take snapshots of the state of the allocated cuda memory, but we do not have a way to correlate these snapshots with the actions the allocator that were taken between snapshots. This PR adds a simple fixed-sized buffer that records the major actions that the allocator takes (ALLOC, FREE, SEGMENT_ALLOC, SEGMENT_FREE, OOM, SNAPSHOT) and includes these with the snapshot information. Capturing period snapshots with a big enough trace buffer makes it possible to see how the allocator state changes over time.
We plan to use this functionality to guide how settings in the allocator can be adjusted and eventually have a more robust overall algorithm.
As a component of this functionality, we also add the ability to get a callback when the allocator will throw an OOM, primarily so that snapshots can be taken immediately to see why the program ran out of memory (most programs have some C++ state that would free tensors before the OutOfMemory exception can be caught).
This PR also updates the _memory_viz.py script to pretty-print the trace information and provide a better textual summary of snapshots distinguishing between internal and external fragmentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86241
Approved by: https://github.com/ngimel
Sometimes the driving process want to save memory snapshots but isn't Python.
Add a simple API to turn it on without python stack traces. It still
saves to the same format for the vizualization and summary scripts, using
the C++ Pickler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86190
Approved by: https://github.com/ezyang
Summary:
- expose a python call to set the allocator settings, it uses the same format as the value for PYTORCH_CUDA_ALLOCATOR
- keep the implementation contained within the cpp file to avoid increasing build times, only expose a function to call the setting
- make some of the Allocator Config methods public, now it looks more like a singleton
Test Plan: added the unit test
Differential Revision: D39487522
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84970
Approved by: https://github.com/zdevito
Fixes#84614
Prior to this PR CUDAGraph did not store the RNG seed, that is why `torch.cuda.manual_seed(new_seed)` would only reset the offset but not update the seed at all keeping whatever value was used during graph capture.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84967
Approved by: https://github.com/ngimel
Added ROCm support for the test_lazy_init unit test by including a condition on TEST_WITH_ROCM to switch CUDA_VISIBLE_DEVICES with HIP_VISIBLE_DEVICES.
This is needed because HIP_VISIBLE_DEVICES is set when running the single-GPU tests in CI: a47bc96fb7/.jenkins/pytorch/test.sh (L38), but this test sets CUDA_VISIBLE_DEVICES, which takes lower precedence than HIP_VISIBLE_DEVICES on ROCm.
**Testing Logs (to show behavior difference)**
12:40:41 Aug 30 11:40:41 CUDA_VISIBLE_DEVICES='0': 0
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 CUDA_VISIBLE_DEVICES='32': 32
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 HIP_VISIBLE_DEVICES='0': 0
12:40:41 Aug 30 11:40:41 1
12:40:41 Aug 30 11:40:41 HIP_VISIBLE_DEVICES='32': 32
12:40:41 Aug 30 11:40:41 0
**Passing UT**
Aug 30 17:03:15 test_lazy_init (main.TestCuda)
Aug 30 17:03:17 Validate that no CUDA calls are made during import torch call ... ok (2.471s)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84333
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
There there are conflicts between `torch.clear_autocast_cache()` and `cudaMallocAsync` from #82682.
Moreover, the use of autocast caching is not reasonable during training which is the main target of `make_graphed_callables`.
cc @eqy @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84289
Approved by: https://github.com/ngimel
This problem updates the the PR [#73040](https://github.com/pytorch/pytorch/pull/73040)
The compilation error in pyTorch with ROCm is successful with these changes when `NDEBUG` is enabled.
Solution:
For HIP we keep `__device__ __assert_fail()`
and for host side compilation we want to use the `__assert_fail()` from the glibc library.
Tested the code by compiling with below steps
```
python3 tools/amd_build/build_amd.py
python3 setup.py develop --cmake-only
cmake -DHIP_HIPCC_FLAGS_RELEASE="-DNDEBUG" build
cmake --build build
```
The UT test_fixed_cuda_assert_async is still skipped due performance overhead.
cc @jithunnair-amd
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81790
Approved by: https://github.com/shintaro-iwasaki, https://github.com/jeffdaily, https://github.com/malfet
Record stack trace information for each allocated segment in the allocator.
It takes around 1.5us to record 50 stack frames of context.
Since invoking a Pytorch operator is around 8us, this adds minimal overhead but we still leave it disabled by default so that we can test it more on real workloads first.
Stack information is kept both for allocated blocks and the last allocation used inactive blocks. We could potential keep around the _first_ allocation that caused the block to get allocated from cuda as well.
Potential Followups:
* stack frame entries are small (16 bytes), but the list of Frames is not compressed eventhough most frames will share some entries. So far this doesn't produce huge dumps (7MB for one real workload that uses all memory on the GPU), but it can be much smaller through compression.
* Code to format the information is slow (a few seconds) because it uses python and FlameGraph.pl
* Things allocated during the backward pass have no stack frames because they are run on another C++ thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82146
Approved by: https://github.com/albanD
### Description
Since the major changes for `_TypedStorage` and `_UntypedStorage` are now complete, they can be renamed to be public.
`TypedStorage._untyped()` is renamed to `TypedStorage.untyped()`.
Documentation for storages is improved as well.
### Issue
Fixes#82436
### Testing
N/A
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82438
Approved by: https://github.com/ezyang
cuDNN via the V8 API supports `bfloat16` on Ampere (`>= (8, 0)` but not older devices) which might be unexpected given current test settings. This PR fixes some dispatching to check the device capability before dispatching `bfloat16` convs and adjusts the expected failure conditions for the autocast test.
CC @xwang233 @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81139
Approved by: https://github.com/ngimel
Near term fix for https://github.com/pytorch/pytorch/issues/76368.
Q. Why does the user need to request `capturable=True` in the optimizer constructor? Why can't capture safety be completely automatic?
A. We need to set up capture-safe (device-side) state variables before capture. If we don't, and step() internally detects capture is underway, it's too late: the best we could do is create a device state variable and copy the current CPU value into it, which is not something we want baked into the graph.
Q. Ok, why not just do the capture-safe approach with device-side state variables all the time?
A. It incurs several more kernel launches per parameter, which could really add up and regress cpu overhead for ungraphed step()s. If the optimizer won't be captured, we should allow step() to stick with its current cpu-side state handling.
Q. But cuda RNG is a stateful thing that maintains its state on the cpu outside of capture and replay, and we capture it automatically. Why can't we do the same thing here?
A. The graph object can handle RNG generator increments because its capture_begin, capture_end, and replay() methods can see and access generator object. But the graph object has no explicit knowledge of or access to optimizer steps in its capture scope. We could let the user tell the graph object what optimizers will be stepped in its scope, ie something like
```python
graph.will_use_optimizer(opt)
graph.capture_begin()
...
```
but that seems clunkier than an optimizer constructor arg.
I'm open to other ideas, but right now I think constructor arg is necessary and the least bad approach.
Long term, https://github.com/pytorch/pytorch/issues/71274 is a better fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77862
Approved by: https://github.com/ezyang
Resubmit of https://github.com/pytorch/pytorch/pull/77673, which was reverted due to Windows test failures: https://github.com/pytorch/pytorch/pull/77673#issuecomment-1130425845.
I suspect these failures happened because I don't explicitly set a side stream for graph capture in the new test.
Not setting a side stream explicitly is alright on Linux because cuda tests implicitly use a side stream.
I think Windows cuda tests implicitly use the default stream, breaking capture and leaving the backend in a bad state.
Other graphs tests explicitly set side streams and don't error in Windows builds, so i'm 95% sure doing the same for the new test will work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77789
Approved by: https://github.com/ezyang
In preparation of adopting future rocblas library options, it is necessary to track when the backward pass of training is executing. The scope-based helper class `BackwardPassGuard` is provided to toggle state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71881
Approved by: https://github.com/albanD
release_cached_blocks calls this:
```
void synchronize_and_free_events() {
TORCH_INTERNAL_ASSERT(captures_underway == 0);
```
Which means we can't call that function when we are capturing a cuda graph:
```
import torch
with torch.cuda.graph(torch.cuda.CUDAGraph()):
torch.zeros(2 ** 40, device="cuda")
```
results in:
```
RuntimeError: captures_underway == 0INTERNAL ASSERT FAILED at "/tmp/torch/c10/cuda/CUDACachingAllocator.cpp":1224, please report a bug to PyTorch.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76247
Approved by: https://github.com/ngimel
Summary:
Recent change (https://github.com/pytorch/pytorch/pull/69751) introduced the requirement of using `.coalesce()` explicitly in the tests. Unfortunately, not all tests are run in the current CI configuration and one test failure slipped through.
Fixes https://github.com/pytorch/pytorch/issues/74015.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74027
Reviewed By: samdow
Differential Revision: D34858112
Pulled By: mruberry
fbshipit-source-id: 8904fac5e2b5335684a21f95a22646469478eb81
(cherry picked from commit 06d6e6d2a796af0e8444f4c57841a07ec4f67c9f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73040
This patch fixes a compilation error in PyTorch with ROCm when `NDEBUG` is passed.
## Problem
Forward declaration of `__host__ __device__ __assert_fail()` is used in `c10/macros/Macros.h` for HIP compilation when `NDEBUG` is set However, HIP has `__device__ __assert_fail()` in `hip/amd_detail/amd_device_functions.h`, causing a function type error.
This issue does not appear in ROCm CI tests since it happens only when `NDEBUG` is passed.
## Solution
[EDIT] After the discussion on GitHub, we chose to entirely disable `CUDA_KERNEL_ASSERT()` for ROCm.
---
To solve this compilation error, this patch disables `CUDA_KERNEL_ASSERT()`, which uses `__assert_fail()` when
1. `c10/macros/Macros.h` is included for `*.hip` (precisely speaking, `__HIP__` or `__HIP_ARCH__` is defined), and
2. `NDEBUG` is passed.
Note that there's no impact on default compilation because, without a special compilation flag, those HIP files are compiled without `-NDEBUG`. And that's why this issue has not been found.
### Justification
[1] We cannot declare one host-and-device function for two separate host and device functions.
```
__device__ int func() {return 0};
__host__ int func() {return 0};
// Compile error (hipcc)
// __device__ __host__ int func();
```
[2] Forward declaration of a correct `__device__` only `__assert_fail()` for `__HIP__` causes the following error:
```
pytorch/c10/util/TypeCast.h:135:7: error: reference to __device__ function '__assert_fail' in __host__ __device__ function
ERROR_UNSUPPORTED_CAST
^
pytorch/c10/util/TypeCast.h:118:32: note: expanded from macro 'ERROR_UNSUPPORTED_CAST'
#define ERROR_UNSUPPORTED_CAST CUDA_KERNEL_ASSERT(false);
^
pytorch/c10/macros/Macros.h:392:5: note: expanded from macro 'CUDA_KERNEL_ASSERT'
__assert_fail(
```
[3] Maybe there's a way to properly define `__assert_fail()` for HIP + NDEBUG, but this might be too much. Please let me just disable it.
### Technical details
Error
```
pytorch/c10/macros/Macros.h:368:5: error: __host__ __device__ function '__assert_fail' cannot overload __device__ function '__assert_fail'
__assert_fail(
^
/opt/rocm/hip/include/hip/amd_detail/amd_device_functions.h:1173:6: note: previous declaration is here
void __assert_fail(const char *assertion,
```
CUDA definition (9.x) of `__assert_fail()`
```
#elif defined(__GNUC__)
extern __host__ __device__ __cudart_builtin__ void __assert_fail(
const char *, const char *, unsigned int, const char *)
__THROW;
```
ROCm definition (the latest version)
```
// 2b59661f3e/include/hip/amd_detail/amd_device_functions.h (L1172-L1177)
extern "C" __device__ __attribute__((noinline)) __attribute__((weak))
void __assert_fail(const char *assertion,
const char *file,
unsigned int line,
const char *function);
```
Test Plan:
CI + reproducer
```
python3 tools/amd_build/build_amd.py
python3 setup.py develop --cmake-only
cmake -DHIP_HIPCC_FLAGS_RELEASE="-DNDEBUG" build
cmake --build build
```
Reviewed By: xw285cornell
Differential Revision: D34310555
fbshipit-source-id: 7542288912590533ced3f20afd2e704b6551991b
(cherry picked from commit 9e52196e36820abe36bf6427cabc7389d3ea6cb5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69299https://github.com/pytorch/pytorch/pull/68906 + https://github.com/pytorch/pytorch/pull/68749 plugged one correctness hole (non-blocking copies of offset pinned memory tensors) while introducing another (non-blocking copies of pinned memory tensors with a non-standard DataPtr context).
In this revision, we use both the tensor data pointer and context to attempt to identify the originating block in the pinned memory allocator.
Test Plan: New unit tests added to cover the missing case previously.
Reviewed By: yinghai
Differential Revision: D32787087
fbshipit-source-id: 0cb0d29d7c39a13f433eb1cd423dc0d2a303c955
(cherry picked from commit 297157b1a1)
Summary:
Also fixes the documentation failing to appear and adds a test to validate that op works with multiple devices properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69640
Reviewed By: ngimel
Differential Revision: D32965391
Pulled By: mruberry
fbshipit-source-id: 4fe502809b353464da8edf62d92ca9863804f08e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68749
The logic for asynchronous copies (either HtoD or DtoH) using cudaMemcpyAsync relies on recording an event with the caching host allocator to notify it that a given allocation has been used on a stream - and thus it should wait for that stream to proceed before reusing the host memory.
This tracking is based on the allocator maintaining a map from storage allocation pointers to some state.
If we try to record an event for a pointer we don't understand, we will silently drop the event and ignore it (9554ebe44e/aten/src/ATen/cuda/CachingHostAllocator.cpp (L171-L175)).
Thus, if we use the data_ptr of a Tensor instead of the storage allocation, then reasonable code can lead to incorrectness due to missed events.
One way this can occur is simply by slicing a tensor into sub-tensors - which have different values of `data_ptr()` but share the same storage, for example:
```
image_batch = torch.randn(M, B, C, H, W).pin_memory()
for m in range(M):
sub_batch = image_batch[m].cuda(non_blocking=True)
# sub_batch.data_ptr() != image_batch.data_ptr() except for m == 0.
# however, sub_batch.storage().data_ptr() == image_batch.storage().data_ptr() always.
```
Therefore, we instead use the storage context pointer when recording events, as this is the same state that is tracked by the caching allocator itself. This is a correctness fix, although it's hard to determine how widespread this issue is.
Using the storage context also allows us to use a more efficient structure internally to the caching allocator, which will be sent in future diffs.
Test Plan: Test added which demonstrates the issue, although it's hard to demonstrate the race explicitly.
Reviewed By: ngimel
Differential Revision: D32588785
fbshipit-source-id: d87cc5e49ff8cbf59052c3c97da5b48dd1fe75cc
Summary:
https://github.com/pytorch/pytorch/issues/67578 disabled reduced precision reductions for FP16 GEMMs. After benchmarking, we've found that this has substantial performance impacts for common GEMM shapes (e.g., those found in popular instantiations of multiheaded-attention) on architectures such as Volta. As these performance regressions may come as a surprise to current users, this PR adds a toggle to disable reduced precision reductions
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = `
rather than making it the default behavior.
CC ngimel ptrblck
stas00 Note that the behavior after the previous PR can be replicated with
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = False`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67946
Reviewed By: zou3519
Differential Revision: D32289896
Pulled By: ngimel
fbshipit-source-id: a1ea2918b77e27a7d9b391e030417802a0174abe
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62533.
In very rare cases, the decorator for detecting memory leak is throwing assertion, even when the test is passing, and the memory is being freed with a tiny delay. The issue is not being reproduced in internal testing, but shows up sometimes in CI environment.
Reducing the severity of such detection to warning, so as not to fail the CI tests, as the actual test is not failing, rather only the check inside the decorator is failing.
Limiting the change to ROCM only for now.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65973
Reviewed By: anjali411
Differential Revision: D31776154
Pulled By: malfet
fbshipit-source-id: 432199fca17669648463c4177c62adb553cacefd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66798
get_cycles_per_ms is copied and used in a few places, move it to common_utils so that it can be used as a shared util function
ghstack-source-id: 140790599
Test Plan: unit tests
Reviewed By: pritamdamania87
Differential Revision: D31706870
fbshipit-source-id: e8dccecb13862646a19aaadd7bad7c8f414fd4ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62030
Remove dtype tracking from Python Storage interface, remove all the different `<type>Storage` classes except for `ByteStorage`, and update serialization accordingly, while maintaining as much FC/BC as possible
Fixes https://github.com/pytorch/pytorch/issues/47442
* **THE SERIALIZATION FORMAT IS FULLY FC/BC.** We worked very hard to make sure this is the case. We will probably want to break FC at some point to make the serialization structure of tensors make more sense, but not today.
* There is now only a single torch.ByteStorage class. Methods like `Tensor.set_` no longer check that the dtype of storage is appropriate.
* As we no longer know what dtype of a storage is, we've **removed** the size method from Storage, replacing it with nbytes. This is to help catch otherwise silent errors where you confuse number of elements with number of bytes.
* `Storage._new_shared` takes a `nbytes` kwarg and will reject previous positional only calls. `Storage._new_with_file` and `_set_from_file` require explicit element size arguments.
* It's no longer possible to convert storages to different types using the float/double/etc methods. Instead, do the conversion using a tensor.
* It's no longer possible to allocate a typed storage directly using FloatStorage/DoubleStorage/etc constructors. Instead, construct a tensor and extract its storage. The classes still exist but they are used purely for unpickling.
* The preexisting serialization format stores dtype with storage, and in fact this dtype is used to determine the dtype of the tensor overall.
To accommodate this case, we introduce a new TypedStorage concept that exists only during unpickling time which is used to temporarily store the dtype so we can construct a tensor. **If you overrode the handling of pickling/unpickling, you MUST add handling for TypedStorage** or your serialization code will degrade to standard file-based serialization.
Original pull request: https://github.com/pytorch/pytorch/pull/59671
Reviewed By: soulitzer, ngimel
Differential Revision: D29466819
Pulled By: ezyang
fbshipit-source-id: 4a14e5d3c2b08e06e558683d97f7378a3180b00e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64261
Note that this does not preserve byte-for-byte compatibility with
existing names.
Test Plan:
* Rely on CI to catch gross errors.
* Merge after release cut to catch subtle issues.
Reviewed By: albanD
Differential Revision: D30700647
Pulled By: dagitses
fbshipit-source-id: 7b02f34b8fae3041240cc78fbc6bcae498c3acd4
Summary:
Graphed workloads that try to capture a full backward pass must do warmup on a non-default stream. If warmup happens on the default stream, AccumulateGrad functions might tag themselves to run on the default stream, and therefore won't be capturable.
ngimel and I suspect some test_cuda.py tests run with the default stream as the ambient stream, which breaks `test_graph_grad_scaling` because `test_graph_grad_scaling` does warmup on the ambient stream _assuming_ the ambient stream is a non-default stream.
This PR explicitly sets a side stream for the warmup in `test_graph_grad_scaling`, which is what I should have done all along because it's what the new documentation recommends.
I pushed the PR branch straight to the main pytorch repo because we need to run ci-all on it, and I'm not sure what the requirements are these days.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64339
Reviewed By: mruberry
Differential Revision: D30690711
Pulled By: ngimel
fbshipit-source-id: 91ad75f46a11f311e25bc468ea184e22acdcc25a
{kind=link}