Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69550
Fix the wiki URL.
Also minor reorganization in onnx.rst.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32994269
Pulled By: malfet
fbshipit-source-id: 112acfe8b7c778d7e3c2cef684023fdaf2c6ec9c
(cherry picked from commit f0787fabde)
Summary:
It is probably the most user friendly to link to that (lesser known?) feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72584
Reviewed By: soulitzer
Differential Revision: D34173999
Pulled By: albanD
fbshipit-source-id: 99fff7a55412faf54888f8317ab2388f4d7d30e4
(cherry picked from commit 2191ee7657)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68491
* Allows implementing symbolic functions for domains other than `aten`, for example `prim`, in symbolic_opset#.py.
* Allows symbolic function to access extra context if needed, through `SymbolicFunctionState`.
* Particularly, the `prim::PythonOp` special case can access node without the need of passing node through inputs. Updates will be made downstreams, and in a follow-up PR we will remove the previous workaround in exporter.
* `prim::Loop`, `prim::If`, etc are now moved outside of `_run_symbolic_function` from utils.py, and to symbolic_opset9.py.
Motivation for this change:
- Better maintainability and reducing complexity. Easier to add symbolic for operators, both simple and complex ones (that need additional context), without the former needing to know the existence of the latter.
- The design idea was long outdated. prim ops are no longer rare special cases, and they shouldn't all be handled inside `_run_symbolic_function`. As a result this function becomes too clumsy. There were also prim ops symbolic added in symbolic_opset#.py with signature `prim_[opname]`, creating separation and confusion.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483782
Pulled By: malfet
fbshipit-source-id: f9affc31b1570af30ffa6668da9375da111fd54a
Co-authored-by: BowenBao <bowbao@microsoft.com>
(cherry picked from commit 1e04ffd2fd)
Summary:
This PR adds a transform that uses the cumulative distribution function of a given probability distribution.
For example, the following code constructs a simple Gaussian copula.
```python
# Construct a Gaussian copula from a multivariate normal.
base_dist = MultivariateNormal(
loc=torch.zeros(2),
scale_tril=LKJCholesky(2).sample(),
)
transform = CumulativeDistributionTransform(Normal(0, 1))
copula = TransformedDistribution(base_dist, [transform])
```
The following snippet creates a "wrapped" Gaussian copula for correlated positive variables with Weibull marginals.
```python
transforms = [
CumulativeDistributionTransform(Normal(0, 1)),
CumulativeDistributionTransform(Weibull(4, 2)).inv,
]
wrapped_copula = TransformedDistribution(base_dist, transforms)
```
cc fritzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72495
Reviewed By: ejguan
Differential Revision: D34085919
Pulled By: albanD
fbshipit-source-id: 7917391519a96b0d9b54c52db65d1932f961d070
(cherry picked from commit 572196146e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72499
Pull Request resolved: https://github.com/pytorch/benchmark/pull/740
To fx2trt out of tree to remove bloatness of PyTorch core.
It's the first and major step. Next, we will move acc_tracer out of the tree and rearrange some fx passes.
Reviewed By: suo
Differential Revision: D34065866
fbshipit-source-id: c72b7ad752d0706abd9a63caeef48430e85ec56d
(cherry picked from commit 91647adbca)
Summary:
Correcting a minor typo: "Users should pay" instead of "Users should be pay"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72500
Reviewed By: albanD
Differential Revision: D34077972
Pulled By: ejguan
fbshipit-source-id: 5d7a138d1f17eca838d2c1da76d7759d96e4375f
(cherry picked from commit d046baa89c)
Summary:
This PR ports `index_copy` implementation to structured kernels, also adds an `out` variant.
~Note to the reviewers: This is in draft mode, waiting for the tests from the CI, and I'll give a final look before requesting the review.~
Issue tracker: https://github.com/pytorch/pytorch/issues/55070
cc: bdhirsh ysiraichi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67329
Reviewed By: ejguan
Differential Revision: D34077219
Pulled By: bdhirsh
fbshipit-source-id: 6accda33957f654b753261c5c3d765a27a64d2c0
(cherry picked from commit f3ac83217a)
Summary:
Let's make the documentation for `torch.sparse.sampled_addmm` searchable in the PyTorch documentation.
This PR shall be cherry-picked for the next 1.11 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72312
Reviewed By: davidberard98
Differential Revision: D34045230
Pulled By: cpuhrsch
fbshipit-source-id: c1b1dc907443284857f48c8ce1efab22c6701bbe
(cherry picked from commit 225929ecf2)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72084
make fsdp folder to be public
ghstack-source-id: 148173447
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D33903417
fbshipit-source-id: 7852a2adc4af09af48a5ffa52ebf210489f834d5
(cherry picked from commit bd06513cfe)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72111
For vectorize flag:
- Advertises the use of functorch
For autograd.functional.jvp:
- Advertises the use of functorch and the low-level jvp API, both of
which will be more performant than the double backprop trick.
Test Plan: - view docs
Reviewed By: albanD
Differential Revision: D33918065
Pulled By: zou3519
fbshipit-source-id: 6e19699aa94f0e023ccda0dc40551ad6d932b7c7
(cherry picked from commit b4662ceb99)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72009
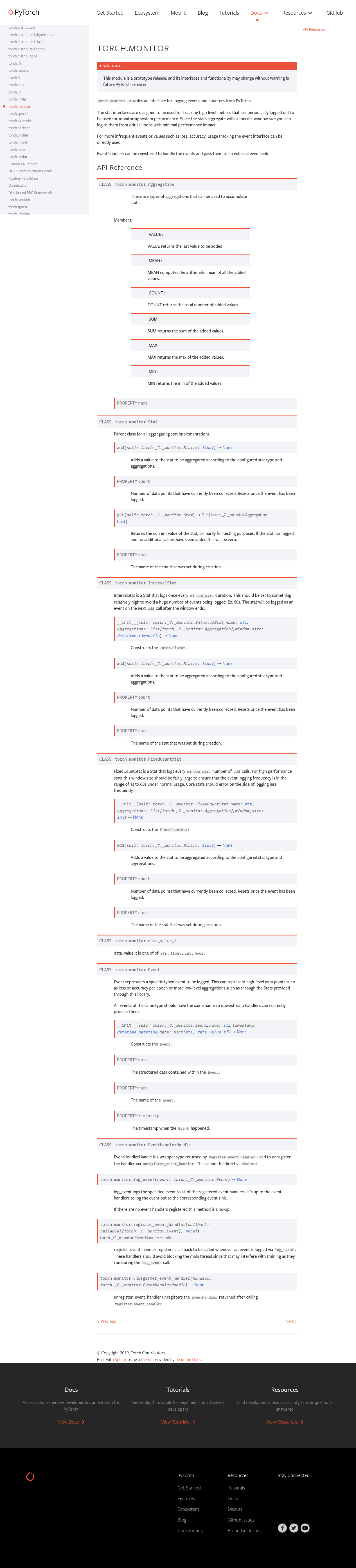
This simplifies the Stats interface by merging IntervalStat and FixedCountStat into a single Stat w/ a specific window size duration and an optional max samples per window. This allows for the original intention of having comparably sized windows (for statistical purposes) while also having a consistent output bandwidth.
Test Plan:
```
buck test //caffe2/test:monitor //caffe2/test/cpp/monitor:monitor
```
Reviewed By: kiukchung
Differential Revision: D33822956
fbshipit-source-id: a74782492421be613a1a8b14341b6fb2e8eeb8b4
(cherry picked from commit 293b94e0b4)
Summary:
Follow up: we would need to update the links to the tutorial later
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71643
Reviewed By: albanD
Differential Revision: D33713982
Pulled By: soulitzer
fbshipit-source-id: a314ffa4e7d5c5ebdef9c50033f338b06578d71c
(cherry picked from commit ba30daaaa5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66745
This PR implement NCCL gather and add gather to ProcessGroupNCCL using nccl send/recv api.
NCCL doesn’t directly provide primitives for gather, so we need to be implemented on top of NCCL’s send/recv API.
1. In ProcessGroupNCCL.cpp, the outputTensors are first flattened, then inputTensors and outputFlattened are passed by the collective class to gather() function in nccl.cpp.
1. In nccl.cpp, gather is implemented using ncclSend/ncclRecv: all the ranks send inputTensor to the root rank, and the root rank uses a for loop to receive these inputTensors.
ghstack-source-id: 147754838
Test Plan:
test_gather_ops
test_gather_checks
test_gather_stress
Reviewed By: pritamdamania87
Differential Revision: D29616361
fbshipit-source-id: b500d9b8e67113194c5cc6575fb0e5d806dc7782
(cherry picked from commit d560ee732e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71658
This adds the beginnings of a TensorboardEventHandler which will log stats to Tensorboard.
Test Plan: buck test //caffe2/test:monitor
Reviewed By: edward-io
Differential Revision: D33719954
fbshipit-source-id: e9847c1319255ce0d9cf2d85d8b54b7a3c681bd2
(cherry picked from commit 5c8520a6ba)
Fix the wiki URL.
Also minor reorganization in onnx.rst.
[ONNX] restore documentation of public functions (#69623)
The build-docs check requires all public functions to be documented.
These should really not be public, but we'll fix that later.'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71609
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69567
This exposes torch.monitor events and stats via pybind11 to the underlying C++ implementation.
* The registration interface is a tad different since it takes a lambda function in Python where as in C++ it's a full class.
* This has a small amount of changes to the counter interfaces since there's no way to create an initializer list at runtime so they now also take a vector.
* Only double based stats are provided in Python since it's intended more for high level stats where float imprecision shouldn't be an issue. This can be changed down the line if need arises.
```
events = []
def handler(event):
events.append(event)
handle = register_event_handler(handler)
log_event(Event(type="torch.monitor.TestEvent", timestamp=datetime.now(), metadata={"foo": 1.0}))
```
D32969391 is now included in this diff.
This cleans up the naming for events. type is now name, message is gone, and metadata is renamed data.
Test Plan: buck test //caffe2/test:monitor //caffe2/test/cpp/monitor:monitor
Reviewed By: kiukchung
Differential Revision: D32924141
fbshipit-source-id: 563304c2e3261a4754e40cca39fc64c5a04b43e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70185
The extraheader block in docs/source/_templates/layout.html overrides the one from the pytorch theme. The theme block adds Google Analytics, so they were missing from the `master` documentation. This came up in PR pytorch/pytorch.github.io#899.
brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70187
Reviewed By: bdhirsh
Differential Revision: D33248466
Pulled By: malfet
fbshipit-source-id: b314916a3f0789b6617cf9ba6bd938bf5ca27242
Summary:
Refactor torch.profiler.profile by separate it into one low level class and one high level wrapper.
The PR include the following change:
1. separate class torch.profiler.profile into two separated class: kineto_profiler and torch.profiler.profile.
2. The former class has the low-level functionality exposed in C++ level like: prepare_profiler, start_profiler, stop_profiler.
3. The original logics in torch.profiler.profile including export_chrome_trace, export_stacks, key_averages, events, add_metadata are all moved into kineto_profiler since they are all exposed by the torch.autograd.profiler.
4. The new torch.profiler.profile is fully back-compatible with original class since it inherit from torch.profiler.kineto_profiler. Its only responsibility in new implementation is the maintenance of the finite state machine of ProfilerAction.
With the refactoring, the responsibility boundary is clear and the new logic is simple to understand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63302
Reviewed By: albanD
Differential Revision: D33006442
Pulled By: robieta
fbshipit-source-id: 30d7c9f5c101638703f1243fb2fcc6ced47fb690
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65993
This PR attempts to port `index_add` to structured kernels, but does more than that:
* Adds an `out=` variant to `index_add`
* Revises `native_functions.yaml` registrations, to not have multiple entries and instead pass default value to `alpha`.
* Changes in `derivatives.yaml` file for autograd functioning
* Revises error messages, please see: https://github.com/pytorch/pytorch/pull/65993#issuecomment-945441615
Follow-up PRs in near future will attempt to refactor the OpInfo test, and will give another look at tests in `test/test_torch.py` for this function. (hence the use of ghstack for this)
~This is WIP because there are tests failing for `Dimname` variant on mobile/android builds, and I'm working on fixing them.~
Issue tracker: https://github.com/pytorch/pytorch/issues/55070
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32646426
fbshipit-source-id: b035ecf843a9a27d4d1e18b202b035adc2a49ab5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69789
Add details on how to save and load quantized models without hitting errors
Test Plan:
CI autogenerated docs
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33030991
fbshipit-source-id: 8ec4610ae6d5bcbdd3c5e3bb725f2b06af960d52
Summary:
Also fixes the documentation failing to appear and adds a test to validate that op works with multiple devices properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69640
Reviewed By: ngimel
Differential Revision: D32965391
Pulled By: mruberry
fbshipit-source-id: 4fe502809b353464da8edf62d92ca9863804f08e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69104
Add nvidia-smi memory and utilization as native Python API
Test Plan:
testing the function returns the appropriate value.
Unit tests to come.
Reviewed By: malfet
Differential Revision: D32711562
fbshipit-source-id: 01e676203299f8fde4f3ed4065f68b497e62a789
{kind=link}
{kind=link}