TorchScript only supports indexing into ModuleLists with integer literals. The error message already warns about this; but this PR adds clarifications around what a "literal" is. I'm adding this PR because, in my opinion, it's not obvious what a "literal" is and how strict its definition is. The clarification provided in this PR should make it easier for users to understand the issue and how to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98606
Approved by: https://github.com/eellison, https://github.com/gmagogsfm
Summary:
Extra C binding module for flatbuffer was introduced because
not all dependencies of Pytorch want (or can) bundle in flatbuffer.
However, flatbuffer is in by default now so this separate binding is not longer needed.
Test Plan: existing unit tests
Differential Revision: D44352583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97476
Approved by: https://github.com/dbort
**Summary** NamedTuple attributes can be annotated to declare their type:
```python
class MyNamedTuple(NamedTuple):
x: int
y: torch.Tensor
z: MyOtherType
```
Normally in python you can also declare your types as strings, `x: 'int'`. But NamedTuples previously didn't support this, because their annotation evaluation process was slightly different. This PR updates the NamedTuple attribute type annotation evaluation method to support ForwardRef declarations (i.e. declaring as strings).
**Details**
Below I repeat the comment I left in _jit_internal.py:
NamedTuple types are slightly different from normal types.
Normally, annotations are evaluted like this (during jit.script):
1. Load strings of python code into c++ and parse.
2. Get annotations as strings
3. Use the PythonResolver's resolution callback (rcb) to convert the string into a python object
4. We call into annotations.py:ann_to_type to convert python obj from step 3 into a type that torchscript understands.
NamedTuples are more complicated, because they have sub-types. Normally, once we have the NamedTuple type object from #3, we can just look at the annotation literal values and use ann_to_type directly on them.
But sometimes, users will annotate with string literals, e.g.
```
x: 'int'
```
This also happens with PEP563 (from __forward__ import annotations)
These annotations appear in the annotation dict as ForwardRef('int').
Then, we need to convert the string into a python object. This requires having local context for custom objects or imported types. rcb() is what gives us this. So, we plumb rcb through the stack so it can be used in this context for the if block below.
FAQ:
- Why do we need this special handling for NamedTuple but string annotations work fine for normal types? Normally, we parse the string directly and then call rcb() directly from C++.
- Why not use ForwardRef._evaluate? For that, we need globals() and locals() for the local context where the NamedTuple was defined. rcb is what lets us look up into these. So, basically rcb does the hard work for us.
- What is rcb? rcb is a ResolutionCallback - python callable that takes a string and returns a type. It's generated by `createResolutionCallback.*` in _jit_internal.py.
**Why is this only partial support**:
This only plumbs the rcb through some paths. In particular, the `toSugaredValue` path uses a fake rcb.
**Alternatives**:
We could also treat this the way we treat non-nn.Module classes: we evaluate them separately, ahead of time. That solution is probably better, but probably requires a more risky refactor for the way NamedTuples are handled.
Fixes#95858
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96933
Approved by: https://github.com/qihqi
This PR do two things:
1. It moves some Windows warning suppression from various CMake files into the main CMakeList.txt, following the conventions of gcc and clang.
2. It fixes some Windows warnings in the source code. Most importantly, it fixes lots of dll warnings by adjusting C10_API to TORCH_API or TORCH_PYTHON_API. There are still some dll warnings because some TORCH_API functions are actually built as part of libtorch_python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94927
Approved by: https://github.com/malfet
The basic idea behind this PR is that we want to continue using the guarding implementations of contiguity tests, if all of the elements are backend (aka, have hints). If they don't have hints, we'll have to do something slower (use the non-short circuiting, non guarding implementations of contiguity), but most of the time you aren't dealing with unbacked SymInts.
So this PR has three parts.
1. We expose `has_hint` on `SymNode`. This allows us to query whether or not a SymInt is backed or not from C++. Fairly self explanatory. Will require LTC/XLA updates; but for backends that don't support unbacked SymInts you can just always return true.
2. We update `compute_non_overlapping_and_dense` to test if the inputs are hinted. If they are all hinted, we use the conventional C++ implementation. Otherwise we call into Python. The Python case is not heavily tested right now because I haven't gotten all of the pieces for unbacked SymInts working yet. Coming soon.
3. We add stubs for all of the other contiguity tests. The intention is to apply the same treatment to them as well, but this is not wired up yet for safety reasons.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94431
Approved by: https://github.com/voznesenskym
We want to make TorchRec sharded models TorchScriptable.
TorchRec sharded models uses generic types Awaitable[W] and LazyAwaitable[W] (https://github.com/pytorch/torchrec/blob/main/torchrec/distributed/types.py#L212).
In sharded model those types are used instead of contained type W, having the initialization function that produces object of type W.
At the moment when the first attribute of W is requested - `LazyAwaitable[W]` will call its initialization function (on the same stack), cache the result inside and work transparently as an object of W. So we can think about it as a delayed object initialization.
To support this behavior in TorchScript - we propose a new type to TorchScript - `Await`.
In eager mode it works the same as `LazyAwaitable[W]` in TorchRec, being dynamically typed - acting as a type `W` while it is `Await[W]`.
Within torchscript it is `Await[W]` and can be only explicitly converted to W, using special function `torch.jit.awaitable_wait(aw)`.
Creation of this `Await[W]` is done via another special function `torch.jit.awaitable(func, *args)`.
The semantic is close to `torch.jit.Future`, fork, wait and uses the same jit mechanics (inline fork Closures) with the difference that it does not start this function in parallel on fork. It only stores as a lambda inside IValue that will be called on the same thread when `torch.jit.awaitable_wait` is called.
For example (more examples in this PR `test/jit/test_await.py`)
```
def delayed(z: Tensor) -> Tensor:
return Tensor * 3
@torch.jit.script
def fn(x: Tensor):
aw: Await[int] = torch.jit._awaitable(delayed, 99)
a = torch.eye(2)
b = torch.jit._awaitable_wait(aw)
return a + b + x
```
Functions semantics:
`_awaitable(func -> Callable[Tuple[...], W], *args, **kwargs) -> Await[W]`
Creates Await object, owns args and kwargs. Once _awaitable_wait calls, executes function func and owns the result of the function. Following _awaitable_wait calls will return this result from the first function call.
`_awaitable_wait(Await[W]) -> W`
Returns either cached result of W if it is not the first _awaitable_wait call to this Await object or calls specified function if the first.
`_awaitable_nowait(W) -> Await[W]`
Creates trivial Await[W] wrapper on specified object To be type complaint for the corner cases.
Differential Revision: [D42502706](https://our.internmc.facebook.com/intern/diff/D42502706)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90863
Approved by: https://github.com/davidberard98
Not only is this change usually shorter and more readable, it also can yield better performance. size() is not always a constant time operation (such as on LinkedLists), but empty() always is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93236
Approved by: https://github.com/malfet
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
Replace cpp string comparisons with more efficient equality operators. These string comparisons are not just more readable, but they also allow for short-circuiting for faster string equality checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92765
Approved by: https://github.com/ezyang
We have known for a while that we should in principle support SymBool as a separate concept from SymInt and SymFloat ( in particular, every distinct numeric type should get its own API). However, recent work with unbacked SymInts in, e.g., https://github.com/pytorch/pytorch/pull/90985 have made this a priority to implement. The essential problem is that our logic for computing the contiguity of tensors performs branches on the passed in input sizes, and this causes us to require guards when constructing tensors from unbacked SymInts. Morally, this should not be a big deal because, we only really care about the regular (non-channels-last) contiguity of the tensor, which should be guaranteed since most people aren't calling `empty_strided` on the tensor, however, because we store a bool (not a SymBool, prior to this PR it doesn't exist) on TensorImpl, we are forced to *immediately* compute these values, even if the value ends up not being used at all. In particular, even when a user allocates a contiguous tensor, we still must compute channels-last contiguity (as some contiguous tensors are also channels-last contiguous, but others are not.)
This PR implements SymBool, and makes TensorImpl use SymBool to store the contiguity information in ExtraMeta. There are a number of knock on effects, which I now discuss below.
* I introduce a new C++ type SymBool, analogous to SymInt and SymFloat. This type supports logical and, logical or and logical negation. I support the bitwise operations on this class (but not the conventional logic operators) to make it clear that logical operations on SymBool are NOT short-circuiting. I also, for now, do NOT support implicit conversion of SymBool to bool (creating a guard in this case). This does matter too much in practice, as in this PR I did not modify the equality operations (e.g., `==` on SymInt) to return SymBool, so all preexisting implicit guards did not need to be changed. I also introduced symbolic comparison functions `sym_eq`, etc. on SymInt to make it possible to create SymBool. The current implementation of comparison functions makes it unfortunately easy to accidentally introduce guards when you do not mean to (as both `s0 == s1` and `s0.sym_eq(s1)` are valid spellings of equality operation); in the short term, I intend to prevent excess guarding in this situation by unit testing; in the long term making the equality operators return SymBool is probably the correct fix.
* ~~I modify TensorImpl to store SymBool for the `is_contiguous` fields and friends on `ExtraMeta`. In practice, this essentially meant reverting most of the changes from https://github.com/pytorch/pytorch/pull/85936 . In particular, the fields on ExtraMeta are no longer strongly typed; at the time I was particularly concerned about the giant lambda I was using as the setter getting a desynchronized argument order, but now that I have individual setters for each field the only "big list" of boolean arguments is in the constructor of ExtraMeta, which seems like an acceptable risk. The semantics of TensorImpl are now that we guard only when you actually attempt to access the contiguity of the tensor via, e.g., `is_contiguous`. By in large, the contiguity calculation in the implementations now needs to be duplicated (as the boolean version can short circuit, but the SymBool version cannot); you should carefully review the duplicate new implementations. I typically use the `identity` template to disambiguate which version of the function I need, and rely on overloading to allow for implementation sharing. The changes to the `compute_` functions are particularly interesting; for most of the functions, I preserved their original non-symbolic implementation, and then introduce a new symbolic implementation that is branch-less (making use of our new SymBool operations). However, `compute_non_overlapping_and_dense` is special, see next bullet.~~ This appears to cause performance problems, so I am leaving this to an update PR.
* (Update: the Python side pieces for this are still in this PR, but they are not wired up until later PRs.) While the contiguity calculations are relatively easy to write in a branch-free way, `compute_non_overlapping_and_dense` is not: it involves a sort on the strides. While in principle we can still make it go through by using a data oblivious sorting network, this seems like too much complication for a field that is likely never used (because typically, it will be obvious that a tensor is non overlapping and dense, because the tensor is contiguous.) So we take a different approach: instead of trying to trace through the logic computation of non-overlapping and dense, we instead introduce a new opaque operator IsNonOverlappingAndDenseIndicator which represents all of the compute that would have been done here. This function returns an integer 0 if `is_non_overlapping_and_dense` would have returned `False`, and an integer 1 otherwise, for technical reasons (Sympy does not easily allow defining custom functions that return booleans). The function itself only knows how to evaluate itself if all of its arguments are integers; otherwise it is left unevaluated. This means we can always guard on it (as `size_hint` will always be able to evaluate through it), but otherwise its insides are left a black box. We typically do NOT expect this custom function to show up in actual boolean expressions, because we will typically shortcut it due to the tensor being contiguous. It's possible we should apply this treatment to all of the other `compute_` operations, more investigation necessary. As a technical note, because this operator takes a pair of a list of SymInts, we need to support converting `ArrayRef<SymNode>` to Python, and I also unpack the pair of lists into a single list because I don't know if Sympy operations can actually validly take lists of Sympy expressions as inputs. See for example `_make_node_sizes_strides`
* On the Python side, we also introduce a SymBool class, and update SymNode to track bool as a valid pytype. There is some subtlety here: bool is a subclass of int, so one has to be careful about `isinstance` checks (in fact, in most cases I replaced `isinstance(x, int)` with `type(x) is int` for expressly this reason.) Additionally, unlike, C++, I do NOT define bitwise inverse on SymBool, because it does not do the correct thing when run on booleans, e.g., `~True` is `-2`. (For that matter, they don't do the right thing in C++ either, but at least in principle the compiler can warn you about it with `-Wbool-operation`, and so the rule is simple in C++; only use logical operations if the types are statically known to be SymBool). Alas, logical negation is not overrideable, so we have to introduce `sym_not` which must be used in place of `not` whenever a SymBool can turn up. To avoid confusion with `__not__` which may imply that `operators.__not__` might be acceptable to use (it isn't), our magic method is called `__sym_not__`. The other bitwise operators `&` and `|` do the right thing with booleans and are acceptable to use.
* There is some annoyance working with booleans in Sympy. Unlike int and float, booleans live in their own algebra and they support less operations than regular numbers. In particular, `sympy.expand` does not work on them. To get around this, I introduce `safe_expand` which only calls expand on operations which are known to be expandable.
TODO: this PR appears to greatly regress performance of symbolic reasoning. In particular, `python test/functorch/test_aotdispatch.py -k max_pool2d` performs really poorly with these changes. Need to investigate.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92149
Approved by: https://github.com/albanD, https://github.com/Skylion007
It turns out our old max/min implementation didn't do anything, because `__max__` and `__min__` are not actually magic methods in Python. So I give 'em the `sym_` treatment, similar to the other non-overrideable builtins.
NB: I would like to use `sym_max` when computing contiguous strides but this appears to make `python test/functorch/test_aotdispatch.py -v -k test_aot_autograd_symbolic_exhaustive_nn_functional_max_pool2d_cpu_float32` run extremely slowly. Needs investigating.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92107
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/Skylion007
As we live in C++17 world
This is a functional no-op, just
- `s/namespace at { namespace native {/namespace at::native {/`
- `s/namespace torch { namespace jit {/namespace torch::jit {/`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92100
Approved by: https://github.com/izaitsevfb
This adds `torch.cuda._DeviceGuard` which is a stripped down version of
`torch.cuda.device` with lower overhead. To do this, it only accepts `int` as
the device so we don't need to call `_get_device_index` and is implemented
with a new C++ helper `torch._C._cuda_exchangeDevice` that allows
`_DeviceGuard.__enter__` to be just a single function call. On my machine,
I see a drop from 3.8us of overhead to 0.94 us with this simple benchmark:
```python
def set_device():
with torch.cuda.device(0):
pass
%timeit set_device()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91045
Approved by: https://github.com/ngimel, https://github.com/anijain2305
#75854
A naive attempt at working around the limitations of using a single 64-bit integer to pack `stream_id`, `device_index`, and `device_type`.
Stills needs sanity checks, testing, and minimization of BC-breaking changes.
Currently a Holder for the `StreamData3` struct is used for `IValue` compatibility. While doing this seems to work for `ivalue.h` and `ivalue_inl.h`, this doesn't seem to be naively working for the JIT CUDA stream wrapper? (Something about ambiguous calls if an `intrusive_ptr` to `c10::ivalue::StreamData3Holder` is used as the return type for `pack()`. It turns out that the methods required to access the fields for rematerializing a CUDA Stream are basically already present anyway, so `pack` is simply removed in the wrapper for now and the methods to access the required fields are called directly.
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81596
Approved by: https://github.com/ezyang
Summary: * when we try to port py obj of script module/obj to c++, `tryToInferType` is flawed in providing type inference metadata. but change it would break normal torch.jit.script flow, so we try extract the ivalue in the py obj value.
Test Plan: NA
Reviewed By: PaliC
Differential Revision: D41749823
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91776
Approved by: https://github.com/842974287
#84624 introduces an update on `torch.norm` [dispatch logic](eaa43d9f25/torch/functional.py (L1489)) which now depends on `layout`. Resulting in regressions to export related operators from TorchScript.
This PR resolves the regression by partially supporting a subset use case of `prim::layout` (only `torch.strided`), `aten::__contains__` (only constants) operators. It requires much more effort to properly support other layouts, e.g. `torch.sparse_coo`. Extending JIT types, and supporting related family of ops like `aten::to_sparse`. This is out of the scope of this PR.
Fixes#83661
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91660
Approved by: https://github.com/justinchuby, https://github.com/kit1980
This applies some more clang-tidy fixups. Particularly, this applies the modernize loops and modernize-use-transparent-functors checks. Transparent functors are less error prone since you don't have to worry about accidentally specifying the wrong type and are newly available as of C++17.
Modern foreach loops tend be more readable and can be more efficient to iterate over since the loop condition is removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91449
Approved by: https://github.com/ezyang
Noticed the toSymFloat / toSymInt overloads always copied the internal pointer of an ivalue even if it was an rvalue unlike other overloads (like toTensor). This fixes that issue by adding the appropriate methods needed to facilitate that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91405
Approved by: https://github.com/ezyang
Apply clang-tidy check modernize-use-emplace. This is slightly more efficient by using an inplace constructor and is the recommended style in parts of the codebase covered by clang-tidy. This just manually applies the check to rest of the codebase. Pinging @ezyang as this is related to my other PRs he reviewed like #89000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91077
Approved by: https://github.com/ezyang
Avoid double exception in destructor if attempting to serialize to
python object that does not have `write` method
Use `Finalizer` class in `PyTorchStreamWriter::writeEndOfFile()` to a
always set `finailized_` property even if excretion occurs. (as there
isn't much one can do at this point)
Add expicit check for the attribue to `_open_zipfile_writer_buffer` and
add unitests
Modernize code a bit by using Python-3 `super()` method
Fixes https://github.com/pytorch/pytorch/issues/87997
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88128
Approved by: https://github.com/albanD
Fixes minor perf regression I saw in #85688 and replaced throughout the code base. `obj == Py_None` is directly equivalent to is_none(). Constructing a temporary py::none() object needlessly incref/decref the refcount of py::none, this method avoids that and therefore is more efficient.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88051
Approved by: https://github.com/albanD
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
At the moment, they were casted to `int64`, which breaks quite a few
casting rules for example in `ops.aten`.
Quite a vintage bug, circa 2020.
With this fix, the following code prints `torch.bool`, rather than `torch.int64`.
```python
import torch
msk = torch.tensor([False])
b = torch.tensor([False])
print(torch.ops.aten.where.ScalarSelf(msk, True, b).dtype)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87179
Approved by: https://github.com/albanD
# Support unpacking python dictionary in **torch.jit.trace()**
## Problem statement & Motivation
### Problem 1(usability):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=value1, key2=value2, key3=value3)`**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3, key2:value2}`**
The problem is that if you want to trace the model using the dict data by the giving dataset, you need unpack the dictionary and reorder its value manually and make up a tuple as **`data_tuple = (value1, value2, value3)`** as the **`example_inputs`** parameter of **`torch.jit.trace()`**. This marshalling process is not user friendly.
### Problem 2 (feasibility):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=None, key2=None, key3=None)`** -> The default value is **None**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3}`** -> Only **part of** the required value by forward was given, the rest use the default value.
The problem is that if you want to trace the model using the dict data by the giving dataset, it's not feasible at all. Cause neither you can pass a tuple like **`T1 = (value1, value3)`** nor **`T2 = (value1, None, value3)`**. T1 will mismatch value3 with key2 and T2 include **None** type which will be blocked by tracer's type checking. (Of course you can pass **`T3 = (value1,)`** to make the trace function finish without exception, but the traced model you get probably is not what you expect cause the different input may result in different traced result.).
These problems come from the HuggingFace's PT model, especially in text-classification tasks with datasets such as [MRPC,](https://paperswithcode.com/dataset/mrpc) [MNLI](https://paperswithcode.com/dataset/multinli) etc.
## Solution
To address these two issues, we propose to support a new type, that is, python dict as example_inputs parameter for torch.jit.trace(). We can base on the runtime type information of the example_inputs object to determine if we fall back to the original tuple path or go into the new dictionary path. Both problem 1 and problem 2 can be solved by utilizing the "**`**`**"
operator.
## Limitation & Mitigation
1. If we use dict as example_inputs to trace the model, then we have to pass a dictionary to the traced model too. (Cause probably we will change the order of debug name of the input parameter in torchscript IR, thus we can't assume the traced model's input parameters order are the same with the original model.). We need highlight this too in the document to mitigate this problem.
For example:
```
# fetch a data from dataloader, and the data is a dictionary
# and the example_inputs_dict is like: {key1:value1, key3:value3, key2:value2}
# the forward() is like: def forward(self, key1=value1, key2=value2, key3=value3)
example_inputs_dict = next(iter(dataloader))
jit_model = model.eval()
# use the dictionary to trace the model
jit_model = torch.jit.trace(jit_model, example_inputs_dict, strict=False) # Now the IR will be graph(%self : __torch__.module.___torch_mangle_n.Mymodule, %key1 : type1, %key3 : type3, %key2 : type2)
jit_model = torch.jit.freeze(jit_model)
# It's OK to use dict as the parameter for traced model
jit_model(**example_inputs_dict)
example_inputs_tuple = (value1, value3, value2)
# It's wrong to rely on the original args order.
jit_model(*example_inputs_tuple)
```
## Note
1. This PR will make some UT introduced in [39601](https://github.com/pytorch/pytorch/pull/39601) fail, which I think should be classified as unpacking a tuple containing a single dictionary element in our solution.
4. I think there is ambiguity since currently we only specify passing a tuple or a single Tensor as our example_inputs parameter in **torch.jit.trace()**'s documentation, but it seems we can still passing a dictionary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81623
Approved by: https://github.com/davidberard98
This reverts commit 978b46d7c9.
Reverted https://github.com/pytorch/pytorch/pull/86488 on behalf of https://github.com/osalpekar due to Broke executorch builds internally with the following message: RuntimeError: Missing out variant for functional op: aten::split.Tensor(Tensor(a -> *) self, SymInt split_size, int dim=0) -> Tensor(a)[] . Make sure you have loaded your custom_ops_generated_lib
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86488
Approved by: https://github.com/ezyang
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86334
Approved by: https://github.com/ezyang
- TensorGeometry supports symint
- check_size supports symint
- functorch batch rule improved symint
- Some operator support for symint in LTC
- More supported operations on SymInt and SymFloat
- More symint support in backwards formulas
This merge includes code contributions from bdhirsh and anjali411.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86160
Approved by: https://github.com/Chillee
We have logic that says if you ask for a SymIntList from an IValue, but the IValue is actually an IntList, we will still give it to you in that case (check ivalue_to_arg in aten/src/ATen/core/boxing/impl/make_boxed_from_unboxed_functor.h). However, we also need the *inverse* version of this logic, which says that if you construct an IValue from a SymIntArrayRef, and it is actually integer only, we need to store it as an IntList, so that toIntList on the IValue will work.
The way this works is a bit twisty, but our basic strategy is to disable construction of IValue from list container types that contain SymInt directly, and then directly implement variants of these constructors by hand, which iterate over the elements of the list and test if there are any SymInts or not to decide what type to construct the underlying List. These variants have to be templated, otherwise we will run afoul ambiguous overloads. I only did the overloads that actually occurred in practice; you may need to add more if you SymIntify more stuff.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86094
Approved by: https://github.com/anjali411, https://github.com/albanD
- Test for symbolic cases first before non-symbolic, as symbolic
ints/floats advertise as being ints/floats
- Add missing case for toPyObject
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86072
Approved by: https://github.com/wconstab
- Make toIValue accept SymIntNode and SymFloatNode where number (aka Scalar) is
expected
- Binding for symintlistOptional in python arg parser
- Teach translate to convert from IntArrayRef to ArrayRef<int64_t>
- Don't query _symint function for meta info in LTC unless LTC is
code generating a symint function
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86042
Approved by: https://github.com/Chillee
From the perspective of having valid sympy expressions for any given size/stride property, we can have tensors inherit SymInts from each other (in cases where the size expression is unchanged, which is a common case).
But we also use SymInts to let us build graph traces of our programs, and we need to be able to trace from a SymInt back to the tensor that it originated from in order to trace correct graphs. This change ensures each tensor starts with fresh SymInts.
- note: our policy has already been to use PySymIntNode objects to store pointers to proxy-tracer objects for use during tracing
- before making this change (to clone symints), sometimes we'd attempt to store more than one proxy-tracer object on the same symint and the last-stored one would clobber all the earlier ones. This would result in tracing the wrong graph in some cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85878
Approved by: https://github.com/ezyang
- Support storing SymFloat in IValue
- Add SymFloat to JIT type system (erases to float)
- Printing support for SymFloat
- add/sub/mul/truediv operator support for SymFloat
- Support truediv on integers, it returns a SymFloat
- Support parsing SymFloat from Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85411
Approved by: https://github.com/albanD
This allows you to explicitly guard on the specific integer value
of a SymInt so that you can condition on it. If possible, prefer
guarding on a boolean expression instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85139
Approved by: https://github.com/Chillee
Signed-off-by: Edward Z. Yang <ezyangfb.com>
From @ezyang's original PR:
There are a number of situations where we have non-backend kernels (e.g., CompositeImplicitAutograd, batching rules) which we would like to port to Python, but we have no way to integrate these ports with the overall system while using preexisting C++ registrations otherwise. This PR changes that by introducing a Python dispatcher (which can have its own kernels directly in Python), which can be interpose over ordinary C++ dispatch. The ingredients:
We introduce a new PythonDispatcher dispatch key, that has the same tenor as FuncTorchDynamicLayerFrontMode: it works by getting triggered before every other dispatch key in the dispatch key, and shunting to a Python implementation
The Python dispatcher is a per-interpreter global object that is enabled/disabled via the guard EnablePythonDispatcher/DisablePythonDispatcher. We don't make it compositional as I have no idea what a compositional version of this feature would look like. Because it is global, we don't need to memory manage it and so I use a simpler SafePyHandle (newly added) to control access to this pointer from non-Python C++. Like __torch_dispatch__, we use PyInterpreter to get to the Python interpreter to handle the dispatch.
I need to reimplement dispatch table computation logic in Python. To do this, I expose a lot more helper functions for doing computations on alias dispatch keys and similar. I also improve the pybind11 handling for DispatchKey so that you can either accept the pybind11 bound enum or a string; this simplifies our binding code. See https://github.com/pybind/pybind11/issues/483#issuecomment-1237418106 for how this works; the technique is generally useful.
I need to be able to call backend fallbacks. I do this by permitting you to call at a dispatch key which doesn't have a kernel for the operator; if the kernel doesn't exist, we check the backend fallback table instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84826
Approved by: https://github.com/ezyang
No changes to contents, just moving things out of header.
I only moved the stuff I suspected I'd be editing; maybe more
things from this header could migrate out.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84919
Approved by: https://github.com/suo
### Description
Add oneDNN graph context manager API to be consistent with other fusers.
NNC and nvFuser have two ways to use: 1) a function to enable/disable and 2) a context manager. And the later way is used extensively in libraries like Dynamo. Currently oneDNN Graph fuser only has the former way. To promote the usage of oneDNN graph fuser, this PR creates the context manager for oneDNN graph fuser.
This PR should not affect any performance.
### Testing
A unit-test `test_context_manager` is added under `test/test_jit_llga_fuser.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82491
Approved by: https://github.com/malfet
This caches the import of `torch.jit.ScriptModule`,
`torch.ScriptObject` and `torch.jit.RecursiveScriptClass`. I measure
a ~0.8 us performance uplift locally when calling a `torch.ops`
function with a `ScriptObject` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84399
Approved by: https://github.com/ezyang
When a torchbind class is returned from an operator, it has the class
`torch.ScriptObject`, yet the `torch.ops` interface checks against
`torch.jit.RecursiveScriptClass` or else falls back to a much slower
path that doesn't return the original c++ object.
On my machine I see a 2 us performance improvement when calling a
`torch.ops` function with a `ScriptObject` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84398
Approved by: https://github.com/ezyang
Adds support for constant tensor tracking within FakeTensors. Copy-pasta'ing from `proxy_tensor.py` why this is useful:
```
# In some circumstances, we will be tracing in a situation where a tensor
# is *statically* known to be a constant (currently, this only happens if
# you run torch.tensor; deterministic factory functions like torch.arange
# don't get this treatment). When the tensor in question is small, it's
# helpful to due constant propagation in case we call item() (in which
# case we can return the constant value that is known, rather than give
# an error.)
```
This PR only attempts to add support for the tracing scenarios where we run each operation linearly - aot autograd, torchdynamo. It does not yet handle how constant tensors should be handled as part of the persistent fx graph. Additionally, it does not yet attempt to de-duplicate or interact with ProxyMode's only constant tensor handling.
Edit: plan is to rely on functionalization for fx graph
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84387
Approved by: https://github.com/ezyang
Also Back out "Revert D39075159: [acc_tensor] Use SymIntArrayRef for overloaded empty.memory_format's signature"
Original commit changeset: dab4a9dba4fa
Original commit changeset: dcaf16c037a9
Original Phabricator Diff: D38984222
Original Phabricator Diff: D39075159
Also update Metal registrations for C++ registration changes.
Also update NNPI registration to account for tightened schema checking
Differential Revision: [D39084762](https://our.internmc.facebook.com/intern/diff/D39084762/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39084762/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84173
Approved by: https://github.com/Krovatkin
Summary:
This diff adds device side API which will convert the model to its
quantized equivalent. THe input model must have been prepared AOT for
quantization.
API is implemented by:
- Running reset obervers
- Running observe method
- Running quantize method
- And replacing method, e.g. forward, with its quantized equivalent.
Test Plan:
test/quantization/jit/test_ondevice_quantization.py
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38889818](https://our.internmc.facebook.com/intern/diff/D38889818)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83807
Approved by: https://github.com/iseeyuan
Summary:
After inserting quant dequant nodes in the graph, we need
1. Insert packed param creation and quantized op
2. Create packed_params attribute in the top module. For this we need
graph that inlined except for calculate_qparams method calls. But they
can be inlined too. So perhaps we need to make sure no other callmethods
exist.
3. Insert SetAttr for the packed param
4. Insert GetAttr for the packed param
5. Use GetAttr output for quantized op where applicable, e.g.
linear_dynamic
The above is added to quantize_<method-name> method created inprevious
step. Once the above steps are done clone the method into
quantized_<method-name>
Modify quantize_<method-name>:
1. Remove all outputs from the method.
2. Run dce
3. Remove all inputs from the method except self.
Modify quantized_<method-name>:
1. Remove all packed_param setAttr nodes.
2. Run dce.
This should result in removal of all nodes that generate packed param.
Test Plan: To be written
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771416](https://our.internmc.facebook.com/intern/diff/D38771416)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83571
Approved by: https://github.com/jerryzh168
Summary:
This diff adds a way to:
- clone previously observed method
- Add calls to observer's calculate_qparams methods
- Extract the scale and zero point
- Use them to insert quant dequant nodes
Now for forward method we have
- observe_forward
- quantize_forward
observe_forward is used post training to observer statistics. In the
case of dynamic PTQ this requires just running that method once to
update weight observer statistics.
quantize_forward method will be used to use the observer
statistics to calculate quantization parameters and apply that to quant
dequant op.
Subsequent diffs will replace dequant + op with their quantized op
counter parts and replace quantize ops with relevant packed params class
where possible
Test Plan:
To be written
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771419](https://our.internmc.facebook.com/intern/diff/D38771419)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83570
Approved by: https://github.com/jerryzh168
Summary:
TO support on device quantization this diff introduces observer
insertion. Specifically observers are inserted by adding new method with
prefix observ_.
Intent is that post training, this method will be run to record
statistics
Test Plan:
test_ondevice_quantization.py
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D38771417](https://our.internmc.facebook.com/intern/diff/D38771417)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83568
Approved by: https://github.com/jerryzh168
This PR adds nvfuser-specific primitive - `var_mean`.
Interpretation `torch.var_mean` -> `torch.ops.nvprims.var_mean` is handled by `TorchRefsNvfuserCapabilityMode` context manager.
I moved some helper code from `_prims/__init__.py` to `_prims_common`. Correctness is tested with OpInfo tests (see `PythonRefInfo("ops.nvprims.var_mean"`).
Layer norm reference now uses `torch.var_mean` instead of `torch._refs.var_mean` to allow interception. Here's a simple comparison of performance with this PR and master (on 3080ti):
```py
import torch
from torch._prims.context import TorchRefsNvfuserCapabilityMode
from torch.fx.experimental.proxy_tensor import make_fx
from torch._prims.executor import execute
def func(a):
return torch.native_layer_norm(a, (1024,), None, None, 1e-6)
a = torch.randn(10, 512, 1024, dtype=torch.float16, device="cuda")
with TorchRefsNvfuserCapabilityMode():
gm = make_fx(func)(a)
for _ in range(10):
execute(gm, a, executor="strictly_nvfuser");
```
run with `PYTORCH_NVFUSER_DUMP=dump_eff_bandwidth python script.py`
```py
# WITH THIS PR
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.033792 ms, achieved: 621.818 GB/s
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.032608 ms, achieved: 644.396 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.03072 ms, achieved: 684 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# ON MASTER
# kernel1 run in 0.05632 ms, achieved: 373.091 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.043808 ms, achieved: 479.649 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
```
So this PR gives about 35% improvement in performance using nvfuser executor with this specific normalized shape.
Also this PR fixes https://github.com/pytorch/pytorch/issues/83506 (see the change in `torch/csrc/jit/python/pybind_utils.cpp`).
Ref. https://github.com/pytorch/pytorch/issues/80187
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83508
Approved by: https://github.com/ngimel
This PR adds nvfuser-specific primitive - `var_mean`.
Interpretation `torch.var_mean` -> `torch.ops.nvprims.var_mean` is handled by `TorchRefsNvfuserCapabilityMode` context manager.
I moved some helper code from `_prims/__init__.py` to `_prims_common`. Correctness is tested with OpInfo tests (see `PythonRefInfo("ops.nvprims.var_mean"`).
Layer norm reference now uses `torch.var_mean` instead of `torch._refs.var_mean` to allow interception. Here's a simple comparison of performance with this PR and master (on 3080ti):
```py
import torch
from torch._prims.context import TorchRefsNvfuserCapabilityMode
from torch.fx.experimental.proxy_tensor import make_fx
from torch._prims.executor import execute
def func(a):
return torch.native_layer_norm(a, (1024,), None, None, 1e-6)
a = torch.randn(10, 512, 1024, dtype=torch.float16, device="cuda")
with TorchRefsNvfuserCapabilityMode():
gm = make_fx(func)(a)
for _ in range(10):
execute(gm, a, executor="strictly_nvfuser");
```
run with `PYTORCH_NVFUSER_DUMP=dump_eff_bandwidth python script.py`
```py
# WITH THIS PR
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.033792 ms, achieved: 621.818 GB/s
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.032608 ms, achieved: 644.396 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.032768 ms, achieved: 641.25 GB/s
# kernel1 run in 0.03072 ms, achieved: 684 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# kernel1 run in 0.031744 ms, achieved: 661.935 GB/s
# ON MASTER
# kernel1 run in 0.05632 ms, achieved: 373.091 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.043808 ms, achieved: 479.649 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.044032 ms, achieved: 477.209 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
# kernel1 run in 0.043008 ms, achieved: 488.571 GB/s
```
So this PR gives about 35% improvement in performance using nvfuser executor with this specific normalized shape.
Also this PR fixes https://github.com/pytorch/pytorch/issues/83506 (see the change in `torch/csrc/jit/python/pybind_utils.cpp`).
Ref. https://github.com/pytorch/pytorch/issues/80187
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83508
Approved by: https://github.com/ngimel
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
This allows you to directly call into the CompositeImplicitAutograd
implementation of an operator, *without* changing any aspects of the
dispatcher state. In particular, you can use this to recursively call
into a decomposition, dispatching back to your tensor subclass/mode
as desired.
Hypothetically, we should also make these available in the
decompositions dictionary, but I'm leaving this as future work as
enumerating these decompositions is annoying (as operators are lazily
registered.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83075
Approved by: https://github.com/albanD
### Description
Adding a custom caster for `c10::SymInt`. This simplifies handling of c10::SymInt on C++/Pytorch boundary. Namely, removing if statements to handle the union nature (e.g. SymIntNode, int) of c10::SymInt.
### Issue
<!-- Link to Issue ticket or RFP -->
### Testing
<!-- How did you test your change? -->
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82692
Approved by: https://github.com/ezyang
New namespace `torch.ops.nvprims` is meant for specific to the nvFuser set of primitives. All `impl_nvfuser` attributes are removed from `torch.ops.prims` functions.
`NvfuserPrimsMode()` context manager can be used for automatic rewrite of `torch.ops.prims` calls to `torch.ops.nvprims` when possible.
The previous way to test whether a prim would be executable with nvFuser was to test `impl_nvfuser is not None`, now all functions in the `torch.ops.nvprims` namespace are supposed to have the `impl_nvfuser` attribute and hence all are executable by nvFuser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82155
Approved by: https://github.com/jjsjann123, https://github.com/ngimel
### Description
Removed some stubbed out code that was necessary for ROCm builds to support JIT compilation of Event and Stream classes. Original motivation for the code to be stubbed out in the ROCm case was likely due to this pull request:
https://github.com/pytorch/pytorch/pull/48020
In this PR, the include statement at the at the top of cuda.h was incorrectly pointed to aten/src/ATen/cuda/CUDAEvent.h when it should have been set to ATen/cuda/CUDAEvent.h. This error caused the hipification process of build_amd.py to not hipify this include statement correctly, causing errors. The include statement in question was subsequently fixed in the following commit:
acd072967a
This PR re-introduces the stubbed out code to the ROCm build and "unskips" the associated unit tests.
### Testing
Note: bullets prepended by ROCm were tested on systems with AMD GPUs while the others were tested with NVIDIA GPUs.
- apply commit
- (ROCm)`python tools/amd_build/build_amd.py`
- `python setup.py develop`
- (ROCm)`PYTORCH_TEST_WITH_ROCM=1 python test/test_jit.py TestCUDA.test_event_args`
- (ROCm)`PYTORCH_TEST_WITH_ROCM=1 python test/test_jit.py TestCUDA.test_stream_args`
- `python test/test_jit.py TestCUDA.test_event_args`
- `python test/test_jit.py TestCUDA.test_stream_args`
- Confirm tests pass in all scenarios
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82346
Approved by: https://github.com/malfet
We define specializations for pybind11 defined templates
(in particular, PYBIND11_DECLARE_HOLDER_TYPE) and consequently
it is important that these specializations *always* be #include'd
when making use of pybind11 templates whose behavior depends on
these specializations, otherwise we can cause an ODR violation.
The easiest way to ensure that all the specializations are always
loaded is to designate a header (in this case, torch/csrc/util/pybind.h)
that ensures the specializations are defined, and then add a lint
to ensure this header is included whenever pybind11 headers are
included.
The existing grep linter didn't have enough knobs to do this
conveniently, so I added some features. I'm open to suggestions
for how to structure the features better. The main changes:
- Added an --allowlist-pattern flag, which turns off the grep lint
if some other line exists. This is used to stop the grep
lint from complaining about pybind11 includes if the util
include already exists.
- Added --match-first-only flag, which lets grep only match against
the first matching line. This is because, even if there are multiple
includes that are problematic, I only need to fix one of them.
We don't /really/ need this, but when I was running lintrunner -a
to fixup the preexisting codebase it was annoying without this,
as the lintrunner overall driver fails if there are multiple edits
on the same file.
I excluded any files that didn't otherwise have a dependency on
torch/ATen, this was mostly caffe2 and the valgrind wrapper compat
bindings.
Note the grep replacement is kind of crappy, but clang-tidy lint
cleaned it up in most cases.
See also https://github.com/pybind/pybind11/issues/4099
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82552
Approved by: https://github.com/albanD
Done via
```
git grep -l 'SymbolicIntNode' | xargs sed -i 's/SymbolicIntNode/SymIntNodeImpl/g'
```
Reasoning for the change:
* Sym is shorter than Symbolic, and consistent with SymInt
* You usually will deal in shared_ptr<...>, so we're going to
reserve the shorter name (SymIntNode) for the shared pointer.
But I don't want to update the Python name, so afterwards I ran
```
git grep -l _C.SymIntNodeImpl | xargs sed -i 's/_C.SymIntNodeImpl/_C.SymIntNode/'
```
and manually fixed up the binding code
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82350
Approved by: https://github.com/Krovatkin
- toTypeInferredIValue will throw an error when given an empty container because it isn't able to tell what kind of container it is. Thus empty containers are ignored in addArgumentValue/s, overlaps, and is_alias_of.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81786
Approved by: https://github.com/davidberard98
- Modify the is_mutable(size_t index) overload to become is_mutable(const SchemaArgument& argument) due to cases where one might want to check the mutability of either input or output arguments.
- Refactored all calls to the function to use this new overload
- Tested through is_mutable() tests in test_schema_info.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81784
Approved by: https://github.com/davidberard98
- Modified is_mutable python binding to accept a string instead of a string_view for better python compatibility.
- Modified argument value adding python bindings to deal with input/self edge case due to inconsistencies in how the first variable is named.
- Modified _is_alias_of and created _contains_alias_of python bindings to accurately find out if values are aliasing, or contain an alias.
- Fixed is_mutable implementation to cover all ops that have mutable optional arguments. (These are all the ops that have the optional arguments 'running_mean' and 'running_var' along with either 'train', 'training' or 'use_input_stats.'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81782
Approved by: https://github.com/davidberard98
Fix torch.save _open_zipfile_writer optimization that uses a c++ stream when `f` is a os.PathLike.
This fastpath requires that we don't `open()` in python if possible, so don't do it unconditionally.
Fix PyTorchStreamWriter construction binding that takes a buffer object.
Use py::memoryview instead of py::bytes as the former doesn't copy the data.
Validated with a trivial benchmark that calls torch.save in a loop 20x with a 10M elements float32 tensor
either on cpu or cuda. Saved to /dev/null.
Tried two variants 'str' and 'open'
In 'str' we pass the string "/dev/null" to torch.save.
In 'open' we pass `open("/dev/null", "wb")` to torch.save.
Timing in seconds.
Before this patch:
str-cpu :: 0.757
open-cpu :: 0.757
str-cuda :: 1.367
open-cuda :: 1.366
After this patch:
str-cpu :: 0.256
open-cpu :: 0.251
str-cuda :: 0.896
open-cuda :: 0.834
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80404
Approved by: https://github.com/jamesr66a
This PR adds support for `SymInt`s in python. Namely,
* `THPVariable_size` now returns `sym_sizes()`
* python arg parser is modified to parse PyObjects into ints and `SymbolicIntNode`s
* pybind11 bindings for `SymbolicIntNode` are added, so size expressions can be traced
* a large number of tests added to demonstrate how to implement python symints.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78135
Approved by: https://github.com/ezyang
Original PR: #77295
Original commit message:
On GPU, conv errors if not all its inputs have the same dtype.
In the case of autocasting during freezing, what we see is:
1) inputs to conv are casted to half
2) inputs to batchnorm are not casted, so many are still floats
3) we try to fold conv + batchnorm, by finding different weight and bias such that conv(input, new_weight, new_bias) is equivalent to the original conv -> batchnorm.
If conv previously had an optional bias, then during freezing we will temporarily create a zero-valued bias as a placeholder for conv_bias. We want to construct it to have the same dtype as the weight input to conv, to avoid errors on GPU.
Reland changes:
There's a memory leak from cuda caching allocator that is a side effect of this fix. The memory leak causes the test to fail, though for some reason it didn't fail on CI in the last PR. This skips the tests for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77617
Approved by: https://github.com/eellison
On GPU, conv errors if not all its inputs have the same dtype.
In the case of autocasting during freezing, what we see is:
1) inputs to conv are casted to half
2) inputs to batchnorm are not casted, so many are still floats
3) we try to fold conv + batchnorm, by finding different weight and bias such that conv(input, new_weight, new_bias) is equivalent to the original conv -> batchnorm.
If conv previously had an optional bias, then during freezing we will temporarily create a zero-valued bias as a placeholder for conv_bias. We want to construct it to have the same dtype as the weight input to conv, to avoid errors on GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77295
Approved by: https://github.com/eellison
Summary:
In order to categorize exceptions/errors, the observability /migration team faced a problem that currently the exception is shown as RuntimeError, and hard to categorize.
The solution to this problem is to be able to get the original python exception's class name and msg, and hopefully to recreate a python exception from that.
TO support this approach, we did the following in this diff:
(1) TorchScript to translate JITException so that it does not show as RuntimeError
(2) record python exception class name, original message during translation.
Then, later, the python exception can be reconstructed.
(3) Added a new decorator to reconstruct the python exception and then rethrow it.
Test Plan:
buck test //caffe2/torch/fb/translate_exception/tests:test_rethrow mode/dev-tsan
```
More details at https://www.internalfb.com/intern/buck/build/1180a788-3767-48e5-a64d-06d284b91a17
BUILD SUCCEEDED
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 24ae6c7c-a647-404e-8f12-d12c762bf728
Trace available for this run at /tmp/tpx-20220507-195320.698499-24ae6c7c-a647-404e-8f12-d12c762bf728/trace.log
RemoteExecution session id: reSessionID-24ae6c7c-a647-404e-8f12-d12c762bf728-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/8162774413147962
✓ ListingSuccess: caffe2/torch/fb/translate_exception/tests:test_rethrow : 3 tests discovered (27.233)
✓ Pass: caffe2/torch/fb/translate_exception/tests:test_rethrow - test_one_parameter (test_rethrow.TestTranslateRethrowPythonException) (28.467)
✓ Pass: caffe2/torch/fb/translate_exception/tests:test_rethrow - test_no_parameter (test_rethrow.TestTranslateRethrowPythonException) (28.495)
✓ Pass: caffe2/torch/fb/translate_exception/tests:test_rethrow - test_2_parameter_with_torch_script_only (test_rethrow.TestTranslateRethrowPythonException) (28.708)
Summary
Pass: 3
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/8162774413147962
```
Differential Revision: D36166520
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77093
Approved by: https://github.com/qihqi
Adds support for scripting ParameterDicts and getattr() on them. It does
not support iterating on ParameterDicts because torch/nn/container.py
implementation of ParameterDict.items() uses a generator, which is not
supported by torchscript. torch/nn/container.py would need to be updated
so that iter gets correctly registered in python_sugared_value.cpp
Added a test in test_module_containers.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77143
Approved by: https://github.com/eellison
Consider the following JIT graph, where the type of `%a` and `%b` are out of sync with tuple `%c`.
Before:
```
graph(%a : Float(123), %b : Float(4, 5, 6)):
c : (Tensor, Tensor) = prim::TupleConstruct(%a, %b)
return (%c)
```
After:
```
graph(%a : Float(123), %b : Float(4, 5, 6)):
c : (Float(123), Float(4, 5, 6)) = prim::TupleConstruct(%a, %b)
return (%c)
```
This PR adds a pass `RefineTypes(...)` to update all such instances with the correct type. This is also available via Python by using `torch._C._jit_pass_refine_types(...)`.
A unit test has been added for unnamed tuples, but no test exists for `NamedTuple` (though it was tested manually) since it isn't supported by the parser:
```
RuntimeError:
unknown type specifier:
graph(%a : Float(123), %b : Float(4, 5, 6)):
%c : NamedTuple(Tensor : Tuple, Tensor : Tuple) = prim::TupleConstruct(%a, %b)
~~~~~~~~~~ <--- HERE
return (%c)
```
cc: @ke1337 @antoniojkim @wconstab @eellison
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76919
Approved by: https://github.com/eellison
This makes prims look as if they were defined in native_functions.yaml
but they're still all written in Python. You now need to give a full
schema string for your prims. The returned prim object is now
torch.ops.prim overload (prims are not allowed to be overloaded,
so we return the overload, not the overload packet, for speed.)
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77117
Approved by: https://github.com/mruberry, https://github.com/albanD
For the most part, PrimTorch refs have the same signature as their
ATen equivalents. I modify most PrimTorch refs to register themselves
as decompositions, using the prim name they wrap to find the aten name
(except for a few cases where the prim/aten names mismatch). There are
some exclusions, falling into one of two categories:
- The torch equivalent was already implemented as a CompositeImplicitAutograd
decomposition in C++
- The ref doesn't support enough features (e.g., the real deal has more
kwargs / overloads than are currently implemented)
PrimTorch refs are written as a single function that supports all
overloads, and this style is convenient for cases where we have a bundle
of overloads for what morally is a single overload with a Union type
on an argument (which we ought to have supported in
native_functions.yaml but blah); to support registering a single decomp
for all the overloads, we modify register_decomposition to register
to ALL overloads if you pass it an overload packet. This is technically
BC breaking but no tests started failing because of it.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76835
Approved by: https://github.com/Chillee, https://github.com/mruberry
Re-landing #68111/#74596
## Description
v0.5 PR of this [RFC](https://github.com/pytorch/pytorch/issues/49444).
On the basis of #50256, the below improvements are included:
* The [v0.5 release branch](https://github.com/oneapi-src/oneDNN/releases/tag/graph-v0.5) of the oneDNN Graph API is used
* The fuser now works with the profiling graph executor. We have inserted type check nodes to guard the profiled tensor properties.
### User API:
The optimization pass is disabled by default. Users could enable it by:
```
torch.jit.enable_onednn_fusion(True)
```
`torch.jit.freeze` should be used after tracing (recommended) or scripting a model.
### Performance:
[pytorch/benchmark](https://github.com/pytorch/benchmark) tool is used to compare the performance:
* SkyLake 8180 (1 socket of 28 cores):

* SkyLake 8180 (single thread):

* By mapping hardswish to oneDNN Graph, it’s 8% faster than PyTorch JIT (NNC + OFI)
** We expect performance gain after mapping transpose, contiguous & view to oneDNN graph ops
### Directory structure of the integration code
Fuser-related code is placed under:
```
torch/csrc/jit/codegen/onednn/
```
Optimization pass registration is done in:
```
torch/csrc/jit/passes/onednn_graph_fuser.h
```
CMake for the integration code is in:
```
caffe2/CMakeLists.txt
cmake/public/mkldnn.cmake
cmake/Modules/FindMKLDNN.cmake
```
## Limitations
* In this PR, we only support Pytorch-oneDNN-Graph integration on Linux platform. Support on Windows and MacOS will be enabled as a next step.
* We have only optimized the inference use-case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76622
Approved by: https://github.com/eellison
This allows us to provide OpOverloadPacket.overloads method that
lists all of the overloads.
This isn't tested; will be exercised in the next PR.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76814
Approved by: https://github.com/mruberry
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73284
Some important ops won't support optional type until opset 16,
so we can't fully test things end-to-end, but I believe this should
be all that's needed. Once ONNX Runtime supports opset 16,
we can do more testing and fix any remaining bugs.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D34625646
Pulled By: malfet
fbshipit-source-id: 537fcbc1e9d87686cc61f5bd66a997e99cec287b
Co-authored-by: BowenBao <bowbao@microsoft.com>
Co-authored-by: neginraoof <neginmr@utexas.edu>
Co-authored-by: Nikita Shulga <nshulga@fb.com>
(cherry picked from commit 822e79f31ae54d73407f34f166b654f4ba115ea5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76485
Adds an environment variable `PYTORCH_JIT_ENABLE_NVFUSER` for
controlling whether or not nvfuser is enabled. This required changing
the PassManager behavior to support the case where nvfuser gets enabled
by default when PYTORCH_JIT_ENABLE_NVFUSER=1.
Previously the solution for turning nvfuser on or off was to use the
PassManager to register or un-register the pass. That works fine if the
pass starts of _disabled_, but causes issues once we try to enable the
pass by default.
The main issue with enabling by default is with the validation check to
see whether NVFuser can be turned on. The check relies on
at::globalContext().hasCUDA(), which requires CUDAHooks to be registered
before hasCUDA() wil work correctly. At static initialization time it's
difficult to ensure that CUDAHooks will be registered _before_ we
attempt to register the nvfuser pass. In OSS it worked fine, but in
internal builds it would fail on ROCm builds.
To fix this, we switch the control of NVFuser enablement to a check in
the pass. i.e. previously, we enabled/disabled nvfuser by registering or
de-registering the pass in pass manager; now, the pass is always
registered in pass manager, and enablement is done by a check within the
nvfuser pass.
Remaining TODO: Connect this with NNC so that in cases where NNC is
available but not NVFuser (i.e. on AMD gpus), NNC can be turned on
automatically.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D35982618
Pulled By: davidberard98
fbshipit-source-id: fd5b76bc0b8c8716c96fdc04bebfb15026a7ef60
(cherry picked from commit ff14603ff5ac8d9b6c749c4f111f4a8be8023b7f)
- Allow registering custom decompositions
- Add easier API for invoking decompositions
- Shorten API names (no users yet)
I am doing these as one pr because they are fairly short/simple and because github first does not support ghstack yet.
cc @Chillee @zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76252
Approved by: https://github.com/davidberard98
Summary:
## Original commit message:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73368
debug_pkl file inside of pytorch's .pt file consists of a list of SourceRanges. Each SourceRange points to a Source which is a stack track, filename, and start, end numbers. Those are emitted in debug_pkl file as strings.
Since many SourceRange shares the same source, the string for trace can be deduped.
The newer format saves a set of unique traces in a tuple, then each SourceRange will save the offset of it's trace w.r.t. position in that tuple. (i.e. manually applying dictionary compression).
The above helps with smaller file size. On loading, if we copy each trace to Source as string the runtime memory would still blowup.
To mitigate this, we use SourceView directly instead of source which will take the reference of string inside of Deserializer and make that into string_view. This is safe because Deserializer is hold by Unpickler by shared_ptr, and Unpickler is also hold by shared_ptr by another Source object. That Source object will be alive during the model construction.
Test Plan:
## Original Test plan
unit test
Took original file (312271638_930.predictor.disagg.local); loaded with `torch.jit.load` save again with `torch.jit.save`. Unzip both, look at contents:
```
[qihan@devvm5585.vll0 ~]$ du archive -h
4.0K archive/xl_model_weights
3.7M archive/extra
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K archive/code/__torch__/caffe2/torch/fb/model_transform
8.0K archive/code/__torch__/caffe2/torch/fb
8.0K archive/code/__torch__/caffe2/torch
8.0K archive/code/__torch__/caffe2
20M archive/code/__torch__/torch/fx/graph_module
20M archive/code/__torch__/torch/fx
8.0K archive/code/__torch__/torch/classes
20M archive/code/__torch__/torch
20M archive/code/__torch__
20M archive/code
2.7M archive/constants
35M archive
[qihan@devvm5585.vll0 ~]$ du resaved -h
4.0K resaved/extra
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform/splitting
8.0K resaved/code/__torch__/caffe2/torch/fb/model_transform
8.0K resaved/code/__torch__/caffe2/torch/fb
8.0K resaved/code/__torch__/caffe2/torch
8.0K resaved/code/__torch__/caffe2
1.3M resaved/code/__torch__/torch/fx/graph_module
1.3M resaved/code/__torch__/torch/fx
8.0K resaved/code/__torch__/torch/classes
1.4M resaved/code/__torch__/torch
1.4M resaved/code/__torch__
1.4M resaved/code
2.7M resaved/constants
13M resaved
[qihan@devvm5585.vll0 ~]$
```
## Additional test:
`buck test mode/dev-tsan //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- --exact 'caffe2/benchmarks/static_runtime:static_runtime_cpptest - StaticRuntime.to'` passes
test jest.fbios.startup_cold_start.local.simulator f333356873 -
Differential Revision: D35196883
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74869
Approved by: https://github.com/gmagogsfm
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74785
Fix for https://github.com/facebookresearch/torchdynamo/issues/93
Because the constructor follow a non-standard input schema (variadic integers), they are handled specially in ir_emitter.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D35362762
Pulled By: eellison
fbshipit-source-id: 960badf08ba2ab0818af5fd331aff3542051250f
(cherry picked from commit bd579dead5a5206fc6e5b535ecf4f99ae67ee135)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75119
Add support for parsing Tensor constants like Double(4, 4) ... by initializing random tensors. This makes saving IR and then parsing it lossy, so I have it toggled as default not on, but is useful in cases like repro-ing Fusions with tensor constants post-freezing.
cc Krovatkin
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D35373999
Pulled By: eellison
fbshipit-source-id: a5c8d9f93f23a7442258fc745ed6b6def330dca8
(cherry picked from commit 32dd6567522973563bd452bf486ed27b02e4e35c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74361
This adds an optional validation after executing an NVFuser node, which checks that the output is the same as the unfused implementation. Then the outputs and the graph are reported via a callback.
```python
import torch
def callback(x, y, graph):
for i in range(len(x)-amt, len(x)):
print(x[i])
print(y[i])
print(graph)
with torch.jit.fuser("fuser2"):
torch._C._jit_nvfuser_set_comparison_callback(True, callback)
torch.jit.script
def g(x, y):
z = torch.add(x, y)
return torch.sin(z)
def f(x, y, a):
z = torch.add(x, y)
return g(torch.relu(z), a)
f_s = torch.jit.script(f)
x = torch.rand((10, 10), dtype=torch.half).cuda()
y = torch.rand((10, 10), dtype=torch.half).cuda()
a = torch.rand((10, 10), dtype=torch.half).cuda()
f_s(x, y, a)
f_s(x, y, a)
f_s(x, y, a)
```
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D34975310
Pulled By: davidberard98
fbshipit-source-id: 2379c9a6f371cd58da6a187c1f16882f3923ab24
(cherry picked from commit 96c87992c65f5e6bb1bdd51791682dd837af99b4)
Summary:
This PR introduces `SymInt` type to Pytorch which will be used by LTC and AOTAutograd for tracing size arithmetic and tests.
`SymInt` is a C++ union structure [int64_t, SymbolicIntNode*] that wraps around an int64_t field where the value of the field could be an index into a list of `shared_ptr<SymbolicIntNode>` or a real int.
This PR doesn't add any support for actually tracing symbolic ints. i.e. data_ for now can only contain real ints.
```
Goal 1: just to show we can add a type to PyTorch core. (wraps int) LANDEABLE
Finalize the naming - symint
Want the name to be short
Does invoke “size” - NO
SInt/SymInt/SymbolicInt
SInt could mean signed int
sym_int or symint or SymInt (originally it was “int”; capitalized implies object semantics, whereas lowercase implies value semantics)
JIT schema - symint
C++ - symint
```
See more details here: https://docs.google.com/document/d/1iiLNwR5ohAsw_ymfnOpDsyF6L9RTUaHMpD8 (d843f63f2a)YLw-jxEw
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74861
Reviewed By: qihqi, ngimel
Differential Revision: D35226230
Pulled By: Krovatkin
fbshipit-source-id: 34acf342bd50fcaa4d8d5dd49c2fd6a98823a5b3
(cherry picked from commit 218643f63ef181cabb92d13a6e837eb64f2dda3c)
This is a technical revert of 6d36bbde7e to reconcile it with e50478c02592597f12b8490ec5496f76c7d8b8cc (which is the same + lint changes applied)
Should be skipped during import
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73938
This is a first step in porting and making usable all of the decompositions defined in [functorch](https://github.com/pytorch/functorch/blob/main/functorch/_src/decompositions.py#L349) in core and in JIT as well as C++.
The decompositions are defined in python, scripted and inlined, and then serialized as C++ code which TorchScript can parse. The workflow is edit python decomposition file then run [tools/codegen/decompositions/gen_jit_decompositions.py](https://github.com/pytorch/pytorch/pull/73938/files#diff-6adef2116be233c3524e3b583e373ab0ffc9169beb6c1f6d96b5d0385e75afa1).
Decompositions are mapped to their corresponding aten schemas via the schema in their python def. This allows multiple decompositions for an overloaded op like `aten.var` (shown here in the example).
This is just a first PR, i'm sure there will be many follows ups such as:
- making these runnable in C++ with simple executor
- porting over more decompositions from AOT Autograd
- Using opinfos / more robust testing
- Categorizing decompositions
- Hooking in decompositions at various points of JIT execution
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D34938126
Pulled By: eellison
fbshipit-source-id: 9559a7cb731982e3a726f2f95af498b84fb09c13
(cherry picked from commit a4e0e748791e378e7e12a9dd0b63fb3c62dc1890)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73875
Previously we had a few settings:
- getExecutor - which toggled between Profiling Executor and Legacy
- getGraphOptimize - if true, overrides PE/Legacy to run with simple executor (no optimizations)
and then...
- getProfilingMode - which would set PE to 0 specializtions.
The last mode is redundant with getGraphOptimize, we should just remove it and use getGraphOptimize in these cases. It would lead to potentially invalid combinations of logic - what does mean if getProfilingMode is true but getExecutor is set to false ? This would lead to a bug in specialize_autograd_zero in this case, see: https://github.com/pytorch/pytorch/blob/master/torch%2Fcsrc%2Fjit%2Fpasses%2Fspecialize_autogradzero.cpp#L93.
The tests here are failing but get fixed with the PR above it, so i'll squash for landing.
Test Plan: Imported from OSS
Reviewed By: cpuhrsch
Differential Revision: D34938130
Pulled By: eellison
fbshipit-source-id: 1a9c0ae7f6d1cfddc2ed3499a5af611053ae5e1b
(cherry picked from commit cf69ce3d155ba7d334022c42fb2cee54bb088c23)
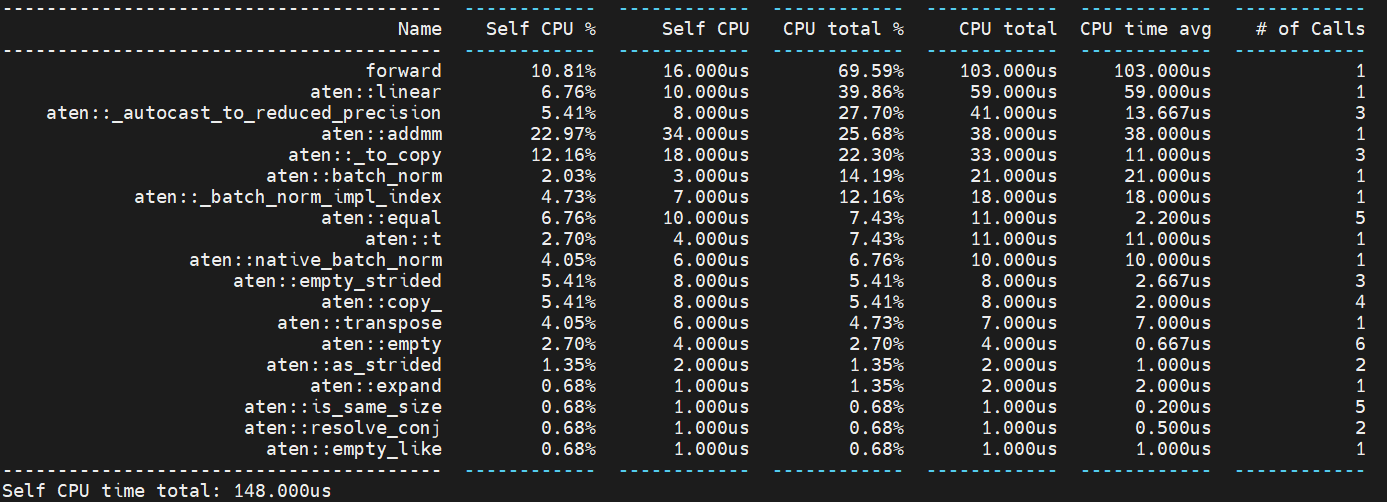{kind=link}
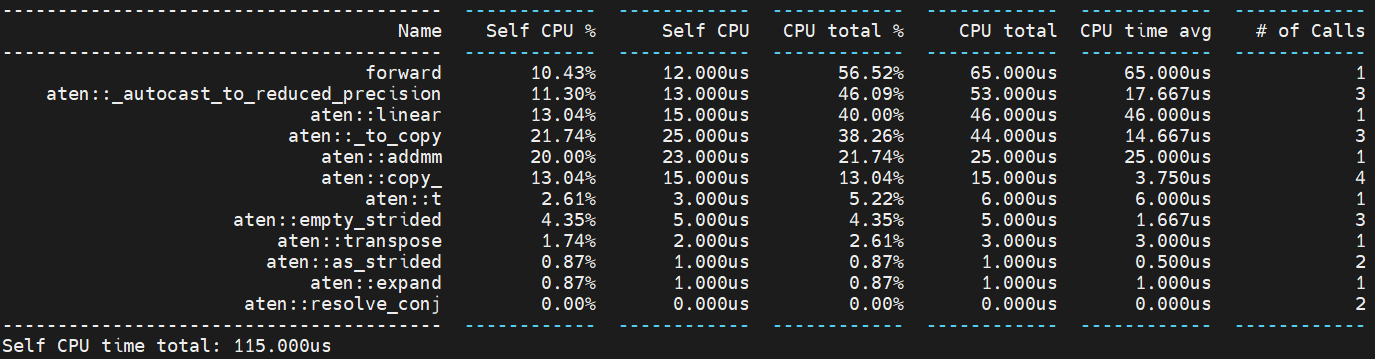{kind=link}
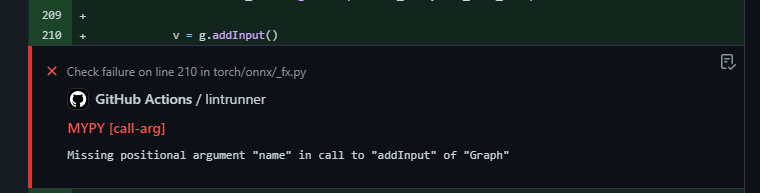{kind=link}
{kind=link}
{kind=link}