Summary: The current C shim layer manually implements a C interface for a handful of ops. Obviously that's not scalable if we want to extend it to cover all aten ops. This new torchgen script automatically generates C shim interfaces for CPU and CUDA backends. The interface follows the same parameter passing rules as the current C shim layer, such as
* Use plain C data types to pass parameters
* Use AtenTensorHandle to pass at::Tensor
* Use pointer type to pass optional parameter
* Use pointer+length to pass list
* Use device_type+device_index to pass device
* When a parameter is a pointer of pointer, e.g. AtenTensorHandle**, the script generates either a list of optional values or an optional list of values
https://gist.github.com/desertfire/83701532b126c6d34dae6ba68a1b074a is an example of the generated torch/csrc/inductor/aoti_torch/generated/c_shim_cuda.cpp file. The current version doesn't generate C shim wrappers for all aten ops, and probably generates more wrappers than needed on the other hand, but it should serve as a good basis.
This PR by itself won't change AOTI codegen and thus won't introduce any FC breakage. The actual wrapper codegen changes will come in another PR with some version control flag to avoid FC breakage.
Differential Revision: [D54258087](https://our.internmc.facebook.com/intern/diff/D54258087)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/120513
Approved by: https://github.com/jansel
Summary:
Expose an option to users to specify name of the LogsSpec implementation to use.
- Has to be defined in entrypoints under `torchrun.logs_specs` group.
- Must implement LogsSpec defined in prior PR/diff.
Test Plan: unit test+local tests
Reviewed By: ezyang
Differential Revision: D54180838
Pull Request resolved: https://github.com/pytorch/pytorch/pull/120942
Approved by: https://github.com/ezyang
Some operations, such as GEMMs, could be implemented using more than one library or more than one technique. For example, a GEMM could be implemented for CUDA or ROCm using either the blas or blasLt libraries. Further, ROCm's rocblas and hipblaslt libraries allow the user to query for all possible algorithms and then choose one. How does one know which implementation is the fastest and should be chosen? That's what TunableOp provides.
See the README.md for additional details.
TunableOp was ported from onnxruntime starting from commit 08dce54266. The content was significantly modified and reorganized for use within PyTorch. The files copied and their approximate new names or source content location within aten/src/ATen/cuda/tunable include the following:
- onnxruntime/core/framework/tunable.h -> Tunable.h
- onnxruntime/core/framework/tuning_context.h -> Tunable.h
- onnxruntime/core/framework/tuning_context_impl.h -> Tunable.cpp
- onnxruntime/core/providers/rocm/tunable/gemm_common.h -> GemmCommon.h
- onnxruntime/core/providers/rocm/tunable/gemm_hipblaslt.h -> GemmHipblaslt.h
- onnxruntime/core/providers/rocm/tunable/gemm_rocblas.h -> GemmRocblas.h
- onnxruntime/core/providers/rocm/tunable/gemm_tunable.cuh -> TunableGemm.h
- onnxruntime/core/providers/rocm/tunable/rocm_tuning_context.cc -> Tunable.cpp
- onnxruntime/core/providers/rocm/tunable/util.h -> StreamTimer.h
- onnxruntime/core/providers/rocm/tunable/util.cc -> StreamTimer.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114894
Approved by: https://github.com/xw285cornell, https://github.com/jianyuh
# Motivation
According to [[1/4] Intel GPU Runtime Upstreaming for Device](https://github.com/pytorch/pytorch/pull/116019), As mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), this third PR covers the changes under `libtorch_python`.
# Design
This PR primarily offers device-related APIs in python frontend, including
- `torch.xpu.is_available`
- `torch.xpu.device_count`
- `torch.xpu.current_device`
- `torch.xpu.set_device`
- `torch.xpu.device`
- `torch.xpu.device_of`
- `torch.xpu.get_device_name`
- `torch.xpu.get_device_capability`
- `torch.xpu.get_device_properties`
- ====================
- `torch.xpu._DeviceGuard`
- `torch.xpu._is_compiled`
- `torch.xpu._get_device`
# Additional Context
We will implement the support of lazy initialization in the next PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116850
Approved by: https://github.com/EikanWang, https://github.com/jgong5, https://github.com/gujinghui, https://github.com/malfet
Summary:
This diff implements a mechanism for safely update torch.export serialization schema, aka schema.py, which is the API surface having the strongest compatibility guarantee.
The diff is consist of 3 changes:
- Added a script to "build" or "materialize" schema.py into a platform neutral format (yaml), which serves as the committed form of the seialization schema.
- Added unittest to compare against schema.py and schema.yaml, so that it forces developers to execute the updater script when there is mismatch between two files.
- Added a checker inside the updater script, so that all the compatible change will result in a minor version bump, and all the incompatible changes will result in a major version bump.
torch.export's serialization BC/FC policy is (tentatively) documented here: https://docs.google.com/document/d/1EN7JrHbOPDhbpLDtiYG4_BPUs7PttpXlbZ27FuwKhxg/edit#heading=h.pup7ir8rqjhx , we will update the
As noted in the code doc, people should be able to run the following command to update schema properly from now on:
```
python scripts/export/update_schema.py --prefix <path_to_torch_development_diretory>
or
buck run caffe2:export_update_schema -- --prefix /data/users/$USER/fbsource/fbcode/caffe2/
```
Test Plan:
buck test mode/opt caffe2/test:test_export -- -r test_schema
buck run caffe2:update_export_schema -- --prefix /data/users/$USER/fbsource/fbcode/caffe2/
Differential Revision: D52971020
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118424
Approved by: https://github.com/angelayi
Fixes #ISSUE_NUMBER
We are trying to adapt `SparsePrivateUse1` in our code. However, I found that `sparse_stup` has not been exposed yet, which makes it impossible for me to implement stup and register. I hope that the header files in this directory can be exposed. @albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118274
Approved by: https://github.com/ezyang
Fix https://github.com/pytorch/pytorch/issues/97352.
This PR changes the way the linking to intel MKL is done and updating MKL on Windows to mkl-2021.4.0 .
There are for both conda and pip packages MKL version with which you can link dynamically. mkl-devel contains the static versions of the dlls and MKL contains the needed dlls for the runtime. MKL dlls and static libs starting with 2021.4.0 have the version in their names( for MKL 2023 we have mkl_core.2.dll and for 2021.4.0 we have mkl_core.1.dll) so its possible to have multiple versions installed and it will work properly.
For the wheel build, I added dependency for whell MKL and on conda a dependecy for the conda MKL and on libtorch I copied the MKL binaries in libtorch.
In order to test this PR I have to use custom builder https://github.com/pytorch/builder/pull/1467
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102604
Approved by: https://github.com/IvanYashchuk, https://github.com/malfet
# Motivation
As mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), The first runtime component we would like to upstream is `Device` which contains the device management functions of Intel GPU's runtime. To facilitate the code review, we split the code changes into 4 PRs. This is one of the 4 PRs and covers the changes under `c10`.
# Design
Intel GPU device is a wrapper of sycl device on which kernels can be executed. In our design, we will maintain a sycl device pool containing all the GPU devices of the current machine, and manage the status of the device pool by PyTorch. The thread local safe is considered in this design. The corresponding C++ files related to `Device` will be placed in c10/xpu folder. And we provide the c10 device runtime APIs, like
- `c10::xpu::device_count`
- `c10::xpu::set_device`
- ...
# Additional Context
In our plan, 4 PRs should be submitted to PyTorch for `Device`:
1. for c10
2. for aten
3. for python frontend
4. for lazy initialization shared with CUDA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116019
Approved by: https://github.com/gujinghui, https://github.com/jgong5, https://github.com/EikanWang, https://github.com/malfet
# Motivation
As mentioned in [[RFC] Intel GPU Runtime Upstreaming](https://github.com/pytorch/pytorch/issues/114842), The first runtime component we would like to upstream is `Device` which contains the device management functions of Intel GPU's runtime. To facilitate the code review, we split the code changes into 4 PRs. This is one of the 4 PRs and covers the changes under `c10`.
# Design
Intel GPU device is a wrapper of sycl device on which kernels can be executed. In our design, we will maintain a sycl device pool containing all the GPU devices of the current machine, and manage the status of the device pool by PyTorch. The thread local safe is considered in this design. The corresponding C++ files related to `Device` will be placed in c10/xpu folder. And we provide the c10 device runtime APIs, like
- `c10::xpu::device_count`
- `c10::xpu::set_device`
- ...
# Additional Context
In our plan, 4 PRs should be submitted to PyTorch for `Device`:
1. for c10
2. for aten
3. for python frontend
4. for lazy initialization shared with CUDA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116019
Approved by: https://github.com/gujinghui, https://github.com/jgong5, https://github.com/EikanWang, https://github.com/malfet
Related to #103973#110532#108404#94891
**Context:**
As commented in 6ae0554d11/cmake/Dependencies.cmake (L1198)
Kernel asserts are enabled by default for CUDA and disabled for ROCm.
However it is somewhat broken, and Kernel assert was still enabled for ROCm.
Disabling kernel assert is also needed for users who do not have PCIe atomics support. These community users have verified that disabling the kernel assert in PyTorch/ROCm platform fixed their pytorch workflow, like torch.sum script, stable-diffusion. (see the related issues)
**Changes:**
This pull request serves the following purposes:
* Refactor and clean up the logic, make it simpler for ROCm to enable and disable Kernel Asserts
* Fix the bug that Kernel Asserts for ROCm was not disabled by default.
Specifically,
- Renamed `TORCH_DISABLE_GPU_ASSERTS` to `C10_USE_ROCM_KERNEL_ASSERT` for the following reasons:
(1) This variable only applies to ROCm.
(2) The new name is more align with #define CUDA_KERNEL_ASSERT function.
(3) With USE_ in front of the name, we can easily control it with environment variable to turn on and off this feature during build (e.g. `USE_ROCM_KERNEL_ASSERT=1 python setup.py develop` will enable kernel assert for ROCm build).
- Get rid of the `ROCM_FORCE_ENABLE_GPU_ASSERTS' to simplify the logic and make it easier to understand and maintain
- Added `#cmakedefine` to carry over the CMake variable to C++
**Tests:**
(1) build with default mode and verify that USE_ROCM_KERNEL_ASSERT is OFF(0), and kernel assert is disabled:
```
python setup.py develop
```
Verify CMakeCache.txt has correct value.
```
/xxxx/pytorch/build$ grep USE_ROCM_KERNEL_ASSERT CMakeCache.txt
USE_ROCM_KERNEL_ASSERT:BOOL=0
```
Tested the following code in ROCm build and CUDA build, and expected the return code differently.
```
subprocess.call([sys.executable, '-c', "import torch;torch._assert_async(torch.tensor(0,device='cuda'));torch.cuda.synchronize()"])
```
This piece of code is adapted from below unit test to get around the limitation that this unit test now was skipped for ROCm. (We will check to enable this unit test in the future)
```
python test/test_cuda_expandable_segments.py -k test_fixed_cuda_assert_async
```
Ran the following script, expecting r ==0 since the CUDA_KERNEL_ASSERT is defined as nothing:
```
>> import sys
>>> import subprocess
>>> r=subprocess.call([sys.executable, '-c', "import torch;torch._assert_async(torch.tensor(0,device='cuda'));torch.cuda.synchronize()"])
>>> r
0
```
(2) Enable the kernel assert by building with USE_ROCM_KERNEL_ASSERT=1, or USE_ROCM_KERNEL_ASSERT=ON
```
USE_ROCM_KERNEL_ASSERT=1 python setup.py develop
```
Verify `USE_ROCM_KERNEL_ASSERT` is `1`
```
/xxxx/pytorch/build$ grep USE_ROCM_KERNEL_ASSERT CMakeCache.txt
USE_ROCM_KERNEL_ASSERT:BOOL=1
```
Run the assert test, and expected return code not equal to 0.
```
>> import sys
>>> import subprocess
>>> r=subprocess.call([sys.executable, '-c', "import torch;torch._assert_async(torch.tensor(0,device='cuda'));torch.cuda.synchronize()"])
>>>/xxxx/pytorch/aten/src/ATen/native/hip/TensorCompare.hip:108: _assert_async_cuda_kernel: Device-side assertion `input[0] != 0' failed.
:0:rocdevice.cpp :2690: 2435301199202 us: [pid:206019 tid:0x7f6cf0a77700] Callback: Queue 0x7f64e8400000 aborting with error : HSA_STATUS_ERROR_EXCEPTION: An HSAIL operation resulted in a hardware exception. code: 0x1016
>>> r
-6
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114660
Approved by: https://github.com/jeffdaily, https://github.com/malfet, https://github.com/jithunnair-amd
Fixes#113940. This vendors the relevant parts of [`packaging==23.2.0`]() to have access to `Version` and `InvalidVersion` without taking a runtime dependency on `setuptools` or `packaging`.
I didn't find any vendoring policy so I put it under `torch._vendor.packaging`. While I have only vendored the files we need, I have not touched or trimmed the files otherwise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/114108
Approved by: https://github.com/malfet, https://github.com/albanD
Building with `USE_CUSTOM_DEBINFO=torch/csrc/Module.cpp python setup.py develop` for example will provide debug info only for this file.
This allows to enable debug symbols very fast from a non-debug build by doing a clean then develop (as long as you have ccache) and avoid very large binaries that take a very long time to load in gdb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111748
Approved by: https://github.com/drisspg, https://github.com/ezyang, https://github.com/malfet
Removes the existing integration code & build of nvfuser in TorchScript.
Note that I intentionally left the part where we wipe out `third_party/nvfuser` repo. I'll do that in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111093
Approved by: https://github.com/albanD
Summary:
This PR adds a limited C shim layer for libtorch. The ultimate goal is to ban any direct reference to aten/c10 data structures or functions, to avoid ABI breakage by providing stable C interfaces.
To make the review and landing easier, we broke the changes into several steps. In this PR (a combination of https://github.com/pytorch/pytorch/pull/109022 and https://github.com/pytorch/pytorch/pull/109351), we add C interfaces for certain libtorch functions and modify the wrapper codegen to generate calls to those interfaces. There are a few other items to be addressed in future PRs:
* The AOTInductor runtime interface still takes lists of aten tensors as input and output
* The interaction with ProxyExecutor (general fallback support) needs to move away from aten tensor
* Remove all references to aten/c10 headers in the AOTInductor-generated code
Differential Revision: D49302669
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109391
Approved by: https://github.com/chenyang78
# Motivate
Without this PR, if we would like to include the header file like ```#include <ATen/native/ForeachUtils.h>``` in our C++ extension, it will raise a Error ```/home/xxx/torch/include/ATen/native/ForeachUtils.h:7:10: fatal error: 'ATen/native/utils/ParamsHash.h' file not found```. We should fix it.
# Solution
Add the ATen/native/utils header file in the build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109013
Approved by: https://github.com/ezyang
Summary: Move AOTInductor runtime header files into its own subdirectory, to separate them from to-be-added libtorch C interface.
Reviewed By: frank-wei
Differential Revision: D48905038
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108564
Approved by: https://github.com/frank-wei
The dependency was added twice before in CUDA and ROCm binaries, one as an installation dependency from builder and the later as an extra dependency for dynamo, for example:
```
Requires-Python: >=3.8.0
Description-Content-Type: text/markdown
License-File: LICENSE
License-File: NOTICE
Requires-Dist: filelock
Requires-Dist: typing-extensions
Requires-Dist: sympy
Requires-Dist: networkx
Requires-Dist: jinja2
Requires-Dist: fsspec
Requires-Dist: pytorch-triton (==2.1.0+e6216047b8)
Provides-Extra: dynamo
Requires-Dist: pytorch-triton (==2.1.0+e6216047b8) ; extra == 'dynamo'
Requires-Dist: jinja2 ; extra == 'dynamo'
Provides-Extra: opt-einsum
Requires-Dist: opt-einsum (>=3.3) ; extra == 'opt-einsum'
```
In the previous release, we needed to remove this part from `setup.py` to build release binaries https://github.com/pytorch/pytorch/pull/96010. With this, that step isn't needed anymore because the dependency will come from builder.
### Testing
Using the draft https://github.com/pytorch/pytorch/pull/108374 for testing and manually inspect the wheels artifact at https://github.com/pytorch/pytorch/actions/runs/6045878399 (don't want to go through all `ciflow/binaries` again)
* torch-2.1.0.dev20230901+cu121-cp39-cp39-linux_x86_64
```
Requires-Python: >=3.8.0
Description-Content-Type: text/markdown
Requires-Dist: filelock
Requires-Dist: typing-extensions
Requires-Dist: sympy
Requires-Dist: networkx
Requires-Dist: jinja2
Requires-Dist: fsspec
Requires-Dist: pytorch-triton (==2.1.0+e6216047b8) <-- This will be 2.1.0 on the release branch after https://github.com/pytorch/builder/pull/1515
Provides-Extra: dynamo
Requires-Dist: jinja2 ; extra == 'dynamo'
Provides-Extra: opt-einsum
Requires-Dist: opt-einsum (>=3.3) ; extra == 'opt-einsum'
```
* torch-2.1.0.dev20230901+cu121.with.pypi.cudnn-cp39-cp39-linux_x86_64
```
Requires-Python: >=3.8.0
Description-Content-Type: text/markdown
Requires-Dist: filelock
Requires-Dist: typing-extensions
Requires-Dist: sympy
Requires-Dist: networkx
Requires-Dist: jinja2
Requires-Dist: fsspec
Requires-Dist: pytorch-triton (==2.1.0+e6216047b8)
Requires-Dist: nvidia-cuda-nvrtc-cu12 (==12.1.105) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cuda-runtime-cu12 (==12.1.105) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cuda-cupti-cu12 (==12.1.105) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cudnn-cu12 (==8.9.2.26) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cublas-cu12 (==12.1.3.1) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cufft-cu12 (==11.0.2.54) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-curand-cu12 (==10.3.2.106) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cusolver-cu12 (==11.4.5.107) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cusparse-cu12 (==12.1.0.106) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-nccl-cu12 (==2.18.1) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-nvtx-cu12 (==12.1.105) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: triton (==2.1.0) ; platform_system == "Linux" and platform_machine == "x86_64" <--This is 2.1.0 because it already has https://github.com/pytorch/pytorch/pull/108423, but the package doesn't exist yet atm
Provides-Extra: dynamo
Requires-Dist: jinja2 ; extra == 'dynamo'
Provides-Extra: opt-einsum
Requires-Dist: opt-einsum (>=3.3) ; extra == 'opt-einsum'
```
* torch-2.1.0.dev20230901+rocm5.6-cp38-cp38-linux_x86_64
```
Requires-Python: >=3.8.0
Description-Content-Type: text/markdown
Requires-Dist: filelock
Requires-Dist: typing-extensions
Requires-Dist: sympy
Requires-Dist: networkx
Requires-Dist: jinja2
Requires-Dist: fsspec
Requires-Dist: pytorch-triton-rocm (==2.1.0+34f8189eae) <-- This will be 2.1.0 on the release branch after https://github.com/pytorch/builder/pull/1515
Provides-Extra: dynamo
Requires-Dist: jinja2 ; extra == 'dynamo'
Provides-Extra: opt-einsum
Requires-Dist: opt-einsum (>=3.3) ; extra == 'opt-einsum'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108424
Approved by: https://github.com/atalman
PR #90689 replaces NVTX with NVTX3. However, the torch::nvtoolsext is created only when the third party NVTX is used.
This is clear a logical error. We now move the creation code out of the branch to cover all cases. This should fix the issues reported in the comments of #90689.
It would be better to move configurations of the failed FRL jobs to CI tests so that we can find such issues early before merging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97582
Approved by: https://github.com/peterbell10
Summary:
This stack of PR's integrates cuSPARSELt into PyTorch.
This PR adds support for cuSPARSELt into the build process.
It adds in a new flag, USE_CUSPARSELT that defaults to false.
When USE_CUSPASRELT=1 is specified, the user can also specify
CUSPASRELT_ROOT, which defines the path to the library.
Compiling pytorch with cusparselt support can be done as follows:
``
USE_CUSPARSELT=1
CUSPARSELT_ROOT=/path/to/cusparselt
python setup.py develop
```
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103700
Approved by: https://github.com/albanD
This change adds the TensorPipe header files to `torch_package_data` if `USE_DISTRIBUTED` is set to `ON` in the CMake cache. The TensorPipe library and CMake config is already available in the Torch wheel, but the headers are not. This resolves issue where out-of-tree backends could not implement TensorPipe converters, because the definition of the `tensorpipe::Message` struct is defined in the TensorPipe headers.
Fixes#105224.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105521
Approved by: https://github.com/albanD
Summary:
Original PR at https://github.com/pytorch/pytorch/pull/104977. Landing from fbcode instead.
Add an aot_inductor backend (Export+AOTInductor) in the benchmarking harness. Note it is not a dynamo backend.
Moved files from torch/_inductor/aot_inductor_include to torch/csrc/inductor as a more standard way for exposing headers
Created a caching function in benchmarks/dynamo/common.py for compiling, loading and caching the .so file, as a proxy for a pure C++ deployment, but easier for benchmarking.
Differential Revision: D47452591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105221
Approved by: https://github.com/jansel
This PR combines the C++ code for the AOTInductor's model and interface with Bin Bao's changes to AOTInductor codegen.
It adds a number of AOTInductor C interfaces that can be used by an inference runtime. Under the hood of the interfaces, the model code generated by the AOTInductor's codegen is wrapped into a class, AOTInductorModel, which manages tensors and run the model inference.
On top of AOTInductorModel, we provide one more abstract layer, AOTInductorModelContainer, which allows the user to have multiple inference runs concurrently for the same model.
This PR also adjusts the compilation options for AOT codegen, particularly some fbcode-related changes such as libs to be linked and header-file search paths.
Note that this is the very first version of the AOTInductor model and interface, so many features (e.g. dynamic shape) are incomplete. We will support those missing features in in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104202
Approved by: https://github.com/desertfire
Now, when you do an inplace mutation and the view is naughty, you get this message:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). To find out where this view was allocated, run your entire forward region under anomaly mode (torch.autograd.detect_anomaly(check_nan=False)).
```
When you run under anomaly mode, you get:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). This view was allocated at:
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4299, in arglebargle
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4306, in test_anomaly_gives_view_stack
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 591, in run
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2266, in _run_with_retry
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2337, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 650, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/runner.py", line 184, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 271, in runTests
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 101, in __init__
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 894, in run_tests
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 11209, in <module>
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103185
Approved by: https://github.com/zdevito
Updating the pin to the same hash as https://github.com/pytorch/pytorch/pull/100922
On the XLA side, build have switch from CMake to bazel, which requires number of changes on PyTorch side:
- Copy installed headers back to the `torch/` folder before starting the build
- Install `torch/csrc/lazy/python/python_utils.h`
- Define `LD_LIBRARY_PATH`
TODO:
- Enable bazel caching
- Pass CXX11_ABI flag to `//test/cpp:all` to reuse build artifacts from `//:_XLAC.so`
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at cd4768b</samp>
> _To fix the XLA tests that were failing_
> _We updated the submodule and scaling_
> _We added `python_util.h`_
> _And copied `torch` as well_
> _And set `LD_LIBRARY_PATH` for linking_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102446
Approved by: https://github.com/huydhn
Failing mechanism on #95424 :
In dynamo mode, when passing numpy.int_ to 'shape' like param (Sequence[Union[int, symint]]) is wrapped as list with FakeTensor. However, in python_arg_parser, parser expect int in symint_list but got FakeTensor.
Following #85759, this PR allow tensor element in symint_list when in dynamo mode
This PR also fix below test with similar failing mechanism
pytest ./generated/test_huggingface_diffusers.py -k test_016
pytest ./generated/test_ustcml_RecStudio.py -k test_036
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97508
Approved by: https://github.com/yanboliang
implementation of DataPtr context for copy-on-write tensors
Summary:
Copy-on-write storage
=====================
This library adds support for copy-on-write storage, i.e. lazy copies,
to tensors. The design maintains the PyTorch invariant that tensors
alias if and only if they share a storage. Thus, tensors that are lazy
copies of one another will have distinct storages that share a data
allocation.
Thread-safety
-------------
The correctness of this design hinges on the pre-existing PyTorch user
requirement (and general default programming assumption) that users
are responsible for guaranteeing that writes do not take places
concurrently with reads and other writes.
Lazily copied tensors add a complication to this programming model
because users are not required to know if lazy copies exist and are
not required to serialize writes across lazy copies. For example: two
tensors with distinct storages that share a copy-on-write data context
may be given to different threads that may do whatever they wish to
them, and the runtime is required to guarantee its safety.
It turns out that this is not that difficult to protect because, due
to the copy-on-write requirement, we just need to materialize a tensor
upon writing. This could be done entirely without synchronization if
we materialized each copy, however, we have a common-sense
optimization to elide the copy for the last remaining reference. This
requires waiting for any pending copies.
### Thread-safety detailed design
There are two operations that affect the copy-on-write details of a
tensor:
1) lazy-clone (e.g. an explicit call or a hidden implementation detail
added through an operator like reshape)
2) materialization (i.e. any write to the tensor)
The key insight that we exploit is that lazy-clone is logically a read
operation and materialization is logically a write operation. This
means that, for a given set of tensors that share a storage, if
materialization is taking place, no other read operation, including
lazy-clone, can be concurrent with it.
However, this insight only applies within a set of tensors that share
a storage. We also have to be concerned with tensors with different
storages that share a copy-on-write context. In this world,
materialization can race with lazy-clone or even other
materializations. _However_, in order for this to be the case, there
must be _at least_ two references to the context. This means that the
context _can not_ vanish out from under you if you are performing a
lazy-clone, and hence, it only requires an atomic refcount bump.
The most complicated case is that all lazy-copies are concurrently
materializing. In this case, because a write is occurring, there are
no in-flight lazy-copies taking place. We must simply ensure that all
lazy-copies are able to materialize (read the data) concurrently. If
we didn't have the aforementioned optimization where the last copy
steals the data, we could get away with no locking whatsoever: each
makes a copy and decrements the refcount. However, because of the
optimization, we require the loser of the materializing race wait for
the pending copies to finish, and then steal the data without copying
it.
We implement this by taking a shared lock when copying the data and
taking an exclusive lock when stealing the data. The exclusive lock
acquisition ensures that all pending shared locks are finished before
we steal the data.
Test Plan: 100% code coverage.
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/100818).
* #100821
* #100820
* #100819
* __->__ #100818
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100818
Approved by: https://github.com/ezyang
Follow up for https://github.com/pytorch/pytorch/pull/96532. Including this in setup.py so the package will be available for CI.
Fsspec package size:
```
du -h /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
264K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/__pycache__
58K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations/__pycache__
377K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations
1017K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec
96K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/EGG-INFO
1.2M /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99768
Approved by: https://github.com/kit1980
Add a PrivateUse1 folder to contain all the feature adaptations for PrivateUse1 under Aten,For example GetGeneratorPrivate which is used for the three-party backend to register his own Generator implementation.This makes it easier for us to centrally manage these features, and it will increase the convenience of adaptation for different back-end manufacturers. For more info: https://github.com/pytorch/pytorch/issues/98073
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98127
Approved by: https://github.com/bdhirsh
1. Packaging nvfuser header for support c++ build against nvfuser;
2. Moving `#include <torch/csrc/jit/codegen/fuser/interface.h>` from `torch/csrc/jit/runtime/register_ops_utils.h` to `torch/csrc/jit/runtime/register_prim_ops_fulljit.cpp` to avoid missing header, since pytorch doesn't package `interface.h`;
3. Patching DynamicLibrary load of nvfuser to leak the handle, this avoids double de-allocation of `libnvfuser_codegen.so`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97404
Approved by: https://github.com/davidberard98
Summary:
Extra C binding module for flatbuffer was introduced because
not all dependencies of Pytorch want (or can) bundle in flatbuffer.
However, flatbuffer is in by default now so this separate binding is not longer needed.
Test Plan: existing unit tests
Differential Revision: D44352583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97476
Approved by: https://github.com/dbort
This PR do two things:
1. It moves some Windows warning suppression from various CMake files into the main CMakeList.txt, following the conventions of gcc and clang.
2. It fixes some Windows warnings in the source code. Most importantly, it fixes lots of dll warnings by adjusting C10_API to TORCH_API or TORCH_PYTHON_API. There are still some dll warnings because some TORCH_API functions are actually built as part of libtorch_python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94927
Approved by: https://github.com/malfet
Add triton support for ROCm builds of PyTorch.
* Enables inductor and dynamo when rocm is detected
* Adds support for pytorch-triton-mlir backend
* Adds check_rocm support for verify_dynamo.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94660
Approved by: https://github.com/malfet
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
setup.py clean now won't remove paths matching .gitignore patterns across the entire OS. Instead, now only files from the repository will be removed.
`/build_*` had to be removed from .gitignore because with the wildcard fixed, build_variables.bzl file was deleted on cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91503
Approved by: https://github.com/soumith
Summary:
This diff is reverting D42257039
D42257039 has been identified to be causing the following test or build failures:
Tests affected:
- [assistant/neural_dm/rl/modules/tests:action_mask_classifier_test - main](https://www.internalfb.com/intern/test/281475048940766/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1493969
Here are the tasks that are relevant to this breakage:
T93770103: 1 test started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: weiwangmeta
Differential Revision: D42272391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91548
Approved by: https://github.com/kit1980
## Job
Test running on most CI jobs.
## Test binary
* `test_main.cpp`: entry for gtest
* `test_operator_registration.cpp`: test cases for gtest
## Helper sources
* `operator_registry.h/cpp`: simple operator registry for testing purpose.
* `Evalue.h`: a boxed data type that wraps ATen types, for testing purpose.
* `selected_operators.yaml`: operators Executorch care about so far, we should cover all of them.
## Templates
* `NativeFunctions.h`: for generating headers for native functions. (not compiled in the test, since we will be using `libtorch`)
* `RegisterCodegenUnboxedKernels.cpp`: for registering boxed operators.
* `Functions.h`: for declaring operator C++ APIs. Generated `Functions.h` merely wraps `ATen/Functions.h`.
## Build files
* `CMakeLists.txt`: generate code to register ops.
* `build.sh`: driver file, to be called by CI job.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89596
Approved by: https://github.com/ezyang
E.g. `test_cpp_extensions_aot_ninja` fails as it includes `vec.h` which requires the vec/vsx/* headers and `sleef.h`. The latter is also required for AVX512 builds on non MSVC compilers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85547
Approved by: https://github.com/kit1980
In this PR, we replace OMP SIMD with `aten::vec` to optimize TorchInductor vectorization performance. Take `res=torch.exp(torch.add(x, y))` as the example. The generated code is as follows if `config.cpp.simdlen` is 8.
```C++
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
float* __restrict__ out_ptr0,
const long ks0,
const long ks1)
{
#pragma omp parallel num_threads(48)
{
#pragma omp for
for(long i0=0; i0<((ks0*ks1) / 8); ++i0)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 + tmp1;
auto tmp3 = tmp2.exp();
tmp3.store(out_ptr0 + 8*i0);
}
#pragma omp for simd simdlen(4)
for(long i0=8*(((ks0*ks1) / 8)); i0<ks0*ks1; ++i0)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 + tmp1;
auto tmp3 = std::exp(tmp2);
out_ptr0[i0] = tmp3;
}
}
}
```
The major pipeline is as follows.
- Check whether the loop body could be vectorized by `aten::vec`. The checker consists of two parts. [One ](bf66991fc4/torch/_inductor/codegen/cpp.py (L702))is to check whether all the `ops` have been supported. The [other one](355326faa3/torch/_inductor/codegen/cpp.py (L672)) is to check whether the data access could be vectorized.
- [`CppSimdVecKernelChecker`](355326faa3/torch/_inductor/codegen/cpp.py (L655))
- Create the `aten::vec` kernel and original omp simd kernel. Regarding the original omp simd kernel, it serves for the tail loop when the loop is vectorized.
- [`CppSimdVecKernel`](355326faa3/torch/_inductor/codegen/cpp.py (L601))
- [`CppSimdVecOverrides`](355326faa3/torch/_inductor/codegen/cpp.py (L159)): The ops that we have supported on the top of `aten::vec`
- Create kernel
- [`aten::vec` kernel](355326faa3/torch/_inductor/codegen/cpp.py (L924))
- [`Original CPP kernel - OMP SIMD`](355326faa3/torch/_inductor/codegen/cpp.py (L929))
- Generate code
- [`CppKernelProxy`](355326faa3/torch/_inductor/codegen/cpp.py (L753)) is used to combine the `aten::vec` kernel and original cpp kernel
- [Vectorize the most inner loop](355326faa3/torch/_inductor/codegen/cpp.py (L753))
- [Generate code](355326faa3/torch/_inductor/codegen/cpp.py (L821))
Next steps:
- [x] Support reduction
- [x] Vectorize the tail loop with `aten::vec`
- [ ] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87068
Approved by: https://github.com/jgong5, https://github.com/jansel
Adds `/FS` option to `CMAKE_CXX_FLAGS` and `CMAKE_CUDA_FLAGS`.
So far I've encountered this kind of errors:
```
C:\Users\MyUser\AppData\Local\Temp\tmpxft_00004728_00000000-7_cuda.cudafe1.cpp: fatal error C1041: cannot open program database 'C:\Projects\pytorch\build\third_party\gloo\gloo\CMakeFiles\gloo_cuda.dir\vc140.pdb'; if multiple CL.EXE write to the same .PDB file, please use /FS
```
when building with VS 2022.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
Related issues:
- https://github.com/pytorch/pytorch/issues/87691
- https://github.com/pytorch/pytorch/issues/39989
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88084
Approved by: https://github.com/ezyang
Also, add `torchtriton` and `jinja2` as extra `dynamo` dependency to PyTorch wheels,
Version packages as first 10 characters of pinned repo hash and make `torch[dynamo]` wheel depend on the exact version it was build against.
TODO: Automate uploading to nightly wheels storage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87234
Approved by: https://github.com/msaroufim
The legacy profiler is an eyesore in the autograd folder. At this point the implementation is almost completely decoupled from the rest of profiler, and it is in maintaince mode pending deprecation.
As a result, I'm moving it to `torch/csrc/profiler/standalone`. Unfortuantely BC requires that the symbols remain in `torch::autograd::profiler`, so I've put some basic forwarding logic in `torch/csrc/autograd/profiler.h`.
One strange bit is that `profiler_legacy.h` forward declares `torch::autograd::Node`, but doesn't seem to do anything with it. I think we can delete it, but I want to test to make sure.
(Note: this should not land until https://github.com/pytorch/torchrec/pull/595 is landed.)
Differential Revision: [D39108648](https://our.internmc.facebook.com/intern/diff/D39108648/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85512
Approved by: https://github.com/aaronenyeshi
There is a concept in profiler of a stub that wraps a profiling API. It was introduced for CUDA profiling before Kineto, and ITT has adopted it to call into VTune APIs. However for the most part we don't really interact with them when developing the PyTorch profiler.
Thus it makes sense to unify the fallback registration mechanism and create a subfolder to free up real estate in the top level `torch/csrc/profiler` directory.
Differential Revision: [D39108647](https://our.internmc.facebook.com/intern/diff/D39108647/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85510
Approved by: https://github.com/aaronenyeshi
https://github.com/pytorch/pytorch/pull/85780 updated all c10d headers in pytorch to use absolute path following the other distributed components. However, the headers were still copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch`, thus external extentions still have to reference the c10d headers as `<c10d/*.h>`, making the usage inconsistent (the only exception was c10d/exception.h, which was copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`).
This patch fixes the installation step to copy all c10d headers to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`, thus external extensions can consistently reference c10d headers with the absolute path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86257
Approved by: https://github.com/kumpera
Depends on https://github.com/pytorch/pytorch/pull/84890.
This PR adds opt_einsum to CI, enabling path optimization for the multi-input case. It also updates the installation sites to install torch with einsum, but those are mostly to make sure it would work on the user's end (as opt-einsum would have already been installed in the docker or in prior set up steps).
This PR also updates the windows build_pytorch.bat script to use the same bdist_wheel and install commands as on Linux, replacing the `setup.py install` that'll become deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85574
Approved by: https://github.com/huydhn, https://github.com/soulitzer
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
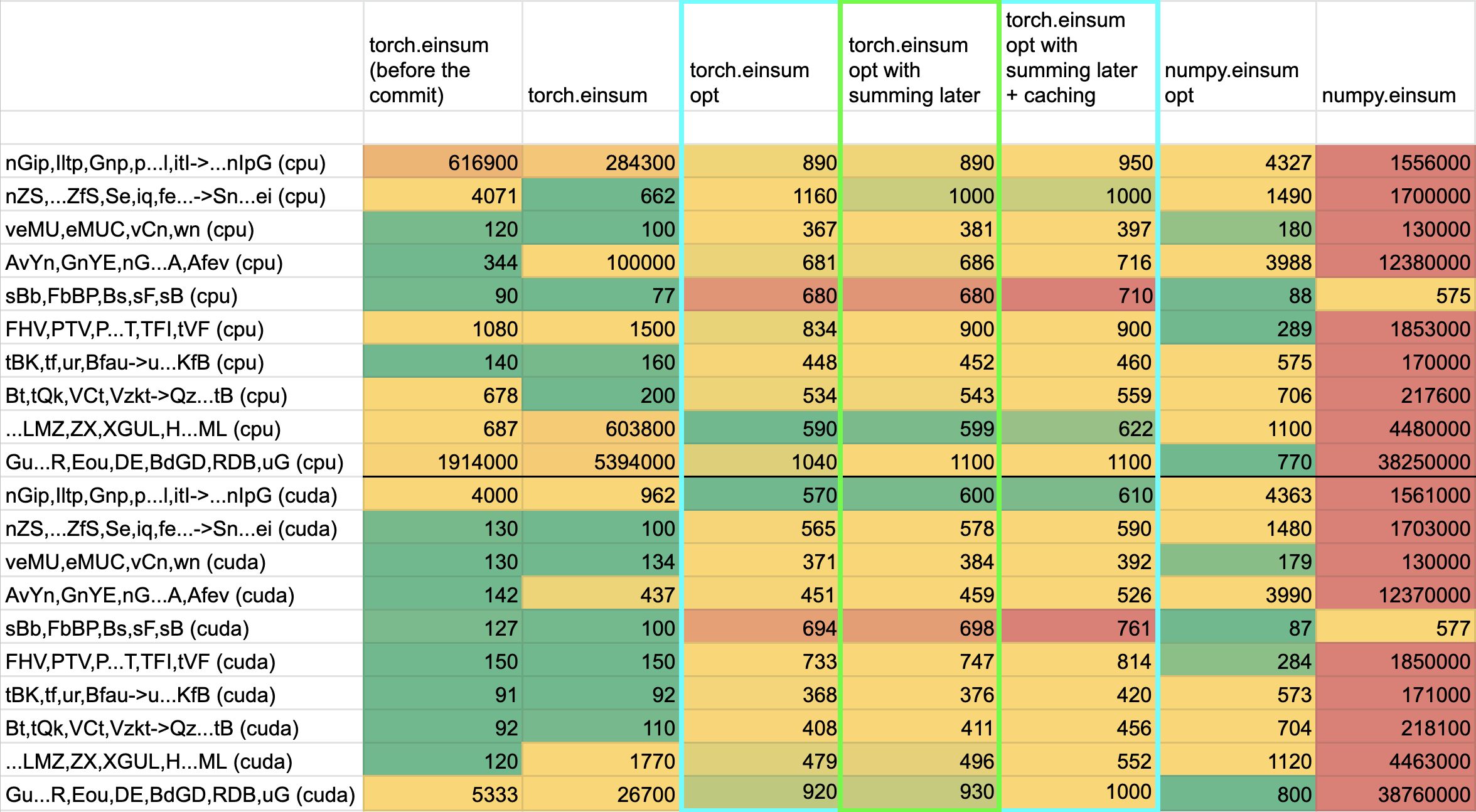
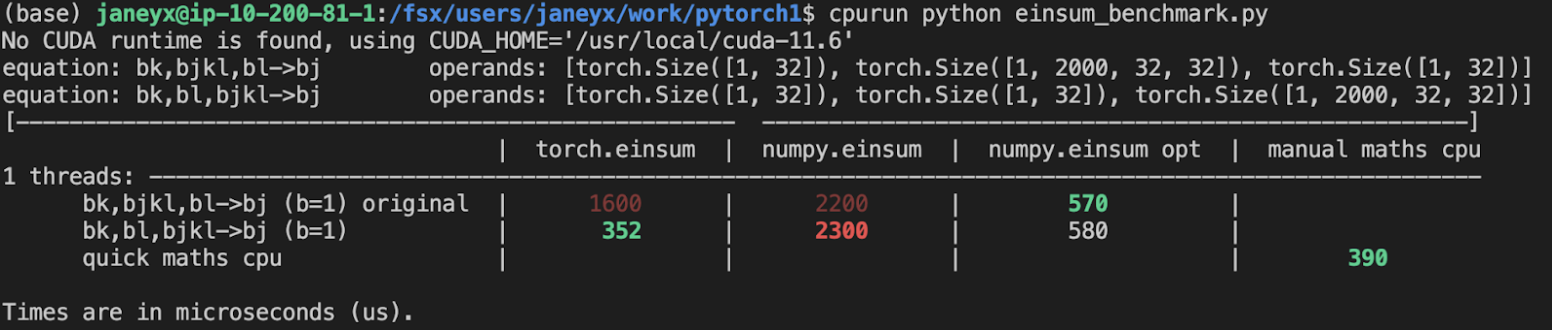
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Move functorch/functorch into `functorch` folder
- Add functorch/CMakeLists.txt that adds `functorch` native python exension
- Modify `setup.py` to package pytorch and functorch together into a single wheel
- Modify `functorch.__version__` is not equal to that of `torch.__version__`
- Add dummy `functorch/setup.py` file for the projects that still want to build it
Differential Revision: [D39058811](https://our.internmc.facebook.com/intern/diff/D39058811)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83464
Approved by: https://github.com/zou3519
# Summary:
- I added a new submodule Cutlass pointing to 2.10 release. The inclusion of flash_attention code should be gated by the flag: USE_FLASH_ATTENTION. This is defaulted to off resulting in flash to not be build anywhere. This is done on purpose since we don't have A100 machines to compile and test on.
- Only looked at CMake did not attempt bazel or buck yet.
- I included the mha_fwd from flash_attention that has ben refactored to use cutlass 2.10. There is currently no backwards kernel on this branch. That would be a good follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81434
Approved by: https://github.com/cpuhrsch
Fixes#81181 by creating a temporary LICENCE file that has all the third-party licenses concatenated together when creating a wheel. Also update the `third_party/LICENSES_BUNDLED.txt` file.
The `third_party/LICENSES_BUNDLED.txt` file is supposed to be tested via `tests/test_license.py`, but the test is not running?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81500
Approved by: https://github.com/rgommers, https://github.com/seemethere
Description:
While using Pytorch header
"torch/csrc/jit/serialization/export.h" got compilation error.
File export_bytecode.h accesses
"#include <torch/csrc/jit/mobile/function.h>"
This mobile folder isn't present in torch installation dir.
This PR adds mobile folder to torch installation setup.
Fixes#79190
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79864
Approved by: https://github.com/ngimel
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Bug fixes and minor refactor
Squashed commits to WAR github API
Commits that's actually in this PR from the devel branch:
```
4c60e7dff22a494632370e5df55c011007340d06 Add examples infrastructure for using nvFuser in a standalone program (#1725)
02a05d98334ffa580d73ccb28fdb8c577ad296fe Fix issue #1751 (#1753)
8a69aa320bd7629e1709fe5ceb7104d2c88ec84c Refactor NvFuser transpose API to match eager mode behavior (#1746)
ffdf6b7709048170d768217fcd7083fc8387f932 Remove BroadcastWithoutStride. (#1738)
02bab16035e70734450c02124f5cdaa95cf5749d Fix flipping of a boolean flag (#1745)
465d66890c8242e811224359cbdb1c2915490741 cleanup (#1744)
26d354e68720bc7dd2d3b1338ac01b707a230b6a fixing noncontig broadcast (#1742)
856b6b2f9073662dd98ca22ba6c3540e20eb1cdd Add IterDomainBuilder (#1736)
1fd974f912cd4c1e21cbd16e2abb23598d66a02f fixing warning for gcc7 (#1732)
de2740a43a869f8272c2648e091d7b8235097db9 disabling complex in python tests for #1730 (#1733)
fbbbe0a2e7c7a63e0e2719b8bfccb759b714221a fixing MSVC build (#1728)
b5feee5e2b28be688dbddc766f3c0220389c8175 Fix the fused reduction runtime kernel (#1729)
5247682dff5980bb66edf8d3aac25dea2ef2ced5 Re-entrant GroupedGridReduction (#1727)
```
RUN_TORCHBENCH: nvfuser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79147
Approved by: https://github.com/davidberard98
Package config/template files with torchgen
This PR packages native_functions.yaml, tags.yaml and ATen/templates
with torchgen.
This PR:
- adds a step to setup.py to copy the relevant files over into torchgen
- adds a docstring for torchgen (so `import torchgen; help(torchgen)`
says something)
- adds a helper function in torchgen so you can get the torchgen root
directory (and figure out where the packaged files are)
- changes some scripts to explicitly pass the location of torchgen,
which will be helpful for the first item in the Future section.
Future
======
- torchgen, when invoked from the command line, should use sources
in torchgen/packaged instead of aten/src. I'm unable to do this because
people (aka PyTorch CI) invokes `python -m torchgen.gen` without
installing torchgen.
- the source of truth for all of these files should be in torchgen.
This is a bit annoying to execute on due to potential merge conflicts
and dealing with merge systems
- CI and testing. The way things are set up right now is really fragile,
we should have a CI job for torchgen.
Test Plan
=========
I ran the following locally:
```
python -m torchgen.gen -s torchgen/packaged
```
and verified that it outputted files.
Furthermore, I did a setup.py install and checked that the files are
actually being packaged with torchgen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78942
Approved by: https://github.com/ezyang
Fixes#78490
Following command:
```
conda install pytorch torchvision torchaudio -c pytorch-nightly
```
Installs libiomp . Hence we don't want to package libiomp with conda installs. However, we still keep it for libtorch and wheels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78632
Approved by: https://github.com/malfet
Next stage of breaking up https://github.com/pytorch/pytorch/pull/74710
IR builder class introduced to decouple the explicit usage of `TsNode` in core lazy tensors.
Requires https://github.com/pytorch/pytorch/pull/75324 to be merged in first.
**Background**
- there are ~ 5 special ops used in lazy core but defined as :public {Backend}Node. (DeviceData, Expand, Scalar...)
- we currently require all nodes derive from {Backend}Node, so that backends can make this assumption safely
- it is hard to have shared 'IR classes' in core/ because they depend on 'Node'
**Motivation**
1. avoid copy-paste of "special" node classes for each backend
2. in general decouple and remove all dependencies that LTC has on the TS backend
**Summary of changes**
- new 'IRBuilder' interface that knows how to make 5 special ops
- move 'special' node classes to `ts_backend/`
- implement TSIRBuilder that makes the special TS Nodes
- new backend interface API to get the IRBuilder
- update core code to call the builder
CC: @wconstab @JackCaoG @henrytwo
Partially Fixes#74628
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75433
Approved by: https://github.com/wconstab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74387
Make temporary python bindings for flatbuffer to test ScriptModule save / load.
(Note: this ignores all push blocking failures!)
Test Plan: unittest
Reviewed By: iseeyuan
Differential Revision: D34968080
fbshipit-source-id: d23b16abda6e4b7ecf6b1198ed6e00908a3db903
(cherry picked from commit 5cbbc390c5f54146a1c469106ab4a6286c754325)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74643
Previously `torch/csrc/deploy/interpreter/Optional.hpp` wasn't getting included in the wheel distribution created by `USE_DEPLOY=1 python setup.py bdist_wheel`, this pr fixes that
Test Plan: Imported from OSS
Reviewed By: d4l3k
Differential Revision: D35094459
Pulled By: PaliC
fbshipit-source-id: 50aea946cc5bb72720b993075bd57ccf8377db30
(cherry picked from commit 6ad5d96594f40af3d49d2137c2b3799a2d493b36)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73991
Automatically generate `datapipe.pyi` via CMake and removing the generated .pyi file from Git. Users should have the .pyi file locally after building for the first time.
I will also be adding an internal equivalent diff for buck.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D34868001
Pulled By: NivekT
fbshipit-source-id: 448c92da659d6b4c5f686407d3723933c266c74f
(cherry picked from commit 306dbc5f469e63bc141dac57ef310e6f0e16d9cd)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}