Decide the memory layout propagation policy and propagate it within the NNC fusion group. The memory layout propagation policy could be `Contiguous` and `Channels-last contiguous`.
- `Contiguous`: Convert the non-contiguous including channels-last contiguous input tensors to contiguous and generate the contiguous output `Buf` for lowering function.
- `Channels-last contiguous`: Convert the input tensors to channels-last contiguous and generate the channels-last contiguous output `Buf` for lowering function.
Currently, the rule is simple. If all the input and out tensors of the NNC fusion group are channels-last contiguous, then the propagated memory layout is `Channels-last contiguous`. Otherwise, it is always `Contiguous` which is as same as current situation. It means that this PR provides a fast path to channels-last and the optimization is conservative since its trigger conditions are strict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76948
Approved by: https://github.com/ZolotukhinM
**Summary:** Previously, FX graph mode quantization configurations
were specified through a dictionary of qconfigs. However, this
API was not in line with other core APIs in PyTorch. This commit
replaces this dictionary with a config object that users will
create and pass to prepare and convert. This leads to better
type safety and better user experience in notebook settings
due to improved auto completion.
The new API is as follows:
```
from torch.ao.quantization import QConfigMapping
from torch.ao.quantization.quantize_fx import prepare_fx
qconfig_mapping = QConfigMapping()
.set_global(qconfig)
.set_object_type(torch.nn.Linear, qconfig)
.set_module_name_regex("foo.*bar", qconfig)
.set_module_name("mod", qconfig)
prepare_fx(model, qconfig_mapping)
```
For backwards compatibility, `prepare_fx`, `prepare_qat_fx`,
and `convert_fx` will continue to accept qconfig_dicts, which
will be converted to QuantizationConfigs internally.
Note that this commit does not modify existing tests to use the
new API; they will continue to pass in qconfig_dict as before,
which still works but triggers a deprecation warning. This will
be handled in a future commit.
**Test Plan:**
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
**Reviewers:** jerryzh168, vkuzo
**Subscribers:** jerryzh168, vkuzo
Differential Revision: D36747998
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78452
Approved by: https://github.com/jerryzh168
Summary:
att, currently it errors out with the following error:
```
---> 72 dummy_weight = trt.Weights(weight_shape)
73 layer = network.add_convolution_nd(
74 input=input_val,
TypeError: __init__(): incompatible constructor arguments. The following argument types are supported:
1. tensorrt.tensorrt.Weights(type: tensorrt.tensorrt.DataType = <DataType.FLOAT: 0>)
2. tensorrt.tensorrt.Weights(a: numpy.ndarray)
```
full error: https://www.internalfb.com/phabricator/paste/view/P503598381
we need to pass arond a numpy ndarray instead of a shape here.
and support conv1d in backend_config_dict for tensorrt
Test Plan:
```
buck test mode/opt deeplearning/trt/fx2trt_oss/test/converters:test_convolution
```
```
buck test mode/opt deeplearning/trt/fx2trt_oss/test/quant:test_quant_trt
```
Differential Revision: D36721313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78402
Approved by: https://github.com/842974287
`check_training_mode` always warned that an op is set to training because it was comparing an int `op_train_mode` with an Enum `GLOBALS.training_mode`. This PR fixes the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78376
Approved by: https://github.com/garymm
Summary: Previously the op was auto-generated but it only covered the pointwise overload of aten::max. This adds support for reduction, overall and along a dim
Test Plan: Added a unit test
Differential Revision: D36656378
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78271
Approved by: https://github.com/mikeiovine
Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
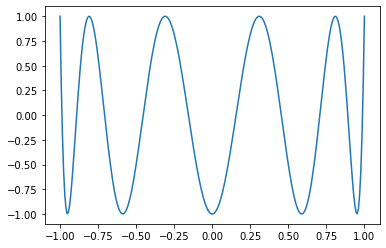
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
This PR is a result of collaboration with @rdspring1 and @mruberry on primTorch.
It adds the following prims:
- `fmax`
- `fmin`
- `fmod`
And adds the following refs:
- `fmax`
- `fmin`
- `fmod`
- `logical_xor`
The work is in progress as there are some tests that fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78023
Approved by: https://github.com/mruberry
PR https://github.com/pytorch/pytorch/pull/77042 has fixed the new folding conv-bn data type issue but missing the case when original conv has no bias input.
In this PR:
- Fix the new folding conv-bn's bias data type issue, when conv has no bias but weight as lower precision datatype, the new generated bias data type should be same as conv's weight.
- Move the Autocast JIT Trace UT from `test_jit.py` to `test_jit_autocast.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78241
Approved by: https://github.com/davidberard98
`nn.Transformer` is not possible to be used to implement BERT, while `nn.TransformerEncoder` does. So this PR moves the sentence 'Users can build the BERT model with corresponding parameters.' from `nn.Transformer` to `nn.TransformerEncoder`.
Fixes#68053
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78337
Approved by: https://github.com/jbschlosser
Co-authored with: @awgu
When `state_dict` has a prefix attached to it, the current logic for ignoring parameters and buffers does not work since it doesn't account for this prefix. To fix this, we make the following changes:
- clean the key if it starts with prefix. Note that all keys may not start with prefix, i.e. if the current module's state_dict_post_hook is running and previous module `state_dict` has already been computed and previous module is on the same level of hierarchy as the current module.
- This prefixing makes it so that it is not current to override child module's ignored params and buffers with the root FSDP instance's (this wouldn't work if child FSDP instances had ignored modules, and root didn't, for example). We fix this by having each parent know about the ignored modules of their children, and computing fully qualified names for ignored params and buffers.
- This means that each for a particular FSDP instance, that instance knows about the names of itself and its children (in fully qualified form) that it needs to ignore. It wouldn't know about parent ignored params and buffers, but it doesn't need to store this data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78278
Approved by: https://github.com/awgu
## Motivation
There is a bug in torch._utils.rebuild_qtensor when to restore a qtensor from pickle for not CPU device type. The tensor is created on the CPU device but set to a storage which maybe a different device type.
## Solution
Create the qtensor based on the storage device type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78234
Approved by: https://github.com/ezyang
Summary:
After https://github.com/pytorch/pytorch/pull/77608 `example_inputs` is required input for `prepare_fx` and `prepare_qat_fx`.
This makes quantizing submodules harder, so we added this utility function to get a dictionary from fqn to submodule example_inputs
Example Call:
```
example_inputs = (tensor0,)
get_fqn_to_example_inputs(m, example_inputs)
```
Example output:
```
{
"linear1": (tensor1,),
"linear2": (tensor2,),
"sub": (tensor3,),
"sub.linear1": (tensor4,),
...
}
```
Test Plan:
python test/test_quantization.py TestUtils
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78286
Approved by: https://github.com/dzdang
Summary:
Removes the restriction from NS for FX on handling nodes which have
no positional arguments, such as `F.linear(input=x, weight=w, bias=b).
In order to achieve this, we delete all places in the code which
were doing things like
```
node.args[0]
```
And replace them with
```
_get_normalized_nth_input(node, gm, 0)
```
The `_get_normalized_nth_input` function is a best effort way to
get the n'th normalized input.
This is needed because some FX tools output nodes normalized to
be kwargs only, and we need to be able to handle this in NS.
Test plan:
```
python test/test_quantization.py -k test_linear_kwargs_shadow
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78181
Approved by: https://github.com/z-a-f, https://github.com/hx89
{kind=link}
{kind=link}
{kind=link}