Decide the memory layout propagation policy and propagate it within the NNC fusion group. The memory layout propagation policy could be `Contiguous` and `Channels-last contiguous`.
- `Contiguous`: Convert the non-contiguous including channels-last contiguous input tensors to contiguous and generate the contiguous output `Buf` for lowering function.
- `Channels-last contiguous`: Convert the input tensors to channels-last contiguous and generate the channels-last contiguous output `Buf` for lowering function.
Currently, the rule is simple. If all the input and out tensors of the NNC fusion group are channels-last contiguous, then the propagated memory layout is `Channels-last contiguous`. Otherwise, it is always `Contiguous` which is as same as current situation. It means that this PR provides a fast path to channels-last and the optimization is conservative since its trigger conditions are strict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76948
Approved by: https://github.com/ZolotukhinM
**Summary:** Previously, FX graph mode quantization configurations
were specified through a dictionary of qconfigs. However, this
API was not in line with other core APIs in PyTorch. This commit
replaces this dictionary with a config object that users will
create and pass to prepare and convert. This leads to better
type safety and better user experience in notebook settings
due to improved auto completion.
The new API is as follows:
```
from torch.ao.quantization import QConfigMapping
from torch.ao.quantization.quantize_fx import prepare_fx
qconfig_mapping = QConfigMapping()
.set_global(qconfig)
.set_object_type(torch.nn.Linear, qconfig)
.set_module_name_regex("foo.*bar", qconfig)
.set_module_name("mod", qconfig)
prepare_fx(model, qconfig_mapping)
```
For backwards compatibility, `prepare_fx`, `prepare_qat_fx`,
and `convert_fx` will continue to accept qconfig_dicts, which
will be converted to QuantizationConfigs internally.
Note that this commit does not modify existing tests to use the
new API; they will continue to pass in qconfig_dict as before,
which still works but triggers a deprecation warning. This will
be handled in a future commit.
**Test Plan:**
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
**Reviewers:** jerryzh168, vkuzo
**Subscribers:** jerryzh168, vkuzo
Differential Revision: D36747998
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78452
Approved by: https://github.com/jerryzh168
Summary:
This diff moved the XNNPACK buck build to a shared build file in xplat/caffe2/third_party, so it can be reused by OSS buck CI in the future. There's no functionality change.
**Background**: as we are moving to github-first, we want community to receive more signals from our internal build. XNNPACK is part of pytorch mobile build so we want to add it to OSS BUCK CI.
**How it works**: all XNNPACK targets are defined in xplat/caffe2/third_party/xnnpack_defs.bzl. When we build it internally, the XNNPACK source is still at xplat/third-party/XNNPACK and we will load that bzl file in xplat/third-party/XNNPACK/BUCK. Everything should work as before. In OSS build, XNNPACK is a submodule in xplat/caffe2/third_party and we will load the same bzl file in pytorch/third_party/BUILD.buck.
**Wrapper Generation**: the wrapper generation script is moved to xplat/caffe2/third_party/generate-xnnpack-wrappers.py. It will take an optional argument for the path of XNNPACK (they are different in internal build and OSS build). The wrapper files will always be generated at the parent folder of XNNPACK source. But the src_defs.bzl and wrapper_defs.bzl will always be in xplat/caffe2/third_party/ (they are now called xnnpack_src_defs.bzl and xnnpack_wrapper_defs.bzl). For OSS build this script will only be used in CI, and the generated files will not be committed.
**Next Steps:** Once landed, I will try to build XNNPACK in OSS BUCK using xnnpack_defs.bzl. Meta-specific symbols need to be resolved, so there will be some refactors to the build file.
Test Plan: buck build xplat/third-party/XNNPACK:XNNPACK
Differential Revision: D36529332
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77941
Approved by: https://github.com/malfet, https://github.com/seemethere
By passing `storage_offset` of source and destination Tensors
This fixes following simple usecase:
```
python3` -c "import torch;x=torch.zeros(3, 3, device='mps'); x[1, 1]=1;print(x)"
```
Add test to validate it would not regress in the future
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78428
Approved by: https://github.com/kulinseth
Summary:
att, currently it errors out with the following error:
```
---> 72 dummy_weight = trt.Weights(weight_shape)
73 layer = network.add_convolution_nd(
74 input=input_val,
TypeError: __init__(): incompatible constructor arguments. The following argument types are supported:
1. tensorrt.tensorrt.Weights(type: tensorrt.tensorrt.DataType = <DataType.FLOAT: 0>)
2. tensorrt.tensorrt.Weights(a: numpy.ndarray)
```
full error: https://www.internalfb.com/phabricator/paste/view/P503598381
we need to pass arond a numpy ndarray instead of a shape here.
and support conv1d in backend_config_dict for tensorrt
Test Plan:
```
buck test mode/opt deeplearning/trt/fx2trt_oss/test/converters:test_convolution
```
```
buck test mode/opt deeplearning/trt/fx2trt_oss/test/quant:test_quant_trt
```
Differential Revision: D36721313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78402
Approved by: https://github.com/842974287
`check_training_mode` always warned that an op is set to training because it was comparing an int `op_train_mode` with an Enum `GLOBALS.training_mode`. This PR fixes the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78376
Approved by: https://github.com/garymm
Summary: Previously the op was auto-generated but it only covered the pointwise overload of aten::max. This adds support for reduction, overall and along a dim
Test Plan: Added a unit test
Differential Revision: D36656378
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78271
Approved by: https://github.com/mikeiovine
Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
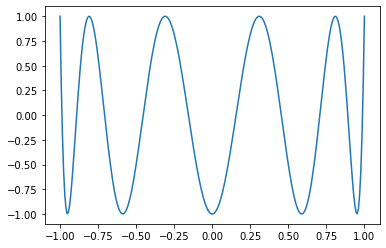
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
{kind=link}
{kind=link}
{kind=link}