This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
### Description
PR #80336 introduced a new parameter to the Sparse Adam optimizer. The new parameter is accessed inside the `step` method of the optimizer. If we try to deserialize and run an older version of the optimizer before this change was introduced, it fails in the step that tries to access the missing parameter.
I have added a workaround to set a default value in case the parameter is unavailable in the optimizer.
### Issue
<!-- Link to Issue ticket or RFP -->
### Testing
* Testing on PyTorch CI
* Manual validation against existing serialized models to make sure they continue to work
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82273
Approved by: https://github.com/mehtanirav, https://github.com/albanD
Adds the `differentiable` argument, a method for updating parameters in an existing optimizer, and a template for testing the differentiability of multiple optimizers.
This is all based in discussions with @albanD & @jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80938
Approved by: https://github.com/albanD
Generator comprehensions with any/all are less verbose and potentially help to save memory/CPU : https://eklitzke.org/generator-comprehensions-and-using-any-and-all-in-python
To make JIT work with this change, I added code to convert GeneratorExp to ListComp. So the whole PR is basically NoOp for JIT, but potentially memory and speed improvement for eager mode.
Also I removed a test from test/jit/test_parametrization.py. The test was bad and had a TODO to actually implement and just tested that UnsupportedNodeError is thrown, and with GeneratorExp support a different error would be thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78142
Approved by: https://github.com/malfet, https://github.com/albanD
This is causing issues if the user has the step on cuda for a good reason.
These assert prevents code that used to run just fine to fail.
Note that this is a pretty bad thing to do for performance though so it is ok to try and push users away from doing it.
For the 1.12.1 milestone: this is not asking for a dot release to fix this (as this is bad practice anyways). But it would be a great thing to add if we do one: it is very low risk and will prevent breakage for users.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80222
Approved by: https://github.com/jbschlosser, https://github.com/ngimel
What was happening is that when we have multiple learning rate schedulers, the order in which they are being initialized is not being taken into account. This is a problem if they were being initialized in sequential order (as one might intuitively do).
Each scheduler calls `step()` on initialization and sets the `lr` in its optimizer's `params_groups`. However, this means that step 0 will be using the `lr` that was set by the very last scheduler (in the case of initializing schedulers sequentially) instead of the first scheduler.
The fix in this PR, addresses the above bug by performing a call to the appropriate scheduler on initialization after decrementing the `last_epoch` values in order to keep them the same post-step. This will ensure that the correct scheduler is the one setting the `lr` values for the optimizer's `param_groups`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72856
Approved by: https://github.com/jbschlosser
### Goal
Fixes https://github.com/pytorch/pytorch/issues/79720
### Approach
replace `Chains list of learning rate schedulers. It takes a list of chainable learning rate schedulers and performs consecutive step() functions` **`belong`** `to them by just one call.` with `Chains list of learning rate schedulers. It takes a list of chainable learning rate schedulers and performs consecutive step() functions` **`belonging`** `to them by just one call.`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79775
Approved by: https://github.com/albanD
Near term fix for https://github.com/pytorch/pytorch/issues/76368.
Q. Why does the user need to request `capturable=True` in the optimizer constructor? Why can't capture safety be completely automatic?
A. We need to set up capture-safe (device-side) state variables before capture. If we don't, and step() internally detects capture is underway, it's too late: the best we could do is create a device state variable and copy the current CPU value into it, which is not something we want baked into the graph.
Q. Ok, why not just do the capture-safe approach with device-side state variables all the time?
A. It incurs several more kernel launches per parameter, which could really add up and regress cpu overhead for ungraphed step()s. If the optimizer won't be captured, we should allow step() to stick with its current cpu-side state handling.
Q. But cuda RNG is a stateful thing that maintains its state on the cpu outside of capture and replay, and we capture it automatically. Why can't we do the same thing here?
A. The graph object can handle RNG generator increments because its capture_begin, capture_end, and replay() methods can see and access generator object. But the graph object has no explicit knowledge of or access to optimizer steps in its capture scope. We could let the user tell the graph object what optimizers will be stepped in its scope, ie something like
```python
graph.will_use_optimizer(opt)
graph.capture_begin()
...
```
but that seems clunkier than an optimizer constructor arg.
I'm open to other ideas, but right now I think constructor arg is necessary and the least bad approach.
Long term, https://github.com/pytorch/pytorch/issues/71274 is a better fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77862
Approved by: https://github.com/ezyang
Fixes#60265
The initial LR for this scheduler is not consistent when a new instance is created with `last_epoch != -1`
Maybe we can refactor the testing code to test `last_epoch != -1` in schedulers that can recreate their state from the current epoch?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60339
Approved by: https://github.com/albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73215
Fixing an issue in optimizers from _multi_tensor, for `sgd_mt` introduced in 2cb03e926f
Reviewed By: mikaylagawarecki
Differential Revision: D34389034
fbshipit-source-id: ede153d52dca15909c6c022853589707f18dc8d1
(cherry picked from commit cc8a58e584)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69980
- Merged `torch/optim/adadelta.py` and `torch/optim/_multitensor/adadelta.py` into `torch/optim/adadelta.py`
- Moved adadelta functional forms from `torch/optim/_functional.py` and `torch/optim/_multi_tensor/_functional.py` to `torch/optim/adadelta.py`
- `torch/optim/_functional.py` just imports from `torch/optim/adadelta.py`
- Added a test `test_optimizers_foreach_flag` which replicates `test_multi_tensor_optimizers` in `test/test_optim.py`
- Add a test `test_adadelta_new` that replicates the behavior of `test_adadelta` but with `foreach` flag instead of using the multitensor adadleta class. If we delete `_multitensor/` we could replace `test_adadelta` with this
Remaining TODO:
- [ ] single_tensor adadelta supports complex but multitensor does not, need to integrate the singletensor logic in multitensor and switch the `test_adadelta_complex` to test for foreach in [True, False]
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin, albanD
Differential Revision: D33413059
Pulled By: mikaylagawarecki
fbshipit-source-id: 92a9fa98705762bb6bd464261671e49aef40070e
(cherry picked from commit a008227d22)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71333
Updated
- Adagrad
- Adamax
- Adam
- AdamW
- RAdam
make multi_tensor functionals take `state_steps: List[Tensor]` instead of taking `states: List[Dict]`
make `state_steps: List[int]s -> state_steps:List[Tensor]` where each is a Singleton tensor so step can be updated within the functional
(NAdam and ASGD) were updated in separate diffs to fold their handling of state into the functionals
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33767872
Pulled By: mikaylagawarecki
fbshipit-source-id: 9baa7cafb6375eab839917df9287c65a437891f2
(cherry picked from commit 831c02b3d0)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69936
Currently, the optimizers in `torch/optim/_multi_tensor/` all override the base Optimizer class' implementation of `zero_grad` with the same foreach zero_grad implementation (e.g. [here](https://github.com/pytorch/pytorch/blob/master/torch/optim/_multi_tensor/adadelta.py#L93-L114)). There is a TODO that indicates that this should be refactored to the base class once the foreach ops are in good shape. This PR is intended to address that TODO.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D33346748
Pulled By: mikaylagawarecki
fbshipit-source-id: 6573f4776aeac757b6a778894681868191a1b4c7
Summary:
- ~optimizer isn't required for `SequentialLR` since it's already present in the schedulers. Trying to match the signature of it with `ChainedScheduler`.~
- ~`verbose` isn't really used anywhere so removed it.~
updated missing docs and added a small check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69817
Reviewed By: ngimel
Differential Revision: D33069589
Pulled By: albanD
fbshipit-source-id: f015105a35a2ca39fe94c70acdfd55cdf5601419
Summary:
Solves the next most important use case in https://github.com/pytorch/pytorch/issues/68052.
I have kept the style as close to that in SGD as seemed reasonable, given the slight differences in their internal implementations.
All feedback welcome!
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68164
Reviewed By: VitalyFedyunin
Differential Revision: D32994129
Pulled By: albanD
fbshipit-source-id: 65c57c3f3dbbd3e3e5338d51def54482503e8850
Summary:
After 'maximize' flag was introduced in https://github.com/pytorch/pytorch/issues/46480 some jobs fail because they resume training from the checkpoints.
After we load old checkpoints we will get an error during optimizer.step() call during backward pass in [torch/optim/sgd.py", line 129] because there is no key 'maximize' in the parameter groups of the SGD.
To circumvent this I add a default value `group.setdefault('maximize', False)` when the optimizer state is restored.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68733
Reviewed By: albanD
Differential Revision: D32480963
Pulled By: asanakoy
fbshipit-source-id: 4e367fe955000a6cb95090541c143a7a1de640c2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67601.
As simple a fix as I could make it. I even managed to delete some testing code!
I checked calling `super()` and, as I had feared, it doesn't work out the box, so perhaps that ought to be revisited later.
As it stands, https://github.com/pytorch/pytorch/issues/20124, still applies to the chained scheduler, but I think this change is still an improvement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68010
Reviewed By: zou3519
Differential Revision: D32278139
Pulled By: albanD
fbshipit-source-id: 4c6f9f1b2822affdf63a6d22ddfdbcb1c6afd579
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46480 -- for SGD.
## Notes:
- I have modified the existing tests to take a new `constructor_accepts_maximize` flag. When this is set to true, the ` _test_basic_cases_template` function will test both maximizing and minimizing the sample function.
- This was the clearest way I could think of testing the changes -- I would appreciate feedback on this strategy.
## Work to be done:
[] I need to update the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67847
Reviewed By: H-Huang
Differential Revision: D32252631
Pulled By: albanD
fbshipit-source-id: 27915a3cc2d18b7e4d17bfc2d666fe7d2cfdf9a4
Summary:
The final learning rate should be 0.05 like the lr used as the argument for the optimizer and not 0.005.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67840
Reviewed By: jbschlosser
Differential Revision: D32187091
Pulled By: albanD
fbshipit-source-id: 8aff691bba3896a847d7b9d9d669a65f67a6f066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66587
Made some changes in the step function of the non-vectorized Adadelta optimizer to handle complex numbers as two real numbers as per 65711 on github
ghstack-source-id: 141484731
Test Plan:
buck test mode/dev caffe2/test:optim -- 'test_adadelta_complex'
https://pxl.cl/1R7kJ
Reviewed By: albanD
Differential Revision: D31630069
fbshipit-source-id: 2741177b837960538ce39772897af36bbce7b7d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66671
Made changes in the step function of the vectorized and non-vectorized adagrad optimizers to handle complex numbers as two real numbers as per 65711 on github
ghstack-source-id: 141442350
Test Plan:
buck test mode/dev caffe2/test:optim -- 'test_adagrad_complex'
https://pxl.cl/1Rd44
Reviewed By: albanD
Differential Revision: D31673503
fbshipit-source-id: 90a0d0c69b556716e2d17c59ce80f09c750fc464
Summary:
## {emoji:1f41b} Bug
'CosineAnnealingWarmRestarts' object has no attribute 'T_cur'.
In the Constructor of the CosineAnnealingWarmRestarts, we're calling the constructor of the Parent class (_LRScheduler) which inturn calls the step method of the CosineAnnealingWarmRestarts.
The called method tries to update the object's attribute 'T_cur' which is not defined yet. So it raises the error.
This only holds, when we give the value for last_epoch argument as 0 or greater than 0 to the 'CosineAnnealingWarmRestarts', while initializing the object.

## To Reproduce
Steps to reproduce the behavior:
1. Give the value for the last_epoch argument as zero OR
1. Give the value for the last_epoch argument as a Positive integer.
## Expected behavior
I only expected the 'CosineAnnealingWarmRestarts' object to be initialized.
## Environment
PyTorch version: 1.9.0+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.21.2
Libc version: glibc-2.31
Python version: 3.8.10 [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.8.0-59-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
## Additional context
We can able to solve this bug by moving the line 'self.T_cur = self.last_epoch' above the 'super(CosineAnnealingWarmRestarts,self).__init__()' line. Since we've initialized the "self.T_cur" to the object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64758
Reviewed By: ezyang
Differential Revision: D31113694
Pulled By: jbschlosser
fbshipit-source-id: 98c0e292291775895dc3566fda011f2d6696f721
Summary:
Partially resolves https://github.com/pytorch/vision/issues/4281
In this PR we are proposing a new scheduler --SequentialLR-- which enables list of different schedulers called in different periods of the training process.
The main motivation of this scheduler is recently gained popularity of warming up phase in the training time. It has been shown that having a small steps in initial stages of training can help convergence procedure get faster.
With the help of SequentialLR we mainly enable to call a small constant (or linearly increasing) learning rate followed by actual target learning rate scheduler.
```PyThon
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = SequentialLR(optimizer, schedulers=[scheduler1, scheduler2], milestones=[5])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
```
which this code snippet will call `ConstantLR` in the first 5 epochs and will follow up with `ExponentialLR` in the following epochs.
This scheduler could be used to provide call of any group of schedulers next to each other. The main consideration we should make is every time we switch to a new scheduler we assume that new scheduler starts from the beginning- zeroth epoch.
We also add Chained Scheduler to `optim.rst` and `lr_scheduler.pyi` files here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64037
Reviewed By: albanD
Differential Revision: D30841099
Pulled By: iramazanli
fbshipit-source-id: 94f7d352066ee108eef8cda5f0dcb07f4d371751
Summary:
It has been discussed before that adding description of Optimization algorithms to PyTorch Core documentation may result in a nice Optimization research tutorial. In the following tracking issue we mentioned about all the necessary algorithms and links to the originally published paper https://github.com/pytorch/pytorch/issues/63236.
In this PR we are adding description of Stochastic Gradient Descent to the documentation.
<img width="466" alt="SGDalgo" src="https://user-images.githubusercontent.com/73658284/132585881-b351a6d4-ece0-4825-b9c0-126d7303ed53.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63805
Reviewed By: albanD
Differential Revision: D30818947
Pulled By: iramazanli
fbshipit-source-id: 3812028e322c8a64f4343552b0c8c4582ea382f3
Summary:
Partially unblocks https://github.com/pytorch/vision/issues/4281
Previously we have added WarmUp Schedulers to PyTorch Core in the PR : https://github.com/pytorch/pytorch/pull/60836 which had two mode of execution - linear and constant depending on warming up function.
In this PR we are changing this interface to more direct form, as separating linear and constant modes to separate Schedulers. In particular
```Python
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="linear")
```
will look like
```Python
scheduler1 = ConstantLR(optimizer, warmup_factor=0.1, warmup_iters=5)
scheduler2 = LinearLR(optimizer, warmup_factor=0.1, warmup_iters=5)
```
correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64395
Reviewed By: datumbox
Differential Revision: D30753688
Pulled By: iramazanli
fbshipit-source-id: e47f86d12033f80982ddf1faf5b46873adb4f324
Summary:
In this PR we are introducing ChainedScheduler which initially proposed in the discussion https://github.com/pytorch/pytorch/pull/26423#discussion_r329976246 .
The idea is to provide a user friendly chaining method for schedulers, especially for the cases many of them are involved and we want to have a clean and easy to read interface for schedulers. This method will be even more crucial once CompositeSchedulers and Schedulers for different type of parameters are involved.
The immediate application of Chained Scheduler is expected to happen in TorchVision Library to combine WarmUpLR and MultiStepLR https://github.com/pytorch/vision/blob/master/references/video_classification/scheduler.py#L5 . However, it can be expected that in many other use cases also this method could be applied.
### Example
The usage is as simple as below:
```python
sched=ChainedScheduler([ExponentialLR(self.opt, gamma=0.9),
WarmUpLR(self.opt, warmup_factor=0.2, warmup_iters=4, warmup_method="constant"),
StepLR(self.opt, gamma=0.1, step_size=3)])
```
Then calling
```python
sched.step()
```
would trigger step function for all three schedulers consecutively
Partially resolves https://github.com/pytorch/vision/issues/4281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63491
Reviewed By: datumbox, mruberry
Differential Revision: D30576180
Pulled By: iramazanli
fbshipit-source-id: b43f0749f55faab25079641b7d91c21a891a87e4
Summary:
It has been discussed in the https://github.com/pytorch/pytorch/pull/60836#issuecomment-899084092 that we have observed an obstacle to chain some type of learning rate schedulers. In particular we observed
* some of the learning rate schedulers returns initial learning rates at epoch 0 as
```
return self.base_lrs`
```
* This can be a problem when two schedulers called as chained as
```
scheduler1.step()
scheduler2.step()
```
in particular, we completely ignore the effect of scheduler1 at epoch 0. This could not be an issue if at epoch 0, scheduler1 was ineffective as in many schedulers, however for schedulers as WarmUp Schedulers, where at epoch 0 schedulers multiplicative value is smaller than 1 this could lead to undesired behaviors.
The following code snippet illustrates the problem better
## Reproducing the bug
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR, ExponentialLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 1.0)
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(10):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()
```
### Current Result
```
0 1.0
1 0.9
2 0.81
3 0.7290000000000001
4 0.6561000000000001
5 5.904900000000001
6 5.314410000000001
7 4.782969000000001
8 4.304672100000001
9 3.874204890000001
```
### Expected Result
```
0 1.0
1 0.9
2 0.81
3 0.7290000000000001
4 0.6561000000000001
5 0.5904900000000001
6 0.5314410000000001
7 0.4782969000000001
8 0.4304672100000001
9 0.3874204890000001
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63457
Reviewed By: datumbox
Differential Revision: D30424160
Pulled By: iramazanli
fbshipit-source-id: 3e15af8d278c872cd6f53406b55f4d3ce5002867
Summary:
Warm up of learning rate scheduling has initially been discussed by Priya et. al. in the paper: https://arxiv.org/pdf/1706.02677.pdf .
In the section 2.2 of the paper they discussed and proposed idea of warming up learning schedulers in order to prevent big variance / noise in the learning rate. Then idea has been further discussed in the following papers:
* Akilesh Gotmare et al. https://arxiv.org/abs/1810.13243
* Bernstein et al http://proceedings.mlr.press/v80/bernstein18a/bernstein18a.pdf
* Liyuan Liu et al: https://arxiv.org/pdf/1908.03265.pdf
There are two type of popularly used learning rate warm up ideas
* Constant warmup (start with very small constant learning rate)
* Linear Warmup ( start with small learning rate and gradually increase)
In this PR we are adding warm up as learning rate scheduler. Note that learning rates are chainable, which means that we can merge warmup scheduler with any other learning rate scheduler to make more sophisticated learning rate scheduler.
## Linear Warmup
Linear Warmup is multiplying learning rate with pre-defined constant - warmup_factor in the first epoch (epoch 0). Then targeting to increase this multiplication constant to one in warmup_iters many epochs. Hence we can derive the formula at i-th step to have multiplication constant equal to:
warmup_factor + (1-warmup_factor) * i / warmup_iters
Moreover, the fraction of this quantity at point i to point i-1 will give us
1 + (1.0 - warmup_factor) / [warmup_iters*warmup_factor+(i-1)*(1-warmup_factor)]
which is used in get_lr() method in our implementation. Below we provide an example how to use linear warmup scheduler and to give an example to show how does it works.
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=10, warmup_method="linear")
for epoch in range(15):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.019000000000000003
2 0.028000000000000008
3 0.03700000000000001
4 0.04600000000000001
5 0.055000000000000014
6 0.06400000000000002
7 0.07300000000000002
8 0.08200000000000003
9 0.09100000000000004
10 0.10000000000000005
11 0.10000000000000005
12 0.10000000000000005
13 0.10000000000000005
14 0.10000000000000005
```
## Constant Warmup
Constant warmup has straightforward idea, to multiply learning rate by warmup_factor until we reach to epoch warmup_factor, then do nothing for following epochs
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
for epoch in range(10):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.010000000000000002
2 0.010000000000000002
3 0.010000000000000002
4 0.010000000000000002
5 0.10000000000000002
6 0.10000000000000002
7 0.10000000000000002
8 0.10000000000000002
9 0.10000000000000002
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60836
Reviewed By: saketh-are
Differential Revision: D29537615
Pulled By: iramazanli
fbshipit-source-id: d910946027acc52663b301f9c56ade686e62cb69
Summary:
Fixes https://github.com/pytorch/pytorch/issues/59998
It has been discussed in the issue that the variance term of Adam optimizer currently doesn't compute correctly for complex domain. As it has been stated in the Generalization to Complex numbers section in https://en.wikipedia.org/wiki/Variance variance is computed as E[(X - mu)(X-mu)*] (where mu = E[X] and * stands for conjugate) for complex random variable X.
However, currently the computation method in implementation of Adam is via E[(X - mu)(X-mu)] which doesn't return right variance value, in particular it returns complex number. Variance is defined to be real number even though underlying random variable is complex.
We fix this issue here, and testing that resulting variance is indeed real number.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62946
Reviewed By: albanD
Differential Revision: D30196038
Pulled By: iramazanli
fbshipit-source-id: ab0a6f31658aeb56bdcb211ff86eaa29f3f0d718
Summary:
Previously in the PR: https://github.com/pytorch/pytorch/issues/58968 we added RAdam to Optimizers. Here in this PR we are proposing multi-tensor version of RAdam for PyTorch.
Radam has been proposed in the paper https://arxiv.org/pdf/1908.03265.pdf Liyuan Liu et al.
It has been one of the most used algorithm in Deep Learning community.
Differing from the paper, we selected variance tractability cut-off as 5 instead of 4 as it is the common practice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59161
Reviewed By: vincentqb
Differential Revision: D29360576
Pulled By: iramazanli
fbshipit-source-id: 7ccdbf12b1ee7f12e66f7d7992123a70cc818b6b
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/24892
In the paper : https://arxiv.org/pdf/1908.03265.pdf Liyuan Liu et al. suggested a new optimization algorithm with an essence of similar to Adam Algorithm.
It has been discussed in the paper that, without warmup heuristic, in the early stage of adaptive optimization / learning algorithms sometimes we can get undesirable large variance which can slow overall convergence process.
Authors proposed the idea of rectification of variance of adaptive learning rate when it is expected to be high.
Differing from the paper, we selected variance tractability cut-off as 5 instead of 4. This adjustment is common practice, and could be found in the code-repository and also tensorflow swift optim library as well :
2f03dd1970/radam/radam.py (L156)f51ee4618d/Sources/TensorFlow/Optimizers/MomentumBased.swift (L638)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58968
Reviewed By: vincentqb
Differential Revision: D29310601
Pulled By: iramazanli
fbshipit-source-id: b7bd487f72f1074f266687fd9c0c6be264a748a9
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/5804
In the paper : https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ Timothy Dozat suggested a new optimization algorithm with an essence of combination of NAG and Adam algorithms.
It is known that the idea of momentum can be improved with the Nesterov acceleration in optimization algorithms, and Dozat is investigating to apply this idea to momentum component of Adam algorithm. Author provided experiment evidence in their work to show excellence of the idea.
In this PR we are implementing the proposed algorithm NAdam in the mentioned paper. Author has a preliminary work http://cs229.stanford.edu/proj2015/054_report.pdf where he shows the decay base constant should be taken as 0.96 which we also followed the same phenomenon here in this implementation similar to Keras. Moreover, implementation / coding practice have been followed similar to Keras in some other places as well:
f9d3868495/tensorflow/python/keras/optimizer_v2/nadam.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59009
Reviewed By: gchanan, vincentqb
Differential Revision: D29220375
Pulled By: iramazanli
fbshipit-source-id: 4b4bb4b15f7e16f7527f368bbf4207ed345751aa
Summary:
Fixes : https://github.com/pytorch/pytorch/issues/24892
In the paper : https://arxiv.org/pdf/1908.03265.pdf Liyuan Liu et al. suggested a new optimization algorithm with an essence of similar to Adam Algorithm.
It has been discussed in the paper that, without warmup heuristic, in the early stage of adaptive optimization / learning algorithms sometimes we can get undesirable large variance which can slow overall convergence process.
Authors proposed the idea of rectification of variance of adaptive learning rate when it is expected to be high.
Differing from the paper, we selected variance tractability cut-off as 5 instead of 4. This adjustment is common practice, and could be found in the code-repository and also tensorflow swift optim library as well :
2f03dd1970/radam/radam.py (L156)f51ee4618d/Sources/TensorFlow/Optimizers/MomentumBased.swift (L638)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58968
Reviewed By: gchanan
Differential Revision: D29241736
Pulled By: iramazanli
fbshipit-source-id: 288b9b1f3125fdc6c7a7bb23fde1ea5c201c0448
Summary:
Functional API is used in large scale distributed training to enable multithreaded training instead of multiprocess, as it gives more optimal resource utilization and efficiency.
In this PR, we provide code migration and refactoring for functional API for ASGD algorithm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58410
Reviewed By: ailzhang
Differential Revision: D28546702
Pulled By: iramazanli
fbshipit-source-id: 4f62b6037d53f35b19f98340e88af2ebb6243a4f
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for optim and cuda functions/classes.
Also fix some minor formatting issues in optim.LBFGS and cuda.stream docstings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55673
Reviewed By: jbschlosser
Differential Revision: D27747741
Pulled By: zou3519
fbshipit-source-id: 070681f840cdf4433a44af75be3483f16e5acf7d
Summary:
*Context:* https://github.com/pytorch/pytorch/issues/53406 added a lint for trailing whitespace at the ends of lines. However, in order to pass FB-internal lints, that PR also had to normalize the trailing newlines in four of the files it touched. This PR adds an OSS lint to normalize trailing newlines.
The changes to the following files (made in 54847d0adb9be71be4979cead3d9d4c02160e4cd) are the only manually-written parts of this PR:
- `.github/workflows/lint.yml`
- `mypy-strict.ini`
- `tools/README.md`
- `tools/test/test_trailing_newlines.py`
- `tools/trailing_newlines.py`
I would have liked to make this just a shell one-liner like the other three similar lints, but nothing I could find quite fit the bill. Specifically, all the answers I tried from the following Stack Overflow questions were far too slow (at least a minute and a half to run on this entire repository):
- [How to detect file ends in newline?](https://stackoverflow.com/q/38746)
- [How do I find files that do not end with a newline/linefeed?](https://stackoverflow.com/q/4631068)
- [How to list all files in the Git index without newline at end of file](https://stackoverflow.com/q/27624800)
- [Linux - check if there is an empty line at the end of a file [duplicate]](https://stackoverflow.com/q/34943632)
- [git ensure newline at end of each file](https://stackoverflow.com/q/57770972)
To avoid giving false positives during the few days after this PR is merged, we should probably only merge it after https://github.com/pytorch/pytorch/issues/54967.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54737
Test Plan:
Running the shell script from the "Ensure correct trailing newlines" step in the `quick-checks` job of `.github/workflows/lint.yml` should print no output and exit in a fraction of a second with a status of 0. That was not the case prior to this PR, as shown by this failing GHA workflow run on an earlier draft of this PR:
- https://github.com/pytorch/pytorch/runs/2197446987?check_suite_focus=true
In contrast, this run (after correcting the trailing newlines in this PR) succeeded:
- https://github.com/pytorch/pytorch/pull/54737/checks?check_run_id=2197553241
To unit-test `tools/trailing_newlines.py` itself (this is run as part of our "Test tools" GitHub Actions workflow):
```
python tools/test/test_trailing_newlines.py
```
Reviewed By: malfet
Differential Revision: D27409736
Pulled By: samestep
fbshipit-source-id: 46f565227046b39f68349bbd5633105b2d2e9b19
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52944
This fix the bug introduced during refactoring optimizers https://github.com/pytorch/pytorch/pull/50411. When all parameters have no grads, we should still allows `beta` like hyper params to be defined.
Reviewed By: ngimel
Differential Revision: D26699827
fbshipit-source-id: 8a7074127704c7a4a1fbc17d48a81e23a649f280
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52055
This fixes the **out of memory error** while using update_bn in **SWA**, by not allocating memory for backpropagation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52654
Reviewed By: malfet
Differential Revision: D26620077
Pulled By: albanD
fbshipit-source-id: 890b5a78ba9c1a148f3ab7c63472a73d8f6412a4
Summary:
Change `avg_fun -> avg_fn` to match the spelling in the `.py` file.
(`swa_utils.pyi` should match `swa_utils.py`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51608
Reviewed By: glaringlee
Differential Revision: D26224779
Pulled By: zou3519
fbshipit-source-id: 01ff7173ba0a996f1b7a653438acb6b6b4659de6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51316
Make optim functional API be private until we release with beta
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26213469
fbshipit-source-id: b0fd001a8362ec1c152250bcd57c7205ed893107
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47441
To give user more information about python level functions in profiler traces, we propose to instrument on the following functions:
```
_BaseDataLoaderIter.__next__
Optimizer.step
Optimizer.zero_grad
```
Because the record_function already uses if (!active) to check whether the profiler is enabled, so we don't explicitly call torch.autograd._profiler_enabled() before each instrument.
Acknowledgement: nbcsm, guotuofeng, gunandrose4u , guyang3532 , mszhanyi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47655
Reviewed By: smessmer
Differential Revision: D24960386
Pulled By: ilia-cher
fbshipit-source-id: 2eb655789e2e2f506e1b8f95ad3d470c83281102
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46405, https://github.com/pytorch/pytorch/issues/43352
I updated the docstring in the local file (function level comments). Do I also need to edit somewhere else or recompile docstrings?
Also, though I didn't change any types here, how is typing (for IDE type checking) documentation generated / used)?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46813
Reviewed By: ezyang
Differential Revision: D24923112
Pulled By: vincentqb
fbshipit-source-id: be7818e0d4593bfc5d74023b9c361ac2a538589a
Summary:
Refactor foreach APIs to use overloads in case of scalar list inputs.
Tested via unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45673
Reviewed By: heitorschueroff
Differential Revision: D24053424
Pulled By: izdeby
fbshipit-source-id: 35976cc50b4acfe228a32ed26cede579d5621cde
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40362
The new `three_phase` option provides a way of constructing schedules according to the scheme recommended in [Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates](https://arxiv.org/abs/1708.07120).
Note that this change maintains backwards compatibility, and as a result the default behaviour of OneCycleLR remains quite counter-intuitive.
vincentqb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42715
Reviewed By: heitorschueroff
Differential Revision: D24289744
Pulled By: vincentqb
fbshipit-source-id: e4aad87880716bb14613c0aa8631e43b04a93e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45221
This PR introduces a distributed functional optimizer, so that
distributed optimizer can reuse the functional optimizer APIs and
maintain their own states. This could enable the torchscript compatible
functional optimizer when using distributed optimizer, helps getting rid
of GIL and improve overall performance of training, especially distributed
model parallel training
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935256
Pulled By: wanchaol
fbshipit-source-id: 59b6d77ff4693ab24a6e1cbb6740bcf614cc624a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44715
We have provided a nice and intuitive API in Python. But in the context of large scale distributed training (e.g. Distributed Model Parallel), users often want to use multithreaded training instead of multiprocess training as it provides better resource utilization and efficiency.
This PR introduces functional optimizer concept (that is similar to the concept of `nn.functional`), we split optimizer into two parts: 1. optimizer state management 2. optimizer computation. We expose the computation part as a separate functional API that is available to be used by internal and OSS developers, the caller of the functional API will maintain their own states in order to directly calls the functional API. While maintaining the end user API be the same, the functional API is TorchScript friendly, and could be used by the distributed optimizer to speed up the training without GIL.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935258
Pulled By: wanchaol
fbshipit-source-id: d2a5228439edb3bc64f7771af2bb9e891847136a
Summary:
The subclass sets "self.last_epoch" when this is set in the parent class's init function. Why would we need to set last_epoch twice? I think calling "super" resets last_epoch anyway, so I am not sure why we would want to include this in the subclass. Am I missing something?
For the record, I am just a Pytorch enthusiast. I hope my question isn't totally silly.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44613
Reviewed By: albanD
Differential Revision: D23691770
Pulled By: mrshenli
fbshipit-source-id: 080d9acda86e1a2bfaafe2c6fcb8fc1544f8cf8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41283
in optimizer.zero_grad(), detach_ is useful to avoid memory leak only when grad has grad_fn, so add check to call grad.detach_ only when the grad has grad_fn in zero_grad() function
ghstack-source-id: 108702289
Test Plan: unit test
Reviewed By: mrshenli
Differential Revision: D22487315
fbshipit-source-id: 861909b15c8497f1da57f092d8963d4920c85e38
Summary:
I encountered a zero division problem when using LBFGS:
File "/home/yshen/anaconda3/lib/python3.7/site-packages/torch/optim/lbfgs.py", line 118, in _strong_wolfe
bracket[1], bracket_f[1], bracket_gtd[1])
File "/home/yshen/anaconda3/lib/python3.7/site-packages/torch/optim/lbfgs.py", line 21, in _cubic_interpolate
d1 = g1 + g2 - 3 * (f1 - f2) / (x1 - x2)
ZeroDivisionError: float division by zero
My solution is to determine whether "line-search bracket is so small" before calling _cubic_interpolate
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42093
Reviewed By: pbelevich
Differential Revision: D22770667
Pulled By: mrshenli
fbshipit-source-id: f8fdfcbd3fd530235901d255208fef8005bf898c
Summary:
This PR fixes an issue in https://github.com/pytorch/pytorch/issues/40967 where duplicate parameters across different parameter groups are not allowed, but duplicates inside the same parameter group are accepted. After this PR, both cases are treated equally and raise `ValueError`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41597
Reviewed By: zou3519
Differential Revision: D22608019
Pulled By: vincentqb
fbshipit-source-id: 6df41dac62b80db042cfefa6e53fb021b49f4399
Summary:
I ran `make linkcheck` using `sphinx.builders.linkcheck` on the documentation and noticed a few links weren't using HTTPS so I quickly updated them all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40878
Differential Revision: D22404647
Pulled By: ngimel
fbshipit-source-id: 9c9756db59197304023fddc28f252314f6cf4af3
Summary:
This is a faster and more idiomatic way of using `itertools.chain`. Instead of computing all the items in the iterable and storing them in memory, they are computed one-by-one and never stored as a huge list. This can save on both runtime and memory space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40156
Reviewed By: ezyang
Differential Revision: D22189038
Pulled By: vincentqb
fbshipit-source-id: 160b2c27f442686821a6ea541e1f48f4a846c186
Summary:
Fixes https://github.com/pytorch/pytorch/issues/36831.
Instead of using `id()`, an arbitrary yet consistent order-based index is used instead. This results in a deterministic output between runs.
I am not the biggest fan of using `nonlocal` (it appears to be used sparingly in the codebase) to get `start_index` between calls to `pack_group()`, but the alternatives had larger issues:
- Using the last value added to `param_mappings` would be ideal, but that only works if `dict` iteration order is consistent, and PyTorch currently supports Python <3.7.
- Using the maximum value added to `param_mappings` wouldn't have that issue but would not be constant time.
For testing, I confirmed that `test_optim.py` works before and after these changes. Randomizing the indices in `param_mappings` causes the tests to fail, which is further evidence these changes work. I'm not 100% if these tests are sufficient, but they're a start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37347
Differential Revision: D21353820
Pulled By: vincentqb
fbshipit-source-id: e549f1f154833a461b1f4df6d07ad509aab34ea1
Summary:
- added tests that showcase the problems
- fixed the problems
These changes would allow me to remove many "# type: ignore" comments in my codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36358
Differential Revision: D21230704
Pulled By: ezyang
fbshipit-source-id: e6d475a0aa1fb40258fa0231ade28c38108355fb
Summary:
This PR is based on the issue https://github.com/pytorch/pytorch/issues/29994#issue-524418771 and the discussion in the previous version of the PR https://github.com/pytorch/pytorch/pull/30559. Specifically, I followed the interface outlined in this [comment](https://github.com/pytorch/pytorch/pull/30559#issuecomment-574864768).
## Structure
- `torch/optim/swa_utils.py` contains the implementation of `AveragedModel` class, `SWALR` learning rate scheduler and `update_bn` utility
- `test/test_optim.py` contains unit tests for the three components of SWA
- `torch/optim/swa_utils.pyi` describes the interface of `torch/optim/swa_utils.py`
The new implementation consists of
- `AveragedModel` class; this class creates a copy of a given model and allows to compute running averages of the parameters.
- `SWALR` learning rate scheduler; after a certain number of epochs switches to a constant learning rate; this scheduler is supposed to be chained with other schedulers.
- `update_bn` utility; updates the Batch Normalization activation statistics for a given model and dataloader; this utility is meant to be applied to `AveragedModel` instances.
For `update_bn` I simplified the implementation compared to the [original PR](https://github.com/pytorch/pytorch/pull/30559) according to the sugestions by vadimkantorov.
## Example
```python
loader, optimizer, model = ...
swa_model = torch.optim.swa_utils.AveragedModel(model)
# You can use custom averaging functions with `avg_fun` parameter
ema_avg = lambda p_avg, p, n_avg: 0.1 * p_avg + 0.9 * p
ema_model = torch.optim.swa_utils.AveragedModel(model,
avg_function=ema_avg)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=300)
swa_start = 160
swa_scheduler = SWALR(optimizer, start_epoch=swa_start, swa_lr=0.05)
for i in range(300):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
scheduler.step()
swa_scheduler.step()
if i > swa_start:
swa_model.update_parameters(model)
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
```
UPDATED:
```python3
loader, optimizer, model, loss_fn = ...
swa_model = torch.optim.swa_utils.AveragedModel(model)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)
swa_start = 160
swa_scheduler = SWALR(optimizer, swa_lr=0.05)
for i in range(300):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
if i > swa_start:
swa_model.update_parameters(model)
swa_scheduler.step()
else:
scheduler.step()
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
```
Fixes https://github.com/pytorch/pytorch/issues/29994
cc soumith vincentqb andrewgordonwilson vadimkantorov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35032
Differential Revision: D21079606
Pulled By: vincentqb
fbshipit-source-id: e07f5e821f72ada63789814c2dcbdc31f0160c37
Summary:
I've been using pytorch with type hintings, and I found errors that can be easily fixed. So I'm creating this PR to fix type bugs.
I expected below code should be type-checked without any errors.
```python
import torch
from torch.nn import Linear
from torch.autograd import Variable
from torch.optim import AdamW
from torch.utils import hooks
# nn.Module should have training attribute
module = Linear(10, 20)
module.training
# torch should have dtype bfloat16
tensor2 = torch.tensor([1,2,3], dtype=torch.bfloat16)
# torch.Tensor.cuda should accept int or str value
torch.randn(5).cuda(1)
torch.tensor(5).cuda('cuda:0')
# optimizer should have default attribute
module = Linear(10, 20)
print(AdamW(module.weight).default)
# torch.Tensor should have these boolean attributes
torch.tensor([1]).is_sparse
torch.tensor([1]).is_quantized
torch.tensor([1]).is_mkldnn
# Size class should tuple of int
a, b = torch.tensor([[1,2,3]]).size()
# check modules can be accessed
torch.nn.parallel
torch.autograd.profiler
torch.multiprocessing
torch.sparse
torch.onnx
torch.jit
torch.hub
torch.random
torch.distributions
torch.quantization
torch.__config__
torch.__future__
torch.ops
torch.classes
# Variable class's constructor should return Tensor
def fn_to_test_variable(t: torch.Tensor):
return None
v = Variable(torch.tensor(1))
fn_to_test_variable(v)
# check RemovableHandle attributes can be accessed
handle = hooks.RemovableHandle({})
handle.id
handle.next_id
# check torch function hints
torch.is_grad_enabled()
```
But current master branch raises errors. (I checked with pyright)
```
$ pyright test.py
Searching for source files
Found 1 source file
test.py
12:45 - error: 'bfloat16' is not a known member of module
15:21 - error: Argument of type 'Literal[1]' cannot be assigned to parameter 'device' of type 'Optional[device]'
'int' is incompatible with 'device'
Cannot assign to 'None'
16:22 - error: Argument of type 'Literal['cuda:0']' cannot be assigned to parameter 'device' of type 'Optional[device]'
'str' is incompatible with 'device'
Cannot assign to 'None'
23:19 - error: Cannot access member 'is_sparse' for type 'Tensor'
Member 'is_sparse' is unknown
24:19 - error: Cannot access member 'is_quantized' for type 'Tensor'
Member 'is_quantized' is unknown
25:19 - error: Cannot access member 'is_mkldnn' for type 'Tensor'
Member 'is_mkldnn' is unknown
32:7 - error: 'autograd' is not a known member of module
33:7 - error: 'multiprocessing' is not a known member of module
34:7 - error: 'sparse' is not a known member of module
35:7 - error: 'onnx' is not a known member of module
36:7 - error: 'jit' is not a known member of module
37:7 - error: 'hub' is not a known member of module
38:7 - error: 'random' is not a known member of module
39:7 - error: 'distributions' is not a known member of module
40:7 - error: 'quantization' is not a known member of module
41:7 - error: '__config__' is not a known member of module
42:7 - error: '__future__' is not a known member of module
44:7 - error: 'ops' is not a known member of module
45:7 - error: 'classes' is not a known member of module
60:7 - error: 'is_grad_enabled' is not a known member of module
20 errors, 0 warnings
Completed in 1.436sec
```
and below list is not checked as errors, but I think these are errors too.
* `nn.Module.training` is not boolean
* return type of `torch.Tensor.size()` is `Tuple[Unknown]`.
---
related issues.
https://github.com/pytorch/pytorch/issues/23731, https://github.com/pytorch/pytorch/issues/32824, https://github.com/pytorch/pytorch/issues/31753
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33762
Differential Revision: D20118884
Pulled By: albanD
fbshipit-source-id: 41557d66674a11b8e7503a48476d4cdd0f278eab
Summary:
Adam and AdamW are missing parameter validation for weight_decay. Other optimisers have this check present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33126
Differential Revision: D19860366
Pulled By: vincentqb
fbshipit-source-id: 286d7dc90e2f4ccf6540638286d2fe17939648fc
Summary:
## problem
```python
class LambdaLR(_LRScheduler):
"""Sets the learning rate of each parameter group to the initial lr
times a given function. When last_epoch=-1, sets initial lr as lr.
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
Example:
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
"""
```
`LambdaLR` takes a lambda that returns a float and takes a int, or a list of such lambdas.
## related issue
Resolve https://github.com/pytorch/pytorch/issues/32645
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33271
Differential Revision: D19878665
Pulled By: vincentqb
fbshipit-source-id: 50b16caea13de5a3cbd187e688369f33500499d0
Summary:
When an error is raised and `__exit__` in a context manager returns `True`, the error is suppressed; otherwise the error is raised. No return value should be given to maintain the default behavior of context manager.
Fixes https://github.com/pytorch/pytorch/issues/32639. The `get_lr` function was overridden with a function taking an epoch parameter, which is not allowed. However, the relevant error was not being raised.
```python
In [1]: import torch
...:
...: class MultiStepLR(torch.optim.lr_scheduler._LRScheduler):
...: def __init__(self, optimizer, gamma, milestones, last_epoch = -1):
...: self.init_lr = [group['lr'] for group in optimizer.param_groups]
...: self.gamma = gamma
...: self.milestones = milestones
...: super().__init__(optimizer, last_epoch)
...:
...: def get_lr(self, step):
...: global_step = self.last_epoch #iteration number in pytorch
...: gamma_power = ([0] + [i + 1 for i, m in enumerate(self.milestones) if global_step >= m])[-1]
...: return [init_lr * (self.gamma ** gamma_power) for init_lr in self.init_lr]
...:
...: optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
...: scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-7fad6ba050b0> in <module>
14
15 optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
---> 16 scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
<ipython-input-1-7fad6ba050b0> in __init__(self, optimizer, gamma, milestones, last_epoch)
6 self.gamma = gamma
7 self.milestones = milestones
----> 8 super().__init__(optimizer, last_epoch)
9
10 def get_lr(self, step):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, last_epoch)
75 self._step_count = 0
76
---> 77 self.step()
78
79 def state_dict(self):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in step(self, epoch)
141 print("1a")
142 # try:
--> 143 values = self.get_lr()
144 # except TypeError:
145 # raise RuntimeError
TypeError: get_lr() missing 1 required positional argument: 'step'
```
May be related to https://github.com/pytorch/pytorch/issues/32898.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32997
Differential Revision: D19737731
Pulled By: vincentqb
fbshipit-source-id: 5cf84beada69b91f91e36b20c3278e9920343655
Summary:
This PR fixes type hints for `torch.optim.optimizer.Optimizer` object, issue also reported in https://github.com/pytorch/pytorch/issues/23731
To test things I used following optimiser implementation, that is fully covered with type hints:
```python
from typing import Optional, Callable, Union, Iterable
from torch import Tensor
from torch.optim.optimizer import Optimizer
OptClosure = Optional[Callable[[], float]]
_params_t = Union[Iterable[Tensor], Iterable[dict]]
class SGD(Optimizer):
def __init__(self, params: _params_t, lr: float = 0.1) -> None:
defaults = dict(lr=lr)
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state: dict) -> None:
super(SGD, self).__setstate__(state)
def step(self, closure: OptClosure = None) -> Optional[float]:
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
p.data.add_(-group['lr'], d_p)
return loss
```
Without fix `mypy` reports bunch of inconsistencies in types and missing properties:
```bash
$ mypy torch_optimizer/sgd.py
torch_optimizer/sgd.py:14: error: Too many arguments for "__init__" of "Optimizer"
torch_optimizer/sgd.py:17: error: "__setstate__" undefined in superclass
torch_optimizer/sgd.py:19: error: Return type "Optional[float]" of "step" incompatible with return type "None" in supertype "Optimizer"
torch_optimizer/sgd.py:24: error: "SGD" has no attribute "param_groups"
Found 4 errors in 1 file (checked 1 source file)
```
with fix not issues:
```bash
$ mypy torch_optimizer/sgd.py
Success: no issues found in 1 source file
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32900
Differential Revision: D19697175
Pulled By: ezyang
fbshipit-source-id: d5e2b3c421f69da3df8c32b3d53b4b6d15d61a41
Summary:
**Patch Description**
Round out the rest of the optimizer types in torch.optim by creating the stubs for the rest of them.
**Testing**:
I ran mypy looking for just errors in that optim folder. There's no *new* mypy errors created.
```
$ mypy torch/optim | grep optim
$ git checkout master; mypy torch/optim | wc -l
968
$ git checkout typeoptims; mypy torch/optim | wc -l
968
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31130
Reviewed By: stephenroller
Differential Revision: D18947145
Pulled By: vincentqb
fbshipit-source-id: 5b8582223833b1d9123d829acc1ed8243df87561
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27850
Many of these are real problems in the documentation (i.e., link or
bullet point doesn't display correctly).
Test Plan: - built and viewed the documentation for each change locally.
Differential Revision: D17908123
Pulled By: zou3519
fbshipit-source-id: 65c92a352c89b90fb6b508c388b0874233a3817a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26423
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
# ghstack
This contains the changes from #24352. Opening again since they were reverted.
This reverts commit 1c477b7e1f.
Test Plan: Imported from OSS
Differential Revision: D17460427
Pulled By: vincentqb
fbshipit-source-id: 8c10f4e7246d6756ac91df734e8bed65bdef63c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24352
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
Test Plan: Imported from OSS
Differential Revision: D17349760
Pulled By: vincentqb
fbshipit-source-id: 0a6ac01e2a6b45000bc6f9df732033dd81f0d89f
Summary:
Hi,
I noticed after v1.2.0 the implement of LBFGS optimizer has been changed. In this new implement, the return condition has been changed from the sum of the gradients to the max value in the gradients (see: b15d91490a/torch/optim/lbfgs.py (L313)). But the default tolerance_grad parameter has not been changed (which is too large for max of gradients), so this result in lots of my old codes not optimizing or only optimizing for one or two steps.
So, I came up this pull request to suggest that changing this tolerance_grad to a smaller value
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25240
Differential Revision: D17102713
Pulled By: vincentqb
fbshipit-source-id: d46acacdca1c319c1db669f75da3405a7db4a7cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24980
We'll need this internally, so just updating the open source version. the other optimizers have this argument anyways.
Test Plan: Imported from OSS
Differential Revision: D16945279
Pulled By: li-roy
fbshipit-source-id: 0b8cc86f15387cd65660747899d3d7dd870cff27
Summary:
Some interfaces of schedulers defined in lr_scheduler.py are missing in lr_scheduler.pyi.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23934
Differential Revision: D16726622
Pulled By: ezyang
fbshipit-source-id: 45fd2d28fbb658c71f6fcd33b8997d6ee8e2b17d
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/23480.
I only verified that the schedule reaches the restart at the expected step as specified in the issue, it would be good to have someone else verify correctness here.
Script:
```
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(torch.optim.SGD([torch.randn(1, requires_grad=True)], lr=0.5), T_0=1, T_mult=2)
for i in range(9):
print(i)
print(scheduler.get_lr())
scheduler.step()
```
Output:
```
0
[0.5]
1
[0.5]
2
[0.25]
3
[0.5]
4
[0.42677669529663687]
5
[0.25]
6
[0.07322330470336313]
7
[0.5]
8
[0.4809698831278217]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23833
Differential Revision: D16657251
Pulled By: gchanan
fbshipit-source-id: 713973cb7cbfc85dc333641cbe9feaf917718eb9
Summary:
# What is this?
This is an implementation of the AdamW optimizer as implemented in [the fastai library](803894051b/fastai/callback.py) and as initially introduced in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101). It decouples the weight decay regularization step from the optimization step during training.
There have already been several abortive attempts to push this into pytorch in some form or fashion: https://github.com/pytorch/pytorch/pull/17468, https://github.com/pytorch/pytorch/pull/10866, https://github.com/pytorch/pytorch/pull/3740, https://github.com/pytorch/pytorch/pull/4429. Hopefully this one goes through.
# Why is this important?
Via a simple reparameterization, it can be shown that L2 regularization has a weight decay effect in the case of SGD optimization. Because of this, L2 regularization became synonymous with the concept of weight decay. However, it can be shown that the equivalence of L2 regularization and weight decay breaks down for more complex adaptive optimization schemes. It was shown in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) that this is the reason why models trained with SGD achieve better generalization than those trained with Adam. Weight decay is a very effective regularizer. L2 regularization, in and of itself, is much less effective. By explicitly decaying the weights, we can achieve state-of-the-art results while also taking advantage of the quick convergence properties that adaptive optimization schemes have.
# How was this tested?
There were test cases added to `test_optim.py` and I also ran a [little experiment](https://gist.github.com/mjacar/0c9809b96513daff84fe3d9938f08638) to validate that this implementation is equivalent to the fastai implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21250
Differential Revision: D16060339
Pulled By: vincentqb
fbshipit-source-id: ded7cc9cfd3fde81f655b9ffb3e3d6b3543a4709
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/19003
The author of this issue also asked that `cycle_momentum` default to `False` if the optimizer does not have a momentum parameter, but I'm not sure what the best way to do this would be. Silently changing the value based on the optimizer may confuse the user in some cases (say the user explicitly set `cycle_momentum=True` but doesn't know that the Adam optimizer doesn't use momentum).
Maybe printing a warning when switching this argument's value would suffice?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20401
Differential Revision: D15765463
Pulled By: ezyang
fbshipit-source-id: 88ddabd9e960c46f3471f37ea46013e6b4137eaf
Summary:
This PR addresses the problem described in the comment: https://github.com/pytorch/pytorch/pull/20203#issuecomment-499231276
and previously coded bad behaviour:
- a warning was raised all the times when lr schedulling is initialized
Now the code checks that:
- on the second call of `lr_scheduler.step`, ensure that `optimizer.step` has been already called, otherwise raise a warning (as it was done in #20203 )
- if optimizer's step is overridden -> raise once another warning to aware user about the new pattern:
`opt.step()` -> `lrs.step()` as we can not check this .
Now tests check that
- at initialization (`lrs = StepLR(...)`)there is no warnings
- if we replace `optimizer.step` by something else (similarly to the [code of nvidia/apex](https://github.com/NVIDIA/apex/blob/master/apex/amp/_process_optimizer.py#L287)) there is another warning raised.
cc ezyang
PS. honestly I would say that there is a lot of overhead introduced for simple warnings. I hope all these checks will be removed in future `1.2.0` or other versions...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21460
Differential Revision: D15701776
Pulled By: ezyang
fbshipit-source-id: eac5712b9146d9d3392a30f6339cd33d90c497c7
Summary:
Fixes a typo in the CyclicLR docs by adding the lr_scheduler directory and puts in other required arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21021
Differential Revision: D15530109
Pulled By: soumith
fbshipit-source-id: 98781bdab8d82465257229e50fa3bd0015da1286
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20880
This clarifies how the momentum parameters should be used.
Reviewed By: soumith
Differential Revision: D15482450
fbshipit-source-id: e3649a38876c5912cb101d8e404abca7c3431766
Summary:
Resubmit #20698 which got messed up.
Idea is that when PyTorch is used in a custom build environment (e.g. Facebook), it's useful to track usage of various APIs centrally. This PR introduces a simple very lightweight mechanism to do so - only first invocation of a trigger point would be logged. This is significantly more lightweight than #18235 and thus we can allow to put logging in e.g. TensorImpl.
Also adds an initial list of trigger points. Trigger points are added in such a way that no static initialization triggers them, i.e. just linking with libtorch.so will not cause any logging. Further suggestions of what to log are welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20745
Differential Revision: D15429196
Pulled By: dzhulgakov
fbshipit-source-id: a5e41a709a65b7ebccc6b95f93854e583cf20aca
Summary:
Class attributes preferably be explicitly initiated within
the __init__() call. Otherwise, overriding step() is
prone to bugs.
This patch partially reverts #7889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20059
Differential Revision: D15195747
Pulled By: soumith
fbshipit-source-id: 3d1a51d8c725d6f14e3e91ee94c7bc7a7d6c1713
Summary:
Because of merge error with master in #15042, open a new PR for ezyang.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17226
Differential Revision: D14418145
Pulled By: mrshenli
fbshipit-source-id: 099ba225b28e6aba71760b81b2153ad1c40fbaae
Summary:
The current code initialize the `state` in `__init__` method, but the initialization process is not invoked in `add_parameter_group`.
I followed the same approach in other Optimizers to init the `state`.
```python
import torch
emb = torch.nn.Embedding(10,10)
emb2 = torch.nn.Embedding(10,10)
optim = torch.optim.Adagrad(emb.parameters())
print(optim.state[emb.weight]) # already initialized
optim.add_param_group({'params': emb2.parameters()})
print(optim.state[emb2.weight]) # empty dict
loss = emb2.weight.sum() + emb.weight.sum()
loss.backward()
optim.step() # raised KeyError
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17679
Differential Revision: D14577575
Pulled By: ezyang
fbshipit-source-id: 12440079ac964b9eedad48e393d47f558babe300
Summary:
Added the formula for the corner case. Updated unit tests.
Fixes#17913
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19180
Differential Revision: D14942023
Pulled By: ezyang
fbshipit-source-id: 167c109b97a7830d5b24541dc91e4788d531feec
Summary:
Hello everyone :) !!
I've found that lr_scheduler was initialized with last_epoch as -1.
This causes that even after the first step (not the one in init but explicit step of scheduler),
learning rate of scheduler's optimizer remains as the previous.
```python
>>> import torch
>>> cc = torch.nn.Conv2d(10,10,3)
>>> myinitial_lr = 0.1
>>> myoptimizer = torch.optim.Adam(cc.parameters(), lr=myinitial_lr)
>>> mylrdecay = 0.5
>>> myscheduler = torch.optim.lr_scheduler.ExponentialLR(myoptimizer,mylrdecay)
>>> myscheduler.get_lr()
[0.2] # this is because of get_lr calculates lr by 0.1 * 0.5^-1
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # this is not consistent with get_lr value
>>> myscheduler.last_epoch
-1
>>> myscheduler.step()
>>> myscheduler.get_lr()
[0.1] # this should be the value right after the init, not after first step
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # since this is after first step, it should have been decayed as 0.05
>>> myscheduler.last_epoch
0
>>> myscheduler.step()
>>> myscheduler.last_epoch
1
>>> myscheduler.get_lr()
[0.05]
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.05
>>> myscheduler.last_epoch
1
```
First problem is, even after the init of lr_scheduler, you get the inconsistent parameter values.
The second problem is, you are stuck with same learning rate in the first 2 epochs if the step function of lr_scheduler is not called in the beginning of the epoch loop.
Of course, you can avoid this by calling lr_scheduler's step in the beginning,
but I don't think this is proper use since, incase of optimizer, step is called in the end of the iteration loop.
I've simply avoided all above issues by setting last_epoch as 0 after the initialization.
This also makes sense when you init with some value of last_epoch which is not -1.
For example, if you want to init with last epoch 10,
lr should not be set with decayed 1 step further. Which is
last_epoch gets +1 in the previous code.
base_lr * self.gamma ** self.last_epoch
Instead, it should be set with step 10 exact value.
I hope this fix find it's way with all your help :)
I'm really looking forward & excited to become a contributor for pytorch!
Pytorch Rocks!!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/7889
Differential Revision: D15012769
Pulled By: ezyang
fbshipit-source-id: 258fc3009ea7b7390a3cf2e8a3682eafb506b08b
Summary:
Add the defaults field to the copied object.
Prior to this patch, optimizer.__getattr__ has excluded the defaults
attribute of optimizer source object, required by some LR schedulers. (e.g. CyclicLR with momentum)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19308
Differential Revision: D15012801
Pulled By: soumith
fbshipit-source-id: 95801b269f6f9d78d531d4fed95c973b280cc96f
Summary:
Added stubs for:
* The `device` module
* The `cuda` module
* Parts of the `optim` module
* Began adding stubs for the `autograd` module. I'll annotate more later but `no_grad` and friends are probably the most used exports from it so it seemed like a good place to start.
This would close#16996, although comments on that issue reference other missing stubs so maybe it's worth keeping open as an umbrella issue.
The big remaining missing package is `nn`.
Also added a `py.typed` file so mypy will pick up on the type stubs. That closes#17639.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18511
Differential Revision: D14715053
Pulled By: ezyang
fbshipit-source-id: 9e4882ac997063650e6ce47604b3eaf1232c61c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
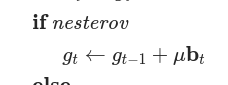{kind=link}
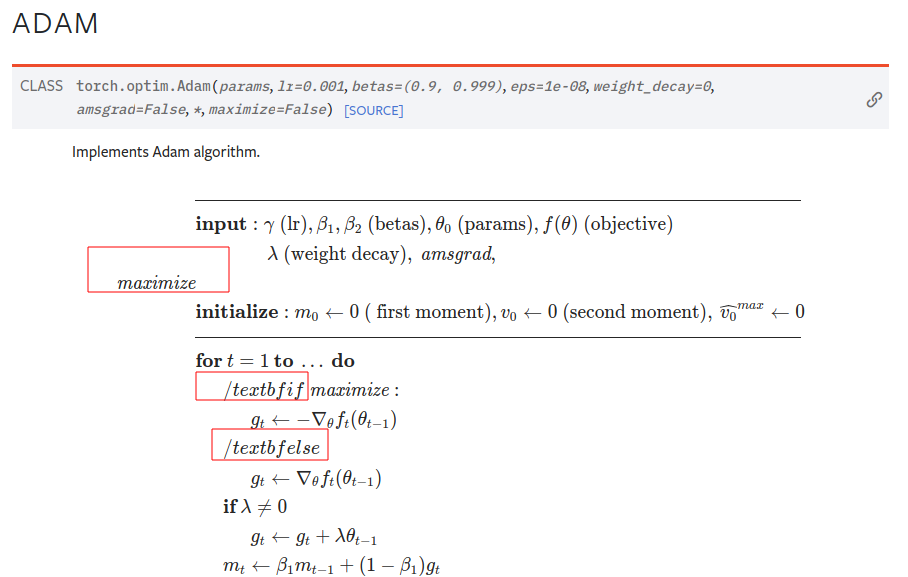{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
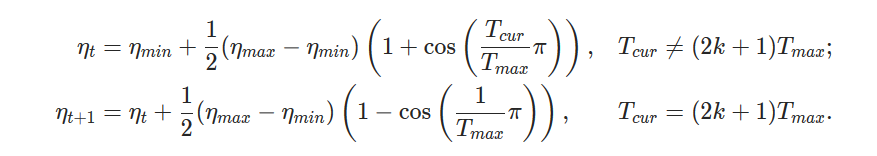{kind=link}
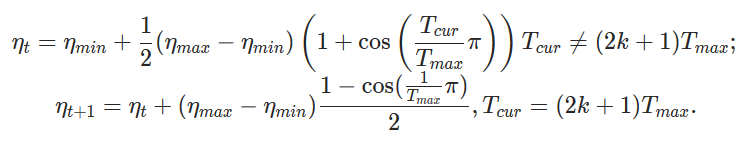{kind=link}
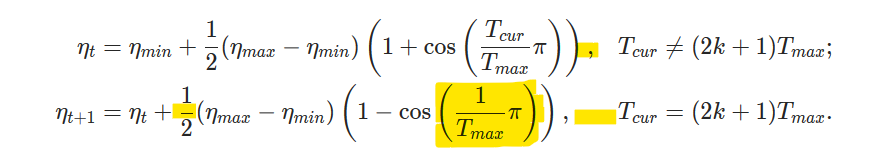{kind=link}
{kind=link}
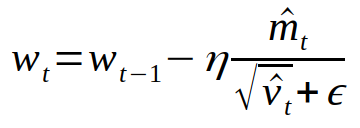{kind=link}
{kind=link}
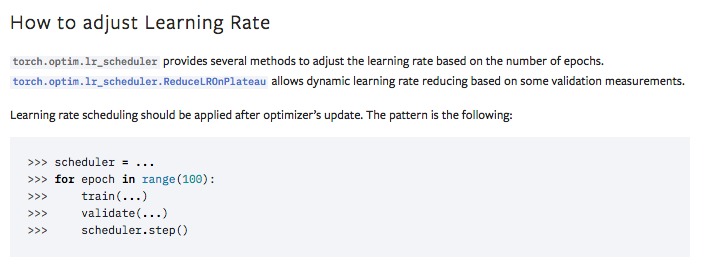{kind=link}