Currently the user can use torch.onnx.dynamo_export to export the model.
to ONNX.
```python
import torch
class Model(torch.nn.Module):
def forward(self, x):
return x + 1.0
onnx_program = torch.onnx.dynamo_export(
Model(),
torch.randn(1, 1, 2, dtype=torch.float),
)
```
The next step would be instantiating a ONNX runtime to execute it.
```python
import onnxruntime # type: ignore[import]
onnx_input = self.adapt_torch_inputs_to_onnx(*args, **kwargs)
options = options or {}
providers = options.get("providers", onnxruntime.get_available_providers())
onnx_model = self.model_proto.SerializeToString()
ort_session = onnxruntime.InferenceSession(onnx_model, providers=providers)
def to_numpy(tensor):
return (
tensor.detach().cpu().numpy()
if tensor.requires_grad
else tensor.cpu().numpy()
)
onnxruntime_input = {
k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)
}
return ort_session.run(None, onnxruntime_input)
```
This PR provides the `ONNXProgram.__call__` method as facilitator to use ONNX Runtime under the hood, similar to how `torch.export.ExportedProgram.__call__` which allows the underlying `torch.fx.GraphModule` to be executed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113495
Approved by: https://github.com/titaiwangms
Since PyTorch 2.1, torch.export API was introduced and the term "export"
got overloaded due to the already existing torch.onnx.export API.
The torch.onnx.dynamo_export API was introduced on pyTorch 2.0 and it
exposed a torch.onnx.ExportOutput which now can be confused with
torch.export.export output
To prevent such ambiguity and standardize names around the new
torch.export.ExportedProgram, this PR renames torch.onnx.ExportOutput to
torch.onnx.ONNXProgram
Pull Request resolved: https://github.com/pytorch/pytorch/pull/112263
Approved by: https://github.com/BowenBao
ghstack dependencies: #112444
Fixes#109889
This PR adds `torch.export.export` as another `FXGraphExtractor` implementation. `torch.onnx.dynamo_export` automatically uses this new FX tracer when a `torch.export.ExportedProgram` is specified as `model`
Implementation is back compatible, thus non `ExportedProgram` models are handled the exact same way as before
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111497
Approved by: https://github.com/BowenBao
Fixes#109889
This PR adds `torch.export.export` as another `FXGraphExtractor` implementation. `torch.onnx.dynamo_export` automatically uses this new FX tracer when a `torch.export.ExportedProgram` is specified as `model`
Implementation is back compatible, thus non `ExportedProgram` models are handled the exact same way as before
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111497
Approved by: https://github.com/BowenBao
This reworks the DORT backend factory function to support the options kwarg of torch.compile, and defines a concrete OrtBackendOptions type that can be used to influence the backend.
Caching is also implemented in order to reuse backends with equal options.
Wrapping the backend in auto_autograd also becomes an option, which allows `OrtBackend` to always be returned as the callable for torch.compile; wrapping happens internally if opted into (True by default).
Lastly, expose options for configuring preferred execution providers (will be attempted first), whether or not to attempt to infer an ORT EP from a torch found device in the graph or inputs, and finally the default/fallback EPs.
### Demo
The following demo runs `Gelu` through `torch.compile(backend="onnxrt")` using various backend options through a dictionary form and a strongly typed form. It additionally exports the model through both the ONNX TorchScript exporter and the new TorchDynamo exporter.
```python
import math
import onnx.inliner
import onnxruntime
import torch
import torch.onnx
torch.manual_seed(0)
class Gelu(torch.nn.Module):
def forward(self, x):
return x * (0.5 * torch.erf(math.sqrt(0.5) * x) + 1.0)
@torch.compile(
backend="onnxrt",
options={
"preferred_execution_providers": [
"NotARealEP",
"CPUExecutionProvider",
],
"export_options": torch.onnx.ExportOptions(dynamic_shapes=True),
},
)
def dort_gelu(x):
return Gelu()(x)
ort_session_options = onnxruntime.SessionOptions()
ort_session_options.log_severity_level = 0
dort_gelu2 = torch.compile(
Gelu(),
backend="onnxrt",
options=torch.onnx._OrtBackendOptions(
preferred_execution_providers=[
"NotARealEP",
"CPUExecutionProvider",
],
export_options=torch.onnx.ExportOptions(dynamic_shapes=True),
ort_session_options=ort_session_options,
),
)
x = torch.randn(10)
torch.onnx.export(Gelu(), (x,), "gelu_ts.onnx")
export_output = torch.onnx.dynamo_export(Gelu(), x)
export_output.save("gelu_dynamo.onnx")
inlined_model = onnx.inliner.inline_local_functions(export_output.model_proto)
onnx.save_model(inlined_model, "gelu_dynamo_inlined.onnx")
print("Torch Eager:")
print(Gelu()(x))
print("DORT:")
print(dort_gelu(x))
print(dort_gelu2(x))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107973
Approved by: https://github.com/BowenBao
Generate diagnostic reports to monitor the internal stages of the export process. This tool aids in unblocking model exports and debugging the exporter.
#### Settings
~~1. Choose if you want to produce a .sarif file and specify its location.~~
1. Updated: saving .sarif file should be done by `export_output.save_sarif_log(dst)`, similar to saving exported onnx model `export_output.save(model_dst)`.
2. Customize diagnostic options:
- Set the desired verbosity for diagnostics.
- Treat warnings as errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106741
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby, https://github.com/malfet
The official move of `OnnxRegistry` to `torch.onnx` allows it to become one of the parameters in `torch.onnx.ExportOption`. By incorporating `OnnxRegistry` in `torch.onnx.ExportOption`, users gain access to various functionalities, including the ability to register custom operators using `register_custom_op`, check whether an operator is supported using `is_registered_op`, and obtain symbolic functions that support specific operators using `get_functions`.
Additionally, `opset_version` is now exclusively available in `torch.onnx.OnnxRegistry` as it is removed from `torch.onnx.ExportOption`. The initialization of the registry with torchlib under the provided opset version ensures that the exporter uses the specified opset version as the primary version for exporting.
These changes encompass scenarios where users can:
1. Register an unsupported ATen operator with a custom implementation using onnx-script.
2. Override an existing symbolic function (onnx invariant).
NOTE: The custom registered function will be prioritized in onnx dispatcher, and if there are multiple custom ones, the one registered the last will be picked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106140
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi
## Context prior to this PR
https://github.com/pytorch/pytorch/pull/100017/ was merged onto PyTorch `main` branch with the goal of enabling `torch._dynamo.export` to perform symbolic tracing.
In that context, symbolic tracing is defined as tracing of a model using fake inputs and weights. An input is Fake when `torch.nn.Tensor` is replaced by `torch._subclasses.FakeTensor`, whereas a weight is fake when a `torch.nn.Parameter` is replaced by `torch._subclasses.FakeTensor`.
For additional context, several strategies were discussed with Meta to enable this feature, including 1) calling `torch._dynamo.export` within a `torch._subclass.FakeTensorMode` context and 2) **fake**fying input and model as separate step and then call `torch._dynamo.export` without an active `torch._subclass.FakeTensorMode` context. At the end, 2) was preferred and implemented by #100017 to minimize the number of side-effects the fake tensor mode has on the code base.
As a consequence, `torch._dynamo.export` API introduced a new argument called `fake_mode`. When symbolic tracing is used, the user must pass in the `fake_mode` used to fakefy both the input and the model. Internally, `torch._dynamo.export` will adopt this `fake_mode` instead of creating its own instance. This is needed because each instance of `FakeTensorMode` has metadata on the tensor/parameter it fakefied. Thus, using real tensor/model and specify a `fake_mode` to `torch._dynamo.export` is an error. Also, specify a `fake_mode` instance to `torch._dynamo.export` different than the one used to fakefy the model and input is also an error.
## Changes introduced from this PR
This PR is intended to integrate `torch._dynamo.export(fake_mode=...)` through `torch.onnx.dynamo_export`. In essence, it
* Introduces a new public API `ONNXFakeContext` which wraps a `FakeTensorMode` under the hood. This removes complexity from the user side while still allow the exporter to leverage the fake mode.
* Adds a new public API `enable_fake_mode` *context manager* that instantiates and return a `ONNXFakeContext`.
* Adds a new `ExportOptions.fake_context` that will be used to persist the `ONNXFakeContext` created by `enable_fake_mode` and plumb through until it reaches the call to `torch._dynamo.export`.
* Adds a `model_state_dict` argument to `ExportOutput.save` API.
* When model is exported with fake tensors, no actual data exist in the FX module and, therefore, in the ONNX graph.
* In fact, `torch.fx.make_fx` lifts initializers as model input when fake tensors are used
* https://github.com/pytorch/pytorch/pull/104493 is needed to enforce name matching between Parameters and inputs
* A model checkpoint file or state_dict is needed to populate the ONNX graph with real initializers through `export_output.save(model_state_dict=...)` API
Symbolic tracing, or onnx fake mode, is only enabled when the user instantiates the input and model within the `enable_fake_mode` context. Otherwise, real tracing is done, which preserves the current behavior.
## Usability
Because symbolic tracing depends a lot on having changes made on Dynamo side before it can be consumed on ONNX exporter, this feature may have its API and assumptions changed as symbolic tracing matures upstream. Nonetheless, it is still important to have this feature merged ASAP on the ONNX exporter side to "lock" changes on Dynamo that would otherwise break ONNX exporter without warning.
Example:
```python
class Model(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = torch.nn.Linear(2, 2)
def forward(self, x):
out = self.linear(x)
return out
with torch.onnx.enable_fake_mode() as fake_context:
x = torch.rand(5, 2, 2)
model = Model()
# Export the model with fake inputs and parameters
export_options = ExportOptions(fake_context=fake_context)
export_output = torch.onnx.dynamo_export(
model, x, export_options=export_options
)
model_state_dict = Model().state_dict() # optional
export_output.save("/path/to/model.onnx", model_state_dict=model_state_dict)
```
## Next steps
* Add unit tests running the exported model with ORT
Today this is not possible yet because `make_fx` used by our Decomposition pass lifts initializers as model inputs. However, the initializer names are not preserved by FX tracing, causing a mismatch between the initializer and input name.
https://github.com/pytorch/pytorch/pull/104493 and https://github.com/pytorch/pytorch/pull/104741 should fix the initializer mismatch, enabling model execution
* Revisit `ONNXTorchPatcher` and how the ONNX initializers are saved in the graph as external data
We can try to get rid of the PyTorch patcher. If we can't, we might prefer to create specific patchers, say `FXSymbolicTracePatcher` used specifically during an export using `torch.fx.symbolic_trace` and maybe a `ExportOutputSavePacther` used specifically for `ExportOutput.save` to prevent "patching too many pytorch API that we don't need
## References
* [FakeTensor implementation](https://github.com/pytorch/pytorch/blob/main/torch/_subclasses/fake_tensor.py)
* [PR that adds fake tensor support to torch._dynamo.export](https://github.com/pytorch/pytorch/pull/100017)
* [Short fake tensor documentation](https://pytorch.org/torchdistx/latest/fake_tensor.html)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103865
Approved by: https://github.com/BowenBao
This is the first phase of the new ONNX exporter API for exporting from TorchDynamo and FX, and represents the beginning of a new era for exporting ONNX from PyTorch.
The API here is a starting point upon which we will layer more capability and expressiveness in subsequent phases. This first phase introduces the following into `torch.onnx`:
```python
dynamo_export(
model: torch.nn.Module,
/,
*model_args,
export_options: Optional[ExportOptions] = None,
**model_kwargs,
) -> ExportOutput:
...
class ExportOptions:
opset_version: Optional[int] = None
dynamic_shapes: Optional[bool] = None
logger: Optional[logging.Logger] = None
class ExportOutputSerializer(Protocol):
def serialize(
self,
export_output: ExportOutput,
destination: io.BufferedIOBase,
) -> None:
...
class ExportOutput:
model_proto: onnx.ModelProto
def save(
self,
destination: Union[str, io.BufferedIOBase],
*,
serializer: Optional[ExportOutputSerializer] = None,
) -> None:
...
```
In addition to the API in the first commit on this PR, we have a few experiments for exporting Dynamo and FX to ONNX that this PR rationalizes through the new Exporter API and adjusts tests to use the new API.
- A base `FXGraphModuleExporter` exporter from which all derive:
- `DynamoExportExporter`: uses dynamo.export to acquire FX graph
- `DynamoOptimizeExporter`: uses dynamo.optimize to acquire FX graph
- `FXSymbolicTraceExporter`: uses FX symbolic tracing
The `dynamo_export` API currently uses `DynamoOptimizeExporter`.
### Next Steps (subsequent PRs):
* Combine `DynamoExportExporter` and `DynamoOptimizeExporter` into a single `DynamoExporter`.
* Make it easy to test `FXSymbolicTraceExporter` through the same API; eventually `FXSymbolicTraceExporter` goes away entirely when the Dynamo approach works for large models. We want to keep `FXSymbolicTraceExporter` around for now for experimenting and internal use.
* Parameterize (on `ExportOptions`) and consolidate Dynamo exporter tests.
- This PR intentionally leaves the existing tests unchanged as much as possible except for the necessary plumbing.
* Subsequent API phases:
- Diagnostics
- Registry, dispatcher, and Custom Ops
- Passes
- Dynamic shapes
Fixes#94774
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97920
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi, https://github.com/shubhambhokare1
This is the 4th PR in the series of #83787. It enables the use of `@onnx_symbolic` across `torch.onnx`.
- **Backward breaking**: Removed some symbolic functions from `__all__` because of the use of `@onnx_symbolic` for registering the same function on multiple aten names.
- Decorate all symbolic functions with `@onnx_symbolic`
- Move Quantized and Prim ops out from classes to functions defined in the modules. Eliminate the need for `isfunction` checking, speeding up the registration process by 60%.
- Remove the outdated unit test `test_symbolic_opset9.py`
- Symbolic function registration moved from the first call to `_run_symbolic_function` to init time.
- Registration is fast:

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84448
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
## Summary
The change brings the new registry for symbolic functions in ONNX. The `SymbolicRegistry` class in `torch.onnx._internal.registration` replaces the dictionary and various functions defined in `torch.onnx.symbolic_registry`.
The new registry
- Has faster lookup by storing only functions in the opset version they are defined in
- Is easier to manage and interact with due to its class design
- Builds the foundation for the more flexible registration process detailed in #83787
Implementation changes
- **Breaking**: Remove `torch.onnx.symbolic_registry`
- `register_custom_op_symbolic` and `unregister_custom_op_symbolic` in utils maintain their api for compatibility
- Update _onnx_supported_ops.py for doc generation to include quantized ops.
- Update code to register python ops in `torch/csrc/jit/passes/onnx.cpp`
## Profiling results
-0.1 seconds in execution time. -34% time spent in `_run_symbolic_function`. Tested on the alexnet example in public doc.
### After
```
└─ 1.641 export <@beartype(torch.onnx.utils.export) at 0x7f19be17f790>:1
└─ 1.641 export torch/onnx/utils.py:185
└─ 1.640 _export torch/onnx/utils.py:1331
├─ 0.889 _model_to_graph torch/onnx/utils.py:1005
│ ├─ 0.478 _optimize_graph torch/onnx/utils.py:535
│ │ ├─ 0.214 PyCapsule._jit_pass_onnx_graph_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ ├─ 0.190 _run_symbolic_function torch/onnx/utils.py:1670
│ │ │ └─ 0.145 Constant torch/onnx/symbolic_opset9.py:5782
│ │ │ └─ 0.139 _graph_op torch/onnx/_patch_torch.py:18
│ │ │ └─ 0.134 PyCapsule._jit_pass_onnx_node_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ └─ 0.033 [self]
```
### Before
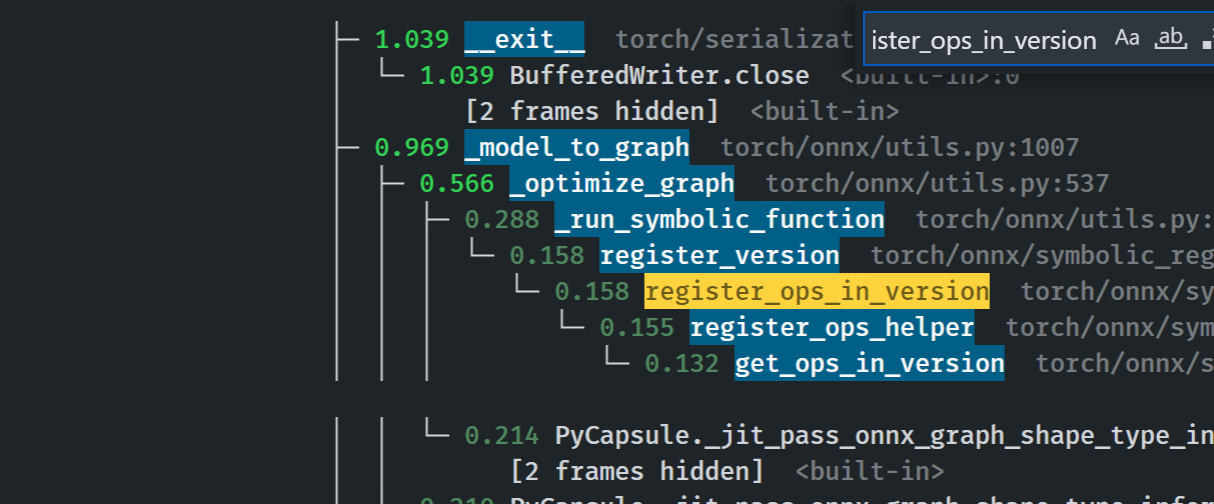
### Start up time
The startup process takes 0.03 seconds. Calls to `inspect` will be eliminated when we switch to using decorators for registration in #84448

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84382
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Re-land #81953
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Deprecated: "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type" in `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82995
Approved by: https://github.com/kit1980
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Breaking: **Remove "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type"** from `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81953
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
- Remove wrappers in `__init__` around utils and instead expose those functions directly. Move the docstrings from `__init__` to corresponding functions in utils
- Annotate `torch.onnx.export` types
- Improve docstrings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78231
Approved by: https://github.com/BowenBao
Cleaning up onnx module imports to prepare for updating `__init__`.
- Simplify importing the `_C` and `_C._onnx` name spaces
- Remove alias of the symbolic_helper module in imports
- Remove any module level function imports. Import modules instead
- Alias `symbilic_opsetx` as `opsetx`
- Fix some docstrings
Requires:
- https://github.com/pytorch/pytorch/pull/77448
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77423
Approved by: https://github.com/BowenBao
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
Summary:
And add a new tool to update it in the future, which follows the policy
of using "latest as of 18 months ago". This policy is meant to balance:
* recent enough to increase the odds of being able to successfully
export
* old enough to increase the odds of exported model being runnable by
different ONNX implementations
Related changes:
* test_models.py: explicitly fix opset_version to 9 rather than relying on default. Caffe2 doesn't support newer versions.
* symbolic_helper.py:
* Remove a misleading comment
* Remove unnecessary check in `_set_opset_version`
* Use a range to define `_onnx_stable_opsets`
* test_pytorch_common.py:
* Rename a variable from min -> max. I think it was a copy-paste error.
* Make skip test messages more informative.
* Remove unused `skipIfONNXShapeInference`. More on that below.
* test_pytorch_onnx_onnxruntime.py:
* Make all the `TestCase` classes explicitly specify opset version.
* Make `test_unsupported_pad` respect `opset_version` by using `run_test`
* Unrelated simplification: make it obvious that all tests run with `onnx_shape_inference=True`. AFAICT this was already the case.
* There was one test that was entirely disabled (test_tolist) because it was asking to be skipped whenever `onnx_shape_inference=True`, but it was always True. I changed the model being tested so as to preserve the intended test coverage but still have the test actually pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73898
Reviewed By: msaroufim
Differential Revision: D35264615
Pulled By: malfet
fbshipit-source-id: cda8fbdffe4cc8210d8d96e659e3a9adf1b5f1d2
(cherry picked from commit b5e639e88828d34442282d0b50c977e610a2ba3a)
Summary:
Add ONNX exporter logging facility. Supporting both C++/Python logging api. Logging can be turned on/off. Logging output stream can be either set to `stdout` or `stderr`.
A few other changes:
* When exception is raised in passes, the current IR graph being processed will be logged.
* When exception is raised from `_jit_pass_onnx` (the pass that converts nodes from namespace `ATen` to `ONNX`), both ATen IR graph and ONNX IR graph under construction will be logged.
* Exception message for ConstantFolding is truncated to avoid being too verbose.
* Update the final printed IR graph with node name in ONNX ModelProto as node attribute. Torch IR Node does not have name. Adding this to printed IR graph helps debugging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71342
Reviewed By: msaroufim
Differential Revision: D34433473
Pulled By: malfet
fbshipit-source-id: 4b137dfd6a33eb681a5f2612f19aadf5dfe3d84a
(cherry picked from commit 67a8ebed5192c266f604bdcca931df6fe589699f)
Enables local function export to capture annotated attributes.
For example:
```python
class M(torch.nn.Module):
num_layers: int
def __init__(self, num_layers):
super().__init__()
self.num_layers = num_layers
def forward(self, args):
...
```
`num_layers` will now be captured as attribute of local function `M`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72883
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68491
* Allows implementing symbolic functions for domains other than `aten`, for example `prim`, in symbolic_opset#.py.
* Allows symbolic function to access extra context if needed, through `SymbolicFunctionState`.
* Particularly, the `prim::PythonOp` special case can access node without the need of passing node through inputs. Updates will be made downstreams, and in a follow-up PR we will remove the previous workaround in exporter.
* `prim::Loop`, `prim::If`, etc are now moved outside of `_run_symbolic_function` from utils.py, and to symbolic_opset9.py.
Motivation for this change:
- Better maintainability and reducing complexity. Easier to add symbolic for operators, both simple and complex ones (that need additional context), without the former needing to know the existence of the latter.
- The design idea was long outdated. prim ops are no longer rare special cases, and they shouldn't all be handled inside `_run_symbolic_function`. As a result this function becomes too clumsy. There were also prim ops symbolic added in symbolic_opset#.py with signature `prim_[opname]`, creating separation and confusion.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483782
Pulled By: malfet
fbshipit-source-id: f9affc31b1570af30ffa6668da9375da111fd54a
Co-authored-by: BowenBao <bowbao@microsoft.com>
(cherry picked from commit 1e04ffd2fd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68490
The use of ATEN as a fallback operator during ONNX conversion is important for increasing operator coverage or even provide more efficient implementations over some ONNX ops.
Currently this feature is available through `OperatorExportTypes.ONNX_ATEN_FALLBACK`,
but it also performs changes to the graph that are runnable by Caffe2, only.
This PR introduces restricts caffe2-specific graph transformations for `ONNX_ATEN_FALLBACK`
operator export type for when pytorch is built with caffe2 support (aka BUILD_CAFFE2=1 during build)
The first version of this PR introduced a new operator export type `ONNX_ATEN__STRICT_FALLBACK`,
which essentially is the same as `ONNX_ATEN_FALLBACK` but without caffe2 transformations.
It was preferred to not introduce a new operator export type, but to refine the existing aten fallback one
## BC-breaking note
### The global constant `torch.onnx.PYTORCH_ONNX_CAFFE2_BUNDLE` is removed in favor of
a less visible `torch.onnx._CAFFE2_ATEN_FALLBACK`.
`PYTORCH_ONNX_CAFFE2_BUNDLE` is really a dead code flag always set to False.
One alternative would be fixing it, but #66658 disables Caffe2 build by default.
Making a Caffe2 feature a private one seems to make more sense for future deprecation.
### The method `torch.onnx.export` now defaults to ONNX when `operator_export_type` is not specified.
Previously `torch.onnx.export's operator_export_type` intended to default to `ONNX_ATEN_FALLBACK` when `PYTORCH_ONNX_CAFFE2_BUNDLE` was set, but it would never happen as `PYTORCH_ONNX_CAFFE2_BUNDLE` is always undefined
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483781
Pulled By: malfet
fbshipit-source-id: e9b447db9466b369e77d747188685495aec3f124
(cherry picked from commit 5fb1eb1b19)
Cover more cases of scope inferencing where consecutive nodes don't have valid scope information. Usually these nodes are created in some pass where authors forgot to assign meaningful scope to them.
* One rule of `InferScope` is to check if the current node's outputs' users share the same scope. Recursively run `InferScope` on the user nodes if they are missing scope as well. Since the graph is SSA, the depth is finite.
* Fix one pass that missed scope information for a new node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71897
Export should fail if export_modules_as_functions is set and opset_version<15.
This is because opeset_version < 15 implies IR version < 8, which means no local function support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71619
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69549
[ONNX] minor clarifications of docstrings
1. Make description of ONNX_ATEN_FALLBACK more accurate (after #67460).
2. Specify minimum and maximum values for opset_version. This is pretty
important information and we should make users dig through source
code to find it.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32994267
Pulled By: msaroufim
fbshipit-source-id: ba641404107baa23506d337eca742fc1fe9f0772
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69546
The arg is not used and was previously deprecated.
Also remove torch.onnx._export_to_pretty_string. It's redundant with the
public version.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32994270
Pulled By: msaroufim
fbshipit-source-id: f8f3933b371a0d868d9247510bcd73c31a9d6fcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67803
* Addresses comments from #63589
[ONNX] remove torch::onnx::PRODUCER_VERSION (#67107)
Use constants from version.h instead.
This simplifies things since we no longer have to update
PRODUCER_VERSION for each release.
Also add TORCH_VERSION to version.h so that a string is available for
this purpose.
[ONNX] Set `ir_version` based on opset_version. (#67128)
This increases the odds that the exported ONNX model will be usable.
Before this change, we were setting the IR version to a value which may
be higher than what the model consumer supports.
Also some minor clean-up in the test code:
* Fix string replacement.
* Use a temporary file so as to not leave files around in the test
current working directory.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181306
Pulled By: malfet
fbshipit-source-id: 02f136d34ef8f664ade0bc1985a584f0e8c2b663
Co-authored-by: BowenBao <bowbao@microsoft.com>
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Co-authored-by: Nikita Shulga <nshulga@fb.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}