Attempt number 2 at https://github.com/pytorch/pytorch/issues/108950.
Improves debugging for guard failures/recompilations by:
- only running guard fail reason generation during recompilation, instead of when a guard fails during dynamo cache lookup (so generating guard failure reasons is not on the critical path)
- ~~always reporting all guard failures~~ Reports the first-failing guard failure for each cache entry.
We don't expect a performance hit since the guard fail reasons are only generated at recompile time rather than runtime. Perf benchmark to check this (https://hud.pytorch.org/benchmark/torchbench/inductor_with_cudagraphs?startTime=Fri,%2027%20Oct%202023%2017:42:43%20GMT&stopTime=Fri,%2003%20Nov%202023%2017:42:43%20GMT&granularity=hour&mode=training&dtype=amp&lBranch=gh/williamwen42/62/head&lCommit=f4724f5ffc6d17ceae513a42fc18627be7b85482&rBranch=main&rCommit=29f3d392bf230072e3bffae37b078e770cae1956). We may also need to verify this on benchmarks where guard fails are common.
Sample script:
```python
import torch
def generate_data(b):
return (
torch.randn(b, 3, 32, 32).to(torch.float32).cuda(),
torch.randint(1000, (b,)).cuda(),
)
from torchvision.models import resnet18
def init_model():
return resnet18().to(torch.float32).cuda()
model = init_model()
model_opt = torch.compile(model, dynamic=False)
for b in range(16, 32):
data = generate_data(b)
model_opt(data[0])
```
Sample logs:
```bash
(/data/users/williamwen/py310-env) [williamwen@devgpu020.odn1 /data/users/williamwen/pytorch (wwen/log-all-guards)]$ python playground5.py
/data/users/williamwen/pytorch/torch/_inductor/compile_fx.py:141: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-11-06 14:50:47,605] torch._dynamo.convert_frame: [WARNING] torch._dynamo hit config.cache_size_limit (8)
[2023-11-06 14:50:47,605] torch._dynamo.convert_frame: [WARNING] function: 'forward' (/data/users/williamwen/torchvision/torchvision/models/resnet.py:284)
[2023-11-06 14:50:47,605] torch._dynamo.convert_frame: [WARNING] last reason: tensor 'L['x']' size mismatch at index 0. expected 16, actual 24
[2023-11-06 14:50:47,605] torch._dynamo.convert_frame: [WARNING] To log all recompilation reasons, use TORCH_LOGS="recompiles".
[2023-11-06 14:50:47,605] torch._dynamo.convert_frame: [WARNING] To diagnose recompilation issues, see https://pytorch.org/docs/master/compile/troubleshooting.html.
(/data/users/williamwen/py310-env) [williamwen@devgpu020.odn1 /data/users/williamwen/pytorch (wwen/log-all-guards)]$ TORCH_LOGS="recompiles" python playground5.py
/data/users/williamwen/pytorch/torch/_inductor/compile_fx.py:141: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-11-06 14:53:31,591] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:53:31,591] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:53:31,591] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 17
[2023-11-06 14:53:41,333] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:53:41,333] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:53:41,333] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 18
[2023-11-06 14:53:41,333] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 18
[2023-11-06 14:53:50,463] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:53:50,463] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:53:50,463] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 19
[2023-11-06 14:53:50,463] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 19
[2023-11-06 14:53:50,463] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 19
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 19, actual 20
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 20
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 20
[2023-11-06 14:53:59,848] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 20
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 20, actual 21
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 19, actual 21
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 21
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 21
[2023-11-06 14:54:08,549] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 21
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 21, actual 22
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 20, actual 22
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 19, actual 22
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 22
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 22
[2023-11-06 14:54:17,795] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 22
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 22, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 21, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 20, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 19, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 23
[2023-11-06 14:54:27,430] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 23
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function forward in /data/users/williamwen/torchvision/torchvision/models/resnet.py:284
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 23, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 22, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 21, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 20, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 19, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 18, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 17, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 16, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.convert_frame: [WARNING] torch._dynamo hit config.cache_size_limit (8)
[2023-11-06 14:54:36,744] torch._dynamo.convert_frame: [WARNING] function: 'forward' (/data/users/williamwen/torchvision/torchvision/models/resnet.py:284)
[2023-11-06 14:54:36,744] torch._dynamo.convert_frame: [WARNING] last reason: tensor 'L['x']' size mismatch at index 0. expected 16, actual 24
[2023-11-06 14:54:36,744] torch._dynamo.convert_frame: [WARNING] To log all recompilation reasons, use TORCH_LOGS="recompiles".
[2023-11-06 14:54:36,744] torch._dynamo.convert_frame: [WARNING] To diagnose recompilation issues, see https://pytorch.org/docs/master/compile/troubleshooting.html.
[2023-11-06 14:54:45,922] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:54:45,922] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:45,922] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 25
[2023-11-06 14:54:54,691] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:54:54,691] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:54:54,691] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 26
[2023-11-06 14:54:54,691] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 26
[2023-11-06 14:55:03,591] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:55:03,591] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:55:03,591] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 26, actual 27
[2023-11-06 14:55:03,591] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 27
[2023-11-06 14:55:03,591] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 27
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 27, actual 28
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 26, actual 28
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 28
[2023-11-06 14:55:12,384] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 28
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 28, actual 29
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 27, actual 29
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 26, actual 29
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 29
[2023-11-06 14:55:21,442] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 29
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 29, actual 30
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 28, actual 30
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 27, actual 30
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 26, actual 30
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 30
[2023-11-06 14:55:30,315] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 30
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] Recompiling function _forward_impl in /data/users/williamwen/torchvision/torchvision/models/resnet.py:266
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] triggered by the following guard failure(s):
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 30, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 29, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 28, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 27, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 26, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 25, actual 31
[2023-11-06 14:55:39,839] torch._dynamo.guards.__recompiles: [DEBUG] - tensor 'L['x']' size mismatch at index 0. expected 24, actual 31
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110325
Approved by: https://github.com/ezyang, https://github.com/jon-chuang
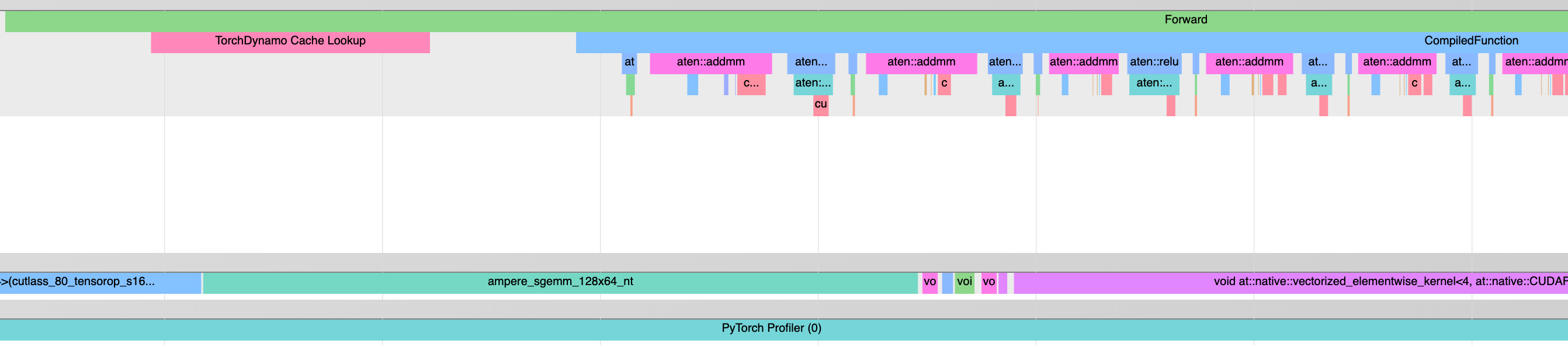
**Motivation**: We already have a `CompiledFunction` event that comes from the autograd.Function added by aot_autograd. However, this doesn't appear during inference, or if none of the inputs to a graph require grad. It also doesn't appear if your backend doesn't use aot_autograd.
This adds a profiler event that will always appear.
<img width="615" alt="Screenshot 2023-09-01 at 4 46 28 PM" src="https://github.com/pytorch/pytorch/assets/5067123/fed90ca9-a8e7-458c-80eb-b4160de55218">
Perf - increase in latency (with profiler turned off) was within noise when I measured a simple cpu-only torch-compiled function that returned `x.view_as(x)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108462
Approved by: https://github.com/anijain2305
**Background**: "TorchDynamo Cache Lookup" events appear in traces to indicate a dynamo cache lookup; it's useful to check when cache lookups are taking a long time. To add a profiler event, one can use the `torch.profiler.record_function` context manager, or the C++ equivalent. Previously, the python version was used; first, when the profiler was enabled, callbacks for record_function_enter and record_function_exit were registered; then those would be called before and after every cache lookup.
**This PR**: Instead of calling the python bindings for `torch.profiler.record_function`, directly call the C++ implementation. This simplifies a lot of the code for binding C/C++. It also improves performance; previously there was a lot of overhead in the "TorchDynamo Cache Lookup" event, making the event artificially take a long time. After this change the events now appear shorter, because there's less overhead in starting/stopping the event: in other words, the profiler no longer distorts the results as much.
**Performance results**:
I ran using the script below on a cpu-only 1.6GHz machine. I report the median time (from 100 measurements) of a "TorchDynamo Cache Lookup" event before and after this PR. I think it is reasonable to consider the difference to be due to a reduction in overhead.
<details>
<summary>Benchmarking script</summary>
```python
def fn(x, y):
return (x * y).relu()
a, b = [torch.rand((4, 4), requires_grad=True) for _ in range(2)]
opt_fn = torch.compile(fn)
opt_fn(a, b)
opt_fn(a, b)
with torch.profiler.profile() as prof:
opt_fn(a, b)
```
</details>
Median before PR: 198-228 us (median of 100, measured 5 times)
Median after PR: 27us
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108436
Approved by: https://github.com/anijain2305, https://github.com/jansel
In https://github.com/pytorch/pytorch/pull/106673 , I created a private API `_debug_get_cache_entry_list` to help pull out cache entries from compiled functions.
Recently, I find that @anijain2305 commented in the code that this API should be revisited, and so I created this PR.
First, this API cannot be removed even if cache entry becomes a first-class python class`torch._C._dynamo.eval_frame._CacheEntry`. The facts that `extra_index` is static, and `get_extra_state` is inline static, make them not accessible elsewhere. This API `_debug_get_cache_entry_list` is the only way for users to get all the cache entries from code.
Second, since the`torch._C._dynamo.eval_frame._CacheEntry` class is a python class, I simplified the C-part code, and remove the necessity of creating a namedtuple for this in the python code.
Third, I also add a small improvement, that if the argument is a function, we can automatically pass its `__code__` to the API.
The above change will slightly change the output, from list of named tuple to list of `torch._C._dynamo.eval_frame._CacheEntry`. I will update the corresponding docs that use this API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108335
Approved by: https://github.com/jansel, https://github.com/anijain2305
This PR makes CacheEntry a PyObject. This is prep PR for cache size changes. As CacheEntry is a py object, we can now traverse the linked list in Python and write cache size policies. It was possible to do in C, but Python is just easier to iterate upon. We call convert_frame only when we (re)compile, so a small bump in latency going from C to Python is acceptable here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107405
Approved by: https://github.com/ezyang
ghstack dependencies: #106917, #107117
Fixes https://github.com/pytorch/pytorch/issues/103210
Test Plan:
Before the fix:
```
pytest test/dynamo/test_export.py -k suppress_errors
```
got result:
```
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/eval_frame.py", line 295, in _fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/eval_frame.py", line 448, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 127, in _fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 360, in _convert_frame_assert
return _compile(
^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/utils.py", line 180, in time_wrapper
r = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 511, in _compile
exception_handler(e, code, frame)
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 216, in exception_handler
log.error(format_error_msg(e, code, record_filename, frame))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/exc.py", line 248, in format_error_msg
stack_above_dynamo = filter_stack(extract_stack(frame))
^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 231, in extract_stack
stack = StackSummary.extract(walk_stack(f), limit=limit)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 393, in extract
return klass._extract_from_extended_frame_gen(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 416, in _extract_from_extended_frame_gen
for f, (lineno, end_lineno, colno, end_colno) in frame_gen:
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 390, in extended_frame_gen
for f, lineno in frame_gen:
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 334, in walk_stack
yield f, f.f_lineno
^^^^^^^^^^
AttributeError: 'torch._C.dynamo.eval_frame._PyInterpreterFrame' object has no attribute 'f_lineno'
```
After the fix:
```
pytest test/dynamo/test_export.py -k suppress_errors -s
```
Got Result:
```
File "/data/users/zhxchen17/pytorch/torch/_dynamo/exc.py", line 135, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: map() operator doesn't support scalar or zero-sized tensors during
tracing.
========== The above exception occurred while processing the following code ==========
File "/data/users/zhxchen17/pytorch/test/dynamo/test_export.py", line 3043, in forward
def forward(self, xs):
File "/data/users/zhxchen17/pytorch/test/dynamo/test_export.py", line 3047, in forward
return map(body, xs)
==========
unimplemented [("map() operator doesn't support scalar or zero-sized tensors during tracing.", 1)]
.
=============================== 1 passed, 133 deselected in 4.60s ================================
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103227
Approved by: https://github.com/williamwen42
Failing mechanism on #95424 :
In dynamo mode, when passing numpy.int_ to 'shape' like param (Sequence[Union[int, symint]]) is wrapped as list with FakeTensor. However, in python_arg_parser, parser expect int in symint_list but got FakeTensor.
Following #85759, this PR allow tensor element in symint_list when in dynamo mode
This PR also fix below test with similar failing mechanism
pytest ./generated/test_huggingface_diffusers.py -k test_016
pytest ./generated/test_ustcml_RecStudio.py -k test_036
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97508
Approved by: https://github.com/yanboliang
Notes:
- No segfaults observed in any CI tests: dynamo unittests, inductor unittests, dynamo-wrapped pytorch tests. So we remove the warning that using dynamo 3.11 may result in segfaults.
- Some dynamo-wrapped pytorch tests hang. They will be skipped in the dynamo-wrapped test suite and will be addressed in a future PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99180
Approved by: https://github.com/malfet
Dynamo will frequently segfault when attempting to print stack traces. We fix this by:
- Fixing stack size calculations, as we did not account for exception tables
- Creating shadow execution frames in a way that more closely resembles what CPython does to create its execution frames
Dynamo/inductor-wrapped pytorch tests are enabled up the stack - those need to be green before this PR can be merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99934
Approved by: https://github.com/albanD, https://github.com/malfet, https://github.com/jansel
This fixes a few reference counting bugs in eval_frame.c, simplifies a few functions a bit, and adds a few missing error handling code paths. Probably the only important reference counting bug is that `call_callback` previously leaked `THPPyInterpreterFrame` in Python 3.11+.
Summary below:
- eval_frame_callback_get shouldn't incref Py_None
- Don't leak THPPyInterpreterFrame in Python 3.11+
- set_profiler_hooks would decref profiler_start_hook and profiler_end_hook too many times if called with None as an argument (but we never actually used that code path).
- Simplify some argument parsing
- Only create guard_profiler_name_str once
- Add a few missing error checks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100496
Approved by: https://github.com/albanD
Planning to do a full writeup later. The short story is, sometimes the following chain of events happens:
1. We turn on Dynamo's custom frame handler
2. GC triggers (and all of the finalizers run under Dynamo)
3. GC hits a GeneratorExit frame
4. You end up in the custom frame handler with throw_flag == TRUE and PyErr_Occurred() != NULL
If this happens and we blindly call into other Python functions (like the Python callback), the executed Python code will immediately raise an exception (because there's already an ambient exception set.) This is very, very confusing. The fix is to defer to the regular handler when throw_flag is TRUE.
I triggered this locally with
```
PYTHONUNBUFFERED=1 pytest test/dynamo/test_dynamic_shapes.py -k 'Unspec and export and not dupes and not reorder' -v -x -s
```
But I also have some tests which trigger the problem synthetically.
Fixes https://github.com/pytorch/pytorch/issues/93781
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96488
Approved by: https://github.com/albanD
Adds a profiler start and end callback to dynamo's C eval_frame impl, which can be used to profile a region providing a name for visualization. Currently only hooks up one usage to profile cache lookup (primarily covering guards and linear search through linked list).
Example profile taken from toy model:
`python benchmarks/dynamo/distributed.py --toy_model --profile --dynamo aot_eager`
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/4984825/223225931-b2f6c5a7-505a-4c90-9a03-34982f6dc033.png">
Planning to measure overhead in CI, and probably can't afford to check this in enabled by default. Will have to evaluate UX options such as `config.profile_dynamo_cache = True` or some other way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96119
Approved by: https://github.com/jansel
Previously we would abort() but this is annoying when you're running
pytest or something. Don't hard crash.
It would be nice to apply this treatment to the other uses of CHECK
macro in this file, but it was just guards that was bothering me.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91053
Approved by: https://github.com/jansel
Modify the lookup procedure for TorchDynamo caches to keep the head of the single linked list as the most recently used cache entry, which may potentially improve probability for cache hitting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88076
Approved by: https://github.com/jansel
{kind=link}