Summary:
Adds NNC-like logging that is configured through an env var `TORCH_COMPILE_LOGS`
Examples:
`TORCH_LOGS="dynamo,guards" python script.py` - prints dynamo logs at level INFO with guards of all functions that are compiled
`TORCH_LOGS="+dynamo,guards,graph" python script.py` - prints dynamo logs at level DEBUG with guards and graphs (in tabular) format of all graphs that are compiled
[More examples with full output](https://gist.github.com/mlazos/b17f474457308ce15e88c91721ac1cce)
Implementation:
The implementation parses the log settings from the environment, finds any components (aot, dynamo, inductor) or other loggable objects (guards, graph, etc.) and generates a log_state object. This object contains all of the enabled artifacts, and a qualified log name -> level mapping. _init_logs then adds handlers to the highest level logs (the registered logs), and sets any artifact loggers to level DEBUG if the artifact is enabled.
Note: set_logs is an alternative for manipulating the log_state, but if the environment contains TORCH_LOGS, the environment settings will be prioritized.
Adding a new log:
To add a new log, a dev should add their log name to torch._logging._registrations (there are examples there already).
Adding a new artifact:
To add a new artifact, a dev should add their artifact name to torch._logging._registrations as well.
Additionally, wherever the artifact is logged, `torch._logging.getArtifactLogger(__name__, <artifact_name>)` should be used instead of the standard logging implementation.
[design doc](https://docs.google.com/document/d/1ZRfTWKa8eaPq1AxaiHrq4ASTPouzzlPiuquSBEJYwS8/edit#)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94858
Approved by: https://github.com/ezyang
Summary: Makes the debug dir location configurable with TORCH_COMPILE_DEBUG_DIR env var
Test Plan: TORCH_COMPILE_DEBUG_DIR=”.” buck2 run mode/dev-nosan //caffe2/test/inductor:minifier_smoke
Reviewed By: bertmaher
Differential Revision: D43639955
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96089
Approved by: https://github.com/bertmaher
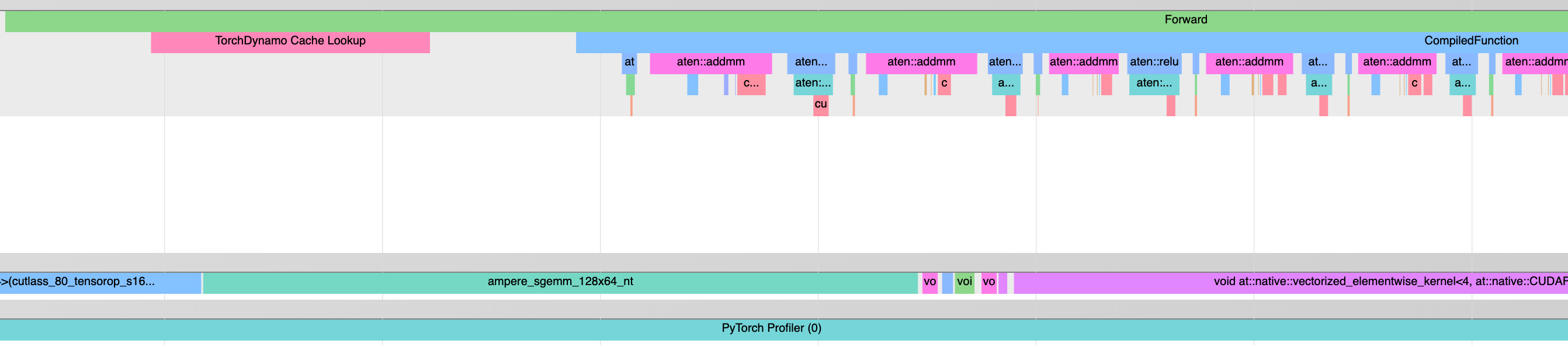
Adds a profiler start and end callback to dynamo's C eval_frame impl, which can be used to profile a region providing a name for visualization. Currently only hooks up one usage to profile cache lookup (primarily covering guards and linear search through linked list).
Example profile taken from toy model:
`python benchmarks/dynamo/distributed.py --toy_model --profile --dynamo aot_eager`
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/4984825/223225931-b2f6c5a7-505a-4c90-9a03-34982f6dc033.png">
Planning to measure overhead in CI, and probably can't afford to check this in enabled by default. Will have to evaluate UX options such as `config.profile_dynamo_cache = True` or some other way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96119
Approved by: https://github.com/jansel
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
This takes the strategy described in https://docs.google.com/document/d/1lFRYAJo5nrfxRhwIzGnfi2pbLpU6T4ytSRSuLJ5qebI/edit#
It is essentially https://github.com/pytorch/pytorch/pull/95222 but squashed and with changes that are unnecessary given that we assume nonzero returns > 1.
What's in the PR:
* nonzero now supports meta propagation. When `capture_dynamic_output_shape_ops`, it will return a tensor with an unbacked SymInt representing the size in question.
* The unbacked SymInt is UNSOUNDLY assumed to be not equal to 0/1. We will still error if you guard otherwise.
* PrimTorch pointwise operators are updated to use empty_permuted, to avoid guarding on unbacked SymInt from empty_strided (tested in `test_dynamic_pointwise_scalar`)
* Convolution is updated to skip backend selection if batch is unbacked, to avoid guarding on unbacked SymInt (tested in `test_unbacked_batch_resnet`)
* I kept the helper utilities like `definitely_true` for working with possibly unbacked SymInts. They're not used right now but maybe someone will find them useful.
* Added `constrain_unify` to let you specify two unbacked SymInts must have the same value
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95387
Approved by: https://github.com/voznesenskym
Summary:
There are a few races/permission errors in file creation, fixing
OSS:
1. caffe2/torch/_dynamo/utils.py, get_debug_dir: multiple process may conflict on it even it's using us. Adding pid to it
2. caffe2/torch/_dynamo/config.py: may not be a right assumption that we have permission to cwd
Test Plan: sandcastle
Differential Revision: D42905908
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93407
Approved by: https://github.com/soumith, https://github.com/mlazos
Previously, Dynamo faked support for item() when `capture_scalar_outputs` was True by representing it internally as a Tensor. With dynamic shapes, this is no longer necessary; we can represent it directly as a SymInt/SymFloat. Do so. Doing this requires you to use dynamic shapes; in principle we could support scalar outputs WITHOUT dynamic shapes but I won't do this unless someone hollers for it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Differential Revision: [D42885775](https://our.internmc.facebook.com/intern/diff/D42885775)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93150
Approved by: https://github.com/voznesenskym
@mlazos: skips `item()` calls if compiling with dynamo, by defining a helper function `_get_value` which either returns the result of `.item()` or the scalar cpu tensor if compiling with dynamo. This was done because removing `item()` calls significantly regresses eager perf. Additionally, `_dispatch_sqrt` calls the appropriate sqrt function (math.sqrt, or torch.sqrt).
Fixes https://github.com/pytorch/torchdynamo/issues/1083
This PR will no longer be needed once symint support is default.
This PR closes all remaining graph breaks in the optimizers (!!)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88173
Approved by: https://github.com/albanD
- Adds `log_level` to aot's config
- Outputs log to `<graph_name>_<log_level>.log` in aot_torchinductor subfolder of the debug directory
- Modifies the Inductor debug context to use the graph name when naming the folder instead of the os pid
- Adds `TORCH_COMPILE_DEBUG` flag to enable it, (as well as separate dynamo and inductor logs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88987
Approved by: https://github.com/Chillee
The old code didn't actually fakeify traceable tensor subclasses at the
time they are added as a GraphArg to the module; now we do, by ignoring
the subclass during fakeification and relying on Dynamo to simulate
the subclass on top. See comments for more details.
BTW, this codepath is super broken, see filed issues linked on the
inside.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90009
Approved by: https://github.com/wconstab, https://github.com/voznesenskym
Performance benchmarks on 6 popular models from 1-64 GPUs compiled with
torchinductor show performance gains or parity with eager, and showed
regressions without DDPOptimizer. *Note: resnet50 with small batch size shows a regression with optimizer, in part due to failing to compile one subgraph due to input mutation, which will be fixed.
(hf_Bert, hf_T5_large, hf_T5, hf_GPT2_large, timm_vision_transformer, resnet50)
Correctness checks are implemented in CI (test_dynamo_distributed.py),
via single-gpu benchmark scripts iterating over many models
(benchmarks/dynamo/torchbench.py/timm_models.py/huggingface.py),
and via (multi-gpu benchmark scripts in torchbench)[https://github.com/pytorch/benchmark/tree/main/userbenchmark/ddp_experiments].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88523
Approved by: https://github.com/davidberard98
I noticed that a lot of bugs are being suppressed by torchdynamo's default
error suppression, and worse yet, there's no way to unsuppress them. After
discussion with voz and soumith, we decided that we will unify error suppression
into a single option (suppress_errors) and default suppression to False.
If your model used to work and no longer works, try TORCHDYNAMO_SUPPRESS_ERRORS=1
to bring back the old suppression behavior.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87440
Approved by: https://github.com/voznesenskym, https://github.com/albanD
{kind=link}