1. If user uses amp to run bfloat16 models, `torch.autocast` will
keep module paramters in acc dtype which will leave `gamma` and`beta`
in float while input/output will be in bfloat16.
2. If user explicitly cast the model to bfloat16 such as:
```
x = torch.randn(n, t, c).bfloat16()
ln = nn.LayerNorm(c).bfloat16()
y = ln(x)
```
The input/output and gamma/beta will all be in bfloat16.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81851
Approved by: https://github.com/ezyang
Fixes empty input convolution issue : when input is empty e.g. shape of (0, 3, 3, 4) and weight is channels last format, at::_unsafe_view will raise "view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86521
Approved by: https://github.com/jgong5, https://github.com/malfet
Fixes T135842750 (follow-up for #87377)
## Description
At present, having both `src_key_padding_mask` and `src_mask` at the same time is not supported on the fastpath in Transformer and Multi-Head Attention.
This PR enables using both masks on the fastpath on CPU and GPU: if both masks are passed, we merge them into a 4D mask in Python and change mask type to 2 before passing downstream.
Downstream processing in native code is not changed, as it already supports 4D mask. Indeed, it is done depending on the device:
- on CUDA, by `SoftMax.cu::masked_softmax_cuda`. When mask type is 2, it calls either `dispatch_softmax_forward` -> `softmax_warp_forward` or `at::softmax` (depending on the input size). In both cases 4D mask is supported.
- on CPU, by `SoftMax.cpp::masked_softmax_cpp`. It calls `hosted_softmax` which supports 4D mask.
## Tests
- Extended `test_mask_check_fastpath` to check that fast path is indeed taken in Transformer when two masks are passed
- Added `test_multihead_self_attn_two_masks_fast_path_mock` to check that fast path is taken in MHA when two masks are passed
- Added `test_multihead_self_attn_two_masks_fast_path` to check that fast and slow paths give the same result when two masks are passed in MHA
- `test_masked_softmax_mask_types` now covers mask type 2
- `test_transformerencoderlayer_fast_path` (CPU smoke test) is expanded to the case of both masks provided simultaneously
- `test_masked_softmax_devices_parity` checks that mask type 2 is accepted by CPU and CUDA paths
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88488
Approved by: https://github.com/mikekgfb
## Issues
Fixes https://github.com/pytorch/pytorch/issues/81129#issuecomment-1179435674
## Description
Passing a 2D attention mask `src_mask` into the fast path of `TransformerEncoderLayer` in CPU was causing an error and so was disabled in https://github.com/pytorch/pytorch/pull/81277. This PR unrolls this fix, enabling `src_mask` on the fast path:
- Either attention mask `src_mask` of shape `(L, L)` or padding mask `src_key_padding_mask` of shape `(B, L)` are now allowed on the CPU fast path. If softmax is applied along the last dimension (as in multi-head attention), these masks are processed without expanding them to 4D. Instead, when iterating through the input, `Softmax.cpp::host_softmax` converts the index to match the mask dimensions, depending on the type.
- If softmax is applied along the dimension other than the last, `Softmax.cpp::masked_softmax_cpu` expands masks to 4D, converting them to `mask_type=2`. Theoretically one could also add special optimized cases for `dim=0, 1, 2` and process them without mask expansion, but I don't know how often is that used
## Tests:
- `test_transformerencoderlayer_fast_path` is extended to cover both attention mask and padding mask
- `test_masked_softmax_mask_types_0_1` is added to ensure results from CPU softmax with attention and padding masks match the explicit slow calculation
- `test_masked_softmax_devices_parity` is added to ensure results from masked softmax on CPU and CUDA match
## Note
I had to replace `float` with `torch.get_default_dtype()` in a couple of tests for the following reason:
- `test_nn.py` [sets the default type to `torch.double`](https://github.com/pytorch/pytorch/blob/master/test/test_nn.py#L24-L26)
- If I execute `test_nn.py` and `test_transformers.py` in one `pytest` run, this default still holds for transformer tests
- Some tests in `test_transformers.py` which were previously following the slow path now switched to fast path, and hard-coded `float` started clashing with default `double`
Let me know if there is a better way around it - or maybe I'm not supposed to run tests with `pytest` like this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87377
Approved by: https://github.com/mikekgfb, https://github.com/weiwangmeta, https://github.com/malfet
There is a bug in the implementation of the registration hooks introduced in https://github.com/pytorch/pytorch/pull/86148 whereby if the hook returns a tensor, then the short circuiting logic:
```
value = hook(self, name, value) or value
```
Raises an exception
```
RuntimeError: Boolean value of Tensor with more than one value is ambiguous
```
Fixing the logic so that it only checks to see if the value is `None` before overriding
Fixes#85837
CC: @albanD @jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87369
Approved by: https://github.com/albanD
The model TTS will crash due to the issue:: when input of BN is not contiguous and the data type of input is different with that of parameters, BN will raise error `RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERNAL ASSERT FAILED at "xxx/pytorch/aten/src/ATen/native/cpu/Loops.h":311, please report a bug to PyTorch`.
Make the data types of output and input consistenst for batchnorm to fix the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84410
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/malfet
As described in the issue, this PR adds hooks to be run when `register_parameter`, `register_buffer` and `register_module` are called.
Fixes#85837
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86148
Approved by: https://github.com/albanD
Fixes#61398
The original implementation is very slow when the state_dict.keys() is long. This PR only passes relevant keys to the child module.
existing test passes: `pytest test/test_nn.py -k state_dict`
I couldn't figure out a good way to write a new test for this new behavior. Had a new snippet, but it will be flaky if integrated into the main CI because it's a timing based check.
But I can verify that the test took 30s to run, after this PR it only takes 0.5s.
```python
def test_load_state_dict_large(self):
# construct a module with 4 levels of module, 10 linear each, leads to 10k items in the dictionary
import copy
import time
base_module = nn.Linear(1,1)
model = base_module
for level in range(4):
model = nn.Sequential(*[copy.deepcopy(model) for _ in range(10)])
state_dict = model.state_dict()
self.assertEqual(len(state_dict), 20000)
st = time.time()
model.load_state_dict(state_dict, strict=True)
strict_load_time = time.time() - st
# it took 0.5 seconds to
self.assertLess(strict_load_time, 10)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85743
Approved by: https://github.com/albanD
Also Back out "Revert D39075159: [acc_tensor] Use SymIntArrayRef for overloaded empty.memory_format's signature"
Original commit changeset: dab4a9dba4fa
Original commit changeset: dcaf16c037a9
Original Phabricator Diff: D38984222
Original Phabricator Diff: D39075159
Also update Metal registrations for C++ registration changes.
Also update NNPI registration to account for tightened schema checking
Differential Revision: [D39084762](https://our.internmc.facebook.com/intern/diff/D39084762/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39084762/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84173
Approved by: https://github.com/Krovatkin
Fixes https://github.com/pytorch/pytorch/issues/83505
BC-breaking message:
- Previously we only required input and weight to have the same dtype on cpu (when input is non-complex). After this change, the dtype of bias is now also expected to have the same dtype. This change was necessary to improve the error message for certain combinations of inputs. This behavior now also matches that of convolution on cuda.
<details>
<summary>
Old plan
</summary>
Previously convolution (at least for slow_conv2d) did not perform type promotion, i.e. the output of `conv(int, int, float)` is an int, and that leads to the autograd assert.
This PR adds type promotion handling at the `at::native::conv2d` (this is a composite) level. We also need to correct or remove many tests that assume that conv errors when input types are mixed
Pros:
- Doing type promotion at this level avoids the complex path from having any special handling for mixed dtypes, and can potentially speed up mixed dtype inputs to now dispatch to faster kernels which are only capable of handling floats.
Cons:
- Doing type promotion at this level has the risk of introducing extra overhead when we would've dispatched to a kernel capable of handle mixed type anyway. I don't know if any of these exist at all though - it is possible that inputs with any non-float arguments are dispatched to the slow path.
If this approach is OK, we can proceed with the other convolutions as well:
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83686
Approved by: https://github.com/ngimel
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81947
Transformer fastpath multiplexes two arguments, src_mask [seq_len x seq_len] and src_key_padding_mask [batch_size x seq_len], and later deduces the type based on mask shape.
In the event that batch_size == seq_len, any src_mask is wrongly interpreted as a src_key padding_mask. This is fixed by requiring a mask_type identifier be supplied whenever batch_size == seq_len.
Additionally, added support for src_mask in masked_softmax CPU path.
Test Plan: existing unit tests + new unit tests (batch_size == seq_len)
Differential Revision: D37932240
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81947
Approved by: https://github.com/zrphercule
To fix https://github.com/pytorch/pytorch/issues/82060
When `input` is not explicitly converted to channels last while `conv` has, the output should also be in channels last. The root cause is that when input has IC of 1, `compute_columns2d` from `\aten\src\ATen\native\ConvolutionMM2d.cpp` would consider it as channels first:
We do have logic to make sure both input and weight have the same memory format even if they are given differently, like:
```
auto input = self.contiguous(memory_format);
auto weight = weight_.contiguous(memory_format);
```
But for a N1HW input, `.contiguous(MemoryFormat::ChannelsLast)` would not change its stride , and its `suggest_memory_format()` still returns `MemoryFormat::Contiguous`. That's how it went wrong.
Also updated the corresponding test cases, without this patch, the new test case would fail on forward path and runtime error on backward path.
attach old fail log on forward path:
```
FAIL: test_conv_thnn_nhwc_cpu_float32 (__main__.TestNNDeviceTypeCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_device_type.py", line 377, in instantiated_test
result = test(self, **param_kwargs)
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_device_type.py", line 974, in only_fn
return fn(slf, *args, **kwargs)
File "test/test_nn.py", line 19487, in test_conv_thnn_nhwc
input_format=torch.contiguous_format, weight_format=torch.channels_last)
File "test/test_nn.py", line 19469, in helper
self.assertEqual(out, ref_out, exact_dtype=False)
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_utils.py", line 2376, in assertEqual
msg=(lambda generated_msg: f"{generated_msg} : {msg}") if isinstance(msg, str) and self.longMessage else msg,
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Tensor-likes are not close!
Mismatched elements: 988 / 1024 (96.5%)
Greatest absolute difference: 42.0 at index (1, 2, 6, 6) (up to 1e-05 allowed)
Greatest relative difference: inf at index (0, 0, 2, 1) (up to 1.3e-06 allowed)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82392
Approved by: https://github.com/jbschlosser
Context: For a while slow gradcheck CI was skipping nearly all tests and this hid the fact that it should've been failing and timing out (10+h runtime for TestGradients). The CI configuration has since been fixed to correct this, revealing the test failures. This PR reenables slow gradcheck CI and makes it pass again.
This PR:
- makes slow and failing tests run in fast gradcheck mode only
- reduce the input size for slow gradcheck only for unary/binary ufuncs (alternatively, skip the test entirely)
- skip entire test files on slow gradcheck runner if they don't use gradcheck (test_ops, test_meta, test_decomp, test_ops_jit)
- reduces the input size for some ops
Follow ups:
1. Investigate slow mode failures https://github.com/pytorch/pytorch/issues/80411
2. See if we can re-enable slow gradcheck tests for some of the slow tests by reducing the sizes of their inputs
The following are failing in slow mode, they are now running in fast mode only.
```
test_fn_fwgrad_bwgrad___rmod___cuda_float64
test_fn_fwgrad_bwgrad_linalg_householder_product_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_float64
test_fn_fwgrad_bwgrad_linalg_matrix_power_cuda_complex128
test_fn_fwgrad_bwgrad_cat_cuda_complex128
test_fn_fwgrad_bwgrad_linalg_lu_factor_ex_cuda_float64
test_fn_fwgrad_bwgrad_copysign_cuda_float64
test_fn_fwgrad_bwgrad_cholesky_inverse_cuda_complex128
test_fn_fwgrad_bwgrad_float_power_cuda_complex128
test_fn_fwgrad_bwgrad_fmod_cuda_float64
test_fn_fwgrad_bwgrad_float_power_cuda_float64
test_fn_fwgrad_bwgrad_linalg_lu_cuda_float64
test_fn_fwgrad_bwgrad_remainder_cuda_float64
test_fn_fwgrad_bwgrad_repeat_cuda_complex128
test_fn_fwgrad_bwgrad_prod_cuda_complex128
test_fn_fwgrad_bwgrad_slice_scatter_cuda_float64
test_fn_fwgrad_bwgrad_tile_cuda_complex128
test_fn_fwgrad_bwgrad_pow_cuda_float64
test_fn_fwgrad_bwgrad_pow_cuda_complex128
test_fn_fwgrad_bwgrad_fft_*
test_fn_fwgrad_bwgrad_zero__cuda_complex128
test_fn_gradgrad_linalg_lu_factor_cuda_float64
test_fn_grad_div_trunc_rounding_cuda_float64
test_fn_grad_div_floor_rounding_cuda_float64
```
Marks the OpInfos for the following ops that run slowly in slow gradcheck as `fast_gradcheck` only (the left column represents runtime in seconds):
```
0 918.722 test_fn_fwgrad_bwgrad_nn_functional_conv_transpose3d_cuda_float64
1 795.042 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_complex128
2 583.63 test_fn_fwgrad_bwgrad_nn_functional_max_pool3d_cuda_float64
3 516.946 test_fn_fwgrad_bwgrad_svd_cuda_complex128
4 503.179 test_fn_fwgrad_bwgrad_linalg_svd_cuda_complex128
5 460.985 test_fn_fwgrad_bwgrad_linalg_lu_cuda_complex128
6 401.04 test_fn_fwgrad_bwgrad_linalg_lstsq_grad_oriented_cuda_complex128
7 353.671 test_fn_fwgrad_bwgrad_nn_functional_max_pool2d_cuda_float64
8 321.903 test_fn_fwgrad_bwgrad_nn_functional_gaussian_nll_loss_cuda_float64
9 307.951 test_fn_fwgrad_bwgrad_stft_cuda_complex128
10 266.104 test_fn_fwgrad_bwgrad_svd_lowrank_cuda_float64
11 221.032 test_fn_fwgrad_bwgrad_istft_cuda_complex128
12 183.741 test_fn_fwgrad_bwgrad_lu_unpack_cuda_complex128
13 132.019 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_float64
14 125.343 test_fn_fwgrad_bwgrad_nn_functional_pad_constant_cuda_complex128
15 124.2 test_fn_fwgrad_bwgrad_kron_cuda_complex128
16 123.721 test_fn_fwgrad_bwgrad_pca_lowrank_cuda_float64
17 121.074 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
18 119.387 test_fn_fwgrad_bwgrad_rot90_cuda_complex128
19 112.889 test_fn_fwgrad_bwgrad__masked_normalize_cuda_complex128
20 107.541 test_fn_fwgrad_bwgrad_dist_cuda_complex128
21 106.727 test_fn_fwgrad_bwgrad_diff_cuda_complex128
22 104.588 test_fn_fwgrad_bwgrad__masked_cumprod_cuda_complex128
23 100.135 test_fn_fwgrad_bwgrad_nn_functional_feature_alpha_dropout_with_train_cuda_float64
24 88.359 test_fn_fwgrad_bwgrad_mH_cuda_complex128
25 86.214 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
26 83.037 test_fn_fwgrad_bwgrad_nn_functional_bilinear_cuda_float64
27 79.987 test_fn_fwgrad_bwgrad__masked_cumsum_cuda_complex128
28 77.822 test_fn_fwgrad_bwgrad_diag_embed_cuda_complex128
29 76.256 test_fn_fwgrad_bwgrad_mT_cuda_complex128
30 74.039 test_fn_fwgrad_bwgrad_linalg_lu_solve_cuda_complex128
```
```
0 334.142 test_fn_fwgrad_bwgrad_unfold_cuda_complex128
1 312.791 test_fn_fwgrad_bwgrad_linalg_lu_factor_cuda_complex128
2 121.963 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
3 108.085 test_fn_fwgrad_bwgrad_diff_cuda_complex128
4 89.418 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
5 72.231 test_fn_fwgrad_bwgrad___rdiv___cuda_complex128
6 69.433 test_fn_fwgrad_bwgrad___getitem___cuda_complex128
7 68.582 test_fn_fwgrad_bwgrad_ldexp_cuda_complex128
8 68.572 test_fn_fwgrad_bwgrad_linalg_pinv_cuda_complex128
9 67.585 test_fn_fwgrad_bwgrad_nn_functional_glu_cuda_float64
10 66.567 test_fn_fwgrad_bwgrad_lu_cuda_float64
```
```
0 630.13 test_fn_gradgrad_nn_functional_conv2d_cuda_complex128
1 81.086 test_fn_gradgrad_linalg_solve_triangular_cuda_complex128
2 71.332 test_fn_gradgrad_norm_cuda_complex128
3 64.308 test_fn_gradgrad__masked_std_cuda_complex128
4 59.519 test_fn_gradgrad_div_no_rounding_mode_cuda_complex128
5 58.836 test_fn_gradgrad_nn_functional_adaptive_avg_pool3
```
Reduces the sizes of the inputs for:
- diff
- diag_embed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80514
Approved by: https://github.com/albanD
`torch.nn.grad` has its own implementations of gradients for conv1d, conv2d, and conv3d. This PR simplifies them by calling into the unified `aten::convolution_backward` backend instead.
The existing implementation of conv2d_weight is incorrect for some inputs (see issue #51430). This PR fixes the issue.
This PR expands coverage in test_nn to include conv1d_weight, conv2d_weight, and conv3d_weight, which were previously untested. It also expands the cases for conv2d to cover issue #51430.
Fixes#51430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81839
Approved by: https://github.com/albanD
Summary: We dont have a small fast path passing test for mha before, this diff added one for better testing
Test Plan: buck build mode/dev-nosan -c fbcode.platform=platform009 -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/dev/gen/caffe2/test/nn\#binary.par -r test_multihead_attn_fast_path_small_test
Differential Revision: D37834319
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81432
Approved by: https://github.com/erichan1
Fixes#69413
After applying parametrization to any `nn.Module` we lose the ability to create a deepcopy of it e.g. it makes it impossible to wrap a module by an `AveragedModel`.
Specifically, the problem is that the `deepcopy` tries to invoke `__getstate__` if object hasn't implemented its own `__deepcopy__` magic method. But we don't allow serialization of the parametrized modules: `__getstate__` raises an error.
My solution is just to create a default `__deepcopy__` method when it doesn't exist yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80811
Approved by: https://github.com/pearu, https://github.com/albanD
`test_conv_transposed_large` expects bitwise perfect results in fp16 on CUDA, but this behavior isn't guaranteed by cuDNN (e.g., in the case of FFT algos).
This PR just changes the tolerance on the test to account for these cases.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78147
Approved by: https://github.com/ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78298
Also back out "improve LayerNorm bfloat16 performance on CPU".
These layer norm changes seem fine, but they are causing `LayerNorm` to not use AVX2 instructions, which is causing performance on internal models to degrade. More investigation is needed to find the true root cause, but we should unland to mitigate the issue ASAP.
I left `mixed_data_type.h` around since there are some other files depending on it.
Differential Revision: [D36675352](https://our.internmc.facebook.com/intern/diff/D36675352/)
Approved by: https://github.com/tenpercent
Fixes#68172. Generally, this corrects multiple flaky convolution unit test behavior seen on ROCm.
The MIOpen integration has been forcing benchmark=True when calling `torch._C._set_cudnn_benchmark(False)`, typically called by `torch.backends.cudnn.set_flags(enabled=True, benchmark=False)`. We now add support for MIOpen immediate mode to avoid benchmarking during MIOpen solution selection.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77438
Approved by: https://github.com/ngimel, https://github.com/malfet
Double-header bug fix:
- As reported by jansel, dtypes are still showing up as integers
when the schema is an optional dtype. This is simple enough to
fix and I added a test for it. But while I was at it...
- I noticed that the THPMemoryFormat_new idiom with "unused" name
doesn't actually work, the repr of the returned memory format
object is wrong and this shows up when we try to log the args/kwargs.
So I fixed memory format to do it properly along with everything
else.
Fixes https://github.com/pytorch/pytorch/issues/77135
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77543
Approved by: https://github.com/albanD, https://github.com/jansel
Summary: For user to convert nested tensor more easily. Some impl detail might change on user's need.
Test Plan: buck test mode/dev caffe2/test:nn -- test_nested_tensor_from_mask
Differential Revision: D36191182
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76942
Approved by: https://github.com/jbschlosser
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76333
The current PyTorch multi-head attention and transformer
implementations are slow. This should speed them up for inference.
ghstack-source-id: 154737857
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: cpuhrsch
Differential Revision: D35239925
fbshipit-source-id: 5a7eb8ff79bc6afb4b7d45075ddb2a24a6e2df28
**Previous behavior**: compute inner product, then normalize.
**This patch**: first normalize, then compute inner product. This should be more numerically stable because it avoids losing precision in inner product for inputs with large norms.
By design ensures that cosine similarity is within `[-1.0, +1.0]`, so it should fix [#29442](https://github.com/pytorch/pytorch/issues/29442).
P.S. I had to change tests because this implementation handles division by 0 differently.
This PR computes cosine similarity as follows: <x/max(eps, ||x||), y/max(eps, ||y||)>.
Let f(x,y) = <x,y>/(||x|| * ||y||), then
df/dx = y/(||x|| * ||y||) - (||y||/||x|| * <x,y> * x)/(||x|| * ||y||)^2.
The changed test checks division by zero in backward when x=0 and y != 0.
For this case the non-zero part of the gradient is just y / (||x|| * ||y||).
The previous test evaluates y/(||x|| * ||y||) to y / eps, and this PR to 1/eps * y/||y||.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31378
Approved by: https://github.com/ezyang, https://github.com/albanD
Summary:
In this PR, we try to optimize PReLU op in CPU path, and enable BFloat16 support based on the optimized PReLU.
The original implementation uses parallel_for to accelerate operation speed, but vectorization is not used. It can be optimized by using TensorIterator, both including parallelization and vectorization.
The difference between PReLU and other activation function ops, is that PReLU supports a learnable parameter `weight`. When called without arguments, nn.PReLU() uses a single parameter `weight` across all input channels. If called with nn.PReLU(nChannels), a separate `weight` is used for each input channel. So we cannot simply use TensorIterator because `weight` is different for each input channel.
In order to use TensorIterator, `weight` should be broadcasted to `input` shape. And with vectorization and parallel_for, this implementation is much faster than the original one. Another advantage is, don't need to separate `share weights` and `multiple weights` in implementation.
We test the performance between the PReLU implementation of public Pytorch and the optimized PReLU in this PR, including fp32/bf16, forward/backward, share weights/multiple weights configurations. bf16 in public Pytorch directly reuses `Vectorized<scalar_t>` for `BFloat16`.
Share weights:
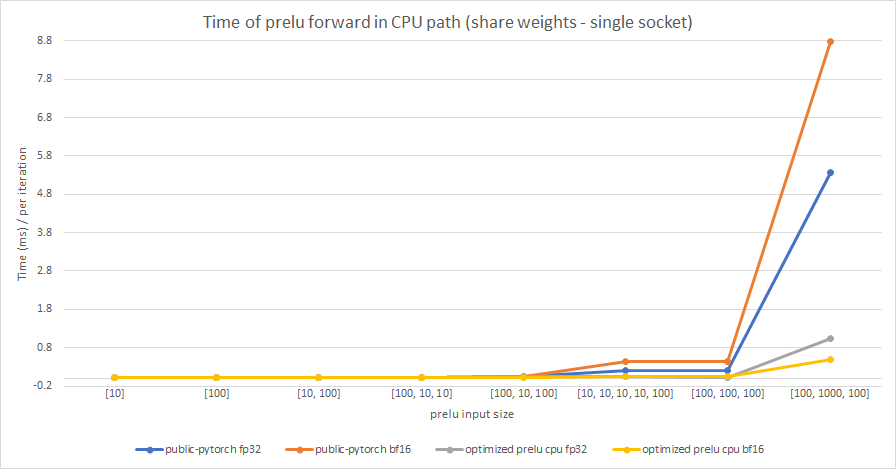
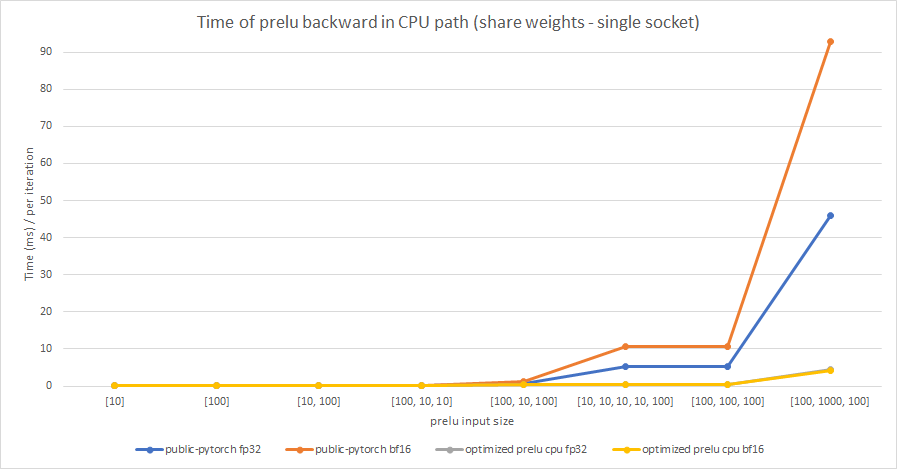
Multiple weights:
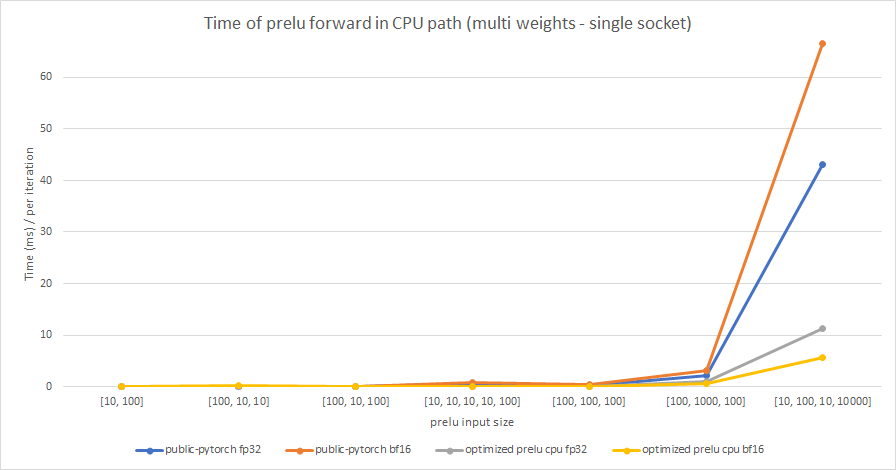
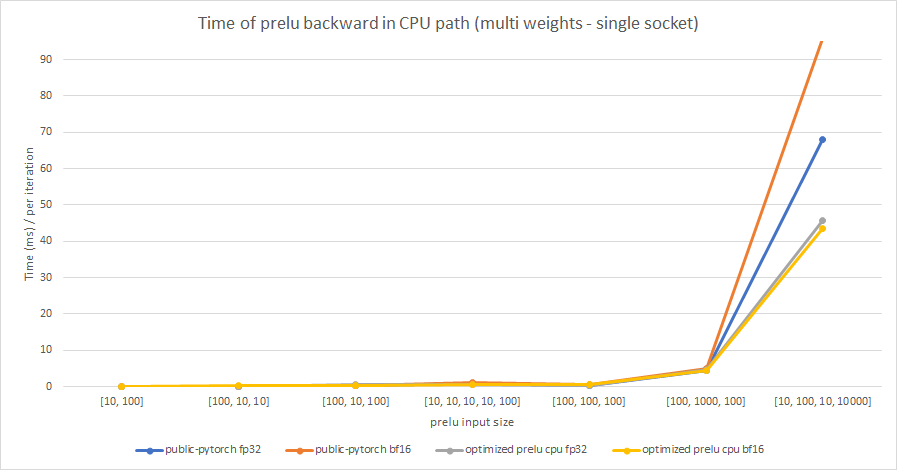
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63634
Reviewed By: yinghai
Differential Revision: D34031616
Pulled By: frank-wei
fbshipit-source-id: 04e2a0f9e92c658fba7ff56b1010eacb7e8ab44c
(cherry picked from commit ed262b15487557720bb0d498f9f2e8fcdba772d9)
{kind=link}
{kind=link}
{kind=link}
{kind=link}