Add non-package python modules to the public API checks.
The original change is to remove the `ispkg` check in this line
https://github.com/pytorch/pytorch/blob/main/docs/source/conf.py#L518
Everything else is to add the appropriate modules to the rst files, make sure every module we provide can be imported (fixed by either making optional dependencies optional or just deleting files that have been un-importable for 3 years), make API that are both modules and functions (like torch.autograd.gradcheck) properly rendered on the docs website without confusion and add every non-documented API to the allow list (~3k of them).
Next steps will be to try and fix these missing docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110568
Approved by: https://github.com/zou3519
This reworks the DORT backend factory function to support the options kwarg of torch.compile, and defines a concrete OrtBackendOptions type that can be used to influence the backend.
Caching is also implemented in order to reuse backends with equal options.
Wrapping the backend in auto_autograd also becomes an option, which allows `OrtBackend` to always be returned as the callable for torch.compile; wrapping happens internally if opted into (True by default).
Lastly, expose options for configuring preferred execution providers (will be attempted first), whether or not to attempt to infer an ORT EP from a torch found device in the graph or inputs, and finally the default/fallback EPs.
### Demo
The following demo runs `Gelu` through `torch.compile(backend="onnxrt")` using various backend options through a dictionary form and a strongly typed form. It additionally exports the model through both the ONNX TorchScript exporter and the new TorchDynamo exporter.
```python
import math
import onnx.inliner
import onnxruntime
import torch
import torch.onnx
torch.manual_seed(0)
class Gelu(torch.nn.Module):
def forward(self, x):
return x * (0.5 * torch.erf(math.sqrt(0.5) * x) + 1.0)
@torch.compile(
backend="onnxrt",
options={
"preferred_execution_providers": [
"NotARealEP",
"CPUExecutionProvider",
],
"export_options": torch.onnx.ExportOptions(dynamic_shapes=True),
},
)
def dort_gelu(x):
return Gelu()(x)
ort_session_options = onnxruntime.SessionOptions()
ort_session_options.log_severity_level = 0
dort_gelu2 = torch.compile(
Gelu(),
backend="onnxrt",
options=torch.onnx._OrtBackendOptions(
preferred_execution_providers=[
"NotARealEP",
"CPUExecutionProvider",
],
export_options=torch.onnx.ExportOptions(dynamic_shapes=True),
ort_session_options=ort_session_options,
),
)
x = torch.randn(10)
torch.onnx.export(Gelu(), (x,), "gelu_ts.onnx")
export_output = torch.onnx.dynamo_export(Gelu(), x)
export_output.save("gelu_dynamo.onnx")
inlined_model = onnx.inliner.inline_local_functions(export_output.model_proto)
onnx.save_model(inlined_model, "gelu_dynamo_inlined.onnx")
print("Torch Eager:")
print(Gelu()(x))
print("DORT:")
print(dort_gelu(x))
print(dort_gelu2(x))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107973
Approved by: https://github.com/BowenBao
Generate diagnostic reports to monitor the internal stages of the export process. This tool aids in unblocking model exports and debugging the exporter.
#### Settings
~~1. Choose if you want to produce a .sarif file and specify its location.~~
1. Updated: saving .sarif file should be done by `export_output.save_sarif_log(dst)`, similar to saving exported onnx model `export_output.save(model_dst)`.
2. Customize diagnostic options:
- Set the desired verbosity for diagnostics.
- Treat warnings as errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106741
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby, https://github.com/malfet
The official move of `OnnxRegistry` to `torch.onnx` allows it to become one of the parameters in `torch.onnx.ExportOption`. By incorporating `OnnxRegistry` in `torch.onnx.ExportOption`, users gain access to various functionalities, including the ability to register custom operators using `register_custom_op`, check whether an operator is supported using `is_registered_op`, and obtain symbolic functions that support specific operators using `get_functions`.
Additionally, `opset_version` is now exclusively available in `torch.onnx.OnnxRegistry` as it is removed from `torch.onnx.ExportOption`. The initialization of the registry with torchlib under the provided opset version ensures that the exporter uses the specified opset version as the primary version for exporting.
These changes encompass scenarios where users can:
1. Register an unsupported ATen operator with a custom implementation using onnx-script.
2. Override an existing symbolic function (onnx invariant).
NOTE: The custom registered function will be prioritized in onnx dispatcher, and if there are multiple custom ones, the one registered the last will be picked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106140
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi
## Context prior to this PR
https://github.com/pytorch/pytorch/pull/100017/ was merged onto PyTorch `main` branch with the goal of enabling `torch._dynamo.export` to perform symbolic tracing.
In that context, symbolic tracing is defined as tracing of a model using fake inputs and weights. An input is Fake when `torch.nn.Tensor` is replaced by `torch._subclasses.FakeTensor`, whereas a weight is fake when a `torch.nn.Parameter` is replaced by `torch._subclasses.FakeTensor`.
For additional context, several strategies were discussed with Meta to enable this feature, including 1) calling `torch._dynamo.export` within a `torch._subclass.FakeTensorMode` context and 2) **fake**fying input and model as separate step and then call `torch._dynamo.export` without an active `torch._subclass.FakeTensorMode` context. At the end, 2) was preferred and implemented by #100017 to minimize the number of side-effects the fake tensor mode has on the code base.
As a consequence, `torch._dynamo.export` API introduced a new argument called `fake_mode`. When symbolic tracing is used, the user must pass in the `fake_mode` used to fakefy both the input and the model. Internally, `torch._dynamo.export` will adopt this `fake_mode` instead of creating its own instance. This is needed because each instance of `FakeTensorMode` has metadata on the tensor/parameter it fakefied. Thus, using real tensor/model and specify a `fake_mode` to `torch._dynamo.export` is an error. Also, specify a `fake_mode` instance to `torch._dynamo.export` different than the one used to fakefy the model and input is also an error.
## Changes introduced from this PR
This PR is intended to integrate `torch._dynamo.export(fake_mode=...)` through `torch.onnx.dynamo_export`. In essence, it
* Introduces a new public API `ONNXFakeContext` which wraps a `FakeTensorMode` under the hood. This removes complexity from the user side while still allow the exporter to leverage the fake mode.
* Adds a new public API `enable_fake_mode` *context manager* that instantiates and return a `ONNXFakeContext`.
* Adds a new `ExportOptions.fake_context` that will be used to persist the `ONNXFakeContext` created by `enable_fake_mode` and plumb through until it reaches the call to `torch._dynamo.export`.
* Adds a `model_state_dict` argument to `ExportOutput.save` API.
* When model is exported with fake tensors, no actual data exist in the FX module and, therefore, in the ONNX graph.
* In fact, `torch.fx.make_fx` lifts initializers as model input when fake tensors are used
* https://github.com/pytorch/pytorch/pull/104493 is needed to enforce name matching between Parameters and inputs
* A model checkpoint file or state_dict is needed to populate the ONNX graph with real initializers through `export_output.save(model_state_dict=...)` API
Symbolic tracing, or onnx fake mode, is only enabled when the user instantiates the input and model within the `enable_fake_mode` context. Otherwise, real tracing is done, which preserves the current behavior.
## Usability
Because symbolic tracing depends a lot on having changes made on Dynamo side before it can be consumed on ONNX exporter, this feature may have its API and assumptions changed as symbolic tracing matures upstream. Nonetheless, it is still important to have this feature merged ASAP on the ONNX exporter side to "lock" changes on Dynamo that would otherwise break ONNX exporter without warning.
Example:
```python
class Model(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = torch.nn.Linear(2, 2)
def forward(self, x):
out = self.linear(x)
return out
with torch.onnx.enable_fake_mode() as fake_context:
x = torch.rand(5, 2, 2)
model = Model()
# Export the model with fake inputs and parameters
export_options = ExportOptions(fake_context=fake_context)
export_output = torch.onnx.dynamo_export(
model, x, export_options=export_options
)
model_state_dict = Model().state_dict() # optional
export_output.save("/path/to/model.onnx", model_state_dict=model_state_dict)
```
## Next steps
* Add unit tests running the exported model with ORT
Today this is not possible yet because `make_fx` used by our Decomposition pass lifts initializers as model inputs. However, the initializer names are not preserved by FX tracing, causing a mismatch between the initializer and input name.
https://github.com/pytorch/pytorch/pull/104493 and https://github.com/pytorch/pytorch/pull/104741 should fix the initializer mismatch, enabling model execution
* Revisit `ONNXTorchPatcher` and how the ONNX initializers are saved in the graph as external data
We can try to get rid of the PyTorch patcher. If we can't, we might prefer to create specific patchers, say `FXSymbolicTracePatcher` used specifically during an export using `torch.fx.symbolic_trace` and maybe a `ExportOutputSavePacther` used specifically for `ExportOutput.save` to prevent "patching too many pytorch API that we don't need
## References
* [FakeTensor implementation](https://github.com/pytorch/pytorch/blob/main/torch/_subclasses/fake_tensor.py)
* [PR that adds fake tensor support to torch._dynamo.export](https://github.com/pytorch/pytorch/pull/100017)
* [Short fake tensor documentation](https://pytorch.org/torchdistx/latest/fake_tensor.html)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103865
Approved by: https://github.com/BowenBao
Summary
* Introduce input/output adapter. Due to design differences, input/output format
between PyTorch model and exported ONNX model are often not the same. E.g., `None`
inputs are allowed for PyTorch model, but are not supported by ONNX. Nested constructs
of tensors are allowed for PyTorch model, but only flattened tensors are supported by ONNX,
etc. The new input/output adapter is exported with the model. Providing an interface to
automatically convert and validate inputs/outputs format.
* As suggested by #98251,
provide extension for unwrapping user defined python classes for `dynamo.export` based
exporter. Unblock huggingface models.
* Re-wire tests to run through `DynamoExporter` w/ `dynamo_export` api. Kept
`DynamoOptimizeExporter` in the tests for now for coverage of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98421
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi
This is the first phase of the new ONNX exporter API for exporting from TorchDynamo and FX, and represents the beginning of a new era for exporting ONNX from PyTorch.
The API here is a starting point upon which we will layer more capability and expressiveness in subsequent phases. This first phase introduces the following into `torch.onnx`:
```python
dynamo_export(
model: torch.nn.Module,
/,
*model_args,
export_options: Optional[ExportOptions] = None,
**model_kwargs,
) -> ExportOutput:
...
class ExportOptions:
opset_version: Optional[int] = None
dynamic_shapes: Optional[bool] = None
logger: Optional[logging.Logger] = None
class ExportOutputSerializer(Protocol):
def serialize(
self,
export_output: ExportOutput,
destination: io.BufferedIOBase,
) -> None:
...
class ExportOutput:
model_proto: onnx.ModelProto
def save(
self,
destination: Union[str, io.BufferedIOBase],
*,
serializer: Optional[ExportOutputSerializer] = None,
) -> None:
...
```
In addition to the API in the first commit on this PR, we have a few experiments for exporting Dynamo and FX to ONNX that this PR rationalizes through the new Exporter API and adjusts tests to use the new API.
- A base `FXGraphModuleExporter` exporter from which all derive:
- `DynamoExportExporter`: uses dynamo.export to acquire FX graph
- `DynamoOptimizeExporter`: uses dynamo.optimize to acquire FX graph
- `FXSymbolicTraceExporter`: uses FX symbolic tracing
The `dynamo_export` API currently uses `DynamoOptimizeExporter`.
### Next Steps (subsequent PRs):
* Combine `DynamoExportExporter` and `DynamoOptimizeExporter` into a single `DynamoExporter`.
* Make it easy to test `FXSymbolicTraceExporter` through the same API; eventually `FXSymbolicTraceExporter` goes away entirely when the Dynamo approach works for large models. We want to keep `FXSymbolicTraceExporter` around for now for experimenting and internal use.
* Parameterize (on `ExportOptions`) and consolidate Dynamo exporter tests.
- This PR intentionally leaves the existing tests unchanged as much as possible except for the necessary plumbing.
* Subsequent API phases:
- Diagnostics
- Registry, dispatcher, and Custom Ops
- Passes
- Dynamic shapes
Fixes#94774
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97920
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi, https://github.com/shubhambhokare1
Re-land #81953
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Deprecated: "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type" in `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82995
Approved by: https://github.com/kit1980
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Breaking: **Remove "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type"** from `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81953
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Add flag (inline_autograd) to enable inline export of model consisting of autograd functions. Currently, this flag should only be used in TrainingMode.EVAL and not for training.
An example:
If a model containing ``autograd.Function`` is as follows
```
class AutogradFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
result = result.log()
ctx.save_for_backward(result)
return result
```
Then the model is exported as
```
graph(%0 : Float):
%1 : Float = ^AutogradFunc(%0)
return (%1)
```
If inline_autograd is set to True, this will be exported as
```
graph(%0 : Float):
%1 : Float = onnx::Exp(%0)
%2 : Float = onnx::Log(%1)
return (%2)
```
If one of the ops within the autograd module is not supported, that particular node is exported as is mirroring ONNX_FALLTHROUGH mode
Fixes: #61813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74765
Approved by: https://github.com/BowenBao, https://github.com/malfet
Summary:
Add ONNX exporter logging facility. Supporting both C++/Python logging api. Logging can be turned on/off. Logging output stream can be either set to `stdout` or `stderr`.
A few other changes:
* When exception is raised in passes, the current IR graph being processed will be logged.
* When exception is raised from `_jit_pass_onnx` (the pass that converts nodes from namespace `ATen` to `ONNX`), both ATen IR graph and ONNX IR graph under construction will be logged.
* Exception message for ConstantFolding is truncated to avoid being too verbose.
* Update the final printed IR graph with node name in ONNX ModelProto as node attribute. Torch IR Node does not have name. Adding this to printed IR graph helps debugging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71342
Reviewed By: msaroufim
Differential Revision: D34433473
Pulled By: malfet
fbshipit-source-id: 4b137dfd6a33eb681a5f2612f19aadf5dfe3d84a
(cherry picked from commit 67a8ebed5192c266f604bdcca931df6fe589699f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69550
Fix the wiki URL.
Also minor reorganization in onnx.rst.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32994269
Pulled By: malfet
fbshipit-source-id: 112acfe8b7c778d7e3c2cef684023fdaf2c6ec9c
(cherry picked from commit f0787fabde)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68491
* Allows implementing symbolic functions for domains other than `aten`, for example `prim`, in symbolic_opset#.py.
* Allows symbolic function to access extra context if needed, through `SymbolicFunctionState`.
* Particularly, the `prim::PythonOp` special case can access node without the need of passing node through inputs. Updates will be made downstreams, and in a follow-up PR we will remove the previous workaround in exporter.
* `prim::Loop`, `prim::If`, etc are now moved outside of `_run_symbolic_function` from utils.py, and to symbolic_opset9.py.
Motivation for this change:
- Better maintainability and reducing complexity. Easier to add symbolic for operators, both simple and complex ones (that need additional context), without the former needing to know the existence of the latter.
- The design idea was long outdated. prim ops are no longer rare special cases, and they shouldn't all be handled inside `_run_symbolic_function`. As a result this function becomes too clumsy. There were also prim ops symbolic added in symbolic_opset#.py with signature `prim_[opname]`, creating separation and confusion.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D32483782
Pulled By: malfet
fbshipit-source-id: f9affc31b1570af30ffa6668da9375da111fd54a
Co-authored-by: BowenBao <bowbao@microsoft.com>
(cherry picked from commit 1e04ffd2fd)
Fix the wiki URL.
Also minor reorganization in onnx.rst.
[ONNX] restore documentation of public functions (#69623)
The build-docs check requires all public functions to be documented.
These should really not be public, but we'll fix that later.'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71609
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66143
Delete test_list_remove. There's no point in testing conversion of
this model since TorchScript doesn't support it.
Add a link to an issue tracking test_embedding_bag_dynamic_input.
[ONNX] fix docs (#65379)
Mainly fix the sphinx build by inserting empty before
bulleted lists.
Also some minor improvements:
Remove superfluous descriptions of deprecated and ignored args.
The user doesn't need to know anything other than that they are
deprecated and ignored.
Fix custom_opsets description.
Make indentation of Raises section consistent with Args section.
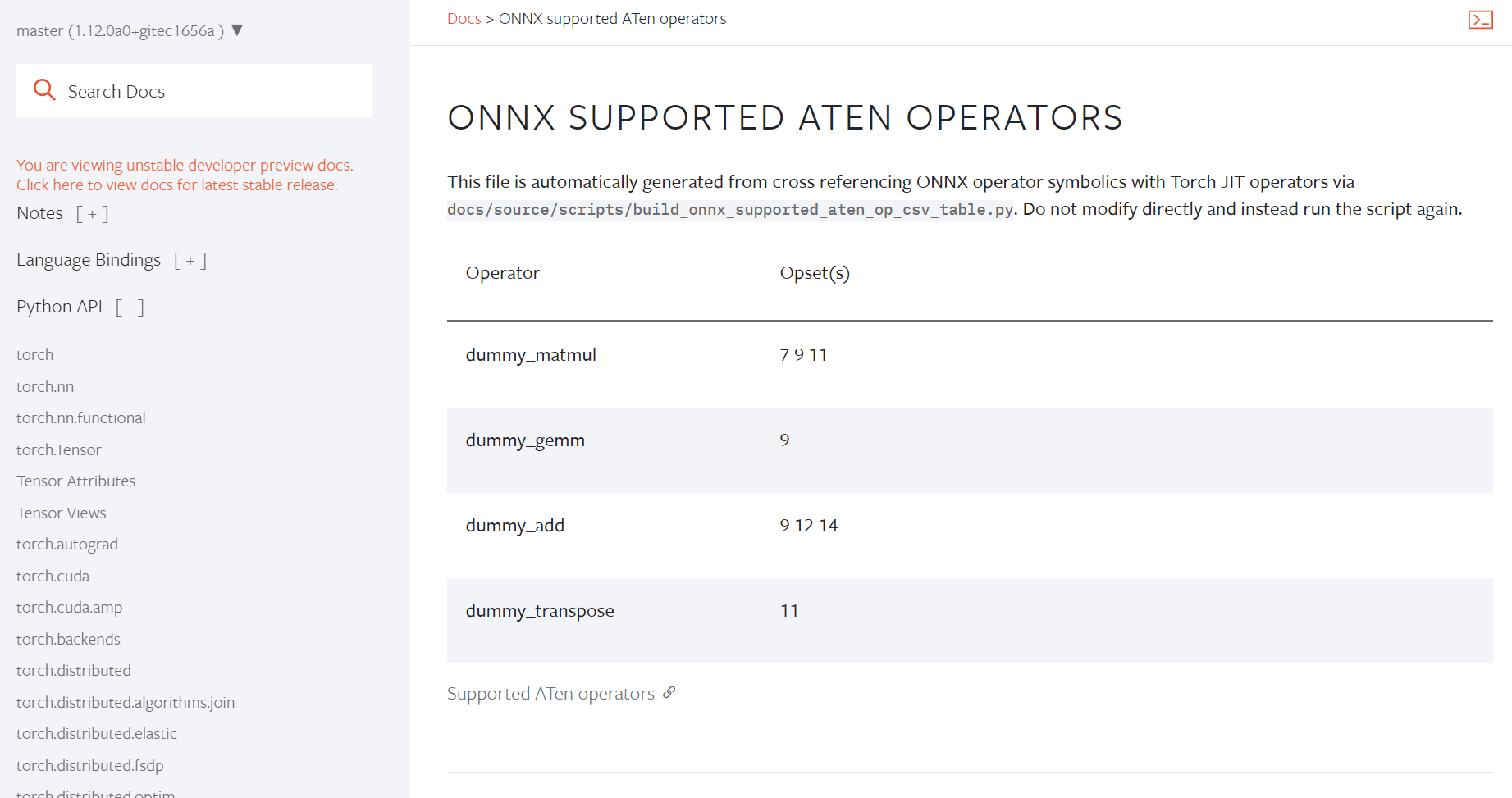
[ONNX] publicize func for discovering unconvertible ops (#65285)
* [ONNX] Provide public function to discover all unconvertible ATen ops
This can be more productive than finding and fixing a single issue at a
time.
* [ONNX] Reorganize test_utility_funs
Move common functionality into a base class that doesn't define any
tests.
Add a new test for opset-independent tests. This lets us avoid running
the tests repeatedly for each opset.
Use simple inheritance rather than the `type()` built-in. It's more
readable.
* [ONNX] Use TestCase assertions rather than `assert`
This provides better error messages.
* [ONNX] Use double quotes consistently.
[ONNX] Fix code block formatting in doc (#65421)
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31424093
fbshipit-source-id: 4ced841cc546db8548dede60b54b07df9bb4e36e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64373
* Fix some bad formatting and clarify things in onnx.rst.
* In `export_to_pretty_string`:
* Add documentation for previously undocumented args.
* Document that `f` arg is ignored and mark it deprecated.
* Update tests to stop setting `f`.
* Warn if `_retain_param_name` is set.
* Use double quotes for string literals in test_operators.py.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905271
Pulled By: malfet
fbshipit-source-id: 3627eeabf40b9516c4a83cfab424ce537b36e4b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60249
* Add introductory paragraph explaining what ONNX is and what the
torch.onnx module does.
* In "Tracing vs Scripting" and doc-string for torch.onnx.export(),
clarify that exporting always happens on ScriptModules and that
tracing and scripting are the two ways to produce a ScriptModule.
* Remove examples of using Caffe2 to run exported models.
Caffe2's website says it's deprecated, so it's probably best not to
encourage people to use it by including it in examples.
* Remove a lot of content that's redundant:
* The example of how to mix tracing and scripting, and instead
link to Introduction to TorchScript, which includes very similar
content.
* "Type annotations" section. Link to TorchScript docs which explain
that in more detail.
* "Using dictionaries to handle Named Arguments as model inputs"
section. It's redundant with the description of the `args` argument
to `export()`, which appears on the same page once the HTML
is generated.
* Remove the list of supported Tensor indexing patterns. If it's not
in the list of unsupported patterns, users can assume it's
supported, so having both is redundant.
* Remove the list of supported operators and models.
I think the list of supported operators is not very useful.
A list of supported model architectures may be useful, but in
reality it's already very out of date. We should add it back if
/ when we have a system for keeping it up to date.
* "Operator Export Type" section. It's redundant with the description
of the `operator_export_type` arg to to `export()`, which appears on
the same page once the HTML is generated.
* "Use external data format" section. It's redundant with the
description of the `use_external_data_format` arg to `export()`.
* "Training" section. It's redundant with the
description of the `training` arg to `export()`.
* Move the content about different operator implementations producing
different results from the "Limitations" section into the doc for the
`operator_export_type` arg.
* Document "quantized" -> "caffe2" behavior of
OperatorExportTypes.ONNX_ATEN_FALLBACK.
* Combing the text about using torch.Tensor.item() and the text about
using NumPy types into a section titled
"Avoid NumPy and built-in Python types", since they're both
fundamentally about the same issue.
* Rename "Write PyTorch model in Torch way" to "Avoiding Pitfalls".
* Lots of minor fixes: spelling, grammar, brevity, fixing links, adding
links.
* Clarify limitation on input and output types. Phrasing it in terms of
PyTorch types is much more accessible than in terms of TorchScript
types. Also clarify what actually happens when dict and str are used
as inputs and outputs.
* In Supported operators, use torch function and class names and link
to them. This is more user friendly than using the internal aten
op names.
* Remove references to VariableType.h, which doesn't appear to contain
the information that it once did. Instead refer to the generated
.pyi files.
* Remove the text in the FAQ about appending to lists within loops.
I think this limitation is no longer present
(perhaps since https://github.com/pytorch/pytorch/pull/51577).
* Minor fixes to some code I read along the way.
* Explain the current rationale for the weird ::prim_PythonOp op name.
Test Plan: Imported from OSS
Reviewed By: zou3519, ZolotukhinM
Differential Revision: D29494912
Pulled By: SplitInfinity
fbshipit-source-id: 7756c010b2320de0692369289604403d28877719
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
The args parameter of ONNX export is changed to better support optional arguments such that args is represented as:
args (tuple of arguments or torch.Tensor, a dictionary consisting of named arguments (optional)):
a dictionary to specify the input to the corresponding named parameter:
- KEY: str, named parameter
- VALUE: corresponding input
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47367
Reviewed By: H-Huang
Differential Revision: D25432691
Pulled By: bzinodev
fbshipit-source-id: 9d4cba73cbf7bef256351f181f9ac5434b77eee8
Summary:
For tracing successfully, we need write pytorch model in torch way. So we add instructions with examples here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46961
Reviewed By: ailzhang
Differential Revision: D24900040
Pulled By: bzinodev
fbshipit-source-id: b375b533396b11dbc9656fa61e84a3f92f352e4b
{kind=link}
{kind=link}
{kind=link}
{kind=link}