Fixes#96064
When deciding whether to fuse nodes, we match indexing like `c0 + 5 * tmp0`, but `tmp0` in the different nodes can refer to totally different values. Even when `tmp0` is the same (like in the added test) inductor still generates wrongly ordered loads and stores (loads come before stores), so better just disable this fusion altogether. We should fix wrong order also:
```
@pointwise(size_hints=[8], filename=__file__, meta={'signature': {0: '*i64', 1: '*fp32', 2: '*fp32', 3: '*fp32', 4: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, in_ptr1, out_ptr0, out_ptr1, xnumel, XBLOCK : tl.constexpr):
xnumel = 5
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0_load = tl.load(in_ptr0 + (0))
tmp0 = tl.broadcast_to(tmp0_load, [XBLOCK])
tmp1 = tl.load(in_ptr1 + (x0), xmask)
tmp2 = tl.load(out_ptr0 + (x0 + (5*tmp0)), xmask)
tl.store(out_ptr0 + (x0 + (5*tmp0) + tl.zeros([XBLOCK], tl.int32)), tmp1, xmask)
tl.store(out_ptr1 + (x0 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask)
```
Note: we are loading from `out_ptr0` here (that shouldn't happen), we are loading from it before storing to it.
After this PR, the kernel above is split in 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96273
Approved by: https://github.com/jansel
This is a follow up for PR #95506 to run all the triton kernels in a compiled module individually as suggested by Horace.
Here are the steps:
1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g.
```
TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training
```
2. From the output we will see 3 lines like
```
Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py
```
That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module.
3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file.
```
python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k
```
Example output:
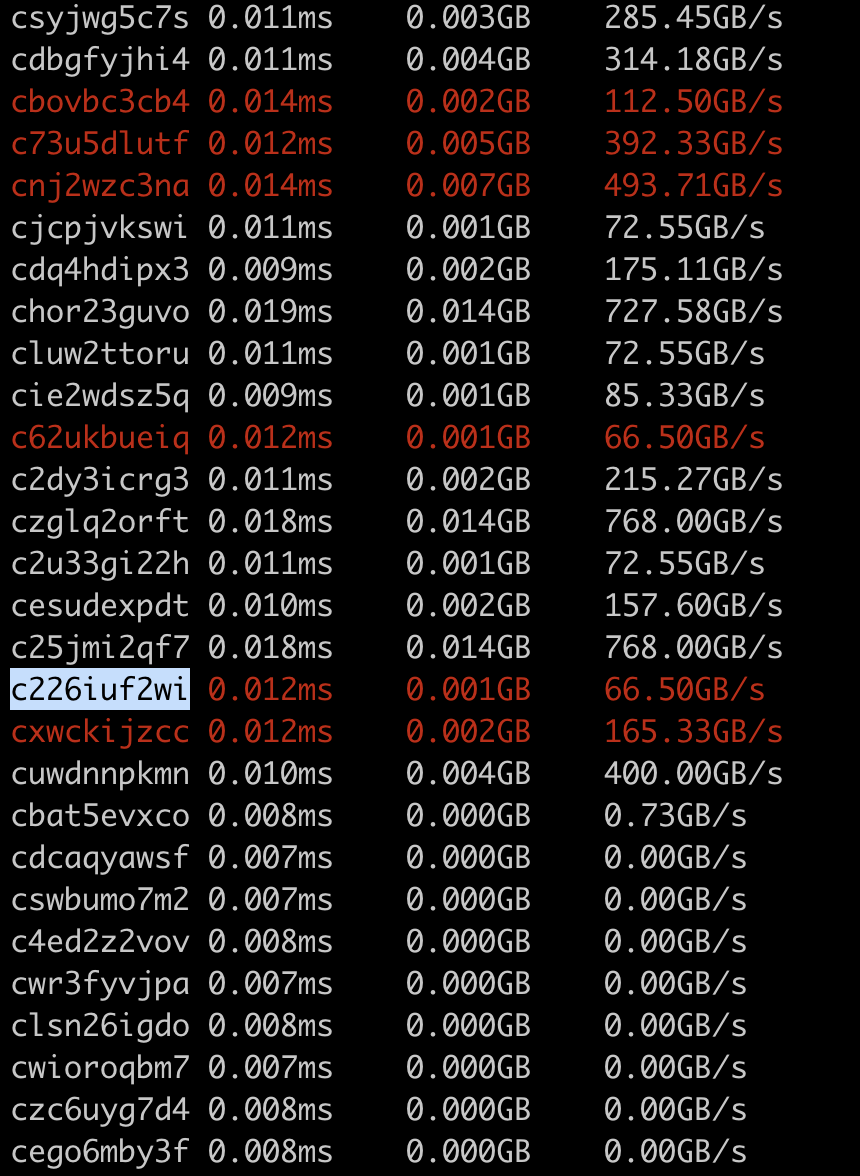
<img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png">
Note: I use the first 10 characters of the hash to identify each kernel since
1. hash is easier to get in the code :)
2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash)
If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95845
Approved by: https://github.com/Chillee
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module.
Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like: `def f(x): return sin(x) + cos(x)` https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part:
- various triton kernels
- a wrapper (or a method named call . The name is hardcoded) that calls the triton kernels and potentially ATen kernels to efficiently do the same work as the original Fx graph being compiled by inductor
- some utility code that generate random inputs and run the wrapper
The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning.
This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well.
The path to each compiled triton kernel is added as comment in the compiled module. E.g.
```
# kernel path: /tmp/torchinductor_shunting/gn/cgn6x3mqoltu7q77gjnu2elwfupinsvcovqwibc6fhsoiy34tvga.py
triton__0 = async_compile.triton('''
import triton
import triton.language as tl
...
""")
````
Example command:
```
TORCHINDUCTOR_OUTPUT_COMPILED_MODULE_PATH=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --training --dashboard --only AlbertForMaskedLM --disable-cudagraphs
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95506
Approved by: https://github.com/Chillee
Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Summary:
this diff adds logic to handle a global autotuning cache, stored in json format at config.global_cache_path.
what is changing from `DiskCache`:
* `DiskCache` is renamed to `PersistentCache`
* the local cache is now stored as a single file in json format, located at `/tmp/torchinductor_{$USER}/local_cache`. the file contains a dictionary structure like `local_cache[name][inputs][choice]` where `name` is the type of operation, like `addmm`, `inputs` is the repr of the inputs, and `choice` is the hash of a `ChoiceCaller`. the stored value is the benchmark time for that `ChoiceCaller`.
* a global cache is added, initially stored at `fbcode/caffe2/torch/_inductor/global_cache`, with almost identical format as the local cache. since the global cache exists over different machines, there is an additional `dinfo` field, such that `global_cache[dinfo] = local_cache` (at least structure wise, there is no guarantee that the global cache and local cache share the same values). `dinfo` is just a repr of the cuda device properties.
* the autotuner will prioritize the global cache, and return values from there first, before looking in the local cache
* the autotuner will look in both the global cache and the local cache even when `max_autotune=False`, but will still only generate values if `max_autotune=True`.
* the autotuner will log global cache hits and misses to a scuba table (inductor_autotuning_cache) which will be used to update the global cache at regular intervals
Test Plan: D43285472
Differential Revision: D42785435
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94922
Approved by: https://github.com/jansel
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
I applied some flake8 fixes and enabled checking for them in the linter. I also enabled some checks for my previous comprehensions PR.
This is a follow up to #94323 where I enable the flake8 checkers for the fixes I made and fix a few more of them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94601
Approved by: https://github.com/ezyang
Historically, we work out `size_hint` by working it out on the fly by doing a substitution on the sympy expression with the `var_to_val` mapping. With this change, we also maintain the hint directly on SymNode (in `expr._hint`) and use it in lieu of Sympy substitution when it is available (mostly guards on SymInt, etc; in particular, in idiomatic Inductor code, we typically manipulate Sympy expressions directly and so do not have a way to conveniently maintain hints.)
While it's possible this will give us modest performance improvements, this is not the point of this PR; the goal is to make it easier to carefully handle unbacked SymInts, where hints are expected not to be available. You can now easily test if a SymInt is backed or not by checking `symint.node.hint is None`.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94201
Approved by: https://github.com/voznesenskym
Currently the default `ops` handler expects strings as arguments and
just formats them into a function call template string. For complex
expressions, this can lead to exponential growth in terms. Say for
example you have:
```python
def fn(a):
for _ in range(3)
a = ops.mul(a, a)
return a
```
You might expect `inner_fn_str` to contain 1 load and 3 multiplies,
but instead you find 8 loads and 7 multiplies:
```python
load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0)
```
This type of blowup is present in the lowering for
`max_pool2d_with_indices_backward` which in #pytorch/torchdynamo#1352
was reported to have caused the entire compilation to hang.
This PR fixes the issue by formatting the string as a series of assignments to
variables, so for the example above, we now get:
```
tmp0 = load(arg_0, i0)
tmp1 = tmp0 * tmp0
tmp2 = tmp1 * tmp1
tmp3 = tmp2 * tmp2
return tmp3
```
Which corresponds to sequence of `ops` calls made.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88933
Approved by: https://github.com/jansel
Relands #89031
Per title. We now set strides from fx graph only for convolutions and mm, which is a hack, but bmm in some cases caused extra copy, and there is no obvious way to fix that, we should rethink the strides anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89530
Approved by: https://github.com/Chillee
- Propagates origin fx nodes through inlining during lowering
- Concatenates op names into kernel name
- Adds config to cap the number of ops in the kernel name so they don't get too long
Caveats:
- The ordering in the name may not match the order that the ops are executed in the kernel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88624
Approved by: https://github.com/anijain2305, https://github.com/jansel
Add stride/contiguity constraints to fallbacks so that inputs will be in the right stride permutation for the fallback kernel.
Improves perf of coat_lite_mini from 1.48415536054865 -> 2.010956856330101.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88534
Approved by: https://github.com/ngimel
{kind=link}
{kind=link}
{kind=link}