Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18155
- Make a python decorator caffe2_flaky for caffe2 operator unit tests.
- The environment variable CAFFE2_RUN_FLAKY_TESTS are now used to mark flaky test mode
During test run,
- If flaky tests mode are on, only flaky tests are run
- If flaky tests mode are off, only non-flaky tests are run
Mark ctc_beam_search_decoder_op_test as flaky
Reviewed By: ezyang, salexspb
Differential Revision: D14468816
fbshipit-source-id: dceb4a48daeb5437ad9cc714bef3343e9761f3a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18129
A lot of tensor interference function assume the operator passes the schema.
So call Verity to make sure this is actually the case.
Created diff before to add checking in Concat (https://github.com/pytorch/pytorch/pull/17110), but I encountered lot more places where this is assumed (for example ElementwiseOpShapeInference)
Reviewed By: mdschatz
Differential Revision: D14503933
fbshipit-source-id: cf0097b8c3e4beb1cded6b61e092a6adee4b8fcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18257
support adding op in global_init_net. because pred_init_net is per thread, and just doesn't cut it.
Reviewed By: jspark1105
Differential Revision: D14552695
fbshipit-source-id: 53dd44c84ad019019ab9f35fc04d076b7f941ddc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17905
support adding op in global_init_net. because pred_init_net is per thread, and just doesn't cut it.
Reviewed By: jspark1105
Differential Revision: D14114134
fbshipit-source-id: 112bb2ceb9d3d5e663dd430585567f4eaa2db35f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18040
Add flag to fails if float point exceptions is detected in operator runs
Sample exception
Exception [enforce fail at operator.h:837] !std::fetestexcept(FE_DIVBYZERO). Division by zero floating point exception (FE_DIVBYZERO) reported.
Error from operator:
input: "1" input: "0" output: "out" name: "" type: "Div"
Reviewed By: jspark1105
Differential Revision: D14467731
fbshipit-source-id: fad030b1d619a5a661ff2114edb947e4562cecdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18084
data_strategy parameter was not used in some of unit tests for optimizers
Reviewed By: hyuen
Differential Revision: D14487830
fbshipit-source-id: d757cd06aa2965f4c0570a4a18ba090b98820ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18036
- Add macros to export c10 cuda operators to caffe2 frontend
- Instead of having a separate caffe2 registry for the c10 operator wrappers, use the existing caffe2 registries
Reviewed By: ezyang
Differential Revision: D14467495
fbshipit-source-id: 7715ed2e38d2bbe16f1446ae82c17193a3fabcb9
Summary:
According to https://docs.python.org/3/tutorial/inputoutput.html, it is good practice to use the "with" keyword when dealing with file objects. If not, you should call f.close() to close the file and immediately free up any system resources used by it. Thus, I adjust the open file function to "with open() as f".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18017
Differential Revision: D14475112
Pulled By: ezyang
fbshipit-source-id: d1c0821e39cb8a09f86d6d08b437b4a99746416c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17548
expose half float operators to OSS
common/math/Float16.h is the original implementation
this is substituted by caffe2/c10/util/Half.h
from the comments seems like the both implementations don't handle denormals
Reviewed By: jspark1105
Differential Revision: D14244200
fbshipit-source-id: f90ba28c5bf6a2b451b429cc4925b8cc376ac651
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17726
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17725
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17461
Implementing a standalone LSTM Operator in Caffe2 adopted from this Aten implementation: diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/native/RNN.cpp. The most tricky thing in this exercise was that caffe2::Tensor has no copy constructor that made it necessary to implement a custom templated copy constructor for the different Tensor containers used in the code. Also there was no way to use off-the-shelf C2 operators in my code easily so I had to copy some code that is doing basic matmul, cat, split, transpose and linear as utility functions.
Two things missing:
- Profiling this implementation against the current ONNXified LSTM op
- Make this operator available to use in PyTorch
Reviewed By: dzhulgakov
Differential Revision: D14351575
fbshipit-source-id: 3b99b53212cf593c7a49e45580b5a07b90809e64
Summary:
Observed the test `TestGroupConvolution.test_group_convolution` to fail with the following error:
```
Falsifying example: test_group_convolution(self=<caffe2.python.operator_test.group_conv_test.TestGroupConvolution testMethod=test_group_convolution>, stride=3, pad=0, kernel=5, size=8, group=4, input_channels_per_group=7, output_channels_per_group=8, batch_size=2, order='NHWC', engine='', use_bias=False, gc=, dc=[, device_type: 1])
You can reproduce this example by temporarily adding reproduce_failure('3.59.1', b'AAAA') as a decorator on your test case
```
This example generated by hypothesis has `group=2, order='NHWC' and dc=[, device_type: 1])`.
I think this example should be skipped.
I have mimicked the change corresponding to [PR#13554](https://github.com/pytorch/pytorch/pull/13554) to skip this example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17715
Differential Revision: D14346642
Pulled By: ezyang
fbshipit-source-id: b1f1fef09f625fdb43d31c7213854e61a96381ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17623
Despite it's generic sounding name, caffe2::DeviceGuard actually
only worked on CUDA devices. Rename it to something that more
clearly spells out its applicability.
I'm not sure if it's the right call, but in this patch I added
'using CUDAGuard = c10::cuda::CUDAGuard', as this seems to be more
in-line with how the Caffe2 codebase is currently written. More
idiomatic c10 namespace style would be to say cuda::CUDAGuard.
Willing to change this if people shout.
This is a respin of D13156470 (#14284)
Reviewed By: dzhulgakov
Differential Revision: D14285504
fbshipit-source-id: 93b8ab938b064572b3b010c307e1261fde0fff3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17461
Implementing a standalone LSTM Operator in Caffe2 adopted from this Aten implementation: diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/native/RNN.cpp. The most tricky thing in this exercise was that caffe2::Tensor has no copy constructor that made it necessary to implement a custom templated copy constructor for the different Tensor containers used in the code. Also there was no way to use off-the-shelf C2 operators in my code easily so I had to copy some code that is doing basic matmul, cat, split, transpose and linear as utility functions.
Two things missing:
- Profiling this implementation against the current ONNXified LSTM op
- Make this operator available to use in PyTorch
Reviewed By: dzhulgakov
Differential Revision: D14160172
fbshipit-source-id: c33e3f9e8aeae578b64d97593cb031a251216029
Summary:
Because of two separate python extensions with different pybind
instances I have to go through void* conversion. Since it's hidden from
user, it's fine.
New APIs added on C2 side:
- workspace.FetchTorch('blob')
- workspace.Workspace.current.blobs['blob'].to_torch()
- workspace.FeedBlob('blob', pytorch_tensor)
Works on CPU an GPU.
The only glitches are with resizing because of variable/tensor split.
But data sharing works properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17190
Reviewed By: ezyang
Differential Revision: D14163882
Pulled By: dzhulgakov
fbshipit-source-id: d18e5b8fcae026f393c842a1149e972515732de2
Summary:
They are previously merged to resolve#17051. However, since it was resolved by the upstream, and it was causing some issues like https://github.com/abjer/tsds/issues/8, I think it's time to revert these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17567
Differential Revision: D14265241
Pulled By: kostmo
fbshipit-source-id: 7fa2b7dd4ebc5148681acb439cf82d983898694e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17549
Currently Dropout is only enabled in training, we enable the option of having dropout in Eval.
This is to follow [1]. This functionality would be used for uncertainty estimation in exploration project.
[1] Gal, Yarin, and Zoubin Ghahramani. "Dropout as a bayesian approximation: Representing model uncertainty in deep learning." international conference on machine learning. 2016.
Reviewed By: Wakeupbuddy
Differential Revision: D14216216
fbshipit-source-id: 87c8c9cc522a82df467b685805f0775c86923d8b
Summary:
MKL-DNN support multi-node mode,but not support multi-devices mode,this commit will support multi-devices for MKL-DNN.This commit depend on https://github.com/pytorch/pytorch/pull/11330
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12856
Differential Revision: D13735075
Pulled By: ezyang
fbshipit-source-id: b63f92b7c792051f5cb22e3dda948013676e109b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16723
Removed obsolete argument correct_transform_coords in bbox_transform op.
* It was only for backward compatibility. We should not have models using it now.
Differential Revision: D13937430
fbshipit-source-id: 504bb066137ce408c12dc9dcc2e0a513bad9b7ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17194
we found that there is a per row absolute error due to int8 quant
and a relative error table-wide in case fp16 is used
Reviewed By: csummersea
Differential Revision: D14113353
fbshipit-source-id: c7065aa9d15c453c2e5609f421ad0155145af889
Summary:
similar to softmax there are issues of getting nan randomly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17170
Differential Revision: D14110515
Pulled By: bddppq
fbshipit-source-id: 5c97661184d45a02122fd69d35a839fdf4520c8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17062
from jiyan's training jobs it seems like we found a quantization bug
fp32
fp32->rowwise int8 is fine
fp16 is fine
fp16->rowwise int8 is not fine
we are preconverting everything to fp32 and using the existing code, so there is no need to change the epsilon in the case of fp16 since at the time of converting, everything is a float
Reviewed By: jspark1105
Differential Revision: D14063271
fbshipit-source-id: 747297d64ed8c6fdf4be5bb10ac584e1d21a85e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17158
Because of Reshape op, batch size can be changed. This diff addresses first order issue raised from multiple batch size system. We need to export different real_batch_size for different max_batch_size input and attach it to the right output.
It also fixes a false exception.
Reviewed By: ipiszy
Differential Revision: D14099541
fbshipit-source-id: 0fa9e86826f417a11d2b5dd2ee60dff64a7ce8c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17074
There are some common functionalities in backend lowering. This diff creates a base class which hosts these common stuff.
Reviewed By: ipiszy
Differential Revision: D14073192
fbshipit-source-id: 9617603d0e73db6f7fcc5572756b9dbab506dae5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17046
As we are moving to use bound shape inference, we can remove the awkward fake inference run path and make the code cleaner.
Reviewed By: ipiszy
Differential Revision: D14061501
fbshipit-source-id: b3ace98b3dabef3c3359086a0bb1410518cefa26
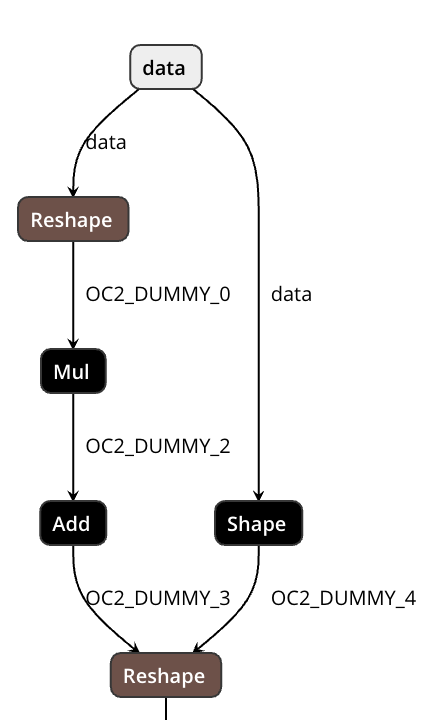
Summary:
For >2D input, previously the code uses static shape captured during tracing and reshape before/after `Gemm`.
Now we add `-1` to the first `Reshape`, and uses `Shape(X) => Slice(outer) => Concat(with -1 for inner) => Reshape` for the second.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16184
Differential Revision: D14070754
Pulled By: ezyang
fbshipit-source-id: 86c69e9b254945b3406c07e122e57a00dfeba3df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16691
Previous diffs already introduced a macro that registers caffe2 CPU kernels with c10.
This now also registers the CUDA kernels with it.
Reviewed By: bwasti
Differential Revision: D13901619
fbshipit-source-id: c15e5b7081ff10e5219af460779b88d6e091a6a6
Summary:
The second input (`lengths`) is not supported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16727
Differential Revision: D14054105
Pulled By: houseroad
fbshipit-source-id: 36b8d00460f9623696439e1bd2a6bc60b7bb263c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16932
During onnxifi transformation net ssa is rewritten. At the last step the weight
names are changed back to what they were before. The diff keeps the weight
names unchanged thru the process.
Reviewed By: yinghai
Differential Revision: D13972597
fbshipit-source-id: 7c29857f788a674edf625c073b345f2b44267b33
{kind=link}