mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-07 12:21:27 +01:00
59dd12042e
9 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
ede3f5421f |
[Pytorch Delegated Backend] Save function name in debug info (#57481)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/57481 This diff introduces function name to InlinedCallStack. Since we are using InlinedCallStack for debug information in lite interpreter as well as delegate backends, where InlinedCallStack cannot be constructed from model source code, we need to save function name. In the absence of function name Function* is used to get name of the function. This is when JIT compiles code at runtime. When that is not possible, this diff introduces a way to obtain function name. Test Plan: test_backend test_cs_debug_info_serialization test_backend test_cs_debug_info_serialization Imported from OSS Differential Revision: D28159097 D28159097 Reviewed By: raziel, ZolotukhinM Pulled By: kimishpatel fbshipit-source-id: deacaea3325e27273f92ae96cf0cd0789bbd6e72 |
||
|
|
813adf1076 |
[Pytorch Delegated Backend] Save operator name and function name in (#57441)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/57441 debug info Previous diffs did not save operator name in debug info. For delegated backends that only idenfity op for profiling with debug handle, operator name should be stores as well. Furthermore to complete debug informaton also serialize function name. Test Plan: Existing lite interpreter and backend tests Existing lite interpreter and backend tests Imported from OSS Differential Revision: D28144581 D28144581 Reviewed By: raziel Pulled By: kimishpatel fbshipit-source-id: 415210f147530a53b444b07f1d6ee699a3570d99 |
||
|
|
d6d726f781 |
[Pytorch Backend delegation] Add api for backend lowering to query debug (#55462)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/55462 handles and symbolicate exception callstack thrown from backend. Objective of this diff is to achieve improve error reporting when exceptions are raised from lowered backend. We would effectively like to get the same model level stack trace that you would get without having lowered some module to backend. For example: ``` class AA(nn.Module): def forward(self, x, y): return x + y class A(nn.Module): def __init__(...): self.AA0 = AA() def forward(self, x, y): return self.AA0.forward(x, y) + 3 class B(nn.Module): def forward(self, x): return x + 2 class C(nn.Module): def __init__(...): self.A0 = A() self.B0 = B() def forward(self, x, y): return self.A0.forward(x, y) + self.B0.forward(x) ``` If the we then do C().forward(torch.rand((2,3)), torch.rand(14,2))) we will likely see error stack like: ``` C++ exception with description "The following operation failed in the TorchScript interpreter. Traceback of TorchScript (most recent call last): File "<string>", line 3, in forward def forward(self, x, y): return self.A0.forward(x, y) + self.B0.forward(x) ~~~~~~~~~~~~~~~ <--- HERE File "<string>", line 3, in forward def forward(self, x, y): return self.AA0.forward(x, y) + 3 ~~~~~~~~~~~~~~~~ <--- HERE File "<string>", line 3, in forward def forward(self, x, y): return x + y ~~~~~ <--- HERE ``` We would like to see the same error stack if we lowered C.A0 to some backend. With this diff we get something like: ``` Module hierarchy:top(C).A0(backend_with_compiler_demoLoweredModule).AA0(AA) Traceback of TorchScript (most recent call last): File "<string>", line 3, in FunctionName_UNKNOWN def forward(self, x, y): return self.A0.forward(x, y) + self.B0.forward(x) ~~~~~~~~~~~~~~~ <--- HERE File "<string>", line 5, in FunctionName_UNKNOWN typed_inputs: List[Any] = [x, y, ] if self.__backend.is_available() : _0, = self.__backend.execute(self.__handles["forward"], typed_inputs) ~~~~~~~~~~~~~~~~~~~~~~ <--- HERE assert isinstance(_0, Tensor) return _0 File "<string>", line 3, in FunctionName_UNKNOWN def forward(self, x, y): return self.AA0.forward(x, y) + 3 ~~~~~~~~~~~~~~~~ <--- HERE File "<string>", line 3, in FunctionName_UNKNOWN def forward(self, x, y): return x + y ~~~~~ <--- HERE ``` This is achieved in 3 parts: Part 1: A. BackendDebugInfoRecorder: During backend lowering, in `to_backend`, before calling the preprocess function corresponding to the backend. This will facilitate recording of debug info (such as source range + inlined callstack) for the lowered module. B. Instantiate WithBackendDebugInfoRecorder with BackendDebugInfoRecorder. This initializes thread local pointer to BackendDebugInfoRecorder. C. generate_debug_handles: In preprocess function, the backend will call generate_debug_handles for each method being lowered separately. generate_debug_handles takes `Graph` of the method being lowered and returns a map of Node*-to-debug_handles. Backend is responsible for storing debug handles appropriately so as to raise exception (and later profiling) using debug handles when the exception being raised corresponds to particular Node that was lowered. Inside generate_debug_handles, we will query the current BackendDebugHandleInfoRecorder, that is issuing debug handles. This debug handle manager will issue debug handles as well as record debug_handles-to-<source range, inlined callstack> map. D. Back in `to_backend`, once the preprocess function is has finished lowering the module, we will call `stopRecord` on BackendDebugInfoRecorder. This will return the debug info map. This debug info is then stored inside the lowered module. Part 2: Serialization: During serialization for bytecode (lite interpreter), we will do two things: 1. Extract all the source ranges that are contained inside debug_handles-to-<source range, inlined callstack> map for lowered module. This will be source range corresponding to debug handles, including what is there is inlined callstack. Since we replaced original module with lowered module, we wont be serializing code for the original module and thus no source range. That is why the source range will have to be stored separately. We will lump all the source ranges for all the lowered modules in one single debug_pkl file. 2. Then we will serialize debug_handles-to-<source range, inlined callstack> map. Now during deserialization we will be able to reconstruct debug_handles-to-<source range, inlined callstack> map. Given all debug_handles are unique we would not need any module information. Test Plan: Tests are added in test_backend.cpp Tests are added in test_backend.cpp Imported from OSS Differential Revision: D27621330 D27621330 Reviewed By: raziel Pulled By: kimishpatel fbshipit-source-id: 0650ec68cda0df0a945864658cab226a97ba1890 |
||
|
|
5288d05cfd |
Revert D27958477: [PyTorch][Edge] Add v4 and v5 models and remove unused model
Test Plan: revert-hammer
Differential Revision:
D27958477 (
|
||
|
|
2e4c68a727 |
[PyTorch][Edge] Add v4 and v5 models and remove unused model (#56751)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/56751 ## Summary 1. Add two models (v4 and v5) for testing runtime. (v5 will be introduced in https://github.com/pytorch/pytorch/pull/56002) 2. Remove an unused model. Side note: these binaries are part of the test in https://github.com/pytorch/pytorch/pull/56002, and currently there is an ongoing issue to `ghexport` with binaries (post is https://fb.workplace.com/groups/533197713799375/permalink/1130109004108240/). `ghimport` can work with binary after checking temporary diff (D23336574). Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D27958477 Pulled By: cccclai fbshipit-source-id: 2e6f985a988da55ad08fb9a5037434a2b6db0776 |
||
|
|
3551bd31be |
[PyTorch] Lite interpreter with a backend delegate (#54462)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/54462 Unclean files during sync - Sat Mar 20 04:00:02 PDT 2021 Unclean files during sync - Sun Mar 21 04:00:01 PDT 2021 ghstack-source-id: 124585992 Test Plan: ``` buck run xplat/caffe2/fb/test/delegate:interpreter_test -- --model_file_path=/path/to/mobile_model.ptl ``` Reviewed By: raziel Differential Revision: D27232309 fbshipit-source-id: 8504a3185339d73bfa6e924485c4745acf269cec |
||
|
|
7605ce4ed8 |
[PyTorch] Enable test_lite_interpreter_runtime running in android (#54579)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/54579 ## Summary 1. Eliminate a few more tests when BUILD_LITE_INTERPRETER is on, such that test_lite_interpreter_runtime can build and run on device. 2. Remove `#include <torch/torch.h>`, because it's not needed. ## Test plan Set the BUILD_TEST=ON `in build_android.sh`, then run ` BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` push binary to android device: ``` adb push ./build_android_x86/bin/test_lite_interpreter_runtime /data/local/tmp ``` Reorganize the folder in `/data/local/tmp` so the test binary and model file is like following: ``` /data/local/tmp/test_bin/test_lite_interpreter_runtime /data/local/tmp/test/cpp/lite_interpreter_runtime/sequence.ptl ``` such that the model file is in the correct path and can be found by the test_lite_interpreter_runtime. 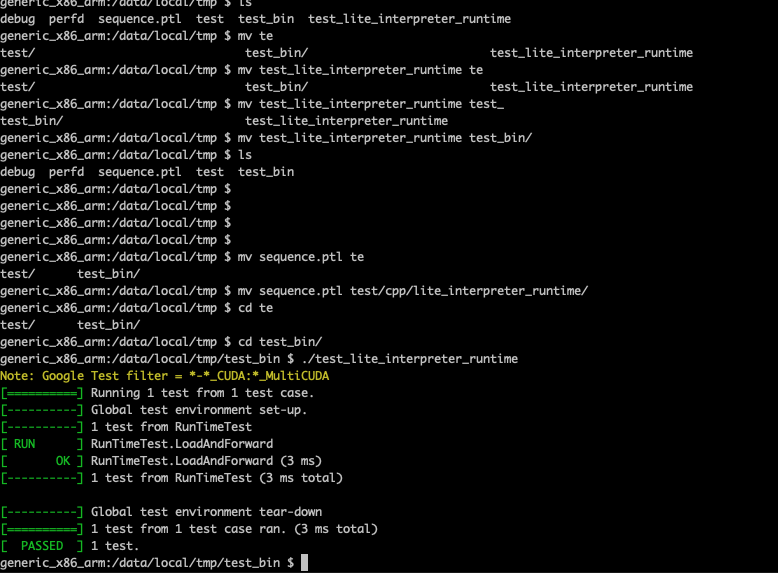 Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D27300720 Pulled By: cccclai fbshipit-source-id: d9526c7d3db8c0d3e76c5a4d604c6877c78afdf9 |
||
|
|
64255294ba |
[PyTorch][CI] Enable building test_lite_interpreter_runtime unittest in CI (macos) (#52566)
Summary: ## Summary 1. Enable building libtorch (lite) in CI (macos) 2. Run `test_lite_interpreter_runtime` unittest in CI (macos) 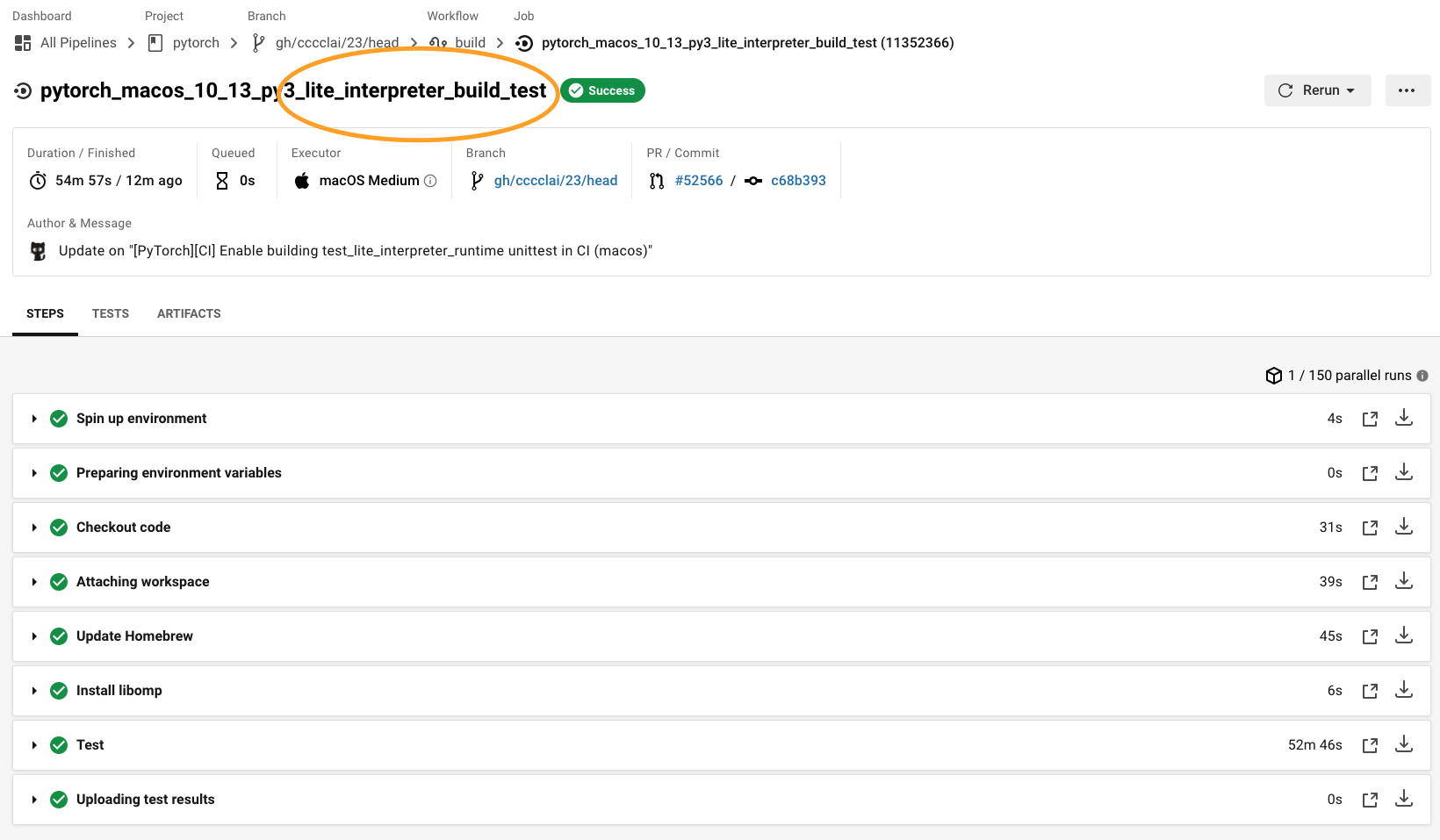 {F467163464} 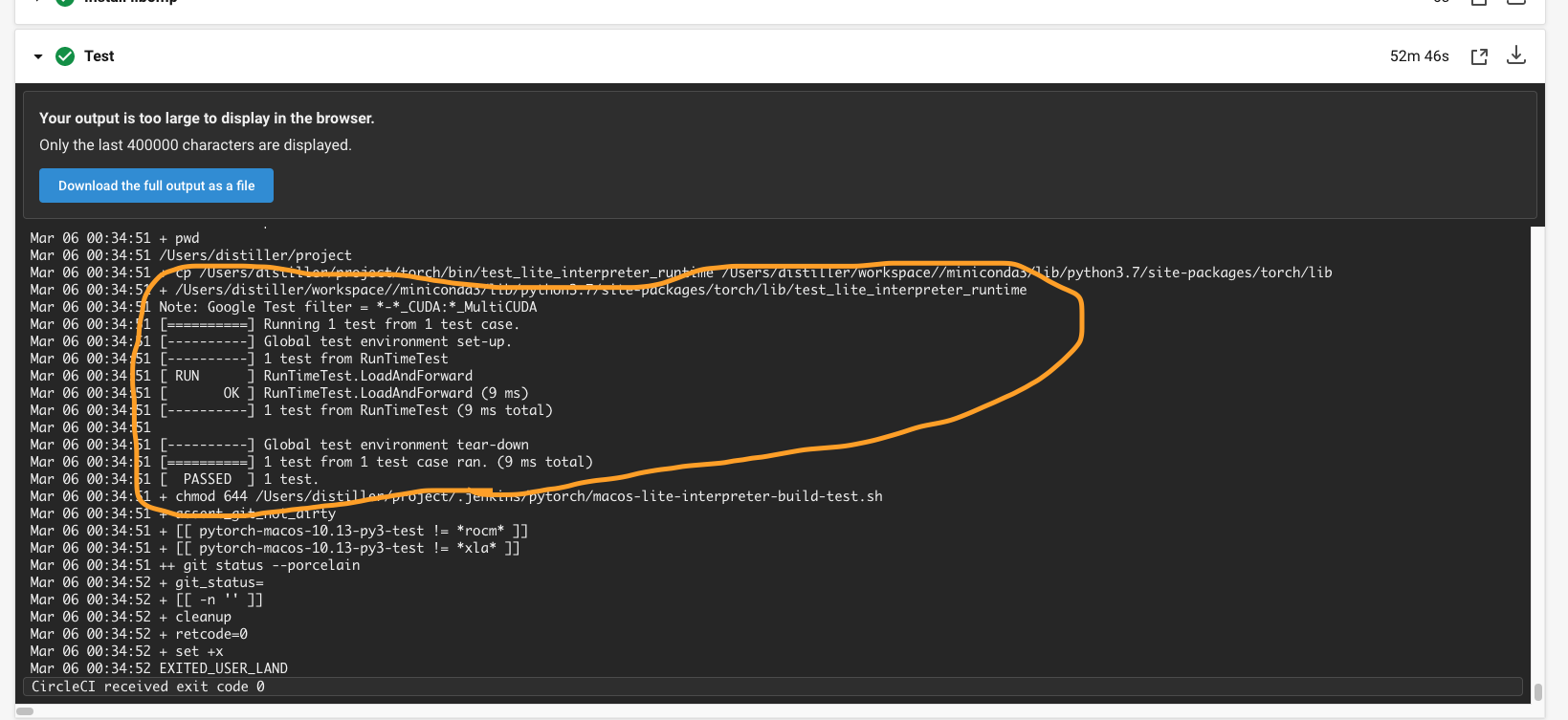 {F467164144} Pull Request resolved: https://github.com/pytorch/pytorch/pull/52566 Test Plan: Imported from OSS Reviewed By: malfet Differential Revision: D26601585 Pulled By: cccclai fbshipit-source-id: da7f47c906317ab3a4ef38fe2dbf2e89bc5bdb24 |
||
|
|
14f7bf0629 |
[PyTorch] update CMake to build libtorch lite (#51419)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/51419 ## Summary 1. Add an option `BUILD_LITE_INTERPRETER` in `caffe2/CMakeLists.txt` and set `OFF` as default. 2. Update 'build_android.sh' with an argument to swtich `BUILD_LITE_INTERPRETER`, 'OFF' as default. 3. Add a mini demo app `lite_interpreter_demo` linked with `libtorch` library, which can be used for quick test. ## Test Plan Built lite interpreter version of libtorch and test with Image Segmentation demo app ([android version](https://github.com/pytorch/android-demo-app/tree/master/ImageSegmentation)/[ios version](https://github.com/pytorch/ios-demo-app/tree/master/ImageSegmentation)) ### Android 1. **Prepare model**: Prepare the lite interpreter version of model by run the script below to generate the scripted model `deeplabv3_scripted.pt` and `deeplabv3_scripted.ptl` ``` import torch model = torch.hub.load('pytorch/vision:v0.7.0', 'deeplabv3_resnet50', pretrained=True) model.eval() scripted_module = torch.jit.script(model) # Export full jit version model (not compatible lite interpreter), leave it here for comparison scripted_module.save("deeplabv3_scripted.pt") # Export lite interpreter version model (compatible with lite interpreter) scripted_module._save_for_lite_interpreter("deeplabv3_scripted.ptl") ``` 2. **Build libtorch lite for android**: Build libtorch for android for all 4 android abis (armeabi-v7a, arm64-v8a, x86, x86_64) `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh`. This pr is tested on Pixel 4 emulator with x86, so use cmd `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` to specify abi to save built time. After the build finish, it will show the library path: ``` ... BUILD SUCCESSFUL in 55s 134 actionable tasks: 22 executed, 112 up-to-date + find /Users/chenlai/pytorch/android -type f -name '*aar' + xargs ls -lah -rw-r--r-- 1 chenlai staff 13M Feb 11 11:48 /Users/chenlai/pytorch/android/pytorch_android/build/outputs/aar/pytorch_android-release.aar -rw-r--r-- 1 chenlai staff 36K Feb 9 16:45 /Users/chenlai/pytorch/android/pytorch_android_torchvision/build/outputs/aar/pytorch_android_torchvision-release.aar ``` 3. **Use the PyTorch Android libraries built from source in the ImageSegmentation app**: Create a folder 'libs' in the path, the path from repository root will be `ImageSegmentation/app/libs`. Copy `pytorch_android-release` to the path `ImageSegmentation/app/libs/pytorch_android-release.aar`. Copy 'pytorch_android_torchvision` (downloaded from [here](https://oss.sonatype.org/#nexus-search;quick~torchvision_android)) to the path `ImageSegmentation/app/libs/pytorch_android_torchvision.aar` Update the `dependencies` part of `ImageSegmentation/app/build.gradle` to ``` dependencies { implementation 'androidx.appcompat:appcompat:1.2.0' implementation 'androidx.constraintlayout:constraintlayout:2.0.2' testImplementation 'junit:junit:4.12' androidTestImplementation 'androidx.test.ext:junit:1.1.2' androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0' implementation(name:'pytorch_android-release', ext:'aar') implementation(name:'pytorch_android_torchvision', ext:'aar') implementation 'com.android.support:appcompat-v7:28.0.0' implementation 'com.facebook.fbjni:fbjni-java-only:0.0.3' } ``` Update `allprojects` part in `ImageSegmentation/build.gradle` to ``` allprojects { repositories { google() jcenter() flatDir { dirs 'libs' } } } ``` 4. **Update model loader api**: Update `ImageSegmentation/app/src/main/java/org/pytorch/imagesegmentation/MainActivity.java` by 4.1 Add new import: `import org.pytorch.LiteModuleLoader;` 4.2 Replace the way to load pytorch lite model ``` // mModule = Module.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.pt")); mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.ptl")); ``` 5. **Test app**: Build and run the ImageSegmentation app in Android Studio,  ### iOS 1. **Prepare model**: Same as Android. 2. **Build libtorch lite for ios** `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR BUILD_LITE_INTERPRETER=1 ./scripts/build_ios.sh` 3. **Remove Cocoapods from the project**: run `pod deintegrate` 4. **Link ImageSegmentation demo app with the custom built library**: Open your project in XCode, go to your project Target’s **Build Phases - Link Binaries With Libraries**, click the **+** sign and add all the library files located in `build_ios/install/lib`. Navigate to the project **Build Settings**, set the value **Header Search Paths** to `build_ios/install/include` and **Library Search Paths** to `build_ios/install/lib`. In the build settings, search for **other linker flags**. Add a custom linker flag below ``` -all_load ``` Finally, disable bitcode for your target by selecting the Build Settings, searching for Enable Bitcode, and set the value to No. ** 5. Update library and api** 5.1 Update `TorchModule.mm`` To use the custom built libraries the project, replace `#import <LibTorch/LibTorch.h>` (in `TorchModule.mm`) which is needed when using LibTorch via Cocoapods with the code below: ``` //#import <LibTorch/LibTorch.h> #include "ATen/ATen.h" #include "caffe2/core/timer.h" #include "caffe2/utils/string_utils.h" #include "torch/csrc/autograd/grad_mode.h" #include "torch/script.h" #include <torch/csrc/jit/mobile/function.h> #include <torch/csrc/jit/mobile/import.h> #include <torch/csrc/jit/mobile/interpreter.h> #include <torch/csrc/jit/mobile/module.h> #include <torch/csrc/jit/mobile/observer.h> ``` 5.2 Update `ViewController.swift` ``` // if let filePath = Bundle.main.path(forResource: // "deeplabv3_scripted", ofType: "pt"), // let module = TorchModule(fileAtPath: filePath) { // return module // } else { // fatalError("Can't find the model file!") // } if let filePath = Bundle.main.path(forResource: "deeplabv3_scripted", ofType: "ptl"), let module = TorchModule(fileAtPath: filePath) { return module } else { fatalError("Can't find the model file!") } ``` ### Unit test Add `test/cpp/lite_interpreter`, with one unit test `test_cores.cpp` and a light model `sequence.ptl` to test `_load_for_mobile()`, `bc.find_method()` and `bc.forward()` functions. ### Size: **With the change:** Android: x86: `pytorch_android-release.aar` (**13.8 MB**) IOS: `pytorch/build_ios/install/lib` (lib: **66 MB**): ``` (base) chenlai@chenlai-mp lib % ls -lh total 135016 -rw-r--r-- 1 chenlai staff 3.3M Feb 15 20:45 libXNNPACK.a -rw-r--r-- 1 chenlai staff 965K Feb 15 20:45 libc10.a -rw-r--r-- 1 chenlai staff 4.6K Feb 15 20:45 libclog.a -rw-r--r-- 1 chenlai staff 42K Feb 15 20:45 libcpuinfo.a -rw-r--r-- 1 chenlai staff 39K Feb 15 20:45 libcpuinfo_internals.a -rw-r--r-- 1 chenlai staff 1.5M Feb 15 20:45 libeigen_blas.a -rw-r--r-- 1 chenlai staff 148K Feb 15 20:45 libfmt.a -rw-r--r-- 1 chenlai staff 44K Feb 15 20:45 libpthreadpool.a -rw-r--r-- 1 chenlai staff 166K Feb 15 20:45 libpytorch_qnnpack.a -rw-r--r-- 1 chenlai staff 384B Feb 15 21:19 libtorch.a -rw-r--r-- 1 chenlai staff **60M** Feb 15 20:47 libtorch_cpu.a ``` `pytorch/build_ios/install`: ``` (base) chenlai@chenlai-mp install % du -sh * 14M include 66M lib 2.8M share ``` **Master (baseline):** Android: x86: `pytorch_android-release.aar` (**16.2 MB**) IOS: `pytorch/build_ios/install/lib` (lib: **84 MB**): ``` (base) chenlai@chenlai-mp lib % ls -lh total 172032 -rw-r--r-- 1 chenlai staff 3.3M Feb 17 22:18 libXNNPACK.a -rw-r--r-- 1 chenlai staff 969K Feb 17 22:18 libc10.a -rw-r--r-- 1 chenlai staff 4.6K Feb 17 22:18 libclog.a -rw-r--r-- 1 chenlai staff 42K Feb 17 22:18 libcpuinfo.a -rw-r--r-- 1 chenlai staff 1.5M Feb 17 22:18 libeigen_blas.a -rw-r--r-- 1 chenlai staff 44K Feb 17 22:18 libpthreadpool.a -rw-r--r-- 1 chenlai staff 166K Feb 17 22:18 libpytorch_qnnpack.a -rw-r--r-- 1 chenlai staff 384B Feb 17 22:19 libtorch.a -rw-r--r-- 1 chenlai staff 78M Feb 17 22:19 libtorch_cpu.a ``` `pytorch/build_ios/install`: ``` (base) chenlai@chenlai-mp install % du -sh * 14M include 84M lib 2.8M share ``` Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D26518778 Pulled By: cccclai fbshipit-source-id: 4503ffa1f150ecc309ed39fb0549e8bd046a3f9c |
{kind=link}
{kind=link}
{kind=link}
{kind=link}