Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56094
Now FunctionCalls are merged with Loads and vectorization for
intermediate values automatically started to work.
Fixes#53553.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27781519
Pulled By: ZolotukhinM
fbshipit-source-id: 1ed68ca2399e9bd4598639bd6dd8f369365f0ef0
Summary:
This PR adds a `padding_idx` parameter to `nn.EmbeddingBag` and `nn.functional.embedding_bag`. As with `nn.Embedding`'s `padding_idx` argument, if an embedding's index is equal to `padding_idx` it is ignored, so it is not included in the reduction.
This PR does not add support for `padding_idx` for quantized or ONNX `EmbeddingBag` for opset10/11 (opset9 is supported). In these cases, an error is thrown if `padding_idx` is provided.
Fixes https://github.com/pytorch/pytorch/issues/3194
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49237
Reviewed By: walterddr, VitalyFedyunin
Differential Revision: D26948258
Pulled By: jbschlosser
fbshipit-source-id: 3ca672f7e768941f3261ab405fc7597c97ce3dfc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55621
Fuser support for thread-level parallelism is a work in progress, so
only fuse when the program is running single-threaded.
ghstack-source-id: 126069259
Test Plan: observe fusion groups formed when torch.get_num_threads==1 vs not
Reviewed By: ZolotukhinM
Differential Revision: D27652485
fbshipit-source-id: 182580cf758d99dd499cc4591eb9d080884aa7ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55825
The mask has never been used (in vectorization we generate an explicit
`IfThenElse` construct when we need to mask out some elements). The PR
removes it and cleans up all its traces from tests.
Differential Revision: D27717776
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 41d1feeea4322da75b3999d661801c2a7f82b9db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55324
With this change `rfactor` only affects the passed loop and its body
never touching anything outside (that was a rootcause of a bug with the
previous implementation). Also, we don't have an `insertion_point`
parameter anymore - its meaning was vague, and the effect of it
should've been achievable with other transformations anyway.
The new `rfactor` semantics is as follows:
```
Requirements:
* S is the reduction store
* S is the only statement in the innermost loop
* There is at least two reduction arguments in S
* OUTER_REDUCTION_FOR loop corresponds to the outermost reduction variable
used in the store and all other reduction variables are index variables of
children loops of OUTER_REDUCTION_FOR
* OUTER_REDUCTION_FOR is a perfect loop nest, i.e. it has only loops
corresponding to the other reduction variables and the store, nested into
each other
What it does:
* Introduce a new buffer with an extra dimension of a size equal to the
span of the loop OUTER_REDUCTION_FOR (the new buffer is returned via
RFAC_BUF_PTR)
* Insert an initialization store for the new buffer in
OUTER_REDUCTION_FOR before its nested loop
* Replace the reduction store to the original buffer with the reduction
store to the temp buffer, removing the index var of OUTER_REDUCTION_FOR
from reduction arguments
* Insert a final reduction store over the extra dimension of the new
buffer to the original buffer
* Returns TRUE if the transformation succeeded and FALSE otherwise
Example:
Original IR:
S1: for i # normal axis
S2: X[i] = 0
S3: for j # reduction axis
S4: for k # reduction axis
S5: X[i] = ReduceOp(X[i] + Y[i,j,k], reduce_axis={j,k})
After RFACTOR(S5, S3)
S1: for i # normal axis
S2: X[i] = 0
S3: for j # reduction axis for X, normal axis for X_rfac
X_rfac[i,j] = 0
S4: for k # reduction axis
X_rfac[i,j] = ReduceOp(X_rfac[i,j] + Y[i,j,k], reduce_axis={k})
X[i] = ReduceOp(X[i] + X_rfac[i,j], reduce_axis={j})
```
Differential Revision: D27694960
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 076fa6a1df2c23f5948302aa6b43e82cb222901c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52690
This PR adds the following APIs:
```
static bool areLoopsPerfectlyNested(const std::vector<For*>& loops);
static std::vector<For*> reorder(
const std::vector<For*>& loops,
const std::vector<size_t>& permutation);
```
The first API checks if the given list of loops are perfectly nested. The second API reorders the given list of loops according to the permutation specified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55568
Reviewed By: albanD
Differential Revision: D27689734
Pulled By: navahgar
fbshipit-source-id: dc1bffdbee068c3f401188035772b41847cbc7c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54403
A few important points about InferenceMode behavior:
1. All tensors created in InferenceMode are inference tensors except for view ops.
- view ops produce output has the same is_inference_tensor property as their input.
Namely view of normal tensor inside InferenceMode produce a normal tensor, which is
exactly the same as creating a view inside NoGradMode. And view of
inference tensor outside InferenceMode produce inference tensor as output.
2. All ops are allowed inside InferenceMode, faster than normal mode.
3. Inference tensor cannot be saved for backward.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27316483
Pulled By: ailzhang
fbshipit-source-id: e03248a66d42e2d43cfe7ccb61e49cc4afb2923b
Summary:
Switched to short forms of `splitWithTail` / `splitWithMask` for all tests in `test/cpp/tensorexpr/test_*.cpp` (except test_loopnest.cpp)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55542
Reviewed By: mrshenli
Differential Revision: D27632033
Pulled By: jbschlosser
fbshipit-source-id: dc2ba134f99bff8951ae61e564cd1daea92c41df
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/55203
Fixes issues (1) and (2) in the following tests:
tests in test/cpp/tensorexpr/test_loopnest.cpp from the beginning to LoopNestReorderLongStringFull (including)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55512
Reviewed By: mrshenli
Differential Revision: D27630679
Pulled By: soulitzer
fbshipit-source-id: b581aaea4f5f54b3285f0348aa76e99779418f80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55497
Migrating some of the NNC API's used in testing, from this issue: https://github.com/pytorch/pytorch/issues/55203
I covered the second half of `test_loopnest.cpp`, and migrated (1) and (2) in the above issue: `LoopNest::getLoopStmtsFor`, `splitWithTail`, and `splitWithMask`
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27628625
Pulled By: bdhirsh
fbshipit-source-id: ec15efba45fae0bbb442ac3577fb9ca2f8023c2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55012
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54442
Added needsOutputs support to RecordFunction, improved ObserverUtil functions to handle list data. Minor refactor names to be consistent.
To get output data from kernel calls, we need to temporarily capture them before passing them to the record function. Then the results are released to function return. We handle two cases, for unboxed and boxed kernels. The boxed version is fairly simple since all outputs are stored in the stack object. For unboxed kernel calls, we added a `ReturnValue` utility class to properly handle the different return values of unboxed kernels.
For optimization, this intermediate capture is only enabled for observers that request `needsOutputs(true)` and should not affect other observers or when the observer is not enabled.
Test Plan:
```
=> buck build //caffe2/test/cpp/jit: --show-output
=> buck-out/gen/caffe2/test/cpp/jit/jit --gtest_filter=RecordFunctionTest*
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = RecordFunctionTest*-*_CUDA:*_MultiCUDA
[==========] Running 7 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 7 tests from RecordFunctionTest
[ RUN ] RecordFunctionTest.TracedTestInputsOutputs
[ OK ] RecordFunctionTest.TracedTestInputsOutputs (226 ms)
[ RUN ] RecordFunctionTest.SampledCallbacks
[ OK ] RecordFunctionTest.SampledCallbacks (771 ms)
[ RUN ] RecordFunctionTest.RecordFunctionGuard
[ OK ] RecordFunctionTest.RecordFunctionGuard (0 ms)
[ RUN ] RecordFunctionTest.Callbacks
[ OK ] RecordFunctionTest.Callbacks (2 ms)
[ RUN ] RecordFunctionTest.ShouldRun
[ OK ] RecordFunctionTest.ShouldRun (0 ms)
[ RUN ] RecordFunctionTest.Basic
[ OK ] RecordFunctionTest.Basic (1 ms)
[ RUN ] RecordFunctionTest.OperatorNameOverload
[ OK ] RecordFunctionTest.OperatorNameOverload (1 ms)
[----------] 7 tests from RecordFunctionTest (1001 ms total)
[----------] Global test environment tear-down
[==========] 7 tests from 1 test case ran. (1002 ms total)
[ PASSED ] 7 tests.
```
Reviewed By: ilia-cher
Differential Revision: D27449877
fbshipit-source-id: 69918b729565f5899471d9db42a587f9af52238d
Summary:
Non-backwards-compatible change introduced in https://github.com/pytorch/pytorch/pull/53843 is tripping up a lot of code. Better to set it to False initially and then potentially flip to True in the later version to give people time to adapt.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55169
Reviewed By: mruberry
Differential Revision: D27511150
Pulled By: jbschlosser
fbshipit-source-id: 1ac018557c0900b31995c29f04aea060a27bc525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54998
The only reason why we couldn't use Load instead of FunctionCall was
DepTracker. Now this is gone and we finally could replace FunctionCall
with Load.
Test Plan: Imported from OSS
Reviewed By: bertmaher, pbelevich
Differential Revision: D27446412
Pulled By: ZolotukhinM
fbshipit-source-id: 9183ae5541c2618abc9026b1dc4c4c9fab085d47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54997
DepTracker was used to automatically pull in dependent computations from
output ones. While it seems quite convenient, it's led to several
architectural issues, which are fixed in this stack.
DepTracker worked on Tensors, which is a pair of Buf and Stmt. However,
Stmt could become stale and there was no way to reliably update the
corresponding tensor. We're now using Bufs and Stmts directly and moving
away from using Tensors to avoid these problems.
Removing DepTracker allowed to unify Loads and FunctionCalls, which
essentially were duplicates of each other.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27446414
Pulled By: ZolotukhinM
fbshipit-source-id: a2a32749d5b28beed92a601da33d126c0a2cf399
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55136
This will ease the transition to the new API where `Buffer` does not
store a length anymore.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27466385
fbshipit-source-id: 9a167f8c501455a3ab49ce75257c69d8b4869925
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54633
Theres currently no information that could be used to determine what is a parameter during the loading of a mobile module. This prevents named parameters from functioning correctly. This change is a temporary hack to help out federated learning the sole user of this api currently.
ghstack-source-id: 124885201
Test Plan: todo
Reviewed By: dhruvbird
Differential Revision: D27308738
fbshipit-source-id: 0af5d1e8381ab7b7a43b20560941aa070a02e7b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54442
Added needsOutputs support to RecordFunction, improved ObserverUtil functions to handle list data. Minor refactor names to be consistent.
To get output data from kernel calls, we need to temporarily capture them before passing them to the record function. Then the results are released to function return. We handle two cases, for unboxed and boxed kernels. The boxed version is fairly simple since all outputs are stored in the stack object. For unboxed kernel calls, we added a `ReturnValue` utility class to properly handle the different return values of unboxed kernels.
For optimization, this intermediate capture is only enabled for observers that request `needsOutputs(true)` and should not affect other observers or when the observer is not enabled.
Test Plan:
```
=> buck build //caffe2/test/cpp/jit: --show-output
=> buck-out/gen/caffe2/test/cpp/jit/jit --gtest_filter=RecordFunctionTest*
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = RecordFunctionTest*-*_CUDA:*_MultiCUDA
[==========] Running 7 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 7 tests from RecordFunctionTest
[ RUN ] RecordFunctionTest.TracedTestInputsOutputs
[ OK ] RecordFunctionTest.TracedTestInputsOutputs (226 ms)
[ RUN ] RecordFunctionTest.SampledCallbacks
[ OK ] RecordFunctionTest.SampledCallbacks (771 ms)
[ RUN ] RecordFunctionTest.RecordFunctionGuard
[ OK ] RecordFunctionTest.RecordFunctionGuard (0 ms)
[ RUN ] RecordFunctionTest.Callbacks
[ OK ] RecordFunctionTest.Callbacks (2 ms)
[ RUN ] RecordFunctionTest.ShouldRun
[ OK ] RecordFunctionTest.ShouldRun (0 ms)
[ RUN ] RecordFunctionTest.Basic
[ OK ] RecordFunctionTest.Basic (1 ms)
[ RUN ] RecordFunctionTest.OperatorNameOverload
[ OK ] RecordFunctionTest.OperatorNameOverload (1 ms)
[----------] 7 tests from RecordFunctionTest (1001 ms total)
[----------] Global test environment tear-down
[==========] 7 tests from 1 test case ran. (1002 ms total)
[ PASSED ] 7 tests.
```
Reviewed By: ilia-cher
Differential Revision: D25966661
fbshipit-source-id: 707886e1f212f40ba16a1fe292ea7dd33f2646e3
Summary:
*Context:* https://github.com/pytorch/pytorch/issues/53406 added a lint for trailing whitespace at the ends of lines. However, in order to pass FB-internal lints, that PR also had to normalize the trailing newlines in four of the files it touched. This PR adds an OSS lint to normalize trailing newlines.
The changes to the following files (made in 54847d0adb9be71be4979cead3d9d4c02160e4cd) are the only manually-written parts of this PR:
- `.github/workflows/lint.yml`
- `mypy-strict.ini`
- `tools/README.md`
- `tools/test/test_trailing_newlines.py`
- `tools/trailing_newlines.py`
I would have liked to make this just a shell one-liner like the other three similar lints, but nothing I could find quite fit the bill. Specifically, all the answers I tried from the following Stack Overflow questions were far too slow (at least a minute and a half to run on this entire repository):
- [How to detect file ends in newline?](https://stackoverflow.com/q/38746)
- [How do I find files that do not end with a newline/linefeed?](https://stackoverflow.com/q/4631068)
- [How to list all files in the Git index without newline at end of file](https://stackoverflow.com/q/27624800)
- [Linux - check if there is an empty line at the end of a file [duplicate]](https://stackoverflow.com/q/34943632)
- [git ensure newline at end of each file](https://stackoverflow.com/q/57770972)
To avoid giving false positives during the few days after this PR is merged, we should probably only merge it after https://github.com/pytorch/pytorch/issues/54967.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54737
Test Plan:
Running the shell script from the "Ensure correct trailing newlines" step in the `quick-checks` job of `.github/workflows/lint.yml` should print no output and exit in a fraction of a second with a status of 0. That was not the case prior to this PR, as shown by this failing GHA workflow run on an earlier draft of this PR:
- https://github.com/pytorch/pytorch/runs/2197446987?check_suite_focus=true
In contrast, this run (after correcting the trailing newlines in this PR) succeeded:
- https://github.com/pytorch/pytorch/pull/54737/checks?check_run_id=2197553241
To unit-test `tools/trailing_newlines.py` itself (this is run as part of our "Test tools" GitHub Actions workflow):
```
python tools/test/test_trailing_newlines.py
```
Reviewed By: malfet
Differential Revision: D27409736
Pulled By: samestep
fbshipit-source-id: 46f565227046b39f68349bbd5633105b2d2e9b19
Summary:
**BC-breaking note**: This change throws errors for cases that used to silently pass. The old behavior can be obtained by setting `error_if_nonfinite=False`
Fixes https://github.com/pytorch/pytorch/issues/46849
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53843
Reviewed By: malfet
Differential Revision: D27291838
Pulled By: jbschlosser
fbshipit-source-id: 216d191b26e1b5919a44a3af5cde6f35baf825c4
Summary:
I added a helper to convert a Stmt to string and FileCheck it, so
started using it in a bunch of places. I replaced about half the current uses,
got tired, started to write a Perl script to automate it, realized that was
hard, and decided to give up for a bit. But this cleans up some of the tests a
bit, so seems easy to review and worth landing.
Test Plan: test_tensorexpr --gtest_filter=LoopNest.*
Reviewed By: navahgar
Differential Revision: D27375866
fbshipit-source-id: 15894b9089dec5cf25f340fe17e6e54546a64257
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54756
We have multiple bugs here, one relating to index flattening and the
other to computeAt.
ghstack-source-id: 125054729
Test Plan: yikes
Reviewed By: ZolotukhinM
Differential Revision: D27354082
fbshipit-source-id: 8b15bac28e3eba4629881ae0f3bd143636f65ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54755
As title. A step on the way to using computeAt to optimize
convolution.
ghstack-source-id: 125054730
Test Plan: new test
Reviewed By: ZolotukhinM
Differential Revision: D27353663
fbshipit-source-id: 930e09d96d1f74169bf148cd30fc195c6759a3e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53953
torch.futures.wait_all, would wait for all specified futures to
complete before it returned. As a result, if there was an error it would still
wait for a long time (ex: long running RPCs) before it returned an error to the
user.
This PR ensures `wait_all` returns and error as soon as any future runs into an
error and doesn't wait for all futures to complete.
I removed the logic _invoke_rpc_python_udf which raised an error in the unwrap
function, because ideally the error should be set on the Future and not be
raised to the user only when `wait()` is called. As an example, in the case of
`wait_all`, the user never calls `wait()` on the future that errored out but a
future down the chain and we should propagate these errors via `setError`
instead.
ghstack-source-id: 124721216
Test Plan:
1) Unit test added.
2) waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D27032362
fbshipit-source-id: c719e2277c27ff3d45f1511d5dc6f1f71a03e3a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54439
For now the only way to represent conv2d in TE is via an external call,
and since aten library doesn't have an out variant for conv2d, the
external call has to perform an extra copy. Because of that fusing
conv2d now regressed performance and hence is disabled. However, in near
future we should have two alternative ways to enable it:
1) represent conv2d natively in TE (without an external call)
2) add an out variant for conv2d
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27237045
Pulled By: ZolotukhinM
fbshipit-source-id: f5545ff711b75f9f37bc056316d1999a70043b4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54579
## Summary
1. Eliminate a few more tests when BUILD_LITE_INTERPRETER is on, such that test_lite_interpreter_runtime can build and run on device.
2. Remove `#include <torch/torch.h>`, because it's not needed.
## Test plan
Set the BUILD_TEST=ON `in build_android.sh`, then run
` BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86`
push binary to android device:
```
adb push ./build_android_x86/bin/test_lite_interpreter_runtime /data/local/tmp
```
Reorganize the folder in `/data/local/tmp` so the test binary and model file is like following:
```
/data/local/tmp/test_bin/test_lite_interpreter_runtime
/data/local/tmp/test/cpp/lite_interpreter_runtime/sequence.ptl
```
such that the model file is in the correct path and can be found by the test_lite_interpreter_runtime.
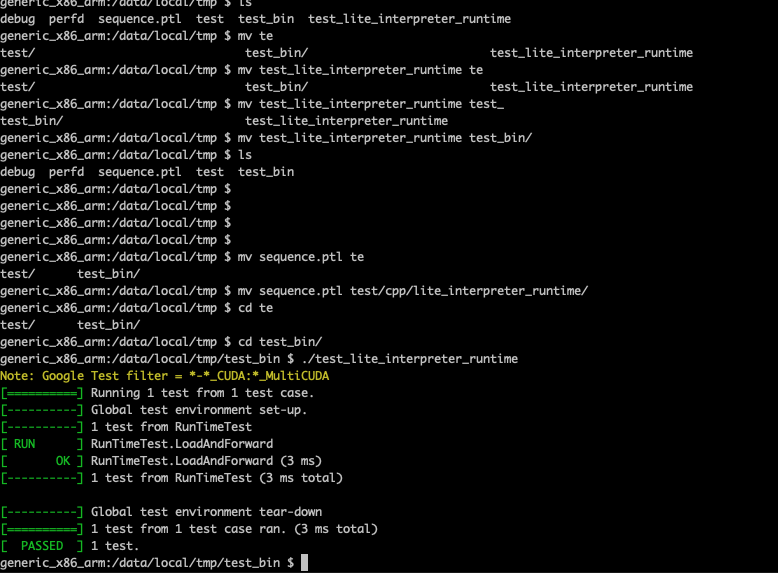
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27300720
Pulled By: cccclai
fbshipit-source-id: d9526c7d3db8c0d3e76c5a4d604c6877c78afdf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52881
**This PR adds:**
1. logic to parse complex constants (complex literals of the form `bj`)
2. logic to parse complex lists
3. support for complex constructors: `complex(tensor/int/float/bool, tensor/int/float/bool)`
4. Limited operator support
- `add`, `sub`, `mul`, `torch.tensor`, `torch.as_tensor`
**Follow-up work:**
1. Add complex support for unary and other registered ops.
2. support complex constructor with string as input (this is supported in Python eager mode).
3. Test all emitXYZ for all XYZ in `ir_emitter.cpp` (currently only emitConst, emitValueToTensor are tested). e.g., test loops etc.
4. onnx doesn't support complex tensors, so we should error out with a clear and descriptive error message.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27245059
Pulled By: anjali411
fbshipit-source-id: af043b5159ae99a9cc8691b5a8401503fa8d6f05
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54337
This PR adds a new API to NNC to perform loop fusion.
```
static For* fuseLoops(const std::vector<For*>& loops);
```
Loop fusion is done only when all the conditions below are satisfied.
* All the loops have the same parent.
* There are no statements between these loops in their parent body.
* The start bounds are the same for all loops.
* The stop bounds are the same for all loops.
* Fusing the loops does not violate or add any dependencies.
This PR also adds an API to check for partial overlaps in `buffer_inference.h` and fixes a bug in `mem_dependency_checker.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54461
Reviewed By: bertmaher
Differential Revision: D27254888
Pulled By: navahgar
fbshipit-source-id: c21b027d738e5022e9cb88f6f72cd9e255bdb15e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54251
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/324
In order to merge the channel hierarchies, we need a generic `Buffer` type, that can wrap either a `CpuBuffer` or a `CudaBuffer`.
The constraints are that, since this type is used by the channels, it cannot explicitly refer to `CudaBuffer`. We propose here a type-erasure based solution, with small-buffer optimization to avoid heap-allocating the wrapped concrete buffer.
This is a new version of D27001339 (c618dc13d2) which broke PyTorch OSS build.
Test Plan: CI
Reviewed By: lw, mrshenli
Differential Revision: D27156053
fbshipit-source-id: 4244302af33a3be91dcd06093c0d6045d081d3cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45667
First part of #3867 (Pooling operators still to do)
This adds a `padding='same'` mode to the interface of `conv{n}d`and `nn.Conv{n}d`. This should match the behaviour of `tensorflow`. I couldn't find it explicitly documented but through experimentation I found `tensorflow` returns the shape `ceil(len/stride)` and always adds any extra asymmetric padding onto the right side of the input.
Since the `native_functions.yaml` schema doesn't seem to support strings or enums, I've moved the function interface into python and it now dispatches between the numerically padded `conv{n}d` and the `_conv{n}d_same` variant. Underscores because I couldn't see any way to avoid exporting a function into the `torch` namespace.
A note on asymmetric padding. The total padding required can be odd if both the kernel-length is even and the dilation is odd. mkldnn has native support for asymmetric padding, so there is no overhead there, but for other backends I resort to padding the input tensor by 1 on the right hand side to make the remaining padding symmetrical. In these cases, I use `TORCH_WARN_ONCE` to notify the user of the performance implications.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D27170744
Pulled By: jbschlosser
fbshipit-source-id: b3d8a0380e0787ae781f2e5d8ee365a7bfd49f22
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53864
This PR adds the following APIs that perform loop distribution to `LoopNest`:
```
static std::vector<For*> distributeLoop(For* loop, const std::unordered_set<Stmt*>& pivots);
static std::vector<For*> distributeLoop(For* loop);
static std::vector<For*> distributeLoopOverInnerLoops(For* loop);
```
* The first method distributes the given loop over its body by splitting after every given pivot stmt.
* The second method distributes the given loop over every stmt in its body.
* The last method distributes the given loop over its body by splitting after every `For` stmt in its body.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53865
Reviewed By: mruberry
Differential Revision: D27075006
Pulled By: navahgar
fbshipit-source-id: 031746aad619fe84c109e78b53387535e7f77cef
Summary:
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/322
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54145
In order to merge the channel hierarchies, we need a generic `Buffer` type, that can wrap either a `CpuBuffer` or a `CudaBuffer`.
The constraints are that, since this type is used by the channels, it cannot explicitly refer to `CudaBuffer`. We propose here a type-erasure based solution, with small-buffer optimization to avoid heap-allocating the wrapped concrete buffer.
ghstack-source-id: 124131499
Test Plan: CI
Reviewed By: lw
Differential Revision: D27001339
fbshipit-source-id: 26d7dc19d69d7e3336df6fd4ff6ec118dc17c5b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53662
Add a base processgroup::options so that we can do inheritance and
provide
a universal option API in python
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D26968856
Pulled By: wanchaol
fbshipit-source-id: 858f4b61b27aecb1943959bba68f8c14114f67d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54121
It would be nice to do range analysis to determine if a condition
cannot be satisfied. These are some tests that we should be able to turn on
once we have this feature.
ghstack-source-id: 124116847
Test Plan: Simplify.*LoopBounds
Reviewed By: ZolotukhinM
Differential Revision: D27107956
fbshipit-source-id: bb27e3d3bc803f0101c416e4a351ba2278684980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54094
We should be able to use 64-bit integers for loop boundaries and
buffer/tensor indexing.
ghstack-source-id: 124116846
Test Plan: New tests, disabled
Reviewed By: ZolotukhinM
Differential Revision: D27094934
fbshipit-source-id: a53de21a0ef523ea3560d5dd4707df50624896ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53677
When serializing bytecode, we serialize it based on methods. It may happen that there are multiple instances of a class. In such a case, the methods inside the class may be serialized multiple times.
To reduce the duplication, we cache the qualified name of the methods, so that one method is serialized only once.
Test Plan: existing unittests and CI
Reviewed By: dhruvbird, raziel
Differential Revision: D26933945
Pulled By: iseeyuan
fbshipit-source-id: 8a9833949fa18f7103a5a0be19e2028040dc7717
{kind=link}