This is the first phase of the new ONNX exporter API for exporting from TorchDynamo and FX, and represents the beginning of a new era for exporting ONNX from PyTorch.
The API here is a starting point upon which we will layer more capability and expressiveness in subsequent phases. This first phase introduces the following into `torch.onnx`:
```python
dynamo_export(
model: torch.nn.Module,
/,
*model_args,
export_options: Optional[ExportOptions] = None,
**model_kwargs,
) -> ExportOutput:
...
class ExportOptions:
opset_version: Optional[int] = None
dynamic_shapes: Optional[bool] = None
logger: Optional[logging.Logger] = None
class ExportOutputSerializer(Protocol):
def serialize(
self,
export_output: ExportOutput,
destination: io.BufferedIOBase,
) -> None:
...
class ExportOutput:
model_proto: onnx.ModelProto
def save(
self,
destination: Union[str, io.BufferedIOBase],
*,
serializer: Optional[ExportOutputSerializer] = None,
) -> None:
...
```
In addition to the API in the first commit on this PR, we have a few experiments for exporting Dynamo and FX to ONNX that this PR rationalizes through the new Exporter API and adjusts tests to use the new API.
- A base `FXGraphModuleExporter` exporter from which all derive:
- `DynamoExportExporter`: uses dynamo.export to acquire FX graph
- `DynamoOptimizeExporter`: uses dynamo.optimize to acquire FX graph
- `FXSymbolicTraceExporter`: uses FX symbolic tracing
The `dynamo_export` API currently uses `DynamoOptimizeExporter`.
### Next Steps (subsequent PRs):
* Combine `DynamoExportExporter` and `DynamoOptimizeExporter` into a single `DynamoExporter`.
* Make it easy to test `FXSymbolicTraceExporter` through the same API; eventually `FXSymbolicTraceExporter` goes away entirely when the Dynamo approach works for large models. We want to keep `FXSymbolicTraceExporter` around for now for experimenting and internal use.
* Parameterize (on `ExportOptions`) and consolidate Dynamo exporter tests.
- This PR intentionally leaves the existing tests unchanged as much as possible except for the necessary plumbing.
* Subsequent API phases:
- Diagnostics
- Registry, dispatcher, and Custom Ops
- Passes
- Dynamic shapes
Fixes#94774
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97920
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi, https://github.com/shubhambhokare1
Fixes https://github.com/pytorch/pytorch/issues/97260
We got some feedback that the page reads like "in order to save an input
for backward, you must return it as an output of the
autograd.Function.forward".
Doing so actually raises an error (on master and as of 2.1), but results
in an ambiguous situation on 2.0.0. To avoid more users running into
this, we clarify the documentation so it doesn't read like the above
and clearly mentions that you can save things from the inputs or
outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98020
Approved by: https://github.com/soulitzer, https://github.com/kshitij12345
Chatted with @stas00 on slack and here are some great improvements he suggested to the compile docs
- [x] Rename `dynamo` folder to `compile`
- [x] Link `compile` docstring on `torch.html` to main index page for compile
- [x] Create a new index page that describes why people should care
- [x] easy perf, memory reduction, 1 line
- [x] Short benchmark table
- [x] How to guide
- [x] TOC that links to the more technical pages folks have written, make the existing docs we have a Technical overview
- [x] Highlight the new APIs for `torch._inductor.list_options()` and `torch._inductor.list_mode_options()` - clarify these are inductor specific and add more prose around which ones are most interesting
He also highlighted an interesting way to think about who is reading this doc we have
- [x] End users, that just want things to run fast
- [x] Library maintainers wrapping torch.compile which would care for example about understanding when in their code they should compile a model, which backends are supported
- [x] Debuggers who needs are somewhat addressed by the troubleshooting guide and faq but those could be dramatically reworked to say what we expect to break
And in a seperate PR I'll work on the below with @SherlockNoMad
- [ ] Authors of new backends that care about how to plug into dynamo or inductor layer so need to explain some more internals like
- [ ] IR
- [ ] Where to plugin, dynamo? inductor? triton?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96706
Approved by: https://github.com/svekars
Fixes#95796
### Implementation
Adds python implementation for `nn.ZeroPad1d` and `nn.ZeroPad3d` in `torch/nn/modules/padding.py`.
Adds cpp implementation for `nn::ZeroPad1d` and `nn::ZeroPad3d` in the following 3 files, refactored with templates similarly to `nn::ConstantPad`'s implementation: <br>
- `torch/crsc/api/include/torch/nn/modules/padding.h`
- `torch/csrc/api/include/torch/nn/options/padding.h`
- `torch/csrc/api/src/nn/modules/padding.cpp`
Also added relevant definitions in `torch/nn/modules/__init__.py`.
### Testing
Adds the following tests:
- cpp tests of similar length and structure as `ConstantPad` and the existing `ZeroPad2d` impl in `test/cpp/api/modules.cpp`
- cpp API parity tests in `torch/testing/_internal/common_nn.py`
- module init tests in `test/test_module_init.py`
Also added relevant definitions in `test/cpp_api_parity/parity-tracker.md`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96295
Approved by: https://github.com/soulitzer
This should be self containable to merge but other stuff that's been bugging me is
* Instructions on debugging IMA issues
* Dynamic shape instructions
* Explaining config options better
Will look at adding a config options doc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95802
Approved by: https://github.com/svekars
Fixed following errors in contribution guide.
"deep neural networks using a **on** tape-based autograd systems." to "deep neural networks **using a tape-based** autograd systems."
"the best entrance **point** and are great places to start." to "the best entrance **points** and are great places to start."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95454
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
Corrected the grammar of a sentence in "Implementing Features or Fixing Bugs" section of the contribution guide.
**Before:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point are great places to start.
**After:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point _and_ are great places to start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93014
Approved by: https://github.com/albanD, https://github.com/kit1980
Fixes#91824
This PR add a new dynamo backend registration mechanism through ``entry_points``. The ``entry_points`` of a package is provides a way for the package to reigster a plugin for another one.
The docs of the new mechanism:
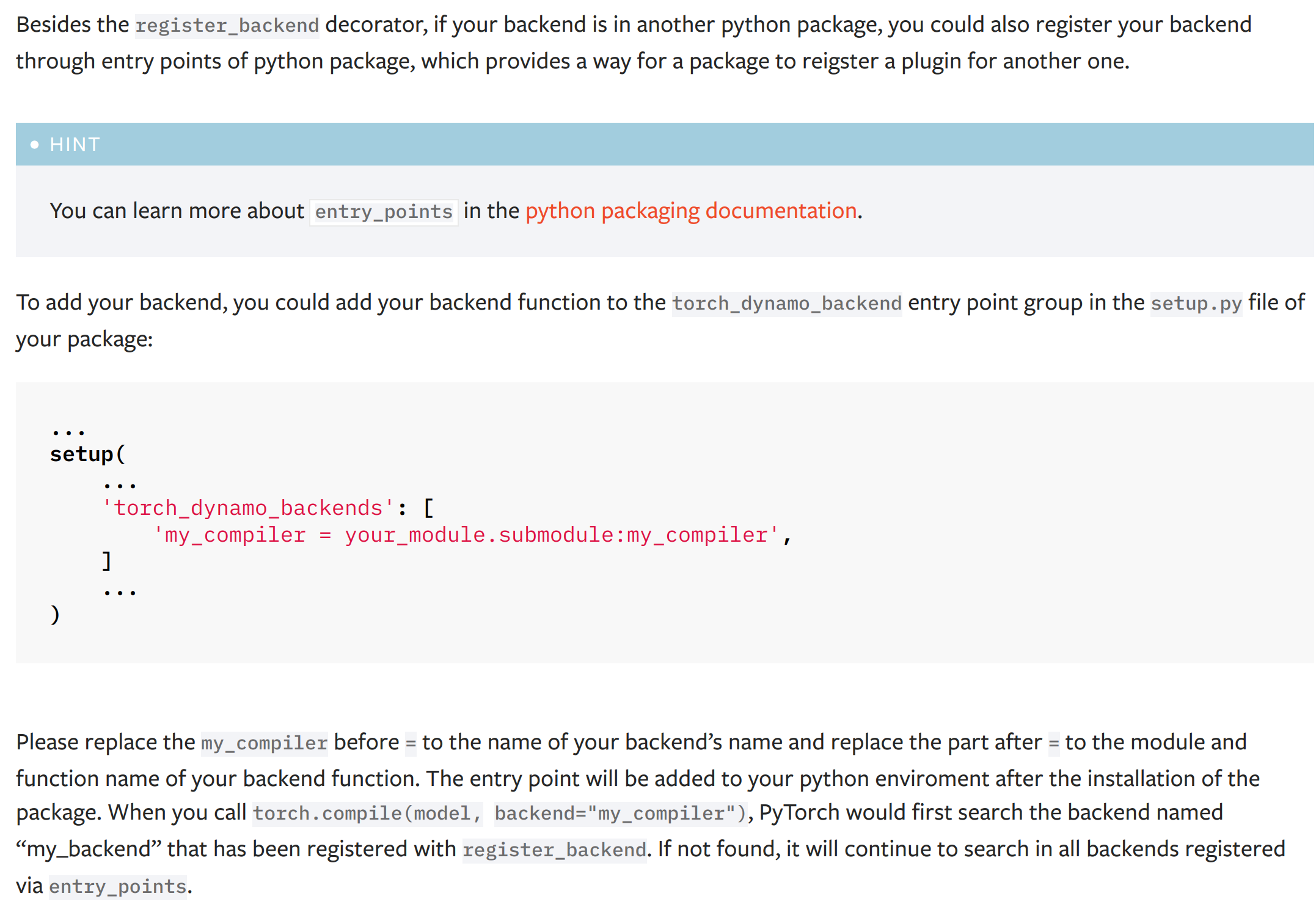
(the typo '...named "my_backend" that has been..." has been fixed to '...named "my_compiler" that has been...')
# Discussion
## About the test
I did not add a test for this PR as it is hard either to install a fack package during a test or manually hack the entry points function by replacing it with a fake one. I have tested this PR offline with the hidet compiler and it works fine. Please let me know if you have any good idea to test this PR.
## About the dependency of ``importlib_metadata``
This PR will add a dependency ``importlib_metadata`` for the python < 3.10 because the modern usage of ``importlib`` gets stable at this python version (see the documentation of the importlib package [here](https://docs.python.org/3/library/importlib.html)). For python < 3.10, the package ``importlib_metadata`` implements the feature of ``importlib``. The current PR will hint the user to install this ``importlib_metata`` if their python version < 3.10.
## About the name and docs
Please let me know how do you think the name ``torch_dynamo_backend`` as the entry point group name and the documentation of this registration mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93873
Approved by: https://github.com/malfet, https://github.com/jansel
- To check for Memory Leaks in `test_mps.py`, set the env-variable `PYTORCH_TEST_MPS_MEM_LEAK_CHECK=1` when running test_mps.py (used CUDA code as reference).
- Added support for the following new python interfaces in MPS module:
`torch.mps.[empty_cache(), set_per_process_memory_fraction(), current_allocated_memory(), driver_allocated_memory()]`
- Renamed `_is_mps_on_macos_13_or_newer()` to `_mps_is_on_macos_13_or_newer()`, and `_is_mps_available()` to `_mps_is_available()` to be consistent in naming with prefix `_mps`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94646
Approved by: https://github.com/malfet
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
# Summary
- Adds type hinting support for SDPA
- Updates the documentation adding warnings and notes on the context manager
- Adds scaled_dot_product_attention to the non-linear activation function section of nn.functional docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94008
Approved by: https://github.com/cpuhrsch
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
{kind=link}
{kind=link}
{kind=link}
{kind=link}