`inspect.getfullargspec` does not properly handle functions/methods wrapped by functools.wraps(). As a result, it gets an empty list of `args` in FullArgSpec.
This PR rewrites the logic using `inspect.signature`, which handles functools.wraps() correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96557
Approved by: https://github.com/jansel
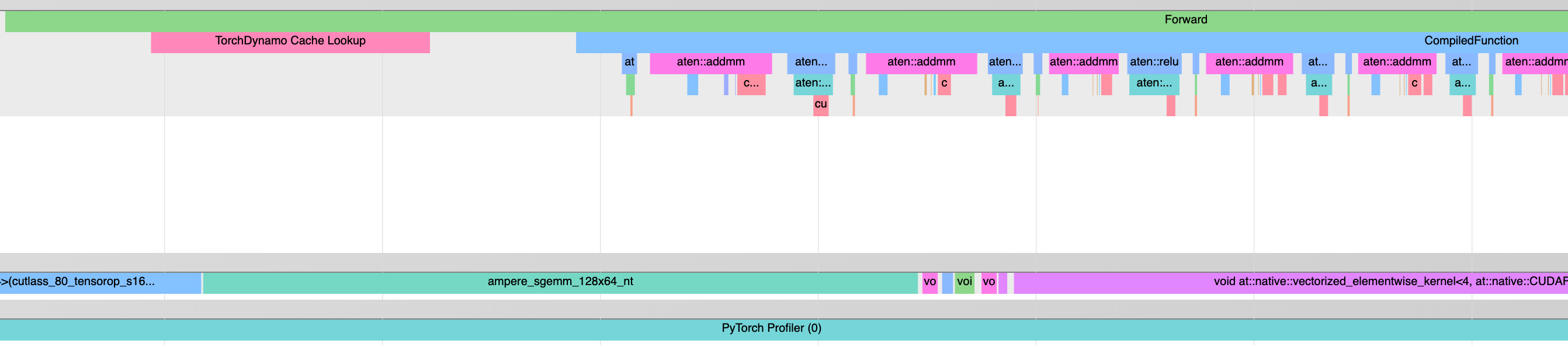
Adds a profiler start and end callback to dynamo's C eval_frame impl, which can be used to profile a region providing a name for visualization. Currently only hooks up one usage to profile cache lookup (primarily covering guards and linear search through linked list).
Example profile taken from toy model:
`python benchmarks/dynamo/distributed.py --toy_model --profile --dynamo aot_eager`
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/4984825/223225931-b2f6c5a7-505a-4c90-9a03-34982f6dc033.png">
Planning to measure overhead in CI, and probably can't afford to check this in enabled by default. Will have to evaluate UX options such as `config.profile_dynamo_cache = True` or some other way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96119
Approved by: https://github.com/jansel
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
This is WIP PR for adding torch.export API in OSS. Couple of points:
- I intentionally named it as experimental_export so that ppl don't get confused thinking this is our official API
- We don't plan to use AOTAutograd backend just yet. The reason we have it here is because the functionalization AOTAutograd uses is what we need for export (handling of param/buffer mutation etc). In the near future, I will extract the functionalization part and use it on top of make_fx. What we have right now is merely a placeholder.
- The reason we want to do it now is because we want to have some minimal tests running in OSS so that we can catch regressions earlier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95070
Approved by: https://github.com/gmagogsfm, https://github.com/zhxchen17
Tweak dynamo behavior in 2 places when calling nn.Modules,
to route the call to __call__ instead of .forward(), since
__call__ is the codepath that eager users hit and will dispatch
to hooks correctly.
(1) inside NNModuleVariable.call_function, which covers the common case
of calling a module from code dynamo is already tracing
(2) at the OptimizedModule layer, which is the entrypoint
into a top-level nn.Module dynamo is about to compile
This exposes a new bug: NNModuleVariable used to special-case calling
module.forward() (which is a method) as a UserFunctionVariable with an extra
'self' arg. After tracing into module.__call__, there is no longer a special
case for the eventual call into .forward, and it gets wrapped in a
UserDefinedObjectVariable following standard behavior of ._wrap(). UDOV can't be
called, so this broke some tests.
- Fix: add a new special case in _wrap() that treats methods as a UserDefinedMethod
instead of UserDefinedObjectVariable. Now, the forward method can be called.
Also, fix NNModuleVar.call_method routing forward back to __call__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92125
Approved by: https://github.com/ezyang, https://github.com/jansel, https://github.com/voznesenskym
Summary: We don't care about params/buffers being mutated in dynamo export, so it is safe to always convert them to faketensor
Test Plan: CI
Differential Revision: D42353789
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91742
Approved by: https://github.com/qihqi
This PR introduces a new function we can pass to torch._dynamo.optimize - guard_failure_fn. Usage is in the PR, and the one stacked on top of it, but the gist of it is that it emits failed guard reason strings alongside code. This is useful for tests and debugging, as it gives far finer grained assertions and control than the compile counter alone.
This is a resubmit of https://github.com/pytorch/pytorch/pull/90129
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90371
Approved by: https://github.com/ezyang
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90091
Approved by: https://github.com/anijain2305, https://github.com/ezyang
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88756
Approved by: https://github.com/ezyang
There was a lot of strangeness in how AOTAutograd backends were previously defined. This refactor replaces the strangeness with something simple and straightforward. The improvements:
- There is no longer a footgun aot_autograd "backend" which doesn't actually work. No more mistyping `torch._dynamo.optimize("aot_autograd")` when you meant "aot_eager"
- Deleted aot_print because it's annoying and anyway there's no uses of it
- Instead of having BOTH the backend Subgraph and AotAutogradStrategy, there is now only an aot_autograd function which takes the kwargs to configure AOTAutograd, and then gives you a compiler function that does AOTAutograd given those kwargs. Easy.
- The primary downside is that we are now eagerly populating all of the kwargs, and that can get us into import cycle shenanigans. Some cycles I resolved directly (e.g., we now no longer manually disable the forward function before passing it to aot_autograd; aot_autograd it does it for us), but for getting inductor decompositions I had to make it take a lambda so I could lazily populate the decomps later.
New code is 130 lines shorter!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89736
Approved by: https://github.com/anjali411, https://github.com/albanD
It's kind of intractable to enable mypy everywhere at the moment,
because there are a lot of errors, and also mypy is really slow
for some reason. I just want enough types to explain the public
types for user compiler calls, going through typing the _C.dynamo
bindings along the way. This is a first step for this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89731
Approved by: https://github.com/suo
There is only one call site for compiler_fn, so we can safely delay
wrapping verify correctness to here. This will help later when we
change the backend compiler calling convention to pass fake tensors
(but I need to pass real tensors here.)
This is adapted from voz's changes at https://github.com/pytorch/pytorch/pull/89392
but with less changes to the substantive logic. I only moved the relevant
inner implementation; there are no changes otherwise.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89662
Approved by: https://github.com/voznesenskym
{kind=link}