Fix the wiki URL.
Also minor reorganization in onnx.rst.
[ONNX] restore documentation of public functions (#69623)
The build-docs check requires all public functions to be documented.
These should really not be public, but we'll fix that later.'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71609
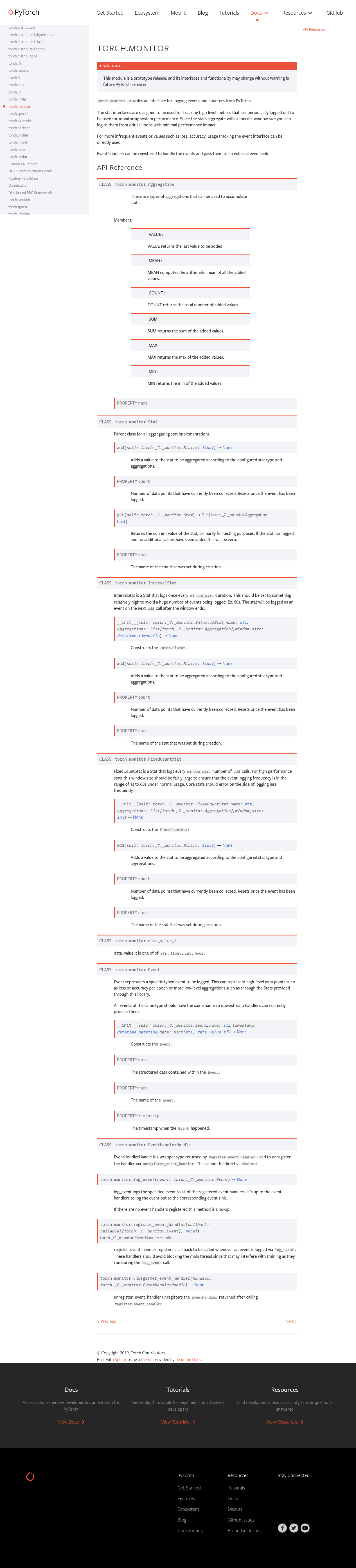
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69567
This exposes torch.monitor events and stats via pybind11 to the underlying C++ implementation.
* The registration interface is a tad different since it takes a lambda function in Python where as in C++ it's a full class.
* This has a small amount of changes to the counter interfaces since there's no way to create an initializer list at runtime so they now also take a vector.
* Only double based stats are provided in Python since it's intended more for high level stats where float imprecision shouldn't be an issue. This can be changed down the line if need arises.
```
events = []
def handler(event):
events.append(event)
handle = register_event_handler(handler)
log_event(Event(type="torch.monitor.TestEvent", timestamp=datetime.now(), metadata={"foo": 1.0}))
```
D32969391 is now included in this diff.
This cleans up the naming for events. type is now name, message is gone, and metadata is renamed data.
Test Plan: buck test //caffe2/test:monitor //caffe2/test/cpp/monitor:monitor
Reviewed By: kiukchung
Differential Revision: D32924141
fbshipit-source-id: 563304c2e3261a4754e40cca39fc64c5a04b43e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70185
The extraheader block in docs/source/_templates/layout.html overrides the one from the pytorch theme. The theme block adds Google Analytics, so they were missing from the `master` documentation. This came up in PR pytorch/pytorch.github.io#899.
brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70187
Reviewed By: bdhirsh
Differential Revision: D33248466
Pulled By: malfet
fbshipit-source-id: b314916a3f0789b6617cf9ba6bd938bf5ca27242
Summary:
Refactor torch.profiler.profile by separate it into one low level class and one high level wrapper.
The PR include the following change:
1. separate class torch.profiler.profile into two separated class: kineto_profiler and torch.profiler.profile.
2. The former class has the low-level functionality exposed in C++ level like: prepare_profiler, start_profiler, stop_profiler.
3. The original logics in torch.profiler.profile including export_chrome_trace, export_stacks, key_averages, events, add_metadata are all moved into kineto_profiler since they are all exposed by the torch.autograd.profiler.
4. The new torch.profiler.profile is fully back-compatible with original class since it inherit from torch.profiler.kineto_profiler. Its only responsibility in new implementation is the maintenance of the finite state machine of ProfilerAction.
With the refactoring, the responsibility boundary is clear and the new logic is simple to understand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63302
Reviewed By: albanD
Differential Revision: D33006442
Pulled By: robieta
fbshipit-source-id: 30d7c9f5c101638703f1243fb2fcc6ced47fb690
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65993
This PR attempts to port `index_add` to structured kernels, but does more than that:
* Adds an `out=` variant to `index_add`
* Revises `native_functions.yaml` registrations, to not have multiple entries and instead pass default value to `alpha`.
* Changes in `derivatives.yaml` file for autograd functioning
* Revises error messages, please see: https://github.com/pytorch/pytorch/pull/65993#issuecomment-945441615
Follow-up PRs in near future will attempt to refactor the OpInfo test, and will give another look at tests in `test/test_torch.py` for this function. (hence the use of ghstack for this)
~This is WIP because there are tests failing for `Dimname` variant on mobile/android builds, and I'm working on fixing them.~
Issue tracker: https://github.com/pytorch/pytorch/issues/55070
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32646426
fbshipit-source-id: b035ecf843a9a27d4d1e18b202b035adc2a49ab5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69789
Add details on how to save and load quantized models without hitting errors
Test Plan:
CI autogenerated docs
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33030991
fbshipit-source-id: 8ec4610ae6d5bcbdd3c5e3bb725f2b06af960d52
Summary:
Also fixes the documentation failing to appear and adds a test to validate that op works with multiple devices properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69640
Reviewed By: ngimel
Differential Revision: D32965391
Pulled By: mruberry
fbshipit-source-id: 4fe502809b353464da8edf62d92ca9863804f08e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69104
Add nvidia-smi memory and utilization as native Python API
Test Plan:
testing the function returns the appropriate value.
Unit tests to come.
Reviewed By: malfet
Differential Revision: D32711562
fbshipit-source-id: 01e676203299f8fde4f3ed4065f68b497e62a789
Summary:
Per title.
This PR introduces a global flag that lets pytorch prefer one of the many backend implementations while calling linear algebra functions on GPU.
Usage:
```python
torch.backends.cuda.preferred_linalg_library('cusolver')
```
Available options (str): `'default'`, `'cusolver'`, `'magma'`.
Issue https://github.com/pytorch/pytorch/issues/63992 inspired me to write this PR. No heuristic is perfect on all devices, library versions, matrix shapes, workloads, etc. We can obtain better performance if we can conveniently switch linear algebra backends at runtime.
Performance of linear algebra operators after this PR should be no worse than before. The flag is set to **`'default'`** by default, which makes everything the same as before this PR.
The implementation of this PR is basically following that of https://github.com/pytorch/pytorch/pull/67790.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67980
Reviewed By: mruberry
Differential Revision: D32849457
Pulled By: ngimel
fbshipit-source-id: 679fee7744a03af057995aef06316306073010a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69251
This adds some actual documentation for deploy, which is probably useful
since we told everyone it was experimentally available so they will
probably be looking at what the heck it is.
It also wires up various compoenents of the OSS build to actually work
when used from an external project.
Differential Revision:
D32783312
D32783312
Test Plan: Imported from OSS
Reviewed By: wconstab
Pulled By: suo
fbshipit-source-id: c5c0a1e3f80fa273b5a70c13ba81733cb8d2c8f8
Summary:
These APIs are not yet officially released and are still under discussion. Hence, this commit removes those APIs from docs and will add them back when ready.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69011
Reviewed By: fduwjj
Differential Revision: D32703124
Pulled By: mrshenli
fbshipit-source-id: ea049fc7ab6b0015d38cc40c5b5daf47803b7ea0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: zou3519, JacobSzwejbka
Differential Revision: D32283178
Pulled By: mruberry
fbshipit-source-id: deb672e6e52f58b76536ab4158073927a35e43a8
Summary:
This PR simply updates the documentation following up on https://github.com/pytorch/pytorch/pull/64234, by adding `Union` as a supported type.
Any feedback is welcome!
cc ansley albanD gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68435
Reviewed By: davidberard98
Differential Revision: D32494271
Pulled By: ansley
fbshipit-source-id: c3e4806d8632e1513257f0295568a20f92dea297
Summary:
The `torch.histogramdd` operator is documented in `torch/functional.py` but does not appear in the generated docs because it is missing from `docs/source/torch.rst`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68273
Reviewed By: cpuhrsch
Differential Revision: D32470522
Pulled By: saketh-are
fbshipit-source-id: a23e73ba336415457a30bae568bda80afa4ae3ed
Summary:
### Create `linalg.cross`
Fixes https://github.com/pytorch/pytorch/issues/62810
As discussed in the corresponding issue, this PR adds `cross` to the `linalg` namespace (**Note**: There is no method variant) which is slightly different in behaviour compared to `torch.cross`.
**Note**: this is NOT an alias as suggested in mruberry's [https://github.com/pytorch/pytorch/issues/62810 comment](https://github.com/pytorch/pytorch/issues/62810#issuecomment-897504372) below
> linalg.cross being consistent with the Python Array API (over NumPy) makes sense because NumPy has no linalg.cross. I also think we can implement linalg.cross without immediately deprecating torch.cross, although we should definitely refer users to linalg.cross. Deprecating torch.cross will require additional review. While it's not used often it is used, and it's unclear if users are relying on its unique behavior or not.
The current default implementation of `torch.cross` is extremely weird and confusing. This has also been reported multiple times previously. (See https://github.com/pytorch/pytorch/issues/17229, https://github.com/pytorch/pytorch/issues/39310, https://github.com/pytorch/pytorch/issues/41850, https://github.com/pytorch/pytorch/issues/50273)
- [x] Add `torch.linalg.cross` with default `dim=-1`
- [x] Add OpInfo and other tests for `torch.linalg.cross`
- [x] Add broadcasting support to `torch.cross` and `torch.linalg.cross`
- [x] Remove out skip from `torch.cross` OpInfo
- [x] Add docs for `torch.linalg.cross`. Improve docs for `torch.cross` mentioning `linalg.cross` and the difference between the two. Also adds a warning to `torch.cross`, that it may change in the future (we might want to deprecate it later)
---
### Additional Fixes to `torch.cross`
- [x] Fix Doc for Tensor.cross
- [x] Fix torch.cross in `torch/overridres.py`
While working on `linalg.cross` I noticed these small issues with `torch.cross` itself.
[Tensor.cross docs](https://pytorch.org/docs/stable/generated/torch.Tensor.cross.html) still mentions `dim=-1` default which is actually wrong. It should be `dim=None` after the behaviour was updated in PR https://github.com/pytorch/pytorch/issues/17582 but the documentation for the `method` or `function` variant wasn’t updated. Later PR https://github.com/pytorch/pytorch/issues/41850 updated the documentation for the `function` variant i.e `torch.cross` and also added the following warning about the weird behaviour.
> If `dim` is not given, it defaults to the first dimension found with the size 3. Note that this might be unexpected.
But still, the `Tensor.cross` docs were missed and remained outdated. I’m finally fixing that here. Also fixing `torch/overrides.py` for `torch.cross` as well now, with `dim=None`.
To verify according to the docs the default behaviour of `dim=-1` should raise, you can try the following.
```python
a = torch.randn(3, 4)
b = torch.randn(3, 4)
b.cross(a) # this works because the implementation finds 3 in the first dimension and the default behaviour as shown in documentation is actually not true.
>>> tensor([[ 0.7171, -1.1059, 0.4162, 1.3026],
[ 0.4320, -2.1591, -1.1423, 1.2314],
[-0.6034, -1.6592, -0.8016, 1.6467]])
b.cross(a, dim=-1) # this raises as expected since the last dimension doesn't have a 3
>>> RuntimeError: dimension -1 does not have size 3
```
Please take a closer look (particularly the autograd part, this is the first time I'm dealing with `derivatives.yaml`). If there is something missing, wrong or needs more explanation, please let me know. Looking forward to the feedback.
cc mruberry Lezcano IvanYashchuk rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63285
Reviewed By: gchanan
Differential Revision: D32313346
Pulled By: mruberry
fbshipit-source-id: e68c2687c57367274e8ddb7ef28ee92dcd4c9f2c
Summary:
https://github.com/pytorch/pytorch/issues/67578 disabled reduced precision reductions for FP16 GEMMs. After benchmarking, we've found that this has substantial performance impacts for common GEMM shapes (e.g., those found in popular instantiations of multiheaded-attention) on architectures such as Volta. As these performance regressions may come as a surprise to current users, this PR adds a toggle to disable reduced precision reductions
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = `
rather than making it the default behavior.
CC ngimel ptrblck
stas00 Note that the behavior after the previous PR can be replicated with
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = False`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67946
Reviewed By: zou3519
Differential Revision: D32289896
Pulled By: ngimel
fbshipit-source-id: a1ea2918b77e27a7d9b391e030417802a0174abe
Summary:
When I run this part of the code on the document with PyTorch version 1.10.0, I found some differences between the output and the document, as follows:
```python
import torch
import torch.fx as fx
class M(torch.nn.Module):
def forward(self, x, y):
return x + y
# Create an instance of `M`
m = M()
traced = fx.symbolic_trace(m)
print(traced)
print(traced.graph)
traced.graph.print_tabular()
```
I get the result:
```shell
def forward(self, x, y):
add = x + y; x = y = None
return add
graph():
%x : [#users=1] = placeholder[target=x]
%y : [#users=1] = placeholder[target=y]
%add : [#users=1] = call_function[target=operator.add](args = (%x, %y), kwargs = {})
return add
opcode name target args kwargs
------------- ------ ----------------------- ------ --------
placeholder x x () {}
placeholder y y () {}
call_function add <built-in function add> (x, y) {}
output output output (add,) {}
```
This pr modified the document。
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68043
Reviewed By: driazati
Differential Revision: D32287178
Pulled By: jamesr66a
fbshipit-source-id: 48ebd0e6c09940be9950cd57ba0c03274a849be5
Summary:
**Summary:** This commit adds the `torch.nn.qat.dynamic.modules.Linear`
module, the dynamic counterpart to `torch.nn.qat.modules.Linear`.
Functionally these are very similar, except the dynamic version
expects a memoryless observer and is converted into a dynamically
quantized module before inference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67325
Test Plan:
`python3 test/test_quantization.py TestQuantizationAwareTraining.test_dynamic_qat_linear`
**Reviewers:** Charles David Hernandez, Jerry Zhang
**Subscribers:** Charles David Hernandez, Supriya Rao, Yining Lu
**Tasks:** 99696812
**Tags:** pytorch
Reviewed By: malfet, jerryzh168
Differential Revision: D32178739
Pulled By: andrewor14
fbshipit-source-id: 5051bdd7e06071a011e4e7d9cc7769db8d38fd73
Summary:
Add check to make sure we do not add new submodules without documenting them in an rst file.
This is especially important because our doc coverage only runs for modules that are properly listed.
temporarily removed "torch" from the list to make sure the failure in CI looks as expected. EDIT: fixed now
This is what a CI failure looks like for the top level torch module as an example:

Pull Request resolved: https://github.com/pytorch/pytorch/pull/67440
Reviewed By: jbschlosser
Differential Revision: D32005310
Pulled By: albanD
fbshipit-source-id: 05cb2abc2472ea4f71f7dc5c55d021db32146928
Summary:
Adds `torch.argwhere` as an alias to `torch.nonzero`
Currently, `torch.nonzero` is actually provides equivalent functionality to `np.argwhere`.
From NumPy docs,
> np.argwhere(a) is almost the same as np.transpose(np.nonzero(a)), but produces a result of the correct shape for a 0D array.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64257
Reviewed By: qihqi
Differential Revision: D32049884
Pulled By: saketh-are
fbshipit-source-id: 016e49884698daa53b83e384435c3f8f6b5bf6bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67449
Adds a description of what the current custom module API does
and API examples for Eager mode and FX graph mode to the main
PyTorch quantization documentation page.
Test Plan:
```
cd docs
make html
python -m http.server
// check the docs page, it renders correctly
```
Reviewed By: jbschlosser
Differential Revision: D31994641
Pulled By: vkuzo
fbshipit-source-id: d35a62947dd06e71276eb6a0e37950d3cc5abfc1
Summary:
This reduces the chance of a newly added functions to be ignored by mistake.
The only test that this impacts is the coverage test that runs as part of the python doc build. So if that one works, it means that the update to the list here is correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67395
Reviewed By: jbschlosser
Differential Revision: D31991936
Pulled By: albanD
fbshipit-source-id: 5b4ce7764336720827501641311cc36f52d2e516
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66143
Delete test_list_remove. There's no point in testing conversion of
this model since TorchScript doesn't support it.
Add a link to an issue tracking test_embedding_bag_dynamic_input.
[ONNX] fix docs (#65379)
Mainly fix the sphinx build by inserting empty before
bulleted lists.
Also some minor improvements:
Remove superfluous descriptions of deprecated and ignored args.
The user doesn't need to know anything other than that they are
deprecated and ignored.
Fix custom_opsets description.
Make indentation of Raises section consistent with Args section.
[ONNX] publicize func for discovering unconvertible ops (#65285)
* [ONNX] Provide public function to discover all unconvertible ATen ops
This can be more productive than finding and fixing a single issue at a
time.
* [ONNX] Reorganize test_utility_funs
Move common functionality into a base class that doesn't define any
tests.
Add a new test for opset-independent tests. This lets us avoid running
the tests repeatedly for each opset.
Use simple inheritance rather than the `type()` built-in. It's more
readable.
* [ONNX] Use TestCase assertions rather than `assert`
This provides better error messages.
* [ONNX] Use double quotes consistently.
[ONNX] Fix code block formatting in doc (#65421)
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31424093
fbshipit-source-id: 4ced841cc546db8548dede60b54b07df9bb4e36e
Summary:
Adds `torch.argwhere` as an alias to `torch.nonzero`
Currently, `torch.nonzero` is actually provides equivalent functionality to `np.argwhere`.
From NumPy docs,
> np.argwhere(a) is almost the same as np.transpose(np.nonzero(a)), but produces a result of the correct shape for a 0D array.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64257
Reviewed By: dagitses
Differential Revision: D31474901
Pulled By: saketh-are
fbshipit-source-id: 335327a4986fa327da74e1fb8624cc1e56959c70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66577
There was a rebase artifact erroneously landed to quantization docs,
this PR removes it.
Test Plan:
CI
Imported from OSS
Reviewed By: soulitzer
Differential Revision: D31651350
fbshipit-source-id: bc254cbb20724e49e1a0ec6eb6d89b28491f9f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66380
Description:
1. creates doc pages for Eager and FX numeric suites
2. adds a link from main quantization doc to (1)
3. formats docblocks in Eager NS to render well
4. adds example code and docblocks to FX numeric suite
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31543173
Pulled By: vkuzo
fbshipit-source-id: feb291bcbe92747495f45165f738631fa5cbffbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66379
Description:
Creates a quantization API reference and fixes all the docblock errors.
This is #66122 to #66210 squashed together
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, looks good
```
Reviewed By: ejguan
Differential Revision: D31543172
Pulled By: vkuzo
fbshipit-source-id: 9131363d6528337e9f100759654d3f34f02142a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66222
Description:
1. creates doc pages for Eager and FX numeric suites
2. adds a link from main quantization doc to (1)
3. formats docblocks in Eager NS to render well
4. adds example code and docblocks to FX numeric suite
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447610
Pulled By: vkuzo
fbshipit-source-id: 441170c4a6c3ddea1e7c7c5cc2f1e1cd5aa65f2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66210
Description:
Moves the backend section of the quantization page further down,
to ensure that the API description and reference sections are closer
to the top.
Test Plan:
```
cd docs
make html
python -m server.http
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447611
Pulled By: vkuzo
fbshipit-source-id: 537b146559bce484588b3c78e6b0cdb4c274e8dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66201
Description:
This PR switches the quantization API reference to use `autosummary`
for each section. We define the sections and manually write a list
of modules/functions/methods to include, and sphinx does the rest.
A result is a single page where we have every quantization function
and module with a quick autogenerated blurb, and user can click
through to each of them for a full documentation page.
This mimics how the `torch.nn` and `torch.nn.functional` doc
pages are set up.
In detail, for each section before this PR:
* creates a new section using `autosummary`
* adds all modules/functions/methods which were previously in the manual section
* adds any additional modules/functions/methods which are public facing but not previously documented
* deletes the old manual summary and all links to it
Test Plan:
```
cd docs
make html
python -m http.server
// renders well, links work
```
Reviewed By: jerryzh168
Differential Revision: D31447615
Pulled By: vkuzo
fbshipit-source-id: 09874ad9629f9c00eeab79c406579c6abd974901
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66198
Consolidates all API reference material for quantization on a single
page, to reduce duplication of information.
Future PRs will improve the API reference page itself.
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447616
Pulled By: vkuzo
fbshipit-source-id: 2f9c4dac2b2fb377568332aef79531d1f784444a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66129
Adds a documentation page for `torch.ao.quantization.QConfig`. It is useful
for this to have a separate page since it shared between Eager and FX graph
mode quantization.
Also, ensures that all important functions and module attributes in this
module have docstrings, so users can discover these without reading the
source code.
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, renders correctly
```
Reviewed By: jerryzh168
Differential Revision: D31447614
Pulled By: vkuzo
fbshipit-source-id: 5d9dd2a4e8647fa17b96cefbaae5299adede619c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66125
Before this PR, the documentation for observers and fake_quants was inlined in the
Eager mode quantization page. This was hard to discover, especially
since that page is really long, and we now have FX graph mode quantization reusing
all of this code.
This PR moves observers and fake_quants into their own documentation pages. It also
adds docstrings to all user facing module attributes such as the default observers
and fake_quants, so people can discover them from documentation without having
to inspect the source code.
For now, enables autoformatting (which means all public classes, functions, members
with docstrings will get docs). If we need to exclude something in these files from
docs in the future, we can go back to manual docs.
Test Plan:
```
cd docs
make html
python -m server.http
// inspect docs on localhost, renders correctly
```
Reviewed By: dagitses
Differential Revision: D31447613
Pulled By: vkuzo
fbshipit-source-id: 63b4cf518badfb29ede583a5c2ca823f572c8599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66122
Description:
Adds a documentation page for FX graph mode quantization APIs which
reads from the docstrings in `quantize_fx`, and links it from the main
quantization documentation page.
Also, updates the docstrings in `quantize_fx` to render well with reStructuredText.
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, looks good
```
Reviewed By: dagitses
Differential Revision: D31447612
Pulled By: vkuzo
fbshipit-source-id: 07d0a6137f1537af82dce0a729f9617efaa714a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65838
closes https://github.com/pytorch/pytorch/pull/65675
The default `--max_restarts` for `torch.distributed.run` was changed to `0` from `3` to make things backwards compatible with `torch.distributed.launch`. Since the default `--max_restarts` used to be greater than `0` we never documented passing `--max_restarts` explicitly in any of our example code.
Test Plan: N/A doc change only
Reviewed By: d4l3k
Differential Revision: D31279544
fbshipit-source-id: 98b31e6a158371bc56907552c5c13958446716f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64373
* Fix some bad formatting and clarify things in onnx.rst.
* In `export_to_pretty_string`:
* Add documentation for previously undocumented args.
* Document that `f` arg is ignored and mark it deprecated.
* Update tests to stop setting `f`.
* Warn if `_retain_param_name` is set.
* Use double quotes for string literals in test_operators.py.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905271
Pulled By: malfet
fbshipit-source-id: 3627eeabf40b9516c4a83cfab424ce537b36e4b3
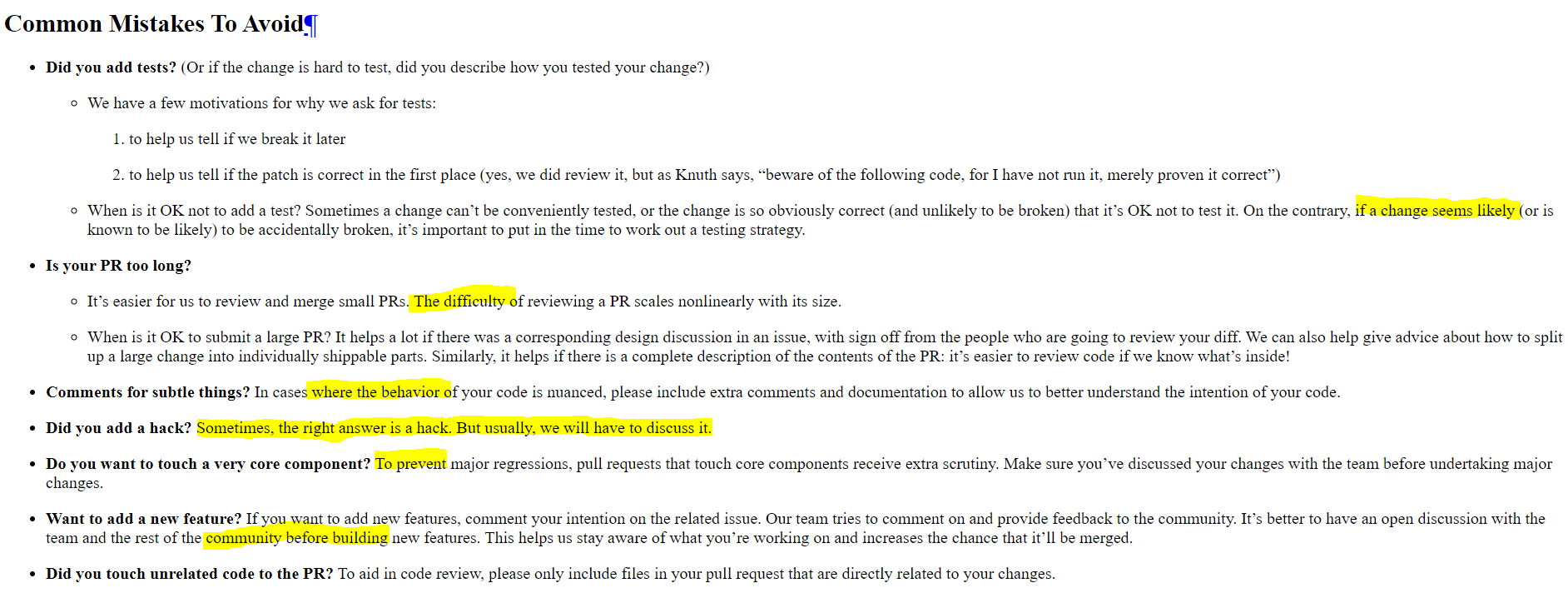
Summary:
Related to https://github.com/pytorch/pytorch/issues/30987. Fix the following task:
- [ ] Remove the use of `.data` in all our internal code:
- [ ] ...
- [x] `docs/source/scripts/build_activation_images.py` and `docs/source/notes/extending.rst`
In `docs/source/scripts/build_activation_images.py`, I used `nn.init` because the snippet already assumes `nn` is available (the class inherits from `nn.Module`).
cc albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65358
Reviewed By: malfet
Differential Revision: D31061790
Pulled By: albanD
fbshipit-source-id: be936c2035f0bdd49986351026fe3e932a5b4032
Summary:
Powers have decided this API should be listed as beta.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65247
Reviewed By: malfet
Differential Revision: D31057940
Pulled By: ngimel
fbshipit-source-id: 137b63cbd2c7409fecdc161a22135619bfc96bfa
Summary:
Puts memory sharing intro under Sharing memory... header, where it should have been all along.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64996
Reviewed By: mruberry
Differential Revision: D30948619
Pulled By: ngimel
fbshipit-source-id: 5d9dd267b34e9d3fc499d4738377b58a22da1dc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62671
Very crude first implementation of `torch.nanmean`. The current reduction kernels do not have good support for implementing nan* variants. Rather than implementing new kernels for each nan* operator, I will work on new reduction kernels with support for a `nan_policy` flag and then I will port `nanmean` to use that.
**TODO**
- [x] Fix autograd issue
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D30515181
Pulled By: heitorschueroff
fbshipit-source-id: 303004ebd7ac9cf963dc4f8e2553eaded5f013f0
Summary:
Partially resolves https://github.com/pytorch/vision/issues/4281
In this PR we are proposing a new scheduler --SequentialLR-- which enables list of different schedulers called in different periods of the training process.
The main motivation of this scheduler is recently gained popularity of warming up phase in the training time. It has been shown that having a small steps in initial stages of training can help convergence procedure get faster.
With the help of SequentialLR we mainly enable to call a small constant (or linearly increasing) learning rate followed by actual target learning rate scheduler.
```PyThon
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = SequentialLR(optimizer, schedulers=[scheduler1, scheduler2], milestones=[5])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
```
which this code snippet will call `ConstantLR` in the first 5 epochs and will follow up with `ExponentialLR` in the following epochs.
This scheduler could be used to provide call of any group of schedulers next to each other. The main consideration we should make is every time we switch to a new scheduler we assume that new scheduler starts from the beginning- zeroth epoch.
We also add Chained Scheduler to `optim.rst` and `lr_scheduler.pyi` files here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64037
Reviewed By: albanD
Differential Revision: D30841099
Pulled By: iramazanli
fbshipit-source-id: 94f7d352066ee108eef8cda5f0dcb07f4d371751
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62811
Add `torch.linalg.matmul` alias to `torch.matmul`. Note that the `linalg.matmul` doesn't have a `method` variant.
Also cleaning up `torch/_torch_docs.py` when formatting is not needed.
cc IvanYashchuk Lezcano mruberry rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63227
Reviewed By: mrshenli
Differential Revision: D30770235
Pulled By: mruberry
fbshipit-source-id: bfba77dfcbb61fcd44f22ba41bd8d84c21132403
Summary:
Partially unblocks https://github.com/pytorch/vision/issues/4281
Previously we have added WarmUp Schedulers to PyTorch Core in the PR : https://github.com/pytorch/pytorch/pull/60836 which had two mode of execution - linear and constant depending on warming up function.
In this PR we are changing this interface to more direct form, as separating linear and constant modes to separate Schedulers. In particular
```Python
scheduler1 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
scheduler2 = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="linear")
```
will look like
```Python
scheduler1 = ConstantLR(optimizer, warmup_factor=0.1, warmup_iters=5)
scheduler2 = LinearLR(optimizer, warmup_factor=0.1, warmup_iters=5)
```
correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64395
Reviewed By: datumbox
Differential Revision: D30753688
Pulled By: iramazanli
fbshipit-source-id: e47f86d12033f80982ddf1faf5b46873adb4f324
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61767
## Changes
- [x] Add `torch.concat` alias to `torch.cat`
- [x] Add OpInfo for `cat`/`concat`
- [x] Fix `test_out` skips (Use `at::native::resize_output` or `at::native::resize_output_check`)
- [x] `cat`/`concat`
- [x] `stack`
- [x] `hstack`
- [x] `dstack`
- [x] `vstack`/`row_stack`
- [x] Remove redundant tests for `cat`/`stack`
~I've not added `cat`/`concat` to OpInfo `op_db` yet, since cat is a little more tricky than other OpInfos (should have a lot of tests) and currently there are no OpInfos for that. I can try to add that in a subsequent PR or maybe here itself, whatever is suggested.~
**Edit**: cat/concat OpInfo has been added.
**Note**: I've added the named tensor support for `concat` alias as well, maybe that's out of spec in `array-api` but it is still useful for consistency in PyTorch.
Thanks to krshrimali for guidance on my first PR :))
cc mruberry rgommers pmeier asmeurer leofang AnirudhDagar asi1024 emcastillo kmaehashi heitorschueroff krshrimali
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62560
Reviewed By: saketh-are
Differential Revision: D30762069
Pulled By: mruberry
fbshipit-source-id: 6985159d1d9756238890488a0ab3ae7699d94337
Summary:
This PR is created to replace https://github.com/pytorch/pytorch/pull/53180 PR stack, which has all the review discussions. Reason for needing a replacement is due to a messy Sandcastle issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64234
Reviewed By: gmagogsfm
Differential Revision: D30656444
Pulled By: ansley
fbshipit-source-id: 77536c8bcc88162e2c72636026ca3c16891d669a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63582
Current quantization docs do not define qconfig and qengine. Added text to define these concepts before they are used.
ghstack-source-id: 137051719
Test Plan: Imported from OSS
Reviewed By: HDCharles
Differential Revision: D30658656
fbshipit-source-id: a45a0fcdf685ca1c3f5c3506337246a430f8f506
Summary:
Implements an orthogonal / unitary parametrisation.
It does passes the tests and I have trained a couple models with this implementation, so I believe it should be somewhat correct. Now, the implementation is very subtle. I'm tagging nikitaved and IvanYashchuk as reviewers in case they have comments / they see some room for optimisation of the code, in particular of the `forward` function.
Fixes https://github.com/pytorch/pytorch/issues/42243
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62089
Reviewed By: ezyang
Differential Revision: D30639063
Pulled By: albanD
fbshipit-source-id: 988664f333ac7a75ce71ba44c8d77b986dff2fe6
Summary:
This PR expands the [note on modules](https://pytorch.org/docs/stable/notes/modules.html) with additional info for 1.10.
It adds the following:
* Examples of using hooks
* Examples of using apply()
* Examples for ParameterList / ParameterDict
* register_parameter() / register_buffer() usage
* Discussion of train() / eval() modes
* Distributed training overview / links
* TorchScript overview / links
* Quantization overview / links
* FX overview / links
* Parametrization overview / link to tutorial
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63963
Reviewed By: albanD
Differential Revision: D30606604
Pulled By: jbschlosser
fbshipit-source-id: c1030b19162bcb5fe7364bcdc981a2eb6d6e89b4
Summary:
This PR introduces a new `torchrun` entrypoint that simply "points" to `python -m torch.distributed.run`. It is shorter and less error-prone to type and gives a nicer syntax than a rather cryptic `python -m ...` command line. Along with the new entrypoint the documentation is also updated and places where `torch.distributed.run` are mentioned are replaced with `torchrun`.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse agolynski SciPioneer H-Huang mrzzd cbalioglu gcramer23
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64049
Reviewed By: cbalioglu
Differential Revision: D30584041
Pulled By: kiukchung
fbshipit-source-id: d99db3b5d12e7bf9676bab70e680d4b88031ae2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63910
Addresses the current issue that `init_method=tcp://` is not compatible with `torch.distributed.run` and `torch.distributed.launch`. When running with a training script that initializes the process group with `init_method=tcp://localhost:$port` as such:
```
$ python -u -m torch.distributed.run --max_restarts 0 --nproc_per_node 1 --nnodes 1 --master_addr $(hostname) --master_port 6000 ~/tmp/test.py
```
An `Address in use` error is raised since the training script tries to create a TCPStore on port 6000, which is already taken since the elastic agent is already running a TCPStore on that port.
For details see: https://github.com/pytorch/pytorch/issues/63874.
This change does a couple of things:
1. Adds `is_torchelastic_launched()` check function that users can use in the training scripts to see whether the script is launched via torchelastic.
1. Update the `torch.distributed` docs page to include the new `is_torchelastic_launched()` function.
1. Makes `init_method=tcp://` torchelastic compatible by modifying `_tcp_rendezvous_handler` in `torch.distributed.rendezvous` (this is NOT the elastic rendezvous, it is the old rendezvous module which is slotted for deprecation in future releases) to check `is_torchelastic_launched()` AND `torchelastic_use_agent_store()` and if so, only create TCPStore clients (no daemons, not even for rank 0).
1. Adds a bunch of unittests to cover the different code paths
NOTE: the issue mentions that we should fail-fast with an assertion on `init_method!=env://` when `is_torchelastic_launched()` is `True`. There are three registered init_methods in pytorch: env://, tcp://, file://. Since this diff makes tcp:// compatible with torchelastic and I've validated that file is compatible with torchelastic. There is no need to add assertions. I did update the docs to point out that env:// is the RECOMMENDED init_method. We should probably deprecate the other init_methods in the future but this is out of scope for this issue.
Test Plan: Unittests.
Reviewed By: cbalioglu
Differential Revision: D30529984
fbshipit-source-id: 267aea6d4dad73eb14a2680ac921f210ff547cc5
Summary:
CUDA_VERSION and HIP_VERSION follow very unrelated versioning schemes, so it does not make sense to use CUDA_VERSION to determine the ROCm path. This note explicitly addresses it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62850
Reviewed By: mruberry
Differential Revision: D30547562
Pulled By: malfet
fbshipit-source-id: 02990fa66a88466c2330ab85f446b25b78545150
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63241
This is a common source of confusion, but it matches the NumPy
behavior.
Fixes#44010Fixes#59526
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D30307646
Pulled By: dagitses
fbshipit-source-id: d848140ba267560387d83f3e7acba8c3cdc53d82
Summary:
- Adds some code examples for `ctx` methods and make requirements of arguments more clear
- Type annotations for `save_for_backward`, `mark_dirty`, `mark_non_differentiable`, and `set_materialize_grads` (BC-breaking?)
- Refactor `torch.autograd.Function` doc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60312
Reviewed By: VitalyFedyunin
Differential Revision: D30314961
Pulled By: soulitzer
fbshipit-source-id: a284314b65662e26390417bd2b6b12cd85e68dc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63242
These functions are part of the native functions namespace as well as the quantized namespace
Test Plan:
CI
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D30316430
fbshipit-source-id: cd9c839e5c1a961e3c6944e514c16fbc256a2f0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63240
Op is exposed via torch.quantized_batch_norm to the end user without any existing documentation
Test Plan:
CI
Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D30316431
fbshipit-source-id: bf2dc8b7b6f497cf73528eaa2bedef9f65029d84
Summary:
Warm up of learning rate scheduling has initially been discussed by Priya et. al. in the paper: https://arxiv.org/pdf/1706.02677.pdf .
In the section 2.2 of the paper they discussed and proposed idea of warming up learning schedulers in order to prevent big variance / noise in the learning rate. Then idea has been further discussed in the following papers:
* Akilesh Gotmare et al. https://arxiv.org/abs/1810.13243
* Bernstein et al http://proceedings.mlr.press/v80/bernstein18a/bernstein18a.pdf
* Liyuan Liu et al: https://arxiv.org/pdf/1908.03265.pdf
There are two type of popularly used learning rate warm up ideas
* Constant warmup (start with very small constant learning rate)
* Linear Warmup ( start with small learning rate and gradually increase)
In this PR we are adding warm up as learning rate scheduler. Note that learning rates are chainable, which means that we can merge warmup scheduler with any other learning rate scheduler to make more sophisticated learning rate scheduler.
## Linear Warmup
Linear Warmup is multiplying learning rate with pre-defined constant - warmup_factor in the first epoch (epoch 0). Then targeting to increase this multiplication constant to one in warmup_iters many epochs. Hence we can derive the formula at i-th step to have multiplication constant equal to:
warmup_factor + (1-warmup_factor) * i / warmup_iters
Moreover, the fraction of this quantity at point i to point i-1 will give us
1 + (1.0 - warmup_factor) / [warmup_iters*warmup_factor+(i-1)*(1-warmup_factor)]
which is used in get_lr() method in our implementation. Below we provide an example how to use linear warmup scheduler and to give an example to show how does it works.
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=10, warmup_method="linear")
for epoch in range(15):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.019000000000000003
2 0.028000000000000008
3 0.03700000000000001
4 0.04600000000000001
5 0.055000000000000014
6 0.06400000000000002
7 0.07300000000000002
8 0.08200000000000003
9 0.09100000000000004
10 0.10000000000000005
11 0.10000000000000005
12 0.10000000000000005
13 0.10000000000000005
14 0.10000000000000005
```
## Constant Warmup
Constant warmup has straightforward idea, to multiply learning rate by warmup_factor until we reach to epoch warmup_factor, then do nothing for following epochs
```python
import torch
from torch.nn import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import WarmUpLR
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = WarmUpLR(optimizer, warmup_factor=0.1, warmup_iters=5, warmup_method="constant")
for epoch in range(10):
print(epoch, scheduler.get_last_lr()[0])
optimizer.step()
scheduler.step()
```
```
0 0.010000000000000002
1 0.010000000000000002
2 0.010000000000000002
3 0.010000000000000002
4 0.010000000000000002
5 0.10000000000000002
6 0.10000000000000002
7 0.10000000000000002
8 0.10000000000000002
9 0.10000000000000002
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60836
Reviewed By: saketh-are
Differential Revision: D29537615
Pulled By: iramazanli
fbshipit-source-id: d910946027acc52663b301f9c56ade686e62cb69
Summary:
This FAQ has a section for CUDA OOMs where there are lots of don'ts. This limits modeling solution. Deep nets can blow up memory due to output caching during training.
It's a known problem with a known solution: to trade-off compute for memory via checkpointing.
FAQ should mention it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62709
Reviewed By: nairbv
Differential Revision: D30103326
Pulled By: ezyang
fbshipit-source-id: 3a8b465a7fbe19aae88f83cc50fe82ebafcb56c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62662
Replaced the methods set_tensor(.) and get_tensor() in the python exposed API from the C++ logic with buffer() and set_buffer(.) to be a cleaner interface.
Reviewed By: SciPioneer
Differential Revision: D30012869
fbshipit-source-id: bd8efab583dd89c96f9aeb3dd48a12073f0b1482
Summary:
**Overview:**
This removes the preceding `_` from `_Join`, `_Joinable`, and `_JoinHook` in preparation for adding the generic join context manager tutorial (see [here](https://github.com/pytorch/tutorials/pull/1610)). This also adds a docs page, which can be linked from the tutorial. [Here](https://github.com/pytorch/pytorch/files/6919475/render.pdf) is a render of the docs page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62605
Test Plan:
`DistributedDataParallel.join()`:
```
touch /tmp/barrier && TEMP_DIR="/tmp" BACKEND="nccl" WORLD_SIZE="2" gpurun python test/distributed/test_distributed_fork.py -- TestDistBackendWithFork.test_ddp_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_inputs_stop_iteration_sync_bn TestDistBackendWithFork.test_ddp_grad_div_uneven_inputs TestDistBackendWithFork.test_ddp_uneven_input_join_disable TestDistBackendWithFork.test_ddp_uneven_input_exception
```
`ZeroRedundancyOptimizer`:
```
gpurun4 python test/distributed/optim/test_zero_redundancy_optimizer.py
```
NOTE: DDP overlap tests are failing due to a landing race. See https://github.com/pytorch/pytorch/pull/62592. Once the fix is landed, I will rebase, and tests should be passing.
`Join`:
```
gpurun4 python test/distributed/algorithms/test_join.py
```
Reviewed By: mrshenli
Differential Revision: D30055544
Pulled By: andwgu
fbshipit-source-id: a5ce1f1d9f1904de3bdd4edd0b31b0a612d87026
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62592
Reland #62510
`GradBucket` is an important class defined in both C++ and Python, used for PyTorch Distributed Training. We need to rename the following methods for simplicity:
1) get_index -> index
2) is_the_last_bucket_to_allreduce -> is_last,
3) get_per_parameter_tensors -> gradients,
4) get_model_params_for_bucket -> parameters.
ghstack-source-id: 134848352
Test Plan: unit test
Reviewed By: andwgu
Differential Revision: D30049431
fbshipit-source-id: 1bcac331aa30e529b7230e3891bc811c531b0ea9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62510
`GradBucket` is an important class defined in both C++ and Python, used for PyTorch Distributed Training. We need to rename the following methods for simplicity:
1) get_index -> index
2) is_the_last_bucket_to_allreduce -> is_last,
3) get_per_parameter_tensors -> gradients,
4) get_model_params_for_bucket -> parameters.
Test Plan:
Local run comprehensive test with following results:
https://pxl.cl/1Ml8b
For two timeout failure test cases, most likely environment related and fail in my devserver.
Reviewed By: SciPioneer
Differential Revision: D30024161
fbshipit-source-id: 07e6072a2f7b81f731425d9b71f8c8b60d383b0f
Summary:
This creates `torch.cuda.set_warn_on_synchronization()` function that would warn or error when synchronizing operation is performed. We could wrap it in a context manager for ease of use, but it would be a lie, because it sets global, and not thread-local state. Since it's intended for debugging, maybe that's ok though.
As all `torch.cuda.*` functions, it's going through CPython, not pybind, so the argument is converted to long before being passed to c10 function. I'll make python argument a python enum class, but without pybind it'll still have to go thourgh long conversion.
For a test script
```
import torch
torch.cuda.set_warn_on_synchronization(1)
x=torch.randn(10, device="cuda")
x.nonzero()
y=torch.randn((), device="cuda")
if y:
print("something")
torch.multinomial(x.abs(), 10, replacement=False)
torch.randperm(20000, device="cuda")
ind = torch.randint(10, (3,), device="cuda")
mask = torch.randint(2, (10,), device="cuda", dtype=torch.bool)
val = torch.randn((), device="cuda")
x[mask]=1.
x[mask] = val
torch.cuda.synchronize()
```
the output is
```
/../playground/sync_warn_test.py:4: UserWarning: called a synchronizing operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:145.)
x.nonzero()
/../playground/sync_warn_test.py:7: UserWarning: called a synchronizing operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:145.)
if y:
something
/../playground/sync_warn_test.py:9: UserWarning: called a synchronizing operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:145.)
torch.multinomial(x.abs(), 10, replacement=False)
/../playground/sync_warn_test.py:15: UserWarning: called a synchronizing operation (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:145.)
x[mask] = val
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62092
Reviewed By: mruberry
Differential Revision: D29968792
Pulled By: ngimel
fbshipit-source-id: cc6f817212c164727ed99ecf6ab050dc29631b9e
Summary:
Sphinx 4.x is out, but it seems that requires many more changes to
adopt. So instead use the latest version of 3.x, which includes
several nice features.
* Add some noindex directives to deal with warnings that would otherwise
be triggered by this change due to conflicts between the docstrings
declaring a function and the autodoc extension declaring the
same function.
* Update distributions.utils.lazy_property to make it look like a
regular property when sphinx autodoc inspects classes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61601
Reviewed By: ejguan
Differential Revision: D29801876
Pulled By: albanD
fbshipit-source-id: 544d2434a15ceb77bff236e934dbd8e4dbd9d160
Summary:
CI built the documentation for the recent 1.9.0rc1 tag, but left the git version in the `version`, so (as of now) going to https://pytorch.org/docs/1.9.0/index.html and looking at the version in the upper-left corner shows "1.9.0a0+git5f0bbb3" not "1.9.0". This PR should change that to cut off everything after and including the "a".
It should be cherry-picked to the release/1.9 branch so that the next rc will override the current documentation with a "cleaner" version.
brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58486
Reviewed By: zou3519
Differential Revision: D28640476
Pulled By: malfet
fbshipit-source-id: 9fd1063f4a2bc90fa8c1d12666e8c0de3d324b5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59077Fixes#58549
`from_buffer` constructs a tensor object from an already allocated buffer through
CPython's buffer protocol. Besides the standard `dtype`, `count`, and `offset` parameters,
this function also accepts:
- `device`: where the buffer lives
- `requires_grad`: should autograd record operations on the new tensor
A new test file _test_buffer_protocol.py_ was created. Currently, only CPU tests were
implemented. That's because neither PyTorch nor Numba implements CPython's buffer
protocol. Therefore, there's no way to create a CUDA buffer with the existing
dependencies (could use PyCUDA for that, though).
At the moment, if `device` differs from the device the buffer actually lives, two things
may happen:
- `RuntimeError`, if `device='cuda'`
- Segmentation fault (not tested -- see above), if `device='cpu'`
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D29870914
Pulled By: mruberry
fbshipit-source-id: 9fa8611aeffedfe39c9af74558178157a11326bb
Summary:
This PR un-reverts https://github.com/pytorch/pytorch/issues/61475 + fixes compilation with MSVC, that does not recognize alternative operator spellings (i.e. using `or` instead of `||` )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61937
Reviewed By: albanD
Differential Revision: D29805941
Pulled By: malfet
fbshipit-source-id: 01e5963c6717c1b44b260300d87ba0bf57f26ce9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61556
Prior to 1.10.0 `torch.__version__` was stored as a str and so many did
comparisons against `torch.__version__` as if it were a str. In order to not
break them we have TorchVersion which masquerades as a str while also
having the ability to compare against both packaging.version.Version as
well as tuples of values, eg. (1, 2, 1)
Examples:
Comparing a TorchVersion object to a Version object
```
TorchVersion('1.10.0a') > Version('1.10.0a')
```
Comparing a TorchVersion object to a Tuple object
```
TorchVersion('1.10.0a') > (1, 2) # 1.2
TorchVersion('1.10.0a') > (1, 2, 1) # 1.2.1
```
Comparing a TorchVersion object against a string
```
TorchVersion('1.10.0a') > '1.2'
TorchVersion('1.10.0a') > '1.2.1'
```
Resolves https://github.com/pytorch/pytorch/issues/61540
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D29671234
Pulled By: seemethere
fbshipit-source-id: 6044805918723b4aca60bbec4b5aafc1189eaad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56058
User facing changes:
1. Adds a negative bit and corresponding new API (`is_neg()`,`resolve_neg()`)
2. `tensor.conj().imag` now returns a floating point tensor with neg bit set to 1 instead of a tensor with no notion of negative bit. Note that imag is still a view and all the view properties still hold for imag.
Non user facing changes:
1. Added a new Negative dispatch key and a backend fallback to handle it
2. Updated copy kernel to handle negative bit
3. Merged conjugate and negative bit fallback kernel
4. fixed https://github.com/pytorch/pytorch/issues/60478 (caused due to https://github.com/pytorch/pytorch/pull/54987)
Testing:
1. Added a new OpInfo based test `test_neg_view` (verifies that out-of-place and in-place operations work correctly for all operations when the input is a neg view tensor by checking the result against an actually negated tensor, verifies that autograd returns the same output for both neg view and actually negated tensors as well as it works fine when grad_out is a neg view).
2. Added a new test class containing `test_conj_view`, `test_neg_view`.
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D29636403
fbshipit-source-id: 12214c9dc4806c51850f4a72a109db9527c0ca63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61145
Remove 'verbose' mode from PackageExporter as people have complained that it is not useful.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D29559681
Pulled By: Lilyjjo
fbshipit-source-id: eadb1a3a25fadc64119334a09bf1fa4b355b1edd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60249
* Add introductory paragraph explaining what ONNX is and what the
torch.onnx module does.
* In "Tracing vs Scripting" and doc-string for torch.onnx.export(),
clarify that exporting always happens on ScriptModules and that
tracing and scripting are the two ways to produce a ScriptModule.
* Remove examples of using Caffe2 to run exported models.
Caffe2's website says it's deprecated, so it's probably best not to
encourage people to use it by including it in examples.
* Remove a lot of content that's redundant:
* The example of how to mix tracing and scripting, and instead
link to Introduction to TorchScript, which includes very similar
content.
* "Type annotations" section. Link to TorchScript docs which explain
that in more detail.
* "Using dictionaries to handle Named Arguments as model inputs"
section. It's redundant with the description of the `args` argument
to `export()`, which appears on the same page once the HTML
is generated.
* Remove the list of supported Tensor indexing patterns. If it's not
in the list of unsupported patterns, users can assume it's
supported, so having both is redundant.
* Remove the list of supported operators and models.
I think the list of supported operators is not very useful.
A list of supported model architectures may be useful, but in
reality it's already very out of date. We should add it back if
/ when we have a system for keeping it up to date.
* "Operator Export Type" section. It's redundant with the description
of the `operator_export_type` arg to to `export()`, which appears on
the same page once the HTML is generated.
* "Use external data format" section. It's redundant with the
description of the `use_external_data_format` arg to `export()`.
* "Training" section. It's redundant with the
description of the `training` arg to `export()`.
* Move the content about different operator implementations producing
different results from the "Limitations" section into the doc for the
`operator_export_type` arg.
* Document "quantized" -> "caffe2" behavior of
OperatorExportTypes.ONNX_ATEN_FALLBACK.
* Combing the text about using torch.Tensor.item() and the text about
using NumPy types into a section titled
"Avoid NumPy and built-in Python types", since they're both
fundamentally about the same issue.
* Rename "Write PyTorch model in Torch way" to "Avoiding Pitfalls".
* Lots of minor fixes: spelling, grammar, brevity, fixing links, adding
links.
* Clarify limitation on input and output types. Phrasing it in terms of
PyTorch types is much more accessible than in terms of TorchScript
types. Also clarify what actually happens when dict and str are used
as inputs and outputs.
* In Supported operators, use torch function and class names and link
to them. This is more user friendly than using the internal aten
op names.
* Remove references to VariableType.h, which doesn't appear to contain
the information that it once did. Instead refer to the generated
.pyi files.
* Remove the text in the FAQ about appending to lists within loops.
I think this limitation is no longer present
(perhaps since https://github.com/pytorch/pytorch/pull/51577).
* Minor fixes to some code I read along the way.
* Explain the current rationale for the weird ::prim_PythonOp op name.
Test Plan: Imported from OSS
Reviewed By: zou3519, ZolotukhinM
Differential Revision: D29494912
Pulled By: SplitInfinity
fbshipit-source-id: 7756c010b2320de0692369289604403d28877719
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61294
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60925
* Make `torch.distributed.launch` restarts to 0
* Remove unnecessary `-use_env` warning, move `-use_env` warnings
* Move `-use_env` warnings to `torch.distributed.launch`
* Make default log level WARNING
* Add new doc section around transitioning to `torch.distributed.run`
* Make `torch.distributed.launch` not use error-propagation
* Set default events handler to `null` that does not print events to console
* Add reference from `torch.distributed.launch` to `torch.distributed.run`
* Set correct preexec function that sends SIGTERM to child processes when parent dies
Issues resolved:
https://github.com/pytorch/pytorch/issues/60716https://github.com/pytorch/pytorch/issues/60754
Test Plan:
sandcastle
python -m torch.distributed.launch --nproc_per_node 2 main.py -> uses 0 restarts
python -m torch.distributed.run --nproc_per_node 2 main.py -> uses default for torchelastic, 0 restarts
python -m torch.distributed.launch --nproc_per_node=4 --use_env --no_python main.py -> produces error
python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py -> no warning
python -m torch.distributed.launch --nproc_per_node=4 --no_python main.py ->warning
Output of running torch.distributed.launch without --use_env:
$path/torch/distributed/launch.py:173: FutureWarning: The module torch.distributed.launch is deprecated
and will be removed in future. Use torch.distributed.run.
Note that --use_env is set by default in torch.distributed.run.
If your script expects `--local_rank` argument to be set, please
change it to read from `os.environ('LOCAL_RANK')` instead.
New section:
{F628923078}
{F628974089}
Reviewed By: cbalioglu
Differential Revision: D29559553
fbshipit-source-id: 03ed9ba638bf154354e1530ffc964688431edf6b
Summary:
Trying to run the doctests for the complete documentation hangs if it reaches the examples of `torch.futures`. It turns out to be only syntax errors, which are normally just reported. My guess is that `doctest` probably doesn't work well for failures within async stuff.
Anyway, while debugging this, I fixed the syntax.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61029
Reviewed By: mruberry
Differential Revision: D29571923
Pulled By: mrshenli
fbshipit-source-id: bb8112be5302c6ec43151590b438b195a8f30a06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60925
* Make `torch.distributed.launch` restarts to 0
* Remove unnecessary `-use_env` warning, move `-use_env` warnings
* Move `-use_env` warnings to `torch.distributed.launch`
* Make default log level WARNING
* Add new doc section around transitioning to `torch.distributed.run`
* Make `torch.distributed.launch` not use error-propagation
* Set default events handler to `null` that does not print events to console
* Add reference from `torch.distributed.launch` to `torch.distributed.run`
* Set correct preexec function that sends SIGTERM to child processes when parent dies
Issues resolved:
https://github.com/pytorch/pytorch/issues/60716https://github.com/pytorch/pytorch/issues/60754
Test Plan:
sandcastle
python -m torch.distributed.launch --nproc_per_node 2 main.py -> uses 0 restarts
python -m torch.distributed.run --nproc_per_node 2 main.py -> uses default for torchelastic, 0 restarts
python -m torch.distributed.launch --nproc_per_node=4 --use_env --no_python main.py -> produces error
python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py -> no warning
python -m torch.distributed.launch --nproc_per_node=4 --no_python main.py ->warning
Output of running torch.distributed.launch without --use_env:
$path/torch/distributed/launch.py:173: FutureWarning: The module torch.distributed.launch is deprecated
and will be removed in future. Use torch.distributed.run.
Note that --use_env is set by default in torch.distributed.run.
If your script expects `--local_rank` argument to be set, please
change it to read from `os.environ('LOCAL_RANK')` instead.
New section:
{F628923078}
{F628974089}
Reviewed By: kiukchung, cbalioglu
Differential Revision: D29413019
fbshipit-source-id: 323bfbad9d0e4aba3b10ddd7a243ca6e48169630
Summary:
Based from https://github.com/pytorch/pytorch/pull/50466
Adds the initial implementation of `torch.cov` similar to `numpy.cov`. For simplicity, we removed support for many parameters in `numpy.cov` that are either redundant such as `bias`, or have simple workarounds such as `y` and `rowvar`.
cc PandaBoi
closes https://github.com/pytorch/pytorch/issues/19037
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58311
Reviewed By: jbschlosser
Differential Revision: D29431651
Pulled By: heitorschueroff
fbshipit-source-id: 167dea880f534934b145ba94291a9d634c25b01b
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}