This PR moves the definitions for:
* `sym_int`
* `sym_ceil` (used only for `sym_int`)
* `sym_floor` (used only for `sym_int`)
* `sym_float`
from `torch/fx/experimental/symbolic_shapes.py` to `torch/__init__.py`, where `SymInt` and `SymFloat` are already defined.
This removes the need for several in-line imports, and enables proper JIT script gating for #91318. I'm very open to doing this in a better way!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91317
Approved by: https://github.com/ezyang, https://github.com/anijain2305
Summary: Introduce causal mask
This PR introduces a causal mask option _causal_mask (as well as causal mask detection if attn_mask is provided), since current custom kernels do not support arbitrary masks.
Test Plan: sandcastle & github ci/cd
Differential Revision: D41723137
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90508
Approved by: https://github.com/albanD
Continuation after https://github.com/pytorch/pytorch/pull/90163.
Here is a script I used to find all the non-existing arguments in the docstrings (the script can give false positives in presence of *args/**kwargs or decorators):
_Edit:_
I've realized that the indentation is wrong for the last `break` in the script, so the script only gives output for a function if the first docstring argument is wrong. I'll create a separate PR if I find more issues with corrected script.
``` python
import ast
import os
import docstring_parser
for root, dirs, files in os.walk('.'):
for name in files:
if root.startswith("./.git/") or root.startswith("./third_party/"):
continue
if name.endswith(".py"):
full_name = os.path.join(root, name)
with open(full_name, "r") as source:
tree = ast.parse(source.read())
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
all_node_args = node.args.args
if node.args.vararg is not None:
all_node_args.append(node.args.vararg)
if node.args.kwarg is not None:
all_node_args.append(node.args.kwarg)
if node.args.posonlyargs is not None:
all_node_args.extend(node.args.posonlyargs)
if node.args.kwonlyargs is not None:
all_node_args.extend(node.args.kwonlyargs)
args = [a.arg for a in all_node_args]
docstring = docstring_parser.parse(ast.get_docstring(node))
doc_args = [a.arg_name for a in docstring.params]
clean_doc_args = []
for a in doc_args:
clean_a = ""
for c in a.split()[0]:
if c.isalnum() or c == '_':
clean_a += c
if clean_a:
clean_doc_args.append(clean_a)
doc_args = clean_doc_args
for a in doc_args:
if a not in args:
print(full_name, node.lineno, args, doc_args)
break
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90505
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
`torch.compile` can be used either as decorator or to optimize model directly, for example:
```
@torch.compile
def foo(x):
return torch.sin(x) + x.max()
```
or
```
mod = torch.nn.ReLU()
optimized_mod = torch.compile(mod, mode="max-autotune")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89607
Approved by: https://github.com/soumith
Using the same repro from the issue (but with BatchNorm2D)
Rectifies native_batch_norm schema by splitting the schema into 2:
1. one will have NON-optional alias-able running_mean and running_var inputs
2. the other will just not have those parameters at all (no_stats variation)
**Calling for name suggestions!**
## test plan
I've added tests in test_functionalization.py as well as an entry in common_method_invocations.py for `native_batch_norm_legit`
CI should pass.
## next steps
Because of bc/fc reasons, we reroute native_batch_norm to call our new schemas ONLY through the python dispatcher, but in 2 weeks or so, we should make `native_batch_norm_legit` the official batch_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88697
Approved by: https://github.com/albanD
Summary: In order to make the layer normalization implementation for nested tensors public, it needs to be generalized to accept a normalized_shape argument instead of assuming it to be the last dimension of the nested_tensor. This commit does that, as well as adding extra unit tests to ensure the implementation is correct.
Test Plan:
All unit tests designed to test different ways of using the function work:
`buck test //caffe2/test:nested -- test_layer_norm`
Differential Revision: D40105207
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86295
Approved by: https://github.com/drisspg
Based on @ezyang's suggestion, mode stack now has "one true mode" which is the _only_ mode that can ever be active at the C++ level. That mode's torch dispatch is just to take the top mode in the stack, reenable itself (if we aren't at the end of the mode stack), and run the top mode's torch_{dispatch|function}
This maintains that in the middle of a mode's torch dispatch, the mode itself will not be active. It changes the function the user has to call to see what the current mode is (no longer queries the C++, it's python only) but allows the user to also see the entire mode stack easily
Removes `enable_torch_dispatch_mode` and `.restore()` since neither makes sense in this new setup
### Background
Why do we want this? Well, a pretty common pattern that was coming up was that users had to do something like
```python
## PRE-PR UX
def f(mode):
with mode.restore(): # user needs to understand this restore thing?
...
with Mode() as m:
pass
f(m)
```
Many users were getting error from forgetting to call `.restore` or from forgetting to add the (tbh weird) "mode instantiation" step where they use the mode as a context manager with an empty body. Really, they wanted to treat modes like context managers and just write
```python
## FROM FEEDBACK, USER DESIRED CODE. POSSIBLE POST-PR
def f(mode):
with mode:
...
f(Mode())
```
** Technical Details **
With the old mode stack, we basically had a linked list so the mode itself could only be used once and had a fixed parent. In this new design, the mode stack is just a python list that we're pushing to and popping from. There's only one mode that's ever active at the C++ level and it runs the next mode in the Python list. The modes don't have state on them anymore
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84774
Approved by: https://github.com/ezyang, https://github.com/zou3519
As per the title. Fixes: #81161
- [x] add ErrorInputs
- ~[ ] dtype argument?~
- ~[ ] casting argument?~
As discussed offline with @kshitij12345, we can currently ignore `dtype` and `casting` arguments.
cc: @kshitij12345!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82946
Approved by: https://github.com/mruberry
unflatten now has a free function version in torch.flatten in addition to
the method in torch.Tensor.flatten.
Updated docs to reflect this and polished them a little.
For consistency, changed the signature of the int version of unflatten in
native_functions.yaml.
Some override tests were failing because unflatten has unusual
characteristics in terms of the .int and .Dimname versions having
different number of arguments so this required some changes
to test/test_override.py
Removed support for using mix of integer and string arguments
when specifying dimensions in unflatten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81399
Approved by: https://github.com/Lezcano, https://github.com/ngimel
Currently we have 2 ways of doing the same thing for torch dispatch and function modes:
`with push_torch_dispatch_mode(X)` or `with X.push(...)`
is now the equivalent of doing
`with X()`
This removes the first API (which is older and private so we don't need to go through a deprecation cycle)
There is some risk here that this might land race with a PR that uses the old API but in general it seems like most are using the `with X()` API or `enable_torch_dispatch_mode(X())` which isn't getting removed.
EDIT: left the `with X.push(...)` API since there were ~3 land races with that over the past day or so. But made it give a warning and ask users to use the other API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78215
Approved by: https://github.com/ezyang
This PR adds support for `SymInt`s in python. Namely,
* `THPVariable_size` now returns `sym_sizes()`
* python arg parser is modified to parse PyObjects into ints and `SymbolicIntNode`s
* pybind11 bindings for `SymbolicIntNode` are added, so size expressions can be traced
* a large number of tests added to demonstrate how to implement python symints.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78135
Approved by: https://github.com/ezyang
This PR heavily simplifies the code of `linalg.solve`. At the same time,
this implementation saves quite a few copies of the input data in some
cases (e.g. A is contiguous)
We also implement it in such a way that the derivative goes from
computing two LU decompositions and two LU solves to no LU
decompositions and one LU solves. It also avoids a number of unnecessary
copies the derivative was unnecessarily performing (at least the copy of
two matrices).
On top of this, we add a `left` kw-only arg that allows the user to
solve `XA = B` rather concisely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74046
Approved by: https://github.com/nikitaved, https://github.com/IvanYashchuk, https://github.com/mruberry
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77634
Approved by: https://github.com/malfet
```Python
chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the third kind $V_{n}(\text{input})$.
```Python
chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the fourth kind $W_{n}(\text{input})$.
```Python
legendre_polynomial_p(input, n, *, out=None) -> Tensor
```
Legendre polynomial $P_{n}(\text{input})$.
```Python
shifted_chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the first kind $T_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_u(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the second kind $U_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the third kind $V_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the fourth kind $W_{n}^{\ast}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78304
Approved by: https://github.com/mruberry
Adds:
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $0$, $J_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $1$, $J_{1}(\text{input})$.
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $0$, $Y_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $1$, $Y_{1}(\text{input})$.
```Python
modified_bessel_i0(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $0$, $I_{0}(\text{input})$.
```Python
modified_bessel_i1(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $1$, $I_{1}(\text{input})$.
```Python
modified_bessel_k0(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $0$, $K_{0}(\text{input})$.
```Python
modified_bessel_k1(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $1$, $K_{1}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78451
Approved by: https://github.com/mruberry
Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
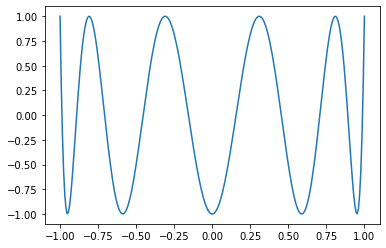
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
Euler beta function:
```Python
torch.special.beta(input, other, *, out=None) → Tensor
```
`reentrant_gamma` and `reentrant_ln_gamma` implementations (using Stirling’s approximation) are provided. I started working on this before I realized we were missing a gamma implementation (despite providing incomplete gamma implementations). Uses the coefficients computed by Steve Moshier to replicate SciPy’s implementation. Likewise, it mimics SciPy’s behavior (instead of the behavior in Cephes).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78031
Approved by: https://github.com/mruberry
We don't have any coverage for meta tensor correctness for backwards
because torch function mode can only allow us to interpose on
Python torch API calls, but backwards invocations happen from C++.
To make this possible, I add torch_dispatch_meta test which runs the
tests with __torch_dispatch__
While doing this, I needed to generate fresh expected failure / skip
lists for the new test suite, and I discovered that my original
scaffolding for this purpose was woefully insufficient. So I rewrote
how the test framework worked, and at the same time rewrote the
__torch_function__ code to also use the new logic. Here's whats
new:
- Expected failure / skip is now done on a per function call basis,
rather than the entire test. This means that separate OpInfo
samples for a function don't affect each other.
- There are now only two lists: expect failure list (where the test
consistently fails on all runs) and skip list (where the test
sometimes passes and fails.
- We explicitly notate the dtype that failed. I considered detecting
when something failed on all dtypes, but this was complicated and
listing everything out seemed to be nice and simple. To keep the
dtypes short, I introduce a shorthand notation for dtypes.
- Conversion to meta tensors is factored into its own class
MetaConverter
- To regenerate the expected failure / skip lists, just run with
PYTORCH_COLLECT_EXPECT and filter on a specific test type
(test_meta or test_dispatch_meta) for whichever you want to update.
Other misc fixes:
- Fix max_pool1d to work with BFloat16 in all circumstances, by making
it dispatch and then fixing a minor compile error (constexpr doesn't
work with BFloat16)
- Add resolve_name for turning random torch API functions into string
names
- Add push classmethod to the Mode classes, so that you can more easily
push a mode onto the mode stack
- Add some more skips for missing LAPACK
- Added an API to let you query if there's already a registration for
a function, added a test to check that we register_meta for all
decompositions (except detach, that decomp is wrong lol), and then
update all the necessary sites to make the test pass.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77477
Approved by: https://github.com/zou3519
This PR adds `linalg.vander`, the linalg version of `torch.vander`.
We add autograd support and support for batched inputs.
We also take this chance to improve the docs (TODO: Check that they
render correctly!) and add an OpInfo.
**Discussion**: The current default for the `increasing` kwargs is extremely
odd as it is the opposite of the classical definition (see
[wiki](https://en.wikipedia.org/wiki/Vandermonde_matrix)). This is
reflected in the docs, where I explicit both the odd defaults that we
use and the classical definition. See also [this stackoverflow
post](https://stackoverflow.com/a/71758047/5280578), which shows how
people are confused by this defaults.
My take on this would be to correct the default to be `increasing=True`
and document the divergence with NumPy (as we do for other `linalg`
functions) as:
- It is what people expect
- It gives the correct determinant called "the Vandermonde determinant" rather than (-1)^{n-1} times the Vandermonde det (ugh).
- [Minor] It is more efficient (no `flip` needed)
- Since it's under `linalg.vander`, it's strictly not a drop-in replacement for `np.vander`.
We will deprecate `torch.vander` in a PR after this one in this stack
(once we settle on what's the correct default).
Thoughts? mruberry
cc kgryte rgommers as they might have some context for the defaults of
NumPy.
Fixes https://github.com/pytorch/pytorch/issues/60197
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76303
Approved by: https://github.com/albanD, https://github.com/mruberry
This PR adds `linalg.lu_solve`. While doing so, I found a bug in MAGMA
when calling the batched MAGMA backend with trans=True. We work around
that by solving the system solving two triangular systems.
We also update the heuristics for this function, as they were fairly
updated. We found that cuSolver is king, so luckily we do not need to
rely on the buggy backend from magma for this function.
We added tests testing this function left and right. We also added tests
for the different backends. We also activated the tests for AMD, as
those should work as well.
Fixes https://github.com/pytorch/pytorch/issues/61657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72935
Approved by: https://github.com/IvanYashchuk, https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
This PR adds `linalg.vander`, the linalg version of `torch.vander`.
We add autograd support and support for batched inputs.
We also take this chance to improve the docs (TODO: Check that they
render correctly!) and add an OpInfo.
**Discussion**: The current default for the `increasing` kwargs is extremely
odd as it is the opposite of the classical definition (see
[wiki](https://en.wikipedia.org/wiki/Vandermonde_matrix)). This is
reflected in the docs, where I explicit both the odd defaults that we
use and the classical definition. See also [this stackoverflow
post](https://stackoverflow.com/a/71758047/5280578), which shows how
people are confused by this defaults.
My take on this would be to correct the default to be `increasing=True`
and document the divergence with NumPy (as we do for other `linalg`
functions) as:
- It is what people expect
- It gives the correct determinant called "the Vandermonde determinant" rather than (-1)^{n-1} times the Vandermonde det (ugh).
- [Minor] It is more efficient (no `flip` needed)
- Since it's under `linalg.vander`, it's strictly not a drop-in replacement for `np.vander`.
We will deprecate `torch.vander` in a PR after this one in this stack
(once we settle on what's the correct default).
Thoughts? mruberry
cc kgryte rgommers as they might have some context for the defaults of
NumPy.
Fixes https://github.com/pytorch/pytorch/issues/60197
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76303
Approved by: https://github.com/albanD
This PR adds a function for computing the LDL decomposition and a function that can solve systems of linear equations using this decomposition. The result of `torch.linalg.ldl_factor_ex` is in a compact form and it's required to use it only through `torch.linalg.ldl_solve`. In the future, we could provide `ldl_unpack` function that transforms the compact representation into explicit matrices.
Fixes https://github.com/pytorch/pytorch/issues/54847.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69828
Approved by: https://github.com/Lezcano, https://github.com/mruberry, https://github.com/albanD
crossref is a new strategy for performing tests when you want
to run a normal PyTorch API call, separately run some variation of
the API call (e.g., same thing but all the arguments are meta tensors)
and then cross-reference the results to see that they are consistent.
Any logic you add to CrossRefMode will get run on *every* PyTorch API
call that is called in the course of PyTorch's test suite. This can
be a good choice for correctness testing if OpInfo testing is not
exhaustive enough.
For now, the crossref test doesn't do anything except verify that
we can validly push a mode onto the torch function mode stack for all
functions.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75988
Approved by: https://github.com/seemethere
I figured these out by unconditionally turning on a no-op torch function
mode on the test suite and then fixing errors as they showed up. Here's
what I found:
- _parse_to failed internal assert when __torch_function__'ed because it
claims its name is "to" to the argument parser; added a name override
so we know how to find the correct name
- Infix operator magic methods on Tensor did not uniformly handle
__torch_function__ and TypeError to NotImplemented. Now, we always
do the __torch_function__ handling in
_wrap_type_error_to_not_implemented and your implementation of
__torch_function__ gets its TypeErrors converted to NotImplemented
(for better or for worse; see
https://github.com/pytorch/pytorch/issues/75462 )
- A few cases where code was incorrectly testing if a Tensor was
Tensor-like in the wrong way, now use is_tensor_like (in grad
and in distributions). Also update docs for has_torch_function to
push people to use is_tensor_like.
- is_grads_batched was dropped from grad in handle_torch_function, now
fixed
- Report that you have a torch function even if torch function is
disabled if a mode is enabled. This makes it possible for a mode
to return NotImplemented, pass to a subclass which does some
processing and then pass back to the mode even after the subclass
disables __torch_function__ (so the tensors are treated "as if"
they are regular Tensors). This brings the C++ handling behavior
in line with the Python behavior.
- Make the Python implementation of overloaded types computation match
the C++ version: when torch function is disabled, there are no
overloaded types (because they all report they are not overloaded).
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75484
Approved by: https://github.com/zou3519
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74226
Update signature of `scatter_reduce_` to match `scatter_/scatter_add_`
`Tensor.scatter_reduce_(int64 dim, Tensor index, Tensor src, str reduce)`
- Add new reduction options in ScatterGatherKernel.cpp and update `scatter_reduce` to call into the cpu kernel for `scatter.reduce`
- `scatter_reduce` now has the same shape constraints as `scatter_` and `scatter_add_`
- Migrate `test/test_torch.py:test_scatter_reduce` to `test/test_scatter_gather_ops.py`
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D35222842
Pulled By: mikaylagawarecki
fbshipit-source-id: 84930add2ad30baf872c495251373313cb7428bd
(cherry picked from commit 1b45139482e22eb0dc8b6aec2a7b25a4b58e31df)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74691
The wrapper just called through to methods on the underlying Tensor.
ghstack-source-id: 152433754
Test Plan: existing tests
Reviewed By: ezyang
Differential Revision: D34689789
fbshipit-source-id: cf53476780cf3ed00a3aa4add441300bfe8e27ce
(cherry picked from commit 5a9e5eb6bc13eb30be6e3c3bc4ac954c92704198)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73999
Seems to be the typical way to detect a flavor of TensorImpl.
ghstack-source-id: 151440167
Test Plan: Existing tests?
Reviewed By: ezyang
Differential Revision: D34665269
fbshipit-source-id: 5081a00928933e0c5252eeddca43bae0b026013d
(cherry picked from commit 7cf62a3f69f158a33c5108f7e96ea4c5520f0f15)
I was working on an explanation of how to call into the "super"
implementation of some given ATen operation inside of __torch_dispatch__
(https://github.com/albanD/subclass_zoo/blob/main/trivial_tensors.py)
and I kept thinking to myself "Why doesn't just calling super() on
__torch_dispatch__ work"? Well, after this patch, it does! The idea
is if you don't actually unwrap the input tensors, you can call
super().__torch_dispatch__ to get at the original behavior.
Internally, this is implemented by disabling PythonKey and then
redispatching. This implementation of disabled_torch_dispatch is
not /quite/ right, and some reasons why are commented in the code.
There is then some extra work I have to do to make sure we recognize
disabled_torch_dispatch as the "default" implementation (so we don't
start slapping PythonKey on all tensors, including base Tensors),
which is modeled the same way as how disabled_torch_function is done.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73684
Approved by: albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72944
Doesn't make sense to develop it in core right now.
ghstack-source-id: 149456040
Test Plan:
CI
run MHA benchmark in benchmark_transformers.py to make sure it doesn't crash
Reviewed By: zrphercule
Differential Revision: D34283104
fbshipit-source-id: 4f0c7a6bc066f938ceac891320d4cf4c3f8a9cd6
(cherry picked from commit b9df65e97c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72200
This op should still remain private in release 1.11, add underscore before op name to make it happens
Test Plan: buck run mode/opt -c fbcode.enable_gpu_sections=true pytext/fb/tools:benchmark_transformers -- mha --batch-size=10 --max-sequence-length=16
Reviewed By: bdhirsh
Differential Revision: D33952191
fbshipit-source-id: 3f8525ac9c23bb286f51476342113ebc31b8ed59
(cherry picked from commit 6e41bfa4fc)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70649
As described in https://fb.quip.com/oxpiA1uDBjgP
This implements the first parts of the RFC, and is a rough draft showing the approach. The idea is that for the first cut we can maintain very close (identical I believe in this diff) numerical equivalence to the existing nn.MHA implementation, which is what this diff attempts to do. In subsequent implementations, once we have a working and adopted native self-attention implementation, we could then explore alternative implementations, etc.
The current implementation is similar to existing dedicated implementations such as LightSeq/FasterTransformer/DeepSpeed, and for MHA on both CPUs and GPUs is between 1.2x and 2x faster depending on the setting. It makes some approximations/restrictions (doesn't handle masking in masked softmax, etc), but these shouldn't materially impact performance.
This does the first few items:
* add native_multi_head_attention(...) , native_multi_head_attention_backward(..) to native_functions.yaml
* Implement native_multi_head_attention(..) on GPU, extracting bits and pieces out of LS/DS/FT as appropriate
* Implement native_multi_head_attention(..) on CPU
The backward implementation is still WIP, but the idea would be to:
* Hook these up in derivatives.yaml
Implement native_multi_head_attention_backward(..) on GPU, extracting out bits and pieces out of LS/DS (not FT since it’s inference only)
* Implement native_multi_head_attention_backward(..) on CPU
* In torch.nn.functional.multi_head_attention_forward 23321ba7a3/torch/nn/functional.py (L4953), add some conditionals to check if we are being called in a BERT/ViT-style encoder fashion, and invoke the native function directly.
Test Plan: TODO
Reviewed By: mikekgfb
Differential Revision: D31829981
fbshipit-source-id: c430344d91ba7a5fbee3138e50b3e62efbb33d96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69327
Original commit changeset: d44096d88265
Original Phabricator Diff: D32144240 (668574af4a)
Test Plan:
CI
original diff failed 175 builds in CI
Reviewed By: airboyang, anjali411
Differential Revision: D32809407
fbshipit-source-id: c7c8e69bcee0274992e2d5da901f035332e60071
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
{kind=link}
{kind=link}