Support fused_sgd_kernel support for CPU.
## Bench result:
32 core/sockets ICX
Test Scripts:
https://gist.github.com/zhuhaozhe/688763e17e93e4c5e12f25f676ec90d9https://gist.github.com/zhuhaozhe/ad9938694bc7fae8b66d376f4dffc6c9
```
Tensor Size: 262144, Num Tensor 4, Num Threads: 1
_single_tensor_sgd time: 0.2301 seconds
_fused_sgd time: 0.0925 seconds
Tensor Size: 4194304, Num Tensor 32, Num Threads: 32
_single_tensor_sgd time: 2.6195 seconds
_fused_sgd time: 1.7543 seconds
```
## Test Plan:
```
python test_optim.py -k test_fused_matches_forloop
python test_optim.py -k test_fused_large_tensor
python test_optim.py -k test_can_load_older_state_dict
python test_optim.py -k test_grad_scaling_autocast_fused_optimizers
python test_torch.py -k test_grad_scaling_autocast_fused
python test_torch.py -k test_params_invalidated_with_grads_invalidated_between_unscale_and_step
```
Looks like we already have some PRs under this issue https://github.com/pytorch/pytorch/issues/123451 to unified the UTs, I did not modified UT in this PR.
Co-authored-by: Jane Xu <janeyx@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123629
Approved by: https://github.com/jgong5, https://github.com/janeyx99
This is a reland of https://github.com/pytorch/pytorch/pull/100007 with a build fix for Windows debug builds.
`at::native::ParamsHash` only works on structs with standard layout, but `std::string` isn't one in Visual C++ debug builds, which one can easily verified by running something like:
```cpp
#define _DEBUG
#include <type_traits>
#include <string>
static_assert(std::is_standard_layout_v<std::string>, "Oh noes");
```
If above conditon is not met, instead of printing a static_assert output, VC++ raises a very cryptic compilation errors, see https://github.com/pytorch/pytorch/pull/100007#discussion_r1227116292 for more detail.
Also, using `std::hash` for string should result in a faster hash function.
(cherry picked from commit 74b7a6c75e)
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 5914771</samp>
This pull request introduces a new function `_group_tensors_by_device_and_dtype` that can group tensors by their device and dtype, and updates the `foreach` utilities and several optimizers to use this function. The goal is to improve the performance, readability, and compatibility of the code that handles tensors with different properties. The pull request also adds a test case and type annotations for the new function, and some error checks for the `fused` argument in Adam and AdamW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103912
Approved by: https://github.com/janeyx99
Big OOP correction continued. Also added a test this time to verify the defaulting was as expected.
The key here is realizing that the grouping for foreach already assumes that the non-param tensorlists follow suit in dtype and device, so it is too narrow to check that _all_ tensors were on CUDA. The main leeway this allowed was state_steps, which are sometimes cpu tensors. Since foreach _can_ handle cpu tensors, this should not introduce breakage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95820
Approved by: https://github.com/albanD
Rolling back the default change for Adam and rectifying the docs to reflect that AdamW never defaulted to fused.
Since our fused implementations are relatively newer, let's give them a longer bake-in time before flipping the switch for every user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95241
Approved by: https://github.com/ngimel
This allows it so that ONLY when the users don't set anything for foreach or fused do we switch the default and cascades adam so that we default to fused, then foreach, then single-tensor.
To clarify:
* if the user puts True in foreach _only_, it will run the foreach implementation.
* if the user puts True in fused _only_, it will run the fused implementation.
* if the user puts True in foreach AND for fused, it will run the fused implementation.
And:
* if the user puts False in foreach _only_, it will run the single tensor implementation.
* if the user puts False in fused _only_, it will still run the single tensor implementation.
* if the user puts False in foreach AND for fused, it will run the single tensor implementation.
I also didn't trust myself that much with the helper function, so I ran some local asserts on _default_to_fused_or_foreach. The only point left to really test is the type(p) -- torch.Tensor but I think the distributed tests will catch that in CI.
```
cuda_only_fp_list = [
torch.rand((1, 2), device="cuda", dtype=torch.float32),
torch.rand((1, 2), device="cuda", dtype=torch.float64),
torch.rand((1, 2), device="cuda", dtype=torch.float16),
torch.rand((1, 2), device="cuda", dtype=torch.bfloat16),
]
cuda_only_int_list = [
torch.randint(1024, (1, 2), device="cuda", dtype=torch.int64),
]
cpu_list = [
torch.rand((1, 2), device="cpu", dtype=torch.float32),
torch.rand((1, 2), device="cpu", dtype=torch.float64),
torch.rand((1, 2), device="cpu", dtype=torch.float16),
]
none_list = [None]
# differentiable should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, False) == (False, False)
# cpu lists should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, False) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, False) == (False, False)
# has fused triggers correctly
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, False) == (False, True)
# ints always goes to foreach
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, False) == (False, True)
# Nones don't error
assert _default_to_fused_or_foreach([cuda_only_fp_list, none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list, none_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([none_list], False, False) == (False, True)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93184
Approved by: https://github.com/albanD
Doing some tests with all Optimizer and LRScheduler classes in optim package, I noticed a couple of mistakes in type annotations, so created a pull request to fix them.
- In Optimizer class, incorrectly named parameter `default` instead of `defaults` in pyi file
- In SGD class, type for `maximize` and `differentiable` not available in either py or pyi files
I don't know if there is a plan to move all types from pyi to py files, so wasn't too sure where to fix what.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90216
Approved by: https://github.com/janeyx99
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
Adds the `differentiable` argument, a method for updating parameters in an existing optimizer, and a template for testing the differentiability of multiple optimizers.
This is all based in discussions with @albanD & @jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80938
Approved by: https://github.com/albanD
Generator comprehensions with any/all are less verbose and potentially help to save memory/CPU : https://eklitzke.org/generator-comprehensions-and-using-any-and-all-in-python
To make JIT work with this change, I added code to convert GeneratorExp to ListComp. So the whole PR is basically NoOp for JIT, but potentially memory and speed improvement for eager mode.
Also I removed a test from test/jit/test_parametrization.py. The test was bad and had a TODO to actually implement and just tested that UnsupportedNodeError is thrown, and with GeneratorExp support a different error would be thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78142
Approved by: https://github.com/malfet, https://github.com/albanD
Summary:
After 'maximize' flag was introduced in https://github.com/pytorch/pytorch/issues/46480 some jobs fail because they resume training from the checkpoints.
After we load old checkpoints we will get an error during optimizer.step() call during backward pass in [torch/optim/sgd.py", line 129] because there is no key 'maximize' in the parameter groups of the SGD.
To circumvent this I add a default value `group.setdefault('maximize', False)` when the optimizer state is restored.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68733
Reviewed By: albanD
Differential Revision: D32480963
Pulled By: asanakoy
fbshipit-source-id: 4e367fe955000a6cb95090541c143a7a1de640c2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46480 -- for SGD.
## Notes:
- I have modified the existing tests to take a new `constructor_accepts_maximize` flag. When this is set to true, the ` _test_basic_cases_template` function will test both maximizing and minimizing the sample function.
- This was the clearest way I could think of testing the changes -- I would appreciate feedback on this strategy.
## Work to be done:
[] I need to update the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67847
Reviewed By: H-Huang
Differential Revision: D32252631
Pulled By: albanD
fbshipit-source-id: 27915a3cc2d18b7e4d17bfc2d666fe7d2cfdf9a4
Summary:
It has been discussed before that adding description of Optimization algorithms to PyTorch Core documentation may result in a nice Optimization research tutorial. In the following tracking issue we mentioned about all the necessary algorithms and links to the originally published paper https://github.com/pytorch/pytorch/issues/63236.
In this PR we are adding description of Stochastic Gradient Descent to the documentation.
<img width="466" alt="SGDalgo" src="https://user-images.githubusercontent.com/73658284/132585881-b351a6d4-ece0-4825-b9c0-126d7303ed53.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63805
Reviewed By: albanD
Differential Revision: D30818947
Pulled By: iramazanli
fbshipit-source-id: 3812028e322c8a64f4343552b0c8c4582ea382f3
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51316
Make optim functional API be private until we release with beta
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26213469
fbshipit-source-id: b0fd001a8362ec1c152250bcd57c7205ed893107
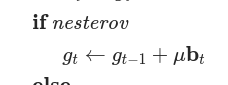{kind=link}
{kind=link}