Aaron Gokaslan
47dca20d80
[BE] Enable flake8-comprehension rule C417 ( #97880 )
...
Enables flake8-comprehension rule C417. Ruff autogenerated these fixes to the codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97880
Approved by: https://github.com/ezyang , https://github.com/kit1980 , https://github.com/albanD
2023-03-30 14:34:24 +00:00
William Wen
b93e1f377e
[dynamo, benchmarks] Add inductor-mode (for max-autotune) and warm start options to dynamo benchmarks ( #97719 )
...
Title.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97719
Approved by: https://github.com/shunting314
2023-03-29 21:09:00 +00:00
Edward Z. Yang
f754be897a
Disable speedup_experiment_ds ( #97806 )
...
It seems to be broken.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97806
Approved by: https://github.com/jansel
2023-03-29 01:27:31 +00:00
Bin Bao
a9a81ab7e3
[CI] Run benchmark test with dynamo_eager in periodic ( #97543 )
...
Summary: The idea is to catch any dynamo_eager regression earlier, and also
we can take that off the dashboard run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97543
Approved by: https://github.com/huydhn
2023-03-28 01:02:49 +00:00
Shunting Zhang
652592efa9
[inductor] use torch.prifiler in the triton wrapper ( #97405 )
...
I think it's helpful to use torch.profiler to profile the triton wrapper.
E.g., I tried it for nvidia_deeprecommender's infernece graph.
Even with max-autotune, we see the majority of the time the GPU is running 2 mm/addmm op. That's why max autotune does not help for this model since tuning does not affect the external mm ops.
<img width="711" alt="Screenshot 2023-03-22 at 5 49 28 PM" src="https://user-images.githubusercontent.com/52589240/227072474-2f0d7205-4a10-4929-b1b7-551214788c61.png ">
next step I'll check why the triton mm kernels are not picked.
EDIT: the above screenshot is captured without max-autotune due to a typo. below is the trace with max-autotune enabled:
<img width="712" alt="Screenshot 2023-03-22 at 6 43 26 PM" src="https://user-images.githubusercontent.com/52589240/227077624-fdccf928-be08-4211-871b-a9e3d7b76fbe.png ">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97405
Approved by: https://github.com/ngimel
2023-03-27 21:54:25 +00:00
Edward Z. Yang
cff4826f28
pytorch_unet is now passing ( #97309 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97309
Approved by: https://github.com/janeyx99 , https://github.com/zou3519
2023-03-22 13:55:05 +00:00
Bin Bao
be49d3b170
[CI] Turn on debug logging for dla102 and gernet_l ( #97307 )
...
Summary: Log the generated code for those two flaky tests to see if
there is any codegen difference when they fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97307
Approved by: https://github.com/ezyang
2023-03-22 13:42:13 +00:00
Natalia Gimelshein
e7d9331688
[inductor] hoist symbolic padding expressions ( #97099 )
...
Towards fixing pnasnet5large, see #96709 . The generated kernel looks much better
```
@pointwise(size_hints=[1048576], filename=__file__, meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32', 3: 'i32', 4: 'i32', 5: 'i32', 6: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': [], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 6), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, out_ptr0, ks0, ks1, ks2, ks3, xnumel, XBLOCK : tl.constexpr):
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x1 = (xindex // ks0) % ks0
x0 = xindex % ks0
x2 = (xindex // ks3)
x4 = xindex
tmp0 = x1 + ((-1)*ks1)
tmp1 = 0
tmp2 = tmp0 >= tmp1
tmp3 = ks2
tmp4 = tmp0 < tmp3
tmp5 = x0 + ((-1)*ks1)
tmp6 = tmp5 >= tmp1
tmp7 = tmp5 < tmp3
tmp8 = tmp2 & tmp4
tmp9 = tmp8 & tmp6
tmp10 = tmp9 & tmp7
tmp11 = tl.load(in_ptr0 + (x0 + ((-1)*ks1) + (ks2*x1) + (x2*(ks2*ks2)) + ((-1)*ks1*ks2) + tl.zeros([XBLOCK], tl.int32)), tmp10 & xmask, other=0)
tmp12 = tl.where(tmp10, tmp11, 0.0)
tl.store(out_ptr0 + (x4 + tl.zeros([XBLOCK], tl.int32)), tmp12, xmask)
```
Interestingly, removing `expand` in in index `simplify` function makes `load` expression a little bit better, but `store` fails to simplify to flat store in this case, so I'm leaving `expand` in.
Full pnasnet still chokes on `ceiling` in batch_norm kernels, additionally, it looks like shape propagation goofs in inductor and generates overly complicated expressions, we should switch to meta data from fx graph.
I'm still not adding `ceil` print to triton, because we should be able to hoist all indexing expression (and just printing ceil without converting to int64 doesn't work)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97099
Approved by: https://github.com/jansel
2023-03-21 21:43:32 +00:00
Edward Z. Yang
e74c5e5637
rexnet_100 is disabled for static, does not need dynamic listing ( #97100 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97100
Approved by: https://github.com/Skylion007
2023-03-19 20:57:49 +00:00
Bin Bao
577d930c39
[CI] Revert https://github.com/pytorch/pytorch/pull/96195 ( #96897 )
...
Summary: https://github.com/pytorch/pytorch/pull/96195 was an experiment
for debugging flaky failures on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96897
Approved by: https://github.com/ngimel
2023-03-16 06:28:18 +00:00
Edward Z. Yang
3606f59366
Default specialize_int to False ( #96624 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96624
Approved by: https://github.com/janeyx99
2023-03-16 02:54:18 +00:00
Will Constable
54cd4a67d0
Output peak memory stats from dynamo torchbench perf CI ( #95666 )
...
Adds absolute memory usage numbers (in addition to compression ratio) to performance jobs.
Example output:
<img width="1211" alt="image" src="https://user-images.githubusercontent.com/4984825/225419950-500908c5-00ce-4711-afa2-c995bf90d35d.png ">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95666
Approved by: https://github.com/ezyang , https://github.com/williamwen42
2023-03-15 19:24:47 +00:00
Bin Bao
33c7be360f
[reland][CI] switch torchbench to a pinned version ( #96782 )
...
Summary: This is reland of https://github.com/pytorch/pytorch/pull/96553
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96782
Approved by: https://github.com/huydhn
2023-03-15 12:46:36 +00:00
Edward Z. Yang
037acd5a22
Update CI skips ( #96745 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96745
Approved by: https://github.com/wconstab
2023-03-14 22:19:10 +00:00
PyTorch MergeBot
be4eaa69c2
Revert "[CI] switch torchbench to a pinned version ( #96553 )"
...
This reverts commit 61d6ccd29ahttps://github.com/pytorch/pytorch/pull/96553 on behalf of https://github.com/desertfire due to land race
2023-03-14 21:39:45 +00:00
PyTorch MergeBot
ba4fb9b6ad
Revert "Default specialize_int to False ( #96624 )"
...
This reverts commit 1ac8782db2https://github.com/pytorch/pytorch/pull/96624 on behalf of https://github.com/kit1980 due to Broke inductor/test_torchinductor_dynamic_shapes.py
2023-03-14 19:43:47 +00:00
Bin Bao
61d6ccd29a
[CI] switch torchbench to a pinned version ( #96553 )
...
Summary: Previously we were using a branch on torchbench which skips
torchaudio. We should switch to make sure a good test coverage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96553
Approved by: https://github.com/huydhn , https://github.com/ezyang
2023-03-14 18:42:22 +00:00
Edward Z. Yang
1ac8782db2
Default specialize_int to False ( #96624 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96624
Approved by: https://github.com/janeyx99
2023-03-14 18:37:47 +00:00
David Berard
6e3d51b08a
[inductor][CI] also skip rexnet_100 on non-dynamic shapes ( #96691 )
...
Recent failures show rexnet_100 accuracy is flaky also on non-dynamic shapes (was already disabled for dynamic shapes in #96474 ). The failure occurs for the same reason (stem.bn.weight.grad).
e.g. https://github.com/pytorch/pytorch/actions/runs/4402868441/jobs/7710977874
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96691
Approved by: https://github.com/desertfire
2023-03-14 18:11:59 +00:00
Edward Z. Yang
ff7e510d1e
Correctly use PythonPrinter for generating wrapper code referencing sympy ( #96710 )
...
Otherwise you get stuff like ceiling(s0) which is not valid Python code. Fixes volo_d1_224
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96710
Approved by: https://github.com/ngimel , https://github.com/jansel
2023-03-14 14:35:52 +00:00
Wang, Eikan
3cad8d23d0
[Inductor] Skip the hf_T5_base due to intermittent failure on CI ( #96649 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96649
Approved by: https://github.com/desertfire
2023-03-14 07:40:20 +00:00
Edward Z. Yang
507feb805f
Don't specialize torch.Size with specialize_int = False ( #96419 )
...
Fixes https://github.com/pytorch/pytorch/issues/95868
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96419
Approved by: https://github.com/jansel , https://github.com/ngimel
2023-03-14 01:32:58 +00:00
Edward Z. Yang
c7f39c0820
Update CI skips ( #96554 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96554
Approved by: https://github.com/janeyx99
2023-03-13 13:40:45 +00:00
David Berard
29cd60dfb7
[CI] handle more dynamo benchmark models that are not expected to be deterministic ( #96324 )
...
Follow-up to #96245 . alexnet, Background_Matting, vision_maskrcnn, and vgg16 all have the same problem; but on float32 they were also failing on the previous day so I missed this. Once the amp jobs became available I could see that these have the same issue (on both float32 and amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96324
Approved by: https://github.com/desertfire
2023-03-10 18:15:34 +00:00
Bin Bao
a651e6253a
[CI] Change compile_threads to 1 when running benchmark accuracy test on CI ( #96195 )
...
Summary: This is not a pretty solution, but it a way to verify if the flakiness is coming from parallel compilation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96195
Approved by: https://github.com/ngimel
2023-03-10 17:39:38 +00:00
Edward Z. Yang
ff2e14f200
Skip rexnet_100 in dynamic CI ( #96474 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96474
Approved by: https://github.com/yanboliang , https://github.com/msaroufim
2023-03-10 01:23:19 +00:00
Edward Z. Yang
c988de1040
[EASY] Update inductor training dynamic skips ( #96298 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96298
Approved by: https://github.com/Chillee , https://github.com/janeyx99
2023-03-08 19:31:46 +00:00
Bin Bao
b3a079810e
[CI] Add a workflow for quick perf comparison ( #96166 )
...
Summary: ciflow/inductor-perf-test-nightly now contains full dashboard
run which takes a very long time. Ed proposed a simplification of the
perf run there, but it is still worth to have a set of fast perf test
which only includes one configuration (--training --amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96166
Approved by: https://github.com/huydhn , https://github.com/weiwangmeta
2023-03-08 19:09:04 +00:00
Bin Bao
664381b293
[CI] Avoid calling torch.use_deterministic_algorithms for some models ( #96245 )
...
tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96245
Approved by: https://github.com/davidberard98
2023-03-08 03:35:32 +00:00
Edward Z. Yang
d0641ed247
[TEST] Turn on unspecialize int dynamic training inductor CI ( #96058 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96058
Approved by: https://github.com/janeyx99 , https://github.com/voznesenskym
2023-03-07 16:08:45 +00:00
Edward Z. Yang
a6e3e7905e
Turn on unspecialize int dynamic inductor CI ( #96034 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96034
Approved by: https://github.com/voznesenskym
2023-03-07 12:39:55 +00:00
Jason Ansel
95d17dc93d
[inductor] Reland #95567 part 1 ( #96023 )
...
This is the non-problematic part of #95567 . The errors were coming from
IR printing changes which will be next in the stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96023
Approved by: https://github.com/ngimel , https://github.com/mlazos
2023-03-06 22:57:22 +00:00
Edward Z. Yang
1fd7ea1ba8
Update skips for RecursionError ( #96109 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96109
Approved by: https://github.com/huydhn
2023-03-06 17:55:38 +00:00
Bin Bao
60cf95610d
[CI] Skip xcit_large_24_p8_224 in TIMM ( #96048 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96048
Approved by: https://github.com/jansel
2023-03-05 14:54:46 +00:00
Bin Bao
1359d16fe8
[CI] Further tighten the checking of two eager runs ( #95902 )
...
Summary: To catch nondeterminism in eager if there is any.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95902
Approved by: https://github.com/jansel
2023-03-05 14:53:02 +00:00
Edward Z. Yang
c7c4a20321
Update dynamic skips ( #95966 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95966
Approved by: https://github.com/janeyx99 , https://github.com/voznesenskym
2023-03-04 23:01:58 +00:00
Jason Ansel
43dd043ea7
Revert "[inductor] Improve error messages ( #95567 )" ( #96014 )
...
This reverts commit 62b775583fhttps://github.com/pytorch/pytorch/pull/96014
Approved by: https://github.com/Chillee
2023-03-04 04:03:31 +00:00
Edward Z. Yang
d303665d33
Make int unspecialization actually work ( #95621 )
...
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel , https://github.com/Chillee
2023-03-04 01:22:08 +00:00
Jason Ansel
62b775583f
[inductor] Improve error messages ( #95567 )
...
Example error message before/after (710 to 131 lines):
https://gist.github.com/jansel/6fecad057738089fa95bf08c3de9fc8a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95567
Approved by: https://github.com/mlazos
2023-03-02 02:20:55 +00:00
Bin Bao
879f0c3fee
[CI] Increate the timeout limit for benchmark test ( #95787 )
...
Summary: xcit_large_24_p8_224 occasionally hits TIMEOUT on CI. Bump up
the limit to reduce flakiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95787
Approved by: https://github.com/ezyang , https://github.com/ZainRizvi
2023-03-01 19:54:25 +00:00
Bin Bao
e79b2b7792
[CI] Force clear triton cache between running each test ( #95729 )
...
Summary: The idea is to see if this reduces some of the flakiness
we have seen on CI. If it does help, then we have a problem in our
caching implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95729
Approved by: https://github.com/ngimel
2023-03-01 04:10:03 +00:00
Will Constable
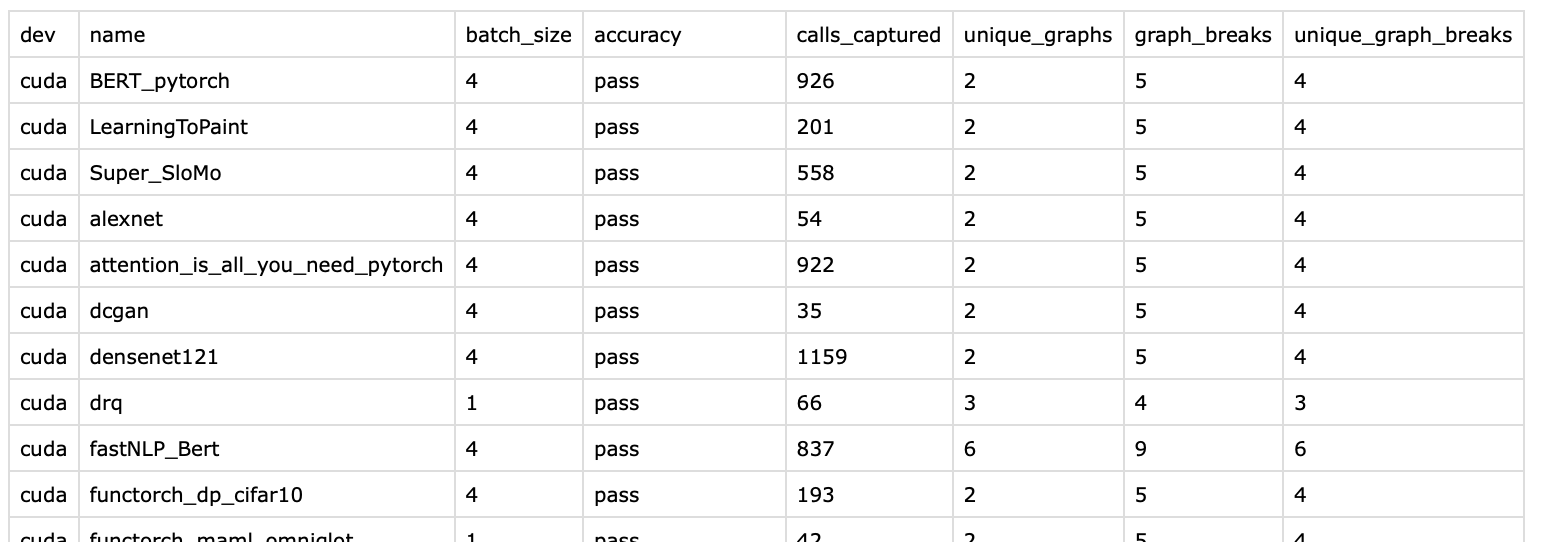
1a72712645
Add dynamo graph break stats to CI ( #95635 )
...
Adds columns to csv produced by accuracy job including dynamo graph break stats.
Example output from torchbench CI job:
<img width="771" alt="image" src="https://user-images.githubusercontent.com/4984825/221716236-9276684e-1be8-43e1-837e-f41671d4e0e3.png ">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95635
Approved by: https://github.com/ezyang
2023-02-28 16:17:46 +00:00
Edward Z. Yang
3762e801ba
Update dynamic skips ( #95587 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95587
Approved by: https://github.com/voznesenskym
2023-02-28 03:26:55 +00:00
Bin Bao
fa5a4b0dfc
[CI] Do not compare two eager run results against fp64 result ( #95616 )
...
Summary: When running the benchmark test with --accuracy, two eager runs
should return the same result. If not, we want to detect it early, but
comparing against fp64_output may hide the non-deterministism in eager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95616
Approved by: https://github.com/ZainRizvi
2023-02-27 20:11:21 +00:00
Bin Bao
ab1ab3ab19
[CI] Specify more torch.backends.cudnn options to reduce non-determinism ( #95478 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95478
Approved by: https://github.com/ezyang
2023-02-25 18:54:12 +00:00
Bin Bao
4c8ad93a7c
[Inductor][CI] Remove hf_GPT2_large from CPU inference test ( #95473 )
...
Summary: hf_GPT2_large shows random failure on CI for the CPU inference. Created https://github.com/pytorch/pytorch/issues/95474 for the Intel team to investigate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95473
Approved by: https://github.com/anijain2305
2023-02-24 18:21:36 +00:00
Will Constable
8de4238a31
Add dynamo bench arg --per_process_memory_fraction ( #95260 )
...
Simply pipes the arg to the existing torch.cuda API by the same name.
Useful for locally debugging OOMs that happened on a smaller GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95260
Approved by: https://github.com/davidberard98
2023-02-22 05:11:18 +00:00
Edward Z. Yang
08370ddad8
Update model skips ( #95089 )
...
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95089
Approved by: https://github.com/albanD
2023-02-20 13:24:49 +00:00
Wang, Eikan
954c767bc6
[Inductor] Enable accuracy test for CPPBackend ( #94898 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94898
Approved by: https://github.com/jgong5 , https://github.com/desertfire
2023-02-20 05:02:15 +00:00
Edward Z. Yang
a2f44d82f8
Flag guard unbacked SymInt/SymFloat support ( #94987 )
...
I believe this fixes the AllenaiLongformerBase problem in periodic.
The longer version of the problem is here is we are currently optimistically converting all item() calls into unbacked SymInt/SymFloat, but sometimes this results in a downstream error due to a data-dependent guard. Fallbacks for this case are non-existent; this will just crash the model. This is bad. So we flag guard until we get working fallbacks.
What could these fallbacks look like? One idea I have is to optimistically make data-dependent calls unbacked, but then if it results in a crash, restart Dynamo analysis with the plan of graph breaking when the item() call immediately happened.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94987
Approved by: https://github.com/Skylion007 , https://github.com/malfet
2023-02-17 00:25:05 +00:00
{kind=link}
{kind=link}
{kind=link}
{kind=link}