Summary:
See internal diff for more changes. Whenever we encounter a non-compliant op,
we add it to a set on the OutputGraph. When a compilation event happens, we log
the contents of this set.
I'm planning on flipping the `only_allow_pt2_compliant_ops` config from False
to True after the logging determines that existing models do not use
non-compliant ops.
Test Plan: - Tested the logging internally locally
Differential Revision: D50884828
Pull Request resolved: https://github.com/pytorch/pytorch/pull/112581
Approved by: https://github.com/yanboliang
I need this for later. This roughly returns all the OpOverloads
for an OpOverloadPacket in the order that the OpOverloadPacket decides
to resolve them in.
Test Plan:
- wait for CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/112198
Approved by: https://github.com/ezyang
Summary:
When raising an exception here this causes pybind11's dispatcher to kick in, which causes aiplatform's logic to kick in (aiplatform::error_reporting::util::printAddressesWithBestEffortLocationInfo), which ultimately uses `folly::symbolizer::Symbolizer::symbolize` for building up the stack trace. In 3.8 this uses about 3.62% of the CPU time per pyperf (https://fburl.com/scuba/pyperf_experimental/on_demand/oi554uvy). In Cinder 3.8 for some reason this is worse - using 5.94% of the CPU.
This exception is happening when doing a hasattr() on `prims` for things like `bitwise_left_shift` which don't exist: https://www.internalfb.com/code/fbsource/[2d695f650d00]/fbcode/caffe2/torch/_inductor/lowering.py?lines=590
That exception is ultimately going to be swallowed anyway, and the stack trace has no meaningful value. Furthermore because this is kind of an expected outcome in the code versus some random C++ exception the stack trace is less valuable as well.
This changes this to return a (None, None) on the failure case instead of returning a valid op/overload list, avoiding the exception, and reclaiming the 3.62%-5.94% of time.
Test Plan: Existing CI and perf run: https://fburl.com/scuba/pyperf_experimental/on_demand/oi554uvy
Differential Revision: D50018789
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111438
Approved by: https://github.com/davidberard98
Fixes#111776
Support check_regex in FileCheck() by adding `find_regex` in `struct TORCH_API StringCordView`.
Callsite accepts RE syntax for std::regex.
However, I haven't figured out submatch ID yet.
For example, "buf5[0], buf6_inputs[0]" is still considered a match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/112077
Approved by: https://github.com/yf225
Removes the existing integration code & build of nvfuser in TorchScript.
Note that I intentionally left the part where we wipe out `third_party/nvfuser` repo. I'll do that in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/111093
Approved by: https://github.com/albanD
We want to be able to use SingletonSymNode to represent strides for Jagged layout tensor. The following is for 3D, but easily generalizable to higher dimensions.
Constraints:
- [B, x, D] (where x represents the "variably lengthed dim") can be strided in two ways [x, 1, sum(x)] and [dx, d, 1]. We need two different placeholder values depending on how the jagged tensor is strided.
- When doing operations we need the strides of output tensors to be expressable in terms of the strides and sizes of the inner tensors. Given [B, x, D] @ [D, D'], the output strides is [x * D', D', 1] rather than some opaque [x2, D', 1]. This constraint exists because if I'm tracing, I need a symint to represent the output stride. This symint needs to come from somewhere; I get it in several ways: (1) create a constant, (2) unbacked symint, (3) create a new input using a source, (4) output of an operation on an existing symint. It is clear that (4) is what we want here, which brings us to the design below.
Design:
Given the two constraints, the most straightforward way to implement this is actually to update SingletonSymNode to include some scalar factor, i.e. Morally, SingletonSymNode represents `factor * [s_0, s_1, …, s_n]` This enables us to symbolically compute strides from sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110369
Approved by: https://github.com/ezyang
ghstack dependencies: #110044
Removing the functionalities from nvfuser python APIs.
Since the use of nvfuser has been deprecated before the last release cut. We are removing torch script support.
I'll have the next PR to actually remove the code base.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110124
Approved by: https://github.com/davidberard98
Bugfix:
- previously, SymBool does not implement `__eq__`, Python falls back to default `__eq__ `and `__hash__`
- in this PR, we make SymBool implement `__eq__`
- symbolic SymBool now raises an error when hashed just like SymInt/SymFloat
New feature:
- previously, SymInt and SymFloat are unhashable (even if you are singleton or constant)
- in this PR, SymInt and SymBool are hashable if singleton/constant
Stay the same:
- SymNode are hashable due to default Python behavior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109170
Approved by: https://github.com/ezyang
ghstack dependencies: #109169
In this PR:
- When Constant SymNode are detected in unary/binary ops demote them to plain int/bool before proceeding. Sometimes this means doing a unary op with a Constant SymNode would result in a plain bool.
- Introduce an is_symbolic method, only available from Python. We need this because isinstance(x, SymInt) is no longer sufficient to check whether a given int/SymInt is symbolic or not. See later PR in the stack to see how this is used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109169
Approved by: https://github.com/ezyang
This commit fixes a memory leak caused by creating a new PyListObject using PyDict_Items() and not releasing that list later. This often prevented the entire model from being de-allocated even when all python references to it have gone out of scope.
Here is a repro script:
```python
import psutil, torch, transformers, gc, os, sys
import math
# Size in MB
model_size = 512
kB = 1024
MB = kB * kB
precision_size = 4 # bytes per float
activation_size = math.floor(math.sqrt(model_size * MB / precision_size))
class Net(torch.nn.Module):
def __init__(self, activation_size):
super(Net, self).__init__()
self.linear = torch.nn.Linear(activation_size, activation_size)
def forward(self, x):
return {"result": self.linear(x)}
def collect_and_report(s):
gc.collect()
print(s)
#print("psutil: ", psutil.virtual_memory().percent)
print("CPU MB used by this process: ", psutil.Process(os.getpid()).memory_info().rss / 1024 ** 2)
print("GPU MB allocated by pytorch: ", torch.cuda.memory_allocated(0) / 1024 ** 2)
print()
def run_test(device_str):
device = torch.device(device_str)
dummy_input = torch.zeros(activation_size, requires_grad=True).to(device)
collect_and_report("Before loading model: ")
model = Net(activation_size).to(device)
collect_and_report("After loading model: ")
torch.onnx.export(model, dummy_input, "dummy.onnx")
collect_and_report("After exporting model: ")
del model
collect_and_report("After deleting model:")
print("Running CPU test: ")
run_test("cpu")
print("Running GPU test: ")
run_test("cuda")
```
Results with this commit:
```
Running CPU test:
Before loading model:
CPU MB used by this process: 346.5
GPU MB allocated by pytorch: 0.0
After loading model:
CPU MB used by this process: 861.078125
GPU MB allocated by pytorch: 0.0
After exporting model:
CPU MB used by this process: 880.12890625
GPU MB allocated by pytorch: 0.0
After deleting model:
CPU MB used by this process: 880.12890625
GPU MB allocated by pytorch: 0.0
Running GPU test:
Before loading model:
CPU MB used by this process: 991.9375
GPU MB allocated by pytorch: 0.04443359375
After loading model:
CPU MB used by this process: 992.19140625
GPU MB allocated by pytorch: 512.0888671875
After exporting model:
CPU MB used by this process: 1026.64453125
GPU MB allocated by pytorch: 520.25830078125
After deleting model:
CPU MB used by this process: 1026.64453125
GPU MB allocated by pytorch: 520.25830078125
```
With this commit:
```
Running CPU test:
Before loading model:
CPU MB used by this process: 372.7734375
GPU MB allocated by pytorch: 0.0
After loading model:
CPU MB used by this process: 887.18359375
GPU MB allocated by pytorch: 0.0
After exporting model:
CPU MB used by this process: 918.96875
GPU MB allocated by pytorch: 0.0
After deleting model:
CPU MB used by this process: 407.3671875
GPU MB allocated by pytorch: 0.0
Running GPU test:
Before loading model:
CPU MB used by this process: 516.6875
GPU MB allocated by pytorch: 0.04443359375
After loading model:
CPU MB used by this process: 516.75390625
GPU MB allocated by pytorch: 512.0888671875
After exporting model:
CPU MB used by this process: 554.25390625
GPU MB allocated by pytorch: 520.2138671875
After deleting model:
CPU MB used by this process: 554.25390625
GPU MB allocated by pytorch: 8.16943359375
```
Fixes#106976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107244
Approved by: https://github.com/BowenBao, https://github.com/kit1980
Summary:
In fbcode, aten and jit ops can get registered in different orders depending on build mode. In dev mode, aten is registered first; in opt mode, jit is registered first.
This causes problems in torch.ops.aten.* calls; these calls use `torch._C._jit_get_operation`, which selects an overload based on the inputs to the call. It searches through the overloads for the op with the given name, and chooses the first one that matches the input types. "First" depends on whether aten or jit ops were registered first - e.g. in `test_both_scalars_cuda` in opt mode, it chooses `add.complex` and returns a complex value.
We also saw this issue in https://github.com/pytorch/pytorch/pull/103576.
This PR sorts the list of overloads first, putting the aten ops first.
Differential Revision: D48304930
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107138
Approved by: https://github.com/ezyang, https://github.com/eellison
This moves the `overloaded_args` field from FunctionSignature to PythonArgs. FunctionSignature is shared by all calls and should be immutable. PythonArgs contains the parsing results for an single call to the PyTorch API.
I did not measure a difference in performance in the "overrides_benchmark", although I expect there to be a bit more work in the common case. Note that the noise factor for the benchmark is much larger than the differences reported below:
Before:
```
Type tensor had a minimum time of 2.3615360260009766 us and a standard deviation of 0.7833134150132537 us.
Type SubTensor had a minimum time of 10.473251342773438 us and a standard deviation of 0.1973132457351312 us.
Type WithTorchFunction had a minimum time of 5.484819412231445 us and a standard deviation of 0.13305981701705605 us.
Type SubWithTorchFunction had a minimum time of 11.098146438598633 us and a standard deviation of 0.15598918253090233 us.
```
After:
```
Type tensor had a minimum time of 2.2134780883789062 us and a standard deviation of 0.802064489107579 us.
Type SubTensor had a minimum time of 10.625839233398438 us and a standard deviation of 0.15155907021835446 us.
Type WithTorchFunction had a minimum time of 5.520820617675781 us and a standard deviation of 0.23115111980587244 us.
Type SubWithTorchFunction had a minimum time of 11.227846145629883 us and a standard deviation of 0.23032321769278497 us.
```
Fixes#106974
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106983
Approved by: https://github.com/zou3519, https://github.com/ezyang, https://github.com/albanD
This pattern shows up in torchrec KeyedJaggedTensor. Most
of the change in this PR is mechanical: whenever we failed
an unbacked symint test due to just error checking, replace the
conditional with something that calls expect_true (e.g.,
torch._check or TORCH_SYM_CHECK).
Some of the changes are a bit more nuanced, I've commented on the PR
accordingly.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106788
Approved by: https://github.com/lezcano
ghstack dependencies: #106720
Here's what it does from the comments:
```
Assume that a boolean is true for the purposes of subsequent symbolic
reasoning. This will keep track of corresponding runtime checks to verify
that the result is upheld: either as a regular guard, or as a special set
of asserts which are triggered when an unbacked SymInt is allocated.
DO NOT use this function for these cases:
- This is inappropriate for "branching" conditions (where both
true and false result in valid programs). We will always assume
the condition evaluates true, and so it will never be possible
to trace the false condition when you use it. For true branching
on unbacked SymInts, you must use torch.cond.
- This is inappropriate for situations where you know some other system
invariant guarantees that this property holds, since you don't
really need to insert a runtime check in that case. Use something
like constrain_range in that case.
This API has a hitch. To avoid having to reimplement error reporting
capabilities, this function CAN return False. The invariant is that
the surrounding code must raise an error when this function returns
False. This is quite low level, so we recommend using other functions
like check() which enforce this in a more intuitive way.
By the way, this name is a nod to the __builtin_expect likely macro,
which is used similarly (but unlike __builtin_expect, you MUST fail
in the unlikely branch.)
```
We don't do anything with this right now, except use it to discharge regular guards. Follow up PRs to (1) use it at important error checking sites, (2) actually ensure the runtime asserts make there way into the exported IR / inductor generated code.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106720
Approved by: https://github.com/ysiraichi, https://github.com/voznesenskym
Using [`nanoGPT/model.py`](https://github.com/karpathy/nanoGPT/blob/master/model.py) run
<details><summary><b>Click for script to save gpt2-xlarge (1.5B params)</b></summary>
```
# test_load_save_gpt.py
from model import GPT
import torch
import time
torch.manual_seed(5)
# gpt2-xlarge 1558M parameters
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
n_layer: int = 48
n_head: int = 25
n_embd: int = 1600
dropout: float = 0.0
bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
def f():
model = GPT(GPTConfig())
state_dict = model.state_dict()
start_saving = time.time()
torch.save(state_dict, "gpt2-xlarge.pth")
end_saving = time.time()
if __name__ == "__main__":
f()
```
</details>
<details><summary><b>Click for script to load</b></summary>
```
# test_load_gpt.py
import torch
from model import GPT
from test_load_save_gpt import GPTConfig
import time
import argparse
def f(mmap, meta):
device = 'meta' if meta else 'cpu'
assign = True if meta else False
with torch.device(device):
model = GPT(GPTConfig())
start_loading = time.time()
loaded_state_dict = torch.load("gpt2-xlarge.pth", _mmap=mmap)
end_loading = time.time()
print(f"loading time using torch.load with mmap={mmap}: ", end_loading - start_loading)
model.load_state_dict(loaded_state_dict, assign=assign)
end_load_state_dict = time.time()
print("load_state_dict time: ", end_load_state_dict - end_loading)
model.cuda()
end_cuda = time.time()
print("cuda time using torch.load with mmap: ", end_cuda - end_load_state_dict)
if __name__ == "__main__":
parser = argparse.ArgumentParser(prog='load_gpt_xlarge')
parser.add_argument('-m', '--mmap', action='store_true')
parser.add_argument('-d', '--devicemeta', action='store_true')
args = parser.parse_args()
mmap = args.mmap
meta = args.devicemeta
f(mmap, meta)
```
</details>
`python test_load_gpt.py`
<img width="614" alt="Screenshot 2023-06-06 at 1 35 43 PM" src="https://github.com/pytorch/pytorch/assets/35276741/ee06e5b3-b610-463b-a867-df995d21af29">
`python test_load_gpt.py --mmap`
<img width="622" alt="Screenshot 2023-06-06 at 1 35 30 PM" src="https://github.com/pytorch/pytorch/assets/35276741/00d2fdd0-b1f5-4313-83dc-e540b654b2af">
If we further use the `with torch.device('meta')` context manager and pull the changes from https://github.com/pytorch/pytorch/pull/102212 that allow the model to reuse tensors from the state_dict, we have
`python test_load_gpt.py --mmap --devicemeta`
<img width="727" alt="Screenshot 2023-06-06 at 1 35 51 PM" src="https://github.com/pytorch/pytorch/assets/35276741/b50257d9-092a-49c3-acae-876ee44d009f">
\
\
Running the above in a docker container containing a build of PyTorch with RAM limited to 512mb by
1) running `make -f docker.Makefile` from `pytorch/` directory
2) `docker run -m 512m -it <image> bash`
3) docker cp `gpt2-xlarge.pth` and `test_load_gpt.py` into the image
`python test_load_gpt.py`
Docker will Kill the process due to OOM whereas
`python test_load_gpt.py --mmap --devicemeta`
<img width="635" alt="Screenshot 2023-06-06 at 1 55 48 PM" src="https://github.com/pytorch/pytorch/assets/35276741/f3820d9e-f24c-43e7-885b-3bfdf24ef8ad">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102549
Approved by: https://github.com/albanD
Potentially fixes the second issue described in #87159.
In python_list.h, `int64_t` is used when `diff_type` is better suited. On 32 bit systems, int64_t isn't a proper signed size type, which may cause the compilation error described in #87159.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101922
Approved by: https://github.com/Skylion007
Summary:
In order to better track models after serialization, this change writes a serialization_id as a UUID to inline container. Having this ID enables traceability of model in saving and loading events.
serialization_id is generated as a new UUID everytime serialization takes place. It can be thought of as a model snapshot identifier at the time of serialization.
Test Plan:
```
buck2 test @//mode/dev //caffe2/caffe2/serialize:inline_container_test
```
Local tests:
```
buck2 run @//mode/opt //scripts/atannous:example_pytorch_package
buck2 run @//mode/opt //scripts/atannous:example_pytorch
buck2 run @//mode/opt //scripts/atannous:example_pytorch_script
```
```
$ unzip -l output.pt
Archive: output.pt
Length Date Time Name
--------- ---------- ----- ----
36 00-00-1980 00:00 output/.data/serialization_id
358 00-00-1980 00:00 output/extra/producer_info.json
58 00-00-1980 00:00 output/data.pkl
261 00-00-1980 00:00 output/code/__torch__.py
326 00-00-1980 00:00 output/code/__torch__.py.debug_pkl
4 00-00-1980 00:00 output/constants.pkl
2 00-00-1980 00:00 output/version
--------- -------
1045 7 files
```
```
unzip -p output.pt "output/.data/serialization_id"
a9f903df-cbf6-40e3-8068-68086167ec60
```
Differential Revision: D45683657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100994
Approved by: https://github.com/davidberard98
arguments() returns vector member of object returned by schema() call.
When object returned by schema() call is destroyed, the vector is deallocated as well,
it's lifetime isn't extended.
This issue detected while running `pytest -v test/mobile/test_lite_script_type.py -k test_nest_typing_namedtuple_custom_classtype` with ASAN.
<details>
<summary>ASAN output</summary>
```
==1134126==ERROR: AddressSanitizer: heap-use-after-free on address 0x60d0005a5790 at pc 0x03ff844488d8 bp 0x03fff584afe8 sp 0x03fff584afd8
READ of size 8 at 0x60d0005a5790 thread T0
#0 0x3ff844488d7 in __gnu_cxx::__normal_iterator<c10::Argument const*, std::vector<c10::Argument, std::allocator<c10::Argument> > >::__normal_iterator(c10::Argument const* const&) /usr/lib/gcc/s390x-i
bm-linux-gnu/11/include/g++-v11/bits/stl_iterator.h:1028
#1 0x3ff8444293f in std::vector<c10::Argument, std::allocator<c10::Argument> >::begin() const /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/stl_vector.h:821
#2 0x3ff84d807d1 in torch::jit::toPyObject(c10::IValue) /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:617
#3 0x3ff84d80305 in torch::jit::toPyObject(c10::IValue) /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
#4 0x3ff84856871 in pybind11::detail::type_caster<c10::IValue, void>::cast(c10::IValue, pybind11::return_value_policy, pybind11::handle) /home/user/pytorch/torch/csrc/jit/python/pybind.h:138
#5 0x3ff85318191 in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is
_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_me
thod const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::operator()(pybind11::detail::function_call&) const /home/user/pytorch/cmake/../third_party/pybin
d11/include/pybind11/pybind11.h:249
#6 0x3ff85317cfd in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is
_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_me
thod const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::__invoke(pybind11::detail::function_call&) /home/user/pytorch/cmake/../third_party/pybind11/incl
ude/pybind11/pybind11.h:224
#7 0x3ff82ee52e9 in pybind11::cpp_function::dispatcher(_object*, _object*, _object*) /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:929
#8 0x3ffab002903 in cfunction_call Objects/methodobject.c:543
#9 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#10 0x3ffaaf8e919 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#11 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#12 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#13 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#14 0x3ffab105447 in call_function Python/ceval.c:5891
#15 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#16 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#17 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#18 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#19 0x3ffaaf8a615 in _PyObject_FastCallDictTstate Objects/call.c:142
#20 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#21 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#22 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#23 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#24 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#25 0x3ffab105447 in call_function Python/ceval.c:5891
#26 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#27 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#28 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#29 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#30 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#31 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#32 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#33 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#34 0x3ffab105447 in call_function Python/ceval.c:5891
#35 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#36 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#37 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#38 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#39 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#40 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#41 0x3ffab105447 in call_function Python/ceval.c:5891
#42 0x3ffab0ff7d7 in _PyEval_EvalFrameDefault Python/ceval.c:4198
#43 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#44 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#45 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#46 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#47 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#48 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#49 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#50 0x3ffab105447 in call_function Python/ceval.c:5891
#51 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#52 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#53 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#54 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#55 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#56 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#57 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#58 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#59 0x3ffab105447 in call_function Python/ceval.c:5891
#60 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#61 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#62 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#63 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#64 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#65 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#66 0x3ffaaf8ab9b in PyVectorcall_Call Objects/call.c:267
#67 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#68 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#69 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#70 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#71 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#72 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#73 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#74 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#75 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#76 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#77 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#78 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#79 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#80 0x3ffab105447 in call_function Python/ceval.c:5891
#81 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#82 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#83 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#84 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#85 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#86 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#87 0x3ffab105447 in call_function Python/ceval.c:5891
#88 0x3ffab0ff7d7 in _PyEval_EvalFrameDefault Python/ceval.c:4198
#89 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#90 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#91 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#92 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#93 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#94 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#95 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#96 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#97 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#98 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#99 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#100 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#101 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#102 0x3ffab105447 in call_function Python/ceval.c:5891
#103 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#104 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#105 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#106 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#107 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#108 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#109 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#110 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#111 0x3ffab105447 in call_function Python/ceval.c:5891
#112 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#113 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#114 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#115 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#116 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#117 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#118 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#119 0x3ffaaf8ad17 in _PyObject_Call Objects/call.c:305
#120 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#121 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#122 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#123 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#124 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#125 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#126 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#127 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#128 0x3ffab105447 in call_function Python/ceval.c:5891
#129 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#130 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#131 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#132 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#133 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#134 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#135 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#136 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#137 0x3ffab105447 in call_function Python/ceval.c:5891
#138 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#139 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#140 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#141 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#142 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#143 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#144 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#145 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#146 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#147 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#148 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#149 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#150 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#151 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#152 0x3ffab105447 in call_function Python/ceval.c:5891
#153 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#154 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#155 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#156 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#157 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#158 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#159 0x3ffab105447 in call_function Python/ceval.c:5891
#160 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#161 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#162 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#163 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#164 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#165 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#166 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#167 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#168 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#169 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#170 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#171 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#172 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#173 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#174 0x3ffab105447 in call_function Python/ceval.c:5891
#175 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#176 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#177 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#178 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#179 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#180 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#181 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#182 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#183 0x3ffab105447 in call_function Python/ceval.c:5891
#184 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#185 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#186 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#187 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#188 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#189 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#190 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#191 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#192 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#193 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#194 0x3ffab105447 in call_function Python/ceval.c:5891
#195 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#196 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#197 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#198 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#199 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#200 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#201 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#202 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#203 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#204 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#205 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#206 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#207 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#208 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#209 0x3ffab105447 in call_function Python/ceval.c:5891
#210 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#211 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#212 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#213 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#214 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#215 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#216 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#216 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#217 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#218 0x3ffab105447 in call_function Python/ceval.c:5891
#219 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#220 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#221 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#222 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#223 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#224 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#225 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#226 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#227 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#228 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#229 0x3ffab105447 in call_function Python/ceval.c:5891
#230 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#231 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#232 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#233 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#234 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#235 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#236 0x3ffab105447 in call_function Python/ceval.c:5891
#237 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#238 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#239 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#240 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#241 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#242 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#243 0x3ffab105447 in call_function Python/ceval.c:5891
#244 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#245 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#246 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#247 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#248 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#249 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
0x60d0005a5790 is located 80 bytes inside of 136-byte region [0x60d0005a5740,0x60d0005a57c8)
freed by thread T0 here:
#0 0x3ffab537de5 in operator delete(void*) /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:160
#1 0x3ff55984fdb in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::deallocate(std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2>*, unsigned long) /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:145
previously allocated by thread T0 here:
#0 0x3ffab53734f in operator new(unsigned long) /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:99
#1 0x3ff5598443f in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::allocate(unsigned long, void const*) /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:127
#2 0x3fff5849ecf ([stack]+0xb2ecf)
SUMMARY: AddressSanitizer: heap-use-after-free /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/stl_iterator.h:1028 in __gnu_cxx::__normal_iterator<c10::Argument const*, std::vector<c10::Argument, std::allocator<c10::Argument> > >::__normal_iterator(c10::Argument const* const&)
Shadow bytes around the buggy address:
0x100c1a000b4aa0: fd fd fd fd fd fd fd fd fd fd fd fa fa fa fa fa
0x100c1a000b4ab0: fa fa fa fa fd fd fd fd fd fd fd fd fd fd fd fd
0x100c1a000b4ac0: fd fd fd fd fd fa fa fa fa fa fa fa fa fa fd fd
0x100c1a000b4ad0: fd fd fd fd fd fd fd fd fd fd fd fd fd fd fd fa
0x100c1a000b4ae0: fa fa fa fa fa fa fa fa fd fd fd fd fd fd fd fd
=>0x100c1a000b4af0: fd fd[fd]fd fd fd fd fd fd fa fa fa fa fa fa fa
0x100c1a000b4b00: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b10: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b20: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b30: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b40: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==1134126==ABORTING
```
Additional backtraces (not full):
Allocation:
```
#0 __memset_z196 () at ../sysdeps/s390/memset-z900.S:144
#1 0x000003ff96f3072a in __asan::Allocator::Allocate (this=this@entry=0x3ff97041eb8 <__asan::instance>, size=size@entry=136, alignment=8, alignment@entry=0, stack=<optimized out>,
stack@entry=0x3ffdbb45d78, alloc_type=<optimized out>, can_fill=true) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_allocator.cpp:599
#2 0x000003ff96f2c088 in __asan::asan_memalign (alignment=alignment@entry=0, size=size@entry=136, stack=stack@entry=0x3ffdbb45d78, alloc_type=alloc_type@entry=__asan::FROM_NEW)
at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_allocator.cpp:1039
#3 0x000003ff96fb73b0 in operator new (size=136) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:99
#4 0x000003ff41404440 in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::allocate (this=0x3ffdbb468c0,
__n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:127
#5 0x000003ff414042a0 in std::allocator_traits<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::allocate (__a=...,
__n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/alloc_traits.h:464
#6 0x000003ff41403b66 in std::__allocate_guarded<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > > (__a=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/allocated_ptr.h:98
#7 0x000003ff4140372a in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::__shared_count<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (this=0x3ffdbb47888, __p=@0x3ffdbb47880: 0x0, __a=..., __args=..., __args=..., __args=..., __args=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:648
#8 0x000003ff41403328 in std::__shared_ptr<c10::FunctionSchema, (__gnu_cxx::_Lock_policy)2>::__shared_ptr<std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (this=0x3ffdbb47880, __tag=..., __args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1342
#9 0x000003ff41402f06 in std::shared_ptr<c10::FunctionSchema>::shared_ptr<std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (
this=0x3ffdbb47880, __tag=..., __args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:409
#10 0x000003ff41402b6e in std::allocate_shared<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (__a=...,
__args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:862
#11 0x000003ff4140215c in std::make_shared<c10::FunctionSchema, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (__args=..., __args=..., __args=..., __args=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:878
#12 0x000003ff413d180c in c10::TupleType::createWithSpec<c10::basic_string_view<char> > (qualName=..., field_names=std::vector of length 1, capacity 1 = {...},
field_types=std::vector of length 1, capacity 1 = {...}, field_defaults=std::vector of length 0, capacity 0) at /home/user/pytorch/aten/src/ATen/core/type.cpp:769
#13 0x000003ff413b9ca6 in c10::TupleType::createNamed (qualName=..., field_names=std::vector of length 1, capacity 1 = {...}, field_types=std::vector of length 1, capacity 1 = {...})
at /home/user/pytorch/aten/src/ATen/core/type.cpp:725
#14 0x000003ff4115fbac in c10::ivalue::TupleTypeFactory<c10::TupleType>::fallback (type=...) at /home/user/pytorch/aten/src/ATen/core/dynamic_type.cpp:383
#15 0x000003ff708217fe in c10::ivalue::Tuple::type<c10::TupleType> (this=0x6080004b8520) at /home/user/pytorch/aten/src/ATen/core/ivalue_inl.h:781
#16 0x000003ff70800740 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:613
#17 0x000003ff70800306 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
#18 0x000003ff702d6872 in pybind11::detail::type_caster<c10::IValue, void>::cast (src=...) at /home/user/pytorch/torch/csrc/jit/python/pybind.h:138
#19 0x000003ff70d98192 in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_method const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::operator()(pybind11::detail::function_call&) const (this=0x3ffdbb4ca20, call=...)
at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:249
#20 0x000003ff70d97cfe in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_method const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::__invoke(pybind11::detail::function_call&) (call=...)
at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:224
#21 0x000003ff6e9652ea in pybind11::cpp_function::dispatcher (self=<PyCapsule at remote 0x3ff83e27720>,
args_in=(<torch._C.LiteScriptModule at remote 0x3ff811844b0>, (<Tensor at remote 0x3ff814efb00>,)), kwargs_in=0x0) at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:929
```
Deallocation:
```
#0 operator delete (ptr=0x60d0005a5740) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:160
#1 0x000003ff44904fdc in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::deallocate (this=0x3ffc5dc8020,
__p=0x60d0005a5740, __t=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:145
#2 0x000003ff44904fa8 in std::allocator_traits<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::deallocate (
__a=..., __p=0x60d0005a5740, __n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/alloc_traits.h:496
#3 0x000003ff449041f2 in std::__allocated_ptr<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::~__allocated_ptr (
this=0x3ffc5dc8030) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/allocated_ptr.h:74
#4 0x000003ff44904888 in std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2>::_M_destroy (this=0x60d0005a5740)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:538
#5 0x000003ff43895a62 in std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release (this=0x60d0005a5740) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:184
#6 0x000003ff43895420 in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::~__shared_count (this=0x611000c40648) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:705
#7 0x000003ff4466e7f4 in std::__shared_ptr<c10::FunctionSchema, (__gnu_cxx::_Lock_policy)2>::~__shared_ptr (this=0x611000c40640)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1154
#8 0x000003ff4466d820 in std::shared_ptr<c10::FunctionSchema>::~shared_ptr (this=0x611000c40640) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:122
#9 0x000003ff448d82f6 in c10::TupleType::~TupleType (this=0x611000c40580) at /home/user/pytorch/aten/src/ATen/core/jit_type.h:1142
#10 0x000003ff448d8346 in c10::TupleType::~TupleType (this=0x611000c40580) at /home/user/pytorch/aten/src/ATen/core/jit_type.h:1142
#11 0x000003ff731296a4 in std::_Sp_counted_ptr<c10::TupleType*, (__gnu_cxx::_Lock_policy)2>::_M_dispose (this=0x603000c43ae0)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:348
#12 0x000003ff71eaf666 in std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release (this=0x603000c43ae0) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:168
#13 0x000003ff71eaf330 in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::~__shared_count (this=0x3ffc5dc9368) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:705
#14 0x000003ff73129ee4 in std::__shared_ptr<c10::TupleType, (__gnu_cxx::_Lock_policy)2>::~__shared_ptr (this=0x3ffc5dc9360)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1154
#15 0x000003ff73122390 in std::shared_ptr<c10::TupleType>::~shared_ptr (this=0x3ffc5dc9360) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:122
#16 0x000003ff73d00788 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:613
#17 0x000003ff73d00306 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
```
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101400
Approved by: https://github.com/zou3519
When handling custom classes from Python, it is nice to be able to specify how they are displayed to the user.
Out of the two standard functions to do this, only `__str__` could be implemented in C++. This PR add `__repr__` to the allowlist of magic methods.
The second commit tweaks the default output of `__str__` to make it more informative, but I can remove the change if you want.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100724
Approved by: https://github.com/ezyang
Without these changes, it can be hard to know which magic methods are not implemented on a given ScriptObject.
before:
```py
torch.ops.load_library("somelib.so")
c = torch.classes.somelib.SomeClass()
print(len(c))
# raise NotImplementedError
```
after:
```py
torch.ops.load_library("somelib.so")
c = torch.classes.somelib.SomeClass()
print(len(c))
# raise NotImplementedError: '__len__' is not implemented for __torch__.torch.classes.somelib.SomeClass
```
------
I could not find a linked issue, if you want me to open one as well I can do this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100171
Approved by: https://github.com/ezyang
Summary:
A very old refactor (https://github.com/pytorch/pytorch/pull/29500) split ScriptModule into ScriptObject (base class) and ScriptModule (subclass). When moving methods around, the `_type` method was moved from ScriptModule to ScriptObject, but the type of its argument wasn't changed. Therefore, it is now impossible to invoke `_type` on a ScriptObject.
The reason I need this fix is that I am using PyTorch's dispatch mode to intercept some operators that accept/return custom classes, which end up being encoded as ScriptObject, and in order to properly handle them I need to be able to verify their type.
Test Plan: N/A
Differential Revision: D45118675
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99542
Approved by: https://github.com/albanD
TorchScript only supports indexing into ModuleLists with integer literals. The error message already warns about this; but this PR adds clarifications around what a "literal" is. I'm adding this PR because, in my opinion, it's not obvious what a "literal" is and how strict its definition is. The clarification provided in this PR should make it easier for users to understand the issue and how to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98606
Approved by: https://github.com/eellison, https://github.com/gmagogsfm
Summary:
Extra C binding module for flatbuffer was introduced because
not all dependencies of Pytorch want (or can) bundle in flatbuffer.
However, flatbuffer is in by default now so this separate binding is not longer needed.
Test Plan: existing unit tests
Differential Revision: D44352583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97476
Approved by: https://github.com/dbort
**Summary** NamedTuple attributes can be annotated to declare their type:
```python
class MyNamedTuple(NamedTuple):
x: int
y: torch.Tensor
z: MyOtherType
```
Normally in python you can also declare your types as strings, `x: 'int'`. But NamedTuples previously didn't support this, because their annotation evaluation process was slightly different. This PR updates the NamedTuple attribute type annotation evaluation method to support ForwardRef declarations (i.e. declaring as strings).
**Details**
Below I repeat the comment I left in _jit_internal.py:
NamedTuple types are slightly different from normal types.
Normally, annotations are evaluted like this (during jit.script):
1. Load strings of python code into c++ and parse.
2. Get annotations as strings
3. Use the PythonResolver's resolution callback (rcb) to convert the string into a python object
4. We call into annotations.py:ann_to_type to convert python obj from step 3 into a type that torchscript understands.
NamedTuples are more complicated, because they have sub-types. Normally, once we have the NamedTuple type object from #3, we can just look at the annotation literal values and use ann_to_type directly on them.
But sometimes, users will annotate with string literals, e.g.
```
x: 'int'
```
This also happens with PEP563 (from __forward__ import annotations)
These annotations appear in the annotation dict as ForwardRef('int').
Then, we need to convert the string into a python object. This requires having local context for custom objects or imported types. rcb() is what gives us this. So, we plumb rcb through the stack so it can be used in this context for the if block below.
FAQ:
- Why do we need this special handling for NamedTuple but string annotations work fine for normal types? Normally, we parse the string directly and then call rcb() directly from C++.
- Why not use ForwardRef._evaluate? For that, we need globals() and locals() for the local context where the NamedTuple was defined. rcb is what lets us look up into these. So, basically rcb does the hard work for us.
- What is rcb? rcb is a ResolutionCallback - python callable that takes a string and returns a type. It's generated by `createResolutionCallback.*` in _jit_internal.py.
**Why is this only partial support**:
This only plumbs the rcb through some paths. In particular, the `toSugaredValue` path uses a fake rcb.
**Alternatives**:
We could also treat this the way we treat non-nn.Module classes: we evaluate them separately, ahead of time. That solution is probably better, but probably requires a more risky refactor for the way NamedTuples are handled.
Fixes#95858
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96933
Approved by: https://github.com/qihqi
This PR do two things:
1. It moves some Windows warning suppression from various CMake files into the main CMakeList.txt, following the conventions of gcc and clang.
2. It fixes some Windows warnings in the source code. Most importantly, it fixes lots of dll warnings by adjusting C10_API to TORCH_API or TORCH_PYTHON_API. There are still some dll warnings because some TORCH_API functions are actually built as part of libtorch_python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94927
Approved by: https://github.com/malfet
The basic idea behind this PR is that we want to continue using the guarding implementations of contiguity tests, if all of the elements are backend (aka, have hints). If they don't have hints, we'll have to do something slower (use the non-short circuiting, non guarding implementations of contiguity), but most of the time you aren't dealing with unbacked SymInts.
So this PR has three parts.
1. We expose `has_hint` on `SymNode`. This allows us to query whether or not a SymInt is backed or not from C++. Fairly self explanatory. Will require LTC/XLA updates; but for backends that don't support unbacked SymInts you can just always return true.
2. We update `compute_non_overlapping_and_dense` to test if the inputs are hinted. If they are all hinted, we use the conventional C++ implementation. Otherwise we call into Python. The Python case is not heavily tested right now because I haven't gotten all of the pieces for unbacked SymInts working yet. Coming soon.
3. We add stubs for all of the other contiguity tests. The intention is to apply the same treatment to them as well, but this is not wired up yet for safety reasons.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94431
Approved by: https://github.com/voznesenskym
We want to make TorchRec sharded models TorchScriptable.
TorchRec sharded models uses generic types Awaitable[W] and LazyAwaitable[W] (https://github.com/pytorch/torchrec/blob/main/torchrec/distributed/types.py#L212).
In sharded model those types are used instead of contained type W, having the initialization function that produces object of type W.
At the moment when the first attribute of W is requested - `LazyAwaitable[W]` will call its initialization function (on the same stack), cache the result inside and work transparently as an object of W. So we can think about it as a delayed object initialization.
To support this behavior in TorchScript - we propose a new type to TorchScript - `Await`.
In eager mode it works the same as `LazyAwaitable[W]` in TorchRec, being dynamically typed - acting as a type `W` while it is `Await[W]`.
Within torchscript it is `Await[W]` and can be only explicitly converted to W, using special function `torch.jit.awaitable_wait(aw)`.
Creation of this `Await[W]` is done via another special function `torch.jit.awaitable(func, *args)`.
The semantic is close to `torch.jit.Future`, fork, wait and uses the same jit mechanics (inline fork Closures) with the difference that it does not start this function in parallel on fork. It only stores as a lambda inside IValue that will be called on the same thread when `torch.jit.awaitable_wait` is called.
For example (more examples in this PR `test/jit/test_await.py`)
```
def delayed(z: Tensor) -> Tensor:
return Tensor * 3
@torch.jit.script
def fn(x: Tensor):
aw: Await[int] = torch.jit._awaitable(delayed, 99)
a = torch.eye(2)
b = torch.jit._awaitable_wait(aw)
return a + b + x
```
Functions semantics:
`_awaitable(func -> Callable[Tuple[...], W], *args, **kwargs) -> Await[W]`
Creates Await object, owns args and kwargs. Once _awaitable_wait calls, executes function func and owns the result of the function. Following _awaitable_wait calls will return this result from the first function call.
`_awaitable_wait(Await[W]) -> W`
Returns either cached result of W if it is not the first _awaitable_wait call to this Await object or calls specified function if the first.
`_awaitable_nowait(W) -> Await[W]`
Creates trivial Await[W] wrapper on specified object To be type complaint for the corner cases.
Differential Revision: [D42502706](https://our.internmc.facebook.com/intern/diff/D42502706)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90863
Approved by: https://github.com/davidberard98
Not only is this change usually shorter and more readable, it also can yield better performance. size() is not always a constant time operation (such as on LinkedLists), but empty() always is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93236
Approved by: https://github.com/malfet
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
Replace cpp string comparisons with more efficient equality operators. These string comparisons are not just more readable, but they also allow for short-circuiting for faster string equality checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92765
Approved by: https://github.com/ezyang
We have known for a while that we should in principle support SymBool as a separate concept from SymInt and SymFloat ( in particular, every distinct numeric type should get its own API). However, recent work with unbacked SymInts in, e.g., https://github.com/pytorch/pytorch/pull/90985 have made this a priority to implement. The essential problem is that our logic for computing the contiguity of tensors performs branches on the passed in input sizes, and this causes us to require guards when constructing tensors from unbacked SymInts. Morally, this should not be a big deal because, we only really care about the regular (non-channels-last) contiguity of the tensor, which should be guaranteed since most people aren't calling `empty_strided` on the tensor, however, because we store a bool (not a SymBool, prior to this PR it doesn't exist) on TensorImpl, we are forced to *immediately* compute these values, even if the value ends up not being used at all. In particular, even when a user allocates a contiguous tensor, we still must compute channels-last contiguity (as some contiguous tensors are also channels-last contiguous, but others are not.)
This PR implements SymBool, and makes TensorImpl use SymBool to store the contiguity information in ExtraMeta. There are a number of knock on effects, which I now discuss below.
* I introduce a new C++ type SymBool, analogous to SymInt and SymFloat. This type supports logical and, logical or and logical negation. I support the bitwise operations on this class (but not the conventional logic operators) to make it clear that logical operations on SymBool are NOT short-circuiting. I also, for now, do NOT support implicit conversion of SymBool to bool (creating a guard in this case). This does matter too much in practice, as in this PR I did not modify the equality operations (e.g., `==` on SymInt) to return SymBool, so all preexisting implicit guards did not need to be changed. I also introduced symbolic comparison functions `sym_eq`, etc. on SymInt to make it possible to create SymBool. The current implementation of comparison functions makes it unfortunately easy to accidentally introduce guards when you do not mean to (as both `s0 == s1` and `s0.sym_eq(s1)` are valid spellings of equality operation); in the short term, I intend to prevent excess guarding in this situation by unit testing; in the long term making the equality operators return SymBool is probably the correct fix.
* ~~I modify TensorImpl to store SymBool for the `is_contiguous` fields and friends on `ExtraMeta`. In practice, this essentially meant reverting most of the changes from https://github.com/pytorch/pytorch/pull/85936 . In particular, the fields on ExtraMeta are no longer strongly typed; at the time I was particularly concerned about the giant lambda I was using as the setter getting a desynchronized argument order, but now that I have individual setters for each field the only "big list" of boolean arguments is in the constructor of ExtraMeta, which seems like an acceptable risk. The semantics of TensorImpl are now that we guard only when you actually attempt to access the contiguity of the tensor via, e.g., `is_contiguous`. By in large, the contiguity calculation in the implementations now needs to be duplicated (as the boolean version can short circuit, but the SymBool version cannot); you should carefully review the duplicate new implementations. I typically use the `identity` template to disambiguate which version of the function I need, and rely on overloading to allow for implementation sharing. The changes to the `compute_` functions are particularly interesting; for most of the functions, I preserved their original non-symbolic implementation, and then introduce a new symbolic implementation that is branch-less (making use of our new SymBool operations). However, `compute_non_overlapping_and_dense` is special, see next bullet.~~ This appears to cause performance problems, so I am leaving this to an update PR.
* (Update: the Python side pieces for this are still in this PR, but they are not wired up until later PRs.) While the contiguity calculations are relatively easy to write in a branch-free way, `compute_non_overlapping_and_dense` is not: it involves a sort on the strides. While in principle we can still make it go through by using a data oblivious sorting network, this seems like too much complication for a field that is likely never used (because typically, it will be obvious that a tensor is non overlapping and dense, because the tensor is contiguous.) So we take a different approach: instead of trying to trace through the logic computation of non-overlapping and dense, we instead introduce a new opaque operator IsNonOverlappingAndDenseIndicator which represents all of the compute that would have been done here. This function returns an integer 0 if `is_non_overlapping_and_dense` would have returned `False`, and an integer 1 otherwise, for technical reasons (Sympy does not easily allow defining custom functions that return booleans). The function itself only knows how to evaluate itself if all of its arguments are integers; otherwise it is left unevaluated. This means we can always guard on it (as `size_hint` will always be able to evaluate through it), but otherwise its insides are left a black box. We typically do NOT expect this custom function to show up in actual boolean expressions, because we will typically shortcut it due to the tensor being contiguous. It's possible we should apply this treatment to all of the other `compute_` operations, more investigation necessary. As a technical note, because this operator takes a pair of a list of SymInts, we need to support converting `ArrayRef<SymNode>` to Python, and I also unpack the pair of lists into a single list because I don't know if Sympy operations can actually validly take lists of Sympy expressions as inputs. See for example `_make_node_sizes_strides`
* On the Python side, we also introduce a SymBool class, and update SymNode to track bool as a valid pytype. There is some subtlety here: bool is a subclass of int, so one has to be careful about `isinstance` checks (in fact, in most cases I replaced `isinstance(x, int)` with `type(x) is int` for expressly this reason.) Additionally, unlike, C++, I do NOT define bitwise inverse on SymBool, because it does not do the correct thing when run on booleans, e.g., `~True` is `-2`. (For that matter, they don't do the right thing in C++ either, but at least in principle the compiler can warn you about it with `-Wbool-operation`, and so the rule is simple in C++; only use logical operations if the types are statically known to be SymBool). Alas, logical negation is not overrideable, so we have to introduce `sym_not` which must be used in place of `not` whenever a SymBool can turn up. To avoid confusion with `__not__` which may imply that `operators.__not__` might be acceptable to use (it isn't), our magic method is called `__sym_not__`. The other bitwise operators `&` and `|` do the right thing with booleans and are acceptable to use.
* There is some annoyance working with booleans in Sympy. Unlike int and float, booleans live in their own algebra and they support less operations than regular numbers. In particular, `sympy.expand` does not work on them. To get around this, I introduce `safe_expand` which only calls expand on operations which are known to be expandable.
TODO: this PR appears to greatly regress performance of symbolic reasoning. In particular, `python test/functorch/test_aotdispatch.py -k max_pool2d` performs really poorly with these changes. Need to investigate.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92149
Approved by: https://github.com/albanD, https://github.com/Skylion007
It turns out our old max/min implementation didn't do anything, because `__max__` and `__min__` are not actually magic methods in Python. So I give 'em the `sym_` treatment, similar to the other non-overrideable builtins.
NB: I would like to use `sym_max` when computing contiguous strides but this appears to make `python test/functorch/test_aotdispatch.py -v -k test_aot_autograd_symbolic_exhaustive_nn_functional_max_pool2d_cpu_float32` run extremely slowly. Needs investigating.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92107
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/Skylion007
As we live in C++17 world
This is a functional no-op, just
- `s/namespace at { namespace native {/namespace at::native {/`
- `s/namespace torch { namespace jit {/namespace torch::jit {/`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92100
Approved by: https://github.com/izaitsevfb
This adds `torch.cuda._DeviceGuard` which is a stripped down version of
`torch.cuda.device` with lower overhead. To do this, it only accepts `int` as
the device so we don't need to call `_get_device_index` and is implemented
with a new C++ helper `torch._C._cuda_exchangeDevice` that allows
`_DeviceGuard.__enter__` to be just a single function call. On my machine,
I see a drop from 3.8us of overhead to 0.94 us with this simple benchmark:
```python
def set_device():
with torch.cuda.device(0):
pass
%timeit set_device()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91045
Approved by: https://github.com/ngimel, https://github.com/anijain2305
#75854
A naive attempt at working around the limitations of using a single 64-bit integer to pack `stream_id`, `device_index`, and `device_type`.
Stills needs sanity checks, testing, and minimization of BC-breaking changes.
Currently a Holder for the `StreamData3` struct is used for `IValue` compatibility. While doing this seems to work for `ivalue.h` and `ivalue_inl.h`, this doesn't seem to be naively working for the JIT CUDA stream wrapper? (Something about ambiguous calls if an `intrusive_ptr` to `c10::ivalue::StreamData3Holder` is used as the return type for `pack()`. It turns out that the methods required to access the fields for rematerializing a CUDA Stream are basically already present anyway, so `pack` is simply removed in the wrapper for now and the methods to access the required fields are called directly.
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81596
Approved by: https://github.com/ezyang
Summary: * when we try to port py obj of script module/obj to c++, `tryToInferType` is flawed in providing type inference metadata. but change it would break normal torch.jit.script flow, so we try extract the ivalue in the py obj value.
Test Plan: NA
Reviewed By: PaliC
Differential Revision: D41749823
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91776
Approved by: https://github.com/842974287
#84624 introduces an update on `torch.norm` [dispatch logic](eaa43d9f25/torch/functional.py (L1489)) which now depends on `layout`. Resulting in regressions to export related operators from TorchScript.
This PR resolves the regression by partially supporting a subset use case of `prim::layout` (only `torch.strided`), `aten::__contains__` (only constants) operators. It requires much more effort to properly support other layouts, e.g. `torch.sparse_coo`. Extending JIT types, and supporting related family of ops like `aten::to_sparse`. This is out of the scope of this PR.
Fixes#83661
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91660
Approved by: https://github.com/justinchuby, https://github.com/kit1980
This applies some more clang-tidy fixups. Particularly, this applies the modernize loops and modernize-use-transparent-functors checks. Transparent functors are less error prone since you don't have to worry about accidentally specifying the wrong type and are newly available as of C++17.
Modern foreach loops tend be more readable and can be more efficient to iterate over since the loop condition is removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91449
Approved by: https://github.com/ezyang
Noticed the toSymFloat / toSymInt overloads always copied the internal pointer of an ivalue even if it was an rvalue unlike other overloads (like toTensor). This fixes that issue by adding the appropriate methods needed to facilitate that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91405
Approved by: https://github.com/ezyang
Apply clang-tidy check modernize-use-emplace. This is slightly more efficient by using an inplace constructor and is the recommended style in parts of the codebase covered by clang-tidy. This just manually applies the check to rest of the codebase. Pinging @ezyang as this is related to my other PRs he reviewed like #89000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91077
Approved by: https://github.com/ezyang
Avoid double exception in destructor if attempting to serialize to
python object that does not have `write` method
Use `Finalizer` class in `PyTorchStreamWriter::writeEndOfFile()` to a
always set `finailized_` property even if excretion occurs. (as there
isn't much one can do at this point)
Add expicit check for the attribue to `_open_zipfile_writer_buffer` and
add unitests
Modernize code a bit by using Python-3 `super()` method
Fixes https://github.com/pytorch/pytorch/issues/87997
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88128
Approved by: https://github.com/albanD
Fixes minor perf regression I saw in #85688 and replaced throughout the code base. `obj == Py_None` is directly equivalent to is_none(). Constructing a temporary py::none() object needlessly incref/decref the refcount of py::none, this method avoids that and therefore is more efficient.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88051
Approved by: https://github.com/albanD
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
At the moment, they were casted to `int64`, which breaks quite a few
casting rules for example in `ops.aten`.
Quite a vintage bug, circa 2020.
With this fix, the following code prints `torch.bool`, rather than `torch.int64`.
```python
import torch
msk = torch.tensor([False])
b = torch.tensor([False])
print(torch.ops.aten.where.ScalarSelf(msk, True, b).dtype)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87179
Approved by: https://github.com/albanD
# Support unpacking python dictionary in **torch.jit.trace()**
## Problem statement & Motivation
### Problem 1(usability):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=value1, key2=value2, key3=value3)`**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3, key2:value2}`**
The problem is that if you want to trace the model using the dict data by the giving dataset, you need unpack the dictionary and reorder its value manually and make up a tuple as **`data_tuple = (value1, value2, value3)`** as the **`example_inputs`** parameter of **`torch.jit.trace()`**. This marshalling process is not user friendly.
### Problem 2 (feasibility):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=None, key2=None, key3=None)`** -> The default value is **None**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3}`** -> Only **part of** the required value by forward was given, the rest use the default value.
The problem is that if you want to trace the model using the dict data by the giving dataset, it's not feasible at all. Cause neither you can pass a tuple like **`T1 = (value1, value3)`** nor **`T2 = (value1, None, value3)`**. T1 will mismatch value3 with key2 and T2 include **None** type which will be blocked by tracer's type checking. (Of course you can pass **`T3 = (value1,)`** to make the trace function finish without exception, but the traced model you get probably is not what you expect cause the different input may result in different traced result.).
These problems come from the HuggingFace's PT model, especially in text-classification tasks with datasets such as [MRPC,](https://paperswithcode.com/dataset/mrpc) [MNLI](https://paperswithcode.com/dataset/multinli) etc.
## Solution
To address these two issues, we propose to support a new type, that is, python dict as example_inputs parameter for torch.jit.trace(). We can base on the runtime type information of the example_inputs object to determine if we fall back to the original tuple path or go into the new dictionary path. Both problem 1 and problem 2 can be solved by utilizing the "**`**`**"
operator.
## Limitation & Mitigation
1. If we use dict as example_inputs to trace the model, then we have to pass a dictionary to the traced model too. (Cause probably we will change the order of debug name of the input parameter in torchscript IR, thus we can't assume the traced model's input parameters order are the same with the original model.). We need highlight this too in the document to mitigate this problem.
For example:
```
# fetch a data from dataloader, and the data is a dictionary
# and the example_inputs_dict is like: {key1:value1, key3:value3, key2:value2}
# the forward() is like: def forward(self, key1=value1, key2=value2, key3=value3)
example_inputs_dict = next(iter(dataloader))
jit_model = model.eval()
# use the dictionary to trace the model
jit_model = torch.jit.trace(jit_model, example_inputs_dict, strict=False) # Now the IR will be graph(%self : __torch__.module.___torch_mangle_n.Mymodule, %key1 : type1, %key3 : type3, %key2 : type2)
jit_model = torch.jit.freeze(jit_model)
# It's OK to use dict as the parameter for traced model
jit_model(**example_inputs_dict)
example_inputs_tuple = (value1, value3, value2)
# It's wrong to rely on the original args order.
jit_model(*example_inputs_tuple)
```
## Note
1. This PR will make some UT introduced in [39601](https://github.com/pytorch/pytorch/pull/39601) fail, which I think should be classified as unpacking a tuple containing a single dictionary element in our solution.
4. I think there is ambiguity since currently we only specify passing a tuple or a single Tensor as our example_inputs parameter in **torch.jit.trace()**'s documentation, but it seems we can still passing a dictionary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81623
Approved by: https://github.com/davidberard98
This reverts commit 978b46d7c9.
Reverted https://github.com/pytorch/pytorch/pull/86488 on behalf of https://github.com/osalpekar due to Broke executorch builds internally with the following message: RuntimeError: Missing out variant for functional op: aten::split.Tensor(Tensor(a -> *) self, SymInt split_size, int dim=0) -> Tensor(a)[] . Make sure you have loaded your custom_ops_generated_lib
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86488
Approved by: https://github.com/ezyang
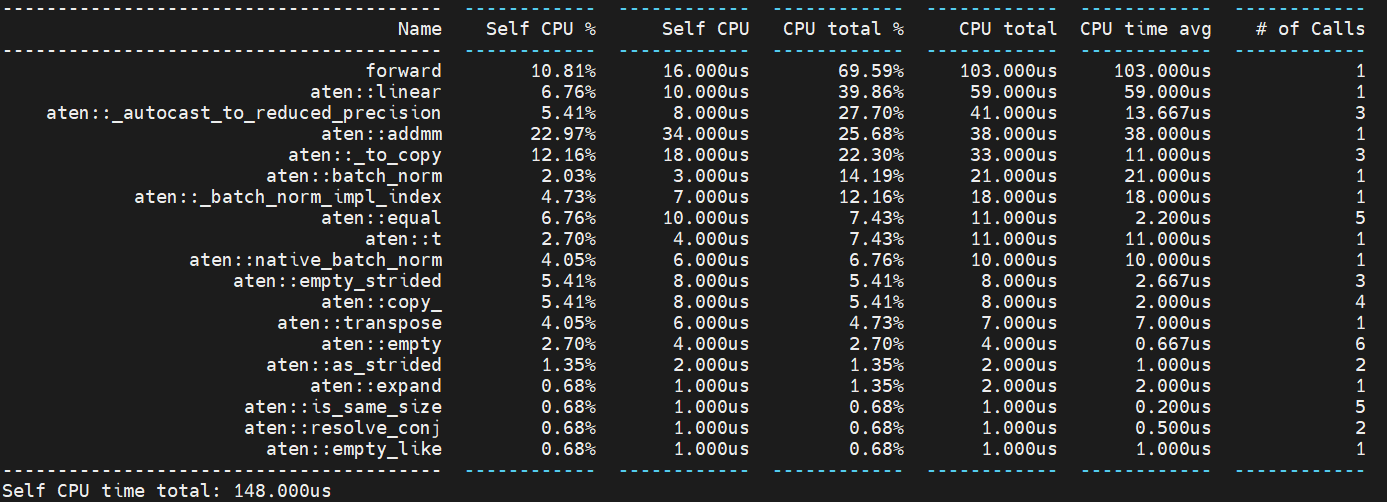{kind=link}
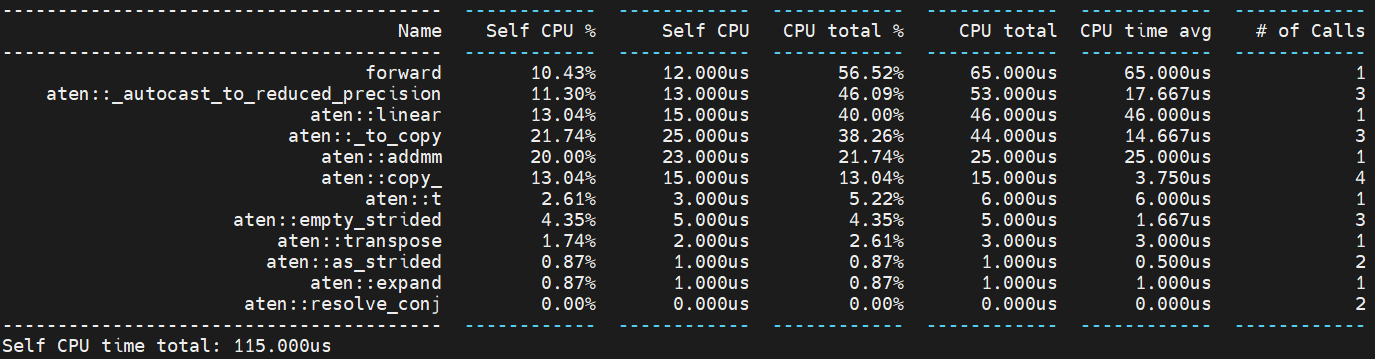{kind=link}
{kind=link}