run tests in parallel at the test file granularity
runs 3 files in parallel using multiprocessing pool, output goes to a file, which is then printed when the test finishes. Some tests cannot be run in parallel (usually due to lacking memory), so we run those after. Sharding is changed to attempt to mask large files with other large files/run them on the same shard.
test_ops* gets a custom handler to run it because it is simply too big (2hrs on windows) and linalg_cholesky fails (I would really like a solution to this if possible, but until then we use the custom handler).
reduces cuda tests by a lot, reduces total windows test time by ~1hr
Ref. https://github.com/pytorch/pytorch/issues/82894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84961
Approved by: https://github.com/huydhn
Follow up:
- ~Remove non-float dtypes from allow-list for gradients~
- ~Map dtypes to short-hand so there aren't so many lines, i.e. float16 should be f16.~
- ~There were a lot of linting issues that flake8 wouldn't format for me, so I reformatted with black. This makes the diff a little trickier to parse.~
Observations:
- there are entries in the allow-list that weren't there before
- some forward that we previously passing now fail with requires_grad=True
- Because the allow list does not know about variants, a special skip was added for that in the block list
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84242
Approved by: https://github.com/kulinseth, https://github.com/malfet
This reverts commit 1187dedd33.
Reverted https://github.com/pytorch/pytorch/pull/83436 on behalf of https://github.com/huydhn due to The previous change breaks internal builds D38714900 and other OSS tests. The bug has been fixed by this PR. But we decide that it is safer to revert both, merge them into one PR, then reland the fix
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
Summary:
In https://github.com/pytorch/pytorch/pull/71146 that line was changed:
- before, the test would run on CUDA and skip on ROCm
- after, the test would skip on CUDA, skip on old ROCm and run on new ROCm
I believe the intention however was that it would run on CUDA, skip on old ROCm, and run on new ROCm.
Found by sypneiwski.
Test Plan:
eyes
By looking at the logs of the CI once it runs.
Differential Revision: D38582143
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83182
Approved by: https://github.com/albanD, https://github.com/malfet
### Description
<!-- What did you change and why was it needed? -->
The nested_tensor impl for `contiguous` was currently disabled. Prior to the work on nested_tensor transpose. Only contiguous nested tensors could be created from python. However now is possible to create nested tensors that are non contiguous. This pr links up the existing function used at the c++ level to the python function.
### Tests
Updated Test in `test/test_nestedtensor.py`
### Notes
The inference mode had to be removed for this test. This is because the func `.contiguous` is a composite implicit function. Currently this does not work in inference mode. However: https://github.com/pytorch/pytorch/pull/81838 should fix that issue.
### Why
When writing kernels in Triton for nested tensors I exposed a helper function that returned the "Buffer" tensor to python. Now contiguity can be checked before running any triton kernel. Also a good follow up would be making `nt.contiguous` on non contiguous nested tensors return a contiguous nested tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82147
Approved by: https://github.com/jbschlosser
### Description
Skip messages can't be found in the logs due to restrictions w/ running in parallel and they take up too much space/required a lot of scrolling if you wanted to look at failure info instead, so tell people that they can still be found in the xml files.
### Testing
Look at the logs to make sure it actually got printed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82901
Approved by: https://github.com/huydhn
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
### Description
Since the major changes for `_TypedStorage` and `_UntypedStorage` are now complete, they can be renamed to be public.
`TypedStorage._untyped()` is renamed to `TypedStorage.untyped()`.
Documentation for storages is improved as well.
### Issue
Fixes#82436
### Testing
N/A
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82438
Approved by: https://github.com/ezyang
If you still want this in CI, we should have a separate CI only
configuration. The current config is pretty unfriendly for local
development.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82262
Approved by: https://github.com/clee2000
Currently we have 2 ways of doing the same thing for torch dispatch and function modes:
`with push_torch_dispatch_mode(X)` or `with X.push(...)`
is now the equivalent of doing
`with X()`
This removes the first API (which is older and private so we don't need to go through a deprecation cycle)
There is some risk here that this might land race with a PR that uses the old API but in general it seems like most are using the `with X()` API or `enable_torch_dispatch_mode(X())` which isn't getting removed.
EDIT: left the `with X.push(...)` API since there were ~3 land races with that over the past day or so. But made it give a warning and ask users to use the other API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78215
Approved by: https://github.com/ezyang
Context: For a while slow gradcheck CI was skipping nearly all tests and this hid the fact that it should've been failing and timing out (10+h runtime for TestGradients). The CI configuration has since been fixed to correct this, revealing the test failures. This PR reenables slow gradcheck CI and makes it pass again.
This PR:
- makes slow and failing tests run in fast gradcheck mode only
- reduce the input size for slow gradcheck only for unary/binary ufuncs (alternatively, skip the test entirely)
- skip entire test files on slow gradcheck runner if they don't use gradcheck (test_ops, test_meta, test_decomp, test_ops_jit)
- reduces the input size for some ops
Follow ups:
1. Investigate slow mode failures https://github.com/pytorch/pytorch/issues/80411
2. See if we can re-enable slow gradcheck tests for some of the slow tests by reducing the sizes of their inputs
The following are failing in slow mode, they are now running in fast mode only.
```
test_fn_fwgrad_bwgrad___rmod___cuda_float64
test_fn_fwgrad_bwgrad_linalg_householder_product_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_float64
test_fn_fwgrad_bwgrad_linalg_matrix_power_cuda_complex128
test_fn_fwgrad_bwgrad_cat_cuda_complex128
test_fn_fwgrad_bwgrad_linalg_lu_factor_ex_cuda_float64
test_fn_fwgrad_bwgrad_copysign_cuda_float64
test_fn_fwgrad_bwgrad_cholesky_inverse_cuda_complex128
test_fn_fwgrad_bwgrad_float_power_cuda_complex128
test_fn_fwgrad_bwgrad_fmod_cuda_float64
test_fn_fwgrad_bwgrad_float_power_cuda_float64
test_fn_fwgrad_bwgrad_linalg_lu_cuda_float64
test_fn_fwgrad_bwgrad_remainder_cuda_float64
test_fn_fwgrad_bwgrad_repeat_cuda_complex128
test_fn_fwgrad_bwgrad_prod_cuda_complex128
test_fn_fwgrad_bwgrad_slice_scatter_cuda_float64
test_fn_fwgrad_bwgrad_tile_cuda_complex128
test_fn_fwgrad_bwgrad_pow_cuda_float64
test_fn_fwgrad_bwgrad_pow_cuda_complex128
test_fn_fwgrad_bwgrad_fft_*
test_fn_fwgrad_bwgrad_zero__cuda_complex128
test_fn_gradgrad_linalg_lu_factor_cuda_float64
test_fn_grad_div_trunc_rounding_cuda_float64
test_fn_grad_div_floor_rounding_cuda_float64
```
Marks the OpInfos for the following ops that run slowly in slow gradcheck as `fast_gradcheck` only (the left column represents runtime in seconds):
```
0 918.722 test_fn_fwgrad_bwgrad_nn_functional_conv_transpose3d_cuda_float64
1 795.042 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_complex128
2 583.63 test_fn_fwgrad_bwgrad_nn_functional_max_pool3d_cuda_float64
3 516.946 test_fn_fwgrad_bwgrad_svd_cuda_complex128
4 503.179 test_fn_fwgrad_bwgrad_linalg_svd_cuda_complex128
5 460.985 test_fn_fwgrad_bwgrad_linalg_lu_cuda_complex128
6 401.04 test_fn_fwgrad_bwgrad_linalg_lstsq_grad_oriented_cuda_complex128
7 353.671 test_fn_fwgrad_bwgrad_nn_functional_max_pool2d_cuda_float64
8 321.903 test_fn_fwgrad_bwgrad_nn_functional_gaussian_nll_loss_cuda_float64
9 307.951 test_fn_fwgrad_bwgrad_stft_cuda_complex128
10 266.104 test_fn_fwgrad_bwgrad_svd_lowrank_cuda_float64
11 221.032 test_fn_fwgrad_bwgrad_istft_cuda_complex128
12 183.741 test_fn_fwgrad_bwgrad_lu_unpack_cuda_complex128
13 132.019 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_float64
14 125.343 test_fn_fwgrad_bwgrad_nn_functional_pad_constant_cuda_complex128
15 124.2 test_fn_fwgrad_bwgrad_kron_cuda_complex128
16 123.721 test_fn_fwgrad_bwgrad_pca_lowrank_cuda_float64
17 121.074 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
18 119.387 test_fn_fwgrad_bwgrad_rot90_cuda_complex128
19 112.889 test_fn_fwgrad_bwgrad__masked_normalize_cuda_complex128
20 107.541 test_fn_fwgrad_bwgrad_dist_cuda_complex128
21 106.727 test_fn_fwgrad_bwgrad_diff_cuda_complex128
22 104.588 test_fn_fwgrad_bwgrad__masked_cumprod_cuda_complex128
23 100.135 test_fn_fwgrad_bwgrad_nn_functional_feature_alpha_dropout_with_train_cuda_float64
24 88.359 test_fn_fwgrad_bwgrad_mH_cuda_complex128
25 86.214 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
26 83.037 test_fn_fwgrad_bwgrad_nn_functional_bilinear_cuda_float64
27 79.987 test_fn_fwgrad_bwgrad__masked_cumsum_cuda_complex128
28 77.822 test_fn_fwgrad_bwgrad_diag_embed_cuda_complex128
29 76.256 test_fn_fwgrad_bwgrad_mT_cuda_complex128
30 74.039 test_fn_fwgrad_bwgrad_linalg_lu_solve_cuda_complex128
```
```
0 334.142 test_fn_fwgrad_bwgrad_unfold_cuda_complex128
1 312.791 test_fn_fwgrad_bwgrad_linalg_lu_factor_cuda_complex128
2 121.963 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
3 108.085 test_fn_fwgrad_bwgrad_diff_cuda_complex128
4 89.418 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
5 72.231 test_fn_fwgrad_bwgrad___rdiv___cuda_complex128
6 69.433 test_fn_fwgrad_bwgrad___getitem___cuda_complex128
7 68.582 test_fn_fwgrad_bwgrad_ldexp_cuda_complex128
8 68.572 test_fn_fwgrad_bwgrad_linalg_pinv_cuda_complex128
9 67.585 test_fn_fwgrad_bwgrad_nn_functional_glu_cuda_float64
10 66.567 test_fn_fwgrad_bwgrad_lu_cuda_float64
```
```
0 630.13 test_fn_gradgrad_nn_functional_conv2d_cuda_complex128
1 81.086 test_fn_gradgrad_linalg_solve_triangular_cuda_complex128
2 71.332 test_fn_gradgrad_norm_cuda_complex128
3 64.308 test_fn_gradgrad__masked_std_cuda_complex128
4 59.519 test_fn_gradgrad_div_no_rounding_mode_cuda_complex128
5 58.836 test_fn_gradgrad_nn_functional_adaptive_avg_pool3
```
Reduces the sizes of the inputs for:
- diff
- diag_embed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80514
Approved by: https://github.com/albanD
This PR uses pytest to run test_ops, test_ops_gradients, and test_ops_jit in parallel in non linux cuda environments to decrease TTS. I am excluding linux cuda because running in parallel results in errors due to running out of memory
Notes:
* update hypothesis version for compatability with pytest
* use rerun-failures to rerun tests (similar to flaky tests, although these test files generally don't have flaky tests)
* reruns are denoted by a rerun tag in the xml. Failed reruns also have the failure tag. Successes (meaning that the test is flaky) do not have the failure tag.
* see https://docs.google.com/spreadsheets/d/1aO0Rbg3y3ch7ghipt63PG2KNEUppl9a5b18Hmv2CZ4E/edit#gid=602543594 for info on speedup (or slowdown in the case of slow tests)
* expecting windows tests to decrease by 60 minutes total
* slow test infra is expected to stay the same - verified by running pytest and unittest on the same job and check the number of skipped/run tests
* test reports to s3 changed - add entirely new table to keep track of invoking_file times
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79898
Approved by: https://github.com/malfet, https://github.com/janeyx99
freeze_rng_state() is this thing we use to test random operations in
OpInfos: it ensures that everytime the op is called the rng state is the
same.
Unfortunately this doesn't work with functorch, because
- torch.cuda.set_rng_state() clones a Tensor and then grabs its data_ptr
- functorch's modes cause functorch wrappers to get emitted on the
.clone() call (even if the thing being cloned a regular Tensor).
Tensor subclasses also had this problem. This PR applies the same
solution as torch_dispatch did before: we're just going to disable
functorch dispatch when setting the rng state.
In the long run, torch_dispatch should probably have an option to
interpose on torch.cuda.set_rng_state or generator.set_state... but I
didn't want to think very hard right now.
Test Plan:
- tested with functorch tests (those tests were previously being
skipped, now I can unskip some of them).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81006
Approved by: https://github.com/samdow
Summary:
Add test just to check if TransformerEncoder will crash when enumerating over params [with_no_grad, use_torchscript, training].
Motivation for this was that TransformerEncoder fast path (so with_no_grad=True) and use_torchscript=True would crash with the issue that NestedTensor doesn't have size. This was caused because the TransformerEncoder fast path generates a NestedTensor automatically as a perf optimization and torchscript attempts to find intermediate tensor sizes while it optimizes. But NestedTensor has not implemented a size method, so things fail.
This test goes together with this fix https://github.com/pytorch/pytorch/pull/79480
Test Plan:
```
buck build --show-output mode/opt -c fbcode.enable_gpu_sections=true -c fbcode.nvcc_arch=a100 mode/inplace //caffe2/test:transformers
./fbcode/buck-out/gen/caffe2/test/transformers#binary.par
```
Test runs and passes together with the changes from the PR above (I made another diff on top of this with those changes). Does not pass without the fix.
Reviewed By: mikekgfb
Differential Revision: D37222923
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79796
Approved by: https://github.com/zrphercule
Ref #54789
A `bool` has only two valid values, 1 or 0. Any in-memory value
outside of those leads to undefined behavior. So, instead of
`reinterpret_cast`-ing to `bool*` I introduce `c10::load<scalar_t>`
which will read as `unsigned char` and convert to a valid `bool`.
This gets >90% of operators working, but the remaining operators where
skips and xfails have been added will require individual attention.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77122
Approved by: https://github.com/mruberry
The change
1. Returns the input param in `instantiate_parametrized_tests` so that we can use it as a decorator.
Instead of
```python
instantiate_parametrized_tests(SomeTestClass)
```
we can now do
```python
@instantiate_parametrized_tests
class SomeTestClass:
...
```
2. Strips spaces around parameters in `parametrize`.
Both
```python
@parametrize("x,y", [(1, 'foo'), (2, 'bar'), (3, 'baz')])
def test_bar(self, x, y):
...
```
and
```python
@parametrize("x, y", [(1, 'foo'), (2, 'bar'), (3, 'baz')])
def test_bar(self, x, y):
...
```
(or
```python
@parametrize("x, y", [(1, 'foo'), (2, 'bar'), (3, 'baz')])
````
, for that matter), are now parsed to the correct argument names.
3. Decorates test wrappers with `functools.wraps` to preserve the test method names (previously the names become "wrapper_xxx", which prevents the parameterized tests from getting the correct names.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78228
Approved by: https://github.com/garymm, https://github.com/seemethere
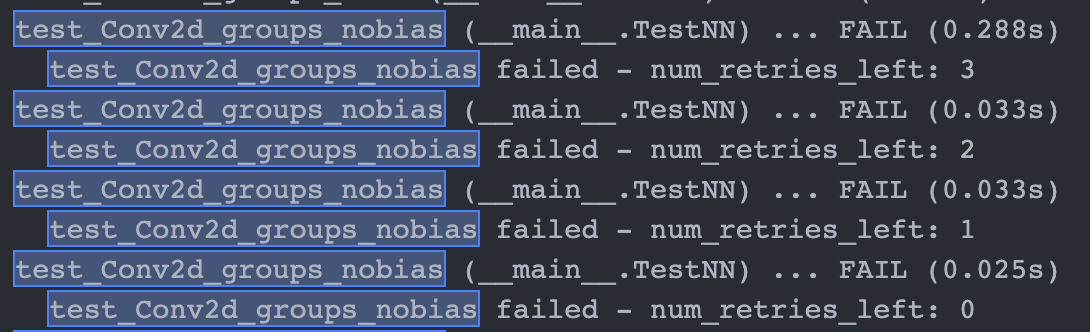
Give context about failures ~and include it in the test report~! Unfortunately I cannot include it easily in the test report through the addExpectedFailures :c as tracebacks are not something I can instantiate. (see revert comment)
Current way doesn't print the stack traces, which has been fine because we don't hide the signal and it shows up at the end:
<img width="545" alt="image" src="https://user-images.githubusercontent.com/31798555/168878182-914edc39-369f-40bc-8b35-9d5cd47a6b1c.png">
However, when we want to hide the signal, we'd like to print the stack traces for each failed attempt, as it won't be shown at the end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77664
Approved by: https://github.com/suo
{kind=link}