The old code didn't actually fakeify traceable tensor subclasses at the
time they are added as a GraphArg to the module; now we do, by ignoring
the subclass during fakeification and relying on Dynamo to simulate
the subclass on top. See comments for more details.
BTW, this codepath is super broken, see filed issues linked on the
inside.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90009
Approved by: https://github.com/wconstab, https://github.com/voznesenskym
Summary:
This diff is reverting D41682843
D41682843 has been identified to be causing the following test or build failures:
Tests affected:
- https://www.internalfb.com/intern/test/281475048939643/
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1444954
Here are the tasks that are relevant to this breakage:
T93770103: 5 tests started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: zyan0, atuljangra, YazhiGao
Differential Revision: D41710749
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90132
Approved by: https://github.com/awgu
This was separated out from the previous PR to decouple. Since not all builds include `torch.distributed`, we should define the globals in the dynamo file and import to distributed instead of vice versa. Unlike the version from the previous PR, this PR prefixes the globals with `_` to future proof against `_dynamo/` eventually becoming public.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89913
Approved by: https://github.com/wconstab
- This is a strict requirement given the way dynamo+FSDP is implemented,
but isn't convenient to assert.
- By plumbing use_orig_param field on all wrapped modules, we can
do this assertion inside dynamo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89523
Approved by: https://github.com/awgu
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
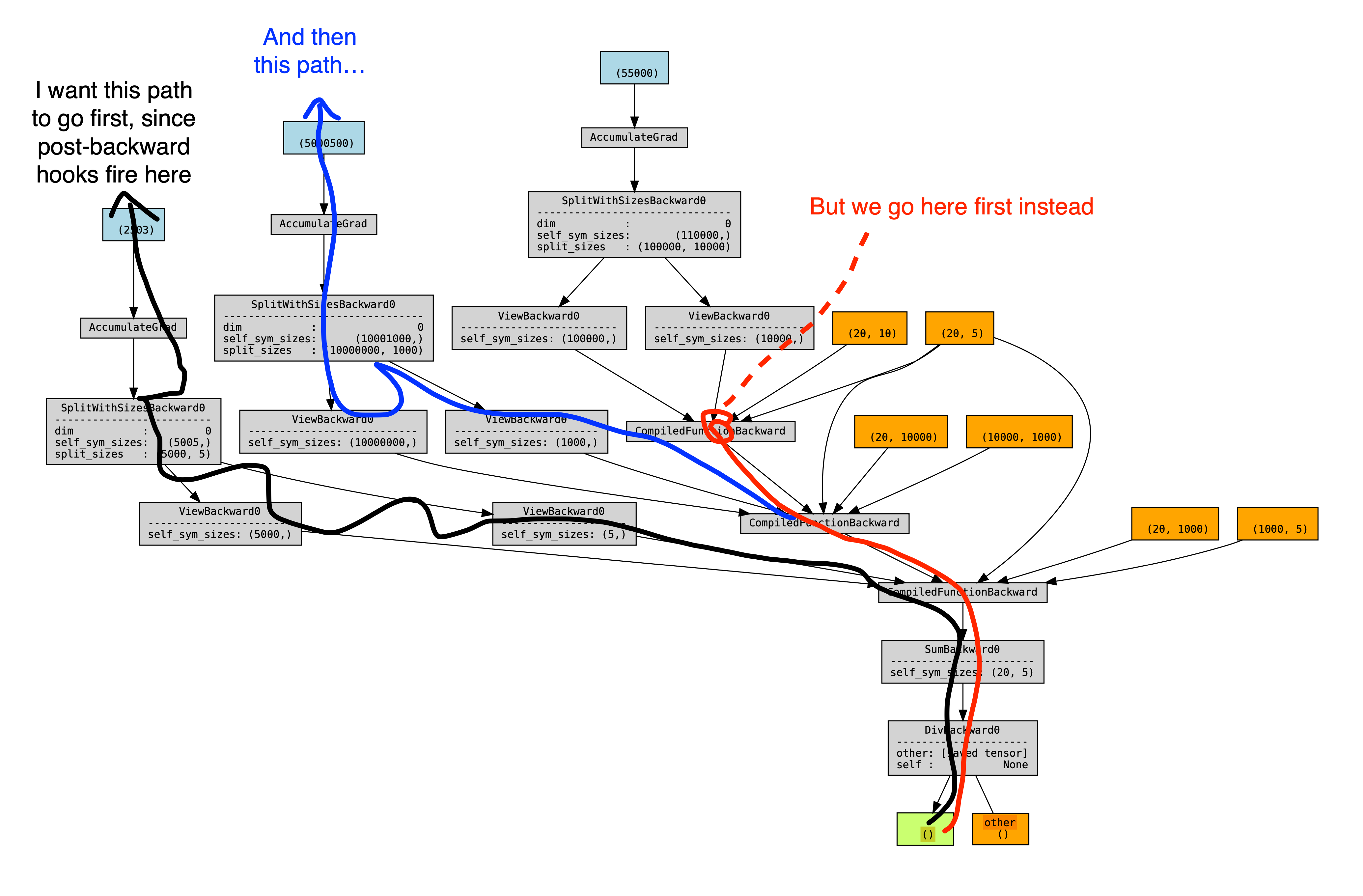
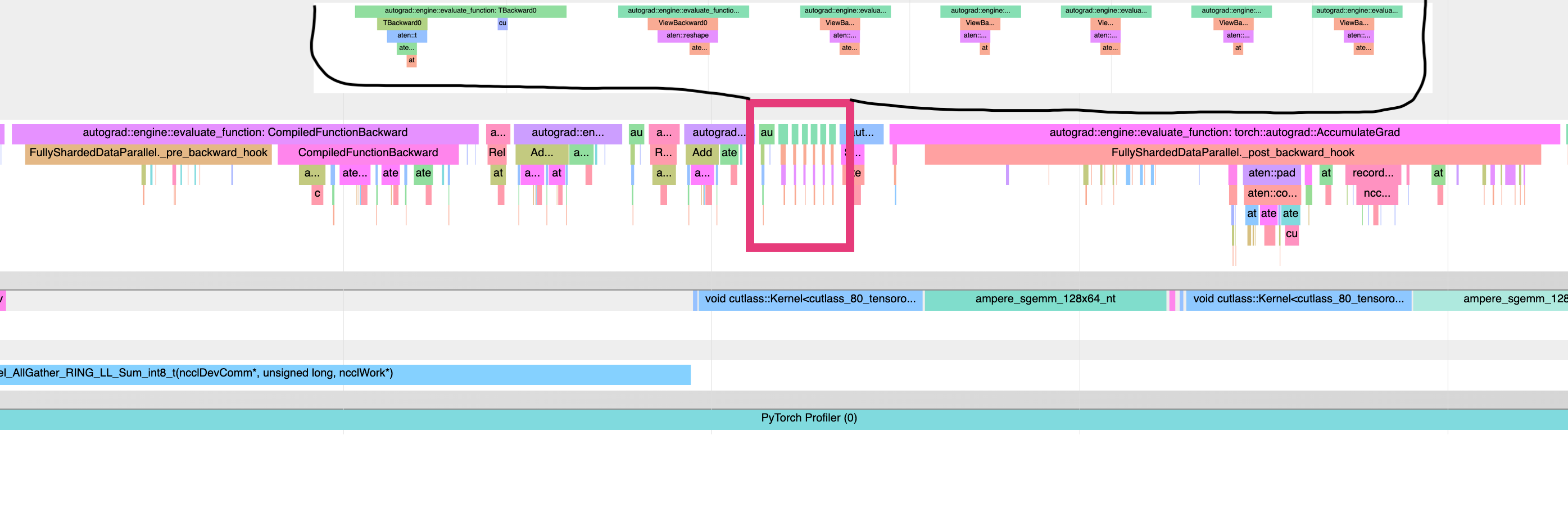
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
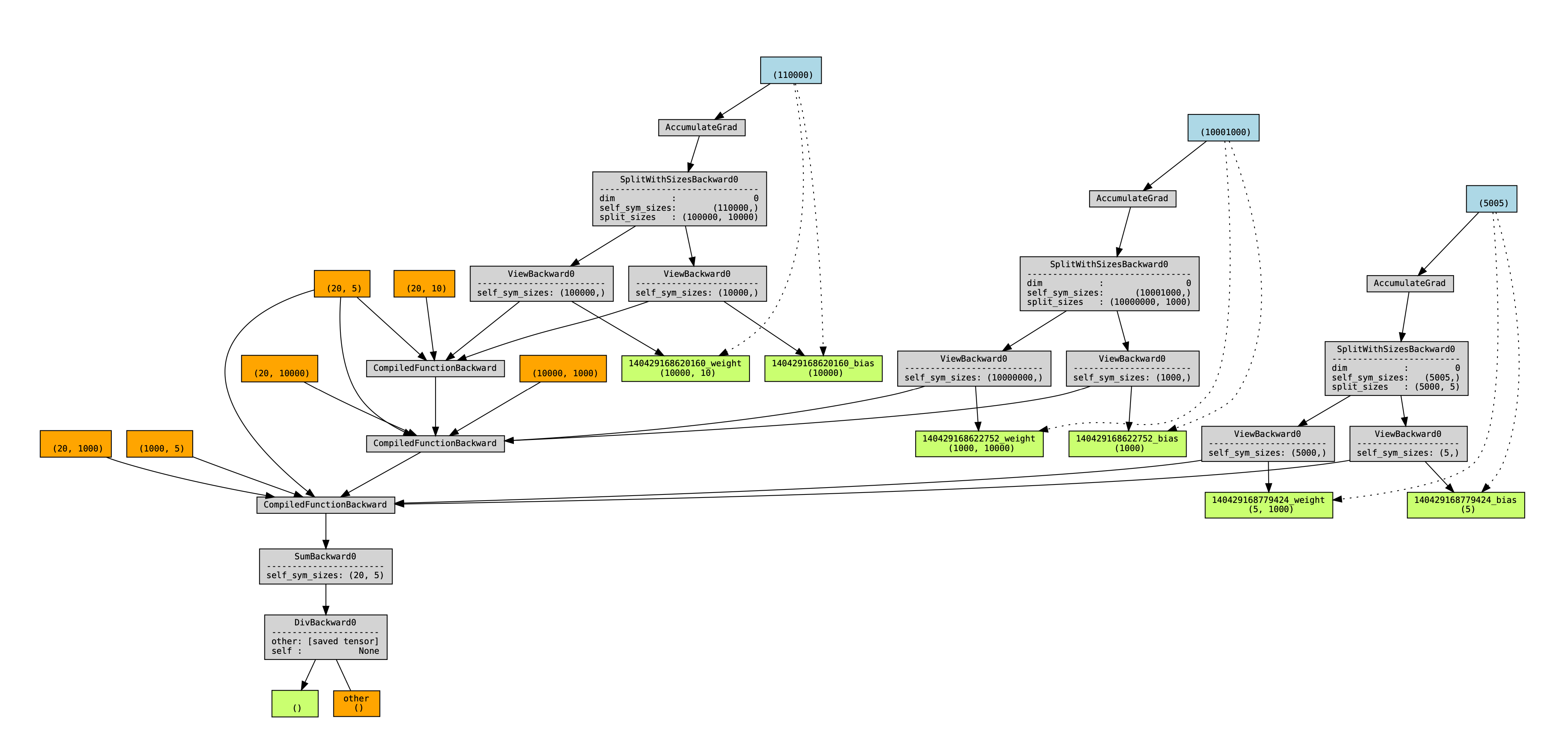
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
This is a slight regression: RAdam and Adagrad don't appear to
trace at all under fake tensors. But I think this is a more accurate
reflection of the current state of affairs.
Along the way fix some problems on the fake tensor path.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89643
Approved by: https://github.com/anjali411
Previously, we hackily wrapped unspecialized integers into
tensors and treated them as tensor inputs. Sometimes, downstream
operations would not be able to deal with the tensor input. Now,
we wrap them into SymInt, so more correct overload selection occurs.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89639
Approved by: https://github.com/anjali411
{kind=link}
{kind=link}
{kind=link}
{kind=link}