### Description
- This PR renames `_all_gather_base` to `all_gather_into_tensor` so that it is clearer in meaning.
- The `all_gather_into_tensor` API differs from the `all_gather` API in the output it accepts -- a single, large tensor instead of a list of tensors.
- This PR also adds deprecation warning to `_all_gather_base`.
### Issue
`_all_gather_base` was implemented in https://github.com/pytorch/pytorch/pull/33924 to avoid unnecessary flattening. There was previous effort (#82639) to merge `_all_gather_base` with the existing `all_gather` API by detecting the parameter type passed in for the output.
There are, however, two "blockers" that make the merge difficult:
(i) The merge leads to backward compatibility break. We would need to change the parameter name `tensor_list` in `all_gather` to a general name `output` that can cover both tensor and tensor list.
(ii) Recently, the `all_gather` API has added uneven tensor support, utilizing the tensor boundaries implied by the list. We are, however, not sure to add such support to the `_all_gather_base` function, because that would require users to pass in additional tensor boundary information.
In view of the above, we decided to productize `_all_gather_base` as a separate function, but with a clearer name.
### Testing
Added tests:
- `test_all_gather_into_cat_tensor_cuda` -- output form as with `torch.cat`. For example:
```
>>> tensor_in
tensor([1, 2], device='cuda:0') # Rank 0
tensor([3, 4], device='cuda:1') # Rank 1
>>> tensor_out
tensor([1, 2, 3, 4], device='cuda:0') # Rank 0
tensor([1, 2, 3, 4], device='cuda:1') # Rank 1
```
- `test_all_gather_into_stack_tensor_cuda` -- output form as with `torch.stack`. For example:
```
>>> tensor_out2
tensor([[1, 2],
[3, 4]], device='cuda:0') # Rank 0
tensor([[1, 2],
[3, 4]], device='cuda:1') # Rank 1
```
The output form is determined by the shape of the output tensor passed by the user, no flag used.
Cc @rohan-varma @mrshenli @crcrpar @ptrblck @H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85686
Approved by: https://github.com/rohan-varma, https://github.com/crcrpar
Move a bunch of globals to instance methods and replace all use to them.
We move all PG related globals under World and use a singleton instance under _world.
This creates an undocumented extension point to inject full control of how how c10d
state behaves.
One simple hack is to change _world to an implementation that uses a threadlocal
and enable per-thread PGs.
It almost get DDP working and the PG is missing an implementation of all_reduce.
This enables notebook usage of PTD, which is a big deal for learning it:
https://gist.github.com/kumpera/32cb051fa26b8cad8bdf671f968dcd68
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84153
Approved by: https://github.com/rohan-varma
0.123 isn't exactly representable as a floating point value, and so
the threshold will move marginally depending on the data type where
the computation is performed. This leads to a rare flake in tests
comparing against a reference implementation.
Instead, this chooses a threshold which is exactly representable as a
bfloat16 value and thus has the same value for all data types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85676
Approved by: https://github.com/ngimel
Fixes https://github.com/pytorch/pytorch/issues/85535
Also fixes the backward and forward gradients of `nn.functional.threshold`. The issue was that in-place gradients weren't tested because the in-place variants were not properly registered to the OpInfo.
Perhaps an alternative to this to make auto_element_wise smart enough to actually handle the in-places cases (we have 4 cases total now where we manually copy_ after doing auto_element_wise), but that requires a few more changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85634
Approved by: https://github.com/albanD
Based on @ezyang's suggestion, mode stack now has "one true mode" which is the _only_ mode that can ever be active at the C++ level. That mode's torch dispatch is just to take the top mode in the stack, reenable itself (if we aren't at the end of the mode stack), and run the top mode's torch_{dispatch|function}
This maintains that in the middle of a mode's torch dispatch, the mode itself will not be active. It changes the function the user has to call to see what the current mode is (no longer queries the C++, it's python only) but allows the user to also see the entire mode stack easily
Removes `enable_torch_dispatch_mode` and `.restore()` since neither makes sense in this new setup
### Background
Why do we want this? Well, a pretty common pattern that was coming up was that users had to do something like
```python
## PRE-PR UX
def f(mode):
with mode.restore(): # user needs to understand this restore thing?
...
with Mode() as m:
pass
f(m)
```
Many users were getting error from forgetting to call `.restore` or from forgetting to add the (tbh weird) "mode instantiation" step where they use the mode as a context manager with an empty body. Really, they wanted to treat modes like context managers and just write
```python
## FROM FEEDBACK, USER DESIRED CODE. POSSIBLE POST-PR
def f(mode):
with mode:
...
f(Mode())
```
** Technical Details **
With the old mode stack, we basically had a linked list so the mode itself could only be used once and had a fixed parent. In this new design, the mode stack is just a python list that we're pushing to and popping from. There's only one mode that's ever active at the C++ level and it runs the next mode in the Python list. The modes don't have state on them anymore
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84774
Approved by: https://github.com/ezyang, https://github.com/zou3519
Fixes#85615
Currently, internal test discovery instantiates an `ArgumentParser` and adds numerous arguments to the internal parser:
f0570354dd/torch/testing/_internal/common_utils.py (L491-L500)
...
In this context, `argparse` will load [system args](b494f5935c/Lib/argparse.py (L1826-L1829)) from any external scripts invoking PyTorch testing (e.g. `vscode`).
The default behavior of `argparse` is to [allow abbreviations](b494f5935c/Lib/argparse.py (L2243-L2251)) of arguments, but when an `ArgumentParser` instance has many arguments and may be invoked in the context of potentially conflicting system args, the `ArgumentParser` should reduce the potential for conflicts by being instantiated with `allow_abbrev` set to `False`.
With the current default configuration, some abbreviations of the `ArgumentParser` long options conflict with system args used by `vscode` to invoke PyTorch test execution:
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/visualstudio_py_testlauncher.py \
--us=./test --up=test_cuda.py --uvInt=2 -ttest_cuda.TestCuda.test_memory_allocation \
--testFile=./test/test_cuda.py
>>>PYTHON-EXEC-OUTPUT
...
visualstudio_py_testlauncher.py: error: argument --use-pytest: ignored explicit argument './test'
```
The full relevant stack:
```
pytorch/test/jit/test_cuda.py, line 11, in <module>\n from torch.testing._internal.jit_utils import JitTestCase\n'\
pytorch/torch/testing/_internal/jit_utils.py, line 18, in <module>\n from torch.testing._internal.common_utils import IS_WINDOWS, \\\n'
pytorch/torch/testing/_internal/common_utils.py, line 518, in <module>\n args, remaining = parser.parse_known_args()\n'
argparse.py, line 1853, in parse_known_args\n namespace, args = self._parse_known_args(args, namespace)\n'
argparse.py, line 2062, in _parse_known_args\n start_index = consume_optional(start_index)\n'
argparse.py, line 1983, in consume_optional\n msg = _(\'ignored explicit argument %r\')\n'
```
The `argparse` [condition](b494f5935c/Lib/argparse.py (L2250)) that generates the error in this case:
```python
print(option_string)
--use-pytest
print(option_prefix)
--us
option_string.startswith(option_prefix)
True
```
It'd be nice if `vscode` didn't use two-letter options 🤦 but PyTorch testing shouldn't depend on such good behavior by invoking wrappers IMHO.
I haven't seen any current dependency on the abbreviated internal PyTorch `ArgumentParser` options so this change should only extend the usability of the (always improving!) PyTorch testing modules.
This simple PR avoids these conflicting options by instantiating the `ArgumentParser` with `allow_abbrev=False`
Thanks to everyone in the community for their continued contributions to this incredibly valuable framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85616
Approved by: https://github.com/clee2000
Fixes#85578
Currently, many test modules customize test loading and discovery via the [load_tests protocol](https://docs.python.org/3/library/unittest.html#load-tests-protocol). The salient custom behavior included (introduced with https://github.com/pytorch/pytorch/pull/13250) is to verify that the script discovering or executing the test is the same script in which the test is defined.
I believe this unnecessarily precludes the use of external tools to discover and execute tests (e.g. the vscode testing extension is widely used and IMHO quite convenient).
This simple PR retains the current restriction by default while offering users the option to disable the aforementioned check if desired by setting an environmental variable.
For example:
1. Setup a test env:
```bash
./tools/nightly.py checkout -b some_test_branch
conda activate pytorch-deps
conda install -c pytorch-nightly numpy expecttest mypy pytest hypothesis astunparse ninja pyyaml cmake cffi typing_extensions future six requests dataclasses -y
```
2. The default test collection behavior discovers 5 matching tests (only tests within `test/jit/test_cuda.py` because it doesn't alter the default `load_test` behavior:
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/testing_tools/unittest_discovery.py \
./test test_cuda.py | grep test_cuda | wc -l
5
```
3. Set the new env variable (in vscode, you would put it in the .env file)
```bash
export PYTORCH_DISABLE_RUNNING_SCRIPT_CHK=1
```
4. All of the desired tests are now discovered and can be executed successfully!
```bash
python ~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/get_output_via_markers.py \
~/.vscode-server/extensions/ms-python.python-2022.14.0/pythonFiles/testing_tools/unittest_discovery.py \
./test test_cuda.py | grep test_cuda | wc -l
175
```
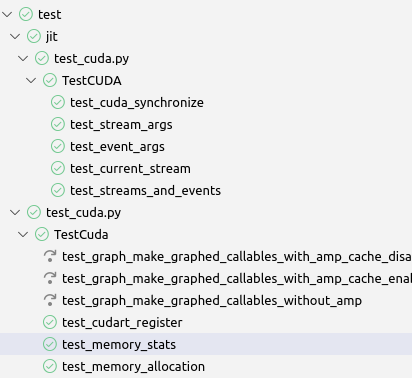
A potentially relevant note, the previous behavior of the custom `load_tests` flattened all the `TestSuite`s in each test module:
4c01c51266/torch/testing/_internal/common_utils.py (L3260-L3262)
I haven't been able to find any code that depends upon this behavior but I think retaining the `TestSuite` structure is preferable from a user perspective and likely safe (`TestSuite`s [can be executed](https://docs.python.org/3/library/unittest.html#load-tests-protocol:~:text=test%20runner%20to-,allow%20it%20to%20be%20run,-as%20any%20other) just like `TestCase`s and this is the structure [recommended](https://docs.python.org/3/library/unittest.html#load-tests-protocol:~:text=provides%20a%20mechanism%20for%20this%3A%20the%20test%20suite) by the standard python documentation).
If necessary, I can change this PR to continue flattening each test module's `TestSuite`s. Since I expect external tools using the `unittest` `discover` API will usually assume discovered `TestSuite`s to retain their structure (e.g. like [vscode](192c3eabd8/pythonFiles/visualstudio_py_testlauncher.py (L336-L349))) retaining the `testsuite` flattening behavior would likely require customization of those external tools for PyTorch though.
Thanks to everyone in the community for the continued contributions to this incredibly valuable framework!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85584
Approved by: https://github.com/huydhn
This is based on wconstab tests from #84680
Technically, slice is covered by the __getitem__ opinfo, but it is
easier to debug/test on a more narrow internal function that only
uses this functionality and not other advanced indexing stuff.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85554
Approved by: https://github.com/mruberry, https://github.com/wconstab
# Summary
This exposes the _scaled_dot_product_attention function to python in the nn namespace. It is still underscored because the api for args, and kwargs is still in flux for the next few weeks and will eventually land as a prototype feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85044
Approved by: https://github.com/cpuhrsch
run tests in parallel at the test file granularity
runs 3 files in parallel using multiprocessing pool, output goes to a file, which is then printed when the test finishes. Some tests cannot be run in parallel (usually due to lacking memory), so we run those after. Sharding is changed to attempt to mask large files with other large files/run them on the same shard.
test_ops* gets a custom handler to run it because it is simply too big (2hrs on windows) and linalg_cholesky fails (I would really like a solution to this if possible, but until then we use the custom handler).
reduces cuda tests by a lot, reduces total windows test time by ~1hr
Ref. https://github.com/pytorch/pytorch/issues/82894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84961
Approved by: https://github.com/huydhn
- This implements explicit forward prefetching following the static 1st iteration's pre-forward order when `forward_prefetch=True` in the FSDP constructor.
- This has the same unit test coverage as the original `forward_prefetch`.
- I checked via print statements that the prefetches are happening, but since I cannot get a good CPU bound workload, it is hard to tell via traces that the prefetch is working.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85177
Approved by: https://github.com/zhaojuanmao
# Summary
This exposes the _scaled_dot_product_attention function to python in the nn namespace. It is still underscored because the api for args, and kwargs is still in flux for the next few weeks and will eventually land as a prototype feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85044
Approved by: https://github.com/cpuhrsch
{kind=link}