Summary:
Input argument `f` in `_model_to_graph()` method in `torch/onnx/utils.py` is unused. This PR removes it. If there's a reason to keep it around, please let me know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19647
Reviewed By: dzhulgakov
Differential Revision: D15071720
Pulled By: houseroad
fbshipit-source-id: 59e0dd7a4d5ebd64d0e30f274b3892a4d218c496
Summary:
in functional interfaces we do boolean dispatch, but all to max_pool\*d_with_indices. This change it to emit max_pool\*d op instead when it's not necessary to expose with_indices ops to different backends (for jit).
It also bind max_pool\*d to the torch namespace, which is the same behavior with avg_pool\*d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19449
Differential Revision: D15016839
Pulled By: wanchaol
fbshipit-source-id: f77cd5f0bcd6d8534c1296d89b061023a8288a2c
Summary:
Strip the doc_string by default from the exported ONNX models (this string has the stack trace and information about the local repos and folders, which can be confidential).
The users can still generate the doc_string by specifying add_doc_string=True in torch.onnx.export().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18882
Differential Revision: D14889684
Pulled By: houseroad
fbshipit-source-id: 26d2c23c8dc3f484544aa854b507ada429adb9b8
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Now compatible with both torch scripts:
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"), pin_memory=False)`
and
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"))`
Same checked for all similar functions `rand_like`, `empty_like` and others
It is fixed version of #18455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18952
Differential Revision: D14801792
Pulled By: VitalyFedyunin
fbshipit-source-id: 8dbc61078ff7a637d0ecdb95d4e98f704d5450ba
Summary:
If JIT constant propagation doesn't work, we have to handle the ListConstructor in symbolic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19102
Reviewed By: zrphercule
Differential Revision: D14875588
Pulled By: houseroad
fbshipit-source-id: d25c847d224d2d32db50aae1751100080e115022
Summary:
Almost there, feel free to review.
these c10 operators are exported to _caffe2 domain.
TODO:
- [x] let the onnx checker pass
- [x] test tensor list as argument
- [x] test caffe2 backend and converter
- [x] check the c10 schema can be exported to onnx
- [x] refactor the test case to share some code
- [x] fix the problem in ONNX_ATEN_FALLBACK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18210
Reviewed By: zrphercule
Differential Revision: D14600916
Pulled By: houseroad
fbshipit-source-id: 2592a75f21098fb6ceb38c5d00ee40e9e01cd144
Summary:
Introduce this check to see whether it will break any existing workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18145
Reviewed By: dzhulgakov
Differential Revision: D14511711
Pulled By: houseroad
fbshipit-source-id: a7bb6ac84c9133fe94d3fe2f1a8566faed14a136
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18455
Reviewed By: ezyang
Differential Revision: D14672084
Pulled By: VitalyFedyunin
fbshipit-source-id: 9d0997ec00f59500ee018f8b851934d334012124
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18512
Ceil and Floor have been supported since version 6 of ONNX: export them using the native onnx ops instead of an Aten op.
Similarly, support for the Where op has been added in version 9, so we don't need to wrap these op in an Aten op.
Reviewed By: houseroad
Differential Revision: D14635130
fbshipit-source-id: d54a2b6e295074a6214b5939b21051a6735c9958
Summary:
Is Tensor has been brought up as misleading a couple times, rename it isCompleteTensor for clarity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18437
Differential Revision: D14605223
Pulled By: eellison
fbshipit-source-id: 189f67f12cbecd76516a04e67d8145c260c79036
Summary:
Set value as tensor of 1 element instead of scalar, according to ONNX spec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18199
Reviewed By: dzhulgakov
Differential Revision: D14542588
Pulled By: houseroad
fbshipit-source-id: 70dc978d870ebe6ef37c519ba4a20061c3f07372
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/12598
This PR was originally authorized by ptrblck at https://github.com/pytorch/pytorch/pull/15495, but since there was no update for months after the request change, I clone that branch and resolve the code reviews here. Hope everything is good now. Especially, the implementation of count is changed from ptrblck's original algorithm to the one ngimel suggest, i.e. using `unique_by_key` and `adjacent_difference`.
The currently implementation of `_unique_dim` is VERY slow for computing inverse index and counts, see https://github.com/pytorch/pytorch/issues/18405. I will refactor `_unique_dim` in a later PR. For this PR, please allow me to keep the implementation as is.
cc: ptrblck ezyang ngimel colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18391
Reviewed By: soumith
Differential Revision: D14605905
Pulled By: VitalyFedyunin
fbshipit-source-id: 555f5a12a8e28c38b10dfccf1b6bb16c030bfdce
Summary:
So, we will keep the names of ONNX initializers the same as the names in PyTorch state dict.
Later, we will make this as the default behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17551
Reviewed By: dzhulgakov
Differential Revision: D14491920
Pulled By: houseroad
fbshipit-source-id: f355c02e1b90d7ebbebf4be7c0fb6ae208ec795f
Summary:
The output format of NonZero in ONNX(numpy https://docs.scipy.org/doc/numpy/reference/generated/numpy.nonzero.html) differs from that in PyTorch:
In ONNX: `[rank_of_input, num_of_nonzeros]`, whereas in PyTorch: `[num_of_nonzeros, rank_of_input]`.
To resolve the difference a Transpose op after the nonzero output is added in the exporter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18047
Differential Revision: D14475081
Pulled By: ezyang
fbshipit-source-id: 7a3e4899f3419766b6145d3e9261e92859e81dc4
Summary:
1) The changes in the new opset won't affect internal pipeline.
2) The CI won't be affected by the ONNX changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17736
Reviewed By: zrphercule
Differential Revision: D14358710
Pulled By: houseroad
fbshipit-source-id: 4ef15d2246b50f6875ee215ce37ecf92d555ca6a
Summary:
Similar to `nn.Parameter`s, this PR lets you store any `IValue` on a module as an attribute on a `ScriptModule` (only from the Python front-end currently). To mark something as an attribute, it should wrapped in `jit.Attribute(value, type)` (ex. `self.table = torch.jit.Attribute(table, Dict[str, torch.Tensor])`)
Followup Work:
* (de)serializing for use in C++
* change `self.training` to be a `bool` attribute instead of a buffer
* mutable attributes
* string frontend support
* documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17309
Differential Revision: D14354316
Pulled By: driazati
fbshipit-source-id: 67e08ab5229366b67fbc837e67b58831a4fb3318
Summary:
Currently, serialization of model parameters in ONNX export depends on the order in which they are stored in a container (`list` on Python side and `std::vector` on C++ side). This has worked fine till now, but if we need to do any pass on that graph that mutates the parameter list, then strictly order-based serialization may not work.
This PR is the first in a set to bring in more passes (such as constant folding) related to ONNX export. This PR lays the groundwork by moving the serialization in ONNX export from order-based to name based approach, which is more amenable to some of the passes.
houseroad - As discussed this change uses a map for export, and removes the code from `export.cpp` that relies on the order to compute initializer names.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17420
Differential Revision: D14361993
Pulled By: houseroad
fbshipit-source-id: da93e945d55755c126de06641f35df87d1648cc4
Summary:
resize_ and resize_as resize the input tensor. because our shape analysis
is flow invariant, we don't do shape analysis on any op that relies on a Tensor that can alias a resized Tensor.
E.g. in the following graph the x += 10 x may have been resized.
```
torch.jit.script
def test(x, y):
for i in range(10):
x += 10
x.resize_as_([1 for i in int(range(torch.rand())))
return x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17518
Differential Revision: D14249835
Pulled By: eellison
fbshipit-source-id: f281b468ccb8c29eeb0f68ca5458cc7246a166d9
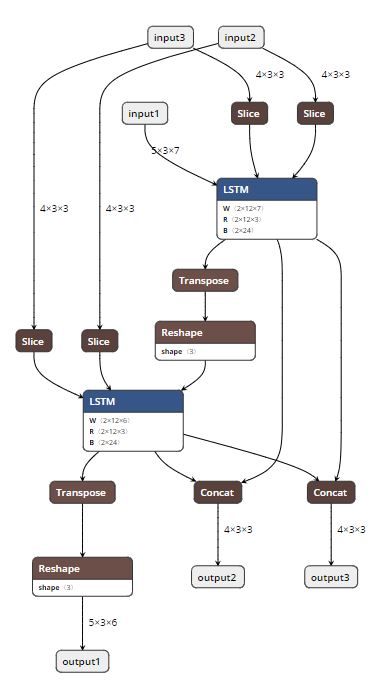
Summary:
Still wip, need more tests and correct handling for opset 8 in symbolics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16068
Reviewed By: zrphercule
Differential Revision: D14185855
Pulled By: houseroad
fbshipit-source-id: 55200be810c88317c6e80a46bdbeb22e0b6e5f9e
{kind=link}
{kind=link}