Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76366
caffe2 is not currently being built for XROS.
Test Plan: CI
Reviewed By: kimishpatel
Differential Revision: D35923922
fbshipit-source-id: 260dacadf0bd5b6bab7833a4ce81e896d280b053
(cherry picked from commit 8370b8dd2519d55a79fa8d45e7951ca8dc0b21a8)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73040
This patch fixes a compilation error in PyTorch with ROCm when `NDEBUG` is passed.
## Problem
Forward declaration of `__host__ __device__ __assert_fail()` is used in `c10/macros/Macros.h` for HIP compilation when `NDEBUG` is set However, HIP has `__device__ __assert_fail()` in `hip/amd_detail/amd_device_functions.h`, causing a function type error.
This issue does not appear in ROCm CI tests since it happens only when `NDEBUG` is passed.
## Solution
[EDIT] After the discussion on GitHub, we chose to entirely disable `CUDA_KERNEL_ASSERT()` for ROCm.
---
To solve this compilation error, this patch disables `CUDA_KERNEL_ASSERT()`, which uses `__assert_fail()` when
1. `c10/macros/Macros.h` is included for `*.hip` (precisely speaking, `__HIP__` or `__HIP_ARCH__` is defined), and
2. `NDEBUG` is passed.
Note that there's no impact on default compilation because, without a special compilation flag, those HIP files are compiled without `-NDEBUG`. And that's why this issue has not been found.
### Justification
[1] We cannot declare one host-and-device function for two separate host and device functions.
```
__device__ int func() {return 0};
__host__ int func() {return 0};
// Compile error (hipcc)
// __device__ __host__ int func();
```
[2] Forward declaration of a correct `__device__` only `__assert_fail()` for `__HIP__` causes the following error:
```
pytorch/c10/util/TypeCast.h:135:7: error: reference to __device__ function '__assert_fail' in __host__ __device__ function
ERROR_UNSUPPORTED_CAST
^
pytorch/c10/util/TypeCast.h:118:32: note: expanded from macro 'ERROR_UNSUPPORTED_CAST'
#define ERROR_UNSUPPORTED_CAST CUDA_KERNEL_ASSERT(false);
^
pytorch/c10/macros/Macros.h:392:5: note: expanded from macro 'CUDA_KERNEL_ASSERT'
__assert_fail(
```
[3] Maybe there's a way to properly define `__assert_fail()` for HIP + NDEBUG, but this might be too much. Please let me just disable it.
### Technical details
Error
```
pytorch/c10/macros/Macros.h:368:5: error: __host__ __device__ function '__assert_fail' cannot overload __device__ function '__assert_fail'
__assert_fail(
^
/opt/rocm/hip/include/hip/amd_detail/amd_device_functions.h:1173:6: note: previous declaration is here
void __assert_fail(const char *assertion,
```
CUDA definition (9.x) of `__assert_fail()`
```
#elif defined(__GNUC__)
extern __host__ __device__ __cudart_builtin__ void __assert_fail(
const char *, const char *, unsigned int, const char *)
__THROW;
```
ROCm definition (the latest version)
```
// 2b59661f3e/include/hip/amd_detail/amd_device_functions.h (L1172-L1177)
extern "C" __device__ __attribute__((noinline)) __attribute__((weak))
void __assert_fail(const char *assertion,
const char *file,
unsigned int line,
const char *function);
```
Test Plan:
CI + reproducer
```
python3 tools/amd_build/build_amd.py
python3 setup.py develop --cmake-only
cmake -DHIP_HIPCC_FLAGS_RELEASE="-DNDEBUG" build
cmake --build build
```
Reviewed By: xw285cornell
Differential Revision: D34310555
fbshipit-source-id: 7542288912590533ced3f20afd2e704b6551991b
(cherry picked from commit 9e52196e36820abe36bf6427cabc7389d3ea6cb5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71196
`caffe2` headers contain code that can elicit warnings when built with strict compiler flags. Rather than force downstream/consuming code to weaken their compiler flags, suppress those warnings in the header using `#pragma clang diagnostic` suppressions.
Test Plan: CI Pass
Reviewed By: malfet
Differential Revision: D33536233
fbshipit-source-id: 74404e7a5edaf244f79f7a0addd991a84442a31f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69110
I pasted the current LLVM code, reapplied the modifications listed in the code comments, caught a few more in the diff/build process. The trivially copyable detection is different now; if gcc builds fail, will try reverting to C10_IS_TRIVIALLY_COPYABLE or copying what LLVM is doing.
The motivation for this change is that, as noted in an existing comment, C10_IS_TRIVIALLY_COPYABLE did the wrong thing for std::unique_ptr, which caused problems with D32454856 / #68412.
ghstack-source-id: 145327773
Test Plan: CI
Reviewed By: bhosmer, mruberry
Differential Revision: D32733017
fbshipit-source-id: 9452ab90328e3fdf457aad23a26f2f6835b0bd3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66540
Currently the macro `HAS_DEMANGLE` is determined by compiler predefined macros. Here I'm adding an option to allow `HAS_DEMANGLE` to be defined in build files.
Test Plan: Rely on CI
Reviewed By: poweic
Differential Revision: D31600007
fbshipit-source-id: 76cf088b0f5ee940e977d3b213f1446ea64be036
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66445
`Type.cpp` implements `demangle()` function based on the macro `HAS_DEMANGLE`. This diff splits it into two `.cpps` so that we can add either one into the build target. This change follows the patternof `flags_use_no_gflags.cpp` and `flags_use_gflags.cpp`.
Test Plan: Rely on CI
Reviewed By: iseeyuan
Differential Revision: D31551432
fbshipit-source-id: f8b11783e513fa812228ec873459ad3043ff9147
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65245
Building and running c10 and qnnpack tests on XROS.
Notable changes:
- Adding #if define(_XROS_) in few places not supported by XROS
- Changing Threadpool to abstract class
ghstack-source-id: 139513579
Test Plan: Run c10 and qnnpack tests on XROS.
Reviewed By: veselinp, iseeyuan
Differential Revision: D30137333
fbshipit-source-id: bb6239b935187fac712834341fe5a8d3377762b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65610
- Replace HIP_PLATFORM_HCC with USE_ROCM
- Dont rely on CUDA_VERSION or HIP_VERSION and use USE_ROCM and ROCM_VERSION.
- In the next PR
- Will be removing the mapping from CUDA_VERSION to HIP_VERSION and CUDA to HIP in hipify.
- HIP_PLATFORM_HCC is deprecated, so will add HIP_PLATFORM_AMD to support HIP host code compilation on gcc.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport amathews-amd
Reviewed By: jbschlosser
Differential Revision: D30909053
Pulled By: ezyang
fbshipit-source-id: 224a966ebf1aaec79beccbbd686fdf3d49267e06
Summary:
warpSize is defined as a constexpr in HIP headers. It is incorrect to assume warpSize 64. This change fixes the C10_WARP_SIZE definition in torch sources similar to [how it was done in caffe2](https://github.com/pytorch/pytorch/blob/master/caffe2/utils/GpuDefs.cuh#L10-L14).
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64302
Reviewed By: mrshenli
Differential Revision: D30785975
Pulled By: malfet
fbshipit-source-id: 68f8333182ad4d02bd0c8d02f1751a50bc5bafa7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62527
If NDEBUG is applied inconsistently in compilation we might get 'ambiguous declaration' error. Let's make sure that the forward declaration matches glibc including all specifiers.
Test Plan: sandcastle
Reviewed By: mdschatz
Differential Revision: D30030051
fbshipit-source-id: 9f4d5f1d4e74f0a4eaeeaaaad76b93ee485d8bcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60214
Relanding this PR, but with a fix for windows cuda builds (example failure in master here: https://github.com/pytorch/pytorch/runs/2852662871)
This is identical to the original PR except for one change in `tools/codegen/gen.py`: `static constexpr` -> `static CONSTEXPR_EXCEPT_WIN_CUDA`
This actually took a while to figure out, until I tracked down a previous pytorch PR that encountered a similar issue: https://github.com/pytorch/pytorch/pull/40675
This reverts commit 6d0fb85a62.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D29213932
Pulled By: bdhirsh
fbshipit-source-id: b90c7c10e5a51f8d6173ddca673b418e5774c248
Summary:
Fixes https://github.com/pytorch/pytorch/issues/60016
For CUDA 92
- OptionalBase was not check if `is_arrayref`
- constexpr seems not expect to raise Exception for cuda 92
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60017
Reviewed By: malfet
Differential Revision: D29139515
Pulled By: ejguan
fbshipit-source-id: 4f4f6d9fe6a5f2eadf913de0a9781cc9f2e6ac6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56017Fixes#55686
This patch is seemingly straightforward but some of the changes are very
subtle. For the general algorithmic approach, please first read the
quoted issue. Based on the algorithm, there are some fairly
straightforward changes:
- New boolean on TensorImpl tracking if we own the pyobj or not
- PythonHooks virtual interface for requesting deallocation of pyobj
when TensorImpl is being released and we own its pyobj, and
implementation of the hooks in python_tensor.cpp
- Modification of THPVariable to MaybeOwned its C++ tensor, directly
using swolchok's nice new class
And then, there is python_variable.cpp. Some of the changes follow the
general algorithmic approach:
- THPVariable_NewWithVar is simply adjusted to handle MaybeOwned and
initializes as owend (like before)
- THPVariable_Wrap adds the logic for reverting ownership back to
PyObject when we take out an owning reference to the Python object
- THPVariable_dealloc attempts to resurrect the Python object if
the C++ tensor is live, and otherwise does the same old implementation
as before
- THPVariable_tryResurrect implements the resurrection logic. It is
modeled after CPython code so read the cited logic and see if
it is faithfully replicated
- THPVariable_clear is slightly updated for MaybeOwned and also to
preserve the invariant that if owns_pyobj, then pyobj_ is not null.
This change is slightly dodgy: the previous implementation has a
comment mentioning that the pyobj nulling is required to ensure we
don't try to reuse the dead pyobj. I don't think, in this new world,
this is possible, because the invariant says that the pyobj only
dies if the C++ object is dead too. But I still unset the field
for safety.
And then... there is THPVariableMetaType. colesbury explained in the
issue why this is necessary: when destructing an object in Python, you
start off by running the tp_dealloc of the subclass before moving up
to the parent class (much in the same way C++ destructors work). The
deallocation process for a vanilla Python-defined class does irreparable
harm to the PyObject instance (e.g., the finalizers get run) making it
no longer valid attempt to resurrect later in the tp_dealloc chain.
(BTW, the fact that objects can resurrect but in an invalid state is
one of the reasons why it's so frickin' hard to write correct __del__
implementations). So we need to make sure that we actually override
the tp_dealloc of the bottom most *subclass* of Tensor to make sure
we attempt a resurrection before we start finalizing. To do this,
we need to define a metaclass for Tensor that can override tp_dealloc
whenever we create a new subclass of Tensor. By the way, it was totally
not documented how to create metaclasses in the C++ API, and it took
a good bit of trial error to figure it out (and the answer is now
immortalized in https://stackoverflow.com/q/67077317/23845 -- the things
that I got wrong in earlier versions of the PR included setting
tp_basicsize incorrectly, incorrectly setting Py_TPFLAGS_HAVE_GC on
the metaclass--you want to leave it unset so that it inherits, and
determining that tp_init is what actually gets called when you construct
a class, not tp_call as another not-to-be-named StackOverflow question
suggests).
Aside: Ordinarily, adding a metaclass to a class is a user visible
change, as it means that it is no longer valid to mixin another class
with a different metaclass. However, because _C._TensorBase is a C
extension object, it will typically conflict with most other
metaclasses, so this is not BC breaking.
The desired new behavior of a subclass tp_dealloc is to first test if
we should resurrect, and otherwise do the same old behavior. In an
initial implementation of this patch, I implemented this by saving the
original tp_dealloc (which references subtype_dealloc, the "standard"
dealloc for all Python defined classes) and invoking it. However, this
results in an infinite loop, as it attempts to call the dealloc function
of the base type, but incorrectly chooses subclass type (because it is
not a subtype_dealloc, as we have overridden it; see
b38601d496/Objects/typeobject.c (L1261) )
So, with great reluctance, I must duplicate the behavior of
subtype_dealloc in our implementation. Note that this is not entirely
unheard of in Python binding code; for example, Cython
c25c3ccc4b/Cython/Compiler/ModuleNode.py (L1560)
also does similar things. This logic makes up the bulk of
THPVariable_subclass_dealloc
To review this, you should pull up the CPython copy of subtype_dealloc
b38601d496/Objects/typeobject.c (L1230)
and verify that I have specialized the implementation for our case
appropriately. Among the simplifications I made:
- I assume PyType_IS_GC, because I assume that Tensor subclasses are
only ever done in Python and those classes are always subject to GC.
(BTW, yes! This means I have broken anyone who has extend PyTorch
tensor from C API directly. I'm going to guess no one has actually
done this.)
- I don't bother walking up the type bases to find the parent dealloc;
I know it is always THPVariable_dealloc. Similarly, I can get rid
of some parent type tests based on knowledge of how
THPVariable_dealloc is defined
- The CPython version calls some private APIs which I can't call, so
I use the public PyObject_GC_UnTrack APIs.
- I don't allow the finalizer of a Tensor to change its type (but
more on this shortly)
One alternative I discussed with colesbury was instead of copy pasting
the subtype_dealloc, we could transmute the type of the object that was
dying to turn it into a different object whose tp_dealloc is
subtype_dealloc, so the stock subtype_dealloc would then be applicable.
We decided this would be kind of weird and didn't do it that way.
TODO:
- More code comments
- Figure out how not to increase the size of TensorImpl with the new
bool field
- Add some torture tests for the THPVariable_subclass_dealloc, e.g.,
involving subclasses of Tensors that do strange things with finalizers
- Benchmark the impact of taking the GIL to release C++ side tensors
(e.g., from autograd)
- Benchmark the impact of adding a new metaclass to Tensor (probably
will be done by separating out the metaclass change into its own
change)
- Benchmark the impact of changing THPVariable to conditionally own
Tensor (as opposed to unconditionally owning it, as before)
- Add tests that this actually indeed preserves the Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27765125
Pulled By: ezyang
fbshipit-source-id: 857f14bdcca2900727412aff4c2e2d7f0af1415a
Summary:
## Motivation
The utils in namespace `c10` require the `__assert_fail` when the NDEBUG is defined in kernel code.
The `__assert_fail` declaration in pytorch is not compatible to the SYCL‘s specification.
This causes compile error when use these utils in SYCL kernels.
## Solution
Add the `__assert_fail` declaration for SYCL kernels to pytorch when compiling the SYCL kernels with `c10` utils.
## Additional context
`__assert_fail` in SYCL kernel
`extern SYCL_EXTERNAL void __assert_fail(const char *expr, const char *file, unsigned int line, const char *func);`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58906
Reviewed By: anjali411
Differential Revision: D28700863
Pulled By: ezyang
fbshipit-source-id: 81896d022b35ace8cd16474128649eabedfaf138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57034
Resolves gh-38915
For the example given in the issue, BatchNorm1d on cuDNN is around 12x slower
than BatchNorm2d. Internally, cuDNN expects at least a 4d tensor (N, C, H, W)
so these two modules actually call the same cuDNN code. My assumption is that
cuDNN just isn't optimized for H=W=1.
Instead, this disables cudnn for 2d batch_norm inputs and improves the CUDA
implementation of `native_batch_norm` to be competative with cuDNN. For the
example in the issue, `BatchNorm1d` now takes 335 us compared to 6.3 ms before,
or a 18x speedup.
Before this change, nvprof shows:
```
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 99.64% 630.95ms 100 6.3095ms 5.6427ms 8.8800ms void cudnn::bn_fw_tr_1C11_kernel_NCHW<float, float, int=512, bool=0, int=2>(cudnnTensorStruct, float const *, cudnn::bn_fw_tr_1C11_kernel_NCHW<float, float, int=512, bool=0, int=2>, cudnnTensorStruct*, float const *, float const , cudnnTensorStruct*, cudnnTensorStruct*, cudnnTensorStruct**, float const *, float const *, float const *, cudnnTensorStruct*, cudnnTensorStruct*)
```
But after, it shows:
```
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 54.76% 14.352ms 100 143.52us 123.52us 756.28us _ZN2at6native27unrolled_elementwise_kernelIZZZNS0_72_GLOBAL__N__48_tmpxft_001e82d0_00000000_7_Normalization_cpp1_ii_db66e07022batch_norm_elementwiseERKNS_6TensorES5_RKN3c108optionalIS3_EESA_S5_S5_ENKUlvE_clEvENKUlvE2_clEvEUlfffffE_NS_6detail5ArrayIPcLi6EEE16OffsetCalculatorILi5EjESI_ILi1EjENS0_6memory15LoadWithoutCastENSL_16StoreWithoutCastEEEviT_T0_T1_T2_T3_T4_
35.09% 9.1951ms 100 91.950us 84.415us 362.17us void at::native::reduce_kernel<int=256, int=2, at::native::ReduceOp<float, at::native::WelfordOps<float, float, int, float, thrust::pair<float, float>>, unsigned int, float, int=2>>(float)
0.71% 186.14us 100 1.8610us 1.8240us 1.9840us _ZN2at6native72_GLOBAL__N__48_tmpxft_001e82d0_00000000_7_Normalization_cpp1_ii_db66e07045unrolled_elementwise_kernel_for_multi_outputsILi3EZZZNS1_34batch_norm_update_stats_and_invertERKNS_6TensorES5_S5_S5_ddlENKUlvE_clEvENKUlvE2_clEvEUlffffE_NS_6detail5ArrayIPcLi7EEE23TrivialOffsetCalculatorILi4EjESD_ILi3EjEEEviT0_T1_T2_T3_
0.59% 153.37us 100 1.5330us 1.4720us 2.6240us
void at::native::vectorized_elementwise_kernel<int=4,
at::native::BUnaryFunctor<at::native::AddFunctor<long>>,
at::detail::Array<char*, int=2>>(int, long,
at::native::AddFunctor<long>)
```
I think there is similar scope to improve the backward implementation.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D28142447
Pulled By: ngimel
fbshipit-source-id: c70109780e206fa85e50a31e90a1cb4c533199da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56830
Opt into formatting on GitHub and format everything. This is a trial run before turning on formatting for more and eventually all of the codebase.
Test Plan: CI
Reviewed By: zertosh
Differential Revision: D27979080
fbshipit-source-id: a80f0c48691c08ae8ca0af06377b87e6a2351151
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53562
On Windows when we try to build //xplat/caffe2/c10:c10Windows, it failed with an error like
```
stderr: buck-out\gen\83497cbb\xplat\caffe2\c10\c10Windows#header-mode-symlink-tree-only,headers\c10/macros/Macros.h(189): error C2220: warning treated as error - no 'object' file generated
buck-out\gen\83497cbb\xplat\caffe2\c10\c10Windows#header-mode-symlink-tree-only,headers\c10/macros/Macros.h(189): warning C4067: unexpected tokens following preprocessor directive - expected a newline
```
See log here: https://www.internalfb.com/intern/buck/build/6eaea1f8-e237-4860-9f3b-3a8edd2207c6/
This is because Windows doesn't support `__has_attribute` keyword. Here I'm changing the ordering of `if` and `elif` so that we don't hit that line when build in Windows.
Test Plan: buck build //xplat/caffe2/c10:c10Windows xplat/mode/windows
Reviewed By: kimishpatel, swolchok
Differential Revision: D26896510
fbshipit-source-id: d52438a3df7bf742e467a919f6ab4fed14484f22
Summary:
All pretty minor. I avoided renaming `class DestructableMock` to `class DestructibleMock` and similar such symbol renames (in this PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49815
Reviewed By: VitalyFedyunin
Differential Revision: D25734507
Pulled By: mruberry
fbshipit-source-id: bbe8874a99d047e9d9814bf92ea8c036a5c6a3fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48286
RecordFunction initialization is a hot path. shouldRun often does little enough work that the function prologue takes a significant proportion of its time. So, this diff forces it to be inline.
ghstack-source-id: 117892387
Test Plan: FB-internal benchmarks
Reviewed By: ezyang
Differential Revision: D25108879
fbshipit-source-id: 7121413e714c5ca22c8bf10c1d2535a878c15aec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48308
The original regex that I added didn't correctly match namespaces that started with an underscore (e.g. `_test`), which caused a master-only test to fail.
The only change from the previous commit is that I updated the regex like so:
before: `^.*TORCH_LIBRARY_IMPL_init_([^_]+)_([^_]+)_[0-9]+(\(.*)?$`
after: `^.*TORCH_LIBRARY_IMPL_init_([_]*[^_]+)_([^_]+)_[0-9]+(\(.*)?$`
I added in a `[_]*` to the beginning of the namespace capture. I did the same for the `_FRAGMENT` regex.
Verified that running `ANALYZE_TEST=1 tools/code_analyzer/build.sh` (as the master-only test does) produces no diff in the output.
Fixing regex pattern to allow for underscores at the beginning of the
namespace
This reverts commit 3c936ecd3c.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25123295
Pulled By: bdhirsh
fbshipit-source-id: 54bd1e3f0c8e28145e736142ad62a18806bb9672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44702
Original commit changeset: c6bd6d277aca
This diff caused windows build to fail due to a compiler bug in VS2019 (lambda capture constant int value). This back out works around the issue with explicit capture of const int value.
Test Plan: Tested and previously landed.
Reviewed By: mruberry
Differential Revision: D23703215
fbshipit-source-id: f9ef23be97540bc9cf78a855295fb8c69f360459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44252
Add tracing to DPP client. Because DPP requests are async, we need to be able to start a trace event in one thread and potentially end in a different thread. RecordFunction and LibgpumonObserver previously assume each trace event starts and finishes in the same thread. So they use a thread local context to track enter and exit call backs. Async events breaks this assumption. This change attaches the event context to the RecordFunction object so we do not need to use thread local context.
Test Plan:
Tested with dpp perf test and able to collect trace.
{F307824044}
Reviewed By: ilia-cher
Differential Revision: D23323486
fbshipit-source-id: 4b6ca6c0e32028fb38a476cd1f44c17a001fc03b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44440
`aten-op.cc` takes a long time to compile due to the large generated constructor. For each case, the `std::function` constructor and the initialization functions are inlined, producing a huge amount of intermediate code that takes a long time to optimize, given that many compiler optimization passes are superlinear in the function size.
This diff moves each case to a separate function, so that each one is cheap to optimize, and the constructor is just a large jump table, which is easy to optimize.
Reviewed By: dzhulgakov
Differential Revision: D23593741
fbshipit-source-id: 1ce7a31cda10d9b0c9d799716ea312a291dc0d36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42249
Main change is to bring Caffe2's superior error messages for cuda initialization into c10 and use them in all code paths.
Basic logic:
| Case | Call to device_count() | init_cuda, e.g. allocating tensor |
| -- | -- | -- |
| all good | non-zero | just works |
| no gpus | 0, no warning | throw exception with good message |
| driver issues | 0, produce warning | throw exception with good message |
| out of memory with ASAN | 0, produce warning| throw exception with ASAN message |
Previously, the error thrown from init_cuda was very generic and the ASAN warning (if any) was buried in the logs.
Other clean up changes:
* cache device_count() always in a static variable
* move all asan macros in c10
Test Plan:
Hard to unittest because of build modes. Verified manually that the behavior from the table above holds by running the following script in different modes (ASAN/no-ASAN, CUDA_VISIBLE_DEVICES=):
```
print('before import')
import torch
print('after import')
print('devices: ', torch.cuda.device_count())
x = torch.tensor([1,2,3])
print('tensor creation')
x = x.cuda()
print('moved to cuda')
```
Reviewed By: ngimel
Differential Revision: D22824329
fbshipit-source-id: 5314007313a3897fc955b02f8b21b661ae35fdf5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40151
For debug android build it throws the following error:
```
In file included from src/pytorch/android/pytorch_android/src/main/cpp/pytorch_jni_common.cpp:9:
In file included from src/pytorch/android/pytorch_android/src/main/cpp/pytorch_jni_common.h:2:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/torch/csrc/api/include/torch/types.h:3:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/ATen.h:5:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/Context.h:4:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/Tensor.h:3:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/core/TensorBody.h:7:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/c10/core/Scalar.h:13:
../../../../src/main/cpp/libtorch_include/armeabi-v7a/c10/util/TypeCast.h:157:22: error: use of undeclared identifier '__assert_fail'
AT_FORALL_QINT_TYPES(DEFINE_UNCASTABLE)
^
```
Seems __assert_fail() isn't available on Android by default - in NDEBUG mode it forward declares the function and CI passes.
But CUDA_KERNEL_ASSERT() shouldn't be relevant for mobile build at all and we already bypass `__APPLE__` so the easiest fix is to add `__ANDROID__`.
Test Plan: Imported from OSS
Differential Revision: D22095562
Pulled By: ljk53
fbshipit-source-id: 793108a7bc64db161a0747761c0fbd70262e7d5a
Summary:
Per title. https://github.com/pytorch/pytorch/issues/32719 essentially disabled asserts in cuda kernels in release build. Asserts in cuda kernels are typically used to prevent invalid reads/writes, so without asserts invalid read/writes are silent errors in most cases (sometimes they would still cause "illegal memory access" errors, but because of caching allocator this usually won't happen).
We don't need 2 macros, CUDA_ALWAYS_ASSERT and CUDA_KERNEL_ASSERT because all current asserts in cuda kernels are important to prevent illegal memory accesses, and they should never be disabled.
This PR removes macro CUDA_ALWAYS_ASSERT and instead makes CUDA_KERNEL_ASSERT (that is commonly used in the kernels) an asserttion both in release and debug builds.
Fixes https://github.com/pytorch/pytorch/issues/38771
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38943
Differential Revision: D21723767
Pulled By: ngimel
fbshipit-source-id: d88d8aa1b047b476d5340e69311e65aff4da5074
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37098
### **Cherry-picked from another stack:**
Some code review already occurred here: https://github.com/pytorch/pytorch/pull/32582
### Summary:
Fixes: https://github.com/pytorch/pytorch/issues/32436
The issue caused incorrect handling of dtypes for scalar ** tensor.
e.g. before this change:
```
>>> 5.5 ** torch.ones(5, dtype=torch.int32)
tensor([5, 5, 5, 5, 5], dtype=torch.int32)
```
should return a float tensor.
Also fixes a number of incorrect cases:
* tensors to negative powers were giving incorrect results (1 instead
of 0 or error)
* Behavior wasn't consistent between cuda/cpu
* large_value ** 1 in some cases gave a result not equal
to large_value because of truncation in conversion to double and back.
BC-breaking:
Previously incorrect behavior (in 1.4):
```
>>> a
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
>>> a.pow_(.5)
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
```
After this change:
`RuntimeError: result type Float can't be cast to the desired output type Int`
Test Plan: Imported from OSS
Differential Revision: D21686207
Pulled By: nairbv
fbshipit-source-id: e797e7b195d224fa46404f668bb714e312ea78ac
Summary:
Because MacOS is not iOS
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37283
Test Plan: CI
Differential Revision: D21244398
Pulled By: malfet
fbshipit-source-id: b822e216e83887e2f2961b5c5384eaf749629f61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37023
Optimize binary size of assert macros, through two ideas:
Concatenate string literals with __FILE__ and __LINE__ at compile time into one literal instead of keeping them in separate literals and combining them with c10::str
Optimize binary size of c10::str for some scenarios, especially for the scenario where it is called with an empty parameter list, this is actually a common call scenario in assert macros.
In server oss builds, this PR reduces binary size from 118.05 MB to 117.05 MB
ghstack-source-id: 102607237
Test Plan: Run oss server build (python setup.py install) and check size of libtorch_cpu.so reducing from 118.05MB to 117.05MB
Differential Revision: D20719400
fbshipit-source-id: 5c61f4195b947f06aafb8f0c8e255de3366e1ff2
Summary:
In C++, casting a floating point value to an integer dtype is undefined when the value is outside the dtype's dynamic range. For example, casting 300.5 to Int8 is undefined behavior because the maximum representable Int8 value is 127, and 300.5 > 127.
PyTorch, like NumPy, deliberately allows and makes these casts, however, and when we do this we trigger undefined behavior that causes our sanitizers to (correctly) complain. I propose skipping this sanitization on our cast function.
The history of this PR demonstrates the issue, showing a single CI failure in the ASAN build when a test is added that converts a large float value to an integral value. The current PR shows a green CI after the sanitization is skipped.
There are alternatives to skipping this sanitization:
- Clamping or otherwise converting floats to the dynamic range of integral types they're cast to
- Throwing a runtime error if a float value is outside the dynamic range of the integral type it's cast to (this would not be NumPy compatible)
- Declaring programs in error if they perform these casts (this is technically true)
- Preventing this happening in PyTorch proper so the ASAN build doesn't fail
None of these alternatives seems particularly appealing, and I think it's appropriate to skip the sanitization because our behavior is deliberate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35086
Differential Revision: D20591163
Pulled By: mruberry
fbshipit-source-id: fa7a90609c73c4c627bd39726a7dcbaeeffa1d1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34157
`[[noreturn]` only conficts with CUDA __asert_fail defition if clang is used if host compiler
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D20232088
fbshipit-source-id: 7182c28a15278e03175865cd0c87410c5de5bf2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34102
if nvcc is invoked with clang host compiler, it will fail with the following error due to the decorators mismatch defined in cuda and c10:
```
error: attribute "noreturn" did not appear on original declaration
```
Test Plan: Build pytorch with clang
Reviewed By: EscapeZero
Differential Revision: D20204951
fbshipit-source-id: ff7cef0db43436e50590cb4bbf1ae7302c1440fa
Summary:
This might lead to silent undefined behaviour (e.g. with out-of-bound indices). This affects `test_multinomial_invalid_probs_cuda` which is now removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32719
Test Plan:
* Build with VERBOSE=1 and manually inspect `less ndebug.build.log | grep 'c++' | grep -v -- -DNDEBUG` (only with nina on Linux)
* CI
Fixes https://github.com/pytorch/pytorch/issues/22745
Differential Revision: D20104340
Pulled By: yf225
fbshipit-source-id: 2ebfd7ddae632258a36316999eeb5c968fb7642c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33632
* `inline_container.h` was unnecessarily exposing all includers to caffe2 headers via `caffe2/core/logging.h`
* Add msvc version of hiding unused warnings.
* Make sure clang on windows does not use msvc pragmas.
* Don't redefine math macro.
Test Plan: CI green
Differential Revision: D20017046
fbshipit-source-id: 230a9743eb88aee08d0a4833680ec2f01b7ab1e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30916
These macros said "make it constexpr if we're in C++14". Since we're now always C++14, we can just say "constexpr" isntead.
ghstack-source-id: 96369584
Test Plan: waitforsandcastle
Differential Revision: D18869635
fbshipit-source-id: f41751e4e26fad6214ec3a98db2d961315fd73ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30917
This is a C++14 feature, we can use this now.
ghstack-source-id: 95255753
Test Plan: waitforsandcastle
Differential Revision: D18869637
fbshipit-source-id: dd02036b9faeaffa64b2d2d305725443054da31b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31276
Change assert --> CUDA_ASSERT_KERNEL to avoid hip undefined __assert_fail()
This is similar to https://github.com/pytorch/pytorch/pull/13902 in caffe2 land.
Test Plan: wait for CI to clear
Reviewed By: bddppq
Differential Revision: D19047582
fbshipit-source-id: 34703b03786c8eee9c78d2459eb54bde8dc21a57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26616
Implement C++17 std::string_view for C++11.
This is useful for compile time type name retrievaly which I'm going to stack on top of this.
It is also useful to replace `const std::string&` with throughout our codebase.
ghstack-source-id: 92100314
Test Plan: unit tests
Differential Revision: D17518992
fbshipit-source-id: 48e31c677d51b0041f4b37e89a92bd176d4a0b08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26757
This doesn't switch any open source builds or CI.
The internal fbcode build is C++17 already for quite some time, but in CUDA code, we had it restricted to C++11.
This diff changes that to C++14.
Because this doesn't change anything open source, the risk of this is low.
ghstack-source-id: 90728524
Test Plan: waitforsandcastle
Differential Revision: D17558142
fbshipit-source-id: 9cfd47e38e71d5a2fdae2f535c01f281bf007d9a
Summary:
Introduce a C10_WARP_SIZE define in Macros.h
For kernels that had ifdef-ing of WARP_SIZE for ROCm vs CUDA, use said macro. This is no functional change - we merely refactor to unify on one WARP_SIZE definition.
I hope we can encourage use of this macro over more WARP_SIZE definitions being sprinkled across the code base (or numerically hard-coded).
Some kernels remain that have their own WARP_SIZE definitions but did not satisfy above condition. They will be fixed in follow-up PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25884
Differential Revision: D17276662
Pulled By: bddppq
fbshipit-source-id: cef8e77a74ae2e5de10df816ea80b25cb2bab713
Summary:
```
This replaces the kernel helpers in Loops.h/cuh with the following:
cpu_kernel
cpu_kernel_vec
gpu_kernel
gpu_kernel_with_scalars
These work with functions with any number of input arugments, with the
exception of 'gpu_kernel_with_scalars' which is limited to binary
operations. Previously, we only supported functions of 0, 1, or 2 input
arguments. Adding support for 3 or 4 input argument functions required
significant amount of additional code.
This makes a few other changes:
Remove 'ntensors' from the for_each/serial_for_each loop. Most loops
assume a fixed number of tensors, and the value is accessible from
TensorIterator::ntensors()
Only lift CPU scalars to parameters in 'gpu_kernel_with_scalars'.
Previously, we performed this recursively in gpu_unary_kernel and
gpu_binary_kernel, so something like `torch.add(3, 4, out=cuda_tensor)`
would specialize to a "nullary" kernel. Now, only the first
scalar input is lifted to a kernel parameter. Any additional scalar
inputs are copied to CUDA tensors. Note that operations like `x + 5`
and `5 + x` still work efficiently. This avoids generating an exponential
number of specializations in the number of input arguments.
```
**Performance measurements**
Timing numbers are unchanged for basic elementwise operations. Linked below is a script to measure torch.add perf on PR vs. master CPU+GPU (GCC 7.3):
[miniperf.py](https://gist.github.com/colesbury/4a61893a22809cb0931f08cd37127be4)
**Generated assembly**
cpu_kernel and cpu_kernel_vec still generate good vectorized code with
both GCC 7.3 and GCC 4.8.5. Below is the assembly for the "hot" inner loop of
torch.add as well as an auto-vectorized torch.mul implementation using cpu_kernel/
binary_kernel. (The real torch.mul uses cpu_kernel_vec but I wanted to check that
auto vectorization still works well):
[torch.add GCC 7.3](https://gist.github.com/colesbury/927ddbc71dc46899602589e85aef1331)
[torch.add GCC 4.8](https://gist.github.com/colesbury/f00e0aafd3d1c54e874e9718253dae16)
[torch.mul auto vectorized GCC 7.3](https://gist.github.com/colesbury/3077bfc65db9b4be4532c447bc0f8628)
[torch.mul auto vectorized GCC 4.8](https://gist.github.com/colesbury/1b38e158b3f0aaf8aad3a76963fcde86)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21475
Differential Revision: D15745116
Pulled By: colesbury
fbshipit-source-id: 914277d7930dc16e94f15bf87484a4ef82890f91
Summary:
Resubmit #20698 which got messed up.
Idea is that when PyTorch is used in a custom build environment (e.g. Facebook), it's useful to track usage of various APIs centrally. This PR introduces a simple very lightweight mechanism to do so - only first invocation of a trigger point would be logged. This is significantly more lightweight than #18235 and thus we can allow to put logging in e.g. TensorImpl.
Also adds an initial list of trigger points. Trigger points are added in such a way that no static initialization triggers them, i.e. just linking with libtorch.so will not cause any logging. Further suggestions of what to log are welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20745
Differential Revision: D15429196
Pulled By: dzhulgakov
fbshipit-source-id: a5e41a709a65b7ebccc6b95f93854e583cf20aca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19779
This macro wasn't set correctly because the target macros weren't included from Apple's header.
Reviewed By: dzhulgakov
Differential Revision: D15090427
fbshipit-source-id: 43ca44f0f409e11718b7f60c3fdcd2aa02d7018e
Summary:
Fixing MSVC errors
```
D:\pytorch-scripts\caffe2_builders\v141\pytorch\aten\src\THC/THCReduce.cuh(144): error C4002: too many actual paramet
ers for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caffe2_gpu.vcxp
roj]
D:\pytorch-scripts\caffe2_builders\v141\pytorch\aten\src\THC/THCReduce.cuh(259): error C4002: too many actual paramet
ers for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caffe2_gpu.vcxp
roj]
D:/pytorch-scripts/caffe2_builders/v141/pytorch/aten/src/THCUNN/SpatialDilatedMaxPooling.cu(51): error C4002: too man
y actual parameters for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2
\caffe2_gpu.vcxproj]
```
on variadic C10_LAUNCH_BOUNDS as well as Debug linking issues with at::Half in pool_op_cudnn.cc like this one
```
pool_op_cudnn.obj : error LNK2019: unresolved external symbol "public: bool __cdecl caffe2::MaxPoolFunctor<class caff
e2::CUDAContext>::GlobalPoolingBackward<struct c10::Half,2>(int,int,int,struct c10::Half const *,struct c10::Half const
,struct c10::Half const ,struct c10::Half ,class caffe2::CUDAContext )const " (??$GlobalPoolingBackward@UHalf@c10@
@$01@?$MaxPoolFunctor@VCUDAContext@caffe2@@caffe2@QEBA_NHHHPEBUHalf@c10@00PEAU23@PEAVCUDAContext@1@Z) referenced in
function "public: bool __cdecl caffe2::`anonymous namespace'::CuDNNMaxPoolFunctor::GlobalPoolingBackward<struct c10::H
alf,2>(int,int,int,struct c10::Half const ,struct c10::Half const ,struct c10::Half const ,struct c10::Half ,class
caffe2::CUDAContext *)const " (??$GlobalPoolingBackward@UHalf@c10@@$01@CuDNNMaxPoolFunctor@?A0xb936404a@caffe2@QEBA_NH
HHPEBUHalf@c10@00PEAU34@PEAVCUDAContext@2@Z) [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caff
e2_gpu.vcxproj]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17201
Differential Revision: D14165732
Pulled By: ezyang
fbshipit-source-id: 875fd9a5b2db6f83fc483f6d750d2c011260eb8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17481
Usually, feature macros are either defined or undefined and checked accordingly.
C10_MOBILE was a weird special case that was always defined but either defined to 1 or to 0.
This caused a lot of confusion for me when trying to disable something from mobile build and it also disabled it
from the server build (because I was using ifdef). Also, I found a place in the existing code base that made
that wrong assumption and used the macro wrongly, see https://fburl.com/y4icohts
Reviewed By: dzhulgakov
Differential Revision: D14214825
fbshipit-source-id: f3a155b6d43d334e8839e2b2e3c40ed2c773eab6
Summary:
When compiling for `TORCH_CUDA_ARCH_LIST=7.5` we were getting ptxas warnings (https://github.com/pytorch/pytorch/issues/14310). This was because we had some hardcoded values when using launch_bounds in kernels. The maximum number of threads per multiprocessor is 1024 for Turing architecture (7.5) but 2048 for previous architectures. The hardcoded launch_bounds in the kernel were requesting for 2048 threads when compiling for Turing and hence were generating the warning.
This PR adds a macro that checks for the bounds on the launch bounds value supplied. The max number of threads per block across all architectures is 1024. If a user supplies more than 1024, I just clamp it down to 512. Depending on this value, I set the minimum number of blocks per sm. This PR should resolve https://github.com/pytorch/pytorch/issues/14310. The gradient computation being wrong reported in that PR is probably due to the faulty card.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15461
Differential Revision: D13633952
Pulled By: soumith
fbshipit-source-id: 795aa151109f343ab5433bf3cb070cb6ec896fff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13920
I want to move CUDAStream and CUDAGuard to c10_cuda without also
bringing along CUDAContext or CUDAEvent for the ride (at least for
now). To do this, I need to eliminate those dependencies.
There's a few functions in CUDAContext.h which don't really need
THCState, so they're separated out and put in general
purpose c10/cuda/CUDAFunctions.h
Reviewed By: smessmer
Differential Revision: D13047468
fbshipit-source-id: 7ed9d5e660f95805ab39d7af25892327edae050e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13838
According to Sebastian, the detail convention is specifically for header-private
functionality. That's not what c10/detail is; it's general, library private headers
which may be used in multiple places within PyTorch. Rename it to impl to avoid
the confusion in nomenclature.
Reviewed By: smessmer
Differential Revision: D13024368
fbshipit-source-id: 050f2632d83a69e3ae53ded88e8f938c5d61f0ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13342
This PR introduces a few new concepts:
- DeviceGuardImplInterface, and implementations for CPU and CUDA, which
provide a generic interface for interfacing with device and stream state,
without requiring a direct dependency on the code in question.
- InlineDeviceGuard, a general template for generating both specialized
and dynamically dispatched device guard implementations. Dynamic
dispatch is done by specializing it on a VirtualGuardImpl.
- Provide a device-independent DeviceGuard class, which can be used even
from CPU code. It uses the aforementioned dynamic dispatch.
- CUDA-specialized CUDAGuard class, which doesn't have a dynamic dispatch
but can only be used from CUDA.
- StreamGuard, which is the same as above, but for streams rather than
devices.
- Optional variants of all the aforementioned guards, which are a no-op if
no device/stream is specified
- CUDAMultiStreamGuard, specifically for the case when we want to set
a device on every guard.
There are some subtle semantic changes, which have been thoroughly documented
in the class definition.
BC-breaking changes:
- Move constructor/assignment have been removed from all device guard
implementations.
- In some cases where you previously wrote 'set_device' (or 'set_stream'), you now must write
'reset_device', because if you switch devices/device types, the stream/device on the
previous device is unset. This is different from previous behavior.
- CUDAGuard no longer handles streams, or multiple streams. Use CUDAStreamGuard
or CUDAMultiStreamGuard as appropriate for your use case.
Reviewed By: dzhulgakov
Differential Revision: D12849620
fbshipit-source-id: f61956256f0b12be754b3234fcc73c2abc1be04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12950
For backwards compatibility, we want the c10 symbols to be reachable from caffe2 and aten.
When we move classes from at/caffe2 to c10, this
1. allow keeping backwards compatibility with third paty code we can't control
2. allows splitting diffs that move such classes into two diffs, where one only fixes the includes and the second one fixes the namespaces.
Reviewed By: ezyang
Differential Revision: D10496244
fbshipit-source-id: 914818688fad8c079889dfdc6242bc228b539f0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12932
I was looking at some assembly for some code I was working on,
and felt a desire to have likely()/unlikely() macros. I checked
if we already had them, and we didn't. This commit adds them,
and fixes up all known use sites to make use of it.
Reviewed By: Maratyszcza
Differential Revision: D10488399
fbshipit-source-id: 7476da208907480d49f02b37c7345c17d85c3db7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12588
By default, this is an alias for REGISTER_CPU_OPERATOR. If gradients are not
required (e.g., on mobile) it can be converted to a no-op by defining
CAFFE2_NO_GRADIENT_OPS, resulting in a smaller build.
GRADIENT_OPERATOR_SCHEMA works similarly.
CAFFE2_NO_GRADIENT_OPS also converts REGISTER_GRADIENT to a no-op.
Use these macros in fully_connected_op.cc as an example.
Follow-up diffs will convert more operators.
I had to introduce MACRO_EXPAND to handle the way Visual Studio expands
VA_ARGS.
Reviewed By: Yangqing
Differential Revision: D10209468
fbshipit-source-id: 4116d9098b97646bb30a00f2a7d46aa5d7ebcae0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12881
TSIA. This should not change any functionality.
Remaining work:
- change the build script to deprecate use of CAFFE2_USE_MINIMAL_GOOGLE_GLOG and use a C10 macro instead.
- Unify the exception name (EnforceNotMet -> Error)
- Unify the logging and warning APIs (like AT_WARNING)
Reviewed By: dzhulgakov
Differential Revision: D10441597
fbshipit-source-id: 4784dc0cd5af83dacb10c4952a2d1d7236b3f14d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12714
This is a short change to enable c10 namespace in caffe2. We did not enable
it before due to gflags global variable confusion, but it should have been
mostly cleaned now. Right now, the plan on record is that namespace caffe2 and
namespace aten will fully be supersets of namespace c10.
Most of the diff is codemod, and only two places of non-codemod is in caffe2/core/common.h, where
```
using namespace c10;
```
is added, and in Flags.h, where instead of creating aliasing variables in c10 namespace, we directly put it in the global namespace to match gflags (and same behavior if gflags is not being built with).
Reviewed By: dzhulgakov
Differential Revision: D10390486
fbshipit-source-id: 5e2df730e28e29a052f513bddc558d9f78a23b9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12630
Instead of providing mutable accessors, our "mutators" now
return new copies of TensorOptions. Since TensorOptions is
simply two 64-bit integers, this is not a big efficiency
problem.
There may be some sites that assumed that TensorOptions was
mutable. They need to be fixed.
Reviewed By: SsnL
Differential Revision: D10249293
fbshipit-source-id: b3d17acc37e78c0b90ea2c29515de5dd01209bd3
Summary:
This does 6 things:
- add c10/util/Registry.h as the unified registry util
- cleaned up some APIs such as export condition
- fully remove aten/core/registry.h
- fully remove caffe2/core/registry.h
- remove a bogus aten/registry.h
- unifying all macros
- set up registry testing in c10
Also, an important note that we used to mark the templated Registry class as EXPORT - this should not happen, because one should almost never export a template class. This PR fixes that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12077
Reviewed By: ezyang
Differential Revision: D10050771
Pulled By: Yangqing
fbshipit-source-id: 417b249b49fed6a67956e7c6b6d22374bcee24cf
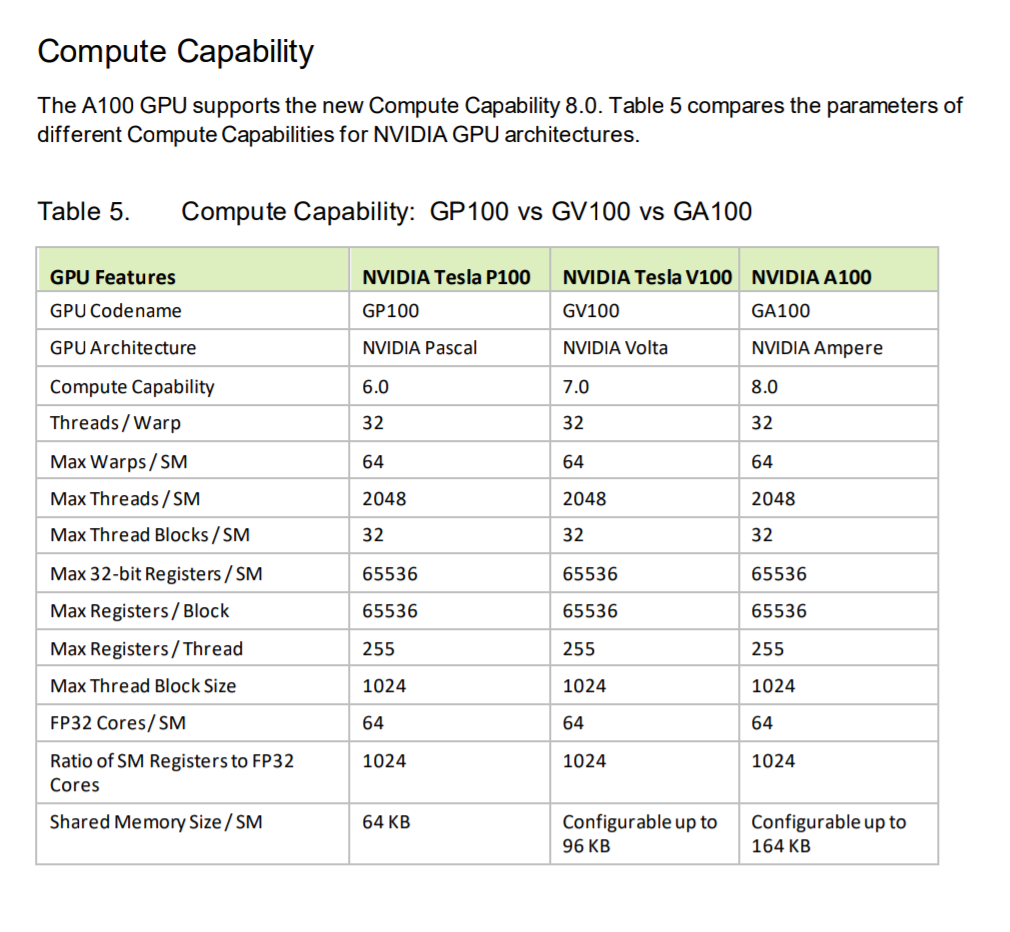{kind=link}