Summary:
The grad() function needs to return the updated values, and hence
needs a non-empty inputs to populate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52016
Test Plan:
Passes Python and C++ unit tests, and added new tests to catch this behavior.
Fixes https://github.com/pytorch/pytorch/issues/47061
Reviewed By: albanD
Differential Revision: D26406444
Pulled By: dagitses
fbshipit-source-id: 023aeca9a40cd765c5bad6a1a2f8767a33b75a1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59711
This is the exact same PR as before.
This was reverted before the PR below was faulty.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28995762
Pulled By: albanD
fbshipit-source-id: 65940ad93bced9b5f97106709d603d1cd7260812
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54987
Based off of ezyang (https://github.com/pytorch/pytorch/pull/44799) and bdhirsh (https://github.com/pytorch/pytorch/pull/43702) 's prototype:
Here's a summary of the changes in this PR:
This PR adds a new dispatch key called Conjugate. This enables us to make conjugate operation a view and leverage the specialized library functions that fast path with the hermitian operation (conj + transpose).
1. Conjugate operation will now return a view with conj bit (1) for complex tensors and returns self for non-complex tensors as before. This also means `torch.view_as_real` will no longer be a view on conjugated complex tensors and is hence disabled. To fill the gap, we have added `torch.view_as_real_physical` which would return the real tensor agnostic of the conjugate bit on the input complex tensor. The information about conjugation on the old tensor can be obtained by calling `.is_conj()` on the new tensor.
2. NEW API:
a) `.conj()` -- now returning a view.
b) `.conj_physical()` -- does the physical conjugate operation. If the conj bit for input was set, you'd get `self.clone()`, else you'll get a new tensor with conjugated value in its memory.
c) `.conj_physical_()`, and `out=` variant
d) `.resolve_conj()` -- materializes the conjugation. returns self if the conj bit is unset, else returns a new tensor with conjugated values and conj bit set to 0.
e) `.resolve_conj_()` in-place version of (d)
f) `view_as_real_physical` -- as described in (1), it's functionally same as `view_as_real`, just that it doesn't error out on conjugated tensors.
g) `view_as_real` -- existing function, but now errors out on conjugated tensors.
3. Conjugate Fallback
a) Vast majority of PyTorch functions would currently use this fallback when they are called on a conjugated tensor.
b) This fallback is well equipped to handle the following cases:
- functional operation e.g., `torch.sin(input)`
- Mutable inputs and in-place operations e.g., `tensor.add_(2)`
- out-of-place operation e.g., `torch.sin(input, out=out)`
- Tensorlist input args
- NOTE: Meta tensors don't work with conjugate fallback.
4. Autograd
a) `resolve_conj()` is an identity function w.r.t. autograd
b) Everything else works as expected.
5. Testing:
a) All method_tests run with conjugate view tensors.
b) OpInfo tests that run with conjugate views
- test_variant_consistency_eager/jit
- gradcheck, gradgradcheck
- test_conj_views (that only run for `torch.cfloat` dtype)
NOTE: functions like `empty_like`, `zero_like`, `randn_like`, `clone` don't propagate the conjugate bit.
Follow up work:
1. conjugate view RFC
2. Add neg bit to re-enable view operation on conjugated tensors
3. Update linalg functions to call into specialized functions that fast path with the hermitian operation.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D28227315
Pulled By: anjali411
fbshipit-source-id: acab9402b9d6a970c6d512809b627a290c8def5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59027
Add underscores to some of the internal names
Test Plan:
python test/test_profiler.py -v
Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28724294
fbshipit-source-id: 1f6252e4befdf1928ac103d0042cbbf40616f74a
Summary:
Adds a note explaining the difference between several often conflated mechanisms in the autograd note
Also adds a link to this note from the docs in `grad_mode` and `nn.module`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58513
Reviewed By: gchanan
Differential Revision: D28651129
Pulled By: soulitzer
fbshipit-source-id: af9eb1749b641fc1b632815634eea36bf7979156
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58254
Don't use CUDA synchronize when profiling in CPU only mode.
minor fixes (a clarification for a doc string, fix spammy logging)
(Note: this ignores all push blocking failures!)
Test Plan: manual + CI
Reviewed By: gdankel, chaekit
Differential Revision: D28423667
Pulled By: ilia-cher
fbshipit-source-id: 04c71727f528ae8e2e0ff90e88271608d291bc69
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56608
- Adds binding to the `c10::InferenceMode` RAII class in `torch._C._autograd.InferenceMode` through pybind. Also binds the `torch.is_inference_mode` function.
- Adds context manager `torch.inference_mode` to manage an instance of `c10::InferenceMode` (global). Implemented in `torch.autograd.grad_mode.py` to reuse the `_DecoratorContextManager` class.
- Adds some tests based on those linked in the issue + several more for just the context manager
Issues/todos (not necessarily for this PR):
- Improve short inference mode description
- Small example
- Improved testing since there is no direct way of checking TLS/dispatch keys
-
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58045
Reviewed By: agolynski
Differential Revision: D28390595
Pulled By: soulitzer
fbshipit-source-id: ae98fa036c6a2cf7f56e0fd4c352ff804904752c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58133
Adding CUDA event fallback for cases when CUPTI tracing is not
available, this corresponds to the legacy profiler GPU profiling
Test Plan: python test/test_profiler.py -v
Reviewed By: gdankel
Differential Revision: D28379596
Pulled By: ilia-cher
fbshipit-source-id: 2db3b2cd8c1c3e6e596784ab00a226c69db2ef27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58013
Add a test case and a fix (legacy profiler) for empty trace handling
Test Plan: python test/test_profiler.py
Reviewed By: gdankel
Differential Revision: D28345388
Pulled By: ilia-cher
fbshipit-source-id: 4727589ab83367ac8b506cc0f186e5292d974671
Summary:
Fixes https://github.com/pytorch/pytorch/issues/30696
### Release Notes
Instantiating a custom autograd function is now deprecated. Users should call `.apply()` on the class itself because it is a static method.
--end release notes--
- There are a couple error messages that we can't entirely remove because accessing these attributes of the autograd function instance may segfault (due to cdata being nullptr). Also added a TORCH_CHECK for the name attribute which previously segfaulted.
- Error message updated to convey 1) old-style functions have been deprecated 2) this access pattern was once valid
- Updates variable -> Tensor for some error messages
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57357
Reviewed By: mrshenli
Differential Revision: D28193095
Pulled By: soulitzer
fbshipit-source-id: f021b105e9a3fd4a20d6ee3dfb6a06a8c34b10ca
Summary:
Add an ability to use new profiler API even if Kineto is not compiled
in, by falling back to the legacy profiler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57612
Test Plan:
compiled
USE_KINETO=0 USE_CUDA=1 USE_MKLDNN=1 BLAS=MKL BUILD_BINARY=1 python
setup.py develop install --cmake
and with USE_KINETO=1
and ran
python test/test_profiler.py -v
Reviewed By: gdankel
Differential Revision: D28217680
Pulled By: ilia-cher
fbshipit-source-id: ec81fb527eb69bb0a3e0bd6aad13592200d7fe70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57253
This PR:
1. Adds is_async getter/setter to RecordFunction
2. Adds is_async field to LegacyEvent and KinetoEvent, read from RecordFunction
3. Modifies python profiler code to check is_async via this flag (and keeps the old thread check as well)
4. Sets profiling of c10d collectives as async in ProcessGroup.cpp
5. Modifies tests to ensure is_async is set
This also fixes flaky tests such as #50840 and #56690 which have been flaky due to the profiling part (https://github.com/pytorch/pytorch/pull/56963 tried to do so as well but this is a better approach).
ghstack-source-id: 128021158
Test Plan: CI
Reviewed By: walterddr, ilia-cher
Differential Revision: D28086719
fbshipit-source-id: 4473db4aed939a71fbe9db5d6655f3008347cb29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56964
This PR does many things but does not update any logic:
- Prefixes all function names that are not `gradcheck`, `gradgradcheck`, `get_numerical_jacobian`, and `get_analytical_jacobian` with underscore to indicate that they aren't part of the public API (https://github.com/pytorch/pytorch/issues/55714).
- Improve naming to avoid referencing Jacobian rows or Jacobian cols when we really mean vjp and jvp as suggested by zou3519
- Try to reduce comment line length so they are more consistent and easier to read
- Other misc improvements to documentaiton
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28096571
Pulled By: soulitzer
fbshipit-source-id: d372b5f8ee080669e525a987402ded72810baa0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55699
Todo:
- error message should be updated to say whether the failure is for fn's real or imaginary component
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28007887
Pulled By: soulitzer
fbshipit-source-id: 1819201f59c8586a1d9631db05983969438bde66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55692
### Release notes
get_numerical_jacobian and get_analytical_jacobian only support `grad_out=1` and `fn` no longer accepts functions that return complex output
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28004614
Pulled By: soulitzer
fbshipit-source-id: 9592c9c69584b4035b39be62252f138dce39d3b5
Summary:
Adding cuda synchronization when entering and exiting the profiler
context manager
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56651
Test Plan: CI
Reviewed By: gdankel
Differential Revision: D27926270
Pulled By: ilia-cher
fbshipit-source-id: 5cf30128590c1c71a865f877578975c4a6e2cb48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55656
### For release notes
What:
- All errors that are silenced by "raise_exception=False" are now GradcheckError (which inherits from RuntimeError).
Why:
- Due to a refactor of gradcheck
Workaround:
- If you catch for 'RuntimeError' with `except RuntimeError`, since GradcheckError inherits from RuntimeError, no changes are necessary. However if you explicitly check for the errors type via `type(error)`, you'll need to update your code to check for `GradcheckError` instead.
Factors out all the logic handling involving `fail_test`, `raise_exception` into 1) a wrapper around gradcheck that uses try/except 2) gradcheck_helper that always raises exception.
This allows us to avoid having to write the `if not x: return False` logic that is scattered throughout gradcheck currently.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920809
Pulled By: soulitzer
fbshipit-source-id: 253aef6d9a3b147ee37a6e37a4ce06437981929a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55237
In this PR, we reenable fast-gradcheck and resolve misc issues that arise:
Before landing this PR, land #55182 so that slow tests are still being run periodically.
Bolded indicates the issue is handled in this PR, otherwise it is handled in a previous PR.
**Non-determinism issues**:
- ops that do not have deterministic implementation (as documented https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html#torch.use_deterministic_algorithms)
- test_pad_cuda (replication_pad2d) (test_nn)
- interpolate (test_nn)
- cummin, cummax (scatter_add_cuda_kernel) (test_ops)
- test_fn_gradgrad_prod_cpu_float64 (test_ops)
Randomness:
- RRelu (new module tests) - we fix by using our own generator as to avoid messing with user RNG state (handled in #54480)
Numerical precision issues:
- jacobian mismatch: test_gelu (test_nn, float32, not able to replicate locally) - we fixed this by disabling for float32 (handled in previous PR)
- cholesky_solve (test_linalg): #56235 handled in previous PR
- **cumprod** (test_ops) - #56275 disabled fast gradcheck
Not yet replicated:
- test_relaxed_one_hot_categorical_2d (test_distributions)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920906
fbshipit-source-id: 894dd7bf20b74f1a91a5bc24fe56794b4ee24656
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54480
This PR shouldn't really change the behavior of gradcheck for most ops. However, the changes in test_autograd allow us to run basic checks for both fast and slow (instead of previously just slow). All it should be doing is wrapping the preexisting tests we introduced in prior PRs in a function which takes `fast_mode` as a param. We then call this function twice, once with `fast_mode=True` and once with `fast_mode=False`.
Plan for rollout:
- This PR should only land the code (and runs some basic checks as described above).
- This should help us verify that a) slow is still working as expected b) basic functionality of fast works
- After we land this, but before we run the next PR in the stack, we should land https://github.com/pytorch/pytorch/pull/55182. This is to ensure that there is no gap where the slow tests aren't running.
- The next PR is responsible for enabling the fast_mode=True flag on all tests (where the function has real inputs/outputs), and selectively disabling for the cases the fail.
- Finally in a later PR, we reenable fast-gradcheck for functions w/ complex inputs/outputs
TODOs and open questions (not necessarily blocking this PR):
- ~How do we think about atol/rtol~ (scale atol, keep rtol as-is)
- ~reenable fast-gradcheck for complex numbers~
- ~when inputs are uncoalesced we don't truly test this case because we coalesce the inputs before calling function. Revisit this when https://github.com/pytorch/pytorch/pull/52874/files is landed~
### Developer Experience
Sample output when jacobian mismatch occurs:
```
Traceback (most recent call last):
File "/home/s/local/pytorch4/test/test_autograd.py", line 4220, in test_gradcheck_jacobian_mismatch
check(fast_mode=True)
File "/home/s/local/pytorch4/test/test_autograd.py", line 4196, in check
gradcheck(fn, (x,), fast_mode=fast_mode)
File "/home/s/local/pytorch4/torch/testing/_internal/common_utils.py", line 2067, in gradcheck
return torch.autograd.gradcheck(fn, inputs, **kwargs)
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 1020, in gradcheck
if not fast_gradcheck(fail_test, seeded_func, func_out, tupled_inputs, outputs, eps, rtol,
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 915, in fast_gradcheck
return fail_test(get_notallclose_msg(a, n, i, j, prefix) + jacobians_str)
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 996, in fail_test
raise RuntimeError(msg)
RuntimeError: Jacobian mismatch for output 0 with respect to input 0,
numerical:tensor(0.9195)
analytical:tensor(0.9389)
The above quantities relating the numerical and analytical jacobians are computed
in fast mode. See: https://github.com/pytorch/pytorch/issues/53876 for more background
about fast mode. Below, we recompute numerical and analytical jacobians in slow mode:
Numerical:
tensor([[1.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 1.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 1.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 1.0000]])
Analytical:
tensor([[1.0100, 0.0100, 0.0100, 0.0100],
[0.0100, 1.0100, 0.0100, 0.0100],
[0.0100, 0.0100, 1.0100, 0.0100],
[0.0100, 0.0100, 0.0100, 1.0100]])
The max per-element difference (slow mode) is: 0.010000000000054632.
```
Additionally, if the per-element difference is small i.e., `allclose(analytical_slow, numerical_slow, rtol, atol) is True` we follow up with this message:
```
Fast gradcheck failed but element-wise differences are small. This means that the
test might've passed in slow_mode!
If you are adding a new operator, please file an issue and then use one of the
workarounds. The workaround depends on how your test invokes gradcheck/gradgradcheck.
If the test
- manually invokes gradcheck/gradgradcheck, then call gradcheck/gradgradcheck
with `fast_mode=False` as a keyword argument.
- is OpInfo-based (e.g., in test_ops.py), then modify the OpInfo for the test
to have `gradcheck_fast_mode=False`
- is a Module test (e.g., in common_nn.py), then modify the corresponding
module_test entry to have `gradcheck_fast_mode=False`
```
Test Plan: Imported from OSS
Reviewed By: walterddr, ejguan
Differential Revision: D27825160
Pulled By: soulitzer
fbshipit-source-id: 1fe60569d8b697c213b0d262a832622a4e9cf0c7
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for autograd functions. I left the autoclass parts intact but manually laid out their members.
Also the Latex formatting of the spcecial page emitted a warning (solved by adding `\begin{align}...\end{align}`) and fixed alignment of equations (by using `&=` instead of `=`).
zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55672
Reviewed By: jbschlosser
Differential Revision: D27736855
Pulled By: zou3519
fbshipit-source-id: addb56f4f81c82d8537884e0ff243c1e34969a6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54479
This change is similar to #54049 in that it helps us factor out some code that can be used in both fast and slow versions of gradcheck.
- `compute_gradient` and `compute_numerical_jacobian_cols` have fewer responsibilities:
- compute_numerical_jacobian_cols essentially only handles the complexity of complex derivatives
- compute_gradient handles only finite differencing (and doesn't worry about different layouts and indexing into the input tensor)
- we have two stages again where we first compute the columns separately, then combine them
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27728727
Pulled By: soulitzer
fbshipit-source-id: fad3d5c1a91882621039beae3d0ecf633c19c28c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54378
### For release notes
`torch.autograd.gradcheck.get_numerical_jacobian` (not part of the public api) is being deprecated.
In the future, user code relying on this function will break because, among other changes, `get_numerical_jacobian` now returns `List[Tuple[torch.Tensor]]` instead of `List[torch.Tensor]`.
(more details if necessary)
For a `fn` that takes in M inputs and N outputs we now return a list of M N-tuples of jacobians where `output[i][j]` would represent the numerical jacobian w.r.t. to the ith input and the jth output. Previously `get_numerical_jacobian` returned a list of tensors where each tensor represents the jacobian w.r.t. to each of the M inputs and a specific output. Finally, the function passed in as the parameter `fn` should expect to handle individual parameters, where previously `fn` is required to expect its parameters wrapped in a tuple.
--- end --
This PR addresses the comment here https://github.com/pytorch/pytorch/pull/53857#discussion_r595429639, to reduce the run-time of old gradcheck's get numerical jacobian by a factor of num_outputs. However, because very few ops actually return multiple outputs, there is not too much real speed up here.
The main benefit of doing this change as part of the refactor is that it helps us isolate the possible bugs that are specific to switching `get numerical jacobian` to run in a per output way vs all outputs at once. Much of the logic implemented here will be the same for the fast gradcheck case, so knowing for certain that everything should pass after this stage will make the next step much simpler.
The get_numerical_jacobian api is also being used in common_nn. So we update the callsite there as well.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27728720
Pulled By: soulitzer
fbshipit-source-id: ee0f90b4f26ddc5fdbe949c4965eaa91c9ed0bb8
Summary:
Generally wildcard imports are bad for the reasons described here: https://www.flake8rules.com/rules/F403.html
This PR replaces wildcard imports with an explicit list of imported items where possible, and adds a `# noqa: F403` comment in the other cases (mostly re-exports in `__init__.py` files).
This is a prerequisite for https://github.com/pytorch/pytorch/issues/55816, because currently [`tools/codegen/dest/register_dispatch_key.py` simply fails if you sort its imports](https://github.com/pytorch/pytorch/actions/runs/742505908).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55838
Test Plan: CI. You can also run `flake8` locally.
Reviewed By: jbschlosser
Differential Revision: D27724232
Pulled By: samestep
fbshipit-source-id: 269fb09cb4168f8a51fd65bfaacc6cda7fb87c34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55226
Fixes a bug caused by using different clocks in legacy events, also fixes two
small issues with not using relative time in memory events and discrepancy
between start and stop profile events CUDA-wise
Test Plan: CI
Reviewed By: xuzhao9
Differential Revision: D27534920
fbshipit-source-id: 7a877367b3031660516c9c4fdda1bf47e77bcb3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54092
This is the first of several refactors to get numerical jacobian:
This one just moves some logic around as to try to split the get_numerical_jacobian function into smaller more manageable functions:
- compute_gradient is now no longer nested, but we have to pass in the parameters instead
- iter_tensor extracts out the logic of iterating through different types of tensors (the code should be almost the exact same here except for instead of calling into the update jacobian function, we yield the arguments instead)
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27354268
Pulled By: soulitzer
fbshipit-source-id: 73288e3c889ae31bb8bf77a0e3acb3e9020e09a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54049
The goal of this is to factor out the core logic of getting the analytical jacobian which is effectively doing `f(grad_out) = grad_out^T J = grad_input`. This allows us to test a lot of logic that was not possible before because now we can replace f with whatever we want in order to simulate potential issues that gradcheck is designed to catch.
Edit: I realize a lot of things this PR was originally aiming to allow is actually possible with hooks, hence the tests have already been added in a earlier PR in the stack. But this is still slightly useful for reducing code duplication when adding the new fast gradcheck code (more details below)
After this change, `get_analytical_jacobian` is only responsible for gathering a list of rows that are later combined into a single Jacobian tensor. This means we don't have to perform any checks for correctness of the dtypes/size at this step
We factor out that logic into a separate function, `combine_jacobian_rows`, which handles the list of rows -> single Tensor step for each jacobian, and the error checking it entails. (This allows this code to be shared between the fast/slow versions.)
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27307240
Pulled By: soulitzer
fbshipit-source-id: 65bb58cda000ed6f3114e5b525ac3cae8da5b878
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53916
This PR fixes some bugs that are made more clear by the previous refactor.
- make sure gradcheck returns false when its supposed to fail and when raise_exception=False.
- make sure when test_batched_grad fails, it returns false when raise_exception=False
Removing checkIfNumericalAnalyticAreClose made sense here to me because underneath its really doing `torch.allclose`, and using that directly instead of adding another opaque function to call seemed to make the code more clear.
TODO:
- ~add a test to see if when torch.allclose fails, we indeed return false.~
- ~uncomment test from previous PR.~
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27201692
Pulled By: soulitzer
fbshipit-source-id: 8b8dc37c59edb7eebc2e8db6f8839ce98a81d78b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53857
This PR basically just factors a lot of the logic out from the main gradcheck function into their own individual functions. It aims to avoid any behavior change (but we may not have enough tests to actually verify this). Refactorings that lead to any behavior chang are done in the next PR in this stack.
The rationale for this change is 1) to make the main gradcheck function cleaner to read, and 2) also allow us to reuse the same pieces when we add the fast gradcheck.
Maybe this PR is also a good place to add some tests for gradcheck, i.e., make sure gradcheck fails when it should fail, as to make sure that we are indeed not changing any logic. This will also help us make sure our fast_gradcheck does all the necessary checks:
So far existing tests are:
- test_gradcheck_fail_when_no_differentiable_outputs_and_num_grad_not_zero` (test_autograd)
- test_gradcheck_single_input (test_autograd)
- test_gradcheck_sparse_input (test_autograd)
- test_gradcheck_nondeterministic (test_autograd)
- test_gradcheck (test_overrides)
Full coverage would potentially require adding the following missing tests (for each test for both raise_exception=True/False) - Methodology for getting the list below is that for every type of error message we spit out, we make sure we can hit it:
- complex:
- when numerical != analytical when tested with imag grad_out
- check_inputs
- ~when inputs are not dense, but check_sparse_nnz is false~
- ~when none of the inputs require grad~
- ~(warning) when inputs are not double precision~
- ~when layout is not mkldnn(aka has strides) and input has a dimension with stride 0.~
- check_no_differentiable_outputs:
- ~when none of the outputs are differentiable, but numerical gradient is not zero~
- check_outputs:
- ~when sparse outputs (always raise)~
- ~when mkldnn outputs (always raise)~
- test_batched_grad
- ~when encounter runtime error while computing batched grad (print big message)~
- when not allclose (print out big message)
- test_backward_mul_by_grad_output
- ~when layout of grad_input is not the same as input~
- ~when grad_input is sparse and has incorrect sparse_dim/dense_dim~
- ~when backward not multiplied by grad_output (sparse/non-sparse case)~
- when grad is incorrect type/size
- test_undefined_grad
- ~when encounter runtime error while running backward~
- when we complete backward but grad inputs (the output of .grad()) is not none
- check_analytical_jacobian_attributes (for both complex/non complex)
- when grad input is incorrect dtype/size
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27201571
Pulled By: soulitzer
fbshipit-source-id: 86670a91e65740d57dd6ada7c6b4512786d15962
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52422
As mentioned in https://github.com/pytorch/pytorch/issues/52415,
`torch.utils.checkpoint` doesn't support checkpointing for functions which have
non-tensor inputs and outputs.
This PR resolves this issue by ensuring the autograd machinery ignores the
non-tensor inputs and outputs and processes the tensors accordingly.
ghstack-source-id: 124406867
Test Plan:
1) unit test
2) waitforbuildbot
Reviewed By: albanD
Differential Revision: D26507228
fbshipit-source-id: 0a5a1591570814176185362e83ad18dabd9c84b0
Summary:
Also updates the doc such that the language matches the type. For example, previously the `tensors` argument is specified as `(sequence of tensor)`, but has type annotation of `_TensorOrTensors`. Now its correctly updated to be `Sequence[Tensor] or Tensor`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53827
Reviewed By: albanD
Differential Revision: D26997541
Pulled By: soulitzer
fbshipit-source-id: e1e609a4e9525139d0fe96f6157175481c90d6f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53424
Fixes https://github.com/pytorch/pytorch/issues/24807 and supersedes the stale https://github.com/pytorch/pytorch/issues/25093 (Cc Microsheep). If you now run the reproduction
```python
import torch
if __name__ == "__main__":
t = torch.tensor([1, 2, 3], dtype=torch.float64)
```
with `pylint==2.6.0`, you get the following output
```
test_pylint.py:1:0: C0114: Missing module docstring (missing-module-docstring)
test_pylint.py:4:8: E1101: Module 'torch' has no 'tensor' member; maybe 'Tensor'? (no-
member)
test_pylint.py:4:38: E1101: Module 'torch' has no 'float64' member (no-member)
```
Now `pylint` doesn't recognize `torch.tensor` at all, but it is promoted in the stub. Given that it also doesn't recognize `torch.float64`, I think fixing this is out of scope of this PR.
---
## TL;DR
This BC-breaking only for users that rely on unintended behavior. Since `torch/__init__.py` loaded `torch/tensor.py` it was populated in `sys.modules`. `torch/__init__.py` then overwrote `torch.tensor` with the actual function. With this `import torch.tensor as tensor` does not fail, but returns the function rather than the module. Users that rely on this import need to change it to `from torch import tensor`.
Reviewed By: zou3519
Differential Revision: D26223815
Pulled By: bdhirsh
fbshipit-source-id: 125b9ff3d276e84a645cd7521e8d6160b1ca1c21
Summary:
The new profiler API was added in PR#48280. This PR is to add FLOPS
support to the new profiler API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51734
Test Plan:
```python
python test/test_profiler.py -k test_flops
```
Reviewed By: xuzhao9
Differential Revision: D26261851
Pulled By: ilia-cher
fbshipit-source-id: dbeba4c197e6f51a9a8e640e8bb60ec38df87f73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51421
Mark memory events that did not happen within an operator context
explicitly in the profiler output.
Test Plan: python test/test_profiler.py -k test_memory_profiler
Reviewed By: ngimel
Differential Revision: D26166518
Pulled By: ilia-cher
fbshipit-source-id: 3c14d3ac25a7137733ea7cc65f0eb48693a98f5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51638
This PR makes the following doc changes:
- Makes it clear to users that they should use vectorize "at their own
risk"
- Makes it clear that vectorize uses the "experimental prototype vmap"
so that when users see error messages related to vmap they will know
where it is coming from.
This PR also:
- makes it so that {jacobian, hessian} call a version of vmap that
doesn't warn the user that they are using an "experimental prototype".
The regular torch.vmap API does warn the user about this. This is to
improve a UX a little because the user already knows from discovering
the flag and reading the docs what they are getting themselves into.
Test Plan:
- Add test that {jacobian, hessian} with vectorize=True don't raise
warnings
Reviewed By: albanD
Differential Revision: D26225402
Pulled By: zou3519
fbshipit-source-id: 1a6db920ecf10597fb2e0c6576f510507d999c34
Summary:
Add the FLOPS metric computation to the experimental Kineto profiler.
This includes saving necessary extra arguments and compute flops in the C++ code,
and extract the FLOPS value from the Python frontend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51503
Test Plan:
Build PyTorch with USE_KINETO option, then run the unit test:
```python
python test/test_profiler.py -k test_flops
```
Reviewed By: ilia-cher
Differential Revision: D26202711
Pulled By: xuzhao9
fbshipit-source-id: 7dab7c513f454355a220b72859edb3ccbddcb3ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51218Fixes#51144.
Context
=======
Users have complained about warning spam from batched gradient
computation. This warning spam happens because warnings in C++ don't
correctly get turned into Python warnings when those warnings arise from
the autograd engine.
To work around that, this PR adds a mechanism to toggle vmap warnings.
By default, the vmap fallback will not warn when it is invoked. However,
by using `torch._C._debug_only_display_vmap_fallback_warnings(enabled)`,
one can toggle the existence of vmap fallback warnings.
This API is meant to be a private, debug-only API. The goal is to be
able to non-intrusively collect feedback from users to improve
performance on their workloads.
What this PR does
=================
This PR adds an option to toggle vmap warnings. The mechanism is
toggling a bool in ATen's global context.
There are some other minor changes:
- This PR adds a more detailed explanation of performance cliffs to the
autograd.functional.{jacobian, hessian} documentation
- A lot of the vmap tests in `test_vmap.py` rely on the fallback warning
to test the presence of the fallback. In test_vmap, I added a context
manager to toggle on the fallback warning while testing.
Alternatives
============
I listed a number of alternatives in #51144. My favorite one is having a new
"performance warnings mode" (this is currently a WIP by some folks on
the team). This PR is to mitigate the problem of warning spam before
a "performance warnings mode" gets shipped into PyTorch
Concerns
========
I am concerned that we are advertising a private API
(`torch._C._debug_only_display_vmap_fallback_warnings(enabled)`) in the
PyTorch documentation. However, I hope the naming makes it clear to
users that they should not rely on this API (and I don't think they have
any reason to rely on the API).
Test Plan
=========
Added tests in `test_vmap.py` to check:
- by default, the fallback does not warn
- we can toggle whether the fallback warns or not
Test Plan: Imported from OSS
Reviewed By: pbelevich, anjali411
Differential Revision: D26126419
Pulled By: zou3519
fbshipit-source-id: 95a97f9b40dc7334f6335a112fcdc85dc03dcc73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50915Fixes#50584
Add a vectorize flag to torch.autograd.functional.jacobian and
torch.autograd.functional.hessian (default: False). Under the hood, the
vectorize flag uses vmap as the backend to compute the jacobian and
hessian, respectively, providing speedups to users.
Test Plan:
- I updated all of the jacobian and hessian tests to also use
vectorized=True
- I added some simple sanity check tests that check e.g. jacobian with
vectorized=False vs
jacobian with vectorized=True.
- The mechanism for vectorized=True goes through batched gradient
computation. We have separate tests for those (see other PRs in this
stack).
Reviewed By: heitorschueroff
Differential Revision: D26057674
Pulled By: zou3519
fbshipit-source-id: a8ae7ca0d2028ffb478abd1b377f5b49ee39e4a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50818
This PR does two things:
1. Add batched grad testing to OpInfo
2. Improve the error message from `gradcheck` if batched gradient
computation fails to include suggestions for workarounds.
To add batched grad testing to OpInfo, this PR:
- adds new `check_batched_grad=True` and `check_batched_gradgrad=True`
attributes to OpInfo. These are True by default because we expect most
operators to support batched gradient computation.
- If `check_batched_grad=True`, then `test_fn_grad` invokes gradcheck
with `check_batched_grad=True`.
- If `check_batched_gradgrad=True`, then `test_fn_gradgradgrad` invokes
gradgradcheck with `check_batched_grad=True`.
The improved gradcheck error message looks like the following when an
exception is thrown while computing batched gradients:
https://gist.github.com/zou3519/5a0f46f908ba036259ca5e3752fd642f
Future
- Sometime in the not-near future, we will separate out "batched grad
testing" from "gradcheck" for the purposes of OpInfo to make the
testing more granular and also so that we can test that the vmap
fallback doesn't get invoked (currently batched gradient testing only
tests that the output values are correct).
Test Plan: - run tests `pytest test/test_ops.py -v -k "Gradients"`
Reviewed By: ejguan
Differential Revision: D25997703
Pulled By: zou3519
fbshipit-source-id: 6d2d444d6348ae6cdc24c32c6c0622bd67b9eb7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50592
This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck.
It defaults to False because gradcheck is a public API and I don't want
to break any existing non-pytorch users of gradcheck.
This:
- runs grad twice with two grad outputs, a & b
- runs a vmapped grad with torch.stack([a, b])
- compares the results of the above against each other.
Furthermore:
- `check_batched_grad=True` is set to be the default for
gradcheck/gradgradcheck inside of test_autograd.py. This is done by
reassigning to the gradcheck object inside test_autograd
- I manually added `check_batched_grad=False` to gradcheck instances
that don't support batched grad.
- I added a denylist for operations that don't support batched grad.
Question:
- Should we have a testing only gradcheck (e.g.,
torch.testing.gradcheck) that has different defaults from our public
API, torch.autograd.gradcheck?
Future:
- The future plan for this is to repeat the above for test_nn.py (the
autogenerated test will require a denylist)
- Finally, we can repeat the above for all pytorch test files that use
gradcheck.
Test Plan: - run tests
Reviewed By: albanD
Differential Revision: D25925942
Pulled By: zou3519
fbshipit-source-id: 4803c389953469d0bacb285774c895009059522f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49120
This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck.
It defaults to False because gradcheck is a public API and I don't want
to break any existing non-pytorch users of gradcheck.
This:
- runs grad twice with two grad outputs, a & b
- runs a vmapped grad with torch.stack([a, b])
- compares the results of the above against each other.
Furthermore:
- `check_batched_grad=True` is set to be the default for
gradcheck/gradgradcheck inside of test_autograd.py. This is done by
reassigning to the gradcheck object inside test_autograd
- I manually added `check_batched_grad=False` to gradcheck instances
that don't support batched grad.
- I added a denylist for operations that don't support batched grad.
Question:
- Should we have a testing only gradcheck (e.g.,
torch.testing.gradcheck) that has different defaults from our public
API, torch.autograd.gradcheck?
Future:
- The future plan for this is to repeat the above for test_nn.py (the
autogenerated test will require a denylist)
- Finally, we can repeat the above for all pytorch test files that use
gradcheck.
Test Plan: - run tests
Reviewed By: albanD
Differential Revision: D25563542
Pulled By: zou3519
fbshipit-source-id: 125dea554abefcef0cb7b487d5400cd50b77c52c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48280
Adding new API for the kineto profiler that supports enable predicate
function
Test Plan: unit test
Reviewed By: ngimel
Differential Revision: D25142220
Pulled By: ilia-cher
fbshipit-source-id: c57fa42855895075328733d7379eaf3dc1743d14
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47441
To give user more information about python level functions in profiler traces, we propose to instrument on the following functions:
```
_BaseDataLoaderIter.__next__
Optimizer.step
Optimizer.zero_grad
```
Because the record_function already uses if (!active) to check whether the profiler is enabled, so we don't explicitly call torch.autograd._profiler_enabled() before each instrument.
Acknowledgement: nbcsm, guotuofeng, gunandrose4u , guyang3532 , mszhanyi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47655
Reviewed By: smessmer
Differential Revision: D24960386
Pulled By: ilia-cher
fbshipit-source-id: 2eb655789e2e2f506e1b8f95ad3d470c83281102
Summary:
Currently the max `src_column_width` is hardcoded to 75 which might not be sufficient for modules with long file names. This PR exposes `max_src_column_width` as a changeable parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46257
Reviewed By: malfet
Differential Revision: D24280834
Pulled By: yf225
fbshipit-source-id: 8a90a433c6257ff2d2d79f67a944450fdf5dd494
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46373
As noted in https://github.com/pytorch/pytorch/issues/46373, there needs to be a flag passed into the engine that indicates whether it was executed through the backward api or grad api. Tentatively named the flag `accumulate_grad` since functionally, backward api accumulates grad into .grad while grad api captures the grad and returns it.
Moving changes not necessary to the python api (cpp, torchscript) to a new PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46855
Reviewed By: ngimel
Differential Revision: D24649054
Pulled By: soulitzer
fbshipit-source-id: 6925d5a67d583eeb781fc7cfaec807c410e1fc65
Summary:
Currently, a GraphRoot instance doesn't have an associated stream. Streaming backward synchronization logic assumes the instance ran on the default stream, and tells consumer ops to sync with the default stream. If the gradient the GraphRoot instance passes to consumer backward ops was populated on a non-default stream, we have a race condition.
The race condition can exist even if the user doesn't give a manually populated gradient:
```python
with torch.cuda.stream(side_stream):
# loss.backward() implicitly synthesizes a one-element 1.0 tensor on side_stream
# GraphRoot passes it to consumers, but consumers first sync on default stream, not side_stream.
loss.backward()
# Internally to backward(), streaming-backward logic takes over, stuff executes on the same stream it ran on in forward,
# and the side_stream context is irrelevant. GraphRoot's interaction with its first consumer(s) is the spot where
# the side_stream context causes a problem.
```
This PR fixes the race condition by associating a GraphRoot instance, at construction time, with the current stream(s) on the device(s) of the grads it will pass to consumers. (i think this relies on GraphRoot executing in the main thread, before backward thread(s) fork, because the grads were populated on the main thread.)
The test demonstrates the race condition. It fails reliably without the PR's GraphRoot diffs and passes with the GraphRoot diffs.
With the GraphRoot diffs, manually populating an incoming-gradient arg for `backward` (or `torch.autograd.grad`) and the actual call to `autograd.backward` will have the same stream-semantics relationship as any other pair of ops:
```python
# implicit population is safe
with torch.cuda.stream(side_stream):
loss.backward()
# explicit population in side stream then backward in side stream is safe
with torch.cuda.stream(side_stream):
kickoff_grad = torch.ones_like(loss)
loss.backward(gradient=kickoff_grad)
# explicit population in one stream then backward kickoff in another stream
# is NOT safe, even with this PR's diffs, but that unsafety is consistent with
# stream-semantics relationship of any pair of ops
kickoff_grad = torch.ones_like(loss)
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
# Safe, as you'd expect for any pair of ops
kickoff_grad = torch.ones_like(loss)
side_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
```
This PR also adds the last three examples above to cuda docs and references them from autograd docstrings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45787
Reviewed By: nairbv
Differential Revision: D24138376
Pulled By: albanD
fbshipit-source-id: bc4cd9390f9f0358633db530b1b09f9c1080d2a3
Summary:
In profiler, cuda did not report self time, so for composite functions there was no way to determine which function is really taking time. In addition, "total cuda time" reported was frequently more than total wallclock time. This PR adds "self CUDA time" in profiler, and computes total cuda time based on self cuda time, similar to how it's done for CPU. Also, slight formatting changes to make table more compact. Before:
```
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
aten::matmul 0.17% 890.805us 99.05% 523.401ms 5.234ms 49.91% 791.184ms 7.912ms 100
aten::mm 98.09% 518.336ms 98.88% 522.511ms 5.225ms 49.89% 790.885ms 7.909ms 100
aten::t 0.29% 1.530ms 0.49% 2.588ms 25.882us 0.07% 1.058ms 10.576us 100
aten::view 0.46% 2.448ms 0.46% 2.448ms 12.238us 0.06% 918.936us 4.595us 200
aten::transpose 0.13% 707.204us 0.20% 1.058ms 10.581us 0.03% 457.802us 4.578us 100
aten::empty 0.14% 716.056us 0.14% 716.056us 7.161us 0.01% 185.694us 1.857us 100
aten::as_strided 0.07% 350.935us 0.07% 350.935us 3.509us 0.01% 156.380us 1.564us 100
aten::stride 0.65% 3.458ms 0.65% 3.458ms 11.527us 0.03% 441.258us 1.471us 300
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 528.437ms
CUDA time total: 1.585s
Recorded timeit time: 789.0814 ms
```
Note recorded timeit time (with proper cuda syncs) is 2 times smaller than "CUDA time total" reported by profiler
After
```
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::matmul 0.15% 802.716us 99.06% 523.548ms 5.235ms 302.451us 0.04% 791.151ms 7.912ms 100
aten::mm 98.20% 519.007ms 98.91% 522.745ms 5.227ms 790.225ms 99.63% 790.848ms 7.908ms 100
aten::t 0.27% 1.406ms 0.49% 2.578ms 25.783us 604.964us 0.08% 1.066ms 10.662us 100
aten::view 0.45% 2.371ms 0.45% 2.371ms 11.856us 926.281us 0.12% 926.281us 4.631us 200
aten::transpose 0.15% 783.462us 0.22% 1.173ms 11.727us 310.016us 0.04% 461.282us 4.613us 100
aten::empty 0.11% 591.603us 0.11% 591.603us 5.916us 176.566us 0.02% 176.566us 1.766us 100
aten::as_strided 0.07% 389.270us 0.07% 389.270us 3.893us 151.266us 0.02% 151.266us 1.513us 100
aten::stride 0.60% 3.147ms 0.60% 3.147ms 10.489us 446.451us 0.06% 446.451us 1.488us 300
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 528.498ms
CUDA time total: 793.143ms
Recorded timeit time: 788.9832 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45209
Reviewed By: zou3519
Differential Revision: D23925491
Pulled By: ngimel
fbshipit-source-id: 7f9c49238d116bfd2db9db3e8943355c953a77d0
Summary:
Change from self to self._class_() in _DecoratorManager to ensure a new object is every time a function is called recursively
Fixes https://github.com/pytorch/pytorch/issues/44531
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44633
Reviewed By: agolynski
Differential Revision: D23783601
Pulled By: albanD
fbshipit-source-id: a818664dee7bdb061a40ede27ef99e9546fc80bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43208
This PR adds gradcheck for complex. The logic used for complex gradcheck is described in Section 3.5.3 here: https://arxiv.org/pdf/1701.00392.pdf
More concretely, this PR introduces the following changes:
1. Updates get_numerical_jacobian to take as input a scalar value for vector (v). Adds gradcheck logic for C -> C, C-> R, R -> C. For R -> C functions, only the real value of gradient is propagated.
2. Adds backward definition for `torch.complex` and also adds a test to verify the definition added.
3. Updates backward for `mul`, `sin`, `cos`, `sinh`, `cosh`.
4. Adds tests for all `torch.real`, `torch.imag`, `torch.view_as_real`, `torch.view_as_complex`, `torch.conj`.
Follow up tasks:
1. Add more thorough tests for R -> C cases. Specifically, add R->C test variants for functions. for e.g., `torch.mul(complex_tensor, real_tensor)`
2. Add back commented test in `common_methods_invocation.py`.
3. Add more special case checking for complex gradcheck to make debugging easier.
4. Update complex autograd note.
5. disable complex autograd for operators not tested for complex.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23655088
Pulled By: anjali411
fbshipit-source-id: caa75e09864b5f6ead0f988f6368dce64cf15deb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44345
As part of enhancing profiler support for RPC, when executing TorchScript functions over RPC, we would like to be able to support user-defined profiling scopes created by `with record_function(...)`.
Since after https://github.com/pytorch/pytorch/pull/34705, we support `with` statements in TorchScript, this PR adds support for `with torch.autograd.profiler.record_function` to be used within TorchScript.
This can be accomplished via the following without this PR:
```
torch.opts.profiler._record_function_enter(...)
# Script code, such as forward pass
torch.opts.profiler._record_function_exit(....)
```
This is a bit hacky and it would be much cleaner to use the context manager now that we support `with` statements. Also, `_record_function_` type operators are internal operators that are subject to change, this change will help avoid BC issues in the future.
Tested with `python test/test_jit.py TestWith.test_with_record_function -v`
ghstack-source-id: 112320645
Test Plan:
Repro instructions:
1) Change `def script_add_ones_return_any(x) -> Any` to `def script_add_ones_return_any(x) -> Tensor` in `jit/rpc_test.py`
2) `buck test mode/dev-nosan //caffe2/test/distributed/rpc:process_group_agent -- test_record_function_on_caller_rpc_async --print-passing-details`
3) The function which ideally should accept `Future[Any]` is `def _call_end_callbacks_on_future` in `autograd/profiler.py`.
python test/test_jit.py TestWith.test_with_foo -v
Reviewed By: pritamdamania87
Differential Revision: D23332074
fbshipit-source-id: 61b0078578e8b23bfad5eeec3b0b146b6b35a870
Summary:
To help with further typing, move dynamically added native contributions from `torch.autograd` to `torch._C._autograd`
Fix invalid error handling pattern in
89ac30afb8/torch/csrc/autograd/init.cpp (L13-L15)
`PyImport_ImportModule` already raises Python exception and nullptr should be returned to properly propagate the to Python runtime.
And all native methods/types in `torch/autograd/__init.py` after `torch._C._init_autograd()` has been called
Use f-strings instead of `.format` in test_type_hints.py
Fixes https://github.com/pytorch/pytorch/issues/44450
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44451
Reviewed By: ezyang
Differential Revision: D23618261
Pulled By: malfet
fbshipit-source-id: fa5f739d7cff8410641128b55b810318c5f636ae
Summary:
This PR adds a new test suite, test_ops.py, designed for generic tests across all operators with OpInfos. It currently has two kinds of tests:
- it validates that the OpInfo has the correct supported dtypes by verifying that unsupported dtypes throw an error and supported dtypes do not
- it runs grad and gradgrad checks on each op and its variants (method and inplace) that has an OpInfo
This is a significant expansion and simplification of the current autogenerated autograd tests, which spend considerable processing their inputs. As an alternative, this PR extends OpInfos with "SampleInputs" that are much easier to use. These sample inputs are analogous to the existing tuples in`method_tests()`.
Future PRs will extend OpInfo-based testing to other uses of `method_tests()`, like test_jit.py, to ensure that new operator tests can be implemented entirely using an OpInfo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43451
Reviewed By: albanD
Differential Revision: D23481723
Pulled By: mruberry
fbshipit-source-id: 0c2cdeacc1fdaaf8c69bcd060d623fa3db3d6459
Summary:
- Add `torch._C` bindings from `torch/csrc/autograd/init.cpp`
- Renamed `torch._C.set_grad_enabled` to `torch._C._set_grad_enabled`
so it doesn't conflict with torch.set_grad_enabled anymore
This is a continuation of gh-38201. All I did was resolve merge conflicts and finish the annotation of `_DecoratorContextManager.__call__` that ezyang started in the first commit.
~Reverts commit b5cd3a80bb, which was only motivated by not having `typing_extensions` available.~ (JIT can't be made to understand `Literal[False]`, so keep as is).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43415
Reviewed By: ngimel
Differential Revision: D23301168
Pulled By: malfet
fbshipit-source-id: cb5290f2e556b4036592655b9fe54564cbb036f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41371
**Summary**
This commit enables the use of `torch.no_grad()` in a with item of a
with statement within JIT. Note that the use of this context manager as
a decorator is not supported.
**Test Plan**
This commit adds a test case to the existing with statements tests for
`torch.no_grad()`.
**Fixes**
This commit fixes#40259.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D22649519
Pulled By: SplitInfinity
fbshipit-source-id: 7fa675d04835377666dfd0ca4e6bc393dc541ab9
Summary:
Added a new option in AutogradContext to tell autograd to not materialize output grad tensors, that is, don't expand undefined/None tensors into tensors full of zeros before passing them as input to the backward function.
This PR is the second part that closes https://github.com/pytorch/pytorch/issues/41359. The first PR is https://github.com/pytorch/pytorch/pull/41490.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41821
Reviewed By: albanD
Differential Revision: D22693163
Pulled By: heitorschueroff
fbshipit-source-id: a8d060405a17ab1280a8506a06a2bbd85cb86461
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42565
After recent changes to the record function we record more
ranges in profiler output and also keep emitting sequence numbers for
all ranges.
Sequence numbers are used by external tools to correlate forward
and autograd ranges and with many ranges having the same sequence number
it becomes impossible to do this.
This PR ensures that we set sequence numbers only for the top-level
ranges and only in case when autograd is enabled.
Test Plan:
nvprof -fo trace.nvvp --profile-from-start off python test_script.py
test_script
https://gist.github.com/ilia-cher/2baffdd98951ee2a5f2da56a04fe15d0
then examining ranges in nvvp
Reviewed By: ngimel
Differential Revision: D22938828
Pulled By: ilia-cher
fbshipit-source-id: 9a5a076706a6043dfa669375da916a1708d12c19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37587
Lifting RecordFunction up into the dispatcher code
Test Plan: Imported from OSS
Differential Revision: D21374246
fbshipit-source-id: 19f9c1719e6fd3990e451c5bbd771121e91128f7
Summary:
Changes in the ROCm runtime have improved hipEventRecord. The events no longer take ~4 usec to execute on the gpu stream, instead they appear instantaneous. If you record two events, with no other activity in between, then they will have the same timestamp and the elapsed duration will be 0.
The profiler uses hip/cuda event pairs to infer gpu execution times. It wraps functions whether they send work to the gpu or not. Functions that send no gpu work will show as having zero duration. Also they will show as running at the same time as neighboring functions. On a trace, all those functions combine into a 'call stack' that can be tens of functions tall (when indeed they should be sequential).
This patch suppresses recording the zero duration 'kernel' events, leaving only the CPU execution part. This means functions that do not use the GPU do not get an entry for how long they were using the GPU, which seams reasonable. This fixes the 'stacking' on traces. It also improves the signal to noise of the GPU trace beyond what was available previously.
This patch will not effect CUDA or legacy ROCm as those are not able to 'execute' eventRecord markers instantaneously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41540
Reviewed By: zou3519
Differential Revision: D22597207
Pulled By: albanD
fbshipit-source-id: 5e89de2b6d53888db4f9dbcb91a94478cde2f525
Summary:
solves most of gh-38011 in the framework of solving gh-32703.
These should only be formatting fixes, I did not try to fix grammer and syntax.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41068
Differential Revision: D22411919
Pulled By: zou3519
fbshipit-source-id: 25780316b6da2cfb4028ea8a6f649bb18b746440
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40440
Shapes sometimes need more than 35 symbols
(Note: this ignores all push blocking failures!)
Test Plan:
found during testing the recipe
https://github.com/pytorch/tutorials/pull/1019
Differential Revision: D22188679
Pulled By: ilia-cher
fbshipit-source-id: efcf5d10882af7d9225897ec87debcf4abdc523f
Summary:
https://github.com/pytorch/pytorch/pull/40129 fixed the error responsible for the first revert, but exposed another error in the same test.
This PR is intended as the "master copy" for merge, and it runs on full CI.
Two other PRs (restricted to run on a small subset of CI) supporting debugging DDP failures/hangs with multiple devices per process (`test_c10d.py:DistributedDataParallelTest.test_grad_layout_1devicemodule_2replicaperprocess`).
- https://github.com/pytorch/pytorch/pull/40290 tries the test with purely rowmajor contiguous params on an untouched master. In other words https://github.com/pytorch/pytorch/pull/40290 contains none of this PR's diffs aside from the test itself.
- https://github.com/pytorch/pytorch/pull/40178, for comparison, tries the test with this PR's diffs.
Both fail the same way, indicating failure is unrelated to this PR's other diffs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40358
Differential Revision: D22165785
Pulled By: albanD
fbshipit-source-id: ac7cdd79af5c080ab74341671392dca8e717554e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40066
Builds on top of the previous PR to ensure that all remotely profiled events are prefixed with the key for the RPC that generated them.
The key is generated by the result of `_build_rpc_profiling_key` in `rpc/internal.py` and prefixed onto the event name. In order to do this, we set the current-key when creating the RPC in Python, retrieve the currently-set key in C++ and save a GloballyUniqueId -> key mapping to an in-memory map. When we receive an RPC with profiling information, we expect to receive this ID back, and look up the corresponding profiling key in the map.
The key is then added to all the remote events.
Tested by adding tests to ensure the key is added to all the remote events. Also added a UT which tests in under the multi-threading scenario, to ensure that the mapping's correctness is maintained when several RPCs are in the process of being created at once.
ghstack-source-id: 106316106
Test Plan: Unit test
Differential Revision: D22040035
fbshipit-source-id: 9215feb06084b294edbfa6e03385e13c1d730c43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38748
This diff contains the message scaffolding and profiler changes in order to be able to remotely run the profiler across different nodes and aggregate the results on a single node.
As discussed, we have implemented this by creating new message types, that similar to autograd messages, wrap the profiling information with the original message, and send this new message over the wire. On the receiving end, this wrapped message is detected, we fetch the original message from it, and process the original message with the profiler enabled. When sending a response with profiling information, we serialize the profiled `Events` and send them back over RPC. When such a message is received, the events profiled on the remote node are stored (added back to the local profiler).
Changes in this PR:
- New message types (run_with_profiling_req, run_with_profiling_resp) to send profiling info over the wire. Message parsing logic is added to handle these wrapped types.
- Handling of sending profiler data over the wire, in particular, the attributes of the `ProfilerConfig` and the serialized profiled `Event`s
- The logic for wrapping RPC messages is deduped with that in `rpc_with_autograd`, and the common payload wrapping/unwrapping logic is moved to helper functions in `rpc/utils.cpp`
- Changes in `autograd/utils.cpp` to detect if we have enabled the profiler and are sending an RPC, if so, uses the above new message types
- Changes in request_callback to parse and turn on the profiler in a thread-local fashion
- Serialization and deserialization of profiling `Events`, and support to add the remote events to the thread-local profiler
- Introduction of the concept of `node_id`, which as discussed with ilia-cher , will be used along with the `Event`s handle attribute to distinguish between events. When there are events from different nodes, this node information is rendered in the profile output (e.g. when printing tables), otherwise, it is not, since it is irrelevant.
- Some changes to profiler.cpp to add useful helper methods/guards
- toHere() is now profiled for RRefs
- Unittests
ghstack-source-id: 106134626
Test Plan: Added unittests, existing profiler unittests.
Differential Revision: D19510010
fbshipit-source-id: 044347af992f19a9e3b357c9567f6fc73e988157
Summary:
Currently, whether `AccumulateGrad` [steals](67cb018462/torch/csrc/autograd/functions/accumulate_grad.h (L42)) or [clones](67cb018462/torch/csrc/autograd/functions/accumulate_grad.h (L80)) an incoming gradient, the gradient ends up rowmajor contiguous, regardless of its param's layout. If the param's layout is channels last, or otherwise not rowmajor contigous, later kernels that apply gradients to params are forced into an uncoalesced memory access pattern for either the param or the gradient. This may not sound like a big deal but for any binary op on large tensors it's a >3X increase in gmem traffic => 3X slowdown.
The present PR changes `AccumulateGrad` to prefer, where possible, stashing gradients that match their params' layouts (["Gradient Layout Contract"](https://github.com/pytorch/pytorch/pull/34904/files#diff-ef1a56d24f66b280dcdb401502d6a796R29-R38)).
Allowing `AccumulateGrad` to stash non-rowmajor-contiguous grads means DDP allreduces and DP reduces must allow non-rowmajor-contiguous grads. This PR extends DDP and DP to allow gradients with non-rowmajor-contiguous strides as long as their layout is nonoverlapping and dense.
For good measure, I include changes that allow all five nccl primitives (allreduce, reduce, broadcast, allgather, reducescatter) to act on non-rowmajor-contiguous tensors (again as long as each input's layout is nonoverlapping and dense, and as long as all tensors participating in a given collective have the same layout). The primitive comm changes aren't necessary to enable the DDP changes, but I wasn't sure this would end up true until I had written both sets of changes. I think primitive comm enablement is reasonable to keep in the PR, especially since the code for it is simple.
Channels last params will be a major beneficiary of this PR, but I don't see it as channels-last-specific fix. The spirit is layout matching in general:
- Grads should be stashed with memory layouts matching their params.
- Src and dst tensors on opposite ends of collectives should have matching dense layouts.
This PR also updates autograd docs to describe potential BC-breaking changes below.
## BC notes
ngimel albanD gchanan
#### BC-breaking
In the common case where the user lets AccumulateGrad decide grad layouts, strides for grads of dense but non-rowmajor-contiguous params will change. Any user code that was accustomed to `view(-1)`ing these grads will break.
Also, the circumstances under which a grad can be stolen directly from the backward function that created it, as opposed to deep-copied by AccumulateGrad, have changed. In most cases we expect silent performance improvement, because we expect channels-last-aware backward kernels will create channels last gradients for channels last params. Now those can be stolen, whereas before this PR they were cloned and made rowmajor contiguous. IMO this is a mild BC breakage. Param backward hooks still see grads come in with whatever format the backward kernel gave them. The only BC breakage potential I see is if user code relies somehow on a grad in a hook having or not having the same deep memory as the eventual `param.grad`. Any such users hopefully know they're off the edge of the map and understand how to update their expectations.
#### BC escape hatches
At alband's recommendation, this PR's changes to AccumulateGrad do not alter the pre-PR code's decisions about whether grad is accumulated in or out of place. Accumulations of new grads onto an existing `.grad` attribute were (usually) in-place before this PR and remain in-place after this PR, keeping the existing `.grad`'s layout. After this PR, if the user wants to force accumulation into a grad with a particular layout, they can preset `param.grad` to a zeroed tensor with the desired strides or call `grad.contiguous(desired format)`. This likely won't be as performant as letting AccumulateGrad establish grad layouts by cloning or stealing grads with contract-compliant strides, but at least users have a control point.
One limitation (present before this PR and unchanged by this PR): Presetting `param.grad` does not ensure in-place accumulation all the time. For example, if `create_graph=True`, or if incoming `new_grad` is dense and existing `variable_grad` is sparse, accumulation occurs out of place, and the out-of-place result may not match the existing grad's strides.
----------------------------
I also noticed some potential DDP improvements that I considered out of scope but want to mention for visibility:
1. make sure Reducer's ops sync with AccumulateGrad streams
2. ~to reduce CPU overhead and incur fewer kernel launches, lazily create flat `contents` tensors by a single `cat` kernel only when a bucket is full, instead of `copy_`ing grads into `contents` individually as soon as they are received.~ PR includes a [minor change](https://github.com/pytorch/pytorch/pull/34904/files#diff-c269190a925a4b0df49eda8a8f6c5bd3R312-R315) to divide grads while copying them into flat buffers, instead of copying them in, then dividing separately. Without cat+div fusion, div-while-copying is the best we can do.
3. https://github.com/pytorch/pytorch/issues/38942
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34904
Differential Revision: D20496044
Pulled By: albanD
fbshipit-source-id: 248d680f4b1bf77b0a986451844ec6e254469217
Summary:
Adds the ability for all backward functions to accept undefined output gradient arguments. An undefined gradient is a Tensor that was created by the argumentless constructor `at::Tensor()`, where `tensor.defined() == false`.
Also adds new autograd nodes, UndefinedGrad and UndefinedGradBackward, that can be used from within Python code to inject undefined gradients into a backward function. A new test case is added to the backward function unit tests to use the UndefinedGrad node to ensure that undefined gradients do not break any backward functions.
Closes https://github.com/pytorch/pytorch/issues/33138
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39400
Differential Revision: D21936588
Pulled By: albanD
fbshipit-source-id: eccc5f55c77babe6dadcea4249d0c68a3c64e85d
Summary:
# What's this
Just a small bug fix related to typing stubs.
I haven't open an issue. I will do so if I must open it, but this PR is very small (only 6 lines diff).
## What I encountered
pytorch 1.5.0 with mypy 0.770 behaves odd. The code is following:
```python
import torch
def f() -> int: # Mypy says: `error: Missing return statement`
with torch.no_grad():
return 1
```
No mypy error is expected, but actually mypy 0.770 warns about `Missing return statement`.
## This is because
`mypy >= 0.730` with `--warn-unreachable` says it's unreachable because `torch.no_grad()` may "swallows" the error in the return statement.
http://mypy-lang.blogspot.com/2019/09/mypy-730-released.html
Here is a small "swallowing" example:
```python
from typing import Generator
from contextlib import contextmanager
contextmanager
def swallow_zerodiv() -> Generator[None, None, None]:
try:
yield None
except ZeroDivisionError:
pass
finally:
pass
def div(a: int, b: int) -> float: # This function seems `(int, int) -> float` but actually `(int, int) -> Optional[float]` because ` return a / b` may be swallowed
with swallow_zerodiv():
return a / b
if __name__ == '__main__':
result = div(1, 0)
print(result, type(result)) # None <class 'NoneType'>
```
To supress this behavior, one can tell mypy not to swallow any exceptions, with returning `Literal[False]` or `None` in `__exit__` method of the context manager.
# What I did
Return `None` instead of `bool` to tell mypy that "I never swallow your exception".
I chose `None` because I cannot interpret `Literal[False]` without typing_extensions in `python <=3.7`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39324
Differential Revision: D21833651
Pulled By: albanD
fbshipit-source-id: d5cad2e5e19068bd68dc773e997bf13f7e60f4de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38847
See motivation and design in https://github.com/pytorch/pytorch/issues/38845.
Close https://github.com/pytorch/pytorch/issues/38845.
Changes,
- Add pre-request and post-response hooks to RPC "request_callback_impl.cpp". For a thread that executes RPC handler, check if the server-side global profiling is on. If it's on, enable profiling on this thread and after response, merge the thread-local profiling result into the global profiling state.
- Add context-style Python API to parse the profiling Events into ranges represented by FunctionEvent.
- Add data-structures to work as global profiling state that support nesting and container for consolidating results from multiple threads.
Test,
- Add a test that uses nested profiling range and inspect the profiling events.
ghstack-source-id: 104991517
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_server_process_global_profiler
Differential Revision: D5665992
fbshipit-source-id: 07f3bef5efd33d1214ef3404284c3803f5deca26
Summary:
These warning's goal is to show the user where to be careful in their code. So make them point to the user's code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39143
Differential Revision: D21764201
Pulled By: albanD
fbshipit-source-id: f1369d1b0e71d93af892ad3b7b1b3030e6699c59
Summary:
Fix https://github.com/pytorch/pytorch/issues/37500
I messed up with the old PR https://github.com/pytorch/pytorch/pull/37755 during rebasing and thus opened this one.
- Add call to `populate_cpu_children` for `__str__` to make sure that the printed result is correctly populated.
- Add test `test_profiler_aggregation_table`
- Fix a minor typo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37816
Reviewed By: ilia-cher
Differential Revision: D21627502
Pulled By: ngimel
fbshipit-source-id: 9c908986b6a979ff08c2ad7e6f4afac1f5fbeebb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38352
Fixes the RPC profiling by using the `then()` API added in https://github.com/pytorch/pytorch/pull/37311. Instead of adding a regular callback, we return a new future that completes when the profiling callback is finished. This is transparent to the user as the future still completes with the value of the original future (i.e. the RPC's return value)
To make this work for RRef, we add a `_set_profiling_future` to set the profiling future, and `_get_profiling_future` to retrieve this future and wait on it in the tests.
Re-enabled profiling tests and stress tested them 1000 times to verify the fix
ghstack-source-id: 104086114
Test Plan: Re-enabled profiling tests
Differential Revision: D21506940
fbshipit-source-id: 35cde22f0551c825c9bc98ddc24cca412878a63a
Summary:
Hi, I found the validation that is unreachable in `gradcheck` function :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37915
Differential Revision: D21551661
Pulled By: albanD
fbshipit-source-id: 8acadcc09cd2afb539061eda0ca5e98860e321eb
Summary:
Reland of https://github.com/pytorch/pytorch/issues/38140. It got reverted since it broke slow tests which were only run on master branch(thanks mruberry !). Enabling all CI tests in this PR to make sure they pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38288
Reviewed By: mruberry
Differential Revision: D21524923
Pulled By: ailzhang
fbshipit-source-id: 3a9ecc7461781066499c677249112434b08d2783
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38255
Now that the futures are consolidated after
https://github.com/pytorch/pytorch/pull/35154, there is no
`torch.distributed.rpc.Future` and we do not need a special path. All futures
can now be profiled through the use of the jit operator defined in
record_function_ops.cpp
As a result, we also get rid of the record_function_ops.h file.
RPC profiling tests are currently disabled, although I re-enabled them locally
to ensure that they still work with this change.
ghstack-source-id: 103869855
Test Plan: CI
Differential Revision: D21506091
fbshipit-source-id: ad68341c9f2eab2dadc72fe6a6c59b05693434f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38080
Originally, my plan was to just delete the torch.autograd stub, but
this triggered a bunch of downstream errors relating to non-existent
to _C modules, and so instead of ignoring those files, I decided to
add a minimal _C type stubs, where it was easy (cases which were
codegened I ignored).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21487841
Pulled By: ezyang
fbshipit-source-id: cfcc467ff1c146d242cb9ff33a46ba26b33b8213
Summary:
I'm mostly done with cleaning up test/ folder. There're a bunch of remaining callsites but they're "valid" in testing `type()` functionalities. We cannot remove them until it's fully deprecated.
Next PR would mainly focus on move some callsites to an internal API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38140
Differential Revision: D21483808
Pulled By: ailzhang
fbshipit-source-id: 12f5de6151bae59374cfa0372e827651de7e1c0f
Summary:
`is_tensor` doesn't really have a reason to exist anymore (other than
backwards compatibility) and is worse for typechecking with mypy (see
gh-32824). Given that it may not be obvious what the fix is once mypy
gives an error, make the change in a number of places at once, and add
a note on this to the `is_tensor` docstring.
Recommending an isinstance check instead has been done for quite a
while, e.g. https://github.com/pytorch/pytorch/pull/7769#discussion_r190458971
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38062
Differential Revision: D21470963
Pulled By: ezyang
fbshipit-source-id: 98dd60d32ca0650abd2de21910b541d32b0eea41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36291
Move profiler state to be a thread local property,
reuse existing thread local propagation mechanism to ensure
correct profiling of async tasks. This also makes
push/pop callback thread safe and easier to use in e.g.
distributed profilier
Test Plan:
USE_BLAS=MKL USE_MKLDNN=0 USE_CUDA=0 python setup.py develop install
./build/bin/test_jit
./build/bin/test_jit
python test/test_autograd.py
python test/test_jit.py
Differential Revision: D20938501
Pulled By: ilia-cher
fbshipit-source-id: c0c6c3eddcfea8fc7c14229534b7246a0ad25845
Summary:
xref gh-32838, gh-34032
This is a major refactor of parts of the documentation to split it up using sphinx's `autosummary` feature which will build out `autofuction` and `autoclass` stub files and link to them. The end result is that the top module pages like torch.nn.rst and torch.rst are now more like table-of-contents to the actual single-class or single-function documentations pages.
Along the way, I modified many of the docstrings to eliminate sphinx warnings when building. I think the only thing I changed from a non-documentation perspective is to add names to `__all__` when adding them to `globals()` in `torch.__init__.py`
I do not know the CI system: are the documentation build artifacts available after the build, so reviewers can preview before merging?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37419
Differential Revision: D21337640
Pulled By: ezyang
fbshipit-source-id: d4ad198780c3ae7a96a9f22651e00ff2d31a0c0f
Summary:
This PR fixes a couple of syntax errors in `torch/` that prevent MyPy from running, fixes simple type annotation errors (e.g. missing `from typing import List, Tuple, Optional`), and adds granular ignores for errors in particular modules as well as for missing typing in third party packages.
As a result, running `mypy` in the root dir of the repo now runs on:
- `torch/`
- `aten/src/ATen/function_wrapper.py` (the only file already covered in CI)
In CI this runs on GitHub Actions, job Lint, sub-job "quick-checks", task "MyPy typecheck". It should give (right now): `Success: no issues found in 329 source files`.
Here are the details of the original 855 errors when running `mypy torch` on current master (after fixing the couple of syntax errors that prevent `mypy` from running through):
<details>
```
torch/utils/tensorboard/_proto_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_proto_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_proto_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/backcompat/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/for_onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch.for_onnx.onnx'
torch/cuda/nvtx.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/utils/show_pickle.py:59: error: Name 'pickle._Unpickler' is not defined
torch/utils/show_pickle.py:113: error: "Type[PrettyPrinter]" has no attribute "_dispatch"
torch/utils/tensorboard/_onnx_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.graph_pb2'
torch/utils/tensorboard/_onnx_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_onnx_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.versions_pb2'
torch/utils/tensorboard/_onnx_graph.py:4: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_onnx_graph.py:5: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/tensorboard/_onnx_graph.py:9: error: Cannot find implementation or library stub for module named 'onnx'
torch/contrib/_tensorboard_vis.py:10: error: Cannot find implementation or library stub for module named 'tensorflow.core.util'
torch/contrib/_tensorboard_vis.py:11: error: Cannot find implementation or library stub for module named 'tensorflow.core.framework'
torch/contrib/_tensorboard_vis.py:12: error: Cannot find implementation or library stub for module named 'tensorflow.python.summary.writer.writer'
torch/utils/hipify/hipify_python.py:43: error: Need type annotation for 'CAFFE2_TEMPLATE_MAP' (hint: "CAFFE2_TEMPLATE_MAP: Dict[<type>, <type>] = ...")
torch/utils/hipify/hipify_python.py:636: error: "object" has no attribute "items"
torch/nn/_reduction.py:27: error: Name 'Optional' is not defined
torch/nn/_reduction.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/_reduction.py:47: error: Name 'Optional' is not defined
torch/nn/_reduction.py:47: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib.pyplot': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends.backend_agg': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends': found module but no type hints or library stubs
torch/nn/modules/utils.py:27: error: Name 'List' is not defined
torch/nn/modules/utils.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
caffe2/proto/caffe2_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/caffe2_pb2.py:25: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:31: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:35: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:39: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:47: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:51: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:55: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:59: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:63: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:67: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:71: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:75: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:108: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:112: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:124: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:134: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:138: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:142: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:146: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:150: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:154: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:158: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:162: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:166: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:170: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:174: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:194: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:200: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:204: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:208: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:212: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:224: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:230: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:238: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:242: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:246: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:250: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:267: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:288: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:295: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:302: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:327: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:334: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:341: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:364: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:371: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:378: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:385: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:392: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:399: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:406: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:413: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:420: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:448: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:455: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:462: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:488: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:495: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:502: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:509: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:516: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:523: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:530: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:537: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:544: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:551: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:558: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:565: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:572: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:596: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:603: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:627: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:634: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:641: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:648: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:655: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:662: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:686: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:693: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:717: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:724: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:731: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:738: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:763: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:770: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:777: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:784: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:808: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:815: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:822: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:829: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:836: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:843: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:850: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:857: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:864: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:871: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:878: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:885: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:892: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:916: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:923: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:930: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:937: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:944: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:951: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:958: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:982: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:989: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:996: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1003: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1010: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1017: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1024: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1031: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1038: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1045: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1052: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1059: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1066: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1090: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1097: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1104: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1128: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1135: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1142: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1166: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1173: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1180: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1187: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1194: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1218: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1225: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1232: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1239: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1246: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1253: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1260: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1267: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1305: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1312: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1319: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1326: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1333: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1340: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1347: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1354: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1361: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1368: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1375: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1382: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1389: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1396: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1420: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1465: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1472: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1479: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1486: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1493: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1500: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1507: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1514: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1538: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1545: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1552: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1559: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1566: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1667: error: "GeneratedProtocolMessageType" has no attribute "Segment"
torch/multiprocessing/queue.py:4: error: No library stub file for standard library module 'multiprocessing.reduction'
caffe2/proto/torch_pb2.py:18: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/torch_pb2.py:27: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/torch_pb2.py:33: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/torch_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:81: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:109: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:116: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:123: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:137: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:144: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:151: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:175: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:189: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:196: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:220: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:227: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:241: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:265: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:272: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:279: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:286: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:293: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:300: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:307: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:314: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:321: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:328: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:335: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:342: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:366: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:373: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:397: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:404: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:411: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:418: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:425: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:432: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/metanet_pb2.py:29: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:36: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:64: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:126: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:133: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:140: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:164: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:171: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:202: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:209: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:216: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:240: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:247: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:261: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:268: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:275: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:282: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:289: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:296: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/__init__.py:13: error: Skipping analyzing 'caffe2.caffe2.fb.session.proto': found module but no type hints or library stubs
torch/multiprocessing/pool.py:3: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/pool.py:3: note: (Stub files are from https://github.com/python/typeshed)
caffe2/python/scope.py:10: error: Skipping analyzing 'past.builtins': found module but no type hints or library stubs
caffe2/python/__init__.py:7: error: Module has no attribute "CPU"
caffe2/python/__init__.py:8: error: Module has no attribute "CUDA"
caffe2/python/__init__.py:9: error: Module has no attribute "MKLDNN"
caffe2/python/__init__.py:10: error: Module has no attribute "OPENGL"
caffe2/python/__init__.py:11: error: Module has no attribute "OPENCL"
caffe2/python/__init__.py:12: error: Module has no attribute "IDEEP"
caffe2/python/__init__.py:13: error: Module has no attribute "HIP"
caffe2/python/__init__.py:14: error: Module has no attribute "COMPILE_TIME_MAX_DEVICE_TYPES"; maybe "PROTO_COMPILE_TIME_MAX_DEVICE_TYPES"?
caffe2/python/__init__.py:15: error: Module has no attribute "ONLY_FOR_TEST"; maybe "PROTO_ONLY_FOR_TEST"?
caffe2/python/__init__.py:34: error: Item "_Loader" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:34: error: Item "None" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:35: error: Module has no attribute "cuda"
caffe2/python/__init__.py:37: error: Module has no attribute "cuda"
caffe2/python/__init__.py:49: error: Module has no attribute "add_dll_directory"
torch/random.py:4: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_classes.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/hub.py:21: error: Skipping analyzing 'tqdm.auto': found module but no type hints or library stubs
torch/hub.py:24: error: Skipping analyzing 'tqdm': found module but no type hints or library stubs
torch/hub.py:27: error: Name 'tqdm' already defined (possibly by an import)
torch/_tensor_str.py:164: error: Not all arguments converted during string formatting
torch/_ops.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_linalg_utils.py:26: error: Name 'Optional' is not defined
torch/_linalg_utils.py:26: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:26: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Optional' is not defined
torch/_linalg_utils.py:63: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Optional' is not defined
torch/_linalg_utils.py:70: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Optional' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:88: error: Name 'Tuple' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_jit_internal.py:17: error: Need type annotation for 'boolean_dispatched'
torch/_jit_internal.py:474: error: Need type annotation for '_overloaded_fns' (hint: "_overloaded_fns: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:512: error: Need type annotation for '_overloaded_methods' (hint: "_overloaded_methods: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:648: error: Incompatible types in assignment (expression has type "FinalCls", variable has type "_SpecialForm")
torch/sparse/__init__.py:11: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Optional' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/sparse/__init__.py:71: error: Name 'Tuple' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/nn/init.py:109: error: Name 'Tensor' is not defined
torch/nn/init.py:126: error: Name 'Tensor' is not defined
torch/nn/init.py:142: error: Name 'Tensor' is not defined
torch/nn/init.py:165: error: Name 'Tensor' is not defined
torch/nn/init.py:180: error: Name 'Tensor' is not defined
torch/nn/init.py:194: error: Name 'Tensor' is not defined
torch/nn/init.py:287: error: Name 'Tensor' is not defined
torch/nn/init.py:315: error: Name 'Tensor' is not defined
torch/multiprocessing/reductions.py:8: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/reductions.py:9: error: No library stub file for standard library module 'multiprocessing.reduction'
torch/multiprocessing/reductions.py:17: error: No library stub file for standard library module 'multiprocessing.resource_sharer'
torch/jit/_builtins.py:72: error: Module has no attribute "_no_grad_embedding_renorm_"
torch/jit/_builtins.py:80: error: Module has no attribute "stft"
torch/jit/_builtins.py:81: error: Module has no attribute "cdist"
torch/jit/_builtins.py:82: error: Module has no attribute "norm"
torch/jit/_builtins.py:83: error: Module has no attribute "nuclear_norm"
torch/jit/_builtins.py:84: error: Module has no attribute "frobenius_norm"
torch/backends/cudnn/__init__.py:8: error: Cannot find implementation or library stub for module named 'torch._C'
torch/backends/cudnn/__init__.py:86: error: Need type annotation for '_handles' (hint: "_handles: Dict[<type>, <type>] = ...")
torch/autograd/profiler.py:13: error: Name 'ContextDecorator' already defined (possibly by an import)
torch/autograd/function.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/autograd/function.py:2: note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports
torch/autograd/function.py:109: error: Unsupported dynamic base class "with_metaclass"
torch/serialization.py:609: error: "Callable[[Any], Any]" has no attribute "cache"
torch/_lowrank.py:11: error: Name 'Tensor' is not defined
torch/_lowrank.py:13: error: Name 'Optional' is not defined
torch/_lowrank.py:13: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Optional' is not defined
torch/_lowrank.py:14: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Optional' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:82: error: Name 'Tuple' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:130: error: Name 'Tensor' is not defined
torch/_lowrank.py:130: error: Name 'Optional' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:130: error: Name 'Tuple' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:167: error: Name 'Tensor' is not defined
torch/_lowrank.py:167: error: Name 'Optional' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:167: error: Name 'Tuple' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:45: error: Variable "torch.quantization.observer.ABC" is not valid as a type
torch/quantization/observer.py:45: note: See https://mypy.readthedocs.io/en/latest/common_issues.html#variables-vs-type-aliases
torch/quantization/observer.py:45: error: Invalid base class "ABC"
torch/quantization/observer.py:127: error: Name 'Tensor' is not defined
torch/quantization/observer.py:127: error: Name 'Tuple' is not defined
torch/quantization/observer.py:127: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:172: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:172: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:192: error: Name 'Tensor' is not defined
torch/quantization/observer.py:192: error: Name 'Tuple' is not defined
torch/quantization/observer.py:192: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:233: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:233: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:534: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tuple' is not defined
torch/quantization/observer.py:885: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:894: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:894: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:899: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:902: error: Name 'Tensor' is not defined
torch/quantization/observer.py:925: error: Name 'Tensor' is not defined
torch/quantization/observer.py:928: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:929: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:946: error: Argument "min" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:946: error: Argument "max" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:1056: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:1058: error: Module has no attribute "per_channel_symmetric"
torch/nn/quantized/functional.py:76: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:76: error: Name 'BroadcastingList2' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:259: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:289: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:290: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:308: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:326: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:356: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:371: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:400: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:430: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:448: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/linear.py:26: error: Module has no attribute "ops"
torch/nn/quantized/modules/linear.py:28: error: Module has no attribute "ops"
torch/nn/quantized/modules/functional_modules.py:40: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:47: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:54: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:61: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:68: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:75: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:140: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:146: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:151: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:157: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:162: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:168: error: Name 'Tensor' is not defined
torch/multiprocessing/spawn.py:9: error: Module 'torch.multiprocessing' has no attribute '_prctl_pr_set_pdeathsig'
torch/multiprocessing/__init__.py:28: error: Module has no attribute "__all__"
torch/jit/frontend.py:9: error: Cannot find implementation or library stub for module named 'torch._C._jit_tree_views'
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList2'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList3'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:9: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributions/distribution.py:16: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/distribution.py:74: error: Name 'arg_constraints' already defined on line 16
torch/distributions/distribution.py:84: error: Name 'support' already defined on line 15
torch/functional.py:114: error: Name 'Tuple' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:114: error: Name 'Optional' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:189: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:200: error: Argument 1 to "_indices_product" has incompatible type "Tuple[int, ...]"; expected "List[int]"
torch/functional.py:204: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:204: note: Possible overload variants:
torch/functional.py:204: note: def __setitem__(self, int, int) -> None
torch/functional.py:204: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:204: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:204: note: def __getitem__(self, int) -> int
torch/functional.py:204: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:207: error: "Tensor" has no attribute "copy_"
torch/functional.py:212: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:212: note: Possible overload variants:
torch/functional.py:212: note: def __setitem__(self, int, int) -> None
torch/functional.py:212: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:212: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:212: note: def __getitem__(self, int) -> int
torch/functional.py:212: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:215: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:334: error: Name 'Optional' is not defined
torch/functional.py:334: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:429: error: Argument 2 to "pad" has incompatible type "Tuple[int, int]"; expected "List[int]"
torch/functional.py:431: error: Module has no attribute "stft"
torch/functional.py:766: error: Module has no attribute "cdist"
torch/functional.py:768: error: Module has no attribute "cdist"
torch/functional.py:770: error: Module has no attribute "cdist"
torch/functional.py:775: error: Name 'Optional' is not defined
torch/functional.py:775: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'Optional' is not defined
torch/functional.py:780: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'number' is not defined
torch/functional.py:780: error: Name 'norm' already defined on line 775
torch/functional.py:785: error: Name 'Optional' is not defined
torch/functional.py:785: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:785: error: Name 'number' is not defined
torch/functional.py:785: error: Name 'norm' already defined on line 775
torch/functional.py:790: error: Name 'Optional' is not defined
torch/functional.py:790: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:790: error: Name 'norm' already defined on line 775
torch/functional.py:795: error: Name 'norm' already defined on line 775
torch/functional.py:960: error: Name 'Any' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Any")
torch/functional.py:960: error: Name 'Tuple' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1036: error: Argument 1 to "len" has incompatible type "int"; expected "Sized"
torch/functional.py:1041: error: Name 'Optional' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1041: error: Name 'Tuple' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1056: error: Name 'Optional' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1056: error: Name 'Tuple' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/distributions/von_mises.py:87: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/negative_binomial.py:25: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/multivariate_normal.py:116: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/laplace.py:23: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/independent.py:34: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/cauchy.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/poisson.py:28: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/one_hot_categorical.py:32: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/normal.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/lowrank_multivariate_normal.py:79: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/gamma.py:30: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/exponential.py:23: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/fishersnedecor.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/dirichlet.py:44: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/nn/quantized/dynamic/modules/rnn.py:230: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:232: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:236: error: Incompatible return value type (got "Tuple[Any, Tensor, Any]", expected "Tuple[int, int, int]")
torch/nn/quantized/dynamic/modules/rnn.py:351: error: Incompatible types in assignment (expression has type "Type[LSTM]", base class "RNNBase" defined the type as "Type[RNNBase]")
torch/nn/quantized/dynamic/modules/rnn.py:381: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:385: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:414: error: Argument 1 to "forward_impl" of "LSTM" has incompatible type "PackedSequence"; expected "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:416: error: Incompatible types in assignment (expression has type "PackedSequence", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:418: error: Incompatible return value type (got "Tuple[Tensor, Tuple[Tensor, Tensor]]", expected "Tuple[PackedSequence, Tuple[Tensor, Tensor]]")
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Argument 1 of "permute_hidden" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Return type "Tuple[Tensor, Tensor]" of "permute_hidden" incompatible with return type "Tensor" in supertype "RNNBase"
torch/nn/quantized/dynamic/modules/rnn.py:426: error: Argument 2 of "check_forward_args" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/intrinsic/qat/modules/conv_fused.py:232: error: Incompatible types in assignment (expression has type "Type[ConvBnReLU2d]", base class "ConvBn2d" defined the type as "Type[ConvBn2d]")
torch/distributions/beta.py:27: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/geometric.py:31: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/continuous_bernoulli.py:38: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/bernoulli.py:30: error: Incompatible types in assignment (expression has type "_Boolean", base class "Distribution" defined the type as "None")
torch/quantization/fake_quantize.py:126: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/fake_quantize.py:132: error: Module has no attribute "per_channel_symmetric"
torch/distributions/transformed_distribution.py:41: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/jit/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/jit/__init__.py:15: error: Module 'torch.utils' has no attribute 'set_module'
torch/jit/__init__.py:70: error: Name 'Attribute' already defined on line 68
torch/jit/__init__.py:213: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:215: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:1524: error: Unsupported dynamic base class "with_metaclass"
torch/jit/__init__.py:1869: error: Name 'ScriptModule' already defined on line 1524
torch/jit/__init__.py:1998: error: Need type annotation for '_jit_caching_layer'
torch/jit/__init__.py:1999: error: Need type annotation for '_jit_function_overload_caching'
torch/distributions/relaxed_categorical.py:34: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_categorical.py:108: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:31: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:114: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/logistic_normal.py:31: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/log_normal.py:26: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_normal.py:27: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_cauchy.py:28: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/gumbel.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/nn/quantized/modules/conv.py:18: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/quantized/modules/conv.py:209: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:209: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:214: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:321: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:321: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:323: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:447: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:447: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:449: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:513: error: Name 'nn.modules.conv._ConvTransposeNd' is not defined
torch/nn/quantized/modules/conv.py:525: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:525: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/conv.py:527: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:527: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/intrinsic/quantized/modules/conv_relu.py:8: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/intrinsic/quantized/modules/conv_relu.py:21: error: Incompatible types in assignment (expression has type "Type[ConvReLU2d]", base class "Conv2d" defined the type as "Type[Conv2d]")
torch/nn/intrinsic/quantized/modules/conv_relu.py:62: error: Incompatible types in assignment (expression has type "Type[ConvReLU3d]", base class "Conv3d" defined the type as "Type[Conv3d]")
torch/distributions/weibull.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/kl.py:35: error: Need type annotation for '_KL_MEMOIZE' (hint: "_KL_MEMOIZE: Dict[<type>, <type>] = ...")
torch/distributions/studentT.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/mixture_same_family.py:48: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/__init__.py:158: error: Name 'transforms' is not defined
torch/onnx/utils.py:21: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributed/rendezvous.py:4: error: Cannot find implementation or library stub for module named 'urlparse'
torch/distributed/rendezvous.py:4: error: Name 'urlparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:4: error: Name 'urlunparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'FileStore'
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'TCPStore'
torch/distributed/rendezvous.py:65: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceOptions'; maybe "ReduceOptions" or "AllreduceCoalescedOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceCoalescedOptions'; maybe "AllreduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllToAllOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'BroadcastOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'GatherOptions'; maybe "ScatterOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceOptions'; maybe "AllreduceOptions", "ReduceScatterOptions", or "ReduceOp"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceScatterOptions'; maybe "ScatterOptions" or "ReduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ScatterOptions'; maybe "ReduceScatterOptions" or
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36584
Reviewed By: seemethere, ailzhang
Differential Revision: D21155985
Pulled By: ezyang
fbshipit-source-id: f628d4293992576207167e7c417998fad15898d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35055
This is the first step to improving the way RPCs are profiled as suggested by Ilia. For now, since RPC can return two different types of futures, we have to implement two different code paths, one for the python eager mode future and one for the jit future.
This diff implements the python eager part. We have defined a method `_call_end_callbacks_on_future` that takes in a future and schedules a `RecordFunction` to be completed as a callback on the future.
Once https://github.com/pytorch/pytorch/pull/35039 lands, we can implement the JIT codepath by registering an operator that takes a `Future(t)` as well.
These code paths will be merged once the futures are merged.
ghstack-source-id: 102478180
Test Plan: Added unit tests
Differential Revision: D20452003
fbshipit-source-id: 1acdcb073bd1f63d6fb2e78277ac0be00fd6671d
Summary:
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
export_chrome_trace generating invalid JSON. This only came up when the
profiler is run with use_cuda=True from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
ghstack-source-id: 99508836
Test Plan: Added a unit test.
Differential Revision: D20237040
fbshipit-source-id: 510befbdf4ec39632ac56544afcddee6c8cc3aca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33987
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
`export_chrome_trace` generating invalid JSON. This only came up when the
profiler is run with `use_cuda=True` from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
Test Plan: Add UT to validate JSON.
Differential Revision: D20171428
fbshipit-source-id: ec135a154ce33f62b78d98468174dce4cf01fedf
Summary:
I've been using pytorch with type hintings, and I found errors that can be easily fixed. So I'm creating this PR to fix type bugs.
I expected below code should be type-checked without any errors.
```python
import torch
from torch.nn import Linear
from torch.autograd import Variable
from torch.optim import AdamW
from torch.utils import hooks
# nn.Module should have training attribute
module = Linear(10, 20)
module.training
# torch should have dtype bfloat16
tensor2 = torch.tensor([1,2,3], dtype=torch.bfloat16)
# torch.Tensor.cuda should accept int or str value
torch.randn(5).cuda(1)
torch.tensor(5).cuda('cuda:0')
# optimizer should have default attribute
module = Linear(10, 20)
print(AdamW(module.weight).default)
# torch.Tensor should have these boolean attributes
torch.tensor([1]).is_sparse
torch.tensor([1]).is_quantized
torch.tensor([1]).is_mkldnn
# Size class should tuple of int
a, b = torch.tensor([[1,2,3]]).size()
# check modules can be accessed
torch.nn.parallel
torch.autograd.profiler
torch.multiprocessing
torch.sparse
torch.onnx
torch.jit
torch.hub
torch.random
torch.distributions
torch.quantization
torch.__config__
torch.__future__
torch.ops
torch.classes
# Variable class's constructor should return Tensor
def fn_to_test_variable(t: torch.Tensor):
return None
v = Variable(torch.tensor(1))
fn_to_test_variable(v)
# check RemovableHandle attributes can be accessed
handle = hooks.RemovableHandle({})
handle.id
handle.next_id
# check torch function hints
torch.is_grad_enabled()
```
But current master branch raises errors. (I checked with pyright)
```
$ pyright test.py
Searching for source files
Found 1 source file
test.py
12:45 - error: 'bfloat16' is not a known member of module
15:21 - error: Argument of type 'Literal[1]' cannot be assigned to parameter 'device' of type 'Optional[device]'
'int' is incompatible with 'device'
Cannot assign to 'None'
16:22 - error: Argument of type 'Literal['cuda:0']' cannot be assigned to parameter 'device' of type 'Optional[device]'
'str' is incompatible with 'device'
Cannot assign to 'None'
23:19 - error: Cannot access member 'is_sparse' for type 'Tensor'
Member 'is_sparse' is unknown
24:19 - error: Cannot access member 'is_quantized' for type 'Tensor'
Member 'is_quantized' is unknown
25:19 - error: Cannot access member 'is_mkldnn' for type 'Tensor'
Member 'is_mkldnn' is unknown
32:7 - error: 'autograd' is not a known member of module
33:7 - error: 'multiprocessing' is not a known member of module
34:7 - error: 'sparse' is not a known member of module
35:7 - error: 'onnx' is not a known member of module
36:7 - error: 'jit' is not a known member of module
37:7 - error: 'hub' is not a known member of module
38:7 - error: 'random' is not a known member of module
39:7 - error: 'distributions' is not a known member of module
40:7 - error: 'quantization' is not a known member of module
41:7 - error: '__config__' is not a known member of module
42:7 - error: '__future__' is not a known member of module
44:7 - error: 'ops' is not a known member of module
45:7 - error: 'classes' is not a known member of module
60:7 - error: 'is_grad_enabled' is not a known member of module
20 errors, 0 warnings
Completed in 1.436sec
```
and below list is not checked as errors, but I think these are errors too.
* `nn.Module.training` is not boolean
* return type of `torch.Tensor.size()` is `Tuple[Unknown]`.
---
related issues.
https://github.com/pytorch/pytorch/issues/23731, https://github.com/pytorch/pytorch/issues/32824, https://github.com/pytorch/pytorch/issues/31753
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33762
Differential Revision: D20118884
Pulled By: albanD
fbshipit-source-id: 41557d66674a11b8e7503a48476d4cdd0f278eab
Summary:
Fix for https://github.com/pytorch/pytorch/issues/19420
So after actually writing a C++ JSON dumping class I figured that
a faster and cleaner way would be simply rewrite the Python without
the JSON module since the JSON that we need to output is so simple.
For now I decided to not touch the `parse_cpu_trace` function since
only changing `export_chrome_trace` shows a 4x speedup.
Here's the script I used for benchmarking:
``` python
import time
import torch
x = torch.ones(2, 2)
start = time.time()
with torch.autograd.profiler.profile() as prof:
for _ in range(10000):
x * x
for i in range(50):
prof.export_chrome_trace("trace.json")
stop = time.time()
print(stop-start)
```
master branch (using json dump) -> 8.07515025138855
new branch (without json dump) -> 2.0943689346313477
I checked the trace file generated in the [test](https://github.com/pytorch/pytorch/blob/master/test/test_autograd.py#L2659)
and it does work fine.
Please let me know what you think.
If you still insist on the C++ version I can send a new patch soon enough.
CC ezyang rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30724
Differential Revision: D19298955
Pulled By: ezyang
fbshipit-source-id: b0d7324ea5f90884ab8a00dd272f3aa3d9bc0427
Summary:
Closes https://github.com/pytorch/pytorch/issues/31497
This allows `torch.no_grad` and `torch.enable_grad` to be used as decorators for generator functions. In which case it disables/enables grad only inside the body of the generator and restores the context outside of the generator.
https://github.com/pytorch/pytorch/issues/31497 doesn't include a complete reproducer but the included test with `torch.is_grad_enabled` show this is working where it failed before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31792
Differential Revision: D19274971
Pulled By: albanD
fbshipit-source-id: fde6d3fd95d76c8d324ad02db577213a4b68ccbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31473
Mitigates #6313
A common use case for the autograd profiler is to use it to run over an
entire model, including dataloading. The following will crash:
- run autograd profiler in CUDA mode
- Use a multi-worker DataLoader (presumably with the 'fork' spawn
method)
- because the autograd profiler initializes CUDA and forking after CUDA is
initialized is bad.
This PR puts in a nice error message when this happens so that users
aren't too confused. The new error message looks like:
https://gist.github.com/zou3519/903f15c3e86bad4585b7e5ce14cc1b70
Test Plan:
- Tested locally.
- I didn't add a test case for this because it's hard to write a test
case that doesn't completely stop the rest of our test suite from
running.
Differential Revision: D19178080
Pulled By: zou3519
fbshipit-source-id: c632525ba1f7b168324f1aa55416e5250f56a086
Summary:
```python
record_function('my_func')
def f(x, y):
return x + y
with profile() as p:
f(1, 2)
print(prof.key_averages().table())
```
```
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
my_func 85.42% 86.796us 87.27% 88.670us 88.670us 1
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 101.606us
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30861
Differential Revision: D18857993
Pulled By: bddppq
fbshipit-source-id: eb6b8e2a8d4f3a7f8e5b4cb3da1ee3320acb1ae7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30892
Fixes all outstanding lints and actually installs a properly configured
flake8
Test Plan: Imported from OSS
Differential Revision: D18862825
Pulled By: suo
fbshipit-source-id: 08e9083338a7309272e17bb803feaa42e348aa85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30677
Currently you can only add FunctionEvents to FunctionEventAvg. This makes it so you can add multiple FunctionEventAvg objects together. This is useful for merging multiple profiles together such as when dealing with distributed training.
Test Plan:
added unit test
buck test //caffe2/test:autograd -- test_profiler
Reviewed By: bddppq
Differential Revision: D18785578
fbshipit-source-id: 567a441dec885db7b0bd8f6e0ac9a60b18092278
Summary:
Example
```python
import torch
x = torch.randn(1)
with torch.autograd.profiler.profile(use_cuda=False) as prof:
x + x
print(prof.key_averages().table(sort_by='cpu_time_total'))
```
Before:
```
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
add 100.00% 25.781ms 100.00% 25.781ms 25.781ms NaN 0.000us 0.000us 1
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 25.781ms
CUDA time total: 0.000us
```
After:
```
------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
------- --------------- --------------- --------------- --------------- --------------- ---------------
add 100.00% 25.037ms 100.00% 25.037ms 25.037ms 1
------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 25.037ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29666
Differential Revision: D18458828
Pulled By: bddppq
fbshipit-source-id: d96ef4cec8b1e85b77c211292a3099048882734d
Summary:
PR to compare shapes of `outputs` and `grad_outputs` in `torch.autograd.grad()`.
> grad_outputs should be a sequence of length matching output containing the pre-computed gradients w.r.t. each of the outputs.
resolve https://github.com/pytorch/pytorch/issues/17893
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25349
Differential Revision: D17119931
Pulled By: CamiWilliams
fbshipit-source-id: 86c9089e240ca0cea5f4ea8ec7bcff95f9d8cf53
Summary:
This PR is intended as a fix for https://github.com/pytorch/pytorch/issues/21644.
It allows the `with emit_nvtx` context manager to take an additional `record_shapes` argument. `record_shapes` is False by default, but if True, the nvtx ranges generated for each autograd op will append additional information about the sizes of Tensors received by that op.
The format of shape information is equivalent to what the CPU-side profiler spits out. For example,
```
M = torch.randn(2, 3)
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
with torch.cuda.profiler.profile():
with torch.autograd.profiler.emit_nvtx(record_shapes=True):
torch.addmm(M, mat1, mat2)
```
produces the following nvtx range label for addmm:

(cf the "Input Shapes" shown in 864cfbc216 (diff-115b6d48fa8c0ff33fa94b8fce8877b6))
I also took the opportunity to do some minor docstring cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21691
Differential Revision: D15816226
Pulled By: gchanan
fbshipit-source-id: b2b01ea10fea61a6409a32b41e85b6c8b4851bed
Summary:
gradcheck currently includes a determinism check (although only trying twice and seeing if results match).
This can lead to flaky tests, e.g. in #20971, but also #13818.
This adds nondet_tol for both gradcheck and gradgradcheck. It does not change / reenable any tests yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20980
Differential Revision: D15530129
Pulled By: soumith
fbshipit-source-id: 04d7f85b5b59cd62867820c74b064ba14f4fa7f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20281
This is how it looks like now:
```
<FunctionEventAvg key=mm self_cpu_time=11.404s cpu_time=2.895ms
cuda_time=0.000us input_shapes=[[26, 4096], [4096, 1024]]>
```
Before I forgot to update the repr for these when updated it for not
averaged events
Differential Revision: D15262862
fbshipit-source-id: a9e5b32c347b31118f98b4b5bf2bf46c1cc6d0d2
Summary:
This is useful when you would like to understand performance
bottlenecks of your model. One can use the shape analysis in order to
fit model to a roofline model of their hardware.
Please note that this feature can potentially skew profiling
results. Also timing for not nested events will become wrong. One
should only use timing for the bottom most events when shape analysis
is used. Also for the case where people don't need shapes, profiling
should not be affected. As in this case we don't collect shapes, which
is the default behavior and this diff doesn't change it.
One of the next steps
could be, for example, choosing best candidates for quantization. In
the scope of this diff I am just adding optional shapes collection
into the Even class. After that in python there is minor functionality
for providing groupping by shapes.
In the output tables shapes are being truncated but in groupping full
shape string is used as a key.
Here is an example output:
test_profiler_shapes (test_autograd.TestAutograd) ...
```
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
unsigned short 2.30% 305.031us 2.30% 305.031us 305.031us NaN 0.000us 0.000us 1 [[30, 20]]
addmm 69.40% 9.199ms 69.40% 9.199ms 9.199ms NaN 0.000us 0.000us 1 [[30], [128, 20], [20, 30], [], []]
unsigned short 0.98% 129.326us 0.98% 129.326us 129.326us NaN 0.000us 0.000us 1 [[40, 30]]
addmm 27.32% 3.621ms 27.32% 3.621ms 3.621ms NaN 0.000us 0.000us 1 [[40], [128, 30], [30, 40], [], []]
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 13.255ms
CUDA time total: 0.000us
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
unsigned short 2.30% 305.031us 2.30% 305.031us 305.031us NaN 0.000us 0.000us 1 [[30, 20]]
addmm 69.40% 9.199ms 69.40% 9.199ms 9.199ms NaN 0.000us 0.000us 1 [[30], [128, 20], [20, 30], [], []]
unsigned short 0.98% 129.326us 0.98% 129.326us 129.326us NaN 0.000us 0.000us 1 [[40, 30]]
addmm 27.32% 3.621ms 27.32% 3.621ms 3.621ms NaN 0.000us 0.000us 1 [[40], [128, 30], [30, 40], [], []]
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 13.255ms
CUDA time total: 0.000us
```
Also added this for older aggregation test:
```
test_profiler_aggregation_lstm (test_autograd.TestAutograd) ...
======================================================================================================================================================================================================
TEST
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
lstm 0.69% 4.606ms 5.30% 35.507ms 35.507ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.67% 4.521ms 5.27% 35.340ms 35.340ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.66% 4.399ms 5.02% 33.638ms 33.638ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.354ms 4.92% 32.958ms 32.958ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.351ms 4.96% 33.241ms 33.241ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.323ms 5.10% 34.163ms 34.163ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.304ms 4.92% 32.938ms 32.938ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.300ms 5.10% 34.172ms 34.172ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.292ms 5.05% 33.828ms 33.828ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.263ms 4.98% 33.357ms 33.357ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 670.120ms
CUDA time total: 0.000us
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
sigmoid 15.32% 102.647ms 15.32% 102.647ms 171.078us NaN 0.000us 0.000us 600 [[3, 20]]
mul 15.20% 101.854ms 15.20% 101.854ms 169.757us NaN 0.000us 0.000us 600 [[3, 20], [3, 20]]
lstm 12.74% 85.355ms 100.00% 670.120ms 33.506ms NaN 0.000us 0.000us 20 [[5, 3, 10]]
addmm 11.16% 74.808ms 11.16% 74.808ms 249.361us NaN 0.000us 0.000us 300 [[80], [3, 20], [20, 80], [], []]
tanh 9.89% 66.247ms 9.89% 66.247ms 165.617us NaN 0.000us 0.000us 400 [[3, 20]]
split 6.42% 43.019ms 6.42% 43.019ms 215.095us NaN 0.000us 0.000us 200 [[3, 80]]
add 5.67% 38.020ms 5.67% 38.020ms 190.101us NaN 0.000us 0.000us 200 [[3, 80], [3, 80], []]
add 4.81% 32.225ms 4.81% 32.225ms 161.124us NaN 0.000us 0.000us 200 [[3, 20], [3, 20], []]
addmm 3.79% 25.380ms 3.79% 25.380ms 253.796us NaN 0.000us 0.000us 100 [[80], [3, 10], [10, 80], [], []]
unsigned short 3.72% 24.925ms 3.72% 24.925ms 83.083us NaN 0.000us 0.000us 300 [[80, 20]]
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 670.120ms
CUDA time total: 0.000us
Total time based on python measurements: 691.366ms
CPU time measurement python side overhead: 3.17%
ok
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20035
Differential Revision: D15174987
Pulled By: salexspb
fbshipit-source-id: 9600c5d1d1a4c2cba08b320fed9da155d8284ab9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19378
Function profile events are typically nested. In this diff I
add parent child relationship to the intervals. This way we can
attribute self time easily. As a result, user printing a table from a
profiler trace gets self cpu time.
This diff doesn't try to address CUDA self time as CUDA kernels are
already getting special care in the profiler.
There are also some other minor improvements. Like reporting total CPU
time spent, reversed sorting, aggregated data after the table,
etc.
There is a new unit test added which tests more functionality than
previous profiler test
Reviewed By: zheng-xq
Differential Revision: D14988612
fbshipit-source-id: 2ee6f64f0a4d0b659c6b23c0510bf13aa46f07dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18092
Previously, tracing required all inputs to be either tensors,
or tuples of tensor. Now, we allow users to pass dicts as well.
Differential Revision: D14491795
fbshipit-source-id: 7a2df218e5d00f898d01fa5b9669f9d674280be3
Summary:
This is a minimalist PR to add MKL-DNN tensor per discussion from Github issue: https://github.com/pytorch/pytorch/issues/16038
Ops with MKL-DNN tensor will be supported in following-up PRs to speed up imperative path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17748
Reviewed By: dzhulgakov
Differential Revision: D14614640
Pulled By: bddppq
fbshipit-source-id: c58de98e244b0c63ae11e10d752a8e8ed920c533
Summary:
Added stubs for:
* The `device` module
* The `cuda` module
* Parts of the `optim` module
* Began adding stubs for the `autograd` module. I'll annotate more later but `no_grad` and friends are probably the most used exports from it so it seemed like a good place to start.
This would close#16996, although comments on that issue reference other missing stubs so maybe it's worth keeping open as an umbrella issue.
The big remaining missing package is `nn`.
Also added a `py.typed` file so mypy will pick up on the type stubs. That closes#17639.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18511
Differential Revision: D14715053
Pulled By: ezyang
fbshipit-source-id: 9e4882ac997063650e6ce47604b3eaf1232c61c9
Summary:
If none of the outputs require_grad, we don't actually check gradgrad, instead we will check that their numerical gradients are 0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18190
Differential Revision: D14563388
Pulled By: ifedan
fbshipit-source-id: a4eb94c9eb60f14dbe6986cd8cef1fe78a7bc839
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18507
ghimport-source-id: 1c3642befad2da78a7e5f39d6d58732b85c76267
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18507 Upgrade flake8-bugbear to master, fix the new lints.**
It turns out Facebobok is internally using the unreleased master
flake8-bugbear, so upgrading it grabs a few more lints that Phabricator
was complaining about but we didn't get in open source.
A few of the getattr sites that I fixed look very suspicious (they're
written as if Python were a lazy language), but I didn't look more
closely into the matter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14633682
fbshipit-source-id: fc3f97c87dca40bbda943a1d1061953490dbacf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18181
ghimport-source-id: 9c23551584a1a1b0b7ac246367f3a7ae1c50b315
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18184 Fix B903 lint: save memory for data classes with slots/namedtuple
* **#18181 Fix B902 lint error: invalid first argument.**
* #18178 Fix B006 lint errors: using mutable structure in default argument.
* #18177 Fix lstrip bug revealed by B005 lint
A variety of sins were committed:
- Some code was dead
- Some code was actually a staticmethod
- Some code just named it the wrong way
- Some code was purposely testing the omitted case
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14530876
fbshipit-source-id: 292a371d9a76ddc7bfcfd38b6f0da9165290a58e
Summary:
Partially fixes: https://github.com/pytorch/pytorch/issues/394
Implementation detail:
Codegen is modified to generate codes that looks like below:
```C++
static PyObject * THPVariable_svd(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"svd(Tensor input, bool some=True, bool compute_uv=True, *, TensorList[3] out=None)",
}, /*traceable=*/true);
ParsedArgs<6> parsed_args;
auto r = parser.parse(args, kwargs, parsed_args);
static PyStructSequence_Field fields0[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc0 = {
"torch.return_types.svd_out", nullptr,
fields0, 3
};
static PyTypeObject type0;
static bool namedtuple_type_initialized0 = false;
if (!namedtuple_type_initialized0) {
PyStructSequence_InitType(&type0, &desc0);
namedtuple_type_initialized0 = true;
}
static PyStructSequence_Field fields1[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc1 = {
"torch.return_types.svd", nullptr,
fields1, 3
};
static PyTypeObject type1;
static bool namedtuple_type_initialized1 = false;
if (!namedtuple_type_initialized1) {
PyStructSequence_InitType(&type1, &desc1);
namedtuple_type_initialized1 = true;
}
if (r.idx == 0) {
if (r.isNone(3)) {
return wrap(&type1, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2)));
} else {
auto results = r.tensorlist_n<3>(3);
return wrap(&type0, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2), results[0], results[1], results[2]));
}
}
Py_RETURN_NONE;
END_HANDLE_TH_ERRORS
}
```
Types are defined as static member of `THPVariable_${op_name}` functions, and initialized at the first time the function is called.
When parsing function prototypes in `native_functions.yaml`, the parser will set the specified name as `field_name` when see things like `-> (Tensor t1, ...)`. These field names will be the field names of namedtuple. The class of namedtuples will be named `torch.return_types.${op_name}`.
In some python 2, `PyStructSequence` is not a subtype of tuple, so we have to create some functions to check if an object is a tuple or namedtuple for compatibility issue.
Operators in `native_functions.yaml` are changed such that only `max` and `svd` are generated as namedtuple. Tests are added for these two operators to see if the return value works as expected. Docs for these two ops are also updated to explicitly mention the return value is a namedtuple. More ops will be added in later PRs.
There is some issue with Windows build of linker unable to resolve `PyStructSequence_UnnamedField`, and some workaround is added to deal with this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15429
Differential Revision: D13709678
Pulled By: ezyang
fbshipit-source-id: 23a511c9436977098afc49374e9a748b6e30bccf
Summary:
A friend of me is learning deep learning and pytorch, and he is confused by the following piece of code from the tutorial https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#gradients :
```python
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(gradients)
print(x.grad)
```
He don't know where the following line comes from:
```python
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
```
What are we computing? Why don't we compute "the gradient of `y` w.r.t `x`"?
In the tutorial, it only says
> You can do many crazy things with autograd!
Which does not explain anything. It seems to be hard for some beginners of deep learning to understand why do we ever do backwards with external gradient fed in and what is the meaning of doing so. So I modified the tutorial in https://github.com/pytorch/tutorials/pull/385
and the docstring correspondingly in this PR, explaining the Jacobian vector product. Please review this PR and https://github.com/pytorch/tutorials/pull/385 together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15197
Differential Revision: D13476513
Pulled By: soumith
fbshipit-source-id: bee62282e9ab72403247384e4063bcdf59d40c3c
Summary:
- allow gradcheck to take sparse tensor as input
- sparse output is not allowed yet at gradcheck
- add backward for `to_dense()` to get around sparse output
- calling gradcheck at test_sparse, so that we can use `_gen_sparse()` and also easily cover coalesced / uncoalesced test cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14596
Differential Revision: D13271904
Pulled By: weiyangfb
fbshipit-source-id: 5317484104404fd38058884c86e987546011dd86
Summary:
Before this patch, the JIT does not allow Module's forward to take
structured objects.
This patch allows cooperative objects to do so.
Cooperative means:
- It has a method self._jit_unwrap() that returns (a list/tuple of)
tensors. These are then used in _iter_tensors.
- It has a method self._jit_wrap(flattened_input) that takes
(a list/tuple?) the flattened_unput (potentially more than it needs)
and returns itself (updated) and the unconsumed flattened_inputs.
This is then used in the _unflatten mechanism.
This is all it takes to permit maskrcnn-benchmark to use
its structured BoxList/ImageList types and trace it without calling
the .forward directly.
I'll push a model working with this patch in
https://github.com/facebookresearch/maskrcnn-benchmark/pull/138
I must admit I haven't fully checked whether there are ONNX changes needed before it, too, can profit, but I would be hopeful that anything currently usable remains so.
fmassa zdevito
So the main downside that I'm aware of is that people will later want to use more elaborate mechanisms, but I think this could be done by just amending what wrap/unwrap are returning / consuming.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13961
Differential Revision: D13103927
Pulled By: soumith
fbshipit-source-id: 2cbc724cc4b53197388b662f75d9e601a495c087
Summary:
Now gradcheck properly accept a single Tensor as input. It was almost supported already but not completely.
Should fix the confusion from #13540
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13543
Differential Revision: D12918526
Pulled By: soumith
fbshipit-source-id: a5bad69af0aea48c146f58df2482cabf91e24a01
Summary:
- Fix broken sparse_coo_examples, update output
- Tensor(...) to tensor(...)
- Fix arguments to math.log to be floats
While the last might be debateable, mypy currently complains when passing an int to math.log. As it is not essential for our examples, let's be clean w.r.t. other people's expectations.
These popped up while checking examples in the context of #12500 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12707
Differential Revision: D10415256
Pulled By: SsnL
fbshipit-source-id: c907b576b02cb0f89d8f261173dbf4b3175b4b8d
Summary:
To illustrate the benefits of this commit, I'll use the time/iter I got from one of the JIT benchmarks on my machine.
| Run | Time |
|----------------------------------------------|-------------------------|
| No profiler | 45ms |
| With profiler | 56ms |
| Use `clock_gettime` instead of `std::chrono` | 48ms |
| Touch all pages on block allocation | 48ms (less jitter) |
| Use `const char*` instead of `std::string` | 47ms (even less jitter) |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11773
Differential Revision: D9886858
Pulled By: apaszke
fbshipit-source-id: 58f926f09e95df0b11ec687763a72b06b66991d0
Summary:
Often, we find ourselves looking at some long-running kernel or emit_nvtx range on an nvvp profile and trying to connect it to the offending line in a training script. If the op is in the forward pass that's easy: ops are enqueued explicitly from the Python side, so tracking it down with manual nvtx ranges supplemented by the built-in emit_nvtx ranges is straightforward. If the op is in the backward pass, it's much more difficult. From the Python side, all you can do is wrap loss.backward() in an nvtx range, and if you also use emit_nvtx, the automatic ranges provide only local information. Right now, the only consistent way to connect backward-pass kernels to their associated forward-pass lines of Python is to understand your script line by line, and know exactly where in the backward pass you are.
This PR augments the existing nvtx machinery to bridge the gap between forward and backward, allowing connection of backward-pass Function apply calls to the forward-pass operations that required/created those Functions.
The method is simple and surgical. During the forward pass, when running with emit_nvtx, the nvtx range for each function in VariableType is tagged with the current sequence number. During the backward pass, the nvtx range associated with each Function's operator() is tagged with that Function's stashed sequence number, which can be compared to "current sequence numbers" from the forward pass to locate the associated op.
Double-backward is not a problem. If a backward pass with create_graph = True is underway, the relationship between backward and double-backward is conceptually the same as the relationship between forward and backward: The functions in VariableType still spit out current-sequence-number-tagged ranges, the Function objects they create still stash those sequence numbers, and in the eventual double-backward execution, their operator() ranges are still tagged with the stashed numbers, which can be compared to "current sequence numbers" from the backward pass.
Minor caveats:
- The sequence number is thread-local, and many VariableType functions (specifically, those without a derivative explicitly defined in derivatives.yaml) don't create an associated function object (instead delegating that to sub-functions further down the call chain, perhaps called from within at::native functions that route back through VariableType by calling at::function_name). So the correspondence of stashed sequence numbers in Function operator() ranges with numbers in forward-pass ranges is not guaranteed to be 1 to 1. However, it's still a vast improvement over the current situation, and I don't think this issue should be a blocker.
- Feel free to litigate my use of stringstream in profiler.cpp. I did it because it was easy and clean. If that's too big a hammer, let's figure out something more lightweight.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10881
Differential Revision: D9833371
Pulled By: apaszke
fbshipit-source-id: 1844f2e697117880ef5e31394e36e801d1de6088
Summary:
Fixes#10851
Speeds up profiling results dramatically.
For the following script:
```
import torch
import time
ITER = 2000
x = torch.randn(1, 1, requires_grad=True)
with torch.autograd.profiler.profile() as prof:
y = x
for i in range(ITER):
y = 3 * y - 2 * y
y.backward()
start = time.time()
print("Done running. Preparing prof")
x = str(prof)
print("Done preparing prof results")
end = time.time()
print("Elapsed: {}".format(end - start))
```
I get 7s before / 0.13s after these changes.
cc apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10969
Differential Revision: D9556129
Pulled By: zou3519
fbshipit-source-id: 26b421686f8a42cdaace6382567d403e6385dc12
Summary:
Commits:
1. In extension doc, get rid of all references of `Variable` s (Closes#6947 )
+ also add minor improvements
+ also added a section with links to cpp extension :) goldsborough
+ removed mentions of `autograd.Function.requires_grad` as it's not used anywhere and hardcoded to `return_Py_True`.
2. Fix several sphinx warnings
3. Change `*` in equations in `module/conv.py` to `\times`
4. Fix docs for `Fold` and `Unfold`.
+ Added better shape check for `Fold` (it previously may give bogus result when there are not enough blocks). Added test for the checks.
5. Fix doc saying `trtrs` not available for CUDA (#9247 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9239
Reviewed By: soumith
Differential Revision: D8762492
Pulled By: SsnL
fbshipit-source-id: 13cd91128981a94493d5efdf250c40465f84346a
Summary:
cc vishwakftw
Also added a check if none of the input tensors in `gradcheck` have `requires_grad=True`.
Closes https://github.com/pytorch/pytorch/pull/9192
Differential Revision: D8739401
Pulled By: SsnL
fbshipit-source-id: 81bb3aa0b5c04eb209b137a4bd978e040e76cbcd
* make as_strided safer
* patching as_strided; and stop using it in backward
* Test a simple case in as_strided_backward
* a long note
* remove boundary checks of as_strided; implement slow path
* wip
* fix as_strided backward when input is overlapping
check for input overlapping too
[doc] clarify gradcheck behabior when input is overlapping
longer note
* fix a deprecation warning in test_autograd
* nits
* Solves #8659
This PR adds a warning to alert users about the possibility of a failure in the gradcheck
* Fix lint
* Update gradcheck.py
* Update gradcheck.py
* update error message
* Update warning message to be more descriptive
* Fix profiler crash when no events register
When trying to profile, attempting to print the event table throws a vague error because the event list is empty:
....
max_name_length = max(len(evt.key) for evt in events)
ValueError: max() arg is an empty sequence
This change fixes the error by returning an empty string.
* Update profiler.py
* Change backward calls to grad to avoid memory leak from #7343; Replace unnecesary create_graph=True with retain_graph=True
* fix gradgradcheck use of make_non_contiguous
* allow non-contguous target
* remove unnecessray .grad.zero_()
* remove contiguous_detach
* fix PReLU double backward always returning ggW as a scalar
* let noncontig gO require grad
* move requires_grad to return
* Codemod to update our codebase to 0.4 standard
* Update some of the test scri[ts
* remove Variable in test_clip_grad_value
* fix _symbolic_override_wrapper_maker
* change irfft signal_sizes arg to be the last
* add docs for fft, ifft, rfft, irfft; update doc for stft
* fix typo in window function docs
* improve gradcheck error message
* implement backward of fft, ifft, rfft, irfft
* add grad tests for fft, ifft, rfft, irfft
* fix nits and typos from #6118
* address comments
* Autograd container for trading compute for memory
* add a unit test for checkpoint
* address comments
* address review comments
* adding some docs for the checkpoint api
* more comments
* more comments
* repro bug
* Fix a subtle bug/apply some review comments
* Update checkpoint.py
* Run everything in grad mode
* fix flake and chunk=1
* use imperative backward as per discussion
* remove Variable and also add models and test for models
* Add a simple thread local variable to check for autograd grad mode
* remove models and models test after debugging
* address review comments
* address more comments
* address more comments
* remove patch
* check that cuda dev environment is also present before running cpp_extension cuda tests
* add OSError to list of exceptions when c++filt is not found
This changes type(tensor) to return `torch.Tensor` instead of
`torch.autograd.Variable`.
This requires a few implementation changes:
- torch.Tensor is now a regular Python class instead of a
pseudo-factory like torch.FloatTensor/torch.DoubleTensor
- torch.autograd.Variable is just a shell with a __new__ function.
Since no instanes are constructed it doesn't have any methods.
- Adds torch.get_default_dtype() since torch.Tensor.dtype returns
<attribute 'dtype' of 'torch._C._TensorBase' objects>
* Deprecate ctx.saved_variables via python warning.
Advises replacing saved_variables with saved_tensors.
Also replaces all instances of ctx.saved_variables with ctx.saved_tensors in the
codebase.
Test by running:
```
import torch
from torch.autograd import Function
class MyFunction(Function):
@staticmethod
def forward(ctx, tensor1, tensor2):
ctx.save_for_backward(tensor1, tensor2)
return tensor1 + tensor2
@staticmethod
def backward(ctx, grad_output):
var1, var2 = ctx.saved_variables
return (grad_output, grad_output)
x = torch.randn((3, 3), requires_grad=True)
y = torch.randn((3, 3), requires_grad=True)
model = MyFunction()
model.apply(x, y).sum().backward()
```
and assert the warning shows up.
* Address comments
* Add deprecation test for saved_variables
Questions/possible future works:
How to template-ize to extend support beyond LongTensor?
How to check if autograd works (and if not, how to add explicit gradient)?
CUDA support?
Testing command:
DEBUG=1 NO_CUDA=1 MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python setup.py build && DEBUG=1 NO_CUDA=1 MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python setup.py develop && python3 test/test_torch.py
Partially fixes#2031
* Initial commit for unique op
* Working unique with test
* Make inverse indices shape conform to input
* flake8 whitespace removal
* address review comment nits
* Expose fn and add docs. Explicitly declare no gradients
* Trial generic dispatch implementation
* Add tests for generics
* flake8 whitespace
* Add basic CUDA error throwing and templateize set
* Explicit contiguous and AT_DISPATCH_ALL_TYPES return
* Remove extraneous numpy conversion
* Refactor out .data calls
* Refactored to variable return length API with wrapper fn as opposed to returning a 0-length tensor, per off-line reviewer comments
* Remove A
* Don't use hidden torch._unique() in test
* Fix documentations
{kind=link}
{kind=link}
{kind=link}
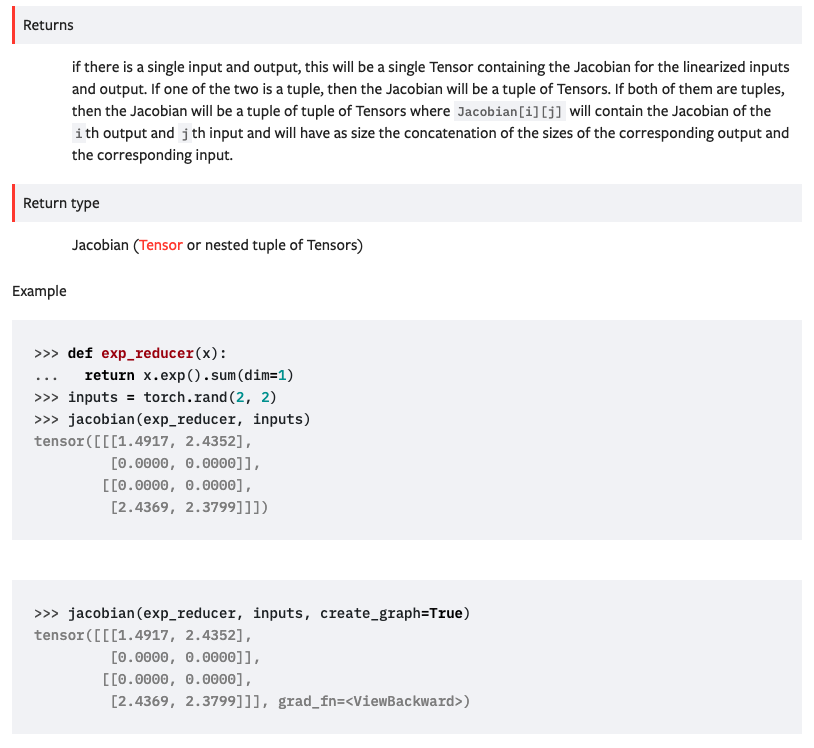{kind=link}
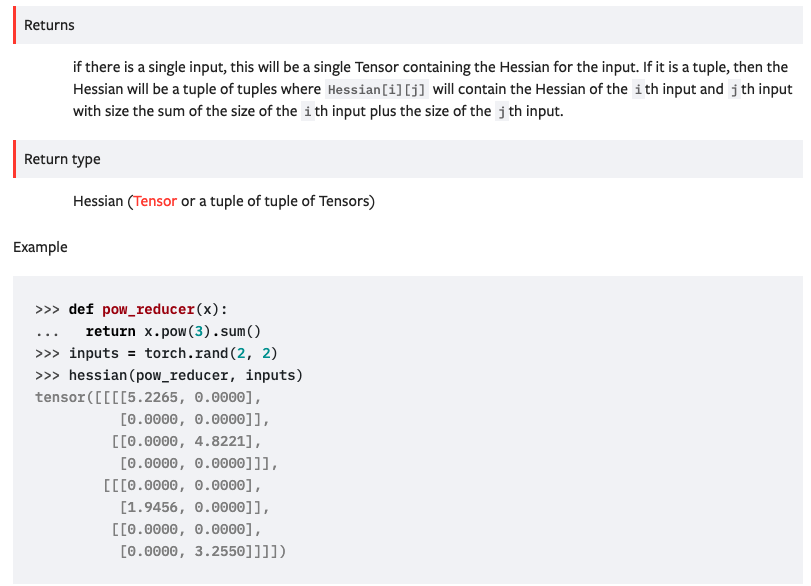{kind=link}
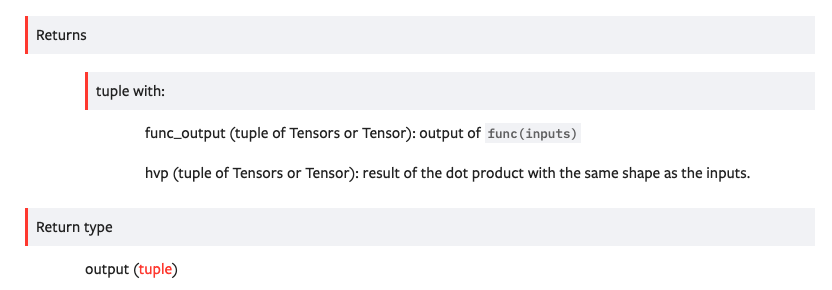{kind=link}
{kind=link}
{kind=link}