Summary:
Original commit changeset: e11cddf1fecc
Original Phabricator Diff: D49064185
Test Plan:
Comparing PT1 and PT2 performance on the IG Feed Model with this diff backed out: N4274204
Comparing the PT1 and PT2 performance on IG Feed with this diff committed: N4271093
Reviewed By: zou3519
Differential Revision: D49230047
Pull Request resolved: https://github.com/pytorch/pytorch/pull/109199
Approved by: https://github.com/zou3519, https://github.com/xw285cornell
Fixes#106893
There are two main changes:
- Before this PR, the function returned by once_differentiable was
included in skipfiles (because its .co_code is
torch/autograd/function.py). This PR adds a mechanism to tell Dynamo
to inline a function, no matter if it is included in skipfiles.
- A bugfix: when we are introspecting the backward, we need to turn the
grad mode off. This is to accurately model the eager-mode semantics:
In eager-mode PyTorch, if second-order gradients were not requested, then
the grad mode is off. torch.compile does not work with higher-order
gradients and just assumes we do first-order gradients, so this is OK.
Test Plan:
- new test
Differential Revision: [D49064185](https://our.internmc.facebook.com/intern/diff/D49064185)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108686
Approved by: https://github.com/voznesenskym
**Background**: "TorchDynamo Cache Lookup" events appear in traces to indicate a dynamo cache lookup; it's useful to check when cache lookups are taking a long time. To add a profiler event, one can use the `torch.profiler.record_function` context manager, or the C++ equivalent. Previously, the python version was used; first, when the profiler was enabled, callbacks for record_function_enter and record_function_exit were registered; then those would be called before and after every cache lookup.
**This PR**: Instead of calling the python bindings for `torch.profiler.record_function`, directly call the C++ implementation. This simplifies a lot of the code for binding C/C++. It also improves performance; previously there was a lot of overhead in the "TorchDynamo Cache Lookup" event, making the event artificially take a long time. After this change the events now appear shorter, because there's less overhead in starting/stopping the event: in other words, the profiler no longer distorts the results as much.
**Performance results**:
I ran using the script below on a cpu-only 1.6GHz machine. I report the median time (from 100 measurements) of a "TorchDynamo Cache Lookup" event before and after this PR. I think it is reasonable to consider the difference to be due to a reduction in overhead.
<details>
<summary>Benchmarking script</summary>
```python
def fn(x, y):
return (x * y).relu()
a, b = [torch.rand((4, 4), requires_grad=True) for _ in range(2)]
opt_fn = torch.compile(fn)
opt_fn(a, b)
opt_fn(a, b)
with torch.profiler.profile() as prof:
opt_fn(a, b)
```
</details>
Median before PR: 198-228 us (median of 100, measured 5 times)
Median after PR: 27us
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108436
Approved by: https://github.com/anijain2305, https://github.com/jansel
_enable_dynamo_cache_lookup_profiler used to get turned on when running `__enter__` or `__exit__` with the profiler. But it's possible to turn the profiler on and off without the context manager (e.g. with a schedule and calling `.step()`). Instead, we should put these calls (which are supposed to be executed when the profiler turns on/off) where `_enable_profiler()` and `_disable_profiler()` are called.
This puts `_enable_dynamo_cache_lookup_profiler` and `_set_is_profiler_enabled` into `_run_on_profiler_(start|stop)` and calls that on the 3 places where `_(enable|disable)_profiler` get called.
Differential Revision: [D48619818](https://our.internmc.facebook.com/intern/diff/D48619818)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107720
Approved by: https://github.com/wconstab
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
torch.profiler.record_function is relatively slow; for example, in some benchmarks I was running, x.view_as(x) was ~2us, and ~16-17us when wrapped in a record_function context. The reasons for this are: dispatcher overhead from going through an op (the main source of overhead), python binding / python conversion overhead, and some overhead from the context manager.
This new implementation is faster, but it won't work with torchscript. Based on the benchmarks I was running, it adds 0.5-0.7us overhead per call when the profiler is turned off. To use it, you can just:
```python
with torch._C._profiler_manual._RecordFunctionFast("title"):
torch.add(x, y)
```
It implements a context manager in python which directly calls the record_function utilities, instead of calling through an op.
* The context manager is implemented directly in python because the overhead from calling a python function seems non-negligible
* All the record_function calls, python object conversions are guarded on checks for whether the profiler is enabled or not. It seems like this saves a few hundred nanoseconds.
For more details about the experiments I ran to choose this implementation, see [my record_functions experiments branch](https://github.com/pytorch/pytorch/compare/main...davidberard98:pytorch:record-function-fast-experiments?expand=1).
This also adds a `torch.autograd.profiler._is_profiler_enabled` global variable that can be used to check whether a profiler is currently enabled. It's useful for further reducing the overhead, like this:
```python
if torch.autograd.profiler._is_profiler_enabled:
with torch._C._profiler_manual._RecordFunctionFast("title"):
torch.add(x, y)
else:
torch.add(x, y)
```
On BERT_pytorch (CPU-bound model), if we add a record_function inside CachedAutotuning.run:
* Naive torch.profiler.record_function() is a ~30% slowdown
* Always wrapping with RecordFunctionFast causes a regression of ~2-4%.
* Guarding with an if statement - any regression is within noise
**Selected benchmark results**: these come from a 2.20GHz machine, GPU build but only running CPU ops; running `x.view_as(x)`, with various record_functions applied (with profiling turned off). For more detailed results see "record_functions experiments branch" linked above (those results are on a different machine, but show the same patterns). Note that the results are somewhat noisy, assume 0.05-0.1us variations
```
Baseline:: 1.7825262546539307 us # Just running x.view_as(x)
profiled_basic:: 13.600390434265137 us # torch.profiler.record_function(x) + view_as
precompute_manual_cm_rf:: 2.317216396331787 us # torch._C._profiler_manual._RecordFunctionFast(), if the context is pre-constructed + view_as
guard_manual_cm_rf:: 1.7994389533996582 us # guard with _is_profiler_enabled + view_as
```
Differential Revision: [D48421198](https://our.internmc.facebook.com/intern/diff/D48421198)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107195
Approved by: https://github.com/albanD, https://github.com/aaronenyeshi
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
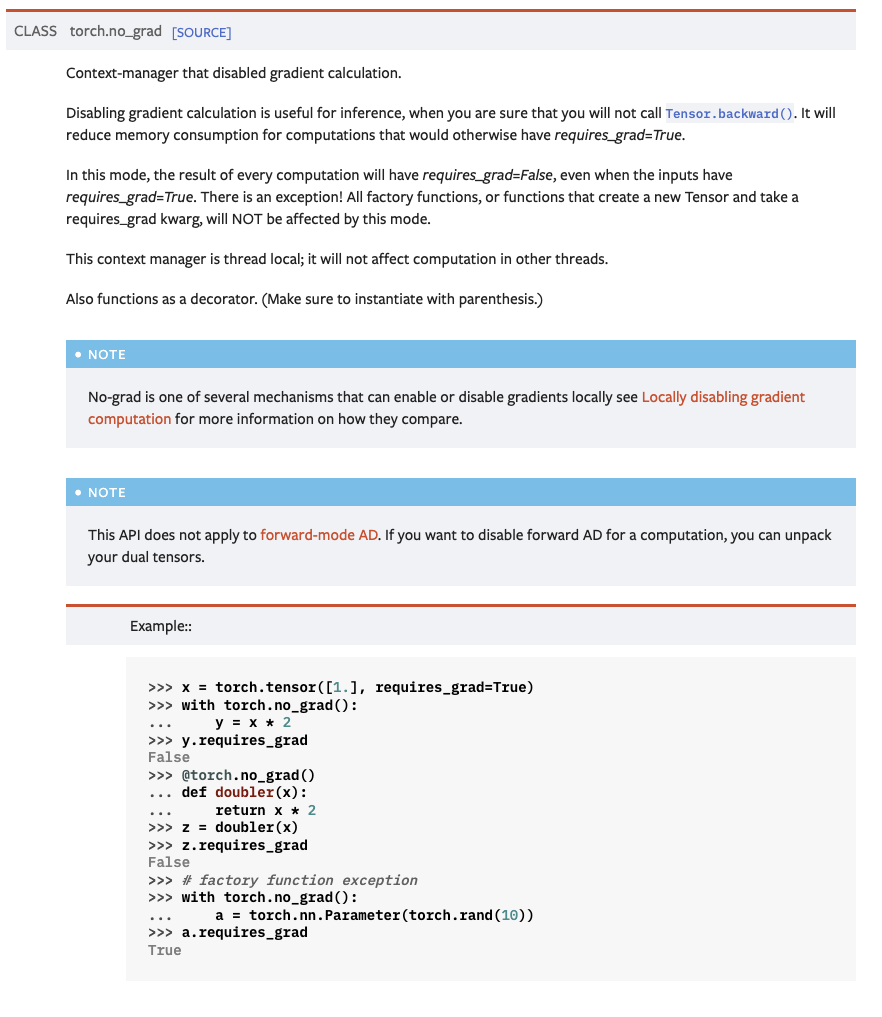
This PR implements the feature described in #107036 for `no_grad`, `enable_grad` and `inference_mode`.
Users can still use the above as before but they can also use them without parentheses.
For example:
```python
import torch
a = torch.ones(1, requires_grad=True)
def do_something():
print(2 * a)
with torch.no_grad():
do_something() # tensor([2.])
torch.no_grad()(do_something)() # tensor([2.])
torch.no_grad(do_something)() # tensor([2.])
do_something() # tensor([2.], grad_fn=<MulBackward0>)
```
For `inference_mode`, decorating without parenthesis is equivalent to decorating with the default `mode=True`, similiar to how dataclasses behave (https://docs.python.org/3/library/dataclasses.html#module-contents)
Closes#107036
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107086
Approved by: https://github.com/albanD
We hope PyTorch profiling parsing ability can also be applicable to custom devices. Based on previous work https://github.com/pytorch/pytorch/pull/101554, we have made supplementary updates to PyTorch profiling to extend its parsing capabilities for custom devices. These modifications do not affect the original logic of the code and mainly include the following aspects:
1. Added the relevant logic for use_device in torch.profiler.profiler._KinetoProfile.
2. In torch.autograd.profiler and torch.autograd.profiler_util, custom devices profiling data parsing ability has been added using privateuse1 and use_device attributes.
3. In torch._C._autograd.pyi and torch._C._autograd.pyi, custom devices related attributes have been added. The underlying C++
logic will be added in subsequent pull requests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106142
Approved by: https://github.com/aaronenyeshi
Fixes#102375
Sequence_nr increments in the forward pass and decrements in the backward pass. Backward ops with the same sequence_nr as a forward op represent the backward implementation for the op. The long term goal is to make this information available to the profiler so users can observe which ops are fused by the inductor openai triton kernels.
Added a test for this feature **test/dynamo/test_aot_autograd.py::AotAutogradFallbackTests::test_aot_sequence_nr**. The test case uses **aot_export_module()** to create a joint fwd/bwd fx graph. Then it walks all the nodes in fx graph using fx_graph.graph.nodes. The seq_nr of each node is recorded in node.meta. During the fwd pass the seq_nr increments and it decrements during the bwd pass. This allows the user to map forward ops to their corresponding bwd ops which is useful for performance analysis.
Expected output from the test case.
SeqNr|OrigAten|SrcFn
0|aten.convolution.default|l__self___conv1
0|aten.add.Tensor|l__self___bn1
1|aten._native_batch_norm_legit_functional.default|l__self___bn1
2|aten.relu.default|l__self___relu1
3|aten.add.Tensor|add
4|aten.view.default|flatten
5|aten.t.default|l__self___fc1
6|aten.unsqueeze.default|l__self___fc1
7|aten.mm.default|l__self___fc1
8|aten.squeeze.dim|l__self___fc1
9|aten.add.Tensor|l__self___fc1
10|aten.sub.Tensor|l__self___loss_fn
11|aten.abs.default|l__self___loss_fn
12|aten.mean.default|l__self___loss_fn
12|aten.ones_like.default|
12|aten.expand.default|
12|aten.div.Scalar|
11|aten.sgn.default|
11|aten.mul.Tensor|
8|aten.unsqueeze.default|
7|aten.t.default|
7|aten.mm.default|
7|aten.t.default|
7|aten.t.default|
7|aten.mm.default|
6|aten.squeeze.dim|
5|aten.t.default|
4|aten.view.default|
2|aten.threshold_backward.default|
1|aten.native_batch_norm_backward.default|
0|aten.convolution_backward.default|
0|aten.add.Tensor|
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103129
Approved by: https://github.com/soulitzer
This branch:
1) converts the autograd tape into an FX graph
2) caches that conversion using a "shadow" graph
3) compiles and runs the generated FX graph instead of the normal autograd
What works currently:
1) Caching, capture, and initial integration
2) Backwards hooks
3) Inlining AotAutograd generated subgraphs
4) torch.compiling the generated FX graph
5) Auto-detecting dynamic shapes based on changes
Future work
1) Larger scale testing
1) Boxed calling convention, so memory can be freed incrementally
1) Support hooks on SavedTensor
1) Additional testing by running eager autograd tests under compiled_autograd.enable()
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103822
Approved by: https://github.com/ezyang, https://github.com/albanD
Fixes#104985
Implemented `set_multithreading_enabled` C++ function to directly alter state rather than using `MultithreadingEnabled` class, which was automatically resetting the state when the object was destroyed. This behavior more closely aligns with set_grad_enabled which does work as expected. This allows us to change python class `set_multithreading_enabled` to act as both a function and context manager.
I also added a getter: `torch._C.is_multithreading_enabled`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105291
Approved by: https://github.com/albanD
Fixes #ISSUE_NUMBER
1、the class named "Type" has not been used anymore in anywhere, so I add warning message to remove it in the future.
2、add a arg(default is "cuda") for save_on_cpu so that it can support more device type (like privateuse1)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103245
Approved by: https://github.com/soulitzer
Summary: trigger tracing for MTIA events on python side when ProfilerActivity.MTIA is specified
Test Plan:
Test diff: D45437426
```
hg graft D45437426
```
- in one terminal
```
cd ~/fbsource/fbcode
buck2 run -j 8 \
//infra_asic_fpga/firmware/tools/mad/service:mad_service
```
- in another terminal
Pytorch profiler
```
buck run mode/dev-nosan -j 8 //caffe2/torch/fb/acc_runtime/afg/tests:test_afg -- -m kernel_add
```
Differential Revision: D46122853
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102288
Approved by: https://github.com/aaronenyeshi
1. `torch.autograd.profiler` interface parameters changed. (use `self.use_device` instead of `self.use_cuda` facilitates access by other devices and integrate it in subsequent pr)
2. Modify `ProfilerEventStub`(aka `std::shared_ptr<CUevent_st>`) to `ProfilerVoidEventStub`(aka `std::shared_ptr<void>`) so that `ProfilerStubs` can be inherited by any `{device}Methods`.
In addition, `cuda_event_start_` is renamed to `device_event_start_` , cuda and other devices can use this event pointer if needed.
4. custom device support using legacy profiling(add `ProfilerState::KINETO_PRIVATEUSE1_FALLBACK` option)
5. add `privateuse1Stubs` register
(parse results and test cases are added in subsequent pr)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101554
Approved by: https://github.com/aaronenyeshi
There are some I can't easily switch due to reasons like:
- Dynamo modelling the guard
- BC concerns (for torch.autograd.set_multithreading_enabled)
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102642
Approved by: https://github.com/albanD
Many ops take as inputs scalars or scalar lists which are important to understand the properties of the op. For example, convolution ops' behavior and output shapes often depend on padding and strides, which are provided as scalars of lists of scalars. This will record scalar lists when record_inputs=True.
Details:
During collection (and this was true before this PR as well), we serialize values and tensor metadata into an InputOutputEncoder. After collection occurs, we deserialize these values to attach the information to each of the events.
This PR does this:
- Adds support for serializing scalar lists during collection / serialization
- Adds an extra field called "Concrete Args"
- Splits up the deserialization process into two steps - one for generating "input shapes" and one for generating "concrete args". We split up input shapes and concrete args to avoid interrupting any previous workflows that relied on the specific data in the input shapes category; additionally, it's just a better description. Note that single scalars will remain in the "input shapes" category as they were already in that category in the past.
Differential Revision: [D45798431](https://our.internmc.facebook.com/intern/diff/D45798431)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100593
Approved by: https://github.com/aaronenyeshi
Fixes#72428 according to decision reached in comments.
I've left other instances of `w.r.t.` in tact (e.g. in parameter/return descriptions, in comments, etc) because there were many, and I didn't' want to go out-of-scope. That being said, I'm happy to change those as well if we'd prefer the consistency!
I've also fixed a typo that I came across while grepping for instances.
Will update with screenshots once docs are built.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100028
Approved by: https://github.com/albanD
Fixes#44189
Adds a new parameter, zero_grad_unused, to the torch.autograd.grad() function. This parameter allows for the gradient to be set to 0 instead of None when a variable is unused, which can be helpful for higher-order partial differentials.
Here is an example of using this new parameter to solve d^3y/dx^3 given y = a * x:
```python
x = torch.tensor(0.5, dtype=torch.float32, requires_grad=True)
a = torch.tensor(1, dtype=torch.float32, requires_grad=True)
y = x * a
dydx = torch.autograd.grad(y, x, create_graph=True, allow_unused=True)
d2ydx2 = torch.autograd.grad(dydx, x, allow_unused=True, zero_grad_unused=True)
try:
d3ydx3 = torch.autograd.grad(d2ydx2, x, allow_unused=True, zero_grad_unused=True)
except RuntimeError as e:
assert False, "Should not raise error"
```
With `zero_grad_unused`, d2ydx2 could be 0 instead of None, enabling d3ydx3 to be calculated as defined in math without throwing an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97015
Approved by: https://github.com/soulitzer
As in the title.
The `masked_grad` kw argument is required for `to_dense` backward to distinguish the expected semantics of sparse tensors. `masked_grad=True` means that the `to_dense` backward will apply a mask to the returned gradient where the mask is defined by the input indices. The default semantics implies `masked_grad==True` for BC but see the [comment](https://github.com/pytorch/pytorch/pull/96095/files#diff-d4df180433a09071e891d552426911c227b30ae9b8a8e56da31046e7ecb1afbeR501-R513) in `to_dense_backward`.
As a consequence, existing code that is run through autograd engine must replace `.to_dense()` calls with `.to_dense(masked_grad=False)`. For example,
```python
torch.autograd.gradcheck(lambda x: torch.sum(x, [0]).to_dense())
torch.autograd.gradcheck(lambda x: torch.sparse.sum(x, [0]).to_dense())
```
(recall, gradcheck has `masked=False` as default) must be updated to
```python
torch.autograd.gradcheck(lambda x: torch.sum(x, [0]).to_dense(masked_grad=False))
torch.autograd.gradcheck(lambda x: torch.sparse.sum(x, [0]).to_dense(masked_grad=True), masked=True)
```
Fixes https://github.com/pytorch/pytorch/issues/95550
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96095
Approved by: https://github.com/cpuhrsch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}