Months ago, in order to get dynamic shapes working through to Dynamo backends, we changed the calling convention to pass fake tensors rather than real tensors as example inputs to backends. The motivation at the time was, well, backends shouldn't really be peeking at the real tensors when they are doing compilation, and so it would make more sense to hide the real tensors from backends. But there were a bunch of problems:
* This interacted poorly with our accuracy minifier design: accuracy minifier needs access to the real inputs in order to run the model and figure out what happens!
* The TensorRT backend required real inputs and we never figured out how to fix it.
* In practice, all the backends needed to detect if they were passed real tensors, and fakeify them anyway (certainly AOTAutograd does this)
* Parameters and inputs are treated non-uniformly: parameters had to be passed as real tensors, because CUDA graphs requires knowing what the actual tensors are
Furthermore, there were some more problems discovered after the fact:
* Backends may want to optimize on aspects of tensors which you cannot tell without having real tensors; e.g., alignment of the data pointer
So, this PR decides that changing the calling convention was a bad idea, and switches back to passing real tensors. There is a problem though: AOTAutograd will perform fakeification, which means that in practice backends are still going to end up with fake tensors in the end anyway. I want to change this, but this will require some work with bdhirsh's upcoming AOTAutograd export refactor.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99320
Approved by: https://github.com/voznesenskym
Months ago, in order to get dynamic shapes working through to Dynamo backends, we changed the calling convention to pass fake tensors rather than real tensors as example inputs to backends. The motivation at the time was, well, backends shouldn't really be peeking at the real tensors when they are doing compilation, and so it would make more sense to hide the real tensors from backends. But there were a bunch of problems:
* This interacted poorly with our accuracy minifier design: accuracy minifier needs access to the real inputs in order to run the model and figure out what happens!
* The TensorRT backend required real inputs and we never figured out how to fix it.
* In practice, all the backends needed to detect if they were passed real tensors, and fakeify them anyway (certainly AOTAutograd does this)
* Parameters and inputs are treated non-uniformly: parameters had to be passed as real tensors, because CUDA graphs requires knowing what the actual tensors are
Furthermore, there were some more problems discovered after the fact:
* Backends may want to optimize on aspects of tensors which you cannot tell without having real tensors; e.g., alignment of the data pointer
So, this PR decides that changing the calling convention was a bad idea, and switches back to passing real tensors. There is a problem though: AOTAutograd will perform fakeification, which means that in practice backends are still going to end up with fake tensors in the end anyway. I want to change this, but this will require some work with bdhirsh's upcoming AOTAutograd export refactor.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99320
Approved by: https://github.com/voznesenskym
Previously, we had a problem when partitioning forward-backward dynamic graphs, which is that we could end up with a backward graph that mentions a symbol in an input tensor (e.g., `f32[s0 + s1]`), but without this symbol being otherwise bound elsewhere. When this happens, we have no way of actually deriving the values of `s0` and `s1`. Our fix for this in https://github.com/pytorch/pytorch/pull/93059 was to just retrace the graph, so that s0 + s1 got allocated a new symbol s2 and everything was happy. However, this strategy had other problems, namely (1) we lost all information from the previous ShapeEnv, including guards and (2) we end up allocating a LOT of fresh new symbols in backwards.
With this change, we preserve the same ShapeEnv between forward and backwards. How do we do this? We simply require that every symbol which may be present inside tensors, ALSO be a plain SymInt input to the graph. This invariant is enforced by Dynamo. Once we have done this, we can straightforwardly modify the partitioner to preserve these SymInt as saved for backwards, if they are needed in the backwards graph to preserve the invariant as well.
This apparently breaks yolov3, but since everything else is OK I'm merging this as obviously good and investigating later.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99089
Approved by: https://github.com/voznesenskym
**Context**
The existing check to see if an arg is duped is `if dupe_arg_pos != kept_pos:`. However, this incorrectly considers every arg after a true duped arg to also be a duped arg.
Consider `flat_args = [a, b, b, c]`, where indices `1` and `2` are duped.
- `add_dupe_map = {0: 0, 1: 1, 2: 1, 3: 2}`
- For `dupe_arg_pos=2, kept_pos=1`, `2 != 1`, so the check correctly identifies the second `b` to be a duped arg.
- For `dupe_arg_pos=3, kept_pos=2`, `3 != 2`, so the check incorrectly identifies the `c` to be a duped arg.
Indeed, if there were more args like `[a, b, b, c, d, e, ...]`, every arg after the second `b` will be considered a duped arg since its `kept_pos` will always be 1 lower than its `dupe_arg_pos`.
**Overview**
This PR changes `add_dupe_map` to be implemented as a `List[int]`, where the list index implicitly represents the `dupe_arg_pos` and the list element represents the `kept_pos`. We use a list to have stable in-order iteration and because we know the keys to be in `{0, 1, ..., len(flat_args) - 1}`.
With `add_dupe_map` as a list, the `is_dupe_arg` condition is whether the entry in `add_dupe_map` shows a new not-yet-seen index in the iteration. One way to do this is to count the number of unique args so far and compare against that.
This closes https://github.com/pytorch/pytorch/issues/98883, where now the guards change from
```
GUARDS ___guarded_code.valid
and ___check_type_id(L['self'], 93996836333040)
and ___check_obj_id(L['self'], 140119034997536)
and not ___are_deterministic_algorithms_enabled()
and ___check_tensors(L['x'])
and L['self']._buf is L['self']._buf_module._buf
and L['self']._buf_module._buf is L['self']._param
```
to without the final incorrect `L['self']._buf_module._buf is L['self']._param` guard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98932
Approved by: https://github.com/ezyang
For the current runtime wrapper in aot, `disable_amp` is always set to True. In fact, we would like to avoid disabling autocast if possible because accessing TLS is slow. In this PR, `disable_amp` depends on whether there is any autocast enabled instead of always being True. Many operators would get an improvement of performance (inductor v.s. eager) with this fix.
Example of operators' 0.8 speedup in torchbench (inductor v.s. eager):
<html xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta name=ProgId content=Excel.Sheet>
<meta name=Generator content="Microsoft Excel 15">
<link id=Main-File rel=Main-File
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip.htm">
<link rel=File-List
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip_filelist.xml">
</head>
<body link="#0563C1" vlink="#954F72">
| current | new
-- | -- | --
aten.hardsigmoid.default | 0.709372349 | 0.81414306
aten.tanh.default | 0.715227805 | 0.855556349
aten.add.Scalar | 0.682292123 | 0.860371222
aten.sigmoid_backward.default | 0.688039934 | 0.915606579
</body>
</html>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97864
Approved by: https://github.com/EikanWang, https://github.com/jansel, https://github.com/jgong5, https://github.com/bdhirsh
The purpose of this API is to execute a few large components of work:
1) Refactor all the internals of plumbing dynamic dimension information after dynamo to be stateless
2) Decouple allocation controls around dynamic dimensions from verification
3) For (2), for allocation, create an enum that dictates whether we are in DUCK (default today), STATIC (aka assume_static_default in the past), or DYNAMIC (aka user constrained, do not duck shape)
4) For (2), for verification, we separate out the list of dynamic ranges entirely from allocation. This means shape_env does not tracking for what we verify on, and instead, it is the callers job to invoke produce_guards() with the various things they want verified, specifically, with the valid ranges. We do use constrain ranges to refine value ranges when doing analysis.
5) We have decided, therefore, as an extension of (4) to double down on "late" checks versus "eager" checks, primarily because the mechanisms for gathering what actually matters happens during guards, and should be a purview of the caller seeking guards, not the shape env. However, for dynamo, these structures are essentially one and the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96699
Approved by: https://github.com/avikchaudhuri, https://github.com/ezyang
Twice this week I have had people confuse "operator defined with Python
operator registration aka torch.library" and "PyOperator which is used
to define control flow operators and other operators that cannot be
represented in JIT schema." Renaming PyOperator for clarity.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97493
Approved by: https://github.com/SherlockNoMad
I added a bunch of asserts to verify that I didn't accidentally kill copy_ in the graph, hopefully this combined with our existing tests is good enough.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97275
Approved by: https://github.com/bdhirsh
This refactor should make it easier to add an export hook into aot autograd.
(1) I killed `create_forward_or_joint_functionalized()` (and the functions that it called, like `forward_or_joint()`) which used to handle autograd + functionalization all-in-one-go for the joint case, and was also used in the inference case.
I added a few separate helper functions:
`create_functionalized_graph()`: this takes a flat fn, and returns a functionalized fx graph. It is mostly just a thin wrapper around functionalization + make_fx(), but also has some extra logic to manually append `copy_()` ops to the end of the graph.
`fn_no_extra_mutations()`: this creates the fn that we want to trace in the inference code path. It takes in a function that it then calls, and returns the outputs + any (updated) mutated inputs.
`joint_fn_no_external_mutations()`: this creates the fn that we want to trace in the joint code path. It takes in a function, and traces out its joint. It also does the work of cloning inputs that are mutated and require gradients, returning mutated inputs as outputs, and returning intermediate bases as outputs
We should be able to add an export hook by basically adding a similar version of `joint_fn_no_external_mutations` but with a lot more restrictions (guaranteed to have no tangents, not synthetic bases, etc), and calling `create_functionalized_graph()` on it.
Differential Revision: [D44204090](https://our.internmc.facebook.com/intern/diff/D44204090)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96341
Approved by: https://github.com/ezyang
I added a bunch of asserts to verify that I didn't accidentally kill copy_ in the graph, hopefully this combined with our existing tests is good enough.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97275
Approved by: https://github.com/bdhirsh
The purpose of this PR is to remove reliance on argument positions in dedup guards, AND extend the functionality to params.
A version of this PR was stamped prior https://github.com/pytorch/pytorch/pull/95831 - but was kinda gross, because it was based on an underlying PR that did way too much with source names.
This PR leaves most of that alone, in favor of just reusing the same name standardization logic that dynamo module registration does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96774
Approved by: https://github.com/ezyang
Summary:
Adds NNC-like logging that is configured through an env var `TORCH_COMPILE_LOGS`
Examples:
`TORCH_LOGS="dynamo,guards" python script.py` - prints dynamo logs at level INFO with guards of all functions that are compiled
`TORCH_LOGS="+dynamo,guards,graph" python script.py` - prints dynamo logs at level DEBUG with guards and graphs (in tabular) format of all graphs that are compiled
[More examples with full output](https://gist.github.com/mlazos/b17f474457308ce15e88c91721ac1cce)
Implementation:
The implementation parses the log settings from the environment, finds any components (aot, dynamo, inductor) or other loggable objects (guards, graph, etc.) and generates a log_state object. This object contains all of the enabled artifacts, and a qualified log name -> level mapping. _init_logs then adds handlers to the highest level logs (the registered logs), and sets any artifact loggers to level DEBUG if the artifact is enabled.
Note: set_logs is an alternative for manipulating the log_state, but if the environment contains TORCH_LOGS, the environment settings will be prioritized.
Adding a new log:
To add a new log, a dev should add their log name to torch._logging._registrations (there are examples there already).
Adding a new artifact:
To add a new artifact, a dev should add their artifact name to torch._logging._registrations as well.
Additionally, wherever the artifact is logged, `torch._logging.getArtifactLogger(__name__, <artifact_name>)` should be used instead of the standard logging implementation.
[design doc](https://docs.google.com/document/d/1ZRfTWKa8eaPq1AxaiHrq4ASTPouzzlPiuquSBEJYwS8/edit#)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94858
Approved by: https://github.com/ezyang
When constructing the joint graph, we normally have to clone any inputs that are mutated, so that we can pass in the original, pre-mutation inputs as leaves to autograd.
Previously, we were doing this for all mutated inputs - but we only need to do it for inputs that require gradients and participate in autograd.
Hopefully this should speed up code like batch norm - I think before this we were unnecessarily cloning the running stats during training.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96342
Approved by: https://github.com/albanD, https://github.com/ezyang
This refactor should make it easier to add an export hook into aot autograd.
(1) I killed `create_forward_or_joint_functionalized()` (and the functions that it called, like `forward_or_joint()`) which used to handle autograd + functionalization all-in-one-go for the joint case, and was also used in the inference case.
I added a few separate helper functions:
`create_functionalized_graph()`: this takes a flat fn, and returns a functionalized fx graph. It is mostly just a thin wrapper around functionalization + make_fx(), but also has some extra logic to manually append `copy_()` ops to the end of the graph.
`fn_no_extra_mutations()`: this creates the fn that we want to trace in the inference code path. It takes in a function that it then calls, and returns the outputs + any (updated) mutated inputs.
`joint_fn_no_external_mutations()`: this creates the fn that we want to trace in the joint code path. It takes in a function, and traces out its joint. It also does the work of cloning inputs that are mutated and require gradients, returning mutated inputs as outputs, and returning intermediate bases as outputs
We should be able to add an export hook by basically adding a similar version of `joint_fn_no_external_mutations` but with a lot more restrictions (guaranteed to have no tangents, not synthetic bases, etc), and calling `create_functionalized_graph()` on it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96341
Approved by: https://github.com/ezyang
Another bonus of factoring the synthetic_base logic into one place: we used to have a `CompiledRuntimeMetadata` object that encapsulated `ViewAndMutationMeta`, plus a bunch of extra synthetic base metadata that was plumbed around. Now I can kill that first metadata object, and use `ViewAndMutationMeta` on its own everywhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96340
Approved by: https://github.com/ezyang
Ed pointed it out a few days ago - I probably added this mistakenly a few months ago. I can't think of any reason it's necessary, and removing it doesn't cause any tests to fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96339
Approved by: https://github.com/ezyang
This refactor doesn't significantly change LoC in aot autograd, but I think this nets out to making it clearer (interested in peoples' thoughts).
The idea is that I tried to re-write the part of aot autograd that deals with synthetic bases in a layered way, similar to how Ed wrote the logic for dedup'ing inputs: it happens in one place, and all of the downstream transformation in aot autograd don't have to worry about it.
Specifically, I added a new function `aot_wrapper_synthetic_base`, similar to the existing `aot_wrapper_dedupe`.
The benefit: none of the other code in aot autograd needs to think about synthetic bases (previously, synthetic base code was intertwined in several places).
The downsides: there are two.
(1) `aot_wrapper_synthetic_base()` needs to have its own epilogue. There is one particularly hairy case, where factoring the synthetic base logic to a single location was painful: If you have two inputs that alias each other, where one gets a data mutation, and the other gets a metadata mutation.
Ordinarily, metadata mutations are handled by the runtime epilogue, in `create_runtime_wrapper`. However, now that things are factored this way, the runtime wrapper operates only on synthetic bases instead of operating on the original inputs. For data mutations, it is fine to apply the data mutation to the synthetic base instead of the original input alias. But for metadata mutations, we **need** to apply the metadata mutation directly to the original inputs.
The way that I handled this was by tracking which inputs slot into this specific case (part of a synthetic base, and get metadata mutations), and updateing the flat_fn() that we pass downstream to return these updated inputs as extra outputs. From the perspective of downstream logic, these are real user outputs, that it can treat like any other user outputs. `aot_wrapper_synthetic_base` will know to grab these extra outputs and use them to apply the metadata mutations.
This was pretty annoying, but has the benefit that all of that logic is encapsulated entirely in `aot_wrapper_synthetic_base()`.
(2) input mutations are now performed on the synthetic base instead of the individual aliases.
You can see the original code comment [here](b0b5f3c6c6/torch/_functorch/aot_autograd.py (L1131)) for details. We used to do the optimized thing in this case, and now we do the less optimized thing (copying the entire synthetic base, instead of the potentially smaller alias).
To be fair, we had no data showing that this optimization was showing improvements on any models in practice. I also think that the main reason anyone would ever run across this problem is because of a graph break - so if you care about perf, you probably want to avoid the extra graph breaks to begin with. I haven't added any warnings for this, but we probably could depending on what people think.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96235
Approved by: https://github.com/ezyang
For a while now, we've been re-running our functionalization analysis pass twice - once for get metadata when dedup'ing, and an entire second time during aot_dispatch_base/autograd.
This should also probably speed up compile times pretty noticeably, since we're going from:
(a) inference-only trace case: 3 fw traces -> 2 fw traces
(b) autograd trace case: 2 fw traces + 1 joint trace -> 1 fw trace + 1 joint trace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95992
Approved by: https://github.com/ezyang
This PR does a few things all at once, as I needed to fix several bugs on the way here. The main goal of the PR is to fix the `'float' object has no attribute '_has_symbolic_sizes_strides'` error. The general idea is to heavily penalize non-SymInt but still SymNode cuts in the graph. This doesn't work for default partitioner, so essentially, dynamic shapes with default partitioner is not supported.
While doing this, I had a fix a few other bugs in the partitioner:
* SymNode operations weren't considered recomputable. But they are very cheap, go wild.
* zeros_like wasn't considered recomputable, and this prevented some gradient formulas (e.g., for angle with real inputs) from successfully finding a cut at all
* AOTAutograd tests use the default partitioner. I switch them to use min-cut partitioner...
* ...but this reveals a bug where if we have nodes in backward outputs that don't depend on tangents, they never get assigned to the backward graph. I fix this by making the backward outputs mandatory to be in backwards. I have to be careful to filter out None backward outputs; those never participate in flow analysis!
This causes some wobbling for the min-cut tests, but these seem legitimate: since we're now willing to recompute, the partitioner can reduce the number of SymInts it transmits by just doing some recompute in the backend.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96653
Approved by: https://github.com/ngimel
This makes the next PR in the stack cleaner: having the top level entry point to aot autograd perform the functionalization analysis pass once, and plumb the metadata everywhere else that we need it.
I put it in a separate PR because I recently learned that this function is used in fbcode, so I'll need to fix up internals when I land this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95991
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/pytorch/issues/95167
More details are in that issue. To summarize, the issue shows up when we have some code like this:
```
def f(x):
x.detach().mul_(2) # can also happen if the mul_() happens under torch.no_grad()
return x + 1
```
AOTAutograd will then spit out code like this:
```
def compiled_fn(x):
x_updated = x.mul(2)
out = x_updated + 1
return x_updated, out
def CompiledFunction.forward(x): # pseudocode, this is part of an autograd.Function
x_updated, out = compiled_function(x):
return x_updated, out
def runtime_wrapper(x):
x_updated, out = CompiledFunction.apply(x)
x.copy_(x_updated)
x = torch.ones(2, requires_grad=True)
out = runtime_wrapper(x)
```
However, the call to `x.copy_(x_updated)` will fail with the error: `a leaf Variable that requires grad is being used in an in-place operation`. This is because `x` is an autograd leaf, and autograd doesn't allow you to mutate leaves.
In this case though, the data mutation should be entirely opaque to autograd - all mutations happened underneath a `.detach()` or a `torch.no_grad()`.
As Ed pointed out in the issue, we can detect this situation by checking if the mutated input is an autograd leaf. If it is, then it must have been the case that any mutations on it must have been hidden from autograd, since otherwise the eager code would have error'd. The solution I added is to detect this situation, and manually run `x.detach().copy_(x_updated)`, to hide the update from autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95980
Approved by: https://github.com/ezyang
Previously, if dynamic shapes were turned on and we had a forward graph that returns a symint, then we would generate a backward graph that takes in a tangent input for that symint fwd output. This causes problems for downstream - inductor will see an input that it expects to be a symint, but it gets a `None` from autograd.
Confirmed that this repro now passes:
```
benchmarks/dynamo/torchbench.py --devices cuda --inductor --dynamic-shapes --unspecialize-int --accuracy --training --only drq
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96219
Approved by: https://github.com/ezyang
The _make_boxed logic probably needs a cleanup, but this fixes a spurious warning that we should get in before the release.
Confirmed that this used to emit a warning and no longer does:
```
import torch
lin = torch.nn.Linear(100, 10)
def f(x):
return lin(x)
opt_f = torch.compile(f)
opt_f(torch.randn(10, 100, requires_grad=False))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95521
Approved by: https://github.com/ngimel
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
I applied some flake8 fixes and enabled checking for them in the linter. I also enabled some checks for my previous comprehensions PR.
This is a follow up to #94323 where I enable the flake8 checkers for the fixes I made and fix a few more of them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94601
Approved by: https://github.com/ezyang
The functorch setting still exists, but now it is no longer necessary:
we infer use of Python dispatcher by checking if the ambient
FakeTensorMode has a ShapeEnv or not. The setting still exists,
but it is for controlling direct AOTAutograd use now; for PT2,
it's sufficient to use torch._dynamo.config.dynamic_shapes.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94469
Approved by: https://github.com/Chillee, https://github.com/voznesenskym, https://github.com/jansel
Historically, we work out `size_hint` by working it out on the fly by doing a substitution on the sympy expression with the `var_to_val` mapping. With this change, we also maintain the hint directly on SymNode (in `expr._hint`) and use it in lieu of Sympy substitution when it is available (mostly guards on SymInt, etc; in particular, in idiomatic Inductor code, we typically manipulate Sympy expressions directly and so do not have a way to conveniently maintain hints.)
While it's possible this will give us modest performance improvements, this is not the point of this PR; the goal is to make it easier to carefully handle unbacked SymInts, where hints are expected not to be available. You can now easily test if a SymInt is backed or not by checking `symint.node.hint is None`.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94201
Approved by: https://github.com/voznesenskym
tldr; this should fix some minor perf regressions that were caused by adding more as_strided() calls in aot autograd.
This PR adds a new context manager, `torch.autograd._set_view_replay_enabled()`.
Context: AOT Autograd has special handling for "outputs that alias graph intermediates". E.g. given this function:
```
def f(x):
y = torch.mul(x, 2)
out = y.view(-1)
return out
```
AOT Autograd will do the following:
```
def fn_to_compile(x):
y = torch.mul(x, 2)
out = y.view(-1)
# return the graph intermediate
return y, out
compiled_fn = compile(fn_to_compile)
def wrapper(x):
y, out = compiled_fn(x)
# regenerate the alias of the graph intermediate
return out._view_func(y)
```
What's annoying is that `out._view_func()` will result in a `.as_strided` call, because `out` is an ordinary runtime tensor. This (likely?) caused a perf regression, because when running the backward, out `as_strided_backward()` is slower than our `view_backward()`.
In this PR, I added some TLS for instructing autograd to do view replay instead of as_strided, even when given a normal tensor. I'm definitely interested in thoughts from autograd folks (cc @albanD @soulitzer). A few points that I want to bring up:
(1) One reason that this API seems generally useful to me is because of the case where you `torch.compile()` a function, and you pass in two inputs that alias each other, and mutate one of the inputs. Autograd is forced to add a bunch of as_strided() calls into the graph when this happens, but this would give users an escape hatch for better compiled perf in this situation
(2) To be fair, AOT Autograd probably won't need this TLS in the long term. There's a better (more complicated) solution, where AOT Autograd manually precomputes the view chain off of graph intermediates during tracing, and re-applies them at runtime. This is kind of complicated though and feels lower priority to implement immediately.
(3) Given all of that I made the API private, but lmk what you all think.
This is a followup of https://github.com/pytorch/pytorch/pull/92255.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92588
Approved by: https://github.com/ezyang, https://github.com/albanD
Two small changes that I'm bundling together because one of them needs to touch fbcode and I'm not sure how to do stacked diffs + internal changes + land before release cut.
Remove allow_meta from ctor, and allow by default: we should be able to trace through meta with fake tensors, so in some senses it's a bit weird to expose to user to disallow this. However, it's still useful debug wise to error from time to time, so I've added an option to the config that will get back previous behavior.
Remove `throw_on_data_dependent_ops=True`: this was intended as a temporary behavior as we were smoothing things turning on the erroring. There are no uses anywhere of `throw_on_data_dependent_ops=False` I could find.
These are technically backward-incompatble, but fake tensor is new since the last release / in a private namespace, and I don't want to release it with baggage that would be hard to remove later.
Fix for https://github.com/pytorch/pytorch/issues/92877.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93993
Approved by: https://github.com/bdhirsh, https://github.com/ezyang
When integrating AOT logging with TorchInductor trace, the ability to print graphs to the console if the user specified any of the env vars was removed (in favor of using TORCH_COMPILE_DEBUG). This restores this by checking if the user set any of the aot debug variables *before* setting up the remainder of the logging, and adding a stream to stdout if any of those env vars are set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92720
Approved by: https://github.com/Chillee
Mitigates https://github.com/pytorch/pytorch/issues/91469
Changes:
- ~once_differentiable can now be parametrized to print a custom error message~
- instead of once_differentiable, we do the backward inside another custom Function, which makes sure the graph is connected, but also makes sure to error on double backward
- we now explicitly error when doing double backward with torch.compile + aot_autograd instead of being silently incorrect. ~The niceness of the error message can vary depending on whether your grad_outputs are passed, or whether you are doing `.grad()` or `.backward()`.~
Unchanged:
- doing backward inside compiled function is still allowed. It currently causes a graph break and is equivalent to doing backward outside the compiled function. It might be nice to disallow this explicitly as well, but that can be done in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92348
Approved by: https://github.com/albanD
Changes in details:
- Fix and update some out-of-date type hints in `_functorch/make_functional.py`.
- ~Explicitly use `OrderedDict` for order-sensitive mappings.~
In `create_names_map()`, `_swap_state()`, and `FunctionalModuleWithBuffers.__init__()`, the unordered `dict` was used. The key order should be preserved for `dict.items()` while it is required to `zip` with a tuple of `params`/`buffers`. Although since Python 3.6, the built-in dictionary is insertion ordered ([PEP 468](https://peps.python.org/pep-0468)). Explicit is better than implicit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91579
Approved by: https://github.com/zou3519
This PR:
- Updates the docs to say it is deprecated
- Raises a UserWarning
- Changes most of the callsites inside PyTorch to use
torch.func.functional_call, minus the test_stateless testing.
The motivation behind this is that we can now align behind a single
functional_call API in PyTorch.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92280
Approved by: https://github.com/albanD
This PR:
- adds deprecation warnings when calling the functorch APIs
- adds documentation saying that those APIs are deprecated
It does this by creating thin wrappers around the original APIs that (1)
raise deprecation warnings and (2) have an additional line in their
documentation that they are deprecated.
NB:
- Python surpresses DeprecationWarning, so we use UserWarning instead.
Test Plan:
- New tests
- the functorch.* APIs are still tested for correctness because that's
what test/functorch/* use (as opposed to directly calling the
torch.func.* APIs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92279
Approved by: https://github.com/albanD, https://github.com/soulitzer
`torch.func.stack_module_state` is our replacement for
`functorch.combine_state_for_ensemble`. The most common usage for
combine_state_for_ensemble is to
- create stacked parameters and buffers
- use vmap to run the forward pass
- use regular PyTorch autograd to run the backward pass (e.g.,
Tensor.backwrd)
- optimize directly over the stacked parameters (this is more performant
than optimizing over the unstacked parameters).
Right now, stack_module_state returns stacked parameters that cannot be
optimized directly (only leaf tensors can have a .grad field); this PR
fixes that by turning the stacked parameters back into leaf tensors.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92278
Approved by: https://github.com/soulitzer
functorch used to have a switch that enables/disables autograd.Function.
That switch now enables/disables torch.autograd.function._SingleLevelFunction, so
I've renamed it accordingly.
We could just delete the switch because users should not be directly
working with torch.autograd.function._SingleLevelFunction. However,
it was useful for debugging when something went wrong when I was
implementing the autograd.Function <> functorch interaction, so I want
to keep it around as a debugging tool for a while since the code is
already there.
Test Plan:
- updated tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92025
Approved by: https://github.com/soulitzer
We don't actually need `output_shapes` to implement
`generate_vmap_rule=True` support for autograd.Function.
- We need this in the vjp (backward) case because autograd automatically
reduces grad_inputs to inputs and we need to replicate that behavior.
In order to replicate that behavior, we recorded the original input
shapes so we know how to reduce the grad_input.
- There is no such behavior for forward-mode AD, so we don't need to
pass an `output_shapes` to reductify.
This PR simplifies the API of `reductify` and `reductify_leaf`. Instead
of accepting `input_shape_without_bdim` and `allow_expanded_grad`, we
now combine these into a single argument,
`reduce_to_input_shape_without_bdim`.
- if it is None, then we don't do anything
- if it is not-None and a shape, then we will reduce the grad to the
provided shape.
Test Plan:
- updated original unittests
- wait for test suite
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92024
Approved by: https://github.com/soulitzer
This PR:
- adds a nice error message if the user doesn't follow the API of the
vmap staticmethod correctly. That is, the user must return two
arguments from the vmap staticmethod API: (outputs, out_dims), and
out_dims must be a PyTree with either the same structure as `outputs`
our be broadcastable to the same structure as `outputs`.
- Fixes an edge case for out_dims=None. out_dims is allowed to be None,
but wrap_outputs_maintaining_identity was treating "None" as "This is
not the vmap case"
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92023
Approved by: https://github.com/soulitzer
This PR:
- changes generate_vmap_rule to either be True or False. Previously it
could be True, False, or not set. This simplifies the implementation a
bit.
- changes the vmap staticmethod to always be on the autograd.Function
rather than sometimes defined.
This is how the other staticmethod (forward, backward, jvp) are
implemented and allows us to document it.
There are 4 possible states for the autograd.Function w.r.t. to the
above:
- generate_vmap_rule is True, vmap staticmethod overriden. This raises
an error when used with vmap.
- generate_vmap_rule is False, vmap staticmethod overriden. This is
valid.
- generate_vmap_rule is True, vmap staticmethod not overriden. This is
valid.
- generate_vmap_rule is False, vmap staticmethod not overriden. This
raises an error when used with vmap.
Future:
- setup_context needs the same treatment, but that's a bit tricker to
implement.
Test Plan:
- new unittest
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91787
Approved by: https://github.com/soulitzer
Support for jvp is very similar to support for backward():
- We need to vmap over a version of the original autograd.Function's jvp
method that does not take ctx as input.
- On the output, we need to reductify to ensure the output tangent has
the same shape as the output. This reductify does not have the
extra reduction semantics, because PyTorch forward-mode AD requires the
output tangent to have the same exact shape as the output.
- setup_context needs to tell us the bdims of the saved_tensors
(necessary for vmap over jvp_no_context), as well
as the output shapes (necessary for reductify).
Test Plan:
- Added jvp support to the *GenVmapAutogradFunction
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91211
Approved by: https://github.com/soulitzer
This PR adds functionalization path for torch.cond. As it is the first pass, we only functionalize for very restrictive use cases. We explicitly restrict following:
- Output of each branch aliasing input
- In-place mutation on inputs given to each branch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89966
Approved by: https://github.com/zou3519
It turns out that we *do* need to update *_scatter ops to return the exact same strides as their inputs. I added a test to `test/test_functionalization.py`, which now trips thanks to Ed's functionalization stride debugging check. It only actually ends up tripping silent correctness if you try to .backward() on that function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91029
Approved by: https://github.com/ezyang
Design document:
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
This PR adds a `generate_vmap_rule` option (default False) to autograd.Function.
By setting it to True, a user promises to us that their autograd.Function's
{forward, backward, jvp}, if defined, only uses PyTorch operations, in addition to the other
limitations of autograd.Function+functorch (such as the user not
capturing any Tensors being transformed over from outside of the
autograd.Function).
Concretely, the approach is:
- we update `custom_function_call` to accept an additional
`generate_vmap_rule` argument.
- The vmap rule for `custom_function_call` and `generate_vmap_rule=True`
is: we construct a vmapped version of the autograd.Function and dispatch
on it.
- The vmapped version of the autograd.Function can be thought of like
the following: if we have an autograd.Function Foo, then
VmappedFoo.apply(in_dims, ...) has the same semantics as
vmap(Foo.apply, in_dims...)
- VmappedFoo's forward, setup_context, and backward staticmethod are
vmapped versions of Foo's staticmethods.
- See the design doc for more motivation and explanation
Test Plan:
- This PR introduces additional autograd.Function with the suffix "GenVmap" to
autograd_function_db.
- There are also some minor UX tests
Future:
- jvp support
- likely more testing to come, but please let me know if you have
cases that you want me to test here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90966
Approved by: https://github.com/soulitzer
As seen in
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
`reductify_leaf(grad_input, ...)` is a helper function that processes a
single grad_input Tensor. The reason why we need it is:
- the grad_input has some optional bdim
- the input has some optional bdim
- if these are different, we need to coerce the grad_input into having
the same shape as the input, either by reducing or expanding the
grad_input.
Note that there is a special case in autograd that the user is allowed
to return a grad_input Tensor that is an expanded version of the
original input tensor. In this case, autograd automatically reduces
grad_input to the same shape as the input. Unfortunately this logic
doesn't work when bdims are involved, so we manually handle it in
`reductify_leaf`.
Test Plan:
- tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90965
Approved by: https://github.com/soulitzer
As seen in
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
`restore_vmap` is a private helper function. It is vmap but has the
following
differences:
- instead of returning outputs, it returns an (outputs, out_dims) tuple.
out_dims is a pytree of shape shape as outputs and contains Optional[int]
specifying where the vmapped dimension, if it exists, is in the
corresponding output.
- does no validation on in_dims or inputs (vmap expects at least one
Tensor to be vmapped).
restore_vmap allows for no inputs to have the vmap dimension
- does no validation on outputs (vmap expects only Tensor outputs)
restore_vmap allows for return of arbitrary outputs (not just
Tensors)
Test Plan:
- added some simple test to test restore_vmap
- I am OK with restore_vmap not being a part of vmap right now -- the
implementation of vmap rarely changes and it is a bit difficult to
refactor vmap in a way that restore_vmap is a subroutine.
Other questions:
- Bikeshedding the `restore_vmap` name
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90963
Approved by: https://github.com/samdow, https://github.com/soulitzer
This PR sets up torch.func and populates it with the following APIs:
- grad
- grad_and_value
- vjp
- jvp
- jacrev
- jacfwd
- hessian
- functionalize
- vmap
It also renames all instances of `functorch` in the APIs for those docs
to `torch.func`.
We rewrite the `__module__` fields on some of the above APIs so that the
APIs fit PyTorch's public api definition.
- For an API to be public, it must have a `__module__` that points to a
public PyTorch submodule. However, `torch._functorch.eager_transforms`
is not public due to the leading underscore.
- The solution is to rewrite `__module__` to point to where the API is
exposed (torch.func). This is what both Numpy and JAX do for their
APIs.
- h/t pmeier in
https://github.com/pytorch/pytorch/issues/90284#issuecomment-1348595246
for idea and code
- The helper function, `exposed_in`, is confined to
torch._functorch/utils for now because we're not completely sure if
this should be the long-term solution.
Implication for functorch.* APIs:
- functorch.grad is the same object as torch.func.grad
- this means that the functorch.grad docstring is actually the
torch.func.grad docstring and will refer to torch.func instead of
functorch.
- This isn't really a problem since the plan on record is to deprecate
functorch in favor of torch.func. We can fix these if we really want,
but I'm not sure if a solution is worth maintaining.
Test Plan:
- view docs preview
Future:
- vmap should actually just be torch.vmap. This requires an extra step
where I need to test internal callsites, so, I'm separating it into a
different PR.
- make_fx should be in torch.func to be consistent with `import
functorch`. This one is a bit more of a headache to deal with w.r.t.
public api, so going to deal with it separately.
- beef up func.rst with everything else currently on the functorch
documention website. func.rst is currently just an empty shell.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91016
Approved by: https://github.com/samdow
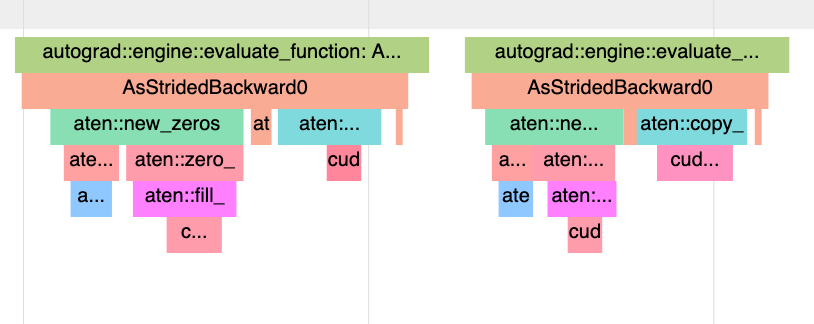
This should fix hf_Longformer, AllenaiLongformerBase, and tacotron2 with dynamic shapes. Example repro:
```
TORCHDYNAMO_DYNAMIC_SHAPES=1 AOT_DYNAMIC_SHAPES=1 python benchmarks/dynamo/torchbench.py --accuracy --backend aot_eager --training --only hf_Longformer
```
used to fail with:
```
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [4, 1024, 12, 513]], which is output 0
of AsStridedBackward0, is at version 6; expected version 4 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient,
with torch.autograd.set_detect_anomaly(True).
```
The problem is that:
(1) when we have a tensor from the forward, whose sizes are needed the backward, we were saving the actual tensor for backward, and directly grabbing the sizes off of it inside of the backward graph (bad for perf)
(2) If that tensor happens to be a graph input that gets mutated, we end up with the above error. Autograd yells at you if you try to save a tensor for backward, and later mutate it.
I confirmed that this problem doesn't happen for the min cut partitioner.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91012
Approved by: https://github.com/ezyang
This PR:
- adds VmapInterpreter.randomness. This returns the randomness option
the user provided in vmap(..., randomness=...)
- adds randomness in the info object passed to the vmap staticmethod of
autograd.Function. This is so that the user can handle random operations
on their own terms (if randomness="error", and if the autograd.Function
has random operations, then it is the user's responsiblity to raise an
error).
Test Plan:
- updated unittest
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90789
Approved by: https://github.com/samdow, https://github.com/soulitzer
It turns out it is possible to break cycles by not directly importing a
module:
- there's a problem that torch.jit imports torch._ops and torch._ops
import torch.jit
- there's another problem that torch.autograd.function imports
custom_function_call but torch._functorch.autograd_function imports
torch.autograd.function
The "better" way to handle all of this is to do some large refactoring so
that torch._functorch.autograd_function imports some file that has
_SingleLevelAutogradFunction and then have torch.autograd.function
depend on torch.functorch.autograd_function... (and ditto for torch.jit
vs torch._ops), but I'm scared to move code around too much for BC
reasons and the fix in this PR works well.
Test Plan:
- import torch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90415
Approved by: https://github.com/albanD, https://github.com/soulitzer
This PR adds functorch.jvp support for autograd.Function. It does so by
adding a jvp rule for custom_function_call.
For a regular PyTorch operation (like at::sin), the VariableType kernel:
- re-dispatches to at::sin
- calls the jvp rule for at::sin
The jvp rule for custom_function_call does just that. It constructs a
new autograd.Function (because the above logic already exists). Inside
the forward, it re-dispatches to custom_function_call. In the jvp rule,
it just calls whatever the jvp rule is supposed to be.
Since this logic is really close to the custom_function_call_grad, I
just put them together.
Test Plan:
- added jvp rules to the autograd.Function in autograd_function_db
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90077
Approved by: https://github.com/albanD, https://github.com/soulitzer
Motivation
- These were previously defined in functorch. They are not
functorch-specific, so I'm moving them to torch.autograd.forward_ad and
the autograd python bindings.
- I need this to avoid some of my cyclic import problems.
Should these be public APIs? Probably. Though this needs discussion, so
punting it to the future.
Test Plan:
- moved the tests of these from test/functorch/test_eager_transforms.py
to test/test_autograd.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90240
Approved by: https://github.com/soulitzer
This PR adds a `vmap` staticmethod to autograd.Function and a
corresponding vmap kernel for custom_function_call. These two items mean
that autograd.Function with a vmap staticmethod can be used with vmap.
```py
class NumpyMul(torch.autograd.Function)
staticmethod
def forward(x, y):
return torch.tensor(to_numpy(x) * to_numpy(y), device=x.device)
staticmethod
def setup_context(ctx, outputs, x, y):
ctx.save_for_backward(x, y)
staticmethod
def backward(ctx, grad_output):
x, y = ctx.saved_tensors
gx = None
if isinstance(x, torch.Tensor) and x.requires_grad:
gx = NumpyMul.apply(grad_output, y)
gy = None
if isinstance(y, torch.Tensor) and y.requires_grad:
gy = NumpyMul.apply(grad_output, x)
return gx, gy
staticmethod
def vmap(info, in_dims, x, y):
x_bdim, y_bdim = in_dims
x = x.movedim(x_bdim, -1) if x_bdim else x.unsqueeze(-1)
y = y.movedim(y_bdim, -1) if y_bdim else y.unsqueeze(-1)
result = NumpyMul.apply(x, y)
result = result.movedim(-1, 0)
return result, 0
```
API Spec
- the staticmethod takes two arguments (info, in_dims) as well as the
unexpanded inputs (x, y).
- If we think about it as `vmap(info, in_dims, *args)`, `in_dims` is a
pytree with the same tree structure as args. It has None if the arg is
not being vmapped over and an integer vmapped dimension index if it is.
- `info` is an object with metadata about the vmap. It currently has one
field, `info.batch_size`. In the future we can extend this by adding
things like the randomness information.
- If there is a single vmap going on, (x, y) are NOT BatchedTensors,
they've already been unpacked.
- We expect the user to return a `(outputs, out_dims)` tuple. `out_dims`
must "broadcast" to the same pytree structure as `outputs`.
Semantics
- vmap(NumpyMul.apply)(x) will apply the vmap staticmethod if there is
one and will never actually run NumpyMul.forward.
- In order for the autograd.Function to support nested vmap (e.g.,
`vmap(vmap(NumpyMul.apply))(x)`, then the vmap staticmethod must call
into operations that vmap understands (i.e. PyTorch operators or more
autograd.Function).
At a high level, this PR:
- adds a vmap rule for custom_function_call
Testing
- Added some tests for in_dims and info
- Added vmap staticmethod to most of the autograd.Function in
autograd_function_db and sent them through functorch's vmap-related
OpInfo tests
Future
- Better error messages if the user gets the return contract wrong. I
didn't include them in this PR because it might involve a refactor of
some of the existing code in functorch/_src/vmap.py that will add
~200LOC to the PR, but LMK if you'd prefer it here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90037
Approved by: https://github.com/samdow, https://github.com/soulitzer
- Adds `log_level` to aot's config
- Outputs log to `<graph_name>_<log_level>.log` in aot_torchinductor subfolder of the debug directory
- Modifies the Inductor debug context to use the graph name when naming the folder instead of the os pid
- Adds `TORCH_COMPILE_DEBUG` flag to enable it, (as well as separate dynamo and inductor logs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88987
Approved by: https://github.com/Chillee
Happy to split this PR more if it helps.
This PR adds functorch.grad support for autograd.Function. There's a lot
going on; here is the high level picture and there are more details as
comments in the code.
Mechanism (PyOperator)
- Somehow, autograd.Function needs to dispatch with functorch. This is
necessary because every layer of functorch needs to see the
autograd.Function; grad layers need to preserve the backward pass.
- The mechanism for this is via PyOperator. If functorch transforms are
active, then we wrap the autograd.Function in a `custom_function_call`
PyOperator where we are able to define various rules for functorch
transforms.
- `custom_function_call` has a rule for the functorch grad transform.
autograd.Function changes
- I needed to make some changes to autograd.Function to make this work.
- First, this PR splits autograd.Function into a _SingleLevelFunction
(that works with a single level of functorch transform) and
autograd.Function (which works with multiple levels). This is necessary
because functorch's grad rule needs some way of specifying a backward
pass for that level only.
- This PR changes autograd.Function's apply to eitehr call
`custom_function_call` (if functorch is active) or super().apply (if
functorch isn't active).
Testing
- Most of this PR is just testing. It creates an autograd.Function
OpInfo database that then gets passed to the functorch grad-based tests
(grad, vjp, vjpvjp).
- Since functorch transform tests are autogenerated from OpInfo tests,
this is the easiest way to test various autograd.Function with
functorch.
Future
- jvp and vmap support coming next
- better error message (functorch only supports autograd.Function that
have the optional setup_context staticmethod)
- documentation to come when we remove the feature flag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89860
Approved by: https://github.com/soulitzer
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90091
Approved by: https://github.com/anijain2305, https://github.com/ezyang
{kind=link}
{kind=link}
{kind=link}