From talking to @wconstab, we agreed that because of the way DDPOptimizer is written, it is (sort of) incompatible with inductor's `keep_output_stride=False` optimizations (and will cause silent correctness problems if you use them ogether). Added an assertion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108235
Approved by: https://github.com/wconstab
ghstack dependencies: #108081
This reworks the DORT backend factory function to support the options kwarg of torch.compile, and defines a concrete OrtBackendOptions type that can be used to influence the backend.
Caching is also implemented in order to reuse backends with equal options.
Wrapping the backend in auto_autograd also becomes an option, which allows `OrtBackend` to always be returned as the callable for torch.compile; wrapping happens internally if opted into (True by default).
Lastly, expose options for configuring preferred execution providers (will be attempted first), whether or not to attempt to infer an ORT EP from a torch found device in the graph or inputs, and finally the default/fallback EPs.
### Demo
The following demo runs `Gelu` through `torch.compile(backend="onnxrt")` using various backend options through a dictionary form and a strongly typed form. It additionally exports the model through both the ONNX TorchScript exporter and the new TorchDynamo exporter.
```python
import math
import onnx.inliner
import onnxruntime
import torch
import torch.onnx
torch.manual_seed(0)
class Gelu(torch.nn.Module):
def forward(self, x):
return x * (0.5 * torch.erf(math.sqrt(0.5) * x) + 1.0)
@torch.compile(
backend="onnxrt",
options={
"preferred_execution_providers": [
"NotARealEP",
"CPUExecutionProvider",
],
"export_options": torch.onnx.ExportOptions(dynamic_shapes=True),
},
)
def dort_gelu(x):
return Gelu()(x)
ort_session_options = onnxruntime.SessionOptions()
ort_session_options.log_severity_level = 0
dort_gelu2 = torch.compile(
Gelu(),
backend="onnxrt",
options=torch.onnx._OrtBackendOptions(
preferred_execution_providers=[
"NotARealEP",
"CPUExecutionProvider",
],
export_options=torch.onnx.ExportOptions(dynamic_shapes=True),
ort_session_options=ort_session_options,
),
)
x = torch.randn(10)
torch.onnx.export(Gelu(), (x,), "gelu_ts.onnx")
export_output = torch.onnx.dynamo_export(Gelu(), x)
export_output.save("gelu_dynamo.onnx")
inlined_model = onnx.inliner.inline_local_functions(export_output.model_proto)
onnx.save_model(inlined_model, "gelu_dynamo_inlined.onnx")
print("Torch Eager:")
print(Gelu()(x))
print("DORT:")
print(dort_gelu(x))
print(dort_gelu2(x))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107973
Approved by: https://github.com/BowenBao
This PR adds support for `enable_grad`/`no_grad`/`autocast` context managers getting properly traced in `pre_dispatch` tracing. The stuff in this PR includes:
- I added a torch function mode that runs during make_fx pre_dispatch tracing, `ProxyTorchFunctionMode`. It directly intercepts the torch ops that run during the above context managers, and adds them to the current graph instead of executing them
- `enable_grad` and `no_grad` currently desugar into `torch._C.set_grad_enabled(bool)`, but this API isn't currently overrideable by torch function so I added the ability to interpose there
- the `torch.amp` context managers don't currently have a nice equivalent, like `set_autocast_enabled(state)`, so I ended up adding two new API's: `torch.amp._set_autocast_enabled` and `torch.amp._set_autocast_disabled`. If you look at how the context manager is implemented, it ends up calling several different state-changing functions, some of which depend on the backend - so I figured that it would be cleaner just to add a new API (that should probably only be used by tracing) - but open to feedback
- I added a new dynamo backend, `compile(backend="pre_dispatch_eager")`. When pre_dispatch tracing becomes always-on in inductor, it will be another potential surface for bugs. I also added a test file for it (`test/dynamo/test_pre_dispatch.py`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103024
Approved by: https://github.com/ezyang
default_partitioner is kind of broken when it comes to memory footprint. Moving aot_eager to use min-cut partitioner is better debugging experience.
One bad thing though would be that we will much lower speedup numbers, because min cut partitioner will try to recompute ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103555
Approved by: https://github.com/eellison, https://github.com/jansel
Subgraphs are partitions cut out of a whole graph. Outputs of a subgraph are either global outputs of the original graph, or can be outputs of a partition that feed inputs of the subsequent partition. Subgraphs are created using the fx utility 'passes.split_module', which requires that each partition
have at least one output node.
In cases where DDPOptimizer asked the partitioner to cut the graph around a set of nodes which only
performed inplace mutation, the partitioner could be left trying to create a subgraph with no output nodes, violating its assumptions.
To circumvent this, DDPOptimizer can expand the set of nodes marked for inclusion in a subgraph that has no outputs until it includes a node that is an output for that subgraph. It still traverses nodes of the original graph in reverse order and only considers widening a subgraph by iterating further in reverse order than it would have ordinarily done (past the cut point dictated by paramter count). It may still be possible the subgraph reaches the input node of the graph without satisfying the subgraph-output condition, in which case an error would still be raised by the partitioner.
Fixes#103385
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103488
Approved by: https://github.com/anijain2305
# torch.compiler public API
## Goal
The goal of this document is to describe the public facing API for torchdynamo and torchinductor.
Today both dynamo and torchinductor are in `torch/_dynamo` and `torch/_inductor` namespace with the only public function
`torch.compile()` which is directly placed in `torch/__init__.py`
This poses a few problems for users trying to take dependencies on PyTorch 2.0
1. Unclear BC guarantees
2. No builtin discovery mechanism outside of reading the source code
3. No hard requirements for docstrings or type annotations
Most importantly it mixes two personas the PyTorch 2.0 developer vs the PyTorch 2.0 customer so this is an attempt to address this. We draw a lot of inspiration from the `functorch` migration to the `func` namespace.
## Alternate names
We did discuss some other alternative names
1. `torch.compile` -> problem is this would break BC on the existing `torch.compile` function
2. `torch.dynamo` -> `dynamo` is so far not something we've deliberately hidden from users but problem is now figuring out what it's `_dynamo` vs `dynamo` might be confusing
3. `torch.compiler` -> 1 would be better but to keep BC this is a good compromise
# The general approach
## Proposal 1
In https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py
We have function called `reset()`, this function is essential if users are trying to `torch.compile()` a model under different settings
```python
# in _dynamo/
def reset():
do_reset_stuff()
```
Instead we propose
```python
# in compiler/
def reset():
do_reset_stuff() # As in copy paste the logic from _dynamo.reset
# in _dynamo/
import warnings
import inspect
def reset():
function_name = inspect.currentframe().f_code.co_name
warnings.warn(f"{function_name} is deprecated, use compiler.{function_name} instead", DeprecationWarning)
return compiler.reset()
```
## Proposal 2
```python
# in compiler/
def reset():
“””
Docstrings here
“””
_dynamo.reset()
# in _dynamo/
No changes
```
Consensus so far seems to be proposal 2 since fewer warnings will be less jarring and it’ll make it quite easy to merge the public API
## Docstrings
The above was an example of a function that has no inputs or outputs but there are other functions which could use an improvement in their docstrings, for example allow_in_graph actually works over lists of functions but that’s not mentioned anywhere in the example only if you read the source code.
def allow_in_graph(fn):
"""
Customize which functions TorchDynamo will include in the generated
graph. Similar to `torch.fx.wrap()`.
Parameters:
fn (callable or list/tuple): The function(s) to be allowed in the graph.
Returns:
callable or list/tuple: The input function(s) included in the graph.
Examples:
Customize inclusion of a single function:
::
torch._dynamo.allow_in_graph(my_custom_function)
Customize inclusion of multiple functions:
::
torch._dynamo.allow_in_graph([my_custom_function1, my_custom_function2])
@torch._dynamo.optimize(...)
def fn(a):
x = torch.add(x, 1)
x = my_custom_function(x)
x = torch.add(x, 1)
return x
fn(...)
Notes:
The `allow_in_graph` function allows customization of which functions TorchDynamo
includes in the generated graph. It can be used to include specific functions that
are not automatically captured by TorchDynamo.
If `fn` is a list or tuple, `allow_in_graph` will be called recursively on each
element in the sequence.
Once a function is allowed in the graph using `allow_in_graph`, it will be captured
in the graph generated by TorchDynamo. This customization enables more fine-grained
control over the functions included in the graph.
Note that `allow_in_graph` expects the input `fn` to be a callable.
"""
if isinstance(fn, (list, tuple)):
return [allow_in_graph(x) for x in fn]
assert callable(fn), "allow_in_graph expects a callable"
allowed_functions._allowed_function_ids.add(id(fn))
allowed_functions._disallowed_function_ids.remove(id(fn))
return fn
So to make the API public, we’d have to write similar docstrings for all public functions we’d like to create.
The benefit of this approach is that
1. No BC risks, internal and external users relying on our tooling can slowly wean off the private functions.
2. We will also have to write correct docstrings which will automatically make our documentation easier to maintain and render correctly on pytorch.org
3. We already have some BC guarantees already, we don’t kill OptimizedModule, we rejected the PR to change the config system
The con of this approach is that
Will be stuck with some potentially suboptimal functions/classes that you can’t kill
## Testing strategy
If the approach is to mostly make a public function call an already tested private function then all we need to do is ensure that the function signatures don't change
## Which functions should be in the public API
Our heuristic for deciding whether something should be public or not is are users already relying on it for lack of other options or have we recommended some non public functions for users to debug their PT 2.0 programs.
Heuristic for not putting something in public is that it’s an experimental subsystem with the goal of turning it on by default, it’s very core dev centric, meta centric, a bunch of different configs that should be batched into a single user facing one, or something that needs to be renamed because the name is confusing
#### Top level
`torch.compile()` -> already is a public API it does require some minor improvements like having configs be passed in to any backend and not just inductor (EDIT: This was already done https://github.com/pytorch/pytorch/pull/99645l) and renaming `mode=reduce-overhead` to `mode=cudagraph`
To make sure that PT 2.0 is supported with a given pytorch version users can create a new public function and this would replace the need for `try/except` blocks around `import torch._dynamo` that has been populating user code.
```python
def pt2_enabled():
if hasattr(torch, 'compile'):
return True
else:
return False
```
For all of the below they will be translated to `torch.compiler.function_name()`
#### From _dynamo
As a starting point we looked at https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py and we suggest redefining these functions in `pytorch/torch/compiler/__init__.py`
It might also make sense to split them over multiple files and import them in `__init__.py` but because the number of functions is small it'd probably be fine to add them all into a single compiler/__init__.py until this list becomes larger
1. `reset()`
2. `allow_in_graph()`
10. `list_backends()`
12. `compile()`: torch.compile() would be mostly a shell function passing arguments to torch.compiler.compile()
13. `assume_constant_result()`: TODO: Double check how this is useful
15. `torch._dynamo.disable()`
Some notable omissions
11. `explain()`: We need to clean up the output for this function, make it a data class and pretty printable
1. `forbid_in_graph()`: Considered adding this but should instead consolidate on `disallow_in_graph`
2. `optimize_assert()`: Already covered by `torch.compile(fullgraph=True)`
3. `check_if_dynamo_supported()`: this would be supplanted by pt2_enabled()
4. `compilation_metrics`, `graph_breaks_reasons` ..: would all be accessed via `torch.compiler.explain()`
5. `replay` does not seem useful to end customers
6. . `graph_break()`: Mostly useful for debugging or unit tests
9. `register_backend()`: End users will just pass a string backend to torch.compile, only devs will create new backends
10. `export()` : Eventually this needs to public but for now it’s not ready so just highlighting that it will be in the public API eventually
11. `disallow_in_graph()`: Usage is limited
12. `mark_static()`: we can keep this private until dynamic=True is recommended in stable
13. `mark_dynamic()`: we can keep this private until dynamic=True is recommended in trunk
14. 8. `OptimizedModule`: This is the only class that we'd expose but is crucial since users are running code like `if isinstance(mod, OptimizedModule): torch.save(mod._orig_mod)` EDIT: because we fixed pickling we no longer need to
expose this
15. `is_compiling()`: Still not clear how this useful to end users
There are also config variables which we need to expose https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/config.py
Some of our configs are useful dev flags, others are to gate experimental functionality and others are essential debugging tools and we seperate out the essential debugging and logging tools to a public facing config.
TODO: I still need to think of a good way of porting the config in a BC way here are some ideas
1. Just make all passes available and controllable via `torch.compile(options={})` but only show docstrings for the ones users should care about.
The current problem with our config system is we have 3 ways of setting them once via `options={}`, environment variables and variables in `config.py`, it'd be worth settling on one source of truth and have that be the public API.
The configs we should make public are
1. `log_file_name`
2. `verbose`
3. `cache_size_limit`
4. `repro_level` and `repro_after`: Although we can rename these to minifier and give human readable names to the levels
Everything else should stay private in particular
1. `print_graph_breaks`, `print_specializations`: should be supplanted by `explain()` for public users
2. dynamic shape configs : Users should only have to worry about `torch.compile(dynamic=True/False)`
3. The distributed flags, hook or guard configs: If we tell a user to use FSDP and DDP then the flag should be enabled by default or be in a private namespace
4. The fbcode flags: Obviously no need to be user facing
5. Skip/Allow lists: Not something normal users should play around with
#### From _inductor
Very little of inductor should be exposed in a public facing API, our core audience as in people writing models mostly just need information on what certain passes mean and how to control them a high level and they can do this with `torch.compile(options={})` so the goal here should be more to make available passes clearer and ideally consolidate them into `torch.compile()` docstrings or modes.
There are some exceptions though from https://github.com/pytorch/pytorch/blob/main/torch/_inductor/__init__.py
1. `list_mode_options()`
2. `list_options()`: this needs an additional pass to hide internal or debug options
For both of these we’d rename them to compiler.inductor_list_mode_options and compiler.inductor_list_options() since they would be in the same init file as the one for dynamo
Notable omissions
1. `_inductor.compile()`: Because of users are coming in with their own fx graph, they are likely developers
2. `_inductor.aot_compile()`:Again this is about capturing and modifying fx graphs so users APIs don't need to be public
However the configs are a slightly different story, because we can choose to either
1. Make all configs public
2. Make some configs public and keep most of the private ones. If public config is set it should override the private version
3. Make all configs controllable via `torch.compile(options={})` but make list_options() hide more things
For now 3 seems like the most reasonable choice with some high level configs we’ll keep like TORCH_COMPILE_DEBUG
Regardless here's what should probably be public or advertised more
1. `disable_progress` and verbose_progress: Combine and enable by default
2. `fallback_random`: We could make the case this shouldn't be public if a top level deterministic mode enables this
3. `profile_bandwidth`: Or could make the case that this should be in TORCH_COMPILE_DEBUG
Notable omissions
1. Any config that would generally improve performance for most that we should probably enable by default but might be disabled in the short term because of stability: example `epilogue_fusion`, `pattern_matcher`, `reordering`
2. Autotuning flags: Should just sit behind `torch.compile(mode="max-autotune")` like `max_autotune`, `max_autotune_gemm`
3. `coordinate_descent_tuning`: This one I'm a but mixed about, maybe it just also fall into `mode="max-autotune"`
4. `trace`: `TORCH_COMPILE_DEBUG` is the best flag for all of this
5. `triton.cudagraphs`: Default should be `torch.compile(mode="reduce-overhead")` - I'd go further and rename the `mode=cudagraph` and we can keep reduce-overhead for BC reasons
6. `triton_unique_kernel_names`: Mostly useful for devs debugging
7. `dce`: which doesnt really do anything
8. `shape_padding`: Elias is working on enabling this by default in which case we also remove it
## Mechanics
This PR would include the public functions with their docstrings
Another PR will take a stab at the configs
And for work where the APIs are still being cleaned up whether its minifier or escape hatches, export or dynamic shapes, aot_inductor etc.. we’ll keep them private until a public commitment can be made
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102182
Approved by: https://github.com/jansel, https://github.com/albanD
- Don't copy inputs in cudagraphs wrapping, since the copies will distorts timing and triton do_bench will clear cache anyway
- Don't skip op if there is a fallback, since we have both fallbacks and lowerings for some ops
- Add option for channels last
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103110
Approved by: https://github.com/desertfire
# torch.compiler public API
## Goal
The goal of this document is to describe the public facing API for torchdynamo and torchinductor.
Today both dynamo and torchinductor are in `torch/_dynamo` and `torch/_inductor` namespace with the only public function
`torch.compile()` which is directly placed in `torch/__init__.py`
This poses a few problems for users trying to take dependencies on PyTorch 2.0
1. Unclear BC guarantees
2. No builtin discovery mechanism outside of reading the source code
3. No hard requirements for docstrings or type annotations
Most importantly it mixes two personas the PyTorch 2.0 developer vs the PyTorch 2.0 customer so this is an attempt to address this. We draw a lot of inspiration from the `functorch` migration to the `func` namespace.
## Alternate names
We did discuss some other alternative names
1. `torch.compile` -> problem is this would break BC on the existing `torch.compile` function
2. `torch.dynamo` -> `dynamo` is so far not something we've deliberately hidden from users but problem is now figuring out what it's `_dynamo` vs `dynamo` might be confusing
3. `torch.compiler` -> 1 would be better but to keep BC this is a good compromise
# The general approach
## Proposal 1
In https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py
We have function called `reset()`, this function is essential if users are trying to `torch.compile()` a model under different settings
```python
# in _dynamo/
def reset():
do_reset_stuff()
```
Instead we propose
```python
# in compiler/
def reset():
do_reset_stuff() # As in copy paste the logic from _dynamo.reset
# in _dynamo/
import warnings
import inspect
def reset():
function_name = inspect.currentframe().f_code.co_name
warnings.warn(f"{function_name} is deprecated, use compiler.{function_name} instead", DeprecationWarning)
return compiler.reset()
```
## Proposal 2
```python
# in compiler/
def reset():
“””
Docstrings here
“””
_dynamo.reset()
# in _dynamo/
No changes
```
Consensus so far seems to be proposal 2 since fewer warnings will be less jarring and it’ll make it quite easy to merge the public API
## Docstrings
The above was an example of a function that has no inputs or outputs but there are other functions which could use an improvement in their docstrings, for example allow_in_graph actually works over lists of functions but that’s not mentioned anywhere in the example only if you read the source code.
def allow_in_graph(fn):
"""
Customize which functions TorchDynamo will include in the generated
graph. Similar to `torch.fx.wrap()`.
Parameters:
fn (callable or list/tuple): The function(s) to be allowed in the graph.
Returns:
callable or list/tuple: The input function(s) included in the graph.
Examples:
Customize inclusion of a single function:
::
torch._dynamo.allow_in_graph(my_custom_function)
Customize inclusion of multiple functions:
::
torch._dynamo.allow_in_graph([my_custom_function1, my_custom_function2])
@torch._dynamo.optimize(...)
def fn(a):
x = torch.add(x, 1)
x = my_custom_function(x)
x = torch.add(x, 1)
return x
fn(...)
Notes:
The `allow_in_graph` function allows customization of which functions TorchDynamo
includes in the generated graph. It can be used to include specific functions that
are not automatically captured by TorchDynamo.
If `fn` is a list or tuple, `allow_in_graph` will be called recursively on each
element in the sequence.
Once a function is allowed in the graph using `allow_in_graph`, it will be captured
in the graph generated by TorchDynamo. This customization enables more fine-grained
control over the functions included in the graph.
Note that `allow_in_graph` expects the input `fn` to be a callable.
"""
if isinstance(fn, (list, tuple)):
return [allow_in_graph(x) for x in fn]
assert callable(fn), "allow_in_graph expects a callable"
allowed_functions._allowed_function_ids.add(id(fn))
allowed_functions._disallowed_function_ids.remove(id(fn))
return fn
So to make the API public, we’d have to write similar docstrings for all public functions we’d like to create.
The benefit of this approach is that
1. No BC risks, internal and external users relying on our tooling can slowly wean off the private functions.
2. We will also have to write correct docstrings which will automatically make our documentation easier to maintain and render correctly on pytorch.org
3. We already have some BC guarantees already, we don’t kill OptimizedModule, we rejected the PR to change the config system
The con of this approach is that
Will be stuck with some potentially suboptimal functions/classes that you can’t kill
## Testing strategy
If the approach is to mostly make a public function call an already tested private function then all we need to do is ensure that the function signatures don't change
## Which functions should be in the public API
Our heuristic for deciding whether something should be public or not is are users already relying on it for lack of other options or have we recommended some non public functions for users to debug their PT 2.0 programs.
Heuristic for not putting something in public is that it’s an experimental subsystem with the goal of turning it on by default, it’s very core dev centric, meta centric, a bunch of different configs that should be batched into a single user facing one, or something that needs to be renamed because the name is confusing
#### Top level
`torch.compile()` -> already is a public API it does require some minor improvements like having configs be passed in to any backend and not just inductor (EDIT: This was already done https://github.com/pytorch/pytorch/pull/99645l) and renaming `mode=reduce-overhead` to `mode=cudagraph`
To make sure that PT 2.0 is supported with a given pytorch version users can create a new public function and this would replace the need for `try/except` blocks around `import torch._dynamo` that has been populating user code.
```python
def pt2_enabled():
if hasattr(torch, 'compile'):
return True
else:
return False
```
For all of the below they will be translated to `torch.compiler.function_name()`
#### From _dynamo
As a starting point we looked at https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py and we suggest redefining these functions in `pytorch/torch/compiler/__init__.py`
It might also make sense to split them over multiple files and import them in `__init__.py` but because the number of functions is small it'd probably be fine to add them all into a single compiler/__init__.py until this list becomes larger
1. `reset()`
2. `allow_in_graph()`
10. `list_backends()`
12. `compile()`: torch.compile() would be mostly a shell function passing arguments to torch.compiler.compile()
13. `assume_constant_result()`: TODO: Double check how this is useful
15. `torch._dynamo.disable()`
Some notable omissions
11. `explain()`: We need to clean up the output for this function, make it a data class and pretty printable
1. `forbid_in_graph()`: Considered adding this but should instead consolidate on `disallow_in_graph`
2. `optimize_assert()`: Already covered by `torch.compile(fullgraph=True)`
3. `check_if_dynamo_supported()`: this would be supplanted by pt2_enabled()
4. `compilation_metrics`, `graph_breaks_reasons` ..: would all be accessed via `torch.compiler.explain()`
5. `replay` does not seem useful to end customers
6. . `graph_break()`: Mostly useful for debugging or unit tests
9. `register_backend()`: End users will just pass a string backend to torch.compile, only devs will create new backends
10. `export()` : Eventually this needs to public but for now it’s not ready so just highlighting that it will be in the public API eventually
11. `disallow_in_graph()`: Usage is limited
12. `mark_static()`: we can keep this private until dynamic=True is recommended in stable
13. `mark_dynamic()`: we can keep this private until dynamic=True is recommended in trunk
14. 8. `OptimizedModule`: This is the only class that we'd expose but is crucial since users are running code like `if isinstance(mod, OptimizedModule): torch.save(mod._orig_mod)` EDIT: because we fixed pickling we no longer need to
expose this
15. `is_compiling()`: Still not clear how this useful to end users
There are also config variables which we need to expose https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/config.py
Some of our configs are useful dev flags, others are to gate experimental functionality and others are essential debugging tools and we seperate out the essential debugging and logging tools to a public facing config.
TODO: I still need to think of a good way of porting the config in a BC way here are some ideas
1. Just make all passes available and controllable via `torch.compile(options={})` but only show docstrings for the ones users should care about.
The current problem with our config system is we have 3 ways of setting them once via `options={}`, environment variables and variables in `config.py`, it'd be worth settling on one source of truth and have that be the public API.
The configs we should make public are
1. `log_file_name`
2. `verbose`
3. `cache_size_limit`
4. `repro_level` and `repro_after`: Although we can rename these to minifier and give human readable names to the levels
Everything else should stay private in particular
1. `print_graph_breaks`, `print_specializations`: should be supplanted by `explain()` for public users
2. dynamic shape configs : Users should only have to worry about `torch.compile(dynamic=True/False)`
3. The distributed flags, hook or guard configs: If we tell a user to use FSDP and DDP then the flag should be enabled by default or be in a private namespace
4. The fbcode flags: Obviously no need to be user facing
5. Skip/Allow lists: Not something normal users should play around with
#### From _inductor
Very little of inductor should be exposed in a public facing API, our core audience as in people writing models mostly just need information on what certain passes mean and how to control them a high level and they can do this with `torch.compile(options={})` so the goal here should be more to make available passes clearer and ideally consolidate them into `torch.compile()` docstrings or modes.
There are some exceptions though from https://github.com/pytorch/pytorch/blob/main/torch/_inductor/__init__.py
1. `list_mode_options()`
2. `list_options()`: this needs an additional pass to hide internal or debug options
For both of these we’d rename them to compiler.inductor_list_mode_options and compiler.inductor_list_options() since they would be in the same init file as the one for dynamo
Notable omissions
1. `_inductor.compile()`: Because of users are coming in with their own fx graph, they are likely developers
2. `_inductor.aot_compile()`:Again this is about capturing and modifying fx graphs so users APIs don't need to be public
However the configs are a slightly different story, because we can choose to either
1. Make all configs public
2. Make some configs public and keep most of the private ones. If public config is set it should override the private version
3. Make all configs controllable via `torch.compile(options={})` but make list_options() hide more things
For now 3 seems like the most reasonable choice with some high level configs we’ll keep like TORCH_COMPILE_DEBUG
Regardless here's what should probably be public or advertised more
1. `disable_progress` and verbose_progress: Combine and enable by default
2. `fallback_random`: We could make the case this shouldn't be public if a top level deterministic mode enables this
3. `profile_bandwidth`: Or could make the case that this should be in TORCH_COMPILE_DEBUG
Notable omissions
1. Any config that would generally improve performance for most that we should probably enable by default but might be disabled in the short term because of stability: example `epilogue_fusion`, `pattern_matcher`, `reordering`
2. Autotuning flags: Should just sit behind `torch.compile(mode="max-autotune")` like `max_autotune`, `max_autotune_gemm`
3. `coordinate_descent_tuning`: This one I'm a but mixed about, maybe it just also fall into `mode="max-autotune"`
4. `trace`: `TORCH_COMPILE_DEBUG` is the best flag for all of this
5. `triton.cudagraphs`: Default should be `torch.compile(mode="reduce-overhead")` - I'd go further and rename the `mode=cudagraph` and we can keep reduce-overhead for BC reasons
6. `triton_unique_kernel_names`: Mostly useful for devs debugging
7. `dce`: which doesnt really do anything
8. `shape_padding`: Elias is working on enabling this by default in which case we also remove it
## Mechanics
This PR would include the public functions with their docstrings
Another PR will take a stab at the configs
And for work where the APIs are still being cleaned up whether its minifier or escape hatches, export or dynamic shapes, aot_inductor etc.. we’ll keep them private until a public commitment can be made
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102182
Approved by: https://github.com/jansel
Previously, minifier testing injected faults by injecting extra code
into the repro scripts, and then ensuring this code got propagated to
all subsequent subprocess calls. This was not only quite complicated,
but also induced a big slowdown on the minifier, because to inject the
faults, you had to import torch._inductor, which would cause the
compilation threads to immediately get initialized before you even got
to do anything else in the repro script.
This new approach fixes this problem by incorporating the fault
injection into "prod" code. Essentially, for inductor fault injection
we introduce some new config flags that let you "configure" Inductor to
be buggy; for Dynamo fault injection we just permanently keep the buggy
testing backends registered. This is MUCH simpler: we only have to
propagate the buggy config (which is something we're already doing),
and it saves the minifier scripts from having to immediately initialize
inductor on entry.
Also, I enable the test for Triton runtime errors, now that tl.assert_device is here.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100357
Approved by: https://github.com/voznesenskym
Talked to @zou3519 and @ezyang on what the right UX is: tentatively, adding a new dynamo backend is cheap and simple, so it seems worth doing. And longer term, we agreed (?) that it's worth seeing if we can get custom ops sanity asserts to run more automatically, instead of needing a separate backend.
Side comment: that actually seems tough: the mode detects secret mutations by cloning every input to every op, running the op, and checking that the data matches between the real input and the cloned input. So I doubt we'll be able to make that behavior always-on? It would need some config at least.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99744
Approved by: https://github.com/albanD, https://github.com/ezyang, https://github.com/zou3519
There are no code changes but I did take the opportunity to
reorder and group the functions once they were placed in their
respective modules.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99450
Approved by: https://github.com/anijain2305
This replaces fake_mode_from_tensors but it preferentially looks for
fake_mode in TracingContext and also if there is an active fake mode
on the dispatch stack, before groveling in tensors to find it.
This advances PegasusForCausalLM, which was previously failing because
we generated a graph that had a parameter (non-fake) and a SymInt,
and thus previously we failed to detect the correct fake mode.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98321
Approved by: https://github.com/voznesenskym
For a while now, we've been re-running our functionalization analysis pass twice - once for get metadata when dedup'ing, and an entire second time during aot_dispatch_base/autograd.
This should also probably speed up compile times pretty noticeably, since we're going from:
(a) inference-only trace case: 3 fw traces -> 2 fw traces
(b) autograd trace case: 2 fw traces + 1 joint trace -> 1 fw trace + 1 joint trace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95992
Approved by: https://github.com/ezyang
In PR #93822 the `fx2trt` backend was removed which registered the `tensorrt` backend names to point to `fx2trt` / `torch_tensorrt` and move the name to `onnxrt`. We want to reserve the name `tensorrt` for `torch_tensorrt` to prevent any confusion but due to code-freeze we cannot complete the integration and set up testing for the next release. So we propose leaving out the `tensorrt` name until we can set up the backend and testing for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94632
Approved by: https://github.com/frank-wei
Fixes#91824
This PR add a new dynamo backend registration mechanism through ``entry_points``. The ``entry_points`` of a package is provides a way for the package to reigster a plugin for another one.
The docs of the new mechanism:
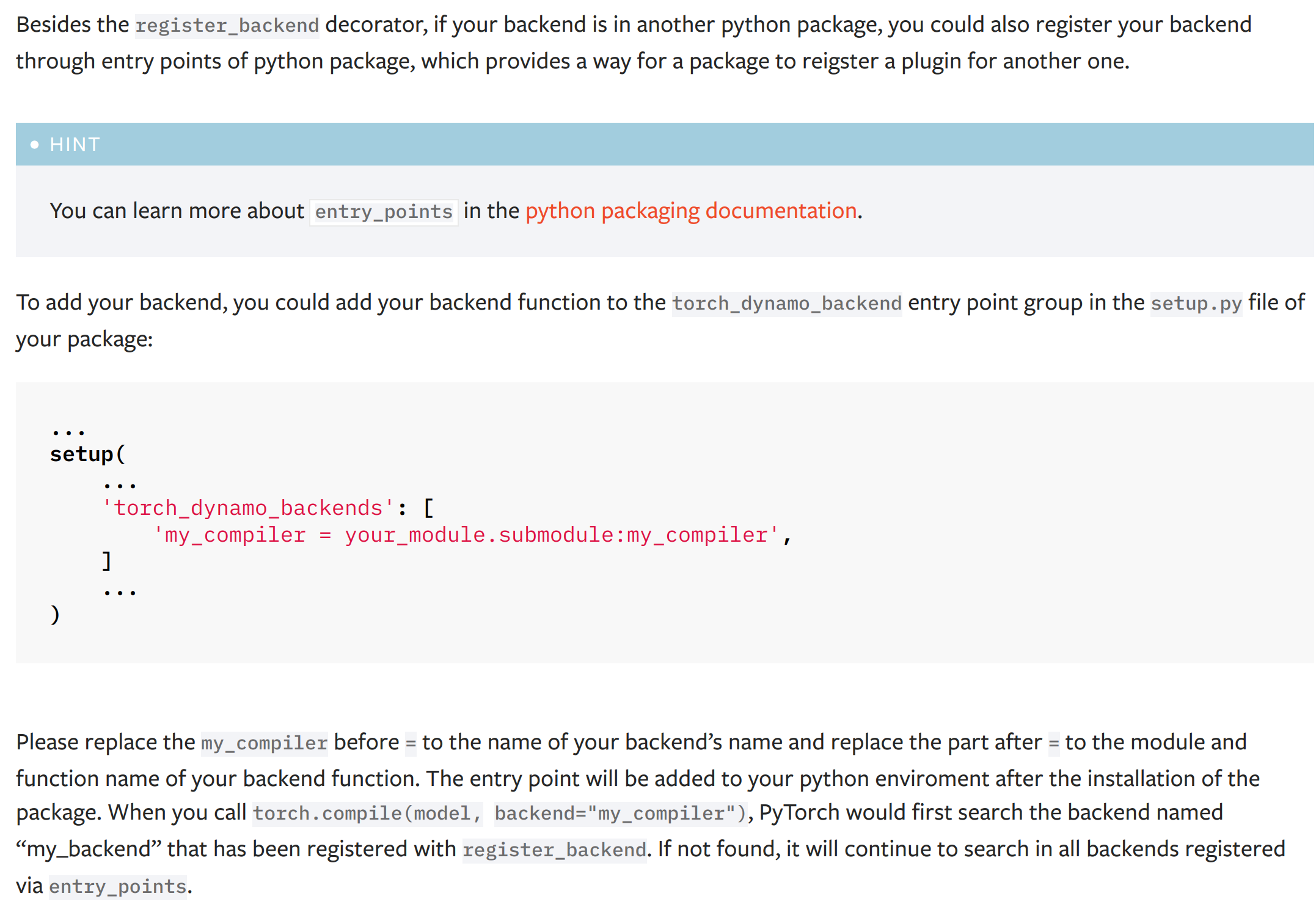
(the typo '...named "my_backend" that has been..." has been fixed to '...named "my_compiler" that has been...')
# Discussion
## About the test
I did not add a test for this PR as it is hard either to install a fack package during a test or manually hack the entry points function by replacing it with a fake one. I have tested this PR offline with the hidet compiler and it works fine. Please let me know if you have any good idea to test this PR.
## About the dependency of ``importlib_metadata``
This PR will add a dependency ``importlib_metadata`` for the python < 3.10 because the modern usage of ``importlib`` gets stable at this python version (see the documentation of the importlib package [here](https://docs.python.org/3/library/importlib.html)). For python < 3.10, the package ``importlib_metadata`` implements the feature of ``importlib``. The current PR will hint the user to install this ``importlib_metata`` if their python version < 3.10.
## About the name and docs
Please let me know how do you think the name ``torch_dynamo_backend`` as the entry point group name and the documentation of this registration mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93873
Approved by: https://github.com/malfet, https://github.com/jansel
GraphModules that were created during DDPOptimizer graph breaking
lacked `compile_subgraph_reason`, which caused an exception when
running .explain().
Now the reason is provided and users can use .explain() to find out
that DDPOptimizer is causing graph breaks.
Fixes#94579
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94749
Approved by: https://github.com/voznesenskym
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
{kind=link}