CaoE
9399e0b1ff
add fp16 support for gemm ( #99498 )
...
### Testing
Native matmul vs. mkldnn matmul on SPR (with avx512_fp16 support)
single core:
Input | Naïve impl / ms | oneDNN / ms | Speed up
-- | -- | -- | --
M: 128, N: 128, K: 128, trans_a: False, trans_b: False | 2010.387 | 64.700 | 31.072
M: 128, N: 256, K: 128, trans_a: False, trans_b: False | 4027.116 | 107.780 | 37.364
M: 8192, N: 768, K: 768, trans_a: False, trans_b: False | 28685868.488 | 90663.008 | 316.401
56 cores:
Input | Naïve impl / ms | oneDNN / ms | Speed up
-- | -- | -- | --
M: 128, N: 128, K: 128, trans_a: False, trans_b: False | 5.091 | 0.24 | 211.30
M: 128, N: 128, K: 128, trans_a: False, trans_b: True | 5.224 | 0.23 | 220.09
M: 128, N: 256, K: 128, trans_a: False, trans_b: False | 10.006 | 0.30 | 330.31
M: 8192, N: 768, K: 768, trans_a: False, trans_b: False | 29435.372 | 1.770 | 1662.80
M: 8192, N: 768, K: 768, trans_a: False, trans_b: True | 31464.961 | 1.728 | 18204.76
M: 8192, N: 768, K: 3072, trans_a: False, trans_b: False | 115035.849 | 7.990 | 14396.90
M: 8192, N: 768, K: 3072, trans_a: False, trans_b: True | 122981.023 | 7.725 | 15918.34
Batch: 768, M: 128, N: 64, K: 128 | 2032.523 | 0.705 | 2882.23
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99498
Approved by: https://github.com/jgong5 , https://github.com/malfet
2023-09-28 01:03:50 +00:00
CaoE
7c9052165a
add fp16 support for native conv and deconv on CPU ( #99497 )
...
### Testing
Native conv vs. mkldnn conv on SPR (with avx512_fp16 support)
Single core:
Input | Naïve impl / us | oneDNN / us | Speed up
-- | -- | -- | --
IC: 64, OC: 256, kernel: 1, stride: 1, N: 256, H: 56, W: 56, G: 1, pad: 0 | 34676789 | 524199.8 | 66.15185
IC: 128, OC: 512, kernel: 1, stride: 1, N: 256, H: 28, W: 28, G: 1, pad: 0 | 33454125 | 349844.4 | 95.62573
IC: 256, OC: 256, kernel: 3, stride: 1, N: 1, H: 16, W: 16, G: 1, pad: 0 | 317650.1 | 2317.677 | 137.0554
IC: 128, OC: 256, kernel: 3, stride: 1, N: 1, L: 64 | 15334.68 | 167.264 | 91.67952
56 cores:
Input | Naïve impl / us | oneDNN / us | Speed up
-- | -- | -- | --
IC: 64, OC: 256, kernel: 1, stride: 1, N: 256, H: 56, W: 56, G: 1, pad: 0 | 1032064 | 11073.58 | 93.20061
IC: 128, OC: 512, kernel: 1, stride: 1, N: 256, H: 28, W: 28, G: 1, pad: 0 | 1000097 | 16371.19 | 61.08883
IC: 256, OC: 1024, kernel: 1, stride: 1, N: 256, H: 14, W: 14, G: 1, pad: 0 | 981813.4 | 9008.908 | 108.9825
IC: 1024, OC: 256, kernel: 1, stride: 1, N: 256, H: 14, W: 14, G: 1, pad: 0 | 1082606 | 10150.47 | 106.6558
IC: 256, OC: 256, kernel: 3, stride: 1, N: 1, H: 16, W: 16, G: 1, pad: 0 | 319980.6 | 181.598 | 1762.027
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99497
Approved by: https://github.com/jgong5 , https://github.com/cpuhrsch
2023-09-25 01:31:26 +00:00
CaoE
8ed906030c
add fp16 support for mkldnn conv and deconv on CPU ( #99496 )
...
The PR is part of https://github.com/pytorch/pytorch/issues/97068 , which is to add fp16 support for mkldnn conv and mkldnn deconv to leverage avx_ne_convert, avx512-fp16, and amx-fp16 via the oneDNN library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99496
Approved by: https://github.com/jgong5 , https://github.com/cpuhrsch
2023-09-19 12:37:28 +00:00
CaoE
283ce12aa9
Add channels_last3d support for mkldnn conv and mkldnn deconv ( #95271 )
...
### Motivation
- Add channels_last3d support for mkldnn conv and mkldnn deconv.
- Use `ideep::convolution_transpose_forward::compute_v3` instead of `ideep::convolution_transpose_forward::compute`. compute_v3 uses `is_channels_last` to notify ideep whether to go CL or not to align with the memory format check of PyTorch.
### Testing
1 socket (28 cores):
- memory format: torch.contiguous_format
module | shape | forward / ms | backward / ms
-- | -- | -- | --
conv3d | input size: (32, 32, 10, 100, 100), weight size: (32, 32, 3, 3, 3) | 64.56885 | 150.1796
conv3d | input size: (32, 16, 10, 200, 200), weight size: (16, 16, 3, 3, 3) | 100.6754 | 231.8883
conv3d | input size: (16, 4, 5, 300, 300), weight size: (4, 4, 3, 3, 3) | 19.31751 | 68.31131
module | shape | forward / ms | backward / ms
-- | -- | -- | --
ConvTranspose3d | input size: (32, 32, 10, 100, 100), weight size: (32, 32, 3, 3, 3) | 122.7646 | 207.5125
ConvTranspose3d | input size: (32, 16, 10, 200, 200), weight size: (16, 16, 3, 3, 3) | 202.4542 | 368.5492
ConvTranspose3d | input size: (16, 4, 5, 300, 300), weight size: (4, 4, 3, 3, 3) | 122.959 | 84.62577
- memory format: torch.channels_last_3d
module | shape | forward / ms | backward / ms
-- | -- | -- | --
conv3d | input size: (32, 32, 10, 100, 100), weight size: (32, 32, 3, 3, 3) | 40.06993 | 114.317
conv3d | input size: (32, 16, 10, 200, 200), weight size: (16, 16, 3, 3, 3 | 49.08249 | 133.4079
conv3d | input size: (16, 4, 5, 300, 300), weight size: (4, 4, 3, 3, 3) | 5.873911 | 17.58647
module | shape | forward / ms | backward / ms
-- | -- | -- | --
ConvTranspose3d | input size: (32, 32, 10, 100, 100), weight size: (32, 32, 3, 3, 3) | 88.4246 | 208.2269
ConvTranspose3d | input size: (32, 16, 10, 200, 200), weight size: (16, 16, 3, 3, 3 | 140.0725 | 270.4172
ConvTranspose3d | input size: (16, 4, 5, 300, 300), weight size: (4, 4, 3, 3, 3) | 23.0223 | 37.16972
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95271
Approved by: https://github.com/jgong5 , https://github.com/cpuhrsch
2023-08-30 02:53:30 +00:00
Aaron Gokaslan
2f95a3d0fc
[BE]: Apply ruff PERF fixes to torch ( #104917 )
...
Applies automated ruff fixes in the PERF modules and enables all automatic ones. I also updated ruff which applied some additional fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104917
Approved by: https://github.com/ezyang , https://github.com/albanD
2023-07-11 20:45:21 +00:00
Nikita Shulga
4cfa06f706
[BE] Deprecate has_XYZ attributes ( #103279 )
...
Use [`__getattr__`](https://peps.python.org/pep-0562/ ) to raise warningwhen one tries to access `has_XYZ` methods and recommend appropriate `torch.backends.XYZ` methods
Make respective properties in `torch._C` private (by prefixing them with underscore), to exclude from `from torch._C import *`.
Added `warnings.simplefilter` to workaround Python-3.11 torch.compile lineinfo issue.
Fixes https://github.com/pytorch/pytorch/issues/102484
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103279
Approved by: https://github.com/janeyx99 , https://github.com/Skylion007
2023-06-10 05:17:17 +00:00
leslie-fang-intel
d7035ffde3
Enable uint8/int8 mkldnn/dense tensor conversion ( #102965 )
...
**Summary**
Support mkldnn tensor and dense tensor conversion with uint8/int8 data type.
**Test Plan**
```
python -m pytest -s -v test_mkldnn.py -k test_conversion_byte_char
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102965
Approved by: https://github.com/jgong5 , https://github.com/XiaobingSuper
2023-06-06 05:05:29 +00:00
PyTorch MergeBot
da57d597e1
Revert "fix onednn ConvTranspose2d channels last issue when ic=1 ( #99539 )"
...
This reverts commit 233cc34d3bhttps://github.com/pytorch/pytorch/pull/99539 on behalf of https://github.com/DanilBaibak due to Break internal build
2023-04-21 08:44:28 +00:00
XiaobingSuper
ccd5ad816e
inductor(CPU): add ISA check before do cpu fx packed weight ( #99502 )
...
1. This PR is to fix https://github.com/pytorch/pytorch/issues/99423 , which will add an ISA check before doing the bf16 weight pack.
2. Move CPU-related tests from ```test_torchinductor.py``` to ```test_cpu_repo.py``` to reduce the CI time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99502
Approved by: https://github.com/jgong5 , https://github.com/desertfire
2023-04-20 08:37:15 +00:00
XiaobingSuper
233cc34d3b
fix onednn ConvTranspose2d channels last issue when ic=1 ( #99539 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99539
Approved by: https://github.com/mingfeima
2023-04-20 04:41:33 +00:00
XiaobingSuper
e21f648cde
improve mkldnn matmul performance when one input is contiguous tensor but the strides is not default contiguous strides ( #99511 )
...
giving the following case:
```
import torch
a= torch.empty_strided([64, 1, 33], [33, 3, 1], dtype=torch.bfloat16).fill_(1)
b = torch.randn(64, 33, 256).to(dtype = torch.bfloat16)
y = torch.ops.aten.bmm(a, b)
```
```a``` is a contiguous tensor, but the strides are not defaulted contiguous strides ([33, 33, 1]), onednn matmul always running a non-optimized path:
```
onednn_verbose,exec,cpu,matmul,gemm:jit,undef,src_bf16::blocked:abc:f0 wei_bf16::blocked:abc:f0 dst_bf16::blocked:abc:f0,attr-scratchpad:user ,,64x1x33:64x33x256:64x1x256,7.28711
```
This PR will convert the inputs' stride to deafult contiguous stride before calling onednn to running an optimization path:
```
onednn_verbose,exec,cpu,matmul,brg:avx512_core_amx_bf16,undef,src_bf16::blocked:abc:f0 wei_bf16::blocked:abc:f0 dst_bf16::blocked:abc:f0,attr-scratchpad:user ,,64x1x33:64x33x256:64x1x256,3.06396
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99511
Approved by: https://github.com/mingfeima , https://github.com/jgong5
2023-04-19 18:13:00 +00:00
yanbing-j
38da54e9c9
Split rnn primitive for inference and training ( #96736 )
...
## Description
Currently, both inference and training will use `forward_training` in rnn primitive, which will bring performance downgrade for inference (The performance drop is from rnn primitive and unnecessary creation of `pd` and `workspace`). This PR is to split them into `forward_inference` and `forward_training` seperately.
## Performance
With this fix PR, in RNN-T inference, the throughput reduction is 167 ms, which increases `3.7%` of E2E time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96736
Approved by: https://github.com/jgong5
2023-03-27 11:14:15 +00:00
mingfeima
26cba842ad
Optimize ConvTransposed2D with mkldnn float32 and bfloat16 on CPU ( #92530 )
...
this PR optimized `ConvTranspose2d` with oneDNN and add channels last support for it. Also the fallback path `slow_conv_transpose2d` also have channels last support. So the memory format propagation behavior would stay the same with or without oneDNN.
Replacement of https://github.com/pytorch/pytorch/pull/77060 , https://github.com/pytorch/pytorch/pull/70897 and https://github.com/pytorch/pytorch/pull/74023 which enables oneDNN for `ConvTranspose2d` and `ConvTranspose3d`
The following results collects on Skylake Xeon 8180, dual sockets, 28 cores per socket.
### single core channels last
configs | forward before/ms | forward after/ms | ratio | backward before/ms | backward after/ms | ratio
-- | -- | -- | -- | -- | -- | --
input size: (32, 32, 100, 100), weight size: (32, 32, 3, 3) | 181.36 | 91.16 | 1.99 | 531.38 | 124.08 | 4.28
input size: (32, 16, 200, 200), weight size: (16, 16, 3, 3) | 324.35 | 153.50 | 2.11 | 973.16 | 185.97 | 5.23
input size: (32, 128, 100, 100), weight size: (128, 128, 3, 3) | 1086.82 | 671.52 | 1.62 | 3008.94 | 1453.33 | 2.07
### single core channels first
configs | forward before/ms | forward after/ms | ratio | backward before/ms | backward after/ms | ratio
-- | -- | -- | -- | -- | -- | --
input size: (32, 32, 100, 100), weight size: (32, 32, 3, 3) | 138.10 | 5.94 | 23.23 | 37.97 | 11.25 | 3.38
input size: (32, 16, 200, 200), weight size: (16, 16, 3, 3) | 236.43 | 8.75 | 27.03 | 87.77 | 18.58 | 4.72
input size: (32, 128, 100, 100), weight size: (128, 128, 3, 3) | 484.39 | 37.69 | 12.85 | 185.40 | 90.57 | 2.05
### single socket channels last
configs | forward before/ms | forward after/ms | ratio | backward before/ms | backward after/ms | ratio
-- | -- | -- | -- | -- | -- | --
input size: (32, 32, 100, 100), weight size: (32, 32, 3, 3) | 138.10 | 5.94 | 23.23 | 37.97 | 11.25 | 3.38
input size: (32, 16, 200, 200), weight size: (16, 16, 3, 3) | 236.43 | 8.75 | 27.03 | 87.77 | 18.58 | 4.72
input size: (32, 128, 100, 100), weight size: (128, 128, 3, 3) | 484.39 | 37.69 | 12.85 | 185.40 | 90.57 | 2.0
### single socket channels first
configs | forward before/ms | forward after/ms | ratio | backward before/ms | backward after/ms | ratio
-- | -- | -- | -- | -- | -- | --
input size: (32, 32, 100, 100), weight size: (32, 32, 3, 3) | 132.56 | 7.19 | 18.43 | 31.43 | 11.20 | 2.81
input size: (32, 16, 200, 200), weight size: (16, 16, 3, 3) | 227.94 | 13.33 | 17.11 | 63.00 | 23.41 | 2.69
input size: (32, 128, 100, 100), weight size: (128, 128, 3, 3) | 473.68 | 52.79 | 8.97 | 150.40 | 87.33 | 1.72
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92530
Approved by: https://github.com/jgong5 , https://github.com/ezyang
2023-02-06 10:11:25 +00:00
yanbing-j
94a7c01159
Enable oneDNN implementation in LSTM op ( #91158 )
...
### Description
This PR is to enable oneDNN implementation in LSTM op to improve the performance of it. Both FP32 and BF16 are supported.
### Performance improvement
In CPX 28C, with setting iomp and jemalloc.
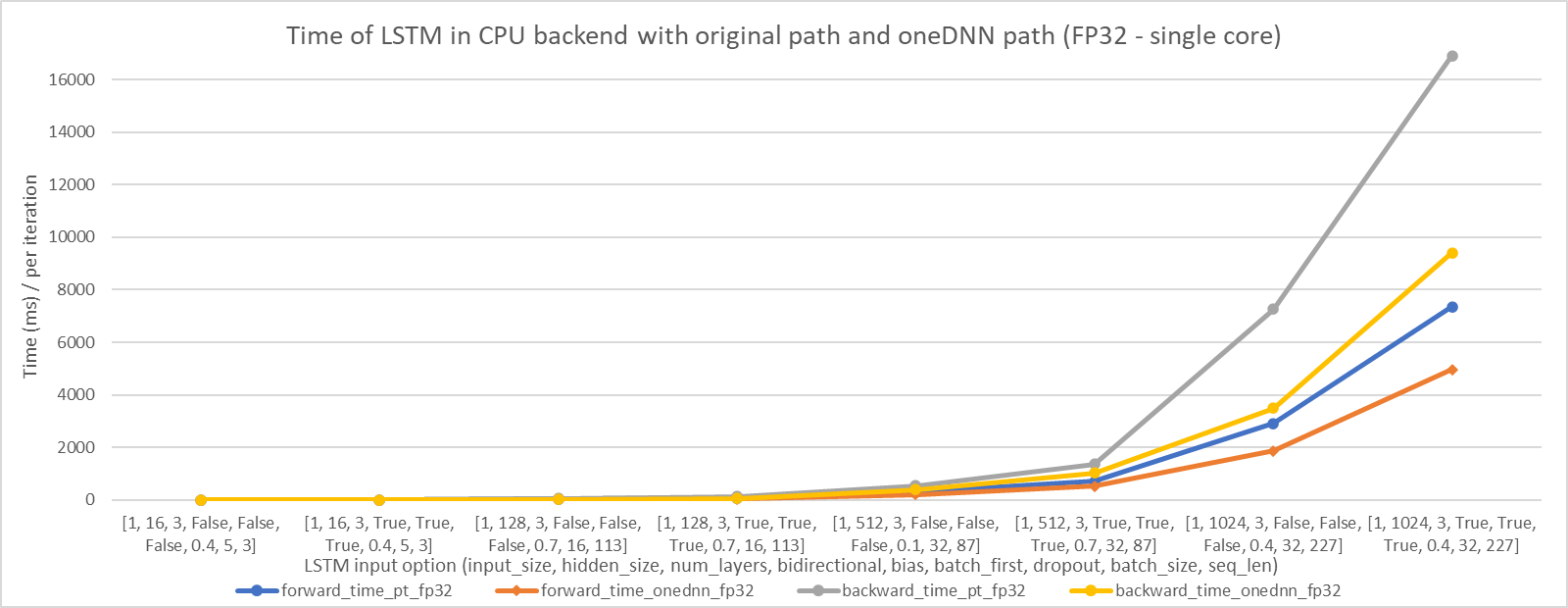
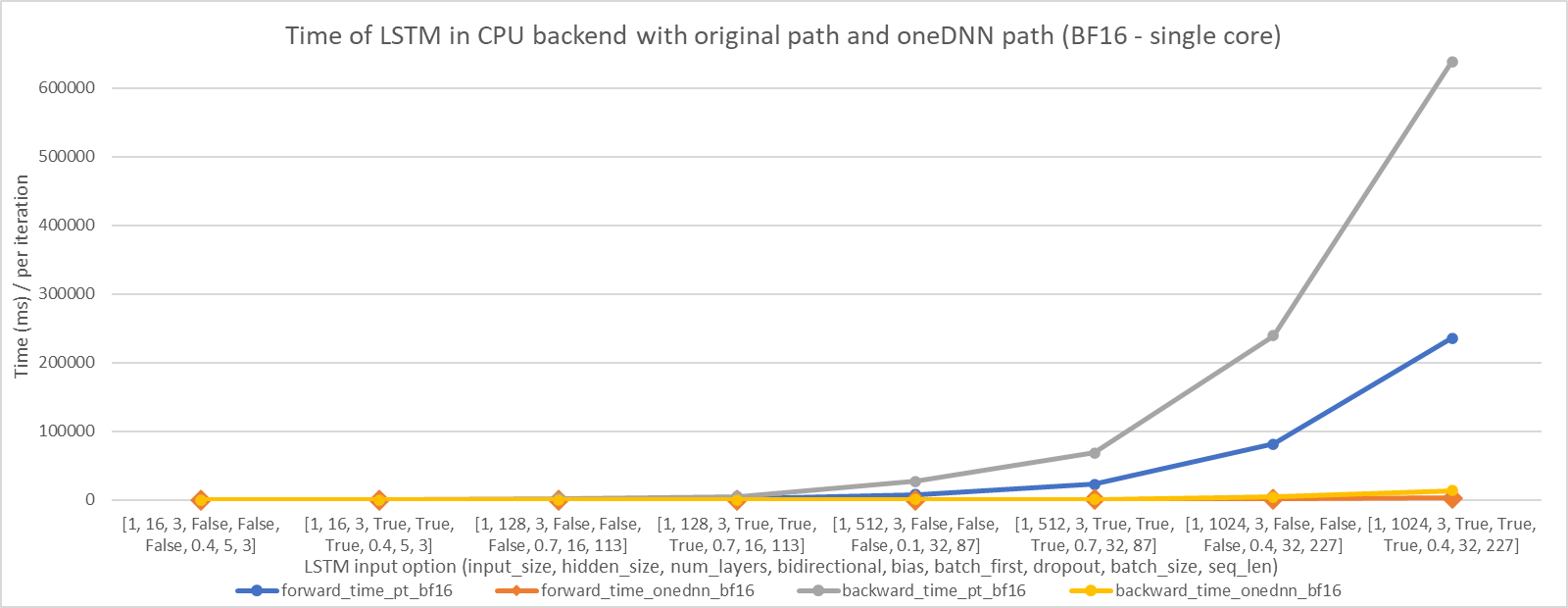
We choose 8 LSTM input options (including input_size, hidden_size, num_layers, bidirectional, bias, batch_first, dropout, batch_size, seq_len), and the final option is a real input from train-clean-100 in LibriSpeech dataset. The performance improvements are shown in the following figures. We can see that LSTM with oneDNN implementation can perform better than the original.
In single socket:
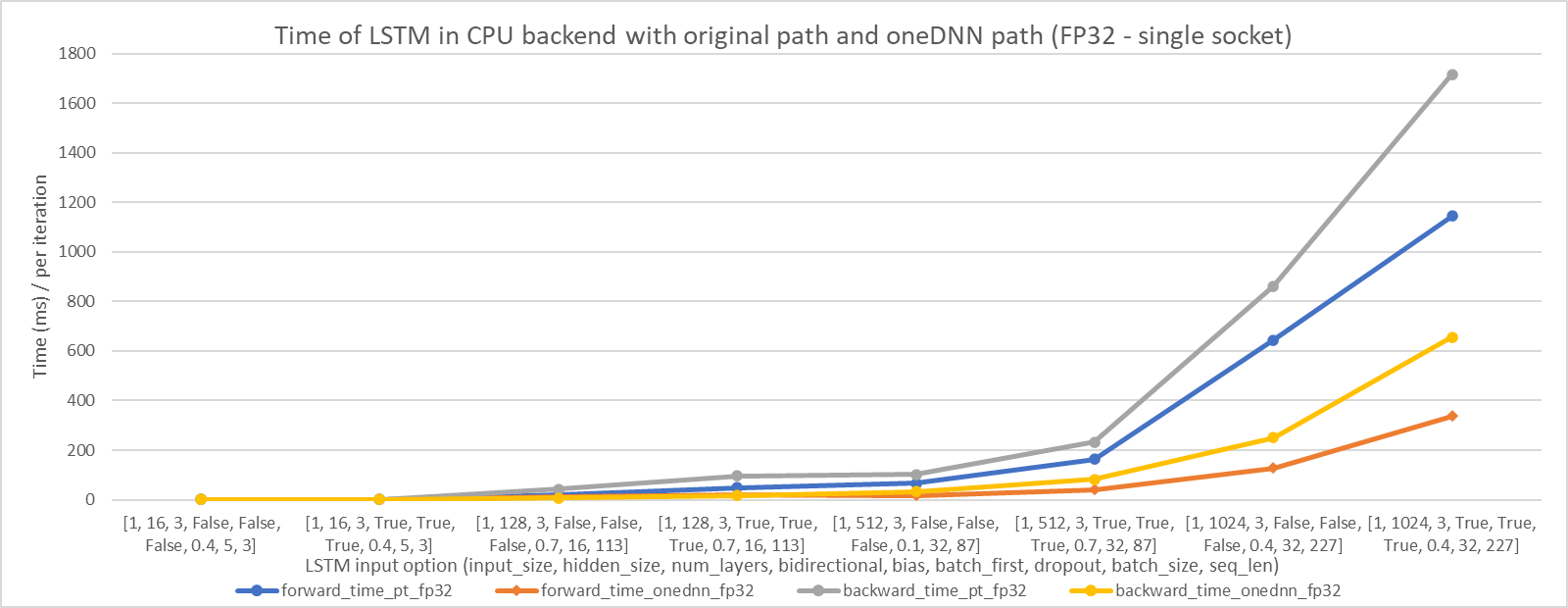
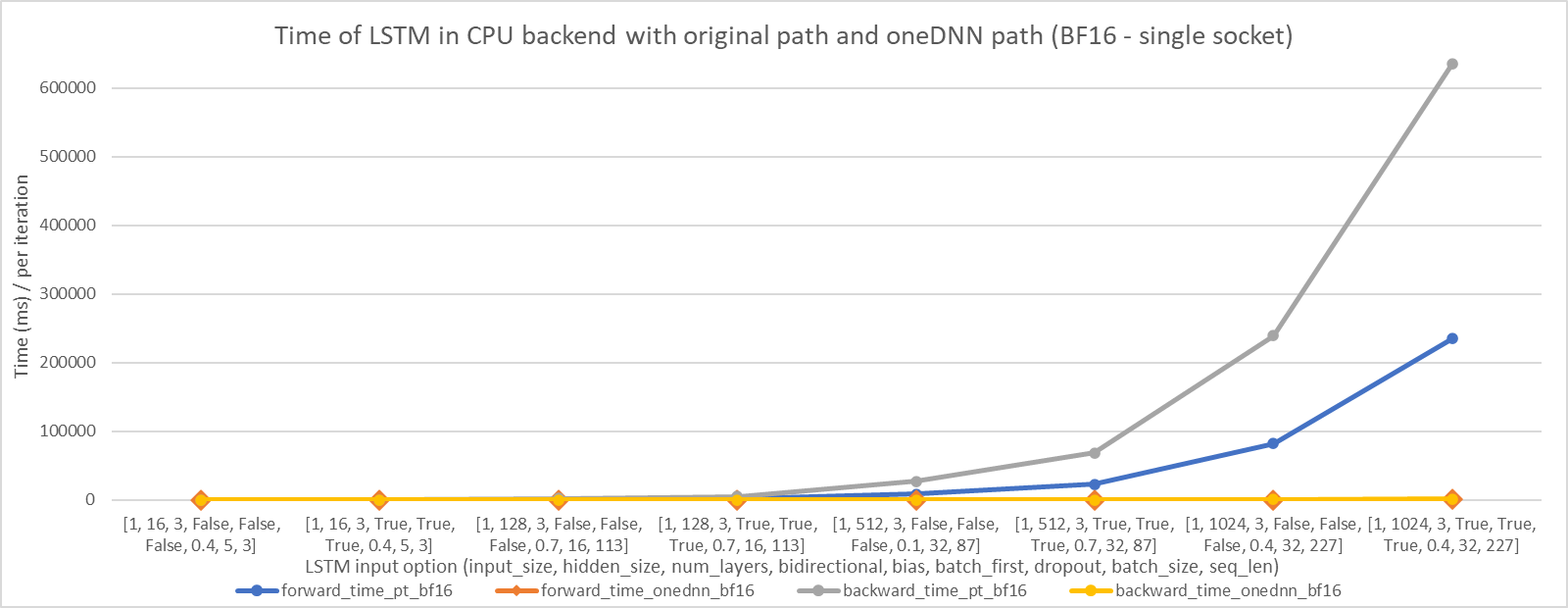
In single core:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91158
Approved by: https://github.com/jgong5 , https://github.com/malfet
2023-01-18 04:41:18 +00:00
Edward Z. Yang
edc5bb5fbe
Only populate real_value_cache during export ( #90468 )
...
Fixes https://github.com/pytorch/torchdynamo/issues/1950
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90468
Approved by: https://github.com/voznesenskym
2022-12-15 02:28:21 +00:00
XiaobingSuper
d70bc222d8
add parameters check for mkldnn_transpose ( #85318 )
...
This PR is about add parameters check for mkldnn_transpose, fixed https://github.com/pytorch/pytorch/issues/85216 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85318
Approved by: https://github.com/jgong5 , https://github.com/mingfeima , https://github.com/leslie-fang-intel
2022-11-03 17:28:33 +00:00
mingfeima
6f72c13f9b
test mkldnn conv2d channels last when weight is nchw format ( #77348 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77348
Approved by: https://github.com/malfet
2022-09-09 07:28:04 +00:00
liukun
9f5f6ba683
check params shape for mkldnn_convolution ( #76526 )
...
Fixes #73193
Follow check rules from native/Convolution.cpp without transpose supported.
Seems that mkldnn_convolution does not support transpose. ideep has special api for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76526
Approved by: https://github.com/XiaobingSuper , https://github.com/mingfeima , https://github.com/jbschlosser
2022-08-02 17:26:36 +00:00
yanbing-j
cd33e412a2
Enable fp32/bf16 PRelu forward and backward in MkldnnCPU path ( #60427 )
...
Enable fp32/bf16 PRelu forward and backward in MkldnnCPU path.
Fixes https://github.com/pytorch/pytorch/issues/58896
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60427
Approved by: https://github.com/VitalyFedyunin , https://github.com/ngimel , https://github.com/malfet
2022-05-10 17:29:11 +00:00
Nikita Shulga
b08633917d
Revert D29463782: opitimze ConvTransposedND with mkldnn float32 and bfloat16 on CPU
...
Test Plan: revert-hammer
Differential Revision:
D29463782 (479e0d64e6479e0d64e6
2022-05-06 19:34:41 +00:00
mingfeima
479e0d64e6
opitimze ConvTransposedND with mkldnn float32 and bfloat16 on CPU ( #58348 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/58348
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D29463782
Pulled By: VitalyFedyunin
fbshipit-source-id: 74b3d613894526280996c8211e0df918ac09364d
(cherry picked from commit 2db963bfaee7823bf5ecb2ef909405eb02db0613)
2022-05-06 17:19:05 +00:00
mingfeima
dbfb9a823d
enable BFloat16 mkldnn_convolution on both contiguous and channels last memory format ( #55864 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/55864
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27941367
Pulled By: VitalyFedyunin
fbshipit-source-id: c6bcb73c41652cc0aca11c1d1e0697a8a2fa43ad
(cherry picked from commit 3fc0b992a7dccbc31042dc35afec9ae3dc59a05a)
2022-05-02 22:23:10 +00:00
mingfeima
92a9c0e3e0
add channels last (2d) support for mkldnn_convolution ( #55584 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/55584
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27941368
Pulled By: VitalyFedyunin
fbshipit-source-id: 7dd6f02a5787efa1995f31cdbd3244b25653840c
(cherry picked from commit bb555ed0fedafd529cb552807326384e95c90df9)
2022-04-20 22:34:44 +00:00
yanbing-j
12026124cc
Avoid the view for mkldnn case in 1D convolution ( #68166 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68166
Reviewed By: mrshenli
Differential Revision: D32432444
Pulled By: jbschlosser
fbshipit-source-id: fc4e626d497d9e4597628a18eb89b94518bb3b33
2021-11-15 11:56:45 -08:00
Jane Xu
6e67150f57
[skip ci] Set test owner for test_mkldnn.py ( #66845 )
...
Summary:
Action following https://github.com/pytorch/pytorch/issues/66232
cc gujinghui PenghuiCheng XiaobingSuper jianyuh VitalyFedyunin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66845
Reviewed By: anjali411
Differential Revision: D31803377
Pulled By: janeyx99
fbshipit-source-id: 4fcf77d3e4bf976449a0b1ab4d750619db3493a1
2021-10-20 12:38:56 -07:00
Shen Li
1022443168
Revert D30279364: [codemod][lint][fbcode/c*] Enable BLACK by default
...
Test Plan: revert-hammer
Differential Revision:
D30279364 (b004307252
2021-08-12 11:45:01 -07:00
Zsolt Dollenstein
b004307252
[codemod][lint][fbcode/c*] Enable BLACK by default
...
Test Plan: manual inspection & sandcastle
Reviewed By: zertosh
Differential Revision: D30279364
fbshipit-source-id: c1ed77dfe43a3bde358f92737cd5535ae5d13c9a
2021-08-12 10:58:35 -07:00
yanbing-j
c7a7c2b62f
Enable Gelu fp32/bf16 in CPU path using Mkldnn implementation ( #58525 )
...
Summary:
Enable Gelu bf16/fp32 in CPU path using Mkldnn implementation. User doesn't need to_mkldnn() explicitly. New Gelu fp32 performs better than original one.
Add Gelu backward for https://github.com/pytorch/pytorch/pull/53615 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58525
Reviewed By: ejguan
Differential Revision: D29940369
Pulled By: ezyang
fbshipit-source-id: df9598262ec50e5d7f6e96490562aa1b116948bf
2021-08-03 06:52:23 -07:00
XiaobingSuper
4f46943e3d
enable check trace when tracing a mkldnn model ( #61241 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43039 , when tracing a MKLDNN model with setting **check_trace=True**, there has an error: **RuntimeError: unsupported memory format option Preserve**, this PR is to solve this problem.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61241
Reviewed By: anjali411
Differential Revision: D29737365
Pulled By: suo
fbshipit-source-id: e8f7f124bc6256f10b9d29969e0c65d332514625
2021-07-19 11:03:53 -07:00
Nikita Shulga
c7d8d8f925
[BE] Improve has_bf16_support ( #57408 )
...
Summary:
Use `functools.lru_cache` to avoid calling this function multiple time
Check that we are running on Linux platform before trying to open
"/proc/cpuinfo"
Do not spawn new process, but simply open("/proc/cpuinfo").read() and
search the output for the keywords
Fixes https://github.com/pytorch/pytorch/issues/57360
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57408
Reviewed By: driazati
Differential Revision: D28136769
Pulled By: malfet
fbshipit-source-id: ab476774c3be2913cb576d98d47a2f7ec03c19aa
2021-05-03 09:11:04 -07:00
Masaya, Kato
473d193966
Use mkldnn copy for copy_ when self and src are Mkldnn layout ( #54248 )
...
Summary:
Currently, when copy_ is called with Mkldnn layout, a RuntimeError is raised.
**Environment**
- CPU : Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
- PyTorch master(1772e26f63https://github.com/pytorch/pytorch/pull/54248
Reviewed By: mrshenli
Differential Revision: D27641352
Pulled By: ezyang
fbshipit-source-id: 70a37cdacb4a40b250ca16f2f6ddb6b71ff52d90
2021-04-08 06:35:39 -07:00
Akao, Kazutoshi
d2a58bfe6f
Add mkldnn tanh operator ( #54656 )
...
Summary:
## 🚀 Feature
Add Mkl-Layout kernel for tanh.
## Motivation
We want to add a Mkl-Layout kernel for tanh to improve tanh's performance when the input Tensor is Mkl-Layout.
Because, PyTorch does not have the Mkl-Layout kernel for tanh, so it cannot execute the tanh input by the Mkl-Layout Tensor.
Off course you can temporarily avoid this problem by executing to_dense/to_mkldnn, but the performance is significantly reduced due to the copy overhead(1.6-4.3 times slower than CPU kernel).
## Perfomance results
### Environment
- CPU: Intel(R) Core(TM) i7-8086K CPU @ 4.00GHz
- OS: 18.04.1 LTS
- compiler: gcc 7.5.0
- branch: master
- commit ID: fe2c126https://spec.oneapi.com/versions/latest/elements/oneDNN/source/primitives/eltwise.html )
There is already exist sigmoid implementation that uses the same Elementwise API as tanh, so we created this PR code with reference to the sigmoid implementation.
527c1e0e37/aten/src/ATen/native/mkldnn/UnaryOps.cpp (L28-L42)https://github.com/pytorch/pytorch/pull/54656
Test Plan:
A test for sigmoid has already been created as shown below.
So, I added a new test of tanh referring to the test of sigmoid.
527c1e0e37/test/test_mkldnn.py (L944-L954)
2021-04-05 00:00:16 -07:00
Masaya, Kato
2c4a64589b
fix mkldnn_add in-place behavior ( #51687 )
...
Summary:
There are the following two patterns to call add in-pace.
```python
torch.add(a, b, out=a) # (1) a in-placed
torch.add(a, b, out=b) # (2) b in-placed
```
If a and b are mkldnn Tensor, the value is different from expected in case (2).
**Sample code to reproduce the behavior:**
```python
import torch
torch.manual_seed(4)
a = torch.randn(4, 4)
b = torch.randn(4, 4)
b.fill_(1.0)
a_mkl = a.to_mkldnn()
b_mkl = b.to_mkldnn()
torch.add(b, a, alpha=1.0, out=a)
torch.add(b_mkl, a_mkl, alpha=1.0, out=a_mkl)
print(a)
print(a_mkl)
```
**Results:**
Actual:
```python
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]])
tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]], layout=torch._mkldnn)
```
Expected:
```python
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]])
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]], layout=torch._mkldnn)
```
This is because `dnnl::sum` called in `mkldnn_add` has the following specifications:
[oneDNN doc : Sum](https://oneapi-src.github.io/oneDNN/dev_guide_sum.html )
> The sum primitive supports in-place operation, meaning that the src0 tensor can be used as both input and output.
> In-place operation overwrites the original data. Using in-place operation requires the memory footprint of the
> output tensor to be either bigger than or equal to the size of the dst memory descriptor used for primitive creation.
but, case 2) are added to the first argument.
So, we modified it so that a and b are swapped and passed to "sum" in case (2).
**Environment**
・CPU : Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
・build USE_MKLDNN=1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51687
Reviewed By: jbschlosser
Differential Revision: D27062172
Pulled By: VitalyFedyunin
fbshipit-source-id: bf76d36f9fdb1b4337d71d87bcdbaf4edb11f12f
2021-03-16 12:54:27 -07:00
XiaobingSuper
793a29a7d5
add OneDNN batch_norm backward ( #50460 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/50460
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D26006887
Pulled By: VitalyFedyunin
fbshipit-source-id: 472398772af01a31594096ccc714fd487ed33dd4
2021-03-15 13:30:17 -07:00
XiaobingSuper
33e3deed4f
add OneDNN relu backward and reshape backward ( #49455 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/49455
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D26006886
Pulled By: VitalyFedyunin
fbshipit-source-id: c81ef115205171b80652800a76170dd759905e28
2021-03-15 13:27:56 -07:00
Elias Ellison
f41c80c267
Dont error on 0-dim in convolution ( #51922 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/51922
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696701
Pulled By: eellison
fbshipit-source-id: f8b2c19e134931971fac00246920c1584dd43581
2021-03-01 21:22:30 -08:00
Elias Ellison
42bfda36e1
Add 0-dim support for binary mkldnn ops ( #51921 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/51921
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696696
Pulled By: eellison
fbshipit-source-id: 96ca79c0d6b5ed7c32c14dc4e7c383f2522a85cb
2021-03-01 21:22:26 -08:00
XiaobingSuper
420fc42eab
add OneDNN pooling backward ( #49454 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/49454
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D26006888
Pulled By: VitalyFedyunin
fbshipit-source-id: 6a4930982db784819fea70ffc9029441d673d90e
2021-02-23 14:45:55 -08:00
XiaobingSuper
8f3ed60d3e
enable mkldnn conv2d backward to support mkldnn tensor input ( #48994 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/48994
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D25537189
Pulled By: VitalyFedyunin
fbshipit-source-id: d81d247798fad3815b735468d66ef9d62c07ef77
2021-02-18 10:23:10 -08:00
XiaobingSuper
324c6aada1
BFloat16: enable prepacked weights's inference ( #48922 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/48922
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D25537188
Pulled By: VitalyFedyunin
fbshipit-source-id: ab6eb1ba8cffb5ba9d00d05db8ef616628f8c932
2021-02-17 11:20:00 -08:00
jiej
bc1b1e8253
fixing mkldnn_linear & backward with silent error ( #51713 )
...
Summary:
mkldnn_linear & mkldnn_linear_backward_input gives wrong result when weight is non contiguous.
Issue exposed in PR https://github.com/pytorch/pytorch/issues/51613
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51713
Reviewed By: zhangguanheng66
Differential Revision: D26282319
Pulled By: ngimel
fbshipit-source-id: 96516e10c9dc72c30dac278fce09b746aa5f51b2
2021-02-05 18:36:30 -08:00
XiaobingSuper
ec378055c3
add OneDNN linear backward ( #49453 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/49453
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D26006889
Pulled By: VitalyFedyunin
fbshipit-source-id: 06e2a02b6e01d847395521a31fe84d844f2ee9ae
2021-02-02 12:18:59 -08:00
Jeffrey Wan
c0966914bc
Internal gradcheck wrapper in testing._internal that sets certain flags to True ( #51133 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49409
There are many call sites where, gradcheck/gradgradcheck is now being implicitly invoked with `check_batched_grad` as True, but they were previously False. Cases fall into two basic categories:
1) the call site was previously using `torch.autograd.gradcheck` but is now changed to use the globally imported function instead
3) the call site was already using globally imported function, but does not explicitly pass `check_batched_grad` flag
Only in the _assertGradAndGradgradChecks cases, which are infrequent, I assumed that the the author is aware that omitting the flag means not applying check_batched_grad=True. (but maybe that is not the case?)
Overall this PR in its current state assumes that unless the author explicitly specified `check_batched_grad=False`, they were just probably not aware of this flag and did not mean to have this flag as False.
So far exceptions to the above (as discovered by CI) include:
- Mkldnn (opaque tensors do not have strides) https://app.circleci.com/pipelines/github/pytorch/pytorch/264416/workflows/e4d87886-6247-4305-8526-2696130aa9a4/jobs/10401882/tests
- all cases in test_sparse (https://app.circleci.com/pipelines/github/pytorch/pytorch/264553/workflows/3c1cbe30-830d-4acd-b240-38d833dccd9b/jobs/10407103 )
- all cases in test_overrides (https://app.circleci.com/pipelines/github/pytorch/pytorch/264553/workflows/3c1cbe30-830d-4acd-b240-38d833dccd9b/jobs/10407236 )
- test_autograd (test_LSTM_grad_and_gradgrad) - (https://app.circleci.com/pipelines/github/pytorch/pytorch/264553/workflows/3c1cbe30-830d-4acd-b240-38d833dccd9b/jobs/10407235 )
- test_data_parallel (test_data_parallel_buffers_requiring_grad) - *SIGSEGV* (https://app.circleci.com/pipelines/github/pytorch/pytorch/264820/workflows/14d89503-040d-4e3d-9f7b-0bc04833589b/jobs/10422697 )
- test_nn (https://app.circleci.com/pipelines/github/pytorch/pytorch/264919/workflows/df79e3ed-8a31-4a8e-b584-858ee99686ff/jobs/10427315 )
Possible TODO is to prevent new tests from invoking external gradcheck.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51133
Reviewed By: ezyang
Differential Revision: D26147919
Pulled By: soulitzer
fbshipit-source-id: dff883b50f337510a89f391ea2fd87de2d531432
2021-01-29 09:13:37 -08:00
XiaobingSuper
f66147ebca
BFloat16: add explicit dtype support for to_mkldnn and to_dense ( #48881 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/48881
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25537190
Pulled By: VitalyFedyunin
fbshipit-source-id: a61a433c638e2e95576f88f081b64ff171b2316e
2020-12-16 16:09:42 -08:00
Xiang Gao
20ac736200
Remove py2 compatible future imports ( #44735 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/44735
Reviewed By: mruberry
Differential Revision: D23731306
Pulled By: ezyang
fbshipit-source-id: 0ba009a99e475ddbe22981be8ac636f8a1c8b02f
2020-09-16 12:55:57 -07:00
XiaobingSuper
b72da0cf28
OneDNN: report error for dilation max_pooling and replace AT_ERROR with TORCH_CHECK in oneDNN codes ( #43538 )
...
Summary:
Fix https://github.com/pytorch/pytorch/issues/43514 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43538
Reviewed By: agolynski
Differential Revision: D23364302
Pulled By: ngimel
fbshipit-source-id: 8d17752cf33dcacd34504e32b5e523e607cfb497
2020-08-28 10:57:19 -07:00
Zhang, Xiaobing
2b14f2d368
[reland][DNNL]:enable max_pool3d and avg_pool3d ( #40996 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40996
Test Plan: Imported from OSS
Differential Revision: D22440766
Pulled By: VitalyFedyunin
fbshipit-source-id: 242711612920081eb4a7e5a7e80bc8b2d4c9f978
2020-07-16 10:26:45 -07:00
Zhang, Xiaobing
2b8db35c7e
[reland][DNNL]:enable batchnorm3d ( #40995 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40995
Test Plan: Imported from OSS
Differential Revision: D22440765
Pulled By: VitalyFedyunin
fbshipit-source-id: b4bf427bbb7010ee234a54e81ade371627f9e82c
2020-07-15 13:56:47 -07:00
Zhang, Xiaobing
b48ee175e6
[reland][DNNL]:enable conv3d ( #40691 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40691
Test Plan: Imported from OSS
Differential Revision: D22296548
Pulled By: VitalyFedyunin
fbshipit-source-id: 8e2a7cf14e8bdfa2f29b735a89e8c83f6119e68d
2020-07-15 13:54:41 -07:00
Zhang, Xiaobing
fc4824aa4a
enable mkldnn dilation conv ( #40483 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40483
Reviewed By: ezyang
Differential Revision: D22213696
Pulled By: ngimel
fbshipit-source-id: 0321eee8fcaf144b20a5182aa76f98d505c65400
2020-06-24 13:28:05 -07:00
{kind=link}
{kind=link}
{kind=link}
{kind=link}