This PR adds a new `CustomPolicy` that acts like the existing `lambda_auto_wrap_policy` except it (1) leverages the new auto wrapping infrastructure and (2) allows overriding FSDP kwargs for particular instances. (1) gives it access to the validation checks (like for frozen parameters), and (2) makes it as expressive as manual wrapping. This should allow us to effectively deprecate manual wrapping if desired.
The API is as follows:
```
def lambda_fn(module: nn.Module) -> Union[bool, Dict[str, Any]]:
...
policy = CustomPolicy(lambda_fn)
```
The `lambda_fn` can return:
- `False` or `{}` to indicate no wrapping
- `True` to indicate wrapping while inheriting the root's FSDP kwargs
- Non-empty `dict` to indicate wrapping while overriding the specified FSDP kwargs and inheriting the rest from the root
---
After this PR, the follow-up work items for auto wrapping are:
1. Add shared parameter validation
2. (Longer-term / exploratory) Add a policy that provides a reasonable auto wrapping with "minimal" user input
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104986
Approved by: https://github.com/ezyang
ghstack dependencies: #104427, #104967, #104999, #104969
This does some code organization improvement.
- It renames `_FSDPPolicy` to `_Policy` to show that it is not only for FSDP but for any module-level API.
- It formalizes the contract that such a policy should return something like `target_module_to_kwargs: Dict[nn.Module, Dict[str, Any]]` that maps each module to wrap to its kwargs. It does so by requiring a `_run_policy` abstract method (this time private since users do not need to care about it). Then, our auto wrapping can just call `_run_policy()` to generate the dict and do any validation or post-processing.
This PR is technically BC-breaking because it removes the public `ModuleWrapPolicy.policy`. However, I do not think anyone was using that anyway, so this is a pretty safe breakage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104969
Approved by: https://github.com/rohan-varma
ghstack dependencies: #104427, #104967, #104999
Purely out of preference, this PR renames the streams to `_unshard_stream` instead of `_streams_unshard` etc. since the former reads more naturally. The PR also removes some duplicated comments and adds back a unit test that streams are shared.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104966
Approved by: https://github.com/rohan-varma
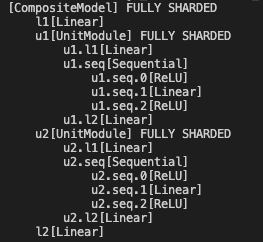
This moves `fully_shard` to use `_auto_wrap()` just like `FullyShardedDataParallel`. This means that `fully_shard` goes through the `_init_param_handle_from_module()` path (i.e. 1 `fully_shard` per "wrap"), removing the need for `_init_param_handles_from_module()` (which was 1 `fully_shard` for all "wraps" of a given policy). `_auto_wrap()` simply calls `fully_shard` on target submodules.
This includes several important fixes:
- We should register the pre/post-forward hooks on the module regardless of it has managed parameters.
- We can permit `_module_handles` to return `[]` in the composable path (for when the module has no managed parameters).
- We should unify the paths for `_get_buffers_and_dtypes_for_computation()` (previously, composable path was buggy in some cases).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104408
Approved by: https://github.com/rohan-varma
This attribute wasn't actually used in tests, add a test ensuring that
if replicate is used on top of FSDP, the replicated parameter names are as
expected.
TODO: there are a few ways to check if module is managed by composable API,
such as replicated param names for replicate, _get_module_state API,
_get_registry_api, etc. We should unify all composable APIs to check in a
unified way (filed an issue)
Differential Revision: [D46236377](https://our.internmc.facebook.com/intern/diff/D46236377/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102401
Approved by: https://github.com/awgu
The fix for https://github.com/pytorch/pytorch/pull/99545 (https://github.com/pytorch/pytorch/pull/99546) explicitly required users to set `cast_forward_inputs=False` if they wanted to avoid hitting #99545 while using an FSDP root module with no direct parameters.
After further consideration, [the team believes](https://github.com/pytorch/pytorch/pull/99546#discussion_r1180898687) it is sufficiently common for the default `cast_forward_inputs=False` to be used with a FSDP root module possessing no direct parameters that a solution to #99545 that accommodates this use case is desired.
This PR builds on @zhaojuanmao's https://github.com/pytorch/pytorch/pull/100290 (nice!) to enhance the FSDP cast forward inputs testing to include a broader range of scenarios and to include `model.eval()` testing as well as training mode validation. (I unfortunately don't have permissions that would allow me to use ghstack directly but I can rebase this PR however the team desires, once #100290 lands etc.)
Currently, the evaluation mode testing is commented out while the team decides on the best approach to implementing the broader solution to https://github.com/pytorch/pytorch/pull/99545. Once an implementation is decided, the evaluation mode validation function in the new tests added in this PR can be uncommented and should continue to pass. I also include one potential evaluation mode solution suggestion in this PR but leave the existing code unchanged since I know the team is intending to consider a range of solutions this week.
Test notes:
1. The 8 tests added here are a superset of the current `test_float16_on_one_submodule` tests, including validation of the following configurations: (`cast_root_forward_inputs_submodule` = True/False, `cast_forward_inputs_submodule` = True/False, `use_root_no_params` = True/False) across both training and evaluation modes.
2. The `float16_on_one_submodule` model configuration is currently only tested in the FSDP root module with parameters scenarios (as was the existing case) but this test can be easily extended to test it in the FSDP root module with no parameters scenarios as well if the team thinks the additional test resource usage is justified.
3. Since this test amortizes the cost of test setup across the aforementioned range of scenarios, the loop-based implementation of `dtype` validation (below) would have been undesirably complex IMHO[^1] :
```python
############### Logical equivalent of current test result matrix ############
if self.cast_root_forward_inputs_submodule or self.cast_forward_inputs_submodule:
self.assertEqual(self.forward_inputs[self.c2].dtype, torch.float16)
if use_root_no_params:
if self.cast_root_forward_inputs_submodule:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float16)
else:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float32)
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float16)
else:
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float32)
else:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float32)
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float32)
if not use_root_no_params: # this input will only exist in the root with params case until eval fix is applied
self.assertEqual(self.forward_inputs[self.c2].dtype, torch.float32)
```
so I implemented the validation function as an expected result lookup that provides the added benefit of explicitly specifying the failed subtest upon failed `dtype` assertions, e.g.:
```python
AssertionError: None mismatch: torch.float32 is not None
Subtest `no_cast_root_no_cast_child_no_root_params` failed.
```
The potential solution to https://github.com/pytorch/pytorch/pull/99545 that I added as a suggestion in the file conversation passes this test set but I know there are a lot of different ways that it could be resolved so I'll assume that change will be tackled in a separate PR unless the team wants to include it in this one.
As mentioned, I've currently based this PR off of https://github.com/pytorch/pytorch/pull/100290 so am happy to either wait for that to land first or rebase this PR however the team wants.
[^1]: Batching the scenarios into different tests is also possible of course but would involve unnecessary test setup overhead, happy to switch to that approach if the team prefers that though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100349
Approved by: https://github.com/awgu
Currently, if we use NO_SHARD strategy for fully_shard and set state_dict_type to be SHARDED_STATE_DICT, a runtime error would be raised ("``sharded_state_dict`` can only be used when parameters are flatten and sharded.").
This PR updates pre_state_dict_hook, post_state_dict_hook, pre_load_state_dict_hook, and post_load_state_dict_hook to set state_dict_type and state_dict_config to full state when using NO_SHARD, even if the state_dict_type and state_dict_config of the root module is set to sharded state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100208
Approved by: https://github.com/rohan-varma
replicate + trec_shard works if we shard / replicate individually, such as follows:
```
m = TestSparseNN()
shard(m.sparse)
replicate(m.dense)
```
but does not work if users do the following:
```
m = TestSparseNN()
shard(m, sharders=[...])
replicate(m)
```
Many upstream trainers use the latter use case, as sharding is not done on individual module level but rather overall module by specifying planners that contain logic for how to shard different embedding table types.
This diff enables the latter approach (while keeping the former intact), but users need to specify `ignored_modules` to ignore embedding tables in replicate(). This is similar to FSDP (class based and composable) and DDP today.
Differential Revision: [D44899155](https://our.internmc.facebook.com/intern/diff/D44899155/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98890
Approved by: https://github.com/mrshenli, https://github.com/yhcharles
This PR splits `test_fully_shard.py` into `fully_shard/test_fully_shard<...>.py`. This should help improve readability and avoid some future rebase conflicts.
The only other real change is resolving a `TODO` for using `run_subtests` in the model checkpointing unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92296
Approved by: https://github.com/mrshenli
This PR adds FSDP and composable API files to `.lintrunner.toml` so that (1) lintrunner enforces that those files are formatted and (2) `lintrunner f` formats those files for you.
There are two requirements here (see https://github.com/pytorch/pytorch/wiki/lintrunner for details):
1. Install lintrunner:
```
pip install lintrunner
lintrunner init
```
2. `lintrunner f` before you finalize your PR, which would now be enforced by CI after this PR.
The code changes in this PR outside of `.lintrunner.toml` are the result of `lintrunner f`.
---
I only plan to land this PR if all of the composable API developers agree that this is something that makes sense and is not too intrusive to the workflow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90873
Approved by: https://github.com/yhcharles, https://github.com/mrshenli, https://github.com/rohan-varma
Cleaning FQN for `FullyShardedDataParallel(use_orig_params=True)` can cause some discrepancies with respect to the FQN compared to manually looping over `named_modules()` and `named_parameters()` together.
There is no requirement for the FQNs to be clean when using wrapper FSDP + `use_orig_params=True`. We can leave clean FQNs to `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91767
Approved by: https://github.com/zhaojuanmao
Cleaning FQN for `FullyShardedDataParallel(use_orig_params=True)` can cause some discrepancies with respect to the FQN compared to manually looping over `named_modules()` and `named_parameters()` together.
There is no requirement for the FQNs to be clean when using wrapper FSDP + `use_orig_params=True`. We can leave clean FQNs to `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91767
Approved by: https://github.com/zhaojuanmao
**What does this PR do?**
This PR refactor `_optim_utils.py` to use `_FSDPState` instead of `FullyShardedDataParallel` class. This change enables the support of optim state_dict for `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91234
Approved by: https://github.com/rohan-varma
This PR supports nesting `replicate` in `fully_shard`.
- The PR achieves this by treating `replicate`-annotated modules are ignored modules. This means that all submodules in the `replicate`-annotated module's subtree are ignored, including nested `fully_shard`-annotated modules, which is the desired behavior.
---
This PR reworks some tree traversal.
One end goal is for `state._handles` to follow the same order for both the wrapper and composable paths. This implies that `_get_fsdp_handles()` returns the same value for both paths.
- The helper function `_get_fully_sharded_module_to_states()` now follows a left-to-right DFS from each fully sharded module instead of a BFS. The left-to-right DFS follows `.modules()` order.
- The composable auto "wrap" initialization function `_init_param_handles_from_module()` follows the reverse left-to-right DFS order. As noted in the code comments, this initialization order is a valid reverse topological sort, but it differs from the wrapper path. This is the _only_ difference with respect to initialization order through the entire process.
```
mod: Module(
submod1: Submodule()
submod2: Submodule(
subsubmod: Subsubmodule(),
),
)
```
For left-to-right DFS, the order is `mod`, `submod1`, `submod2`, `subsubmod`. (For context, right-to-left DFS would be `mod`, `submod2`, `subsubmod`, `submod1`. In other words, the left-to-right vs. right-to-left corresponds to `.children()` vs. `reversed(.children())` respectively.) Then, reverse left-to-right DFS is `subsubmod`, `submod2`, `submod1`, `mod`, which is a valid initialization order. However, the wrapper auto wrap initialization order would be `submod1`, `subsubmod`, `submod2`, `mod` since it directly follows a left-to-right DFS and initializes as a part of the recursive DFS logic.
- At the end of `_init_param_handles_from_module()`, we reverse the newly populated `state._handles`, so this is the reverse reverse left-to-right DFS order, which is equivalent to the left-to-right DFS order. Thus, `state._handles` has the same order for both paths.
Another goal is for `_get_fsdp_states()` to not traverse into any submodule that is annotated with an API that is not compatible with `fully_shard` (e.g. `replicate`). To achieve this while preserving that `_get_fsdp_states()` follows `.modules()` order, we again use a left-to-right DFS.
The reason the DFSs may look strange is because I implemented them non-recursively, which requires a stack.
- `test_get_fully_sharded_module_to_states()` in `test_utils.py` checks the traversal order of `_get_fully_sharded_module_to_states()`.
- `test_policy()` in `test_fully_shard.py` checks the traversal order returned by `_get_fsdp_handles()`.
---
Due to a circular dependency issue, we must move the graph/tree traversal helpers to their own file `_traversal_utils.py`, and any usages must import the entire file like `import torch.distributed.fsdp._traversal_utils as traversal_utils` instead of `from torch.distributed.fsdp._traversal_utils import ...`.
The cycle comes from the fact that the traversals require `_composable()`, which requires `_get_registry()` from `composable/contract.py`, which when imported, imports `composable/fully_shard.py`, which requires the traversals.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91044
Approved by: https://github.com/mrshenli
This PR adds manual "wrapping" support for `fully_shard`. For example, for
```
fully_shard(mod.sub)
fully_shard(mod)
```
`mod.sub` and `mod` will share the same FSDP data structures.
To have parity with wrapper FSDP, this PR only checks support for when each manual application of `fully_shard` passes `policy=None`. Hybrid auto / manual wrapping is not in scope for this PR since it is not supported for wrapper FSDP either. I can follow up to either add support properly or raise and error early.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90874
Approved by: https://github.com/mrshenli
Ensures that load_state_dict for fully_shard works:
- Don't add back FSDP prefix
- Small fix to ensure mixed precision check for buffers work
Follow ups:
- state_dict_type does not work, blocking rank0_only and CPU offload as well as other state dict implementations
- No testing when wrapped with AC, using mixed precision, integration with distributed checkpoint, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90945
Approved by: https://github.com/awgu
**Why this PR?**
For the composable APIs implementation, sometimes the internal APIs may not have the application (FSDP, DDP) root module but only the local module. One example is the state_dict/optimizer_state_dict implementation of FSDP. These APIs are designed to start with the root module of the model. It is tricky for these APIs to tell whether a random submodule is managed by either DDP or FSDP.
It will be useful to have APIs like:
`_get_module_state(module)`: return the composable state if this module is managed by composable API.
`_get_module_fsdp_state(module)`: return the FSDP state if this module is managed by FSDP.
**What does this PR propose?**
1. Make `_State` out of `_composable` module so that `FullyShardedDataParallel` can inherit from it.
2. A global `_module_state_mapping: Dict[nn.Module, _State]` that keeps the mapping of all submodules (not just root module) to the state.
3. Create `_get_module_state(module)` to look up `_module_state_mapping`.
4. Create `_get_module_fsdp_state(module)` that uses `_get_module_state(module)` to get the state then verifies if the state is `_FSDPState`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89147
Approved by: https://github.com/awgu
Co-authored with @rohan-varma.
**Overview**
This adds preliminary `state_dict()` support for `fully_shard`.
- The only explicit branching between composable and wrapper code paths happens in the state dict hook registration, which is inevitable.
- We introduce a `_comm_module_prefix` to match the FQNs between the two code paths. This is needed since for composable, the FQNs are prefixed from the local FSDP root, whereas for state dict purposes, we want them to be prefixed from the comm. module. Thus, we need this `_comm_module_prefix` to be stripped during state dict.
- In my understanding, the alternative to not use the `prefix` argument in `state_dict()` does not support the case when `fully_shard` is applied to a submodule (i.e. not the global root module) since we still need _part_ of `prefix` then.
**Follow-Ups**
- We can retire the `functools.partial` usage once @fegin's PR lands.
- We should add more thorough testing (e.g. sharded state dict, save and load together etc.).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90767
Approved by: https://github.com/rohan-varma, https://github.com/fegin
{kind=link}