Currently, we return `unimplemented` w/o a graph break on seeing a x.unsqueeze_ when x is input. This essentially means we fall back to the original frame.
This PR actually graph breaks so that we can generate the continuation frame for the rest of the function. Instead of graph breaking at LOAD_ATTR, we delay the graph break to the actual CALL_FUNCTION, where its cleaner to graph break.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99986
Approved by: https://github.com/jansel
Follow up on Jason's idea of tensor layout tuning. Add a script to show the perf impact of layout to convolution (will add more cases like batch/layer norm, reduction to the scripts).
For convolution, a quick test shows using channels last layout, we get 1.4x speedup for convolution:
```
baseline 4.509183883666992 test 3.178528070449829 speedup 1.419x
```
The speedup definitely also depends on input/weight shapes. E.g., change input channel from 3 in the test to 8, we see speedup to be 2.1x
The trace shows cudnn calls different kernels when input layout changes to channels last.
<img width="997" alt="Screenshot 2023-04-19 at 5 27 54 PM" src="https://user-images.githubusercontent.com/52589240/233228656-4bdcac0a-7633-416a-82e1-17d8dc8ea9a6.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99583
Approved by: https://github.com/jansel
Previously, we had a problem when partitioning forward-backward dynamic graphs, which is that we could end up with a backward graph that mentions a symbol in an input tensor (e.g., `f32[s0 + s1]`), but without this symbol being otherwise bound elsewhere. When this happens, we have no way of actually deriving the values of `s0` and `s1`. Our fix for this in https://github.com/pytorch/pytorch/pull/93059 was to just retrace the graph, so that s0 + s1 got allocated a new symbol s2 and everything was happy. However, this strategy had other problems, namely (1) we lost all information from the previous ShapeEnv, including guards and (2) we end up allocating a LOT of fresh new symbols in backwards.
With this change, we preserve the same ShapeEnv between forward and backwards. How do we do this? We simply require that every symbol which may be present inside tensors, ALSO be a plain SymInt input to the graph. This invariant is enforced by Dynamo. Once we have done this, we can straightforwardly modify the partitioner to preserve these SymInt as saved for backwards, if they are needed in the backwards graph to preserve the invariant as well.
This apparently breaks yolov3, but since everything else is OK I'm merging this as obviously good and investigating later.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99089
Approved by: https://github.com/voznesenskym
Dynamo benchmark --verbose is broken:
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 400, in <module>
torchbench_main()
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 396, in torchbench_main
main(TorchBenchmarkRunner(), original_dir)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 1967, in main
return maybe_fresh_cache(
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 993, in inner
return fn(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 2135, in run
torch._dynamo.config.log_level = logging.DEBUG
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/config_utils.py", line 67, in __setattr__
raise AttributeError(f"{self.__name__}.{name} does not exist")
AttributeError: torch._dynamo.config.log_level does not exist
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99224
Approved by: https://github.com/voznesenskym
Allowed modules are stuck into dynamo's fx graph as call_module
nodes, without dynamo doing any tracing of the module. This means
during AOT trace time, hooks will fire during tracing when the
call_module is executed, but the hooks themselves will disappear
after that and not be present in the compiled program.
(worse, if they performed any tensor operations, those would get
traced so you could end up with part of the hook's functionality).
To circumvent this, there are two options for 'allowed modules' with hooks.
1) don't treat them as 'allowed' - trace into them
2) graph-break, so the module is no longer part of the dynamo trace at all
(1) will fail for users that opted into allowed modules becuase they know
their module has problems being traced by dynamo.
(2) causes graph breaks on common modules such as nn.Linear, just because they
are marked as 'allowed'.
It would help matters if we could differentiate between types of allowed modules
(A) allowed to avoid overheads - used for common ops like nn.Linear
(B) allowed to avoid dynamo graphbreaks caused by unsupported code
Ideally, we'd use method (1) for group (A) and (2) for (B).
For now, graph-break on all cases of allowed modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97184
Approved by: https://github.com/jansel
[perf-compare](https://github.com/pytorch/pytorch/actions/workflows/inductor-perf-compare.yml) has a different structure than that of the nightlies.
For these files, the script now generates:
```
# cuda float32 training performance results
## Geometric mean speedup
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 1.46 1.4 1.17
## Mean compilation time
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 57.85 97.63 60.18
## Peak memory compression ratio
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 1.06 1.01 0.83
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99095
Approved by: https://github.com/ezyang
Summary:
Replace _dynamo.config with an object instead of module
Current usage patterns of setting and reading fields on config will work
unchanged.
Only changes needed going forward:
1. import torch._dynamo.config will not work. However, just doing
import torch._dynamo is sufficient to access dynamo config
as torch._dynamo.config.
2. Files inside of _dynamo folder need to access config via
from torch._dynamo.config_util import config instead of
from torch._dynamo import config. Because _dynamo/__init__.py
imports some of the files so it would be circular import.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96455
Approved by: https://github.com/williamwen42
Summary: Skip mobilenet_v3_large for accuracy checking to reduce
noise on the dashboard. The root cause still needs to be investigated.
mobilenet_v3_large shows random accuracy check failures with different
error values from time to time, and here are some examples:
```
cuda train mobilenet_v3_large [2023-04-04 14:54:50,990] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.02172, (ref-fp64): 0.01068 and shape=torch.Size([960, 1, 5, 5])
[2023-04-04 14:54:50,990] torch._dynamo.utils: [ERROR] Accuracy failed for key name features.14.block.1.0.weight.grad
```
```
cuda train mobilenet_v3_large [2023-04-04 14:57:59,972] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.07744, (ref-fp64): 0.03073 and shape=torch.Size([72, 1, 5, 5])
[2023-04-04 14:57:59,973] torch._dynamo.utils: [ERROR] Accuracy failed for key name features.4.block.1.0.weight.grad
```
One observation is turnning off cudnn in the eager mode with
`torch.backends.cudnn.enabled = False` makes the non-deterministic
behvior go away but meanwhile it fails accuaracy checking consistently.
Minifier didn't help to narrow down the error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98314
Approved by: https://github.com/huydhn
Symbolic shapes compile time on full CI with inductor is horribly long (even though our aot_eager local runs seemed to suggest that the added latency was only 10s per model.) To patch over the problem for now, run the benchmark suite with dynamic batch only. This should absolve a lot of sins.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97912
Approved by: https://github.com/janeyx99, https://github.com/desertfire
Fixes#97382#95416 fixed a critical bug in dynamo benchmark, where AMP tests fall back to eager mode before that PR. However, after that PR, we found [a list of TIMM models amp + eager + training testing failed](https://docs.google.com/spreadsheets/d/1DEhirVOkj15Lu4UNawIUon9MqkVLaWqyT-DQPif5NHk/edit#gid=0).
Now we identified the root cause is: high loss values make gradient checking harder, as small changes in accumulation order upset accuracy checks. We should switch to the helper function ```reduce_to_scalar_loss``` which has been used by Torchbench tests.
After switching to ```reduce_to_scalar_loss```, TIMM models accuracy pass rate grows from 67.74% to 91.94% in my local test. The rest 5 failed models(ese_vovnet19b_dw, fbnetc_100, mnasnet_100, mobilevit_s, sebotnet33ts_256) need further investigation and handling, but I think it should be similar reason.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97423
Approved by: https://github.com/Chillee
previously this would clone triton, and then try to checkout without being in the git repo directory. This wasn't usually a problem because the environment already had a triton repo downloaded; but I ran into this while trying to construct a new environment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96623
Approved by: https://github.com/anijain2305
TODO (cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @ZainRizvi) hopefully i can convert the rocks query i'm using to a public API and delete the rocs api usage (and need for apikey) from this before landing. If that's not easy or if i need to make a new query first, maybe i should land this as-is and at least people can use it if they get an apikey. Also, any bad practices in how i parsed/mangled the filenames? Would be nice to make the naming of artifacts more consistent with the job names so less mangling is needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96480
Approved by: https://github.com/ZainRizvi
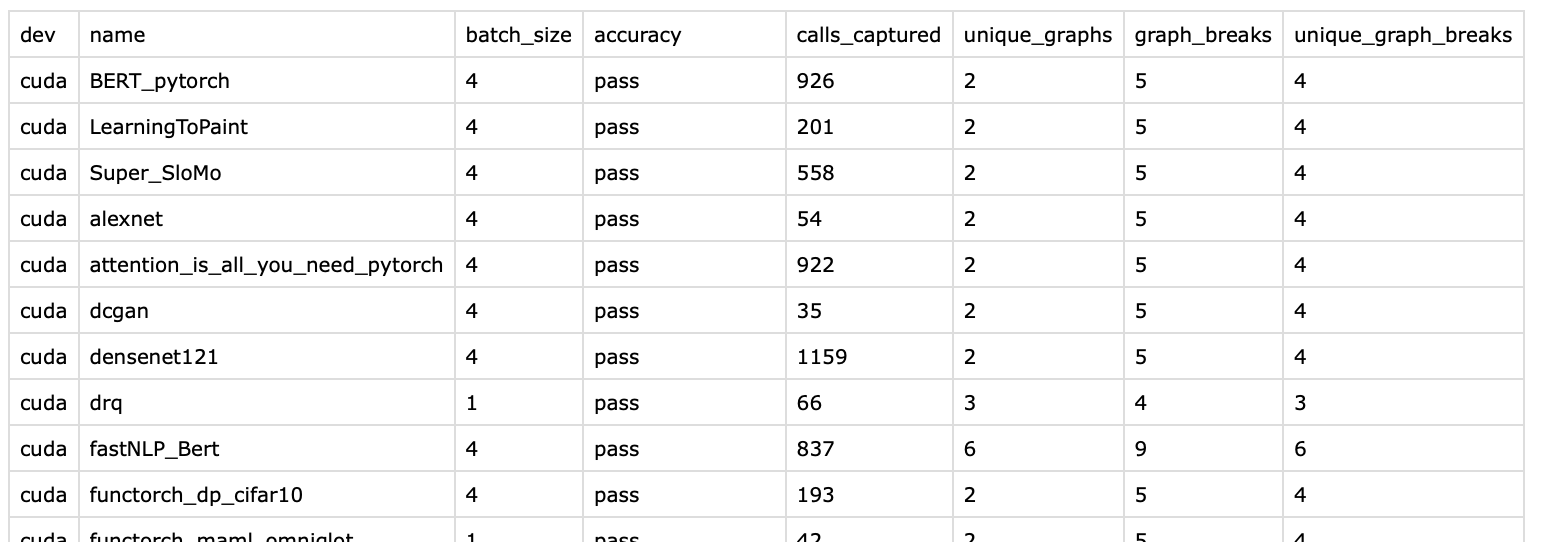
- add graph-breaks baselines
- add check_graph_breaks script (message users on regress or improvement)
- hook up test.sh for existing accuracy job
Refactor graph-break CI check
Take steps toward merging checker with existing check flow,
consider merging it all the way inside the bench runner.
csvs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96346
Approved by: https://github.com/ezyang
Current dashboard issue is due to a .pt file in torchbench that has beeen modified for some reason. This clears any local changes before pulling.
Tested in a duplicate dashboard environment with the same .pt file modified:
* Before the change to this makefile, `make pull-deps` fails
* After the change to this makefile, `make pull-deps` succeeds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96667
Approved by: https://github.com/anijain2305
I notice from the Rockset data that there are only `float32` records, while there should be both dtypes there. It turns out that the benchmarks script generated by `runner.py` always removes the output directory by default, so there are only records from `float32` running later left.
For example, `rm -rf /var/lib/jenkins/workspace/test/test-reports` appeared twice in the CI log https://ossci-raw-job-status.s3.amazonaws.com/log/11840774308.
I'm adding a new flag `--keep-output-dir` to keep the output directory. This is off by default as I'm not sure how this script is used internally, people probably expect to see the output directory cleaned up everytime.
### Testing
Not really want to start the 10h jobs just to test this small flag, so I'm triple check the change to make sure that there is no bug
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96398
Approved by: https://github.com/weiwangmeta
Follow-up to #96245. alexnet, Background_Matting, vision_maskrcnn, and vgg16 all have the same problem; but on float32 they were also failing on the previous day so I missed this. Once the amp jobs became available I could see that these have the same issue (on both float32 and amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96324
Approved by: https://github.com/desertfire
Summary: ciflow/inductor-perf-test-nightly now contains full dashboard
run which takes a very long time. Ed proposed a simplification of the
perf run there, but it is still worth to have a set of fast perf test
which only includes one configuration (--training --amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96166
Approved by: https://github.com/huydhn, https://github.com/weiwangmeta
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
Summary: When running the benchmark test with --accuracy, two eager runs
should return the same result. If not, we want to detect it early, but
comparing against fp64_output may hide the non-deterministism in eager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95616
Approved by: https://github.com/ZainRizvi
I believe this fixes the AllenaiLongformerBase problem in periodic.
The longer version of the problem is here is we are currently optimistically converting all item() calls into unbacked SymInt/SymFloat, but sometimes this results in a downstream error due to a data-dependent guard. Fallbacks for this case are non-existent; this will just crash the model. This is bad. So we flag guard until we get working fallbacks.
What could these fallbacks look like? One idea I have is to optimistically make data-dependent calls unbacked, but then if it results in a crash, restart Dynamo analysis with the plan of graph breaking when the item() call immediately happened.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94987
Approved by: https://github.com/Skylion007, https://github.com/malfet
```
GuardOnDataDependentSymNode: It appears that you're trying to get a value out of symbolic int/float whose value is data-dependent (and thus we do not know the true value.) The expression we were trying to evaluate is Eq(i3, -1). Scroll up to see where each of these data-dependent accesses originally occurred.
While executing %as_strided : [#users=1] = call_method[target=as_strided](args = (%pad,), kwargs = {size: (12, %add, 768, 64), stride: (%getitem, %mul, %getitem_1, %getitem_2)})
Original traceback:
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/models/longformer/modeling_longformer.py", line 928, in <graph break in _sliding_chunks_matmul_attn_probs_value>
chunked_value = padded_value.as_strided(size=chunked_value_size, stride=chunked_value_stride)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94986
Approved by: https://github.com/albanD
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
I applied some flake8 fixes and enabled checking for them in the linter. I also enabled some checks for my previous comprehensions PR.
This is a follow up to #94323 where I enable the flake8 checkers for the fixes I made and fix a few more of them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94601
Approved by: https://github.com/ezyang
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
The functorch setting still exists, but now it is no longer necessary:
we infer use of Python dispatcher by checking if the ambient
FakeTensorMode has a ShapeEnv or not. The setting still exists,
but it is for controlling direct AOTAutograd use now; for PT2,
it's sufficient to use torch._dynamo.config.dynamic_shapes.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94469
Approved by: https://github.com/Chillee, https://github.com/voznesenskym, https://github.com/jansel
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Change the dynamo benchmark timeout from hard code to a parameter with default value 1200ms, cause the hard code 1200ms timeout led some single thread mode model crashed on CPU platform. With the parameter, users can specify the timeout freely.
Fixes#94281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94284
Approved by: https://github.com/malfet
## Problem history
There seems to always have been a bug in `_vec_log_softmax_lastdim `.
In particular, there were two issues with it -
#### Bug 1
Before AVX512 support was added, `CHUNK_SIZE` had been heuristically chosen in `_vec_log_softmax_lastdim`:
`CHUNK_SIZE = (128 / sizeof(scalar_t)) * Vec::size();`
It was `256` for float32, bfloat16, and float16.
When AVX512 support was added, `CHUNK_SIZE` became `512`.
The rationale behind determining `CHUNK_SIZE` has not been described, and seems flawed, since the number of OpenMP threads used currently depends upon it.
#### Bug 2
`grain_size` had been defined as `internal::GRAIN_SIZE / (16 * dim_size * CHUNK_SIZE)`
So, `grain_size` was usually 0, as it was `8 / (dim_size)`, so, it's always replaced by `CHUNK_SIZE`, viz. 256.
Since `256` was always the `grain_size` for `at::parallel_for`, few threads were used in certain cases.
#### Problem caused by bugs
With `outer_size` of say, 700, only 3 threads would have been used with AVX2, irrespective of the value of `dim_size`!
When AVX512 support was added, since `CHUNK_SIZE` became `512`, only 2 threads were used if `outer_dim` was 700.
In the Transformers training example, `log_softmax` was computed on the last dim of a tensor of shape `(700, 23258)`.
AVX512 thus appeared to be quite slower, cloaking the actual issue that even AVX2 performance for the kernel was quite poor due to inefficient work distribution amongst OpenMP threads.
## Solution
Distribute work more efficiently, which would result in higher performance for both AVX2 & AVX512 than now,
and fixes the regression observed with AVX512 (AVX512 kernel would now be faster than its AVX2 counterpart).
## Benchmarks
##### Machine-config:
Intel(R) Xeon(R) Platinum 8371HC CPU (Cooper Lake)
One socket of 26 physical cores was used.
Intel OpenMP & tcmalloc were preloaded.
Example of a command to run benchmark:
`ATEN_CPU_CAPABILITY=avx512 KMP_AFFINITY=granularity=fine,verbose,compact,1,0 KMP_BLOCKTIME=1 KMP_SETTINGS=1 MKL_NUM_THREADS=26 OMP_NUM_THREADS=26 numactl --membind=0 --cpunodebind=0 python3.8 -m pt.softmax_test --test_name LogSoftmax_N1024_seq_len23258_dim1_cpu`
Benchmark | Old implementation time (us) | New implementation time (us) | Speedup ratio (old/new)
-- | -- | -- | --
LogSoftmax_N1024_seq_len23258_dim1_cpu AVX2 | 11069.281 | 2651.186 | 4.17x
LogSoftmax_N1024_seq_len23258_dim1_cpu AVX512 | 18292.928 | 2586.550| 7.07x
LogSoftmax_N700_seq_len23258_dim1_cpu AVX2 | 9611.902 | 1762.833 | 5.452x
LogSoftmax_N700_seq_len23258_dim1_cpu AVX512 | 12168.371 | 1717.824 | 7.08x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85398
Approved by: https://github.com/jgong5, https://github.com/mingfeima, https://github.com/peterbell10, https://github.com/lezcano
graph break != graph count - 1. Suppose you have a nested
inline function call f1 to f2 to f3. A graph break in f3
results in six graphs: f1 before, f2 before, f3 before, f3 after,
f2 after, f1 after.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94143
Approved by: https://github.com/voznesenskym
These backends have been broken for some time. I tried to get them
running again, but as far as I can tell they are not maintained.
Installing torch_tensorrt downgrades PyTorch to 1.12. If I manually
bypass that downgrade, I get import errors from inside fx2trt. Fixes that
re-add these are welcome, but it might make sense to move these wrappers
to the torch_tensorrt repo once PyTorch 2.0 support is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93822
Approved by: https://github.com/frank-wei
As @peterbell10 pointed out, it was giving incorrect results for `compression_ratio`
and `compression_latency` when you used `--diff-branch`.
This fixes this by running a separate subprocess for each branch to make sure you are not being affected by run for other branch.
Also added a couple of more significant figures
to numbers in summary table.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93989
Approved by: https://github.com/jansel
# Summary
In preparation for pt 2.0 launch this PR updates SDPA's API and makes the function a nn.funcitonal public function.
## Changes
### API
Previously the the function signature was:
`scaled_dot_product_attention(query, key, value, attn_mask=None, need_attn_weights=False, dropout_p=0.0, is_causal=False) -> (Tensor, Tensor)`
Updated signature:
`scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False) -> Tensor`
This PR removes the need_attn_weights optional boolean variable and updates the return type to a singular tensor.
#### Reasoning:
The main goal of this function is to provide an easy interface for users to call into fused attention kernels e.g. (FlashAttention). The fused kernels do not currently support arbitrary attn_mask or dropout but there is a PR to mem-efficient attention to enable these. We want to have the API surface ready for when the backing kernels get updated.
The fused kernels save on memory usage by not materializing the weights and it is unlikely that a fast fused implementation will enable this feature so we are removing.
Discussed with folks at FAIR/Xformers and +1 this API change.
#### Make function Public
In preparation for the pt 2.0 launch we make the function public to start to generate user feedback
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92189
Approved by: https://github.com/cpuhrsch
Saw some places we missed some old requirements that are no longer necessary (dataclasses and future). Testing to see if all the CIs still work. We don't need dataclasses anymore now that we are on Python >= 3.7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92763
Approved by: https://github.com/ezyang
--diff_main renamed to --diff-branch BRANCH and now works again
Summary table splits results per branch.
csv output now has column with branch name when run in this mode
Added --progress flag so you can track how many models are going to be
run.
Example output:
```
$ python benchmarks/dynamo/torchbench.py --quiet --performance --backend inductor --float16 --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt) --filter 'alexnet|vgg16' --progress --diff viable/strict
Running model 1/2
batch size: 1024
cuda eval alexnet dynamo_bench_diff_branch 1.251x p=0.00
cuda eval alexnet viable/strict 1.251x p=0.00
Running model 2/2
batch size: 128
cuda eval vgg16 dynamo_bench_diff_branch 1.344x p=0.00
cuda eval vgg16 viable/strict 1.342x p=0.00
Summary for tag=dynamo_bench_diff_branch:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.09x mean=25.26x
compilation_latency mean=2.0 seconds
compression_ratio mean=0.9x
Summary for tag=viable/strict:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.11x mean=25.29x
compilation_latency mean=0.5 seconds
compression_ratio mean=1.0x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92713
Approved by: https://github.com/jansel
Since the CI exclusions are hard-coded in our script, we might as well require them to match exactly. This solved some head scratching where I was like, "this model is not obviously excluded, why is it not showing up in CI."
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92761
Approved by: https://github.com/jansel
Since the dynamic aot_eager CI skips list is very short now,
I find that I need to run this script with other flags now.
Make it more easy to change the flags.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92581
Approved by: https://github.com/bdhirsh
@bypass-github-export-checks
Pointwise Conv2d is one of the ops which we want to benchmark using different Vulkan Shaders (```conv2d_pw_2x2``` vs ```conv2d_pw_1x1```) with
The configs are copied from Conv2d with the kernel parameter removed.
I considered just using the same configs but ignoring the provided kernel and hardcoding the kernel to 1 when initializing nn.Conv2d, but then in the op benchmark title, it would say kernel=3 even if though that would not be the case.
Differential Revision: [D42303453](https://our.internmc.facebook.com/intern/diff/D42303453/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91918
Approved by: https://github.com/mcr229
We've already shown some promising perf result by integrating dynamo with torchxla for inference. To provide consistent UX for training and for inference, in this PR we try to enable training for dynamo/torchxla.
Training is trickier than inference and we may not expect much perf gains since
1. in training case, torchxla only generate a single combined graph for fwd/bwd/optimizer while in `torchxla_trace_once` bridge we added in dynamo, due to how AOT_Autograd works, we will generate 3 graphs: one for forward, one for backward and one for the optimizer. XLA favors larger graph to do more optimizations.
2. in training case, tracing overhead can be overlapped with computation. Tracing overhead is not as a big deal for training as for inference. After all training cares more about throughput while inference cares more about latency.
3. in training case, people can increase batch size to 'mitigate' the tracing overhead. Increase batch size does not change tracing overhead, thus it shows like the tracing overhead 'per example' reduces.
But we still want to add training support to dynamo/torchxla to make the work complete.
We added '--iterations-per-run' argument to control how may iterations we do per measure/device sync. This is to understand the impact of item 2 above.
Results:
With '--iterations-per-run' equals to 1, here are the perf numbers:
```
+-------------------------+--------------------+-------------------------+
| Model | XLA (trace once) | XLA (trace everytime) |
+=========================+====================+=========================+
| resnet18 | 0.91 | 0.959 |
+-------------------------+--------------------+-------------------------+
| resnet50 | 0.917 | 0.932 |
+-------------------------+--------------------+-------------------------+
| resnext50_32x4d | 0.912 | 0.905 |
+-------------------------+--------------------+-------------------------+
| alexnet | 1.038 | 0.974 |
+-------------------------+--------------------+-------------------------+
| mobilenet_v2 | 0.881 | 0.835 |
+-------------------------+--------------------+-------------------------+
| mnasnet1_0 | 0.903 | 0.931 |
+-------------------------+--------------------+-------------------------+
| vgg16 | 0.914 | 0.967 |
+-------------------------+--------------------+-------------------------+
| BERT_pytorch | 1.359 | 0.84 |
+-------------------------+--------------------+-------------------------+
| timm_vision_transformer | 1.288 | 0.893 |
+-------------------------+--------------------+-------------------------+
| geomean | 1.0006 | 0.913794 |
+-------------------------+--------------------+-------------------------+
```
Overall it looks like graph break indeed cause perf loss. But for BERT_pytorch and timm_vision_transformer we still see perf gain. We need do more experiments with larger '--iterations-per-run'
NOTE:
In torchbench.py I added the following code to do a few workaround:
```
from myscripts import workaround # TODO will remove this line before landing
```
Here are the content of workaround.py:
```
import torch
from torch import nn
import os
# override max_pool2d with avg_pool2d
if os.environ.get("REPLACE_MAXPOOL", "0") == "1":
torch.nn.MaxPool2d = torch.nn.AvgPool2d
```
It work around a few issues we found
1. MaxPool2d does not work for training in dynamo/torchxla: https://github.com/pytorch/torchdynamo/issues/1837 . WIP fix from Brian in https://github.com/pytorch/pytorch/pull/90226 , https://github.com/pytorch/xla/pull/4276/files (WIP)
2. recent change ( this PR https://github.com/pytorch/pytorch/pull/88697 ) in op decomposition cause batch_norm ops to fallback in torchxla. Fix from jack in https://github.com/pytorch/xla/pull/4282#event-7969608134 . (confirmed the fix after adding Deduper to handle duplicated return from fx graph generated by AOTAutograd)
3. we have issue to handle dropout because of random seed out of sync issue. Here is the fix: https://github.com/pytorch/xla/pull/4293 (confirmed the fix)
Example command:
```
REPLACE_MAXPOOL=1 USE_FAKE_TENSOR=0 GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --training --backend=aot_torchxla_trace_once --only vgg16
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88449
Approved by: https://github.com/wconstab, https://github.com/qihqi, https://github.com/malfet
Summary:
1) Setting torch.backends.cudnn.deterministic to True helps to
eliminate the eager_variance failures seen on CI
2) Skip Triton failure instead of retry
3) Some minor script cleanup is also included in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91283
Approved by: https://github.com/anijain2305
Fixes https://github.com/pytorch/torchdynamo/issues/1995
Running `python benchmarks/dynamo/timm_models.py --performance --float32 -dcuda --output=out.csv --training --inductor --only bad_model_name` gives
```
Traceback (most recent call last):
File "benchmarks/dynamo/timm_models.py", line 338, in <module>
main(TimmRunnner())
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 1660, in main
return maybe_fresh_cache(run, args.cold_start_latency and args.only)(
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 833, in inner
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 2000, in run
) = runner.load_model(device, model_name, batch_size=batch_size)
File "benchmarks/dynamo/timm_models.py", line 215, in load_model
raise RuntimeError(f"Failed to load model '{model_name}'")
RuntimeError: Failed to load model 'bad_model_name'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91049
Approved by: https://github.com/ezyang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}