**Motivation:**
We try to make torch.cond use torch.compile automatically so that we could error out when there is side-effects in the branches and correctly handle the closures.
Before this PR, we have a warning if we don't turn on a config raise_on_backend_change (turning it on gives us an error) for the following code:
```python
def foo()
# Inside torch.cond, we'd like to do something like
torch.compile(foo, backend="eager", fullgraph=True)(...)
...
# Users may then call torch.compile somewhere else.
# Dynamo will use the cached code of foo for "eager" backend
# but we expect dynamo to recompile with "inductor" backend.
torch.compile(foo, backend="inductor")(...)
```
This PR adds a BACKEND_MATCH guard. Effectively, it implements a per-backend cache. In the above example, the cached code for "eager" won't work for "inductor" due to guard check failures and the second torch.compile will do a re-compilation. In the future, it might be useful to have something like a configuration guard that guards against dynamo configuration changes across different compiles (e.g. compile a function with fullgraph=False then compile it again with fullgraph=True).
**Implementation:**
1. We add a guarded_backend_cache and check the most_recent_backend against the backend associated with cached code. We also remove the raise_on_backend_change flag.
2. Then newly added context manager and guard adds more lines for debug log so we change the uppper limit from 50 to 55.
**Test Plan:**
Removed original tests that raise on different backend and add a new test to test whether the BACKEND_MATCH guard can guard against backend change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107337
Approved by: https://github.com/jansel
Currently numel only supports static shapes, but this expands it to support
generating symbolic arithmetic into the graph. e.g.
```
# x.size().numel with x.size() = [s0, 1, s1]
size = l_x_.size()
getitem = size[0]
getitem_2 = size[2]; size = None
mul = getitem * getitem_2; getitem = getitem_2 = None
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108239
Approved by: https://github.com/ezyang
**Background**: "TorchDynamo Cache Lookup" events appear in traces to indicate a dynamo cache lookup; it's useful to check when cache lookups are taking a long time. To add a profiler event, one can use the `torch.profiler.record_function` context manager, or the C++ equivalent. Previously, the python version was used; first, when the profiler was enabled, callbacks for record_function_enter and record_function_exit were registered; then those would be called before and after every cache lookup.
**This PR**: Instead of calling the python bindings for `torch.profiler.record_function`, directly call the C++ implementation. This simplifies a lot of the code for binding C/C++. It also improves performance; previously there was a lot of overhead in the "TorchDynamo Cache Lookup" event, making the event artificially take a long time. After this change the events now appear shorter, because there's less overhead in starting/stopping the event: in other words, the profiler no longer distorts the results as much.
**Performance results**:
I ran using the script below on a cpu-only 1.6GHz machine. I report the median time (from 100 measurements) of a "TorchDynamo Cache Lookup" event before and after this PR. I think it is reasonable to consider the difference to be due to a reduction in overhead.
<details>
<summary>Benchmarking script</summary>
```python
def fn(x, y):
return (x * y).relu()
a, b = [torch.rand((4, 4), requires_grad=True) for _ in range(2)]
opt_fn = torch.compile(fn)
opt_fn(a, b)
opt_fn(a, b)
with torch.profiler.profile() as prof:
opt_fn(a, b)
```
</details>
Median before PR: 198-228 us (median of 100, measured 5 times)
Median after PR: 27us
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108436
Approved by: https://github.com/anijain2305, https://github.com/jansel
In https://github.com/pytorch/pytorch/pull/106673 , I created a private API `_debug_get_cache_entry_list` to help pull out cache entries from compiled functions.
Recently, I find that @anijain2305 commented in the code that this API should be revisited, and so I created this PR.
First, this API cannot be removed even if cache entry becomes a first-class python class`torch._C._dynamo.eval_frame._CacheEntry`. The facts that `extra_index` is static, and `get_extra_state` is inline static, make them not accessible elsewhere. This API `_debug_get_cache_entry_list` is the only way for users to get all the cache entries from code.
Second, since the`torch._C._dynamo.eval_frame._CacheEntry` class is a python class, I simplified the C-part code, and remove the necessity of creating a namedtuple for this in the python code.
Third, I also add a small improvement, that if the argument is a function, we can automatically pass its `__code__` to the API.
The above change will slightly change the output, from list of named tuple to list of `torch._C._dynamo.eval_frame._CacheEntry`. I will update the corresponding docs that use this API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108335
Approved by: https://github.com/jansel, https://github.com/anijain2305
# Summary
## PR Dependencies
I don't use ghstack :( this is a PR where it would have been helpful. That beings said I am going to peel off some PRs to make reviewing this easier:
- [x] Separate build flags for Flash and MemEff: #107985
### Description
This pull request updates the version of _scaled_dot_product_flash_attention from version 1 to version 2. The changes are based on the flash attention code originally authored by @tridao
### Changes Made
The majority of the changes in this pull request involve:
- Copying over the flash_attention sources.
- Updating header files.
- Removing padding and slicing code from within the flash_attention kernel and relocating it to the composite implicit region of the SDPA. This was need to make the kernel functional and appease autograd.
- Introducing a simple kernel generator to generate different instantiations of the forward and backward flash templates.
- Adding conditional compilation (ifdef) to prevent building when nvcc is invoked with gencode < sm80.
- Introducing a separate dependent option for mem_eff_attention, as flash_attention v2 lacks support for Windows and cannot be built for sm50 generation codes.
- Modifying build.sh to reduce parallelization on sm86 runners and to lower the maximum parallelization on the manywheel builds. This adjustment was made to address out-of-memory issues during the compilation of FlashAttentionV2 sources.
- Adding/Updating tests.
### Notes for Reviewers
This is not a fun review, and I apologize in advance.
Most of the files-changed are in the flash_attn/ folder. The only files of interest here IMO:
- aten/src/ATen/native/transformers/cuda/flash_attn/flash_api.cpp
- aten/src/ATen/native/transformers/cuda/flash_attn/kernels/generate_kernels.py ( this has been incorporated upstream to flash-attention github)
There are a number of files all related to avoiding OOMs in CI/CD. These are typically shell scripts.
### Follow up items
- Include the updates from e07aa036db and 9e5e8bc91e | https://github.com/pytorch/pytorch/issues/108108
### Work Items
- [x] I don't think Windows will be supported for 3.1.0 - Need to update cmakee
- [x] Let multi_query/attention pass through and test | UPDATE: I have the fast path implemented here: https://github.com/pytorch/pytorch/pull/106730 but since this will require changes to semantics of math to call repeat_interleave, I think this should be done as a followup.
- [x] Had to drop cutlass back to 3.0.0 to get it to compile. Need to figure out how to upgrade to 3.1.0 and later. Spoke with Tri and he is going to be taking a look. Note: compiling with clang currently errors for the cute headers.
- [x] Update test exercise above codepath
- [x] Still need to disable on seq_len % 128 != 0 for backward( Tri beat me to it a4f148b6ab)
- [x] Add determinism warning to BWD, Tri got to this one as well: 1c41d2b
- [x] Update dispatcher to universally prefer FlashV2
- [x] Update tests to exercise new head_dims
- [x] Move the head_dim padding from kernel to top level composite implicit function in order to make it purely functional
- [x] Create template generator script
- [x] Initial cmake support for building kernels/ folder
- [x] Replay CudaGraph changes
### Results
#### Forward only
The TFlops are reported here are on a100 that is underclocked.

#### Forward+Backward
Ran a sweep and for large compute bound sizes we do see a ~2x performance increase for forw+back.
<img width="1684" alt="Screenshot 2023-07-20 at 3 47 47 PM" src="https://github.com/pytorch/pytorch/assets/32754868/fdd26e07-0077-4878-a417-f3a418b6fb3b">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105602
Approved by: https://github.com/huydhn, https://github.com/cpuhrsch
This pattern shows up in torchrec KeyedJaggedTensor. Most
of the change in this PR is mechanical: whenever we failed
an unbacked symint test due to just error checking, replace the
conditional with something that calls expect_true (e.g.,
torch._check or TORCH_SYM_CHECK).
Some of the changes are a bit more nuanced, I've commented on the PR
accordingly.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106788
Approved by: https://github.com/lezcano
ghstack dependencies: #106720
RFC: https://github.com/pytorch/rfcs/pull/54
First commit is the contents of https://github.com/Quansight-Labs/numpy_pytorch_interop/
We have already been using this in core for the last few months as a external dependency. This PR pulls all these into core.
In the next commits, I do a number of things in this order
- Fix a few small issues
- Make the tests that this PR adds pass
- Bend backwards until lintrunner passes
- Remove the optional dependency on `torch_np` and simply rely on the upstreamed code
- Fix a number dynamo tests that were passing before (they were not tasting anything I think) and are not passing now.
Missing from this PR (but not blocking):
- Have a flag that deactivates tracing NumPy functions and simply breaks. There used to be one but after the merge stopped working and I removed it. @lezcano to investigate.
- https://github.com/pytorch/pytorch/pull/106431#issuecomment-1667079543. @voznesenskym to submit a fix after we merge.
All the tests in `tests/torch_np` take about 75s to run.
This was a work by @ev-br, @rgommers @honno and I. I did not create this PR via ghstack (which would have been convenient) as this is a collaboration, and ghstack doesn't allow for shared contributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106211
Approved by: https://github.com/ezyang
This PR makes Z3 expressions easier to read and understand by creating a custom printer
for them.
Z3 expressions can be printed in 2 forms:
1. Using the builtin `str(e)` function
2. Using the `e.sexpr()` method
Problem is that (1) is a bit hard to read because its line breaks are not so
intuitive. (2) is a bit nicer, but the `to_int` and `to_real` functions clutter things up.
The custom printer is an improved `sexpr()` function:
- Leaves everything in one line
- Gets rid of `to_int` and `to_real` functions
- Reconstruct the floor division operations
- Merge commutative operation chains
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106643
Approved by: https://github.com/ezyang
When inlining a function which loads a closure, its direct parent may not load that closure. So we cannot find the closure name in parent's symbolic locals. In this PR, we fix it by recursively searching the parent instruction translator stack to resolve the closure.
**Background**
When developing https://github.com/pytorch/pytorch/pull/105679, this corner case is triggered. A small repro is added in the test of this pr, where outer is loaded by deep2 but not by deep.
```python
def test_inline_closure_not_loaded_by_parent(self):
def outer(a):
return a + 1
def indirect(x):
return direct(x)
def direct(x):
def deep2(c):
return outer(c)
def deep(c):
return deep2(c)
return deep(x)
x = torch.randn(3)
eager = indirect(x)
counter = CompileCounter()
compiled = torch._dynamo.optimize(counter)(indirect)(x)
```
Running the test, we have the following error before the PR:
```
Traceback (most recent call last):
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6584, in test_inline_closure_not_loaded_by_parent
compiled = torch._dynamo.optimize(counter)(indirect)(x)
File "/home/yidi/local/pytorch/torch/_dynamo/eval_frame.py", line 321, in _fn
return fn(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/eval_frame.py", line 481, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 543, in _convert_frame
result = inner_convert(frame, cache_size, hooks, frame_state)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 130, in _fn
return fn(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 362, in _convert_frame_assert
return _compile(
File "/home/yidi/local/pytorch/torch/_dynamo/utils.py", line 194, in time_wrapper
r = func(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 531, in _compile
raise InternalTorchDynamoError(str(e)).with_traceback(e.__traceback__) from None
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 432, in _compile
out_code = transform_code_object(code, transform)
File "/home/yidi/local/pytorch/torch/_dynamo/bytecode_transformation.py", line 1028, in transform_code_object
transformations(instructions, code_options)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 417, in transform
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2067, in run
super().run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 261, in call_function
return super().call_function(tx, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2279, in inline_call_
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2279, in inline_call_
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2227, in inline_call_
sub_locals, closure_cells = func.bind_args(parent, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 471, in bind_args
result[name] = parent.symbolic_locals[name]
torch._dynamo.exc.InternalTorchDynamoError: outer
from user code:
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6570, in indirect
return direct(x)
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6579, in direct
return deep(x)
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6577, in deep
return deep2(c)
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
import torch._dynamo
torch._dynamo.config.suppress_errors = True
To execute this test, run the following from the base repo dir:
python test/dynamo/test_misc.py -k test_inline_closure_not_loaded_by_parent
This message can be suppressed by setting PYTORCH_PRINT_REPRO_ON_FAILURE=0
---------------------------------------------------------------------------------------------------------------------------- Captured stdout call -----------------------------------------------------------------------------------------------------------------------------
frames [('total', 1)]
inline_call []
---------------------------------------------------------------------------------------------------------------------------- Captured stderr call -----------------------------------------------------------------------------------------------------------------------------
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __init__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __enter__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping helper /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __init__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __enter__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping enable_dynamic /home/yidi/local/pytorch/torch/_dynamo/eval_frame.py
[2023-08-02 15:48:36,561] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6569
TRACE starts_line indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6569
def indirect(x):
[2023-08-02 15:48:36,591] torch._dynamo.variables.builder: [DEBUG] wrap_to_fake L['x'] (3,) [<DimDynamic.STATIC: 2>] [None]
TRACE starts_line indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6570
return direct(x)
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_DEREF direct []
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST x [UserFunctionVariable()]
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [UserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] INLINING <code object direct at 0x7fbe4d366810, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6572>
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6572 (inline depth: 1)
def direct(x):
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6573 (inline depth: 1)
def deep2(c):
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CLOSURE outer []
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE BUILD_TUPLE 1 [InlinedClosureVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST <code object deep2 at 0x7fbe4d3666b0, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6573> [TupleVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST MiscTests.test_inline_closure_not_loaded_by_parent.<locals>.direct.<locals>.deep2 [TupleVariable(), ConstantVariable(code)]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE MAKE_FUNCTION 8 [TupleVariable(), ConstantVariable(code), ConstantVariable(str)]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE STORE_DEREF deep2 [NestedUserFunctionVariable()]
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6576 (inline depth: 1)
def deep(c):
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CLOSURE deep2 []
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE BUILD_TUPLE 1 [NewCellVariable()]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576> [TupleVariable()]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST MiscTests.test_inline_closure_not_loaded_by_parent.<locals>.direct.<locals>.deep [TupleVariable(), ConstantVariable(code)]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE MAKE_FUNCTION 8 [TupleVariable(), ConstantVariable(code), ConstantVariable(str)]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE STORE_FAST deep [NestedUserFunctionVariable()]
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6579 (inline depth: 1)
return deep(x)
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST deep []
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST x [NestedUserFunctionVariable()]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [NestedUserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] INLINING <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576>
TRACE starts_line deep /home/yidi/local/pytorch/test/dynamo/test_misc.py:6576 (inline depth: 2)
def deep(c):
TRACE starts_line deep /home/yidi/local/pytorch/test/dynamo/test_misc.py:6577 (inline depth: 2)
return deep2(c)
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_DEREF deep2 []
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST c [NestedUserFunctionVariable()]
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [NestedUserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576>
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object direct at 0x7fbe4d366810, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6572>
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
```
Test Plan:
add new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106491
Approved by: https://github.com/williamwen42, https://github.com/jansel, https://github.com/zou3519
Fix: #105074
This PR makes dynamo handle Numpy global variables the same way as PyTorch tensor global
variables by tracking them as side-effect.
In summary, we add `NumpyNdarrayVariable` to the
`VariableBuilder._can_lift_attrs_to_inputs` function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105959
Approved by: https://github.com/ezyang
Since Python 3.11 bytecode contains endline and column information, for each bytecode, we attribute the source code corresponding to the bytecode in a more accurate way. For example, we can highlight a function call in a series of nested function calls, or highlight a function call spanning multiple lines.
Sample:
```python
import torch
import torch._dynamo
from functorch.experimental.control_flow import cond
def h(x):
return x * 5
def true_fn(x):
return x * 2
def false_fn(x):
return x * 3
def f(pred, x):
x = h(
h(h(x))
)
x = x[1:][:2]
torch._dynamo.graph_break()
x = cond(pred, true_fn, false_fn, [x])
opt_f = torch.compile(f, backend="eager")
opt_f(torch.tensor(True), torch.randn(3, 3, 3, 3))
```
Output:
```
$ TORCH_LOGS="trace_call" python playground9.py
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:16
h(h(x))
~^^^
TRACE FX call mul from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:16
h(h(x))
~^^^^^^
TRACE FX call mul_1 from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:15
x = h(
~^
h(h(x))
^^^^^^^
)
^
TRACE FX call mul_2 from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE FX call getitem from f /scratch/williamwen/work/pytorch/playground9.py:18
x = x[1:][:2]
~^^^^
TRACE FX call getitem_1 from f /scratch/williamwen/work/pytorch/playground9.py:18
x = x[1:][:2]
~~~~~^^^^
TRACE inlined call true_fn from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TRACE FX call mul from true_fn /scratch/williamwen/work/pytorch/playground9.py:9 (inline depth: 1)
return x * 2
~~^~~
TRACE inlined call false_fn from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TRACE FX call mul from false_fn /scratch/williamwen/work/pytorch/playground9.py:12 (inline depth: 1)
return x * 3
~~^~~
TRACE FX call cond from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104676
Approved by: https://github.com/ezyang
Fixes: #105143
In summary, the changes are:
- Check if Z3 is installed when the module is loaded
- Naming consistently as "translation validation" (not "validator")
- Skipping tests if Z3 is not installed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105168
Approved by: https://github.com/ezyang
Original PR: #103546
Trying to support numpy function call in dynamo, with numpy dtype as argument.
For example:
```
def fn(x: int):
return np.empty_like(x, dtype=np.float64)
```
This currently doesn't work because `NumpyVariable` doesn't implement `as_proxy()`. The idea in `as_proxy()` for now is to convert `np.float64` and other np.<dtype> into `str` and then feed into the corresponding `torch_np` method. The assumption here is that all `torch_np` methods that are taking `dtype` kwarg will be able to also take `str` as `dtype`. This assumption stands for `numpy`.
For previous example, we convert `np.float64` to `"float64"` in `as_proxy()` and then feed it into `torch_np.empy_like()` method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105034
Approved by: https://github.com/voznesenskym
## Problem
Trying to support numpy function call in dynamo, with numpy dtype as argument.
For example:
```
def fn(x: int):
return np.empty_like(x, dtype=np.float64)
```
## Solution
This currently doesn't work because `NumpyVariable` doesn't implement `as_proxy()`. The idea in `as_proxy()` for now is to convert `np.float64` and other np.<dtype> into `torch.dtype` and then feed into the corresponding `torch_np` method.
For previous example, we convert `np.float64` to `torch.float64` in `as_proxy()` and then feed it into `torch_np.empy_like()` method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103546
Approved by: https://github.com/ezyang
Python `mod` semantics is not the same as the mathematical modulus operation. According to
the Python reference: `a = floor(a / b) * b + a % r`.
In other words: `a % b = a - floor(a / b) * b`.
This PR fixes the old implementation which used SMT-LIB2 semantics for `mod`. In short, it
only worked with integers and had the following guarantee: `0 <= a % b < b`.
In summary, the changes are:
- `a % b = a - floordiv(a, b) * b`
- `a` and `b` can be both integer or real
- The result will be real if any of the arguments is real. Otherwise, it will be integer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104827
Approved by: https://github.com/lezcano
Some notes:
* I now manually turn off `_generate` jobs from running with cudagraphs, as it is unrealistic to expect to cudagraph autoregressive generation up to max sequence length, this would imply compiling the entire unrolled sequence generation. Concretely, cm3leon_generate was timing out post this change, likely due to the compile time slowdown of dynamic shapes ON TOP OF accidentally unrolling all the loops
* A few torch._dynamo.reset tactically inserted to force recompiles on tests that expected it
* expectedFailureAutomaticDynamic flip into patching automatic_dynamic_shapes=False
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103623
Approved by: https://github.com/voznesenskym
This PR turns translation validation on by default for tests and accuracy benchmark
runs. It also installs Z3 on CI.
The main changes are:
- Add `--no-translation-validation` as an option in _test/run_tests.py_
- Set `PYTORCH_TEST_WITH_TV` environment variable
- Add `TEST_WITH_TV` variable in _torch/testing/_internal/common_utils.py_
- Turn translation validation on for accuracy benchmarks in _benchmarks/dynamo/common.py_
- Add Z3 installation on CI scripts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103611
Approved by: https://github.com/ezyang
Fix https://github.com/pytorch/pytorch/issues/99639 by handling the case in `InliningInstructionTranslator`'s `LOAD_CLOSURE` definition when the requested cell is not in `self.closure_cells`.
My intuition is that the behavior of `LOAD_DEREF` and `STORE_DEREF` on a cell/freevar should not depend on whether or not we called `LOAD_CLOSURE` (that is, we shouldn't create a new cell var in `LOAD_CLOSURE` like in https://github.com/pytorch/pytorch/pull/101357). But we need a way to push cells created by the inlined function that were not present in the caller - `InlinedClosureVariable` is used to differentiate these cells from other cells.
Adding this test causes an error though (EDIT: this test is not relevant to this PR and instead just reveals that `cond` with Python side effects is still broken):
```python
def test_closure_out_of_scope_cell_with_cond(self):
from functorch.experimental.control_flow import cond
cell1 = torch.rand(3, 3)
cell2 = torch.rand(3, 3)
orig3 = torch.rand(3, 3)
def test(x):
cell3 = orig3.clone()
def then():
nonlocal cell3
cell3 += cell1
return cell3
def els():
nonlocal cell3
cell3 += cell2
return cell3
return cond(x > 0, then, els, [])
opt_fn = torch._dynamo.optimize("eager")(test)
result1 = opt_fn(1)
self.assertTrue(torch.allclose(result1, orig3 + cell1))
result2 = opt_fn(-1)
self.assertTrue(torch.allclose(result1, orig3 + cell1 + cell2))
```
```
Traceback (most recent call last):
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1768, in test_closure_out_of_scope_cell_with_cond
result1 = opt_fn(1)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/eval_frame.py", line 295, in _fn
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/eval_frame.py", line 448, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 526, in _convert_frame
result = inner_convert(frame, cache_size, hooks, frame_state)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 127, in _fn
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 360, in _convert_frame_assert
return _compile(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/utils.py", line 180, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 430, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/bytecode_transformation.py", line 1000, in transform_code_object
transformations(instructions, code_options)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 415, in transform
tracer.run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2029, in run
super().run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 708, in run
and self.step()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 668, in step
getattr(self, inst.opname)(inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 391, in wrapper
return inner_fn(self, inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 1100, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 559, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 1061, in call_function
(false_r, false_graph, false_lifted_freevars) = speculate_branch(False)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 1044, in speculate_branch
ret_val, ret_graph, ret_lifted_freevars = speculate_subgraph(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 850, in speculate_subgraph
output = f.call_function(tx, args, {})
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/functions.py", line 121, in call_function
return tx.inline_user_function_return(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 595, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2134, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2231, in inline_call_
tracer.run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 708, in run
and self.step()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 668, in step
getattr(self, inst.opname)(inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 162, in impl
self.push(fn_var.call_function(self, self.popn(nargs), {}))
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/builtin.py", line 497, in call_function
proxy = tx.output.create_proxy(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 345, in create_proxy
return self.current_tracer.create_proxy(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1109, in create_proxy
new_arg = self.lift_tracked_freevar_to_input(arg)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1226, in lift_tracked_freevar_to_input
self.parent.lift_tracked_freevar_to_input(proxy)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1219, in lift_tracked_freevar_to_input
assert (
AssertionError: lift_tracked_freevar_to_input on root SubgraphTracer
from user code:
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1766, in test
return cond(x > 0, then, els, [])
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1764, in els
cell3 += cell2
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104222
Approved by: https://github.com/jansel
Added two signpost_event calls to torch.fx.experimental.symbolic_shapes, one for produce_guards (where we can give stats like how many free symbols and how many guards produced) and the other is for evaluate_expr after freeze (so we can look for cases where we're improperly discarding guards in backwards.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103882
Approved by: https://github.com/Skylion007
before the PR, when compiling a function with signature symint/symintlist/intlist, we have runtime error like ```argument 'shifts' must be tuple of ints, not FakeTensor```. see newly added unit test in test/dynamo/test_misc.py for repro
after the PR, for FakeTensor with empty size and numel()=1, we will try
to convert it into symint/symintlist. we will likely see expected
exception
```torch._subclasses.fake_tensor.DataDependentOutputException / aten._local_scalar_dense.default``` during conversion
reference PR:
* we handle FakeTensor for symintlist as 1st varags: https://github.com/pytorch/pytorch/pull/97508
* we handle FakeTensor for intlist in a similar way:
https://github.com/pytorch/pytorch/pull/85759/files
* call local_scalar_dense on a FakeTensor:
f7365eca90
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103448
Approved by: https://github.com/yanboliang
First, infra improvements: new combinator `expectedFailureDynamic` which subsumes expectedFailure calls in test_dynamic_shapes.py. It's just nicer to have these right with the test. Implementation in torch/_dynamo/testing.py and it works by putting an attr on the test, which is then converted into a real expectedFailure when we actually generate the dynamic shapes test class
Next, some housekeeping:
* test/dynamo/test_unspec.py accidentally was running mostly statically due to the `assume_static_by_default` config flip. Don't assume static by default and xfail some tests which regressed in that time.
* New test file test/dynamo/test_config.py, for testing permutations of configuration options. `test_dynamic_shapes` got moved there.
Finally, grinding through tests in a way that will make them more compatible with dynamic by default:
* If the test explicitly requires dynamic_shapes=False, remove that patch (and probably xfail it)
* If the test checks dynamic_shapes internally, remove that test and patch the test so it ALWAYS runs with dynamic_shapes (this is not coverage loss because we're going to switch the default)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103542
Approved by: https://github.com/anijain2305
The main concept behind this refactor is this: if we know that a size/stride/etc is constant, do NOT trace it into the graph, EXCEPT for any preexisting special cases that applied for static shapes. The refactor unfolds like this:
1. Delete the `dynamic_shapes` branches in torch/_dynamo/variables/builder.py which accept int/float/bool outputs. This is over-aggressive and we don't want to allow this (because if the operator returns a constant, we shouldn't have called wrap_fx_proxy in the first place.) This causes a bunch of failures because we are blindly feeding the result of size() call to wrap_fx_proxy when dynamic shapes is enabled.
2. Modify TensorVariable.call_method in torch/_dynamo/variables/tensor.py to avoid sending constant ints to wrap_fx_proxy. After normal specialization (which should be deleted, see https://github.com/pytorch/pytorch/pull/103434) we consult the fake tensor to see if the values in question have free variables or not. If they don't we short circuit tracing into graph. We only trace into graph if the operation in question is truly symbolic. Note that there is a near miss here: it's OK to trace x.size() call entirely into the graph, even if it doesn't have all dynamic shapes, because operator.getitem with int output is special cased in builder.py. This is a preexisting special case and I don't try to get rid of it.
3. It turns out that the change here also breaks torch_np compatibility layer. So I completely rewrite getattr handling in torch/_dynamo/variables/tensor.py to follow the same pattern (only trace into graph if truly dynamic).
There's some minor housekeeping in torch/fx/experimental/symbolic_shapes.py and some test files.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103438
Approved by: https://github.com/larryliu0820
Fixes: #101979
This PR adds support for dictionaries with torch object as keys in dynamo.
The main problem was that, for example, the source built for `d[torch.float]` (`d` being a
dictionary) was `ODictGetItemSource(GlobalSource('d'), index=torch.float)`. When
`Source.name` method was called, we got `odict_getitem(G['d'], torch.float)`. Evaluating
that string raised an error, since `torch` was only available in the global dictionary `G`
as `G["torch"]`.
Instead, this PR builds the source:
`ODictGetItemSource(GlobalSource('d'), index=AttrSource(GlobalSource('torch'), 'float'))`.
The to-be-evaluated string is correctly generated as:
`odict_getitem(G['d'], G['torch'].float)`.
Here's a minimal example that reproduces the error, before this PR:
```python
import torch
d = {
torch.float16: torch.float32,
}
@torch.compile
def f():
return torch.randn(3, dtype=d[torch.float16])
f()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103158
Approved by: https://github.com/mlazos
Fixes#102315
The root cause is for ```UnspecializedNNModuleVariable``` which extends from ```UserDefinedObjectVariable```, if ```__bool__``` is missing, we should use ```__len__``` to infer a truth value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102583
Approved by: https://github.com/jansel
Issue: #93684
In previous PRs #95849#99560 we redirect `numpy.*`, `<tensor>.numpy()` calls to `torch_np.*` methods and attributes, by creating `NumpyNdarrayVariable` for those calls.
We need to handle `NumpyNdarrayVariable` when graph break happens.
This PR did 2 things:
1. In `codegen.py` we made sure we can reconstruct the value wrapped by `NumpyNdarrayVariable`, to be `torch_np.ndarray` in the stack whenerver we recompiles the subgraph.
2. In `builder.py` we can wrap the value to be `NumpyNdarrayVariable` and save it as graph input.
-----
Starting from commit 6:
## A new design for supporting numpy in dynamo
In short the core concept doesn't change: we still convert `numpy` API calls to `torch_np` API calls. However, instead of wrapping a `torch_np.ndarray` in `NumpyNdarrayVariable`, the new design wraps a `torch.Tensor`.
The reason for doing this change is because we need to keep `torch.Tensor` everywhere in the captured graph, so that it works well with the backend of dynamo. See discussions in https://github.com/Quansight-Labs/numpy_pytorch_interop/issues/142 for details.
### Flow
This is an example showing how do we think about dynamo working on a simple function:
```python
def f(x: torch.Tensor, y: torch.Tensor):
a, b = x.numpy(), y.numpy()
c = np.add(x, y)
return torch.from_numpy(c)
```
```
+------------+ +------------+
torch.Tensor | |numpy.ndarray| |
-------------- .numpy() --------------| |
| | | | +------------------+
+------------+ | numpy.add |numpy.ndarray| |torch.Tensor
+------------+ | --------------| torch.from_numpy --------------
torch.Tensor | |numpy.ndarray| | | |
-------------- .numpy() --------------| | +------------------+
| | | |
+------------+ +------------+
+------------+ +----------------+
torch.Tensor | |torch.Tensor | |
-------------- .detach() --------------| |
| | | | +----------------+ +------------+
+------------+ | |torch_np.ndarray| |torch.Tensor| |torch.Tensor
| torch_np.add -----------------| util.to_tensor -------------| .detach() --------------
+------------+ | | | | | |
torch.Tensor | |torch.Tensor | | +----------------+ +------------+
-------------- .detach() --------------| |
| | | |
+------------+ | +----------------+ |
| wrapper on torch_np.add |
+--------------------------------------------------------+
```
### Approach
`torch_np` APIs can take both `torch_np.ndarray` as well as `torch.Tensor`. What we need to do is to have a wrapper for these APIs to convert the return value back to `torch.Tensor`. This way only the wrapper is showing up in the captured graph, with `torch.Tensor`s as input and `torch.Tensor` as output.
If we have a graph break or we've traced to the end of the program, we need to inspect all the `NumpyNdarrayVariable` in the stack and convert them back to `numpy.ndarray`, to make sure the compiled version is still behaving the same as the eager version.
### Examples
Here's an example of the graph generated:
```python
def fn(x: np.ndarray, y: np.ndarray):
a = x.real
b = y.real
torch._dynamo.graph_break()
return np.add(a, 1), np.add(b, 1)
```
Graph generated:
```
[2023-05-16 10:31:48,737] torch._dynamo.output_graph.__graph: [DEBUG] TRACED GRAPH
__compiled_fn_0 <eval_with_key>.0 opcode name target args kwargs
------------- -------------- ---------------------------------------------------------- ---------------------- --------
placeholder l_x_ L_x_ () {}
placeholder l_y_ L_y_ () {}
call_function from_numpy <built-in method from_numpy of type object at 0x12b1fdc80> (l_x_,) {}
call_function from_numpy_1 <built-in method from_numpy of type object at 0x12b1fdc80> (l_y_,) {}
call_function attr_wrapper <function attr_wrapper at 0x12e8693a0> (from_numpy, 'real') {}
call_function attr_wrapper_1 <function attr_wrapper at 0x12e8693a0> (from_numpy_1, 'real') {}
output output output ((),) {}
[2023-05-16 10:31:48,908] torch._dynamo.output_graph.__graph: [DEBUG] TRACED GRAPH
__compiled_fn_2 <eval_with_key>.1 opcode name target args kwargs
------------- ------------- ---------------------------------------------------------- ------------------------------- --------
placeholder l_a_ L_a_ () {}
placeholder l_b_ L_b_ () {}
call_function from_numpy <built-in method from_numpy of type object at 0x12b1fdc80> (l_a_,) {}
call_function from_numpy_1 <built-in method from_numpy of type object at 0x12b1fdc80> (l_b_,) {}
call_function wrapped_add <Wrapped function <original add>> (from_numpy, 1) {}
call_function wrapped_add_1 <Wrapped function <original add>> (from_numpy_1, 1) {}
output output output ((wrapped_add, wrapped_add_1),) {}
```
### Changes
* `codegen.py`: reconstruct `numpy.ndarray` from `NumpyNdarrayVariable` by adding bytecode to call `utils.to_numpy_helper()`.
* `output_graph.py`: getting rid of legacy code that does exactly what `codegen.py` does, which only handling return case but not graph break case.
* `utils.py`: added helpers to convert `numpy.ndarray` to `torch.Tensor` and vice versa. Also adding a wrapper class that takes in a function. In `__call__` it calls the function and converts its out to `torch.Tensor` (or a list of it).
* `builder.py`: add method to wrap `numpy.ndarray` graph inputs into `NumpyNdarrayVariable`, by calling `torch.numpy` in the proxy.
* `misc.py`: `numpy` API calls goes into `NumpyVariable` and we find the function with the same name in `torch_np` module, then wrap it with the wrapper defined in `utils.py`.
* `tensor.py`, `torch.py`: proxy `tensor.numpy()` to be `torch.detach()` but wrap it with `NumpyNdarrayVariable`. Similarly, `torch.from_numpy()` -> `torch.detach()` but wrap it with `TensorVariable`. In `NumpyNdarrayVariable`, do the similar `torch_np.ndarray` to `torch.Tensor` wrapping for attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100839
Approved by: https://github.com/ezyang
Failing mechanism on #95424 :
In dynamo mode, when passing numpy.int_ to 'shape' like param (Sequence[Union[int, symint]]) is wrapped as list with FakeTensor. However, in python_arg_parser, parser expect int in symint_list but got FakeTensor.
Following #85759, this PR allow tensor element in symint_list when in dynamo mode
This PR also fix below test with similar failing mechanism
pytest ./generated/test_huggingface_diffusers.py -k test_016
pytest ./generated/test_ustcml_RecStudio.py -k test_036
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97508
Approved by: https://github.com/yanboliang
Summary:
https://github.com/pytorch/pytorch/pull/98488 implements CSE for dynamo guards, and it relies on astunparse to perform the optimization.
`test_guards_cse_pass_single` was broken and later was fixed by introducing a check_and_skip_if_needed. This actually fixes the root cause on fbcode and should bring some perf gain internally.
Test Plan: `buck2 test @//mode/opt //caffe2/test/dynamo:test_dynamo -- --exact 'caffe2/test/dynamo:test_dynamo - test_misc.py::DynamicShapesMiscTests::test_guards_cse_pass_single' --run-disabled`
Reviewed By: malfet
Differential Revision: D46126742
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102120
Approved by: https://github.com/malfet
This PR adds support for tracing autograd.Function with grad.
A few important bullet points outlining our approach:
1) Our goal is to verify soundness in order to add a call_function to the autograd.Function's `apply` to the graph.
2) We achieve (1) by either verifying soundness or rejecting soundness, by ensuring that both forward and backward of the autograd.Function are sound.
3) For the forward, if we verify soundness, we install its guards into the graph.
4) For the backward, if we verify soundness, we throw it out. However, backwards soundness verification is more onerous, and has a config driven set of banned attrs and methods for tensors.
1-4 above are achieved by turning the forward and backward into UserDefinedFunctionVariables, and inlining through them, relying on dynamo's soundness detection. If we graph break in these, we raise and treat them as unsound. As noted above, backwards is stricter yet.
For the tracing, the safety comes from dynamo's HigherOrderOperator system. That system ensures that not only do we trace soundly, but that no new variables are lifted into inputs during the tracing, and that the forward and backwards are entirely self contained.
Whenever we reject a function as unsound, we restore back, as usual.
Due to some limitations in the lifting logic, we have an escape hatch we implemented for tensors that are known in forward, but cross into backwards through save_tensors (save) /saved_tensors (load). We escape hatch here to avoid having the known saved tensors coming from forward end up being accidentally treated as lifted variables (and rejected). This is sound, but a little hacky feeling.
Additionally, due to some limitations in fx node removal, combined with how we produce subgraphs for the traces installed from HigherOrderOperators, we had to improve our node removal logic. In the event of a restore, we remove the old nodes from the graph, as usual in dynamo. However, because the references to these nodes may exist in subgraphs, we traverse any nodes users and remove them first if and only if they are in another graph. This is always sound, because removal should only be downstream of restoration at this point.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99483
Approved by: https://github.com/zou3519
If `astunparse` is not installed, following guard will be generated in `test_guard_function_builder_with_cse`:
```python
def ___make_guard_fn():
def guard(L):
if not (x[0].a < x[1].a * (3 - x[2].a)):
return False
if not (a.b.c[0].d.e + a.b.c[1].d.e * a.b.c[2].d.e > 0):
return False
if not (f(m.n[0], '0').x.y.z * f(m.n[0], '1').x.y.z * f(m.n[0], '2').x.y.z < 512):
return False
if not (self.g(a, b).k + (1 - self.g(a, b).k) <= m[0].a + self.g(a, b).k):
return False
return True
return guard
```
Though, I have to say, hardcoding string comparison is pretty weird.
Also, skip `test_guards_cse_pass_[single|multiple]` if AST unparsing is missing.
Fixes failure in a test introduced by https://github.com/pytorch/pytorch/pull/98488
copilot:poem
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101805
Approved by: https://github.com/atalman, https://github.com/ysiraichi
Previously, anomaly detection was only enabled on the inner forward function, and not on the overall joint function that calls backward. I believe this impeded us from printing "this is the forward that triggered the backward" because that printing only happens if anomaly mode is enabled when you run backward(). This PR fixes it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101047
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Fixes#99665
Let me explain the root cause using the unit test I added:
* This bug is triggered when:
* ```wrapped``` is a nested function.
* ```wrapped``` is in another module which is different from the main function ```fn```.
* There is a graph break inside of ```wrapped```.
* The root cause is when resuming nested function, actually we are using the outermost function(```fn``` in my example)'s global variables, but ```wrapped``` calls ```inner_func``` which is not part of ```fn```'s globals, so we have to set correct globals when nested function resume execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100426
Approved by: https://github.com/jansel
Dynamo will frequently segfault when attempting to print stack traces. We fix this by:
- Fixing stack size calculations, as we did not account for exception tables
- Creating shadow execution frames in a way that more closely resembles what CPython does to create its execution frames
Dynamo/inductor-wrapped pytorch tests are enabled up the stack - those need to be green before this PR can be merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99934
Approved by: https://github.com/albanD, https://github.com/malfet, https://github.com/jansel
Fixes#99665
Let me explain the root cause using the unit test I added:
* This bug is triggered when:
* ```wrapped``` is a nested function.
* ```wrapped``` is in another module which is different from the main function ```fn```.
* There is a graph break inside of ```wrapped```.
* The root cause is when resuming nested function, actually we are using the outermost function(```fn``` in my example)'s global variables, but ```wrapped``` calls ```inner_func``` which is not part of ```fn```'s globals, so we have to set correct globals when nested function resume execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100426
Approved by: https://github.com/jansel
Currently, we return `unimplemented` w/o a graph break on seeing a x.unsqueeze_ when x is input. This essentially means we fall back to the original frame.
This PR actually graph breaks so that we can generate the continuation frame for the rest of the function. Instead of graph breaking at LOAD_ATTR, we delay the graph break to the actual CALL_FUNCTION, where its cleaner to graph break.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99986
Approved by: https://github.com/jansel
All Sources must be hashable, since we are using set equality to check for
duplicate sources in AOTAutograd. We should have a more systematic way
of asserting this. For this PR just fix the local issue.
Fixes#99145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99379
Approved by: https://github.com/ezyang
Summary of changes:
- Add CPython exceptiontable parsing/assembling functions in torch/_dynamo/bytecode_transformation.py, based on https://github.com/python/cpython/blob/3.11/Objects/exception_handling_notes.txt.
- Add optional `exn_tab_entry` field to dynamo `Instruction`s in torch/_dynamo/bytecode_transformation.py in order to virtualize exception table entries (start, end, target instructions).
- Add checks guarding against duplicate instructions in dynamo, so that jump/exceptiontable targets are unambiguous. See `get_indexof` in torch/_dynamo/bytecode_analysis.py. Ensure that bytecode generation throughout dynamo does not generate duplicate instructions.
- Allow dynamo bytecode generation logic to generate nested exception table entries for developer convenience. CPython expects entries to not overlap, so we flatten nested entries during assembly in torch/_dynamo/bytecode_transformation.py:compute_exception_table.
- Simulate the block stack in torch/_dynamo/symbolic_convert.py. CPython removed the block stack in 3.11, but dynamo needs it in order to keep track of active contexts. So we simulate the block stack as before by looking at exceptiontable entries in order to determine the current blocks.
- Update context codegen in torch/_dynamo/resume_execution.py. The `SETUP_FINALLY` bytecode, which conveniently had a jump target to the finally block, was removed in 3.11, so we need to keep track of the jump target of the finally block using exceptiontables. Generating resume functions is more difficult since the original exceptiontable entries pointing to old cleanup code need to be modified to point to new cleanup code.
- Fix a push_null bug in torch/_dynamo/variables/functions.py introduced by https://github.com/pytorch/pytorch/pull/98699
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96511
Approved by: https://github.com/jansel, https://github.com/yanboliang, https://github.com/albanD
* Introduce a frame counter which lets us uniquely identify frames.
This makes it easier to tell if you are recompiling the same frame
* Shorten evaluate_expr to eval for more visual distinctiveness
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99159
Approved by: https://github.com/Skylion007
Summary -
`disallow_in_graph` is mostly useful for backends. Suppose, your backend does not support `torch.abs()`. So, you can use `disallow_in_graph` to do a graph break.
The assumption in the above statement is that `disallow_in_graph` is called on an `allowed` callable. `allowed` in Dynamo language refers to a callable that is put as-is in the Dynamo graph.
Therefore, if one uses `disallow_in_graph` on some non-torch non-allowed function, we want to raise an exception to tell user that they probably want something else.
* If they want to disable Dynamo - they should use torch._dynamo.disable
* If they wanted to stop inlining - they should use torch._dynamo.graph_break. However this is not a decorator. So, we need to provide another API. But, the question - who would want to do this?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98892
Approved by: https://github.com/jansel
Summary: Add new experimental python op (`torch.nonzero_static`) for export. There is NO cuda impl included in this PR
Example:
Say input tensor is `x = torch.tensor([[1, 0], [3, 2]])`
call regular `nonzero()` on x will give you a tensor `tensor([[0, 0], [1, 0], [1, 1])`
call `nonzero_static(x, size=4)` on x will give you a tensor `tensor([[0, 0], [1, 0], [1, 1], [fill_value, fill_value])` (padded)
call `nonzero_static(x, size=2)` on x will give you a tensor `tensor([[0, 0], [1, 0])` (truncated)
Test Plan:
**Unit Tests**
```
buck test @mode/dev-nosan //caffe2/test:test_dynamo -- 'caffe2/test:test_dynamo - test_export.py::ExportTests::test_export_with_nonzero_static' -- 'caffe2/test:test_dynamo - test_misc.py::MiscTests::test_nonzero_static'
```
**PT2 Export with `nonzero_static()`**
Example of `GraphModule` in the exported graph
```
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
nonzero_static_default = torch.ops.aten.nonzero_static.default(arg0, size = 4); arg0 = None
return pytree.tree_unflatten([nonzero_static_default], self._out_spec)
```
Differential Revision: D44324808
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97417
Approved by: https://github.com/ezyang
In the terminal state, it won't matter if you have dynamic_shapes
on or not, mark_dynamic will always work.
Today, it's helpful to make this not error so I can easily swap
between static or not and run experiments.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98324
Approved by: https://github.com/voznesenskym
repo:
from #92670 this address one of the bug for TorchDynamo
pytest ./generated/test_PeterouZh_CIPS_3D.py -k test_003
Issue:
In GuardBuilder, when parsing argnames with "getattr(a.layers[slice(2)][0]._abc, '0')" it returns "getattr(a", where it suppose to return "a", and thus causing SyntaxError.
This PR fix the regex and add couple test cases.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97810
Approved by: https://github.com/yanboliang
The purpose of this API is to execute a few large components of work:
1) Refactor all the internals of plumbing dynamic dimension information after dynamo to be stateless
2) Decouple allocation controls around dynamic dimensions from verification
3) For (2), for allocation, create an enum that dictates whether we are in DUCK (default today), STATIC (aka assume_static_default in the past), or DYNAMIC (aka user constrained, do not duck shape)
4) For (2), for verification, we separate out the list of dynamic ranges entirely from allocation. This means shape_env does not tracking for what we verify on, and instead, it is the callers job to invoke produce_guards() with the various things they want verified, specifically, with the valid ranges. We do use constrain ranges to refine value ranges when doing analysis.
5) We have decided, therefore, as an extension of (4) to double down on "late" checks versus "eager" checks, primarily because the mechanisms for gathering what actually matters happens during guards, and should be a purview of the caller seeking guards, not the shape env. However, for dynamo, these structures are essentially one and the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96699
Approved by: https://github.com/avikchaudhuri, https://github.com/ezyang
The purpose of this PR is to remove reliance on argument positions in dedup guards, AND extend the functionality to params.
A version of this PR was stamped prior https://github.com/pytorch/pytorch/pull/95831 - but was kinda gross, because it was based on an underlying PR that did way too much with source names.
This PR leaves most of that alone, in favor of just reusing the same name standardization logic that dynamo module registration does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96774
Approved by: https://github.com/ezyang
Previously, when starting to trace a function, we would record a frame summary recording the definition loc. This would lead to an unconventional-looking stack trace when used for debugging, e.g., shape guards.
```
File ".../scripts/avik/pt2/example.py", line 407, in forward
def forward(self, x):
...
File ".../transformers/models/bert/modeling_bert.py", line 912, in forward
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
...
File ".../transformers/models/bert/modeling_bert.py", line 562, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 484, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 416, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 275, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 351, in forward
attention_scores = attention_scores + attention_mask
```
As noted in https://github.com/pytorch/pytorch/pull/95848#discussion_r1134397096, we would like to change this to record function calls instead, like conventional stack traces do. This diff makes this change. The above stack now looks like the following, which is way more helpful at a glance to understand what's going on.
```
File ".../scripts/avik/pt2/example.py", line 408, in forward
bert_out = self.bert(**x)
...
File ".../transformers/models/bert/modeling_bert.py", line 1021, in forward
encoder_outputs = self.encoder(
...
File ".../transformers/models/bert/modeling_bert.py", line 610, in forward
layer_outputs = layer_module(
...
File ".../transformers/models/bert/modeling_bert.py", line 496, in forward
self_attention_outputs = self.attention(
...
File ".../transformers/models/bert/modeling_bert.py", line 426, in forward
self_outputs = self.self(
...
File ".../transformers/models/bert/modeling_bert.py", line 351, in forward
attention_scores = attention_scores + attention_mask
```
Differential Revision: [D44101882](https://our.internmc.facebook.com/intern/diff/D44101882/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96882
Approved by: https://github.com/ezyang
# Summary
This PR adds an optional kwarg to torch torch.nn.functional.scaled_dot_product_attention()
The new kwarg is a scaling factor that is applied after the q@k.T step of the computation. Made updates to the efficient kernel to support but flash and math were minimally updated to support as well.
Will reduce the complexity of: #94729 and has been asked for by a couple of users.
# Review Highlights
- As far as I know I did this the correct way and this both BC and FC compliant. However I always seem to break internal workloads so I would love if someone can advice I did this right?
- I named the optional arg 'scale'. This is probably dumb and I should name it 'scale_factor'. I will make this change but this is annoying and it will require someone thinking we should rename.
- 'scale' is interpreted as `Q@K.T * (scale)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95259
Approved by: https://github.com/cpuhrsch
Adds a profiler start and end callback to dynamo's C eval_frame impl, which can be used to profile a region providing a name for visualization. Currently only hooks up one usage to profile cache lookup (primarily covering guards and linear search through linked list).
Example profile taken from toy model:
`python benchmarks/dynamo/distributed.py --toy_model --profile --dynamo aot_eager`
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/4984825/223225931-b2f6c5a7-505a-4c90-9a03-34982f6dc033.png">
Planning to measure overhead in CI, and probably can't afford to check this in enabled by default. Will have to evaluate UX options such as `config.profile_dynamo_cache = True` or some other way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96119
Approved by: https://github.com/jansel
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
This PR allows us to reuse the static per tensor decision making we make at fake tensorification time. We can use this to avoid setting up dynamic dim guards later if the tensor was never a candidate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95566
Approved by: https://github.com/ezyang
Fixes issues with things like:
```python
x = 2
x += y.shape[0]
```
resulting in invalid `2 += y.shape[0]` code in the FX graph.
Fix: Whenever dynamic shapes are involved, insert the out-of-place op to the FX graph instead of the in-place op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95446
Approved by: https://github.com/ezyang
**Summary**: torch.nn.Module implementations previously did not support custom implementations of `__getattr__`; if a torch.nn.Module subclass implemented `__getattr__` and we tried to access an attribute that was expected to be present in `__getattr__`, dynamo would not check `__getattr__` and would error out with an AttributeError. This PR copies the functionality from UserDefinedObjectVariable into torch.nn.Module so that it also supports `__getattr__`
Example of a module which previously would fail:
```python
class MyMod(torch.nn.Module):
def __init__(self):
super().__init__()
self.custom_dict = {"queue": [torch.rand((2, 2)) for _ in range(3)]}
self.other_attr = torch.rand((2, 2))
def __getattr__(self, name):
custom_dict = self.custom_dict
if name in custom_dict:
return custom_dict[name]
return super().__getattr__(name)
def forward(self, x):
return x @ self.other_attr + self.queue[-1]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94658
Approved by: https://github.com/yanboliang, https://github.com/jansel
Fixes https://github.com/pytorch/pytorch/issues/93890
We do the following:
1. fix __init__constructor for `AutocastModeVariable` with exisiting `mode` while copying
2. `resume_execution` is made aware of constant args (`target_values`), by storing said args in `ReenterWith`. To propagate between subgraphs (in straightline code), we also store the constant args in the downstream's `code_options["co_consts"]` if not already.
---
Future work:
1. handle instantiating context manager in non-inlineable functions. Simultaneously fix nested grad mode bug.
2. generalize to general `ContextManager`s
3. generalize to variable arguments passed to context manager, with guards around the variable.
---
Actually, if we look at the repro: 74592a43d0/test/dynamo/test_repros.py (L1249), we can see that the method in this PR doesn't work for graph breaks in function calls, in particular, in function calls that don't get inlined.
Why inlining functions with graph breaks is hard:
- When we handle graph breaks, we create a new code object for the remainder of the code. It's hard to imagine doing this when you are inside a function, then we need a frame stack. And we just want to deal with the current frame as a sequence of straight line codes.
Why propagating context manager information is hard:
- If we do not inline the function, the frame does not contain any information about the parent `block_stack` or `co_consts`. So we cannot store it on local objects like the eval frame. It has to be a global object in the output_graph.
---
Anyway, I'm starting to see clearly that dynamo must indeed be optimized for torch use-case. Supporting more general cases tends to run into endless corner-cases and caveats.
One direction that I see as viable to handle function calls which have graph breaks and `has_tensor_in_frame` is stick with not inlining them, while installing a global `ContextManagerManager`, similar to the `CleanupManager` (which cleans up global variables). We can know which context managers are active at any given point, so that we can install their setup/teardown code on those functions and their fragments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94137
Approved by: https://github.com/yanboliang
Supports the following with dynamic shapes:
```python
for element in tensor:
# do stuff with element
```
Approach follows what's done when `call_range()` is invoked with dynamic shape inputs: guard on tensor size and continue tracing with a real size value from `dyn_dim0_size.evaluate_expr()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94326
Approved by: https://github.com/ezyang
**Problem**: For a tensor `x`, you can assign `x.my_attr = 3.14` and then later access it. Dynamo does not support this right now; it errors out with an AttributError (it was broken in #91840).
**Fix**: This fixes the problem by catching AttributeErrors in dynamo if we try to access an attr that does not exist on a standard torch.Tensor.
**Tests**: Added tests for accessing and setting attributes to make sure dynamo does not error out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94332
Approved by: https://github.com/yanboliang
By moving guard string assembly into dynamo's default behavior and letting code_parts do the work, we can have much better shape guard failures.
Before this fix, the guard failure in the test would look like:
```
'x.size()[1] == x.size()[0] and x.stride()[0] == x.[264 chars]!= 1' != 'x.size()[0] < 3'
- x.size()[1] == x.size()[0] and x.stride()[0] == x.size()[0] and x.stride()[1] == 1 and x.storage_offset() == 0 and y.size()[0] == x.size()[0] and y.size()[1] == x.size()[0] and y.stride()[0] == x.size()[0] and y.stride()[1] == 1 and y.storage_offset() == 0 and x.size()[0] < 3 and x.size()[0] != 0 and x.size()[0] != 1
+ x.size()[0] < 3
```
now it is
```
"x.size()[0] < 3"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93894
Approved by: https://github.com/ezyang
# Summary
This PR creates _flash_attention_backward and _scaled_dot_product_flash_attention_backward native functions and registers them to the respective derivatives.yaml.
The goal is to replicate the torch.autograd.Function defined in the FlashAttention repo [here](33e0860c9c/flash_attn/flash_attn_interface.py (L126)) natively in PyTorch. One thing that we don't have access to is ctx.save_for_backward in native PyTorch so in order to save these variables I extended the returned objects from the forward functions.
### MetaFunctions
I also updated the FlashAttention meta functions to mirror the real outputs now. As well I added a meta registration for backwards. I have an XLMR training script and while eager training now works with FlashAttention compiling this module fails with the inductor error down below.
### Questions?
Performance issues vs mem efficient when using torch.nn.mha_forward
TorchCompile -> See purposed solution below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92917
Approved by: https://github.com/cpuhrsch
**Background:** Before this PR, support in dynamo for tensor attributes (e.g. `x.H`, `x.T`, ...) need to be individually implemented one-by-one. This could potentially lead to errors, e.g. if the implementation in [variables/tensor.py](21c7c7c72f/torch/_dynamo/variables/tensor.py (L160)) differs from the implementation from a direct call to the attribute. For attributes that were not special-cased in tensor.py, dynamo tracing would fail. This PR adds generic support for tensor attributes that return tensors without needing to specially handle them. (Notably, for x.real and x.imag, which previously weren't supported).
**In this PR:** This directly creates a proxy node for a `"call_function"` node with `target=getattr`, and feeds it into wrap_fx_proxy. This will produce a TensorVariable for the attribute returned.
This also removes the implementations for H, T, mH, mT which were broken (previously `torch.relu(x.T)` would fail). They now fall back to this default implementation (for which `torch.relu(x.T)` passes).
**Further context**:
* Ed's original suggestion in [90463](https://github.com/pytorch/pytorch/pull/90463#discussion_r1043398340) is to use `torch.Tensor.H.__get__(x)`. I wasn't able to get this to work; fx compilation fails with `getset_descriptor does not have attribute __module__`. Basically, the `__module__` attribute which is available on most python attributes, is not available on `getset_descriptor` objects. (i.e., these are implemented in C++ as attributes on torch.Tensor, so they don't obey some assumptions made by fx)
* Although both tensor attributes and methods (like `x.relu()`) both go through this, this PR should only handle attributes (e.g. see the `"getset_descriptor"` in variables/tensor.py). Methods are handled already by by GetAttrVariable.
* Prior to this PR, we already returned GetAttrVariables for unsupported attrs: the parent caller would catch the NotImplementedError and fallback to returning a GetAttrVariable. But if this GetAttrVariable was ever passed into a torch.\* function (as it could quite possibly be, since most of these attrs are tensors), it would fail because its proxy node would be missing an [example_value](https://github.com/pytorch/pytorch/blob/master/torch/_dynamo/utils.py#L1017). So: before, for some tensor x, `x.real` would work fine; but `torch.relu(x.real)` would fail.
**Testing**: added tests in test_misc.py for x.real, x.imag, x.T, x.real.T.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91840
Approved by: https://github.com/ezyang
Previously, Dynamo faked support for item() when `capture_scalar_outputs` was True by representing it internally as a Tensor. With dynamic shapes, this is no longer necessary; we can represent it directly as a SymInt/SymFloat. Do so. Doing this requires you to use dynamic shapes; in principle we could support scalar outputs WITHOUT dynamic shapes but I won't do this unless someone hollers for it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Differential Revision: [D42885775](https://our.internmc.facebook.com/intern/diff/D42885775)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93150
Approved by: https://github.com/voznesenskym
This PR adds `@comptime`, a decorator that causes a given function to be executed at compile time when Dynamo is symbolically evaluating their program. To query the Dynamo state, we offer a public ComptimeContext API which provides a limited set of APIs for querying Dynamo's internal state. We intend for users to use this API and plan to keep it stable. Here are some things you can do with it:
* You want to breakpoint Dynamo compilation when it starts processing a particular line of user code: give comptime a function that calls breakpoint
* You want to manually induce a graph break for testing purposes; give comptime a function that calls unimplemented
* You want to perform a debug print, but you don't want to induce a graph break; give comptime a function that prints.
* You can print what the symbolic locals at a given point in time are.
* You can print out the partial graph the Dynamo had traced at this point.
* (My original motivating use case.) You want to add some facts to the shape env, so that a guard evaluation on an unbacked SymInt doesn't error with data-dependent. Even if you don't know what the final user API for this should be, with comptime you can hack out something quick and dirty. (This is not in this PR, as it depends on some other in flight PRs.)
Check out the tests to see examples of comptime in action.
In short, comptime is a very powerful debugging tool that lets you drop into Dynamo from user code, without having to manually jerry-rig pdb inside Dynamo to trigger after N calls.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90983
Approved by: https://github.com/jansel
Tracing `torch.backends.cudnn.is_acceptable(Tensor) -> bool:` fails with:
```
...
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/functions.py", line 196, in call_function
return super(UserFunctionVariable, self).call_function(tx, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/functions.py", line 67, in call_function
return tx.inline_user_function_return(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 426, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1698, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1752, in inline_call_
tracer.run()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 485, in run
and self.step()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 455, in step
getattr(self, inst.opname)(inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 281, in wrapper
return inner_fn(self, inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 912, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 389, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/torch.py", line 431, in call_function
tensor_variable = wrap_fx_proxy(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 662, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 820, in wrap_fx_proxy_cls
raise AssertionError(
AssertionError: torch.* op returned non-Tensor bool call_function <function is_acceptable at 0x7f00deefb790>
```
So instead, evaluate `is_acceptable()` and convert the result to a constant. The result of `is_acceptable(tensor) -> bool` depends on:
* dtype/device of the input tensor (this should already be guarded)
* properties of the build & whether cudnn is available
* some global state that gets initialized during the first call to `torch.backends.cudnn._init()` (this is NOT guarded in this PR)
Note: this fixes tts_angular with FSDP. This was an issue with FSDP because FSDP modules are interpreted as UnspecializedNNModules, and UnspecializedNNModules try to inline calls. In comparison, NNModules (e.g. when the tts_angular model is not wrapped in FSDP) do not inline calls and instead evaluate subsequent calls. In subsequent calls, cudnn.is_acceptable would be skipped by eval_frame.py:catch_errors because it is not in an allowlist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90323
Approved by: https://github.com/jansel
This PR introduces a new function we can pass to torch._dynamo.optimize - guard_failure_fn. Usage is in the PR, and the one stacked on top of it, but the gist of it is that it emits failed guard reason strings alongside code. This is useful for tests and debugging, as it gives far finer grained assertions and control than the compile counter alone.
This is a resubmit of https://github.com/pytorch/pytorch/pull/90129
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90371
Approved by: https://github.com/ezyang
The current cond implementation is silently incorrect when
there are outstanding side effects, since the locally tracked
side effects are lost when the recursive export call is made.
At least we raise an assert now.
I'm working on a refactor of cond which should be able to sidestep
this problem. Maybe.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: [D41746973](https://our.internmc.facebook.com/intern/diff/D41746973)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90208
Approved by: https://github.com/voznesenskym
This is a group of bug fixes for [7k github models](https://github.com/pytorch/torchdynamo/issues/1884), it would fix 30+ model tests.
* Support ```tensor.type()```.
* Support ```tensor.get_device()```.
* Support ```torch.nn.functional._Reduction.get_enum```.
* Support ```torch._utils._get_device_index()```.
* Fallback ```tensor.data_ptr()```.
* ```FakeTensor``` always returns 0
* For no fake tensor propagation, we ```clone``` the input tensor, which makes no sense to track the original ```data_ptr```. And I don't think this is a very popular API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89486
Approved by: https://github.com/jansel
Fix bugs in [7k github models](https://github.com/pytorch/torchdynamo/issues/1884).
* Legacy code still use ```tensor.data```, I think we can use ```tensor.detach``` to rewrite, not sure if there is anything I didn't anticipate.
* Support ```tensor.layout```.
The root cause of these issues are: dynamo wraps unimplemented ```tensor.x``` call into ```GetAttrVariable(TensorVariable, x)```, but this op was not inserted into FX graph. Hence, during the fake tensor propagation, it throws ```KeyError: 'example_value` ```.
For these two popular attributes, Dynamo should support them anyway. However, if dynamo should support ___all___ ```tensor.x``` call and not fallback to ```GetAttrVariable```, I think it's debatable.
If I turn off fake tensor propagation, it works well even not including this fix. So I'm curious if we should improve the fake propagation to cover similar cases. cc @mlazos @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @jansel @eellison
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 404, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 392, in transform
tracer.run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 1523, in run
super().run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 389, in run
and self.step()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 359, in step
getattr(self, inst.opname)(inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 193, in wrapper
return inner_fn(self, inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 865, in CALL_FUNCTION_KW
self.call_function(fn, args, kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 301, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/torch.py", line 407, in call_function
tensor_variable = wrap_fx_proxy(
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/builder.py", line 636, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/builder.py", line 676, in wrap_fx_proxy_cls
example_value = get_fake_value(proxy.node, tx)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1024, in get_fake_value
args, kwargs = torch.fx.node.map_arg((node.args, node.kwargs), visit)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 613, in map_arg
return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 621, in map_aggregate
t = tuple(map_aggregate(elem, fn) for elem in a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 621, in <genexpr>
t = tuple(map_aggregate(elem, fn) for elem in a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 627, in map_aggregate
return immutable_dict((k, map_aggregate(v, fn)) for k, v in a.items())
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 627, in <genexpr>
return immutable_dict((k, map_aggregate(v, fn)) for k, v in a.items())
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 631, in map_aggregate
return fn(a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 613, in <lambda>
return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1022, in visit
return n.meta["example_value"]
KeyError: 'example_value\n\nfrom user code:\n File "./generated/test_BayesWatch_pytorch_prunes.py", line 108, in forward\n return torch.zeros([x.size()[0], self.channels, x.size()[2] // self.spatial, x.size()[3] // self.spatial], dtype=x.dtype, layout=x.layout, device=x.device)\n\nSet torch._dynamo.config.verbose=True for more information\n\n\nYou can suppress this exception and fall back to eager by setting:\n torch._dynamo.config.suppress_errors = True\n'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89257
Approved by: https://github.com/jansel
Fixes error from 7k github models: https://github.com/jansel/pytorch-jit-paritybench/blob/master/generated/test_arashwan_matrixnet.py
Error:
```
AssertionError: torch.* op returned non-Tensor bool call_function <function is_tensor at 0x7fca94d0faf0>
from user code:
File "/scratch/ybliang/work/repos/pytorch-jit-paritybench/generated/test_arashwan_matrixnet.py", line 749, in scatter
return scatter_map(inputs)
File "/scratch/ybliang/work/repos/pytorch-jit-paritybench/generated/test_arashwan_matrixnet.py", line 741, in scatter_map
assert not torch.is_tensor(obj), 'Tensors not supported in scatter.'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88704
Approved by: https://github.com/jansel
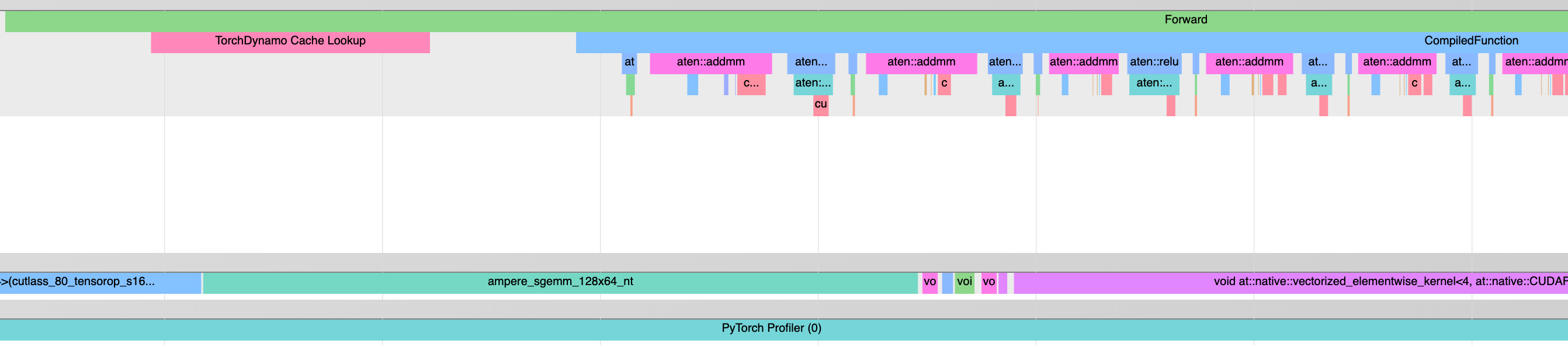{kind=link}